 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Jailbreaking is Best Solved by Definition
Mar 20, 2024
The rise of "jailbreak" attacks on language models has led to a flurry of defenses aimed at preventing the output of undesirable responses. In this work, we critically examine the two stages of the defense pipeline: (i) the definition of what constitutes unsafe outputs, and (ii) the enforcement of the definition via methods such as input processing or fine-tuning. We cast severe doubt on the efficacy of existing enforcement mechanisms by showing that they fail to defend even for a simple definition of unsafe outputs--outputs that contain the word "purple". In contrast, post-processing outputs is perfectly robust for such a definition. Drawing on our results, we present our position that the real challenge in defending jailbreaks lies in obtaining a good definition of unsafe responses: without a good definition, no enforcement strategy can succeed, but with a good definition, output processing already serves as a robust baseline albeit with inference-time overheads.
Near-Real-Time Mueller Polarimetric Image Processing for Neurosurgical Intervention
Mar 01, 2024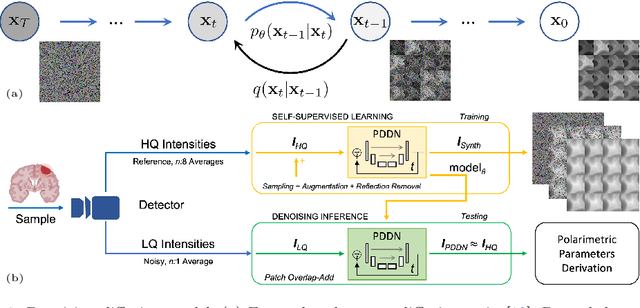

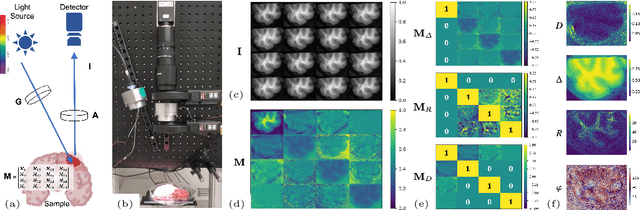
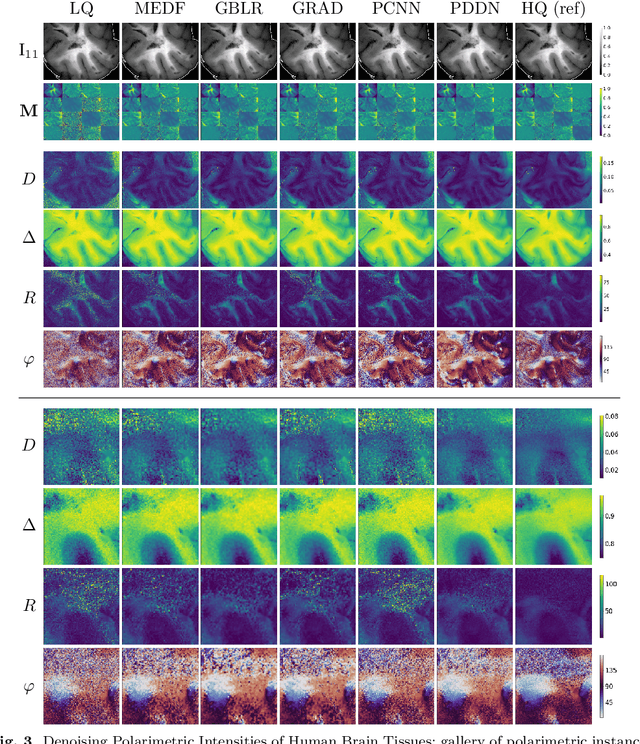
Wide-field imaging Mueller polarimetry is a revolutionary, label-free, and non-invasive modality for computer-aided intervention: in neurosurgery it aims to provide visual feedback of white matter fibre bundle orientation from derived parameters. Conventionally, robust polarimetric parameters are estimated after averaging multiple measurements of intensity for each pair of probing and detected polarised light. Long multi-shot averaging, however, is not compatible with real-time in-vivo imaging, and the current performance of polarimetric data processing hinders the translation to clinical practice. A learning-based denoising framework is tailored for fast, single-shot, noisy acquisitions of polarimetric intensities. Also, performance-optimised image processing tools are devised for the derivation of clinically relevant parameters. The combination recovers accurate polarimetric parameters from fast acquisitions with near-real-time performance, under the assumption of pseudo-Gaussian polarimetric acquisition noise. The denoising framework is trained, validated, and tested on experimental data comprising tumour-free and diseased human brain samples in different conditions. Accuracy and image quality indices showed significant improvements on testing data for a fast single-pass denoising versus the state-of-the-art and high polarimetric image quality standards. The computational time is reported for the end-to-end processing. The end-to-end image processing achieved real-time performance for a localised field of view. The denoised polarimetric intensities produced visibly clear directional patterns of neuronal fibre tracts in line with reference polarimetric image quality standards; directional disruption was kept in case of neoplastic lesions. The presented advances pave the way towards feasible oncological neurosurgical translations of novel, label free, interventional feedback.
Accelerating Diffusion Sampling with Optimized Time Steps
Feb 27, 2024Diffusion probabilistic models (DPMs) have shown remarkable performance in high-resolution image synthesis, but their sampling efficiency is still to be desired due to the typically large number of sampling steps. Recent advancements in high-order numerical ODE solvers for DPMs have enabled the generation of high-quality images with much fewer sampling steps. While this is a significant development, most sampling methods still employ uniform time steps, which is not optimal when using a small number of steps. To address this issue, we propose a general framework for designing an optimization problem that seeks more appropriate time steps for a specific numerical ODE solver for DPMs. This optimization problem aims to minimize the distance between the ground-truth solution to the ODE and an approximate solution corresponding to the numerical solver. It can be efficiently solved using the constrained trust region method, taking less than $15$ seconds. Our extensive experiments on both unconditional and conditional sampling using pixel- and latent-space DPMs demonstrate that, when combined with the state-of-the-art sampling method UniPC, our optimized time steps significantly improve image generation performance in terms of FID scores for datasets such as CIFAR-10 and ImageNet, compared to using uniform time steps.
CathFlow: Self-Supervised Segmentation of Catheters in Interventional Ultrasound Using Optical Flow and Transformers
Mar 21, 2024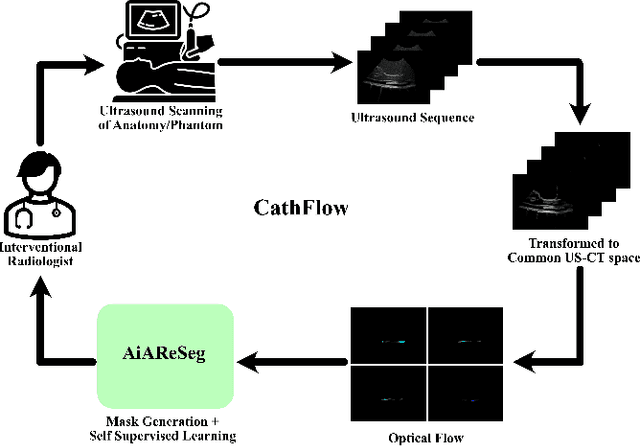
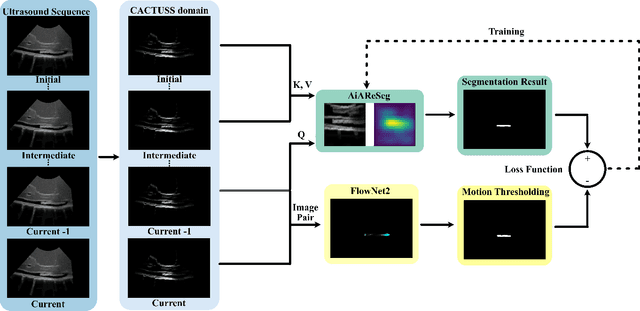

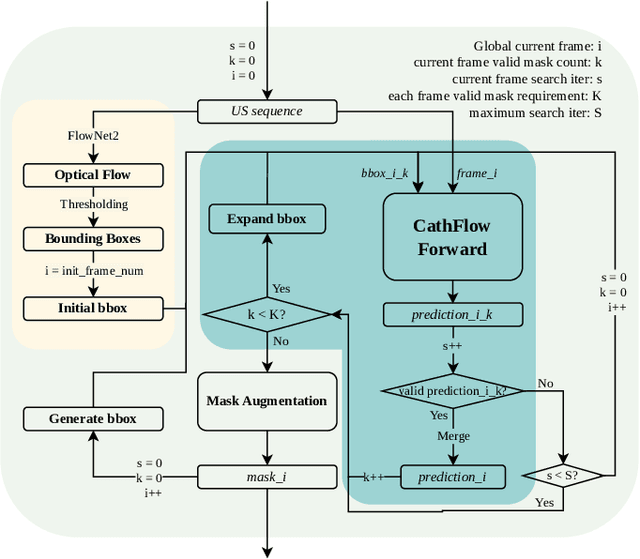
In minimally invasive endovascular procedures, contrast-enhanced angiography remains the most robust imaging technique. However, it is at the expense of the patient and clinician's health due to prolonged radiation exposure. As an alternative, interventional ultrasound has notable benefits such as being radiation-free, fast to deploy, and having a small footprint in the operating room. Yet, ultrasound is hard to interpret, and highly prone to artifacts and noise. Additionally, interventional radiologists must undergo extensive training before they become qualified to diagnose and treat patients effectively, leading to a shortage of staff, and a lack of open-source datasets. In this work, we seek to address both problems by introducing a self-supervised deep learning architecture to segment catheters in longitudinal ultrasound images, without demanding any labeled data. The network architecture builds upon AiAReSeg, a segmentation transformer built with the Attention in Attention mechanism, and is capable of learning feature changes across time and space. To facilitate training, we used synthetic ultrasound data based on physics-driven catheter insertion simulations, and translated the data into a unique CT-Ultrasound common domain, CACTUSS, to improve the segmentation performance. We generated ground truth segmentation masks by computing the optical flow between adjacent frames using FlowNet2, and performed thresholding to obtain a binary map estimate. Finally, we validated our model on a test dataset, consisting of unseen synthetic data and images collected from silicon aorta phantoms, thus demonstrating its potential for applications to clinical data in the future.
Exploring Green AI for Audio Deepfake Detection
Mar 21, 2024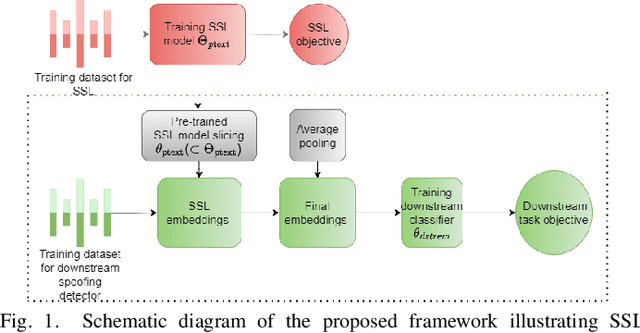
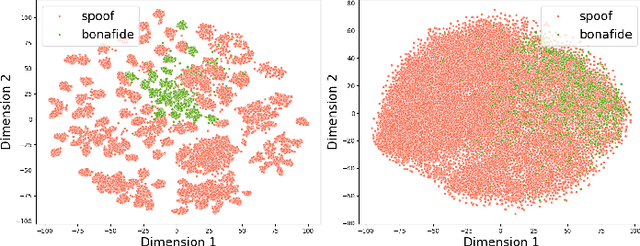
The state-of-the-art audio deepfake detectors leveraging deep neural networks exhibit impressive recognition performance. Nonetheless, this advantage is accompanied by a significant carbon footprint. This is mainly due to the use of high-performance computing with accelerators and high training time. Studies show that average deep NLP model produces around 626k lbs of CO\textsubscript{2} which is equivalent to five times of average US car emission at its lifetime. This is certainly a massive threat to the environment. To tackle this challenge, this study presents a novel framework for audio deepfake detection that can be seamlessly trained using standard CPU resources. Our proposed framework utilizes off-the-shelve self-supervised learning (SSL) based models which are pre-trained and available in public repositories. In contrast to existing methods that fine-tune SSL models and employ additional deep neural networks for downstream tasks, we exploit classical machine learning algorithms such as logistic regression and shallow neural networks using the SSL embeddings extracted using the pre-trained model. Our approach shows competitive results compared to the commonly used high-carbon footprint approaches. In experiments with the ASVspoof 2019 LA dataset, we achieve a 0.90\% equal error rate (EER) with less than 1k trainable model parameters. To encourage further research in this direction and support reproducible results, the Python code will be made publicly accessible following acceptance. Github: https://github.com/sahasubhajit/Speech-Spoofing-
Tur[k]ingBench: A Challenge Benchmark for Web Agents
Mar 21, 2024![Figure 1 for Tur[k]ingBench: A Challenge Benchmark for Web Agents](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2F341da3f8af6edd31edd8f5a3d9452957aeaaa744%2F2-Figure1-1.png&w=640&q=75)
![Figure 2 for Tur[k]ingBench: A Challenge Benchmark for Web Agents](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2F341da3f8af6edd31edd8f5a3d9452957aeaaa744%2F3-Table1-1.png&w=640&q=75)
![Figure 3 for Tur[k]ingBench: A Challenge Benchmark for Web Agents](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2F341da3f8af6edd31edd8f5a3d9452957aeaaa744%2F5-Figure2-1.png&w=640&q=75)
![Figure 4 for Tur[k]ingBench: A Challenge Benchmark for Web Agents](/_next/image?url=https%3A%2F%2Fd3i71xaburhd42.cloudfront.net%2F341da3f8af6edd31edd8f5a3d9452957aeaaa744%2F5-Figure3-1.png&w=640&q=75)
Recent chatbots have demonstrated impressive ability to understand and communicate in raw-text form. However, there is more to the world than raw text. For example, humans spend long hours of their time on web pages, where text is intertwined with other modalities and tasks are accomplished in the form of various complex interactions. Can state-of-the-art multi-modal models generalize to such complex domains? To address this question, we introduce TurkingBench, a benchmark of tasks formulated as web pages containing textual instructions with multi-modal context. Unlike existing work which employs artificially synthesized web pages, here we use natural HTML pages that were originally designed for crowdsourcing workers for various annotation purposes. The HTML instructions of each task are also instantiated with various values (obtained from the crowdsourcing tasks) to form new instances of the task. This benchmark contains 32.2K instances distributed across 158 tasks. Additionally, to facilitate the evaluation on TurkingBench, we develop an evaluation framework that connects the responses of chatbots to modifications on web pages (modifying a text box, checking a radio, etc.). We evaluate the performance of state-of-the-art models, including language-only, vision-only, and layout-only models, and their combinations, on this benchmark. Our findings reveal that these models perform significantly better than random chance, yet considerable room exists for improvement. We hope this benchmark will help facilitate the evaluation and development of web-based agents.
Light Curve Classification with DistClassiPy: a new distance-based classifier
Mar 18, 2024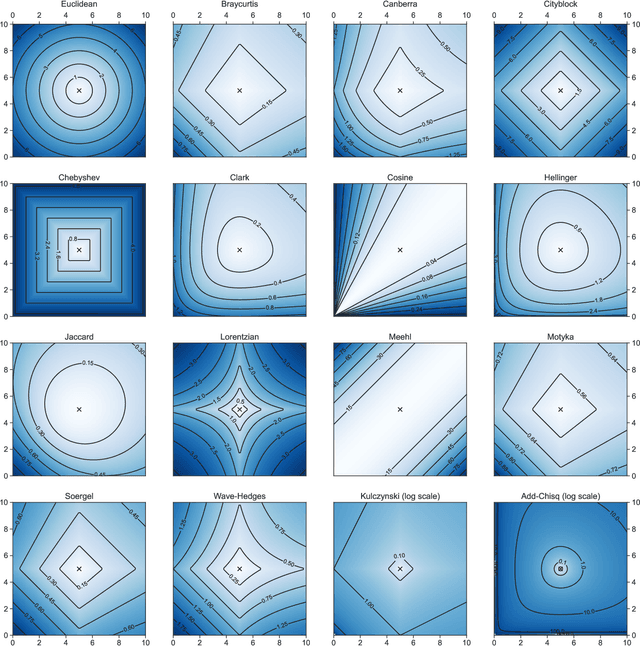
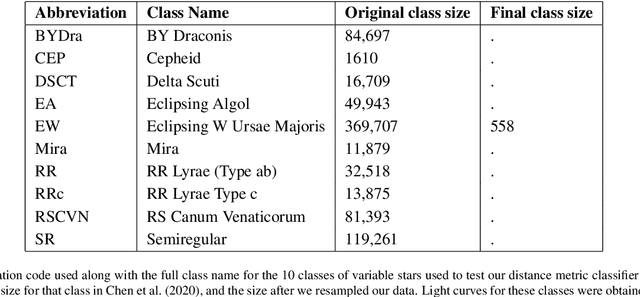
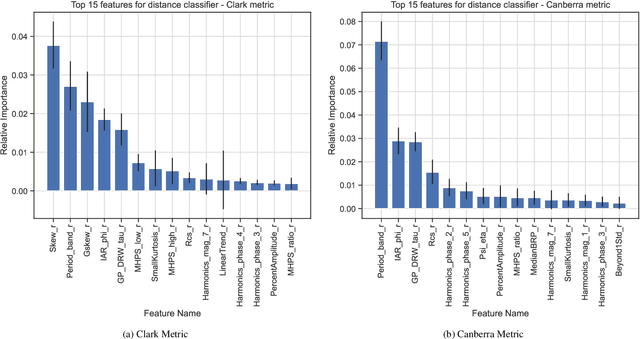
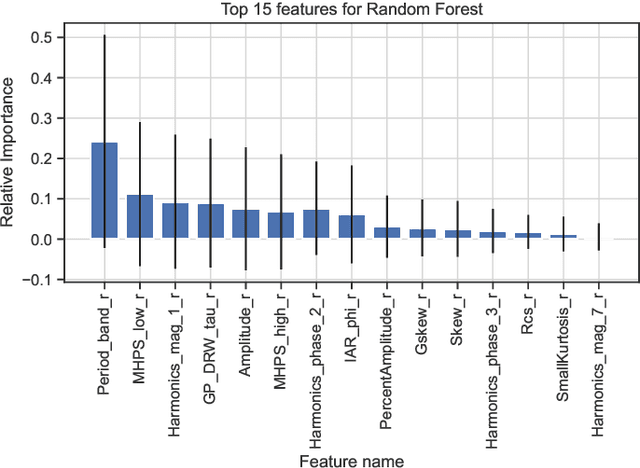
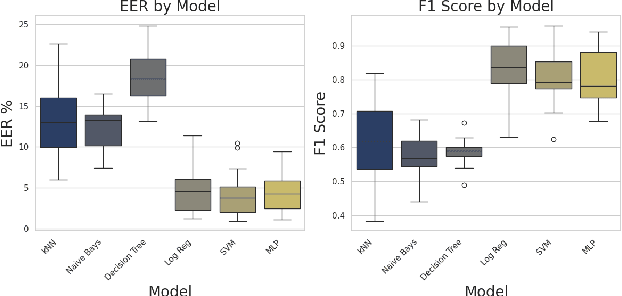
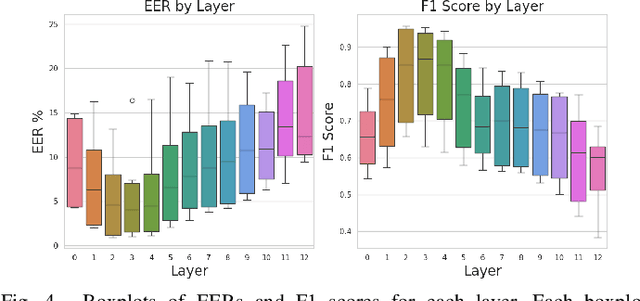
The rise of synoptic sky surveys has ushered in an era of big data in time-domain astronomy, making data science and machine learning essential tools for studying celestial objects. Tree-based (e.g. Random Forests) and deep learning models represent the current standard in the field. We explore the use of different distance metrics to aid in the classification of objects. For this, we developed a new distance metric based classifier called DistClassiPy. The direct use of distance metrics is an approach that has not been explored in time-domain astronomy, but distance-based methods can aid in increasing the interpretability of the classification result and decrease the computational costs. In particular, we classify light curves of variable stars by comparing the distances between objects of different classes. Using 18 distance metrics applied to a catalog of 6,000 variable stars in 10 classes, we demonstrate classification and dimensionality reduction. We show that this classifier meets state-of-the-art performance but has lower computational requirements and improved interpretability. We have made DistClassiPy open-source and accessible at https://pypi.org/project/distclassipy/ with the goal of broadening its applications to other classification scenarios within and beyond astronomy.
Accelerating Model Predictive Control for Legged Robots through Distributed Optimization
Mar 18, 2024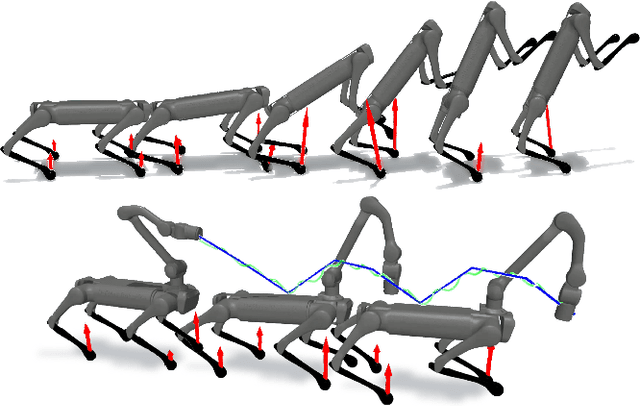
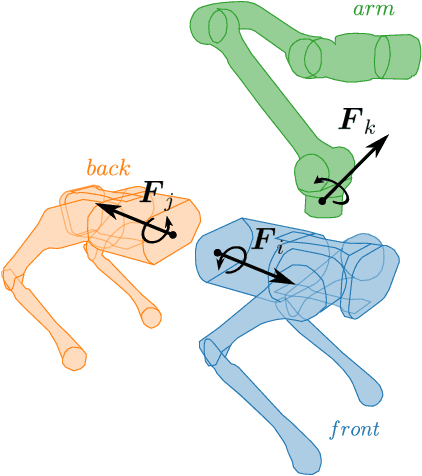
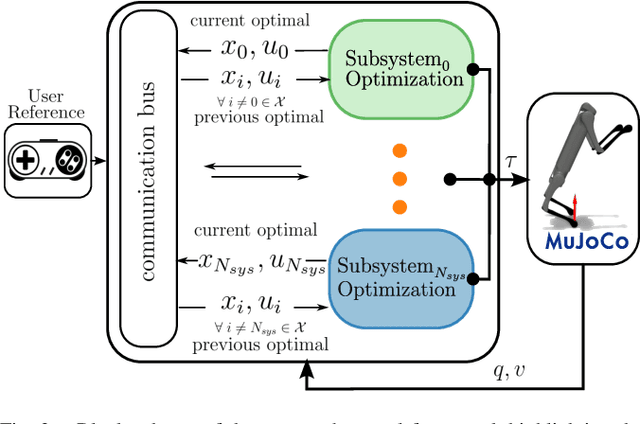
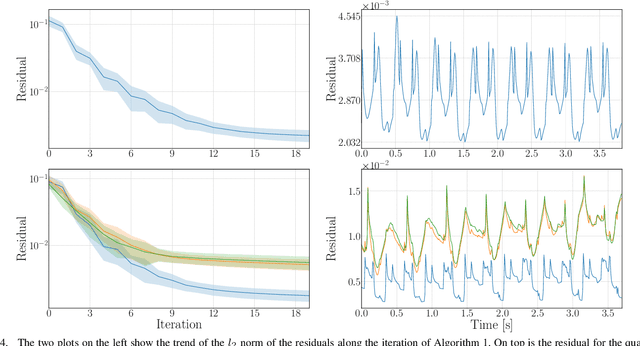
This paper presents a novel approach to enhance Model Predictive Control (MPC) for legged robots through Distributed Optimization. Our method focuses on decomposing the robot dynamics into smaller, parallelizable subsystems, and utilizing the Alternating Direction Method of Multipliers (ADMM) to ensure consensus among them. Each subsystem is managed by its own \gls{ocp}, with ADMM facilitating consistency between their optimizations. This approach not only decreases the computational time but also allows for effective scaling with more complex robot configurations, facilitating the integration of additional subsystems such as articulated arms on a quadruped robot. We demonstrate, through numerical evaluations, the convergence of our approach on two systems with increasing complexity. In addition, we showcase that our approach converges towards the same solution when compared to a state-of-the-art centralized whole-body MPC implementation. Moreover, we quantitatively compare the computational efficiency of our method to the centralized approach, revealing up to a 75\% reduction in computational time. Overall, our approach offers a promising avenue for accelerating MPC solutions for legged robots, paving the way for more effective utilization of the computational performance of modern hardware.
DiffMOT: A Real-time Diffusion-based Multiple Object Tracker with Non-linear Prediction
Mar 04, 2024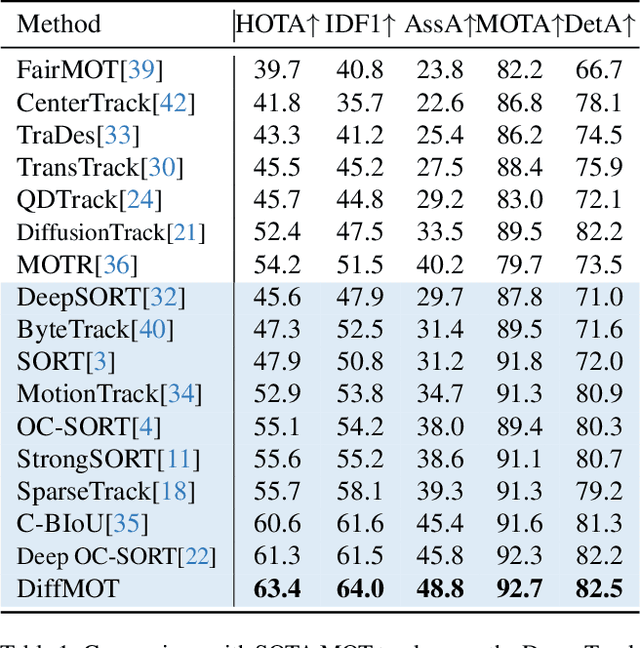
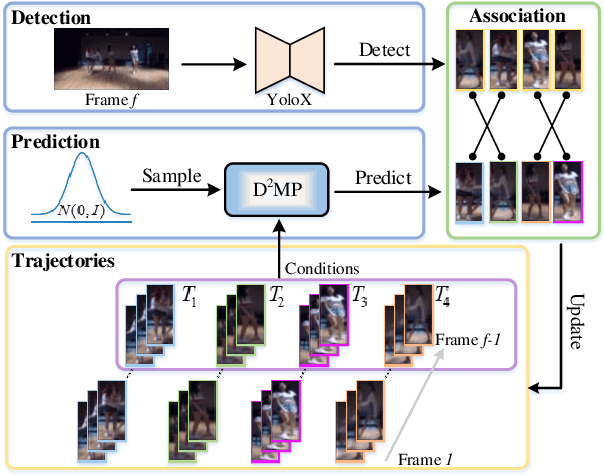
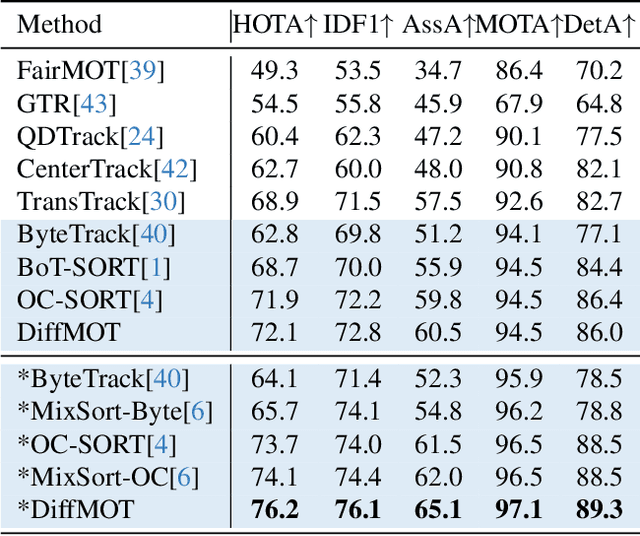
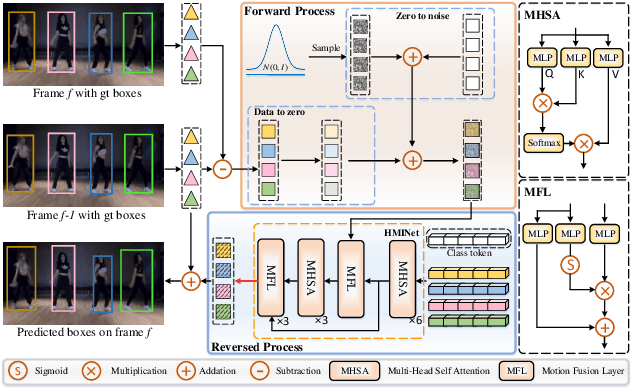
In Multiple Object Tracking, objects often exhibit non-linear motion of acceleration and deceleration, with irregular direction changes. Tacking-by-detection (TBD) with Kalman Filter motion prediction works well in pedestrian-dominant scenarios but falls short in complex situations when multiple objects perform non-linear and diverse motion simultaneously. To tackle the complex non-linear motion, we propose a real-time diffusion-based MOT approach named DiffMOT. Specifically, for the motion predictor component, we propose a novel Decoupled Diffusion-based Motion Predictor (D MP). It models the entire distribution of various motion presented by the data as a whole. It also predicts an individual object's motion conditioning on an individual's historical motion information. Furthermore, it optimizes the diffusion process with much less sampling steps. As a MOT tracker, the DiffMOT is real-time at 22.7FPS, and also outperforms the state-of-the-art on DanceTrack and SportsMOT datasets with 63.4 and 76.2 in HOTA metrics, respectively. To the best of our knowledge, DiffMOT is the first to introduce a diffusion probabilistic model into the MOT to tackle non-linear motion prediction.
Graph Expansion in Pruned Recurrent Neural Network Layers Preserve Performance
Mar 17, 2024
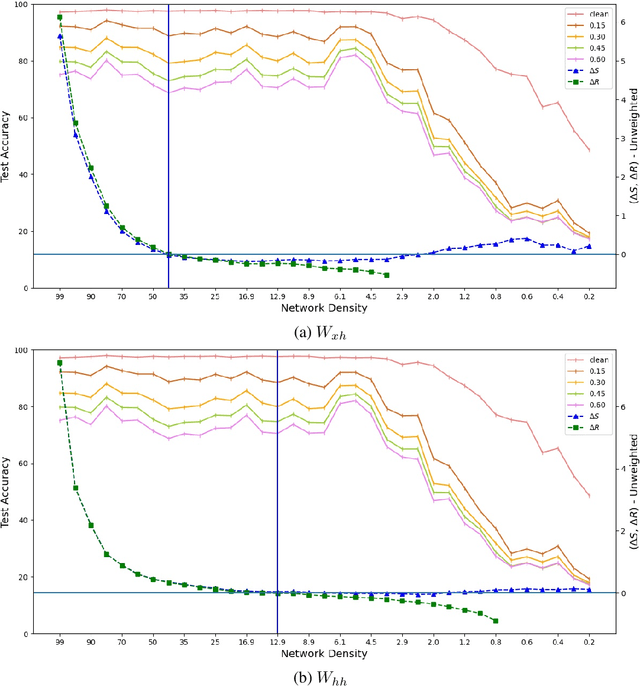
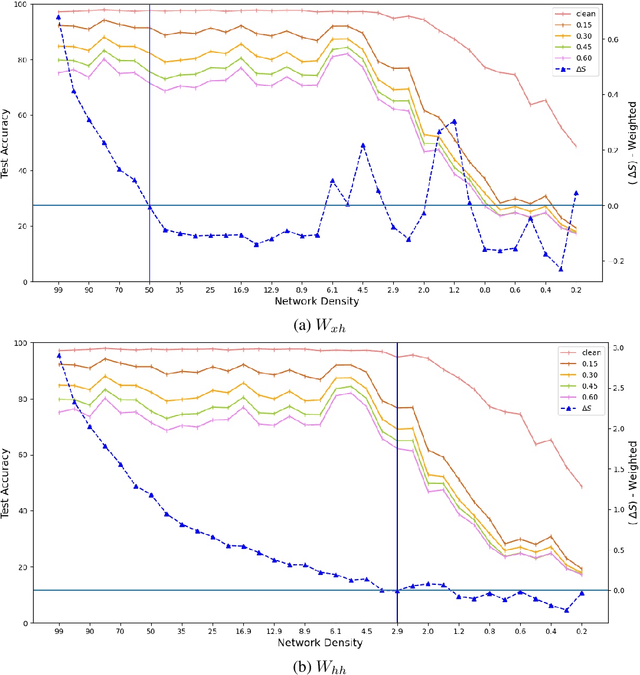
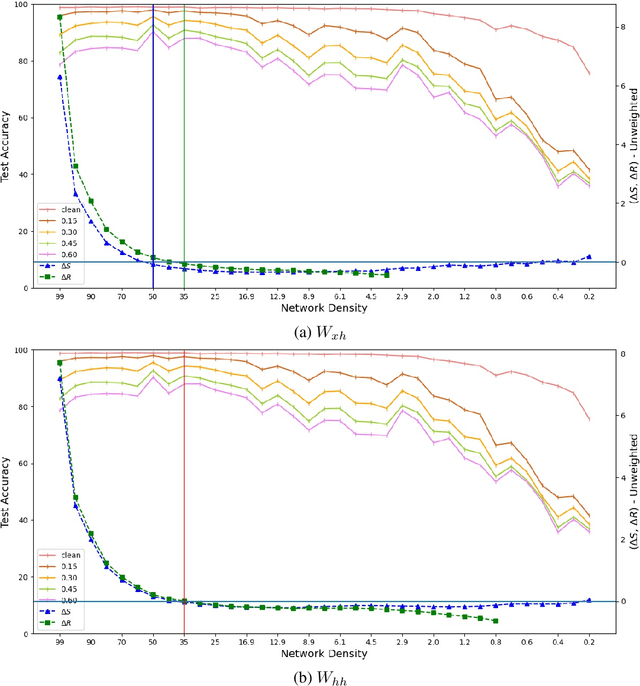
Expansion property of a graph refers to its strong connectivity as well as sparseness. It has been reported that deep neural networks can be pruned to a high degree of sparsity while maintaining their performance. Such pruning is essential for performing real time sequence learning tasks using recurrent neural networks in resource constrained platforms. We prune recurrent networks such as RNNs and LSTMs, maintaining a large spectral gap of the underlying graphs and ensuring their layerwise expansion properties. We also study the time unfolded recurrent network graphs in terms of the properties of their bipartite layers. Experimental results for the benchmark sequence MNIST, CIFAR-10, and Google speech command data show that expander graph properties are key to preserving classification accuracy of RNN and LSTM.