 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Diversity is Strength: Mastering Football Full Game with Interactive Reinforcement Learning of Multiple AIs
Jun 28, 2023
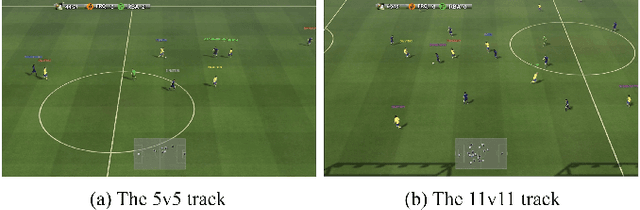

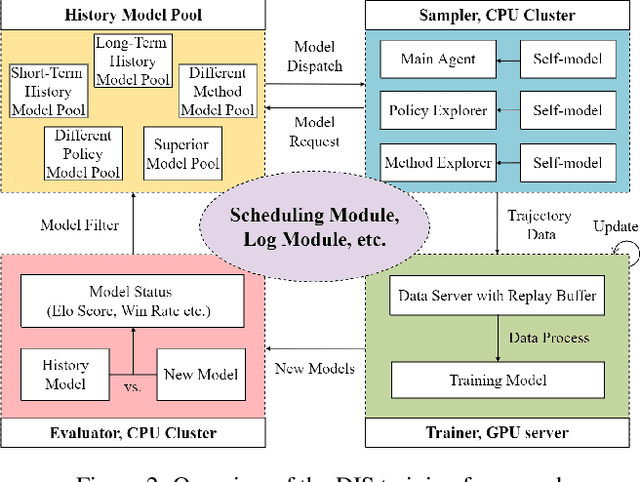
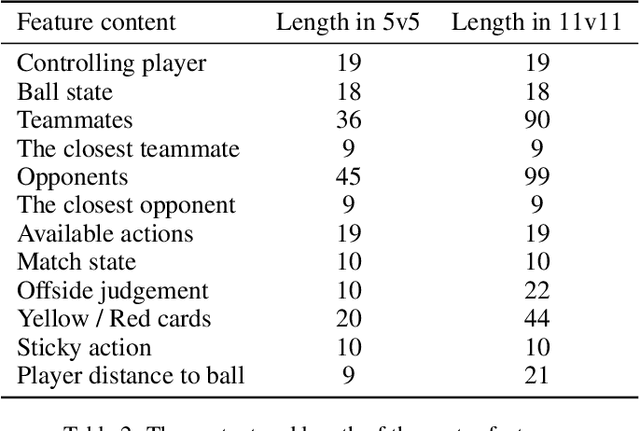
Training AI with strong and rich strategies in multi-agent environments remains an important research topic in Deep Reinforcement Learning (DRL). The AI's strength is closely related to its diversity of strategies, and this relationship can guide us to train AI with both strong and rich strategies. To prove this point, we propose Diversity is Strength (DIS), a novel DRL training framework that can simultaneously train multiple kinds of AIs. These AIs are linked through an interconnected history model pool structure, which enhances their capabilities and strategy diversities. We also design a model evaluation and screening scheme to select the best models to enrich the model pool and obtain the final AI. The proposed training method provides diverse, generalizable, and strong AI strategies without using human data. We tested our method in an AI competition based on Google Research Football (GRF) and won the 5v5 and 11v11 tracks. The method enables a GRF AI to have a high level on both 5v5 and 11v11 tracks for the first time, which are under complex multi-agent environments. The behavior analysis shows that the trained AI has rich strategies, and the ablation experiments proved that the designed modules benefit the training process.
Individualized Dosing Dynamics via Neural Eigen Decomposition
Jun 24, 2023Dosing models often use differential equations to model biological dynamics. Neural differential equations in particular can learn to predict the derivative of a process, which permits predictions at irregular points of time. However, this temporal flexibility often comes with a high sensitivity to noise, whereas medical problems often present high noise and limited data. Moreover, medical dosing models must generalize reliably over individual patients and changing treatment policies. To address these challenges, we introduce the Neural Eigen Stochastic Differential Equation algorithm (NESDE). NESDE provides individualized modeling (using a hypernetwork over patient-level parameters); generalization to new treatment policies (using decoupled control); tunable expressiveness according to the noise level (using piecewise linearity); and fast, continuous, closed-form prediction (using spectral representation). We demonstrate the robustness of NESDE in both synthetic and real medical problems, and use the learned dynamics to publish simulated medical gym environments.
Active Data Acquisition in Autonomous Driving Simulation
Jun 24, 2023

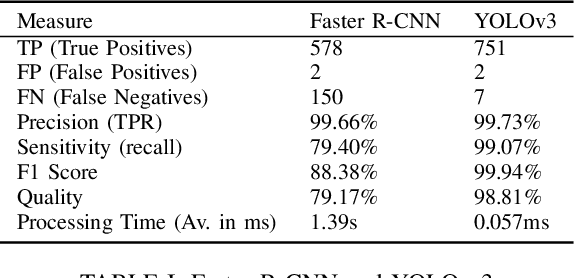
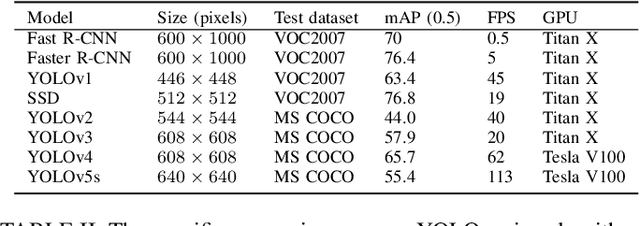
Autonomous driving algorithms rely heavily on learning-based models, which require large datasets for training. However, there is often a large amount of redundant information in these datasets, while collecting and processing these datasets can be time-consuming and expensive. To address this issue, this paper proposes the concept of an active data-collecting strategy. For high-quality data, increasing the collection density can improve the overall quality of the dataset, ultimately achieving similar or even better results than the original dataset with lower labeling costs and smaller dataset sizes. In this paper, we design experiments to verify the quality of the collected dataset and to demonstrate this strategy can significantly reduce labeling costs and dataset size while improving the overall quality of the dataset, leading to better performance of autonomous driving systems. The source code implementing the proposed approach is publicly available on https://github.com/Th1nkMore/carla_dataset_tools.
Boost Video Frame Interpolation via Motion Adaptation
Jun 24, 2023
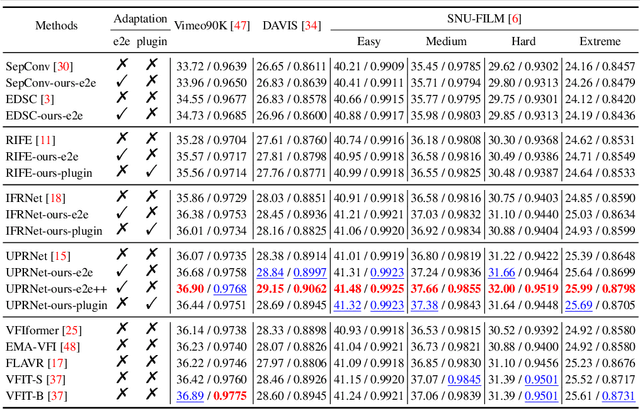
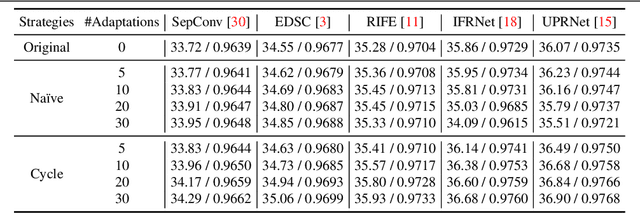
Video frame interpolation (VFI) is a challenging task that aims to generate intermediate frames between two consecutive frames in a video. Existing learning-based VFI methods have achieved great success, but they still suffer from limited generalization ability due to the limited motion distribution of training datasets. In this paper, we propose a novel optimization-based VFI method that can adapt to unseen motions at test time. Our method is based on a cycle-consistency adaptation strategy that leverages the motion characteristics among video frames. We also introduce a lightweight adapter that can be inserted into the motion estimation module of existing pre-trained VFI models to improve the efficiency of adaptation. Extensive experiments on various benchmarks demonstrate that our method can boost the performance of two-frame VFI models, outperforming the existing state-of-the-art methods, even those that use extra input.
The Impacts of Human-Cobot Collaboration on Perceived Cognitive Load and Usability during an Industrial Task: An Exploratory Experiment
May 30, 2023Since cobots (collaborative robots) are increasingly being introduced in industrial environments, being aware of their potential positive and negative impacts on human collaborators is essential. This study guides occupational health workers by identifying the potential gains (reduced perceived time demand, number of gestures and number of errors) and concerns (the cobot takes a long time to perceive its environment, which eads to an increased completion time) associated with working with cobots. In our study, the collaboration between human and cobot during an assembly task did not negatively impact perceived cognitive load, increased completion time (but decreased perceived time demand), and decreased the number of gestures performed by participants and the number of errors made. Thus, performing the task in collaboration with a cobot improved the user's experience and performance, except for completion time, which increased. This study opens up avenues to investigate how to improve cobots to ensure the usability of the human-machine system at work.
* 12 pages
TempT: Temporal consistency for Test-time adaptation
Mar 19, 2023
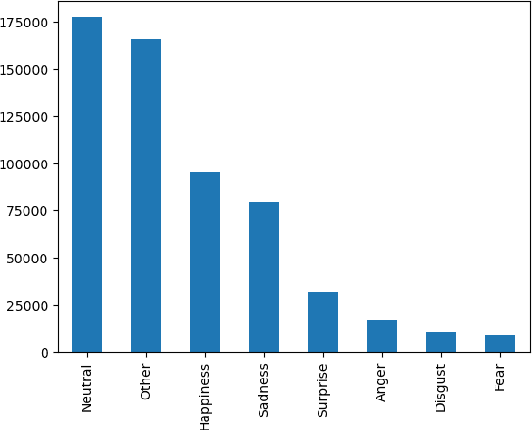
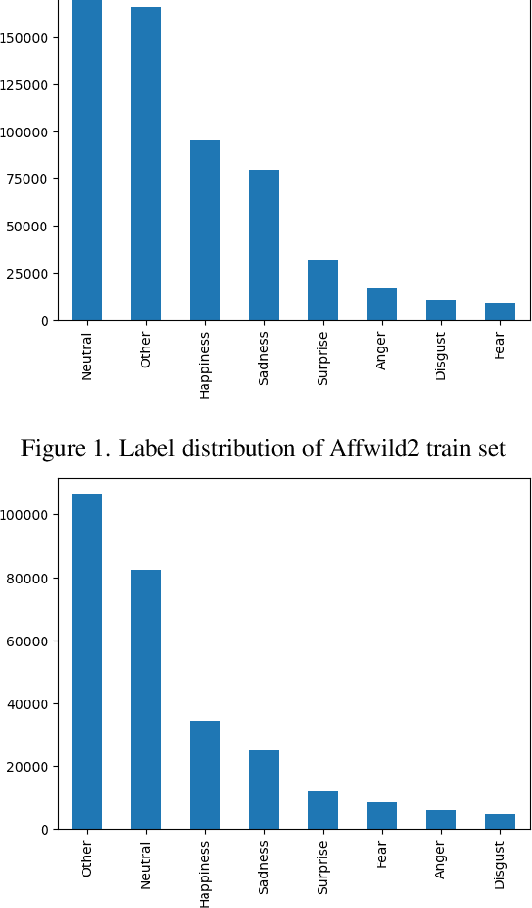

In this technical report, we introduce TempT, a novel method for test time adaptation on videos by ensuring temporal coherence of predictions across sequential frames. TempT is a powerful tool with broad applications in computer vision tasks, including facial expression recognition (FER) in videos. We evaluate TempT's performance on the AffWild2 dataset as part of the Expression Classification Challenge at the 5th Workshop and Competition on Affective Behavior Analysis in the wild (ABAW). Our approach focuses solely on the unimodal visual aspect of the data and utilizes a popular 2D CNN backbone, in contrast to larger sequential or attention based models. Our experimental results demonstrate that TempT has competitive performance in comparison to previous years reported performances, and its efficacy provides a compelling proof of concept for its use in various real world applications.
Magnitude-Corrected and Time-Aligned Interpolation of Head-Related Transfer Functions
Mar 17, 2023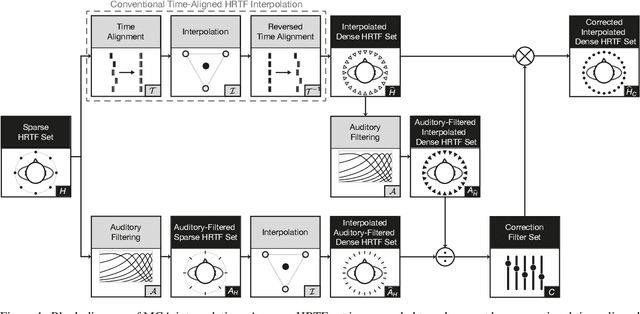
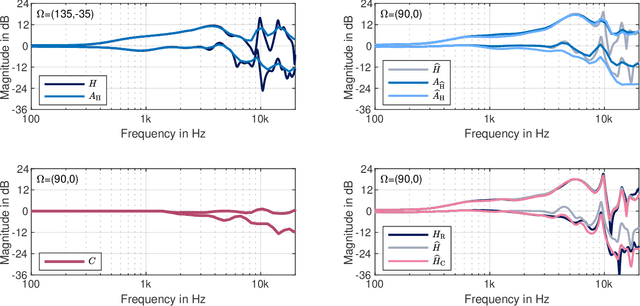
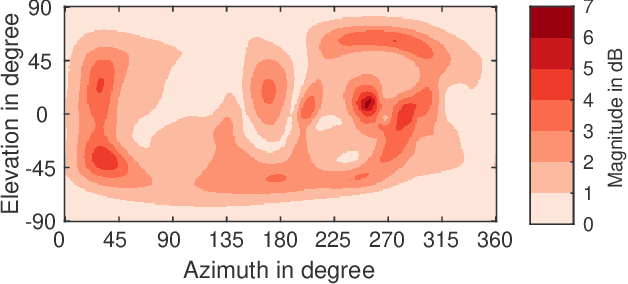
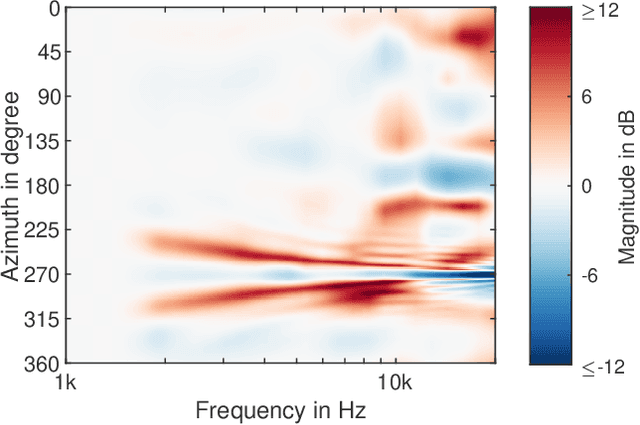
Head-related transfer functions (HRTFs) are essential for virtual acoustic realities, as they contain all cues for localizing sound sources in three-dimensional space. Acoustic measurements are one way to obtain high-quality HRTFs. To reduce measurement time, cost, and complexity of measurement systems, a promising approach is to capture only a few HRTFs on a sparse sampling grid and then upsample them to a dense HRTF set by interpolation. However, HRTF interpolation is challenging because small changes in source position can result in significant changes in the HRTF phase and magnitude response. Previous studies greatly improved the interpolation by time-aligning the HRTFs in preprocessing, but magnitude interpolation errors, especially in contralateral regions, remain a problem. Building upon the time-alignment approaches, we propose an additional post-interpolation magnitude correction derived from a frequency-smoothed HRTF representation. Employing all 96 individual simulated HRTF sets of the HUTUBS database, we show that the magnitude correction significantly reduces interpolation errors compared to state-of-the-art interpolation methods applying only time alignment. Our analysis shows that when upsampling very sparse HRTF sets, the subject-averaged magnitude error in the critical higher frequency range is up to 1.5 dB lower when averaged over all directions and even up to 4 dB lower in the contralateral region. As a result, the interaural level differences in the upsampled HRTFs are considerably improved. The proposed algorithm thus has the potential to further reduce the minimum number of HRTFs required for perceptually transparent interpolation.
A real-time blind quality-of-experience assessment metric for HTTP adaptive streaming
Mar 17, 2023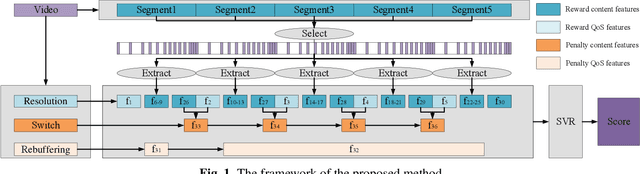

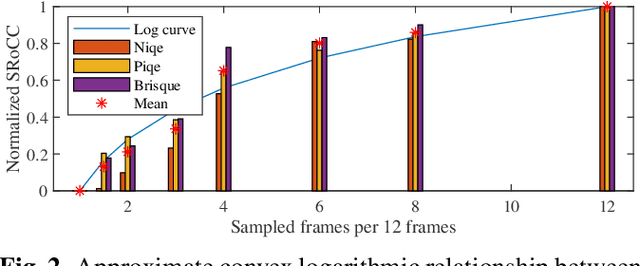
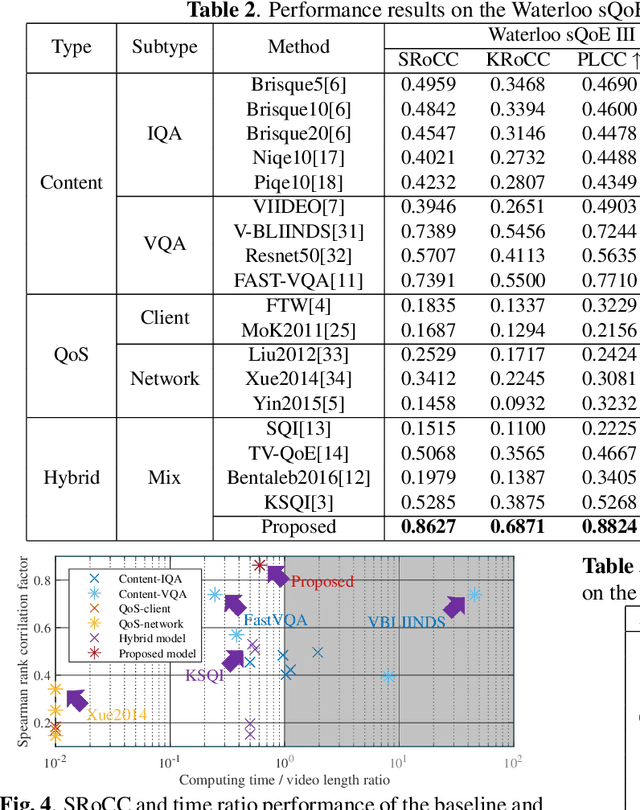
In today's Internet, HTTP Adaptive Streaming (HAS) is the mainstream standard for video streaming, which switches the bitrate of the video content based on an Adaptive BitRate (ABR) algorithm. An effective Quality of Experience (QoE) assessment metric can provide crucial feedback to an ABR algorithm. However, predicting such real-time QoE on the client side is challenging. The QoE prediction requires high consistency with the Human Visual System (HVS), low latency, and blind assessment, which are difficult to realize together. To address this challenge, we analyzed various characteristics of HAS systems and propose a non-uniform sampling metric to reduce time complexity. Furthermore, we design an effective QoE metric that integrates resolution and rebuffering time as the Quality of Service (QoS), as well as spatiotemporal output from a deep neural network and specific switching events as content information. These reward and penalty features are regressed into quality scores with a Support Vector Regression (SVR) model. Experimental results show that the accuracy of our metric outperforms the mainstream blind QoE metrics by 0.3, and its computing time is only 60\% of the video playback, indicating that the proposed metric is capable of providing real-time guidance to ABR algorithms and improving the overall performance of HAS.
Low-Resource White-Box Semantic Segmentation of Supporting Towers on 3D Point Clouds via Signature Shape Identification
Jun 13, 2023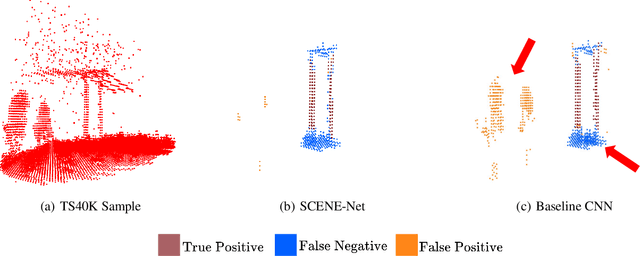

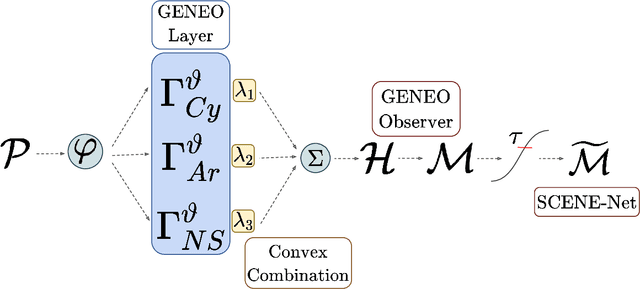
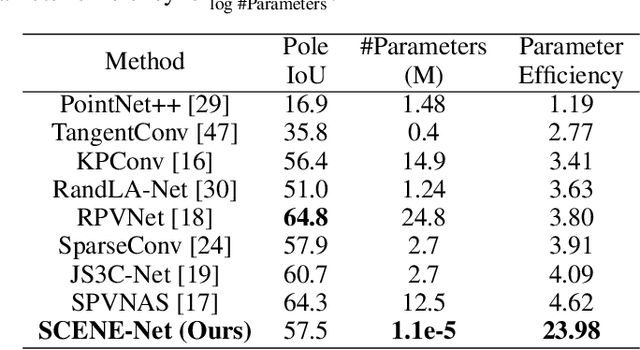
Research in 3D semantic segmentation has been increasing performance metrics, like the IoU, by scaling model complexity and computational resources, leaving behind researchers and practitioners that (1) cannot access the necessary resources and (2) do need transparency on the model decision mechanisms. In this paper, we propose SCENE-Net, a low-resource white-box model for 3D point cloud semantic segmentation. SCENE-Net identifies signature shapes on the point cloud via group equivariant non-expansive operators (GENEOs), providing intrinsic geometric interpretability. Our training time on a laptop is 85~min, and our inference time is 20~ms. SCENE-Net has 11 trainable geometrical parameters and requires fewer data than black-box models. SCENE--Net offers robustness to noisy labeling and data imbalance and has comparable IoU to state-of-the-art methods. With this paper, we release a 40~000 Km labeled dataset of rural terrain point clouds and our code implementation.
Computing large deviation prefactors of stochastic dynamical systems based on machine learning
Jun 20, 2023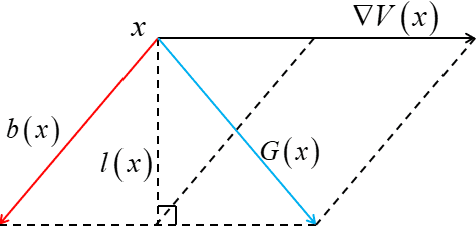

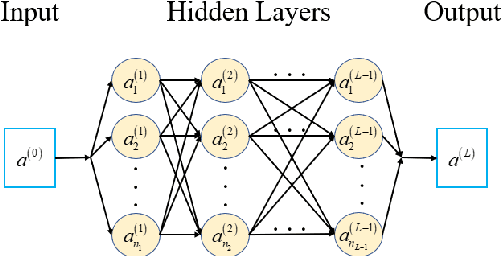
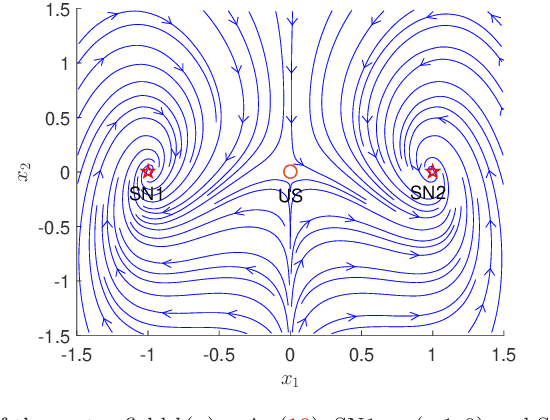
In this paper, we present large deviation theory that characterizes the exponential estimate for rare events of stochastic dynamical systems in the limit of weak noise. We aim to consider next-to-leading-order approximation for more accurate calculation of mean exit time via computing large deviation prefactors with the research efforts of machine learning. More specifically, we design a neural network framework to compute quasipotential, most probable paths and prefactors based on the orthogonal decomposition of vector field. We corroborate the higher effectiveness and accuracy of our algorithm with a practical example. Numerical experiments demonstrate its powerful function in exploring internal mechanism of rare events triggered by weak random fluctuations.