 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Suicide Prevention from Bipolar Disorder with Temporal Symptom-Aware Multitask Learning
Jul 03, 2023
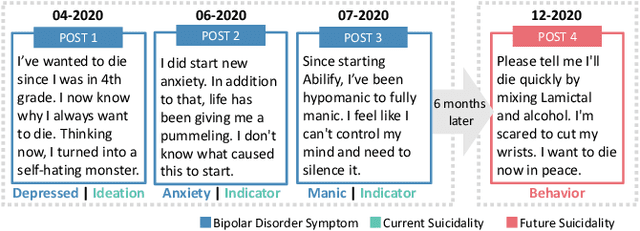
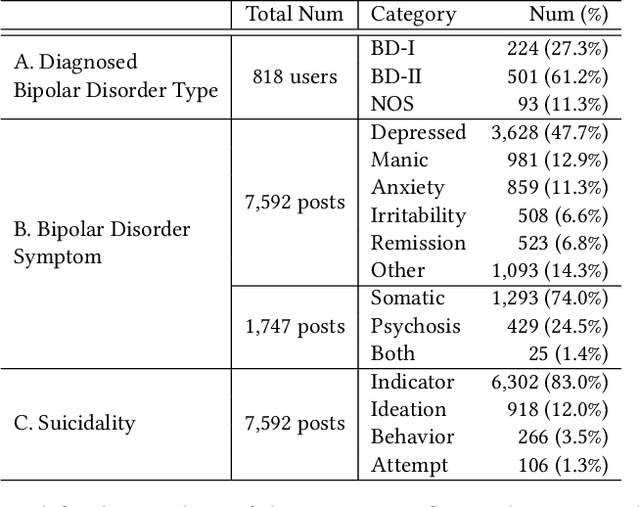
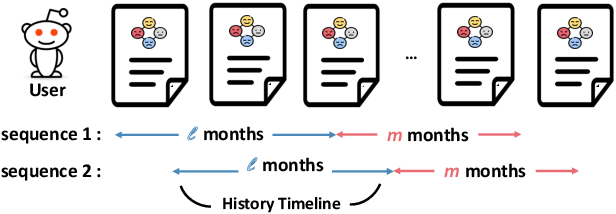
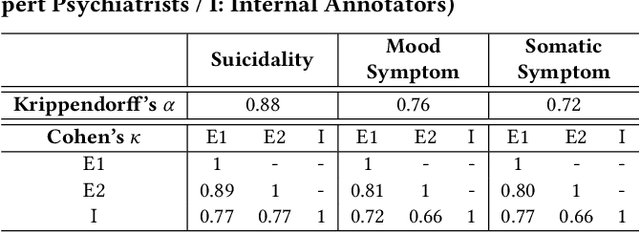
Bipolar disorder (BD) is closely associated with an increased risk of suicide. However, while the prior work has revealed valuable insight into understanding the behavior of BD patients on social media, little attention has been paid to developing a model that can predict the future suicidality of a BD patient. Therefore, this study proposes a multi-task learning model for predicting the future suicidality of BD patients by jointly learning current symptoms. We build a novel BD dataset clinically validated by psychiatrists, including 14 years of posts on bipolar-related subreddits written by 818 BD patients, along with the annotations of future suicidality and BD symptoms. We also suggest a temporal symptom-aware attention mechanism to determine which symptoms are the most influential for predicting future suicidality over time through a sequence of BD posts. Our experiments demonstrate that the proposed model outperforms the state-of-the-art models in both BD symptom identification and future suicidality prediction tasks. In addition, the proposed temporal symptom-aware attention provides interpretable attention weights, helping clinicians to apprehend BD patients more comprehensively and to provide timely intervention by tracking mental state progression.
* KDD 2023 accepted
Factors Impacting the Quality of User Answers on Smartphones
Jun 12, 2023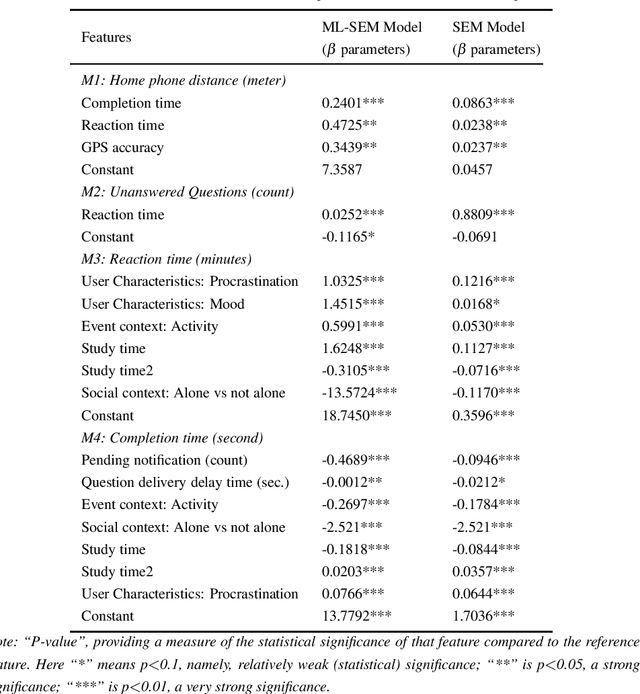
So far, most research investigating the predictability of human behavior, such as mobility and social interactions, has focused mainly on the exploitation of sensor data. However, sensor data can be difficult to capture the subjective motivations behind the individuals' behavior. Understanding personal context (e.g., where one is and what they are doing) can greatly increase predictability. The main limitation is that human input is often missing or inaccurate. The goal of this paper is to identify factors that influence the quality of responses when users are asked about their current context. We find that two key factors influence the quality of responses: user reaction time and completion time. These factors correlate with various exogenous causes (e.g., situational context, time of day) and endogenous causes (e.g., procrastination attitude, mood). In turn, we study how these two factors impact the quality of responses.
* 5 pages, 1 table
S.T.A.R.-Track: Latent Motion Models for End-to-End 3D Object Tracking with Adaptive Spatio-Temporal Appearance Representations
Jun 30, 2023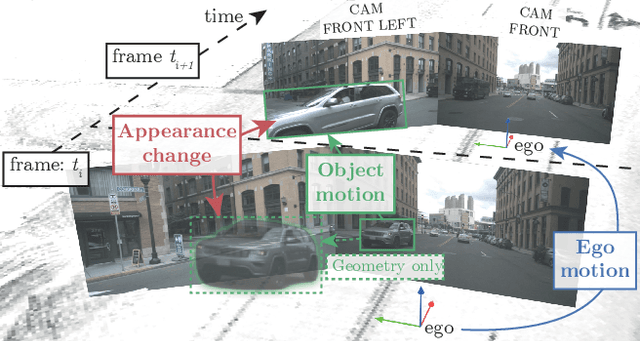
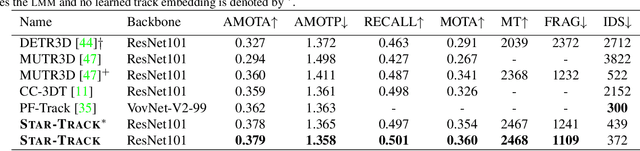
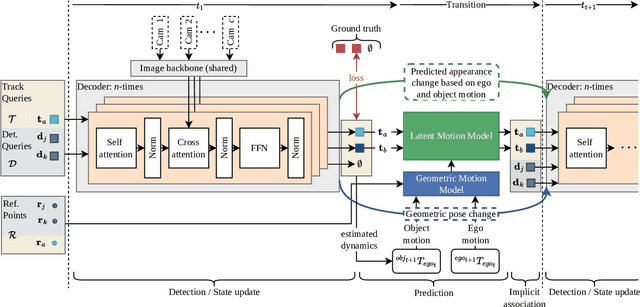
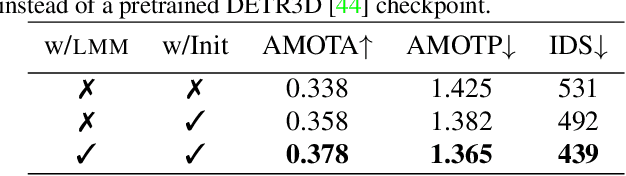
Following the tracking-by-attention paradigm, this paper introduces an object-centric, transformer-based framework for tracking in 3D. Traditional model-based tracking approaches incorporate the geometric effect of object- and ego motion between frames with a geometric motion model. Inspired by this, we propose S.T.A.R.-Track, which uses a novel latent motion model (LMM) to additionally adjust object queries to account for changes in viewing direction and lighting conditions directly in the latent space, while still modeling the geometric motion explicitly. Combined with a novel learnable track embedding that aids in modeling the existence probability of tracks, this results in a generic tracking framework that can be integrated with any query-based detector. Extensive experiments on the nuScenes benchmark demonstrate the benefits of our approach, showing state-of-the-art performance for DETR3D-based trackers while drastically reducing the number of identity switches of tracks at the same time.
Theoretical Analysis of Heterodyne Rydberg Atomic Receiver Sensitivity Based on Transit Relaxation Effect and Frequency Detuning
Jun 30, 2023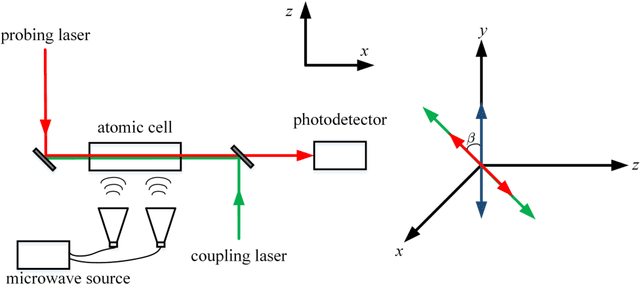
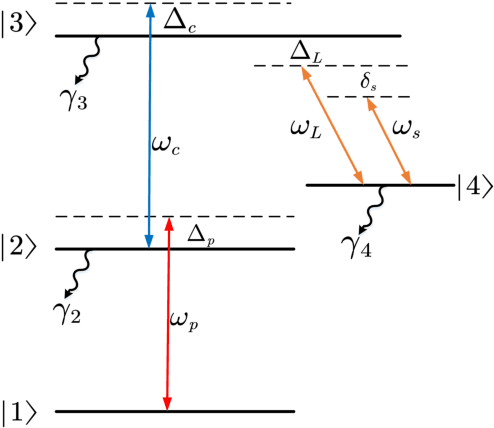
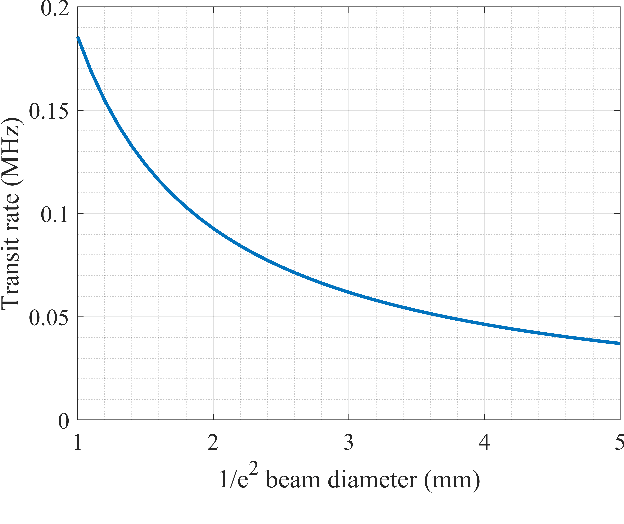
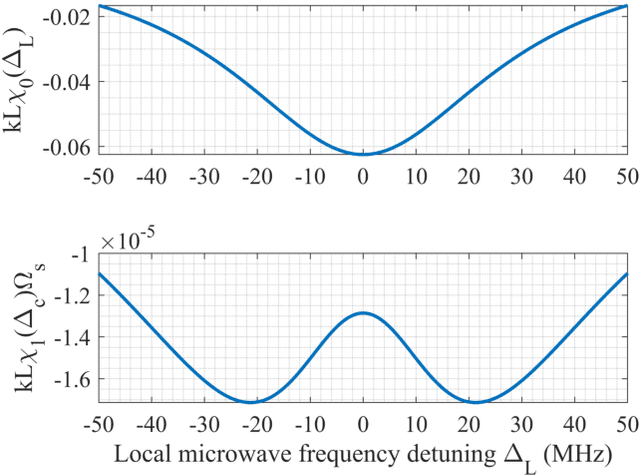
We conduct a theoretical investigation into the impacts of local microwave electric field frequency detuning, laser frequency detuning, and transit relaxation rate on enhancing heterodyne Rydberg atomic receiver sensitivity. To optimize the output signal amplitude given the input microwave signal, we derive the steady-state solutions of the atomic density matrix. Numerical results show that laser frequency detuning and local microwave electric field frequency detuning can improve the system detection sensitivity, which can help the system achieve extra sensitivity gain. It also shows that the heterodyne Rydberg atomic receiver can detect weak microwave signals continuously over a wide frequency range with the same sensitivity or even more sensitivity than the resonance case. To evaluate the transit relaxation effect, a modified Liouville equation is used. We find that the transition relaxation rate increases the time it takes to reach steady state and decreases the sensitivity of the system detection.
Knowledge Graph for NLG in the context of conversational agents
Jul 04, 2023
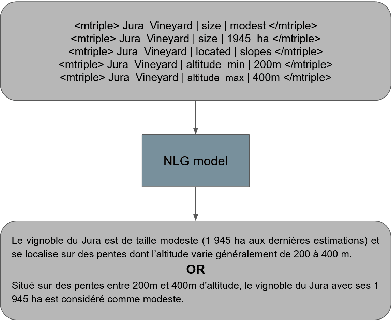
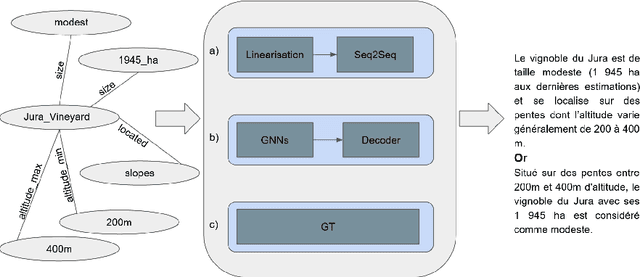
The use of knowledge graphs (KGs) enhances the accuracy and comprehensiveness of the responses provided by a conversational agent. While generating answers during conversations consists in generating text from these KGs, it is still regarded as a challenging task that has gained significant attention in recent years. In this document, we provide a review of different architectures used for knowledge graph-to-text generation including: Graph Neural Networks, the Graph Transformer, and linearization with seq2seq models. We discuss the advantages and limitations of each architecture and conclude that the choice of architecture will depend on the specific requirements of the task at hand. We also highlight the importance of considering constraints such as execution time and model validity, particularly in the context of conversational agents. Based on these constraints and the availability of labeled data for the domains of DAVI, we choose to use seq2seq Transformer-based models (PLMs) for the Knowledge Graph-to-Text Generation task. We aim to refine benchmark datasets of kg-to-text generation on PLMs and to explore the emotional and multilingual dimensions in our future work. Overall, this review provides insights into the different approaches for knowledge graph-to-text generation and outlines future directions for research in this area.
Capturing Local Temperature Evolution during Additive Manufacturing through Fourier Neural Operators
Jul 04, 2023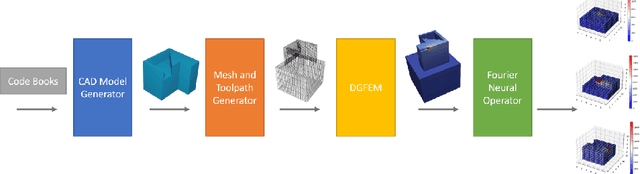
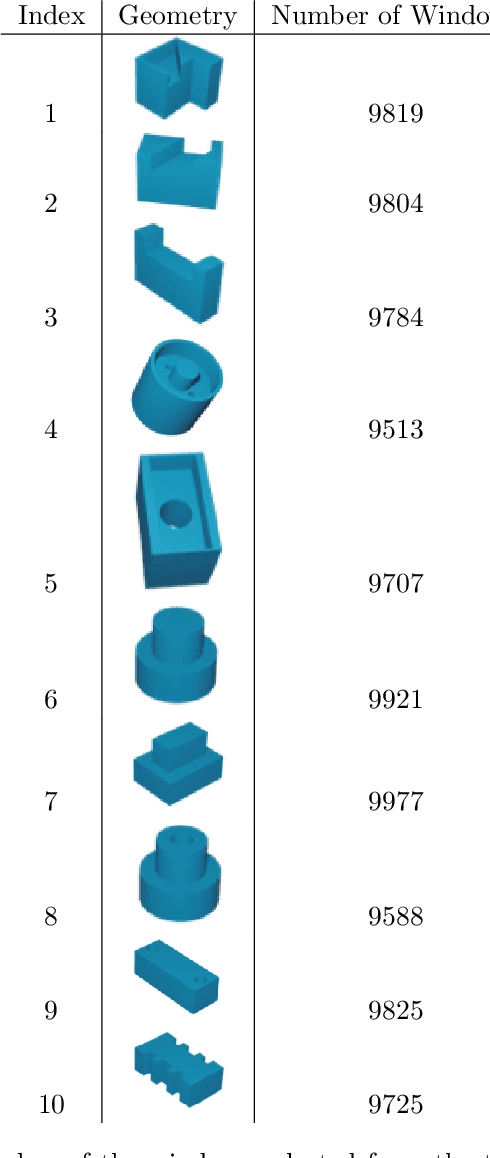

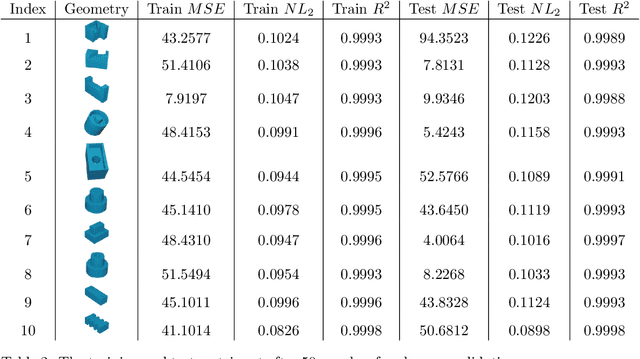
High-fidelity, data-driven models that can quickly simulate thermal behavior during additive manufacturing (AM) are crucial for improving the performance of AM technologies in multiple areas, such as part design, process planning, monitoring, and control. However, the complexities of part geometries make it challenging for current models to maintain high accuracy across a wide range of geometries. Additionally, many models report a low mean square error (MSE) across the entire domain (part). However, in each time step, most areas of the domain do not experience significant changes in temperature, except for the heat-affected zones near recent depositions. Therefore, the MSE-based fidelity measurement of the models may be overestimated. This paper presents a data-driven model that uses Fourier Neural Operator to capture the local temperature evolution during the additive manufacturing process. In addition, the authors propose to evaluate the model using the $R^2$ metric, which provides a relative measure of the model's performance compared to using mean temperature as a prediction. The model was tested on numerical simulations based on the Discontinuous Galerkin Finite Element Method for the Direct Energy Deposition process, and the results demonstrate that the model achieves high fidelity as measured by $R^2$ and maintains generalizability to geometries that were not included in the training process.
Denoising of discrete-time chaotic signals using echo state networks
Apr 03, 2023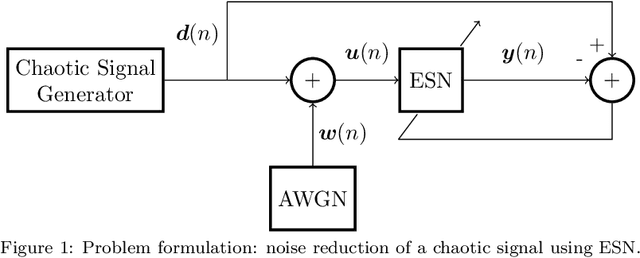
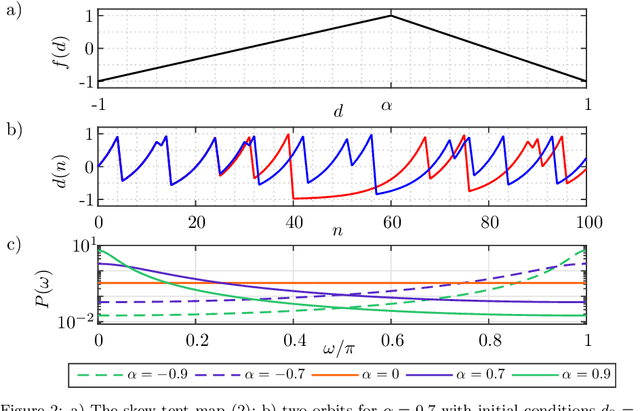
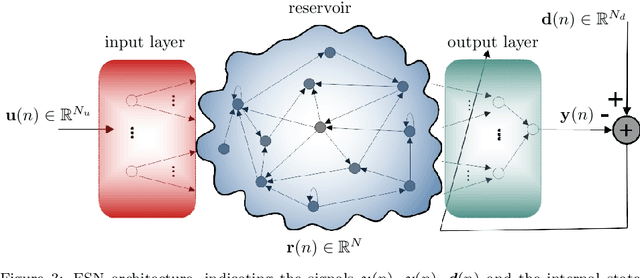
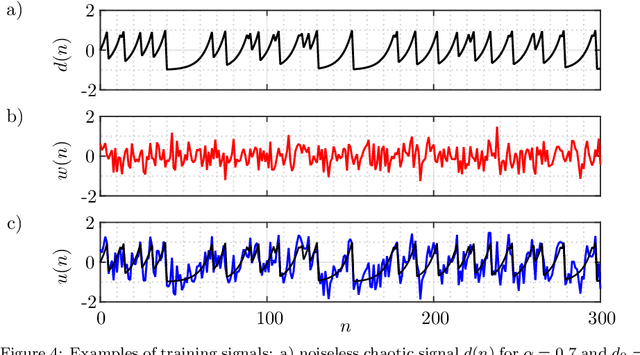
Noise reduction is a relevant topic when considering the application of chaotic signals in practical problems, such as communication systems or modeling biomedical signals. In this paper an echo state network (ESN) is employed to denoise a discrete-time chaotic signal corrupted by additive white Gaussian noise. The choice for applying ESNs in this context is motivated by their successful exploitation for separation and prediction of chaotic signals. The results show that the processing gain of ESN is higher than that of the Wiener filter, especially when the power spectral density of the chaotic signals is white.
Trajectory Generation, Control, and Safety with Denoising Diffusion Probabilistic Models
Jun 27, 2023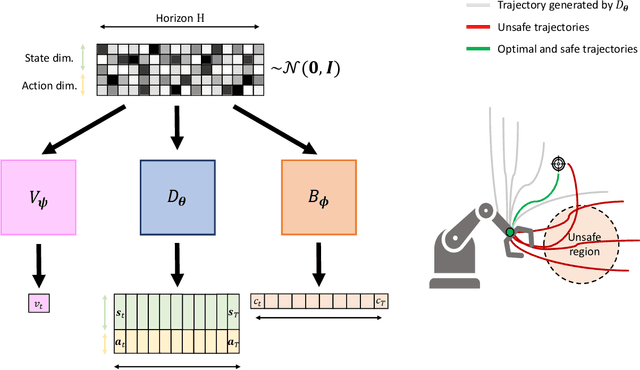
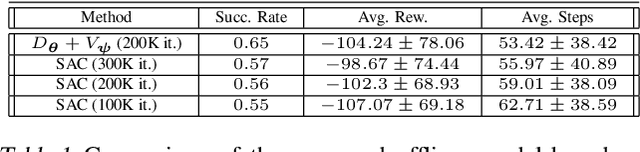
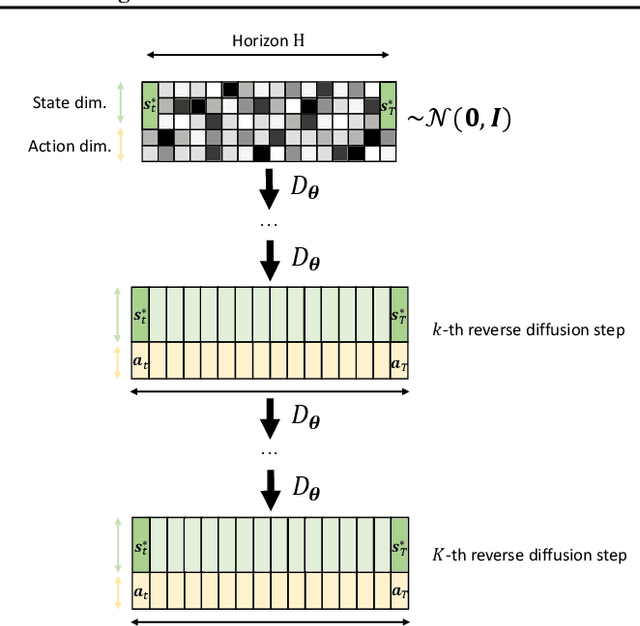
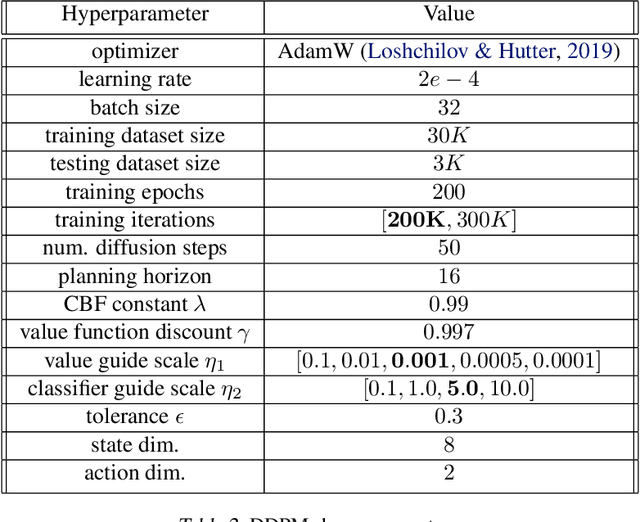
We present a framework for safety-critical optimal control of physical systems based on denoising diffusion probabilistic models (DDPMs). The technology of control barrier functions (CBFs), encoding desired safety constraints, is used in combination with DDPMs to plan actions by iteratively denoising trajectories through a CBF-based guided sampling procedure. At the same time, the generated trajectories are also guided to maximize a future cumulative reward representing a specific task to be optimally executed. The proposed scheme can be seen as an offline and model-based reinforcement learning algorithm resembling in its functionalities a model-predictive control optimization scheme with receding horizon in which the selected actions lead to optimal and safe trajectories.
Towards Language-Based Modulation of Assistive Robots through Multimodal Models
Jun 27, 2023
In the field of Geriatronics, enabling effective and transparent communication between humans and robots is crucial for enhancing the acceptance and performance of assistive robots. Our early-stage research project investigates the potential of language-based modulation as a means to improve human-robot interaction. We propose to explore real-time modulation during task execution, leveraging language cues, visual references, and multimodal inputs. By developing transparent and interpretable methods, we aim to enable robots to adapt and respond to language commands, enhancing their usability and flexibility. Through the exchange of insights and knowledge at the workshop, we seek to gather valuable feedback to advance our research and contribute to the development of interactive robotic systems for Geriatronics and beyond.
Homological Neural Networks: A Sparse Architecture for Multivariate Complexity
Jun 27, 2023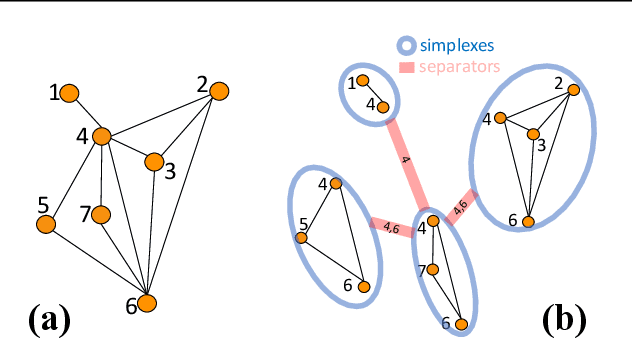
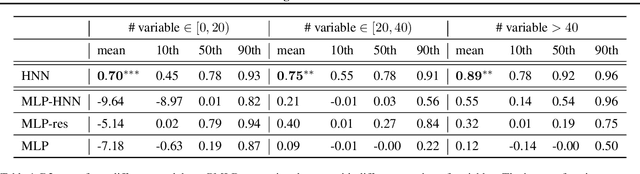
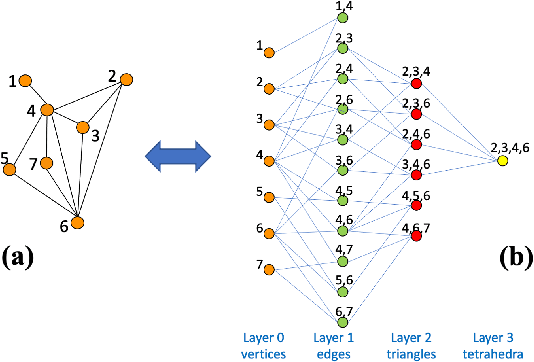
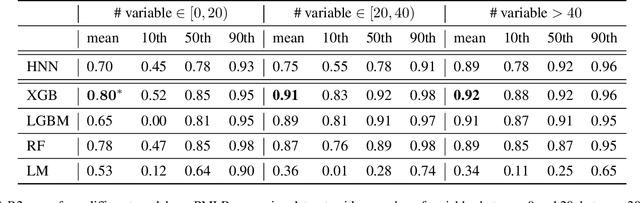
The rapid progress of Artificial Intelligence research came with the development of increasingly complex deep learning models, leading to growing challenges in terms of computational complexity, energy efficiency and interpretability. In this study, we apply advanced network-based information filtering techniques to design a novel deep neural network unit characterized by a sparse higher-order graphical architecture built over the homological structure of underlying data. We demonstrate its effectiveness in two application domains which are traditionally challenging for deep learning: tabular data and time series regression problems. Results demonstrate the advantages of this novel design which can tie or overcome the results of state-of-the-art machine learning and deep learning models using only a fraction of parameters.