 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time speech enhancement with dynamic attention span
Feb 21, 2023
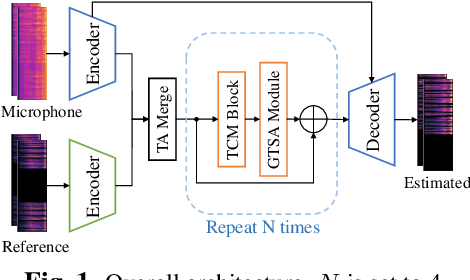
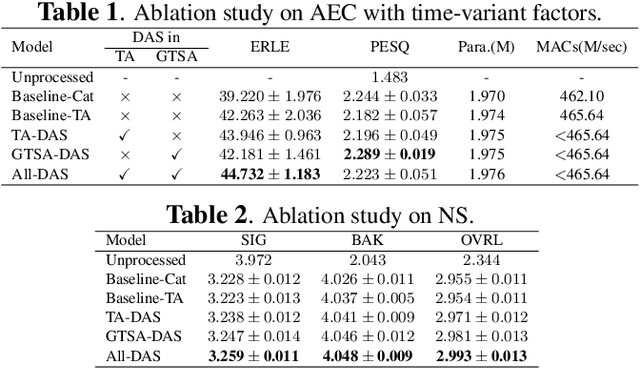
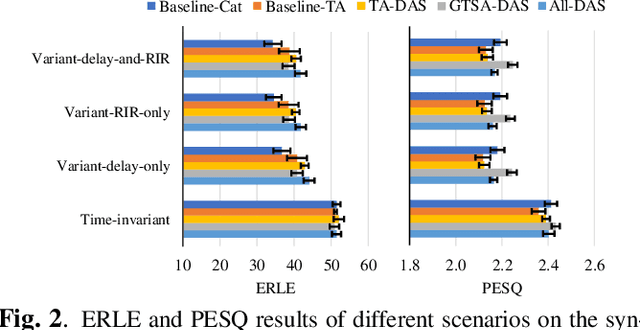
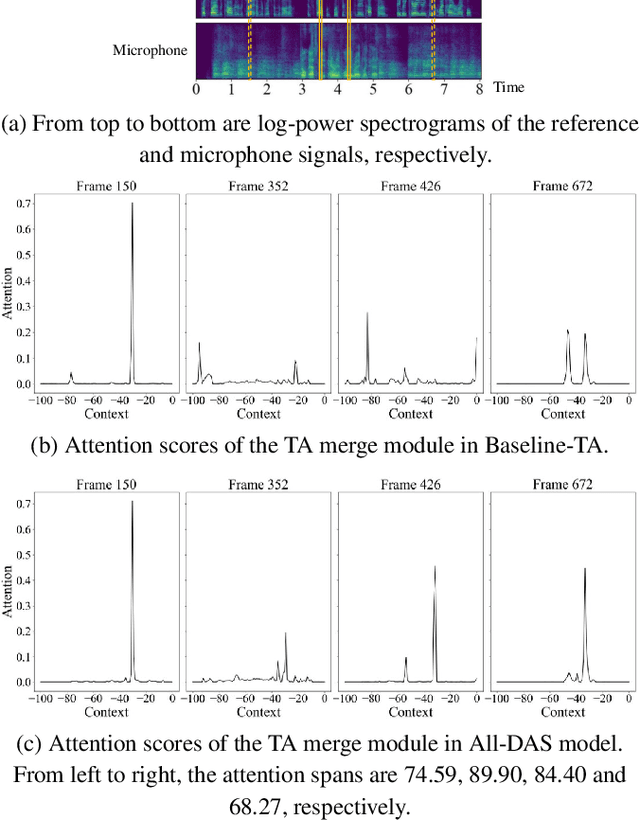
For real-time speech enhancement (SE) including noise suppression, dereverberation and acoustic echo cancellation, the time-variance of the audio signals becomes a severe challenge. The causality and memory usage limit that only the historical information can be used for the system to capture the time-variant characteristics. We propose to adaptively change the receptive field according to the input signal in deep neural network based SE model. Specifically, in an encoder-decoder framework, a dynamic attention span mechanism is introduced to all the attention modules for controlling the size of historical content used for processing the current frame. Experimental results verify that this dynamic mechanism can better track time-variant factors and capture speech-related characteristics, benefiting to both interference removing and speech quality retaining.
Low-Resource White-Box Semantic Segmentation of Supporting Towers on 3D Point Clouds via Signature Shape Identification
Jun 13, 2023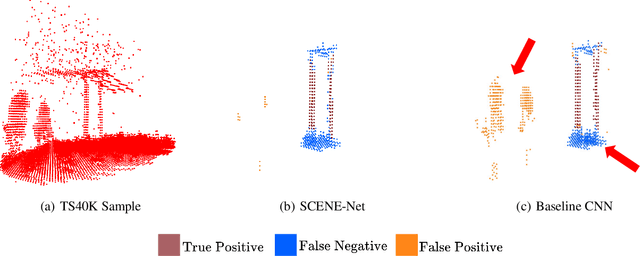

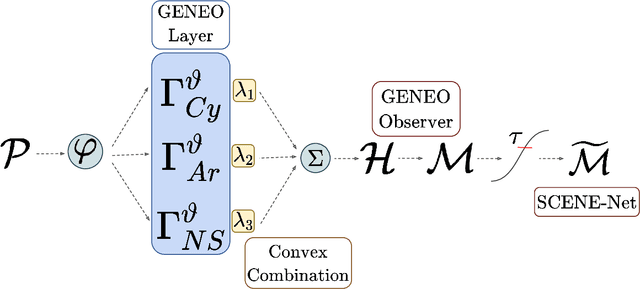
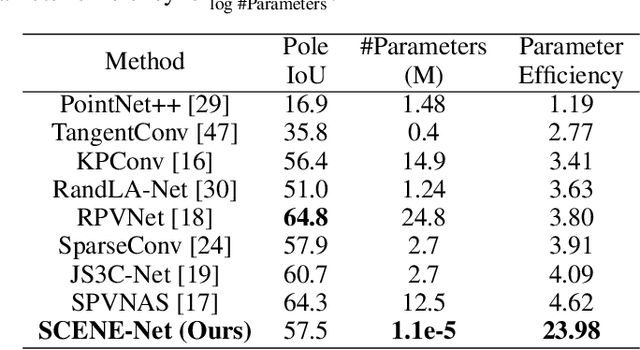
Research in 3D semantic segmentation has been increasing performance metrics, like the IoU, by scaling model complexity and computational resources, leaving behind researchers and practitioners that (1) cannot access the necessary resources and (2) do need transparency on the model decision mechanisms. In this paper, we propose SCENE-Net, a low-resource white-box model for 3D point cloud semantic segmentation. SCENE-Net identifies signature shapes on the point cloud via group equivariant non-expansive operators (GENEOs), providing intrinsic geometric interpretability. Our training time on a laptop is 85~min, and our inference time is 20~ms. SCENE-Net has 11 trainable geometrical parameters and requires fewer data than black-box models. SCENE--Net offers robustness to noisy labeling and data imbalance and has comparable IoU to state-of-the-art methods. With this paper, we release a 40~000 Km labeled dataset of rural terrain point clouds and our code implementation.
Neuro-Modulated Hebbian Learning for Fully Test-Time Adaptation
Mar 10, 2023
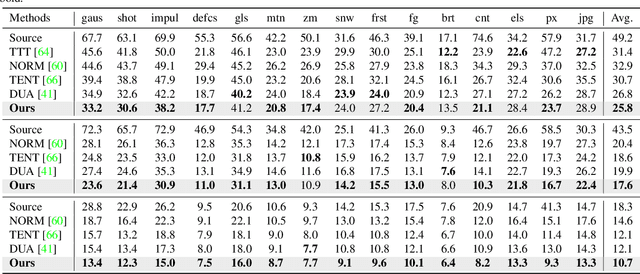
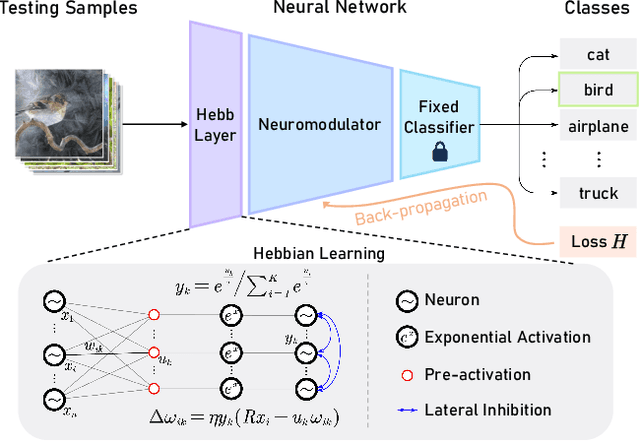
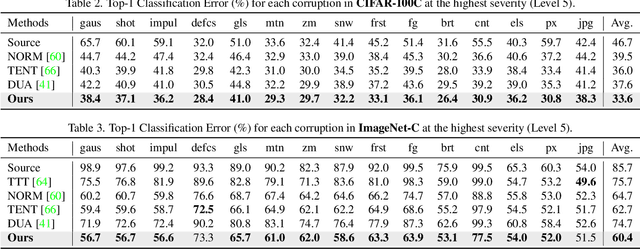
Fully test-time adaptation aims to adapt the network model based on sequential analysis of input samples during the inference stage to address the cross-domain performance degradation problem of deep neural networks. We take inspiration from the biological plausibility learning where the neuron responses are tuned based on a local synapse-change procedure and activated by competitive lateral inhibition rules. Based on these feed-forward learning rules, we design a soft Hebbian learning process which provides an unsupervised and effective mechanism for online adaptation. We observe that the performance of this feed-forward Hebbian learning for fully test-time adaptation can be significantly improved by incorporating a feedback neuro-modulation layer. It is able to fine-tune the neuron responses based on the external feedback generated by the error back-propagation from the top inference layers. This leads to our proposed neuro-modulated Hebbian learning (NHL) method for fully test-time adaptation. With the unsupervised feed-forward soft Hebbian learning being combined with a learned neuro-modulator to capture feedback from external responses, the source model can be effectively adapted during the testing process. Experimental results on benchmark datasets demonstrate that our proposed method can significantly improve the adaptation performance of network models and outperforms existing state-of-the-art methods.
Worst-Case Control and Learning Using Partial Observations Over an Infinite Time-Horizon
Mar 31, 2023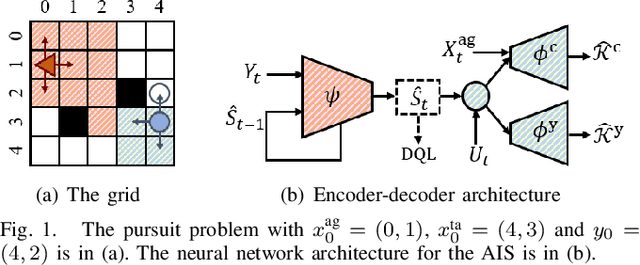
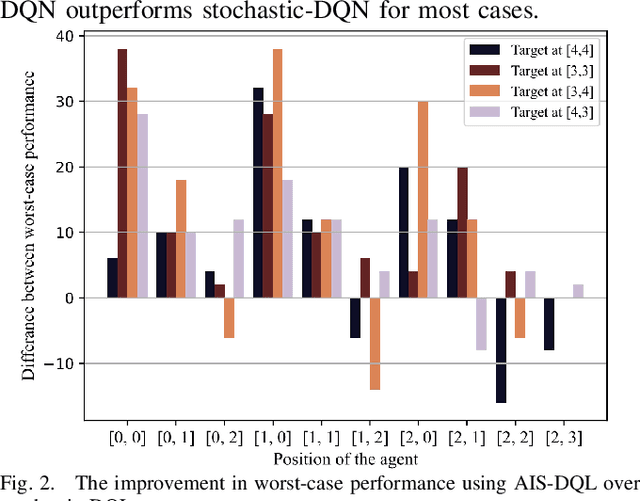
Safety-critical cyber-physical systems require control strategies whose worst-case performance is robust against adversarial disturbances and modeling uncertainties. In this paper, we present a framework for approximate control and learning in partially observed systems to minimize the worst-case discounted cost over an infinite time horizon. We model disturbances to the system as finite-valued uncertain variables with unknown probability distributions. For problems with known system dynamics, we construct a dynamic programming (DP) decomposition to compute the optimal control strategy. Our first contribution is to define information states that improve the computational tractability of this DP without loss of optimality. Then, we describe a simplification for a class of problems where the incurred cost is observable at each time instance. Our second contribution is defining an approximate information state that can be constructed or learned directly from observed data for problems with observable costs. We derive bounds on the performance loss of the resulting approximate control strategy and illustrate the effectiveness of our approach in partially observed decision-making problems with a numerical example.
Classifier Robustness Enhancement Via Test-Time Transformation
Mar 27, 2023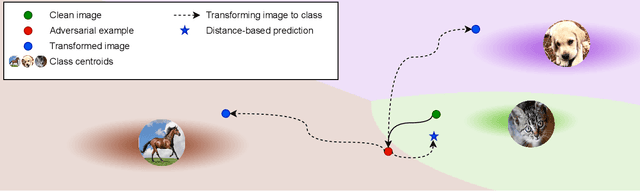
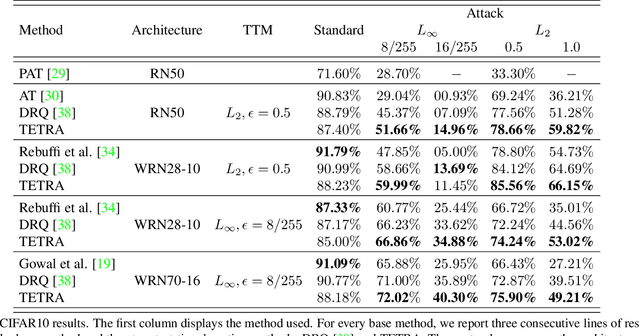

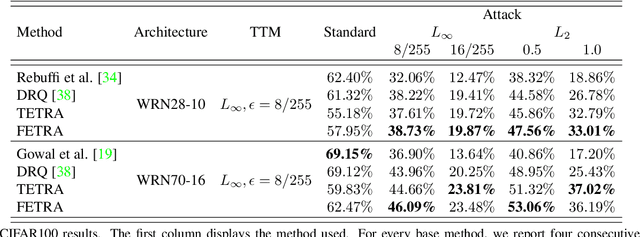
It has been recently discovered that adversarially trained classifiers exhibit an intriguing property, referred to as perceptually aligned gradients (PAG). PAG implies that the gradients of such classifiers possess a meaningful structure, aligned with human perception. Adversarial training is currently the best-known way to achieve classification robustness under adversarial attacks. The PAG property, however, has yet to be leveraged for further improving classifier robustness. In this work, we introduce Classifier Robustness Enhancement Via Test-Time Transformation (TETRA) -- a novel defense method that utilizes PAG, enhancing the performance of trained robust classifiers. Our method operates in two phases. First, it modifies the input image via a designated targeted adversarial attack into each of the dataset's classes. Then, it classifies the input image based on the distance to each of the modified instances, with the assumption that the shortest distance relates to the true class. We show that the proposed method achieves state-of-the-art results and validate our claim through extensive experiments on a variety of defense methods, classifier architectures, and datasets. We also empirically demonstrate that TETRA can boost the accuracy of any differentiable adversarial training classifier across a variety of attacks, including ones unseen at training. Specifically, applying TETRA leads to substantial improvement of up to $+23\%$, $+20\%$, and $+26\%$ on CIFAR10, CIFAR100, and ImageNet, respectively.
Computing large deviation prefactors of stochastic dynamical systems based on machine learning
Jun 20, 2023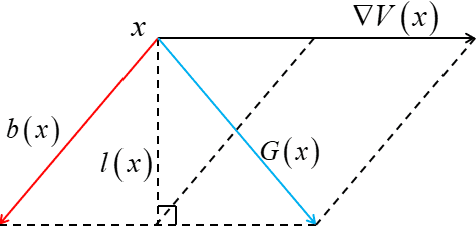

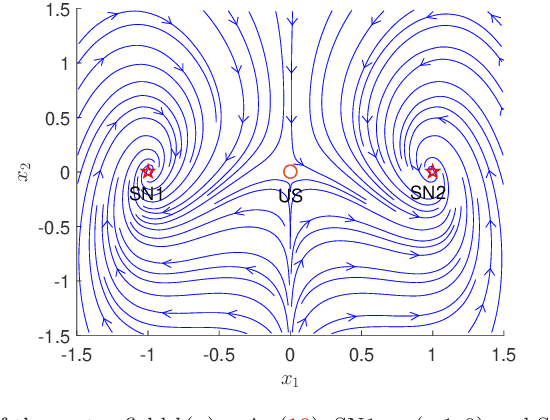
In this paper, we present large deviation theory that characterizes the exponential estimate for rare events of stochastic dynamical systems in the limit of weak noise. We aim to consider next-to-leading-order approximation for more accurate calculation of mean exit time via computing large deviation prefactors with the research efforts of machine learning. More specifically, we design a neural network framework to compute quasipotential, most probable paths and prefactors based on the orthogonal decomposition of vector field. We corroborate the higher effectiveness and accuracy of our algorithm with a practical example. Numerical experiments demonstrate its powerful function in exploring internal mechanism of rare events triggered by weak random fluctuations.
Low Latency Edge Classification GNN for Particle Trajectory Tracking on FPGAs
Jun 20, 2023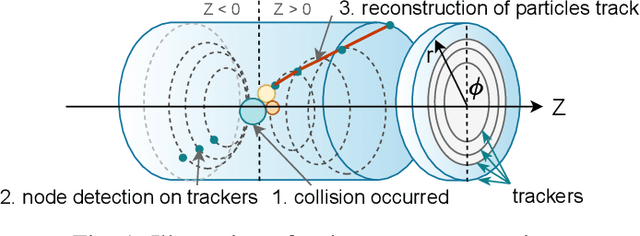
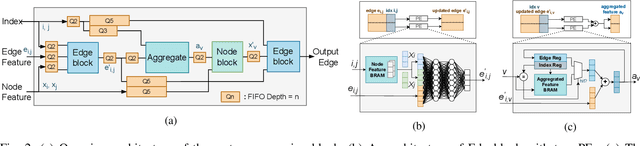
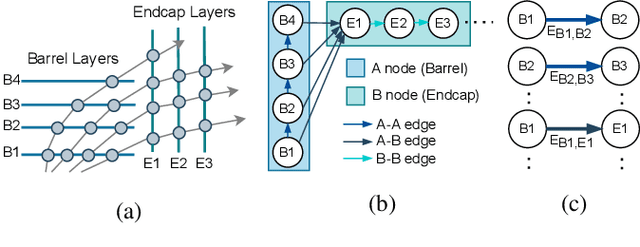
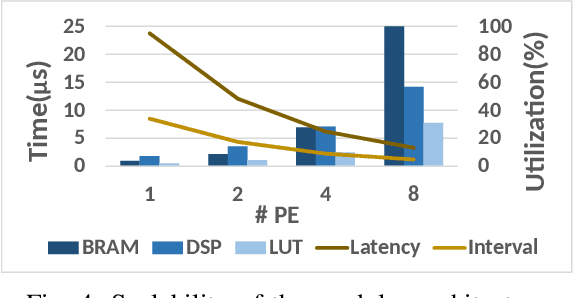
In-time particle trajectory reconstruction in the Large Hadron Collider is challenging due to the high collision rate and numerous particle hits. Using GNN (Graph Neural Network) on FPGA has enabled superior accuracy with flexible trajectory classification. However, existing GNN architectures have inefficient resource usage and insufficient parallelism for edge classification. This paper introduces a resource-efficient GNN architecture on FPGAs for low latency particle tracking. The modular architecture facilitates design scalability to support large graphs. Leveraging the geometric properties of hit detectors further reduces graph complexity and resource usage. Our results on Xilinx UltraScale+ VU9P demonstrate 1625x and 1574x performance improvement over CPU and GPU respectively.
Time-varying Signals Recovery via Graph Neural Networks
Feb 22, 2023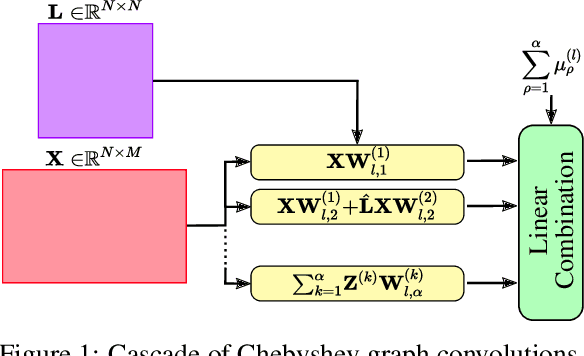

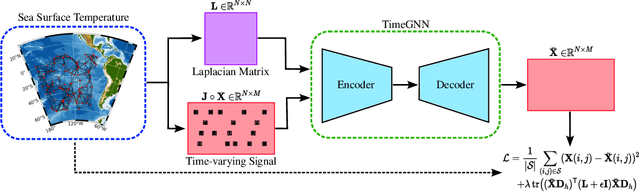
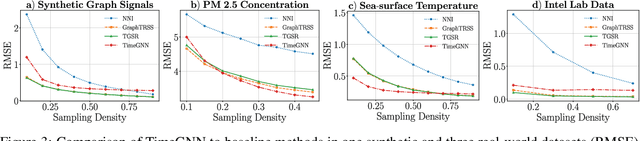
The recovery of time-varying graph signals is a fundamental problem with numerous applications in sensor networks and forecasting in time series. Effectively capturing the spatio-temporal information in these signals is essential for the downstream tasks. Previous studies have used the smoothness of the temporal differences of such graph signals as an initial assumption. Nevertheless, this smoothness assumption could result in a degradation of performance in the corresponding application when the prior does not hold. In this work, we relax the requirement of this hypothesis by including a learning module. We propose a Time Graph Neural Network (TimeGNN) for the recovery of time-varying graph signals. Our algorithm uses an encoder-decoder architecture with a specialized loss composed of a mean squared error function and a Sobolev smoothness operator.TimeGNN shows competitive performance against previous methods in real datasets.
Deep Imbalanced Time-series Forecasting via Local Discrepancy Density
Feb 27, 2023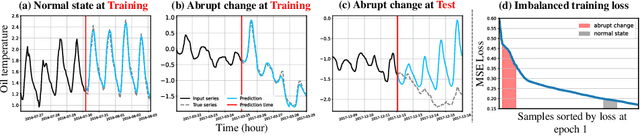
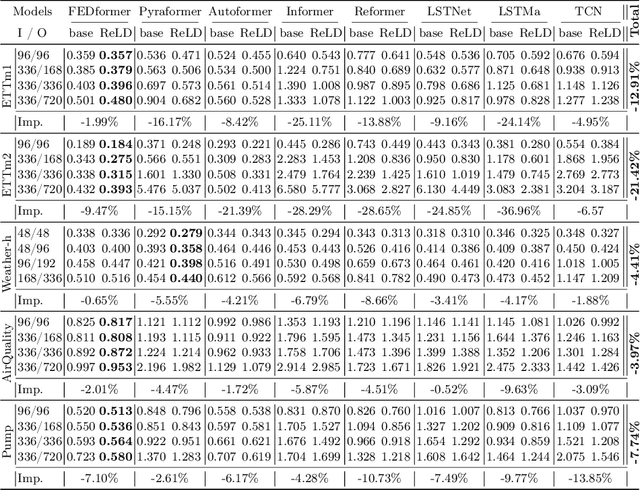
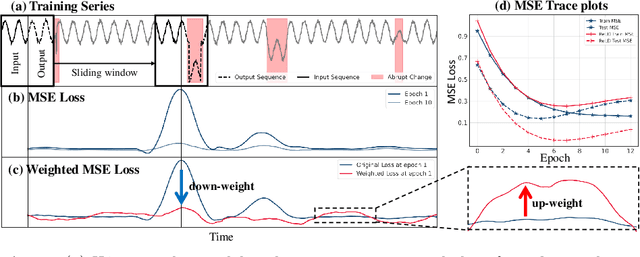
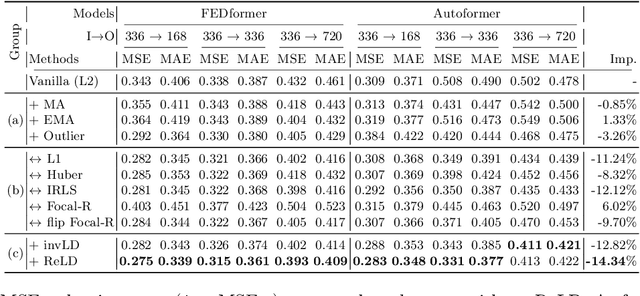
Time-series forecasting models often encounter abrupt changes in a given period of time which generally occur due to unexpected or unknown events. Despite their scarce occurrences in the training set, abrupt changes incur loss that significantly contributes to the total loss. Therefore, they act as noisy training samples and prevent the model from learning generalizable patterns, namely the normal states. Based on our findings, we propose a reweighting framework that down-weights the losses incurred by abrupt changes and up-weights those by normal states. For the reweighting framework, we first define a measurement termed Local Discrepancy (LD) which measures the degree of abruptness of a change in a given period of time. Since a training set is mostly composed of normal states, we then consider how frequently the temporal changes appear in the training set based on LD. Our reweighting framework is applicable to existing time-series forecasting models regardless of the architectures. Through extensive experiments on 12 time-series forecasting models over eight datasets with various in-output sequence lengths, we demonstrate that applying our reweighting framework reduces MSE by 10.1% on average and by up to 18.6% in the state-of-the-art model.
Explaining Explainability: Towards Deeper Actionable Insights into Deep Learning through Second-order Explainability
Jun 14, 2023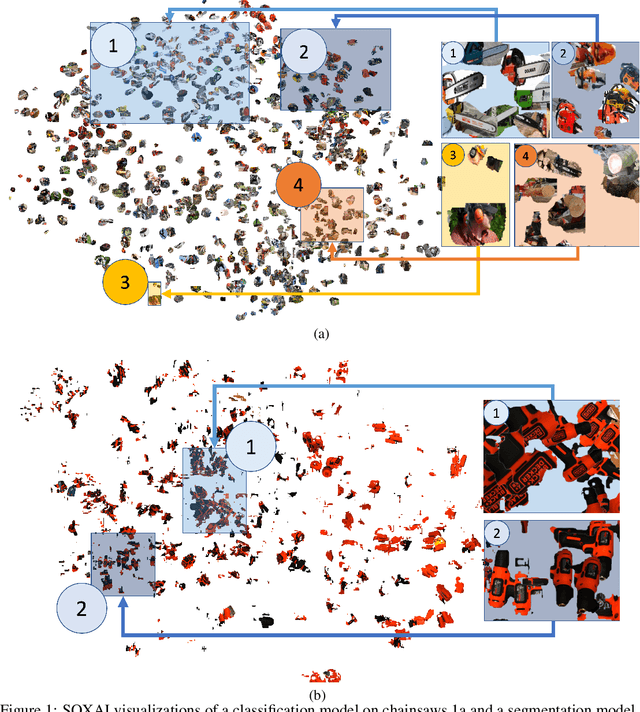

Explainability plays a crucial role in providing a more comprehensive understanding of deep learning models' behaviour. This allows for thorough validation of the model's performance, ensuring that its decisions are based on relevant visual indicators and not biased toward irrelevant patterns existing in training data. However, existing methods provide only instance-level explainability, which requires manual analysis of each sample. Such manual review is time-consuming and prone to human biases. To address this issue, the concept of second-order explainable AI (SOXAI) was recently proposed to extend explainable AI (XAI) from the instance level to the dataset level. SOXAI automates the analysis of the connections between quantitative explanations and dataset biases by identifying prevalent concepts. In this work, we explore the use of this higher-level interpretation of a deep neural network's behaviour to allows us to "explain the explainability" for actionable insights. Specifically, we demonstrate for the first time, via example classification and segmentation cases, that eliminating irrelevant concepts from the training set based on actionable insights from SOXAI can enhance a model's performance.