 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Leaping Into Memories: Space-Time Deep Feature Synthesis
Mar 20, 2023
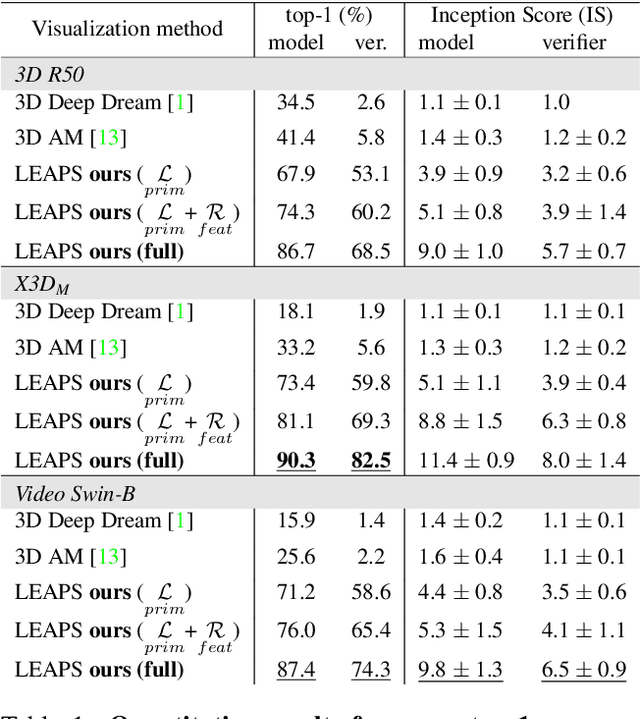
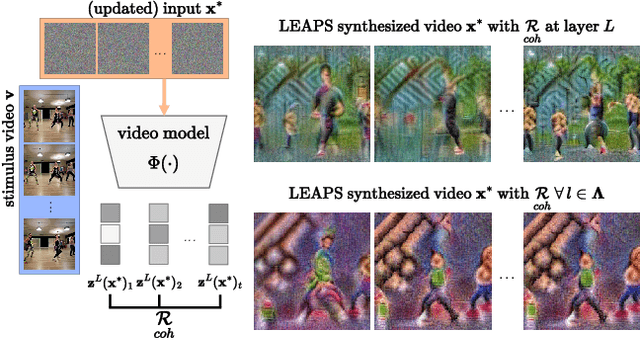
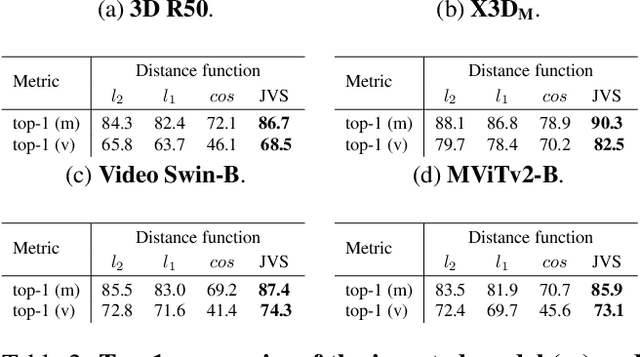
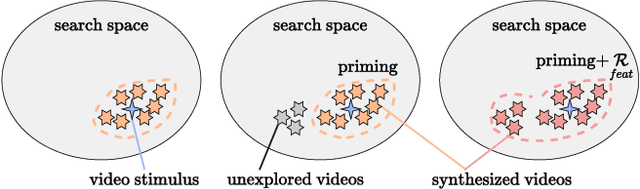
The success of deep learning models has led to their adaptation and adoption by prominent video understanding methods. The majority of these approaches encode features in a joint space-time modality for which the inner workings and learned representations are difficult to visually interpret. We propose LEArned Preconscious Synthesis (LEAPS), an architecture-agnostic method for synthesizing videos from the internal spatiotemporal representations of models. Using a stimulus video and a target class, we prime a fixed space-time model and iteratively optimize a video initialized with random noise. We incorporate additional regularizers to improve the feature diversity of the synthesized videos as well as the cross-frame temporal coherence of motions. We quantitatively and qualitatively evaluate the applicability of LEAPS by inverting a range of spatiotemporal convolutional and attention-based architectures trained on Kinetics-400, which to the best of our knowledge has not been previously accomplished.
Evaluation and Optimization of Rendering Techniques for Autonomous Driving Simulation
Jun 27, 2023
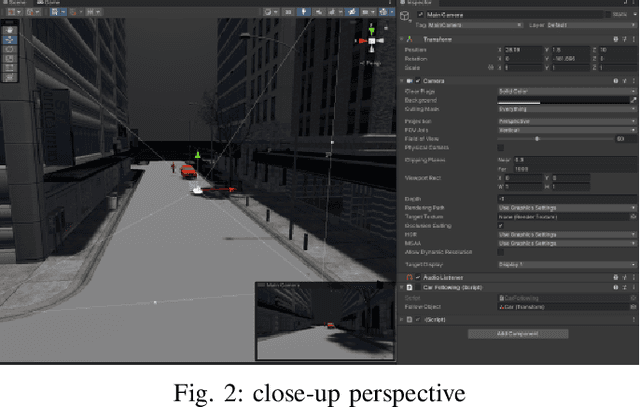
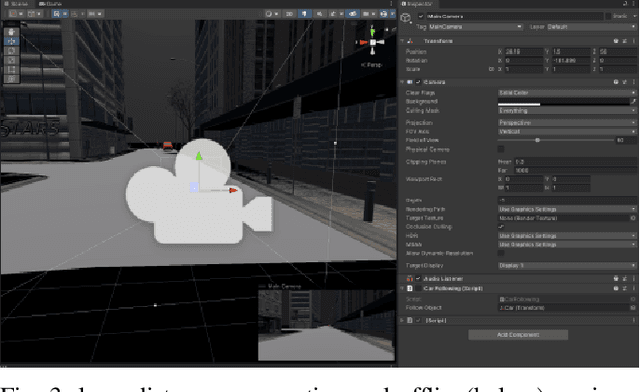

In order to meet the demand for higher scene rendering quality from some autonomous driving teams (such as those focused on CV), we have decided to use an offline simulation industrial rendering framework instead of real-time rendering in our autonomous driving simulator. Our plan is to generate lower-quality scenes using a game engine, extract them, and then use an IQA algorithm to validate the improvement in scene quality achieved through offline rendering. The improved scenes will then be used for training.
Deep Fusion: Efficient Network Training via Pre-trained Initializations
Jun 20, 2023
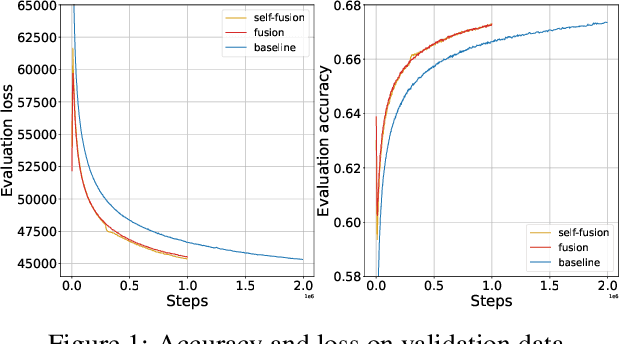
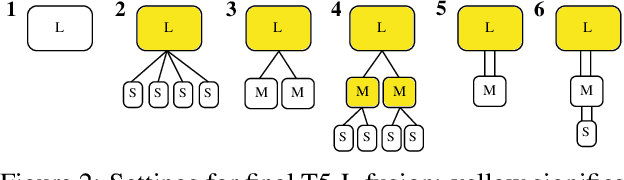

In recent years, deep learning has made remarkable progress in a wide range of domains, with a particularly notable impact on natural language processing tasks. One of the challenges associated with training deep neural networks is the need for large amounts of computational resources and time. In this paper, we present Deep Fusion, an efficient approach to network training that leverages pre-trained initializations of smaller networks. % We show that Deep Fusion accelerates the training process, reduces computational requirements, and leads to improved generalization performance on a variety of NLP tasks and T5 model sizes. % Our experiments demonstrate that Deep Fusion is a practical and effective approach to reduce the training time and resource consumption while maintaining, or even surpassing, the performance of traditional training methods.
Do we become wiser with time? On causal equivalence with tiered background knowledge
Jun 02, 2023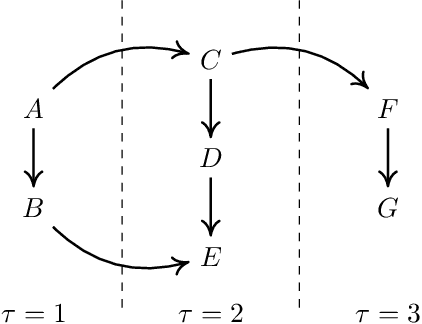
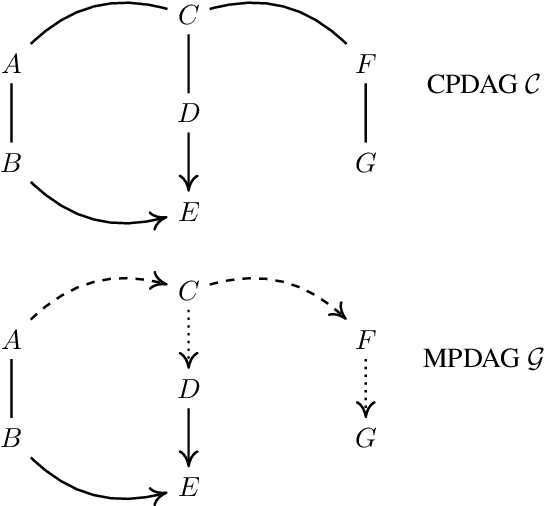
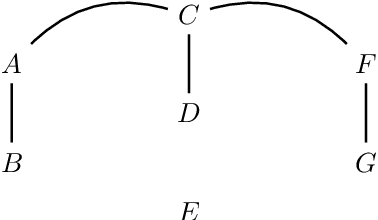
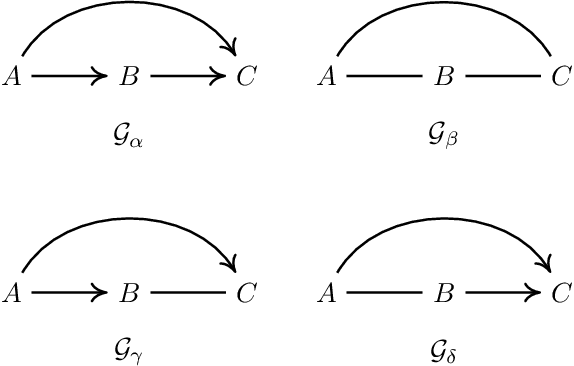
Equivalence classes of DAGs (represented by CPDAGs) may be too large to provide useful causal information. Here, we address incorporating tiered background knowledge yielding restricted equivalence classes represented by 'tiered MPDAGs'. Tiered knowledge leads to considerable gains in informativeness and computational efficiency: We show that construction of tiered MPDAGs only requires application of Meek's 1st rule, and that tiered MPDAGs (unlike general MPDAGs) are chain graphs with chordal components. This entails simplifications e.g. of determining valid adjustment sets for causal effect estimation. Further, we characterise when one tiered ordering is more informative than another, providing insights into useful aspects of background knowledge.
Dynablox: Real-time Detection of Diverse Dynamic Objects in Complex Environments
Apr 21, 2023
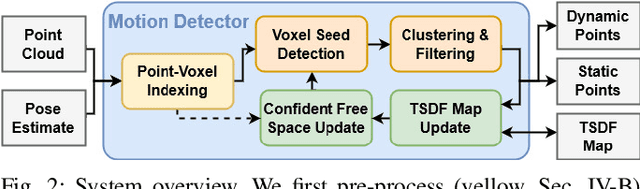

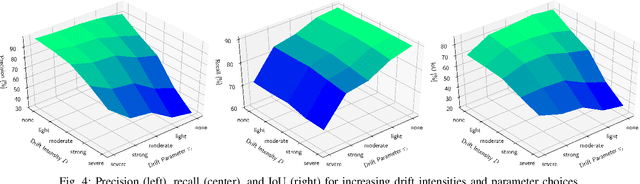
Real-time detection of moving objects is an essential capability for robots acting autonomously in dynamic environments. We thus propose Dynablox, a novel online mapping-based approach for robust moving object detection in complex environments. The central idea of our approach is to incrementally estimate high confidence free-space areas by modeling and accounting for sensing, state estimation, and mapping limitations during online robot operation. The spatio-temporally conservative free space estimate enables robust detection of moving objects without making any assumptions on the appearance of objects or environments. This allows deployment in complex scenes such as multi-storied buildings or staircases, and for diverse moving objects such as people carrying various items, doors swinging or even balls rolling around. We thoroughly evaluate our approach on real-world data sets, achieving 86% IoU at 17 FPS in typical robotic settings. The method outperforms a recent appearance-based classifier and approaches the performance of offline methods. We demonstrate its generality on a novel data set with rare moving objects in complex environments. We make our efficient implementation and the novel data set available as open-source.
Random Forests for time-fixed and time-dependent predictors: The DynForest R package
Feb 06, 2023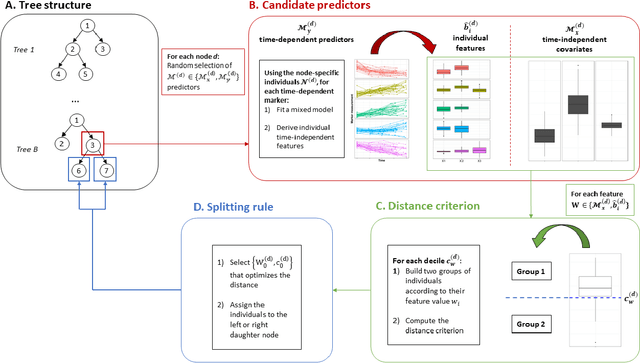

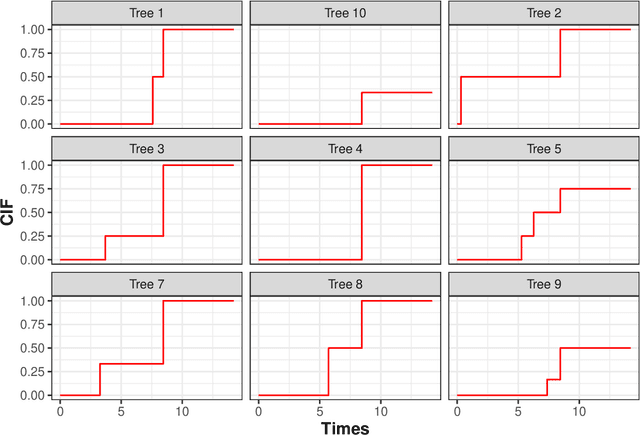
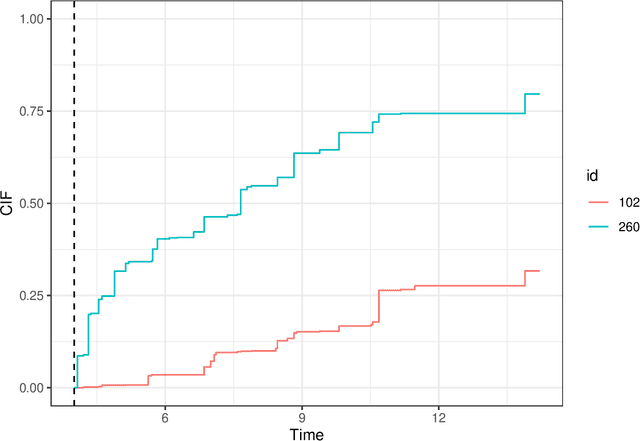
The R package DynForest implements random forests for predicting a categorical or a (multiple causes) time-to-event outcome based on time-fixed and time-dependent predictors. Through the random forests, the time-dependent predictors can be measured with error at subject-specific times, and they can be endogeneous (i.e., impacted by the outcome process). They are modeled internally using flexible linear mixed models (thanks to lcmm package) with time-associations pre-specified by the user. DynForest computes dynamic predictions that take into account all the information from time-fixed and time-dependent predictors. DynForest also provides information about the most predictive variables using variable importance and minimal depth. Variable importance can also be computed on groups of variables. To display the results, several functions are available such as summary and plot functions. This paper aims to guide the user with a step-by-step example of the different functions for fitting random forests within DynForest.
Monte Carlo Sampling without Isoperimetry: A Reverse Diffusion Approach
Jul 05, 2023
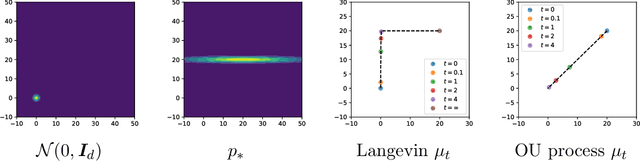

The efficacy of modern generative models is commonly contingent upon the precision of score estimation along the diffusion path, with a focus on diffusion models and their ability to generate high-quality data samples. This study delves into the potentialities of posterior sampling through reverse diffusion. An examination of the sampling literature reveals that score estimation can be transformed into a mean estimation problem via the decomposition of the transition kernel. By estimating the mean of the auxiliary distribution, the reverse diffusion process can give rise to a novel posterior sampling algorithm, which diverges from traditional gradient-based Markov Chain Monte Carlo (MCMC) methods. We provide the convergence analysis in total variation distance and demonstrate that the isoperimetric dependency of the proposed algorithm is comparatively lower than that observed in conventional MCMC techniques, which justifies the superior performance for high dimensional sampling with error tolerance. Our analytical framework offers fresh perspectives on the complexity of score estimation at various time points, as denoted by the properties of the auxiliary distribution.
$ν^2$-Flows: Fast and improved neutrino reconstruction in multi-neutrino final states with conditional normalizing flows
Jul 05, 2023In this work we introduce $\nu^2$-Flows, an extension of the $\nu$-Flows method to final states containing multiple neutrinos. The architecture can natively scale for all combinations of object types and multiplicities in the final state for any desired neutrino multiplicities. In $t\bar{t}$ dilepton events, the momenta of both neutrinos and correlations between them are reconstructed more accurately than when using the most popular standard analytical techniques, and solutions are found for all events. Inference time is significantly faster than competing methods, and can be reduced further by evaluating in parallel on graphics processing units. We apply $\nu^2$-Flows to $t\bar{t}$ dilepton events and show that the per-bin uncertainties in unfolded distributions is much closer to the limit of performance set by perfect neutrino reconstruction than standard techniques. For the chosen double differential observables $\nu^2$-Flows results in improved statistical precision for each bin by a factor of 1.5 to 2 in comparison to the Neutrino Weighting method and up to a factor of four in comparison to the Ellipse approach.
ScalOTA: Scalable Secure Over-the-Air Software Updates for Vehicles
Jul 05, 2023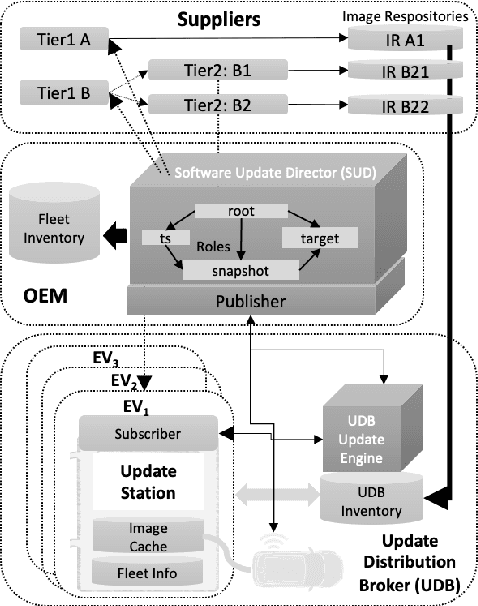
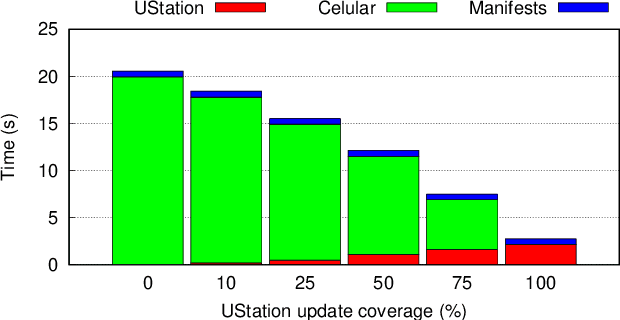
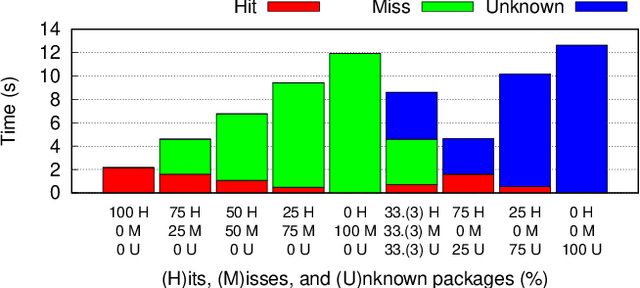
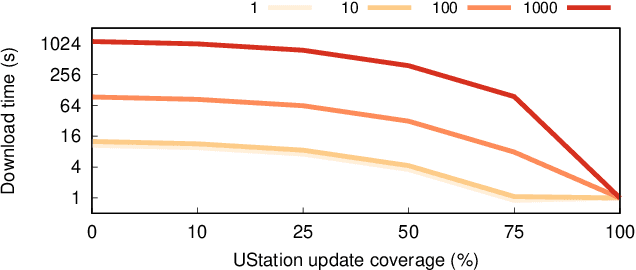
Over-the-Air (OTA) software updates are becoming essential for electric/electronic vehicle architectures in order to reduce recalls amid the increasing software bugs and vulnerabilities. Current OTA update architectures rely heavily on direct cellular repository-to-vehicle links, which makes the repository a communication bottleneck, and increases the cellular bandwidth utilization cost as well as the software download latency. In this paper, we introduce ScalOTA, an end-to-end scalable OTA software update architecture and secure protocol for modern vehicles. For the first time, we propose using a network of update stations, as part of Electric Vehicle charging stations, to boost the download speed through these stations, and reduce the cellular bandwidth overhead significantly. Our formalized OTA update protocol ensures proven end-to-end chain-of-trust including all stakeholders: manufacturer, suppliers, update stations, and all layers of in-vehicle Electric Control Units (ECUs). The empirical evaluation shows that ScalOTA reduces the bandwidth utilization and download latency up to an order of magnitude compared with current OTA update systems.
Physics-assisted Deep Learning for FMCW Radar Quantitative Imaging of Two-dimension Target
Jul 05, 2023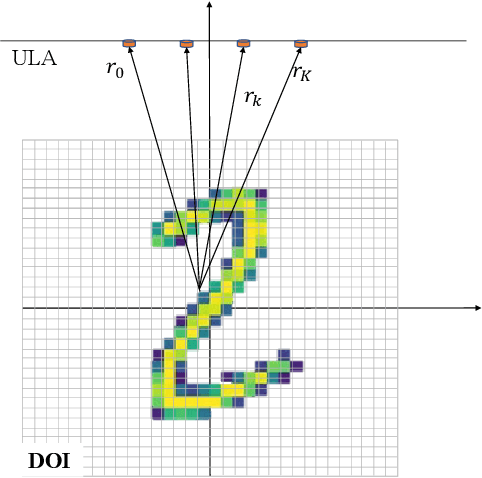
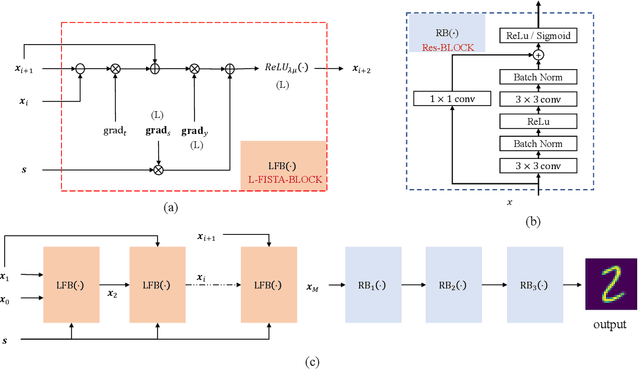


Radar imaging is crucial in remote sensing and has many applications in detection and autonomous driving. However, the received radar signal for imaging is enormous and redundant, which degrades the speed of real-time radar quantitative imaging and leads to obstacles in the downlink applications. In this paper, we propose a physics-assisted deep learning method for radar quantitative imaging with the advantage of compressed sensing (CS). Specifically, the signal model for frequency-modulated continuous-wave (FMCW) radar imaging which only uses four antennas and parts of frequency components is formulated in terms of matrices multiplication. The learned fast iterative shrinkage-thresholding algorithm with residual neural network (L-FISTA-ResNet) is proposed for solving the quantitative imaging problem. The L-FISTA is developed to ensure the basic solution and ResNet is attached to enhance the image quality. Simulation results show that our proposed method has higher reconstruction accuracy than the traditional optimization method and pure neural networks. The effectiveness and generalization performance of the proposed strategy is verified in unseen target imaging, denoising, and frequency migration tasks.