 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Most Language Models can be Poets too: An AI Writing Assistant and Constrained Text Generation Studio
Jun 28, 2023

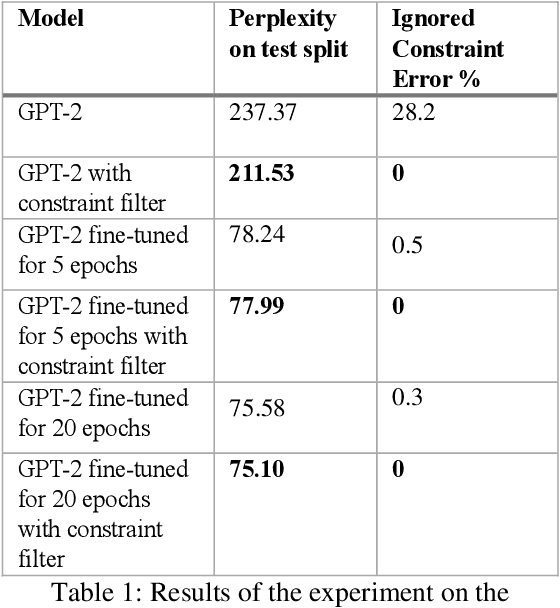
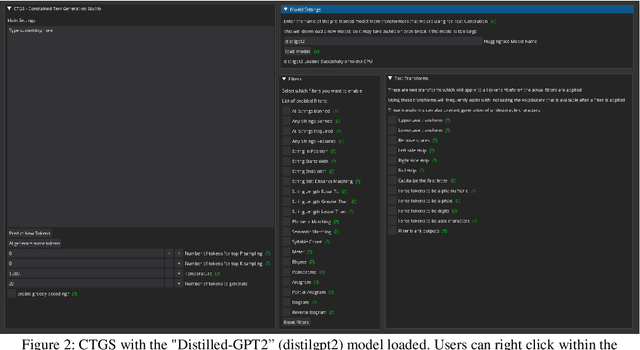
Despite rapid advancement in the field of Constrained Natural Language Generation, little time has been spent on exploring the potential of language models which have had their vocabularies lexically, semantically, and/or phonetically constrained. We find that most language models generate compelling text even under significant constraints. We present a simple and universally applicable technique for modifying the output of a language model by compositionally applying filter functions to the language models vocabulary before a unit of text is generated. This approach is plug-and-play and requires no modification to the model. To showcase the value of this technique, we present an easy to use AI writing assistant called Constrained Text Generation Studio (CTGS). CTGS allows users to generate or choose from text with any combination of a wide variety of constraints, such as banning a particular letter, forcing the generated words to have a certain number of syllables, and/or forcing the words to be partial anagrams of another word. We introduce a novel dataset of prose that omits the letter e. We show that our method results in strictly superior performance compared to fine-tuning alone on this dataset. We also present a Huggingface space web-app presenting this technique called Gadsby. The code is available to the public here: https://github.com/Hellisotherpeople/Constrained-Text-Generation-Studio
Restart Sampling for Improving Generative Processes
Jun 26, 2023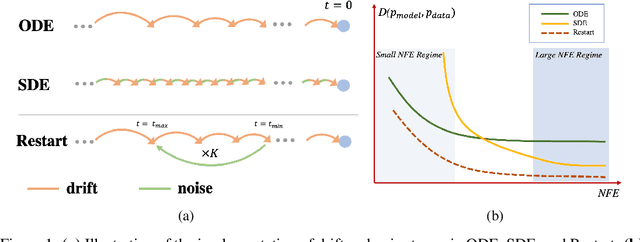
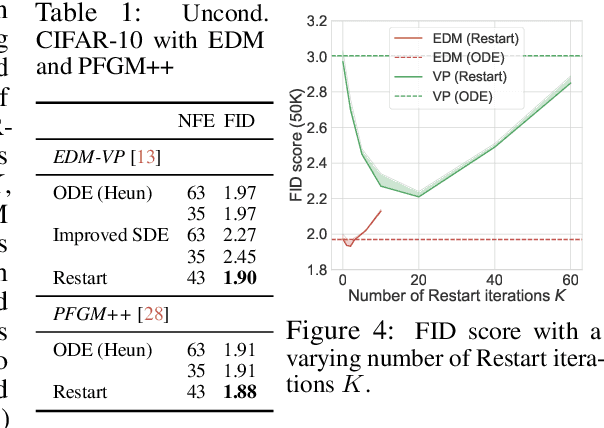
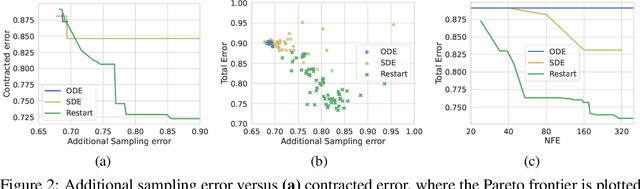

Generative processes that involve solving differential equations, such as diffusion models, frequently necessitate balancing speed and quality. ODE-based samplers are fast but plateau in performance while SDE-based samplers deliver higher sample quality at the cost of increased sampling time. We attribute this difference to sampling errors: ODE-samplers involve smaller discretization errors while stochasticity in SDE contracts accumulated errors. Based on these findings, we propose a novel sampling algorithm called Restart in order to better balance discretization errors and contraction. The sampling method alternates between adding substantial noise in additional forward steps and strictly following a backward ODE. Empirically, Restart sampler surpasses previous SDE and ODE samplers in both speed and accuracy. Restart not only outperforms the previous best SDE results, but also accelerates the sampling speed by 10-fold / 2-fold on CIFAR-10 / ImageNet $64 \times 64$. In addition, it attains significantly better sample quality than ODE samplers within comparable sampling times. Moreover, Restart better balances text-image alignment/visual quality versus diversity than previous samplers in the large-scale text-to-image Stable Diffusion model pre-trained on LAION $512 \times 512$. Code is available at https://github.com/Newbeeer/diffusion_restart_sampling
SIMF: Semantics-aware Interactive Motion Forecasting for Autonomous Driving
Jun 26, 2023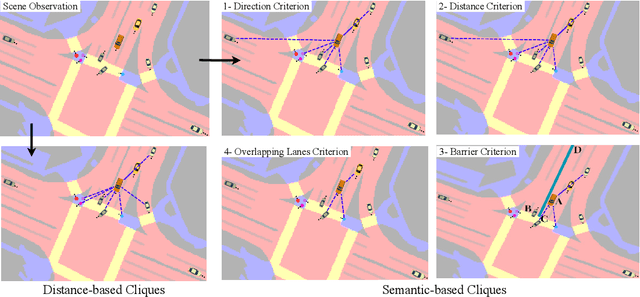
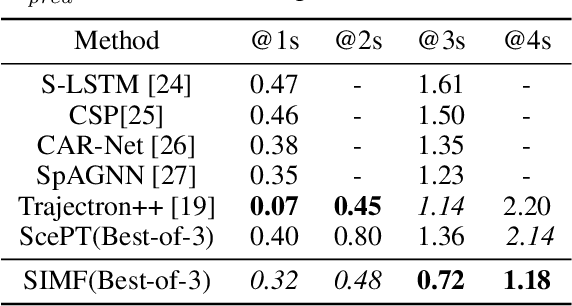
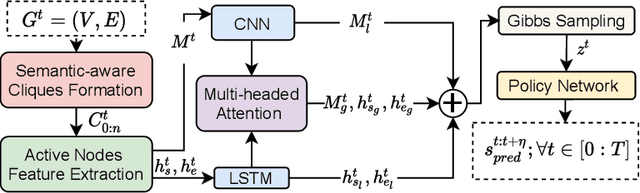
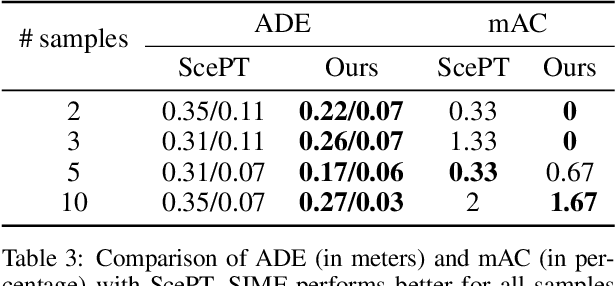
Autonomous vehicles require motion forecasting of their surrounding multi-agents (pedestrians and vehicles) to make optimal decisions for navigation. The existing methods focus on techniques to utilize the positions and velocities of these agents and fail to capture semantic information from the scene. Moreover, to mitigate the increase in computational complexity associated with the number of agents in the scene, some works leverage Euclidean distance to prune far-away agents. However, distance-based metric alone is insufficient to select relevant agents and accurately perform their predictions. To resolve these issues, we propose Semantics-aware Interactive Motion Forecasting (SIMF) method to capture semantics along with spatial information, and optimally select relevant agents for motion prediction. Specifically, we achieve this by implementing a semantic-aware selection of relevant agents from the scene and passing them through an attention mechanism to extract global encodings. These encodings along with agents' local information are passed through an encoder to obtain time-dependent latent variables for a motion policy predicting the future trajectories. Our results show that the proposed approach outperforms state-of-the-art baselines and provides more accurate predictions in a scene-consistent manner.
Balanced Filtering via Non-Disclosive Proxies
Jun 26, 2023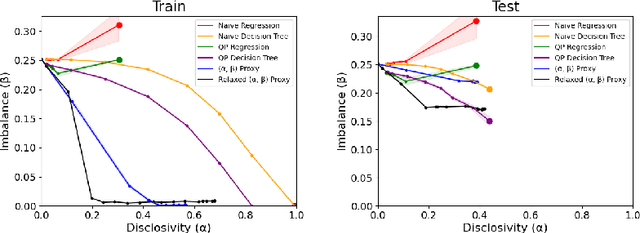
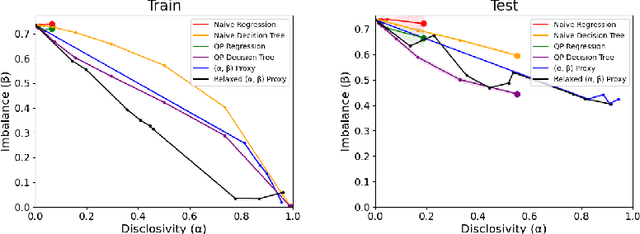
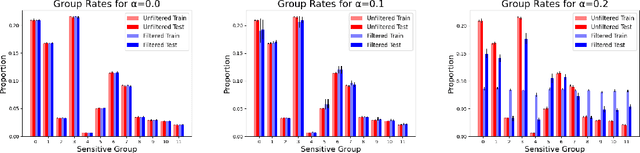
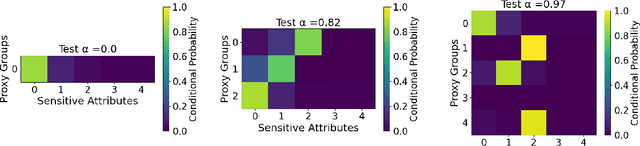
We study the problem of non-disclosively collecting a sample of data that is balanced with respect to sensitive groups when group membership is unavailable or prohibited from use at collection time. Specifically, our collection mechanism does not reveal significantly more about group membership of any individual sample than can be ascertained from base rates alone. To do this, we adopt a fairness pipeline perspective, in which a learner can use a small set of labeled data to train a proxy function that can later be used for this filtering task. We then associate the range of the proxy function with sampling probabilities; given a new candidate, we classify it using our proxy function, and then select it for our sample with probability proportional to the sampling probability corresponding to its proxy classification. Importantly, we require that the proxy classification itself not reveal significant information about the sensitive group membership of any individual sample (i.e., it should be sufficiently non-disclosive). We show that under modest algorithmic assumptions, we find such a proxy in a sample- and oracle-efficient manner. Finally, we experimentally evaluate our algorithm and analyze generalization properties.
Single-shot 3D photoacoustic computed tomography with a densely packed array for transcranial functional imaging
Jun 26, 2023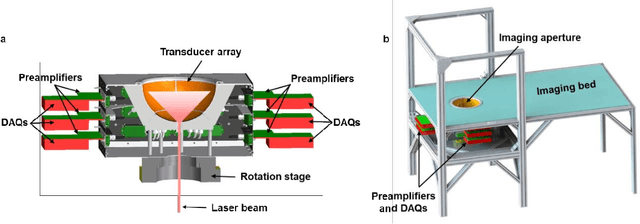
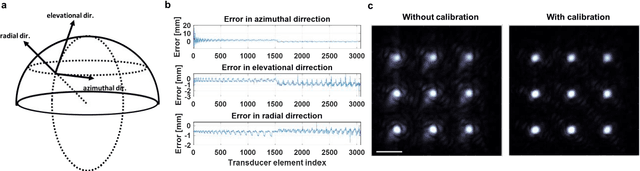

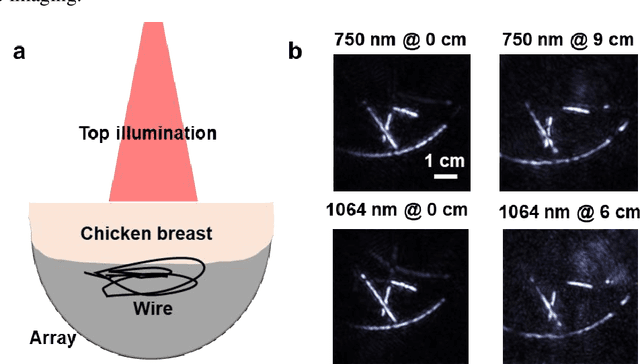
Photoacoustic computed tomography (PACT) is emerging as a new technique for functional brain imaging, primarily due to its capabilities in label-free hemodynamic imaging. Despite its potential, the transcranial application of PACT has encountered hurdles, such as acoustic attenuations and distortions by the skull and limited light penetration through the skull. To overcome these challenges, we have engineered a PACT system that features a densely packed hemispherical ultrasonic transducer array with 3072 channels, operating at a central frequency of 1 MHz. This system allows for single-shot 3D imaging at a rate equal to the laser repetition rate, such as 20 Hz. We have achieved a single-shot light penetration depth of approximately 9 cm in chicken breast tissue utilizing a 750 nm laser (withstanding 3295-fold light attenuation and still retaining an SNR of 74) and successfully performed transcranial imaging through an ex vivo human skull using a 1064 nm laser. Moreover, we have proven the capacity of our system to perform single-shot 3D PACT imaging in both tissue phantoms and human subjects. These results suggest that our PACT system is poised to unlock potential for real-time, in vivo transcranial functional imaging in humans.
Iterative-in-Iterative Super-Resolution Biomedical Imaging Using One Real Image
Jun 26, 2023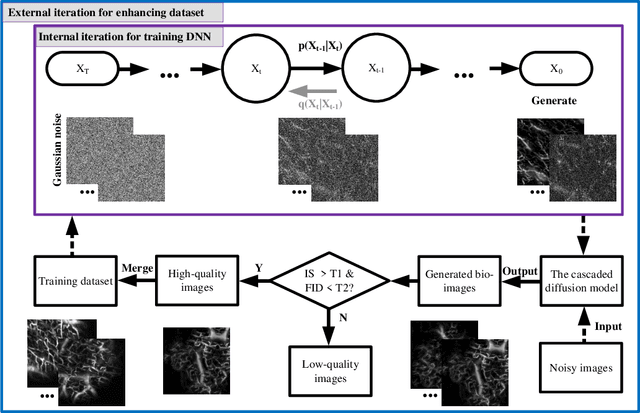
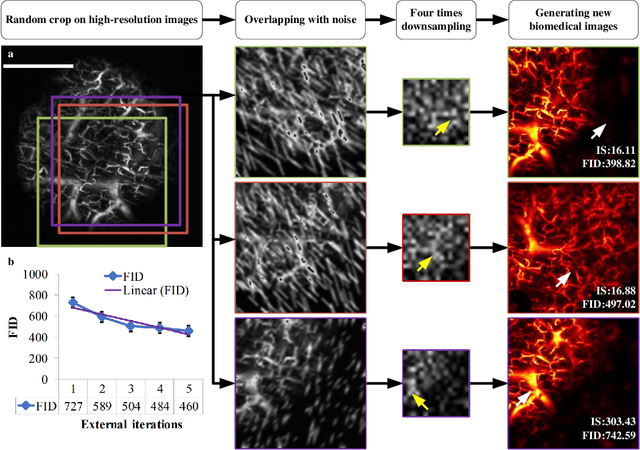
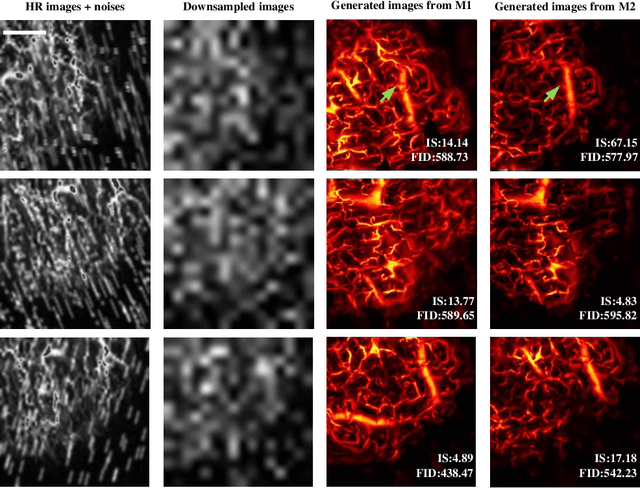
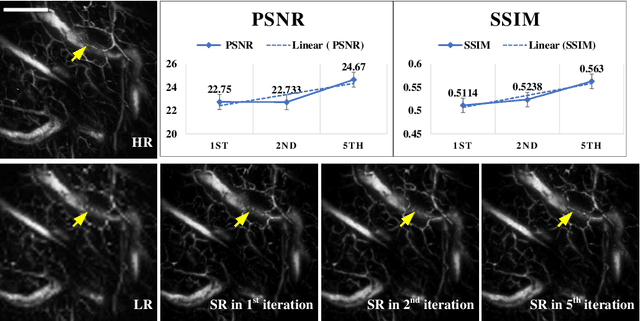
Deep learning-based super-resolution models have the potential to revolutionize biomedical imaging and diagnoses by effectively tackling various challenges associated with early detection, personalized medicine, and clinical automation. However, the requirement of an extensive collection of high-resolution images presents limitations for widespread adoption in clinical practice. In our experiment, we proposed an approach to effectively train the deep learning-based super-resolution models using only one real image by leveraging self-generated high-resolution images. We employed a mixed metric of image screening to automatically select images with a distribution similar to ground truth, creating an incrementally curated training data set that encourages the model to generate improved images over time. After five training iterations, the proposed deep learning-based super-resolution model experienced a 7.5\% and 5.49\% improvement in structural similarity and peak-signal-to-noise ratio, respectively. Significantly, the model consistently produces visually enhanced results for training, improving its performance while preserving the characteristics of original biomedical images. These findings indicate a potential way to train a deep neural network in a self-revolution manner independent of real-world human data.
Last-Iterate Convergent Policy Gradient Primal-Dual Methods for Constrained MDPs
Jun 20, 2023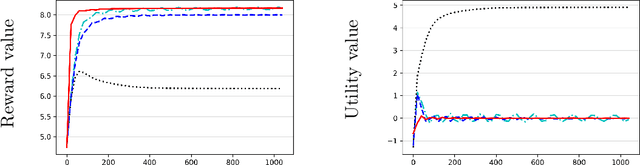
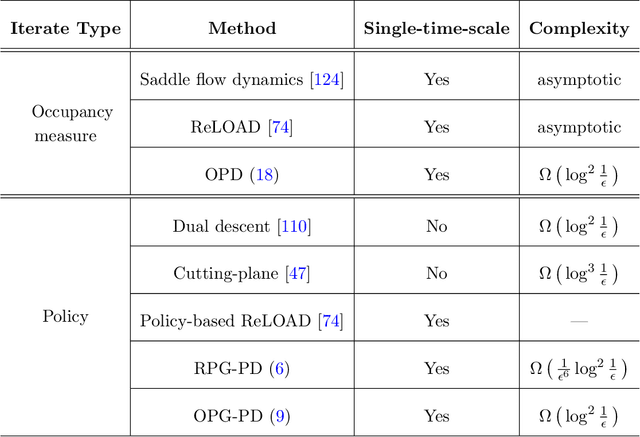
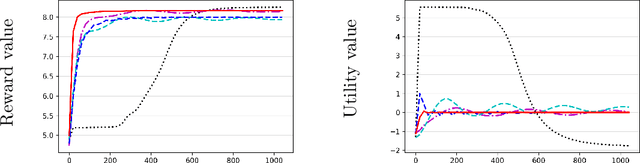
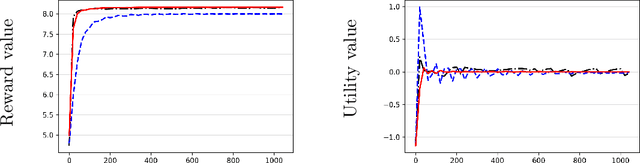
We study the problem of computing an optimal policy of an infinite-horizon discounted constrained Markov decision process (constrained MDP). Despite the popularity of Lagrangian-based policy search methods used in practice, the oscillation of policy iterates in these methods has not been fully understood, bringing out issues such as violation of constraints and sensitivity to hyper-parameters. To fill this gap, we employ the Lagrangian method to cast a constrained MDP into a constrained saddle-point problem in which max/min players correspond to primal/dual variables, respectively, and develop two single-time-scale policy-based primal-dual algorithms with non-asymptotic convergence of their policy iterates to an optimal constrained policy. Specifically, we first propose a regularized policy gradient primal-dual (RPG-PD) method that updates the policy using an entropy-regularized policy gradient, and the dual via a quadratic-regularized gradient ascent, simultaneously. We prove that the policy primal-dual iterates of RPG-PD converge to a regularized saddle point with a sublinear rate, while the policy iterates converge sublinearly to an optimal constrained policy. We further instantiate RPG-PD in large state or action spaces by including function approximation in policy parametrization, and establish similar sublinear last-iterate policy convergence. Second, we propose an optimistic policy gradient primal-dual (OPG-PD) method that employs the optimistic gradient method to update primal/dual variables, simultaneously. We prove that the policy primal-dual iterates of OPG-PD converge to a saddle point that contains an optimal constrained policy, with a linear rate. To the best of our knowledge, this work appears to be the first non-asymptotic policy last-iterate convergence result for single-time-scale algorithms in constrained MDPs.
FuXi: A cascade machine learning forecasting system for 15-day global weather forecast
Jun 27, 2023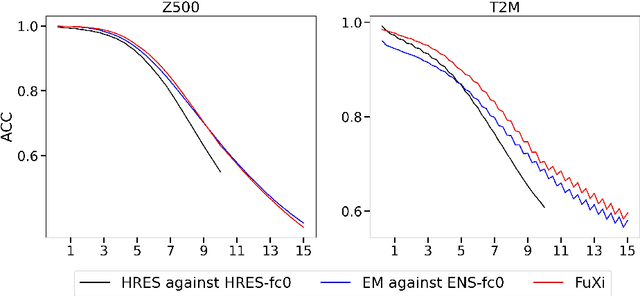
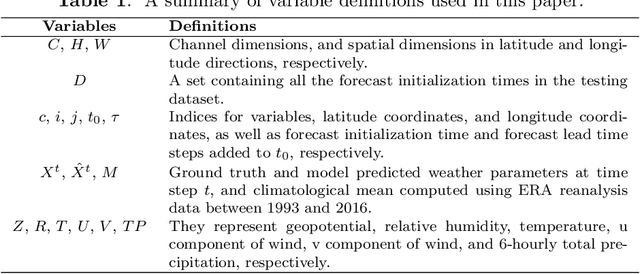
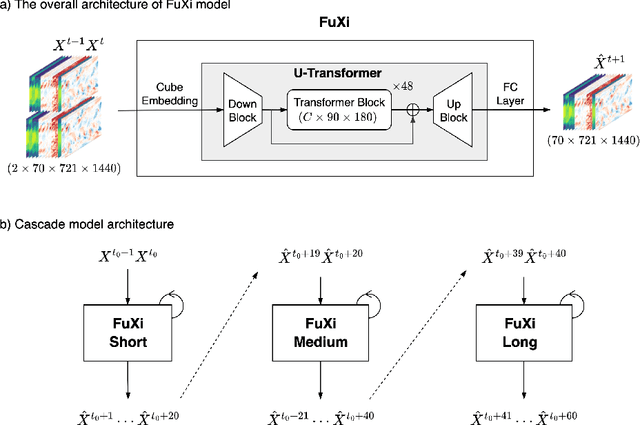
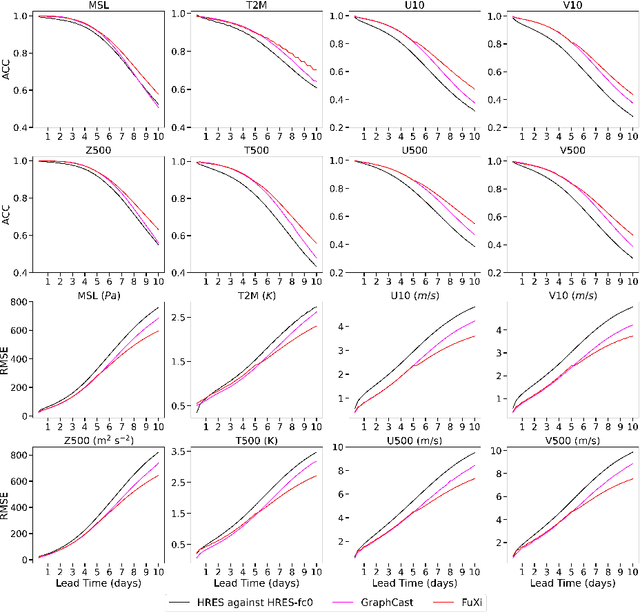
Over the past few years, due to the rapid development of machine learning (ML) models for weather forecasting, state-of-the-art ML models have shown superior performance compared to the European Centre for Medium-Range Weather Forecasts (ECMWF)'s high-resolution forecast (HRES) in 10-day forecasts at a spatial resolution of 0.25 degree. However, the challenge remains to perform comparably to the ECMWF ensemble mean (EM) in 15-day forecasts. Previous studies have demonstrated the importance of mitigating the accumulation of forecast errors for effective long-term forecasts. Despite numerous efforts to reduce accumulation errors, including autoregressive multi-time step loss, using a single model is found to be insufficient to achieve optimal performance in both short and long lead times. Therefore, we present FuXi, a cascaded ML weather forecasting system that provides 15-day global forecasts with a temporal resolution of 6 hours and a spatial resolution of 0.25 degree. FuXi is developed using 39 years of the ECMWF ERA5 reanalysis dataset. The performance evaluation, based on latitude-weighted root mean square error (RMSE) and anomaly correlation coefficient (ACC), demonstrates that FuXi has comparable forecast performance to ECMWF EM in 15-day forecasts, making FuXi the first ML-based weather forecasting system to accomplish this achievement.
FLuRKA: Fast fused Low-Rank & Kernel Attention
Jun 27, 2023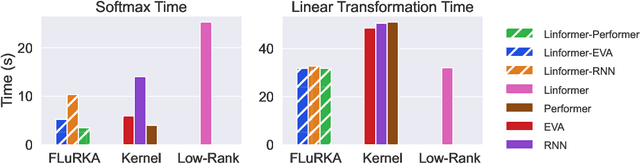
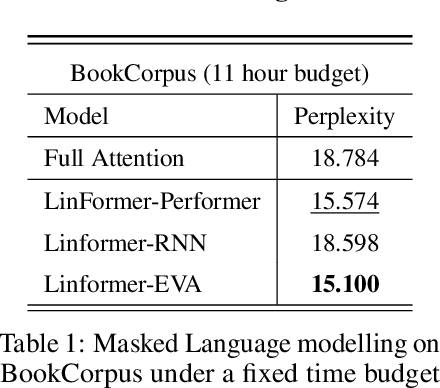
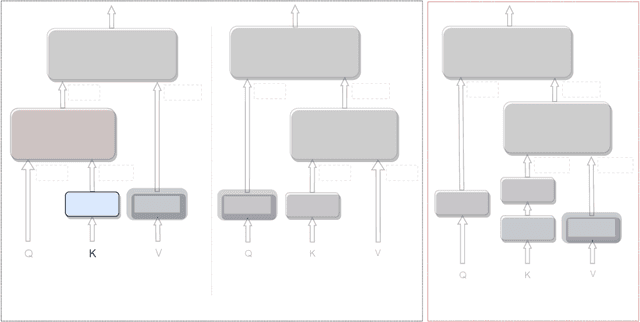
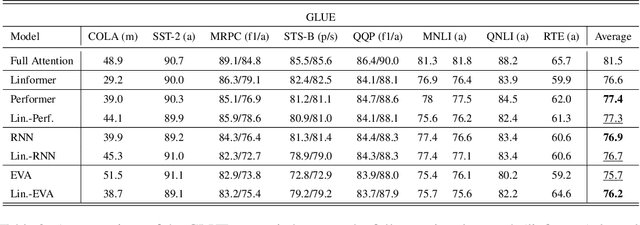
Many efficient approximate self-attention techniques have become prevalent since the inception of the transformer architecture. Two popular classes of these techniques are low-rank and kernel methods. Each of these methods has its own strengths. We observe these strengths synergistically complement each other and exploit these synergies to fuse low-rank and kernel methods, producing a new class of transformers: FLuRKA (Fast Low-Rank and Kernel Attention). FLuRKA provide sizable performance gains over these approximate techniques and are of high quality. We theoretically and empirically evaluate both the runtime performance and quality of FLuRKA. Our runtime analysis posits a variety of parameter configurations where FLuRKA exhibit speedups and our accuracy analysis bounds the error of FLuRKA with respect to full-attention. We instantiate three FLuRKA variants which experience empirical speedups of up to 3.3x and 1.7x over low-rank and kernel methods respectively. This translates to speedups of up to 30x over models with full-attention. With respect to model quality, FLuRKA can match the accuracy of low-rank and kernel methods on GLUE after pre-training on wiki-text 103. When pre-training on a fixed time budget, FLuRKA yield better perplexity scores than models with full-attention.
Methodology for Jointly Assessing Myocardial Infarct Extent and Regional Contraction in 3-D CMRI
Jun 27, 2023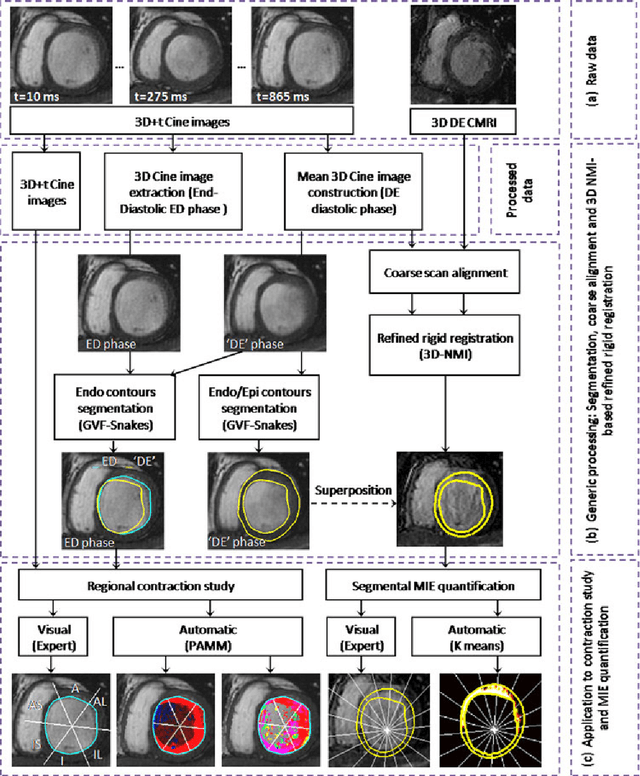
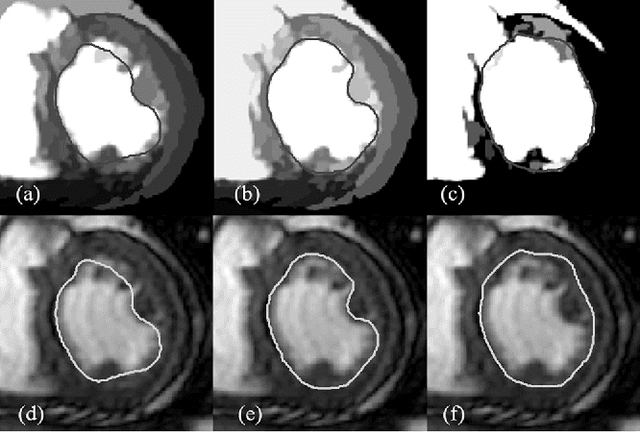
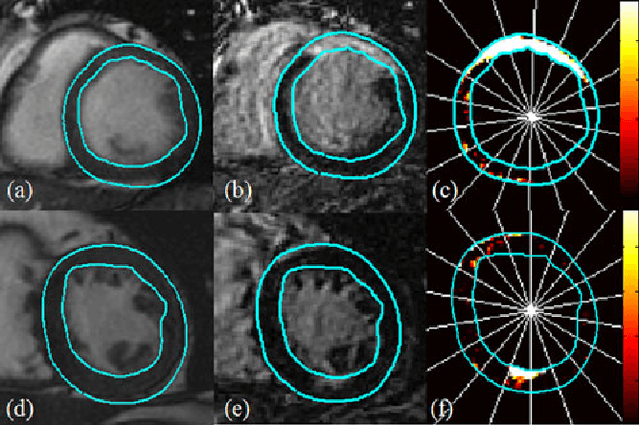
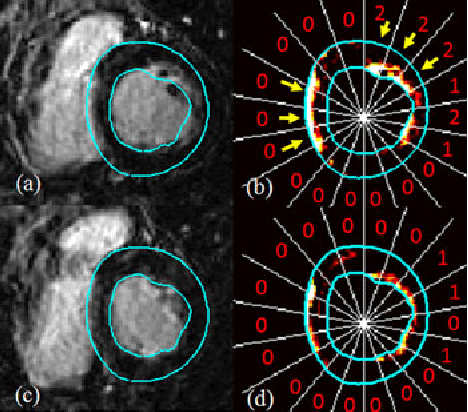
Automated extraction of quantitative parameters from Cardiac Magnetic Resonance Images (CMRI) is crucial for the management of patients with myocardial infarct. This work proposes a post-processing procedure to jointly analyze Cine and Delayed-Enhanced (DE) acquisitions in order to provide an automatic quantification of myocardial contraction and enhancement parameters and a study of their relationship. For that purpose, the following processes are performed: 1) DE/Cine temporal synchronization and 3D scan alignment, 2) 3D DE/Cine rigid registration in a region about the heart, 3) segmentation of the myocardium on Cine MRI and superimposition of the epicardial and endocardial contours on the DE images, 4) quantification of the Myocardial Infarct Extent (MIE), 5) study of the regional contractile function using a new index, the Amplitude to Time Ratio (ATR). The whole procedure was applied to 10 patients with clinically proven myocardial infarction. The comparison between the MIE and the visually assessed regional function scores demonstrated that the MIE is highly related to the severity of the wall motion abnormality. In addition, it was shown that the newly developed regional myocardial contraction parameter (ATR) decreases significantly in delayed enhanced regions. This largely automated approach enables a combined study of regional MIE and left ventricular function.