 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Magnitude-Corrected and Time-Aligned Interpolation of Head-Related Transfer Functions
Mar 17, 2023
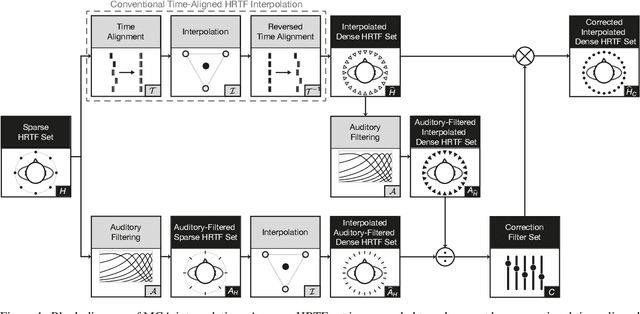
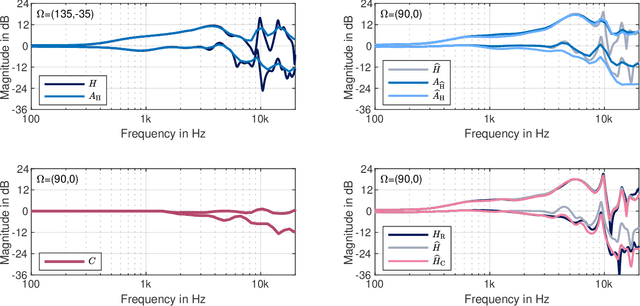
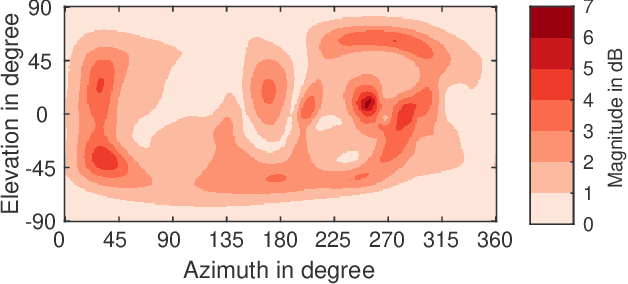
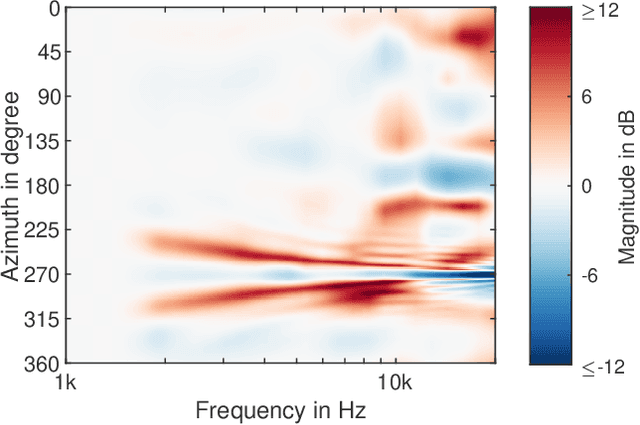
Head-related transfer functions (HRTFs) are essential for virtual acoustic realities, as they contain all cues for localizing sound sources in three-dimensional space. Acoustic measurements are one way to obtain high-quality HRTFs. To reduce measurement time, cost, and complexity of measurement systems, a promising approach is to capture only a few HRTFs on a sparse sampling grid and then upsample them to a dense HRTF set by interpolation. However, HRTF interpolation is challenging because small changes in source position can result in significant changes in the HRTF phase and magnitude response. Previous studies greatly improved the interpolation by time-aligning the HRTFs in preprocessing, but magnitude interpolation errors, especially in contralateral regions, remain a problem. Building upon the time-alignment approaches, we propose an additional post-interpolation magnitude correction derived from a frequency-smoothed HRTF representation. Employing all 96 individual simulated HRTF sets of the HUTUBS database, we show that the magnitude correction significantly reduces interpolation errors compared to state-of-the-art interpolation methods applying only time alignment. Our analysis shows that when upsampling very sparse HRTF sets, the subject-averaged magnitude error in the critical higher frequency range is up to 1.5 dB lower when averaged over all directions and even up to 4 dB lower in the contralateral region. As a result, the interaural level differences in the upsampled HRTFs are considerably improved. The proposed algorithm thus has the potential to further reduce the minimum number of HRTFs required for perceptually transparent interpolation.
A real-time blind quality-of-experience assessment metric for HTTP adaptive streaming
Mar 17, 2023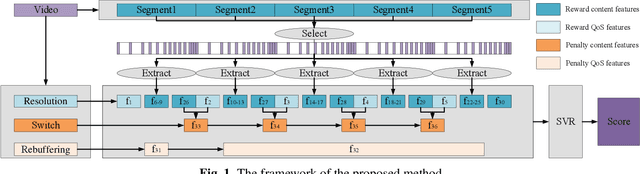

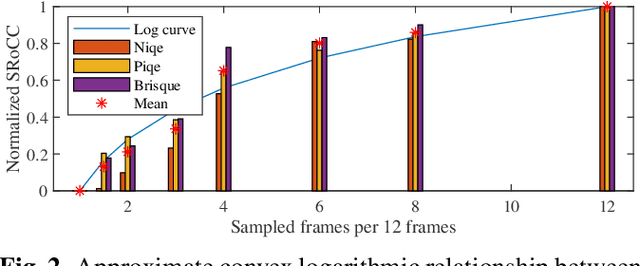
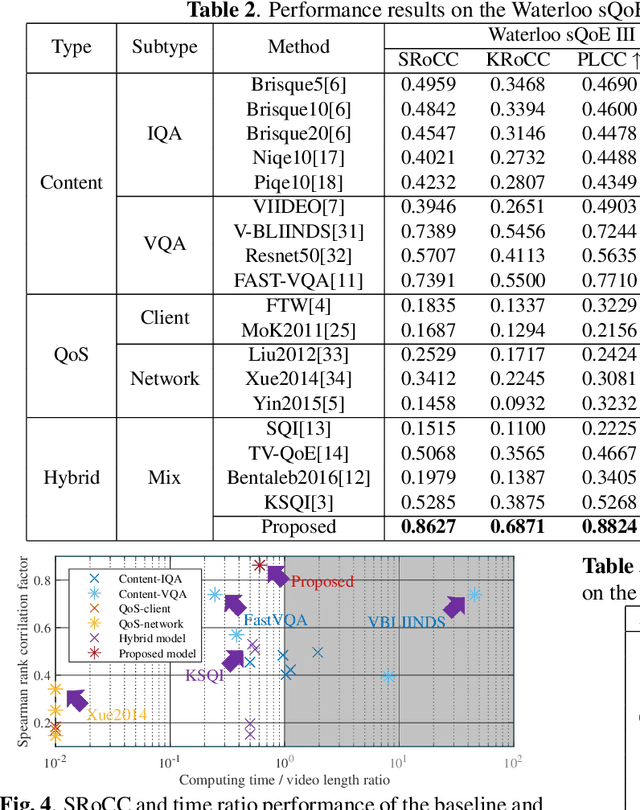
In today's Internet, HTTP Adaptive Streaming (HAS) is the mainstream standard for video streaming, which switches the bitrate of the video content based on an Adaptive BitRate (ABR) algorithm. An effective Quality of Experience (QoE) assessment metric can provide crucial feedback to an ABR algorithm. However, predicting such real-time QoE on the client side is challenging. The QoE prediction requires high consistency with the Human Visual System (HVS), low latency, and blind assessment, which are difficult to realize together. To address this challenge, we analyzed various characteristics of HAS systems and propose a non-uniform sampling metric to reduce time complexity. Furthermore, we design an effective QoE metric that integrates resolution and rebuffering time as the Quality of Service (QoS), as well as spatiotemporal output from a deep neural network and specific switching events as content information. These reward and penalty features are regressed into quality scores with a Support Vector Regression (SVR) model. Experimental results show that the accuracy of our metric outperforms the mainstream blind QoE metrics by 0.3, and its computing time is only 60\% of the video playback, indicating that the proposed metric is capable of providing real-time guidance to ABR algorithms and improving the overall performance of HAS.
The Impacts of Human-Cobot Collaboration on Perceived Cognitive Load and Usability during an Industrial Task: An Exploratory Experiment
May 30, 2023Since cobots (collaborative robots) are increasingly being introduced in industrial environments, being aware of their potential positive and negative impacts on human collaborators is essential. This study guides occupational health workers by identifying the potential gains (reduced perceived time demand, number of gestures and number of errors) and concerns (the cobot takes a long time to perceive its environment, which eads to an increased completion time) associated with working with cobots. In our study, the collaboration between human and cobot during an assembly task did not negatively impact perceived cognitive load, increased completion time (but decreased perceived time demand), and decreased the number of gestures performed by participants and the number of errors made. Thus, performing the task in collaboration with a cobot improved the user's experience and performance, except for completion time, which increased. This study opens up avenues to investigate how to improve cobots to ensure the usability of the human-machine system at work.
* 12 pages
Label-Aware Hyperbolic Embeddings for Fine-grained Emotion Classification
Jun 26, 2023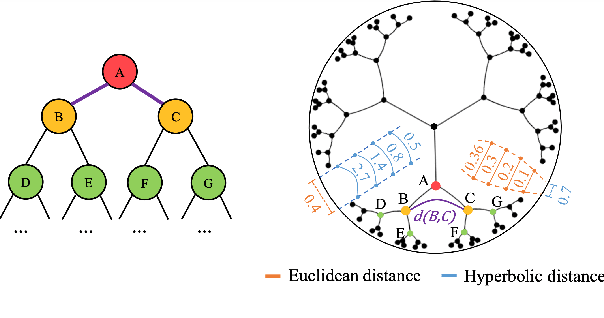
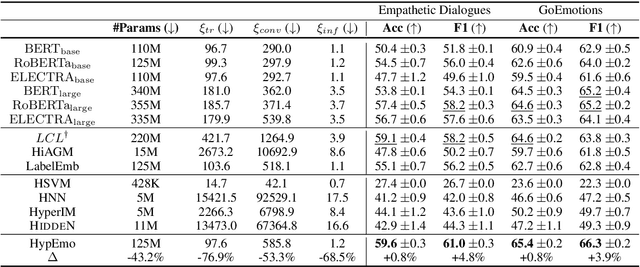
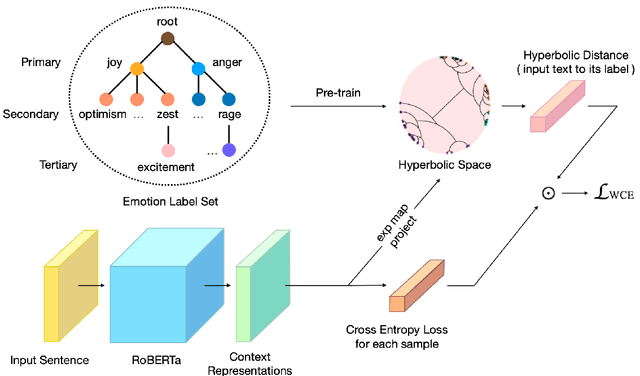
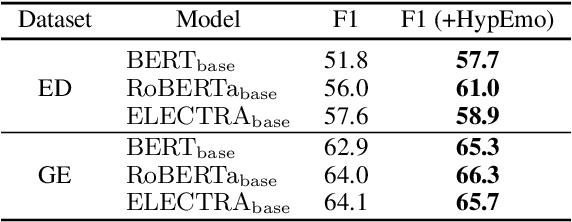
Fine-grained emotion classification (FEC) is a challenging task. Specifically, FEC needs to handle subtle nuance between labels, which can be complex and confusing. Most existing models only address text classification problem in the euclidean space, which we believe may not be the optimal solution as labels of close semantic (e.g., afraid and terrified) may not be differentiated in such space, which harms the performance. In this paper, we propose HypEmo, a novel framework that can integrate hyperbolic embeddings to improve the FEC task. First, we learn label embeddings in the hyperbolic space to better capture their hierarchical structure, and then our model projects contextualized representations to the hyperbolic space to compute the distance between samples and labels. Experimental results show that incorporating such distance to weight cross entropy loss substantially improves the performance with significantly higher efficiency. We evaluate our proposed model on two benchmark datasets and found 4.8% relative improvement compared to the previous state of the art with 43.2% fewer parameters and 76.9% less training time. Code is available at https: //github.com/dinobby/HypEmo.
Accelerating Molecular Graph Neural Networks via Knowledge Distillation
Jun 26, 2023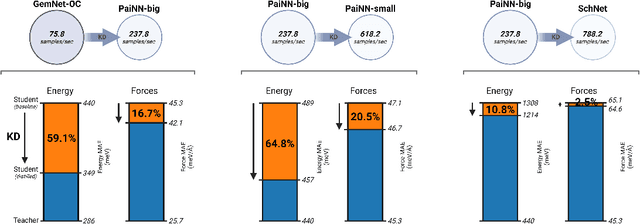

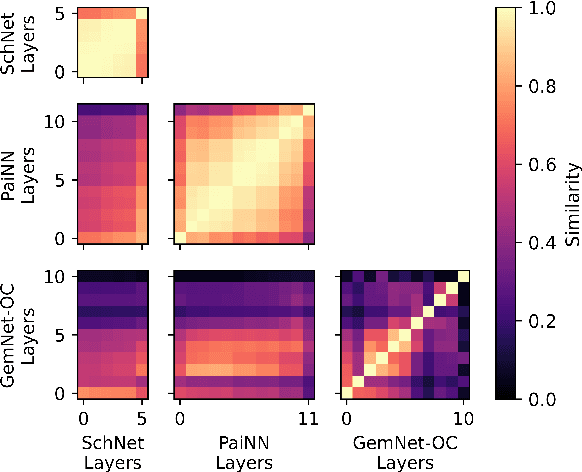
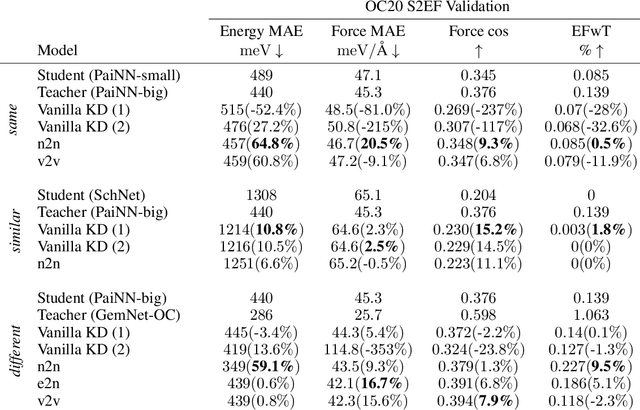
Recent advances in graph neural networks (GNNs) have allowed molecular simulations with accuracy on par with conventional gold-standard methods at a fraction of the computational cost. Nonetheless, as the field has been progressing to bigger and more complex architectures, state-of-the-art GNNs have become largely prohibitive for many large-scale applications. In this paper, we, for the first time, explore the utility of knowledge distillation (KD) for accelerating molecular GNNs. To this end, we devise KD strategies that facilitate the distillation of hidden representations in directional and equivariant GNNs and evaluate their performance on the regression task of energy and force prediction. We validate our protocols across different teacher-student configurations and demonstrate that they can boost the predictive accuracy of student models without altering their architecture. We also conduct comprehensive optimization of various components of our framework, and investigate the potential of data augmentation to further enhance performance. All in all, we manage to close as much as 59% of the gap in predictive accuracy between models like GemNet-OC and PaiNN with zero additional cost at inference.
A Closed-Loop Bin Picking System for Entangled Wire Harnesses using Bimanual and Dynamic Manipulation
Jun 26, 2023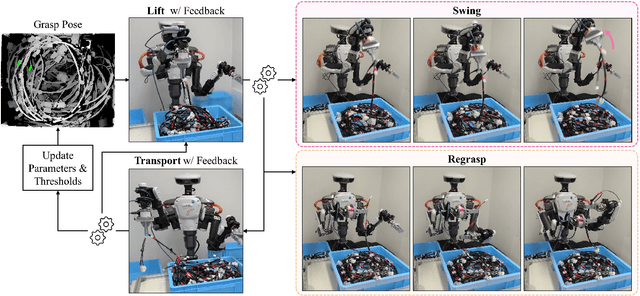



This paper addresses the challenge of industrial bin picking using entangled wire harnesses. Wire harnesses are essential in manufacturing but poses challenges in automation due to their complex geometries and propensity for entanglement. Our previous work tackled this issue by proposing a quasi-static pulling motion to separate the entangled wire harnesses. However, it still lacks sufficiency and generalization to various shapes and structures. In this paper, we deploy a dual-arm robot that can grasp, extract and disentangle wire harnesses from dense clutter using dynamic manipulation. The robot can swing to dynamically discard the entangled objects and regrasp to adjust the undesirable grasp pose. To improve the robustness and accuracy of the system, we leverage a closed-loop framework that uses haptic feedback to detect entanglement in real-time and flexibly adjust system parameters. Our bin picking system achieves an overall success rate of 91.2% in the real-world experiments using two different types of long wire harnesses. It demonstrates the effectiveness of our system in handling various wire harnesses for industrial bin picking.
ChiPFormer: Transferable Chip Placement via Offline Decision Transformer
Jun 26, 2023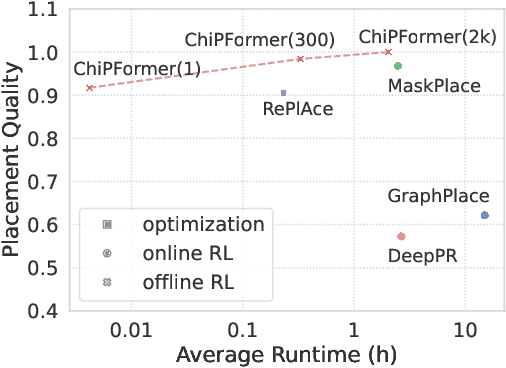



Placement is a critical step in modern chip design, aiming to determine the positions of circuit modules on the chip canvas. Recent works have shown that reinforcement learning (RL) can improve human performance in chip placement. However, such an RL-based approach suffers from long training time and low transfer ability in unseen chip circuits. To resolve these challenges, we cast the chip placement as an offline RL formulation and present ChiPFormer that enables learning a transferable placement policy from fixed offline data. ChiPFormer has several advantages that prior arts do not have. First, ChiPFormer can exploit offline placement designs to learn transferable policies more efficiently in a multi-task setting. Second, ChiPFormer can promote effective finetuning for unseen chip circuits, reducing the placement runtime from hours to minutes. Third, extensive experiments on 32 chip circuits demonstrate that ChiPFormer achieves significantly better placement quality while reducing the runtime by 10x compared to recent state-of-the-art approaches in both public benchmarks and realistic industrial tasks. The deliverables are released at https://sites.google.com/view/chipformer/home.
Multi-View Attention Learning for Residual Disease Prediction of Ovarian Cancer
Jun 26, 2023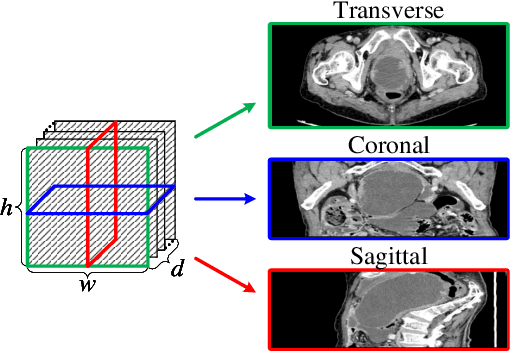
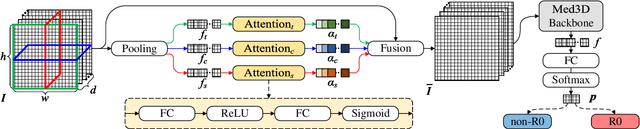
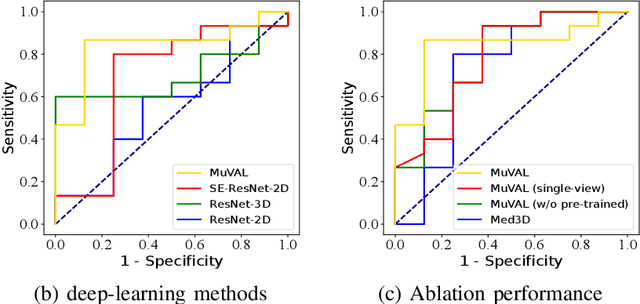

In the treatment of ovarian cancer, precise residual disease prediction is significant for clinical and surgical decision-making. However, traditional methods are either invasive (e.g., laparoscopy) or time-consuming (e.g., manual analysis). Recently, deep learning methods make many efforts in automatic analysis of medical images. Despite the remarkable progress, most of them underestimated the importance of 3D image information of disease, which might brings a limited performance for residual disease prediction, especially in small-scale datasets. To this end, in this paper, we propose a novel Multi-View Attention Learning (MuVAL) method for residual disease prediction, which focuses on the comprehensive learning of 3D Computed Tomography (CT) images in a multi-view manner. Specifically, we first obtain multi-view of 3D CT images from transverse, coronal and sagittal views. To better represent the image features in a multi-view manner, we further leverage attention mechanism to help find the more relevant slices in each view. Extensive experiments on a dataset of 111 patients show that our method outperforms existing deep-learning methods.
Prediction of Deep Ice Layer Thickness Using Adaptive Recurrent Graph Neural Networks
Jun 22, 2023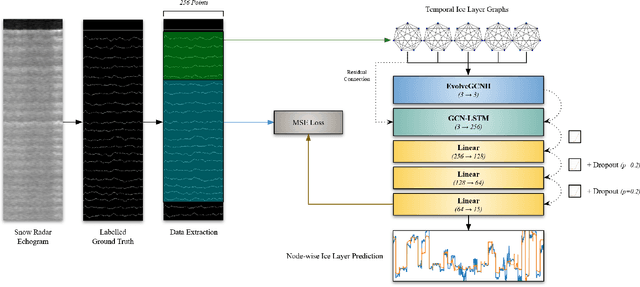

As we deal with the effects of climate change and the increase of global atmospheric temperatures, the accurate tracking and prediction of ice layers within polar ice sheets grows in importance. Studying these ice layers reveals climate trends, how snowfall has changed over time, and the trajectory of future climate and precipitation. In this paper, we propose a machine learning model that uses adaptive, recurrent graph convolutional networks to, when given the amount of snow accumulation in recent years gathered through airborne radar data, predict historic snow accumulation by way of the thickness of deep ice layers. We found that our model performs better and with greater consistency than our previous model as well as equivalent non-temporal, non-geometric, and non-adaptive models.
A Machine Learning Pressure Emulator for Hydrogen Embrittlement
Jun 22, 2023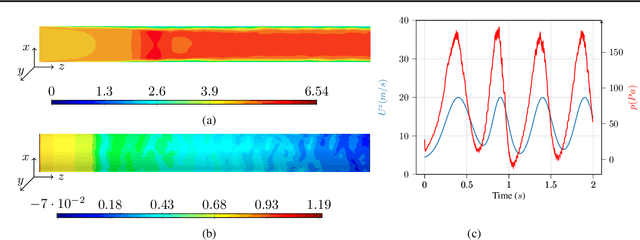
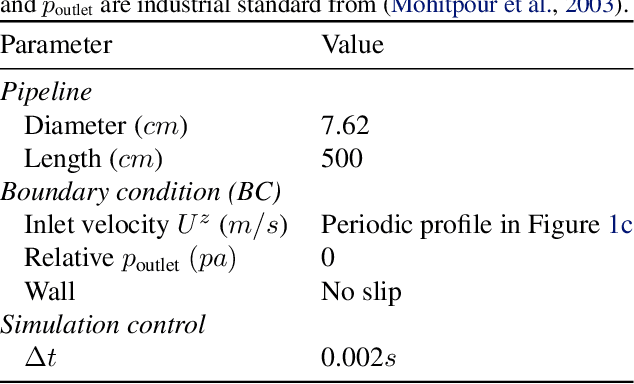
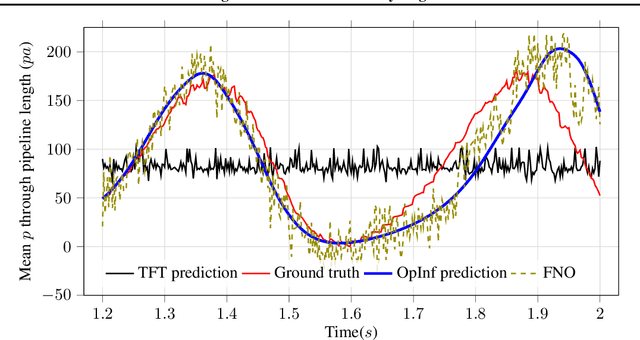

A recent alternative for hydrogen transportation as a mixture with natural gas is blending it into natural gas pipelines. However, hydrogen embrittlement of material is a major concern for scientists and gas installation designers to avoid process failures. In this paper, we propose a physics-informed machine learning model to predict the gas pressure on the pipes' inner wall. Despite its high-fidelity results, the current PDE-based simulators are time- and computationally-demanding. Using simulation data, we train an ML model to predict the pressure on the pipelines' inner walls, which is a first step for pipeline system surveillance. We found that the physics-based method outperformed the purely data-driven method and satisfy the physical constraints of the gas flow system.