 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Model-Driven Engineering for Artificial Intelligence -- A Systematic Literature Review
Jul 10, 2023


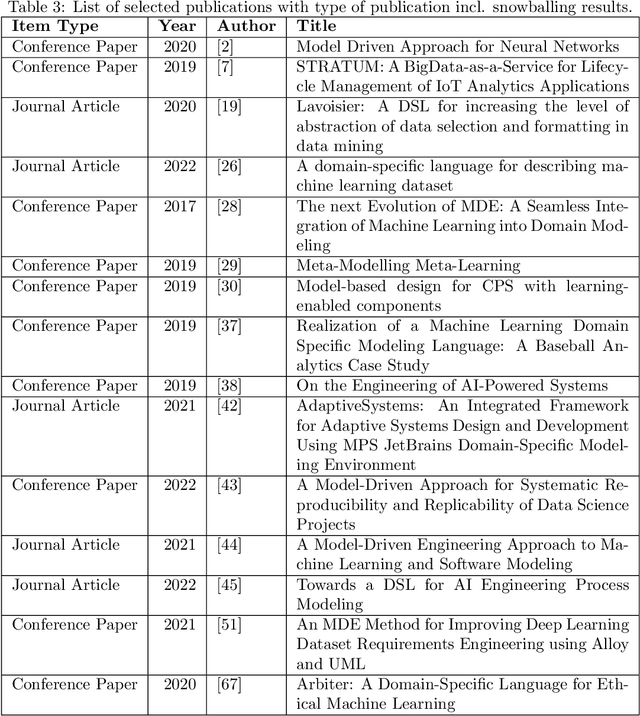
Objective: This study aims to investigate the existing body of knowledge in the field of Model-Driven Engineering MDE in support of AI (MDE4AI) to sharpen future research further and define the current state of the art. Method: We conducted a Systemic Literature Review (SLR), collecting papers from five major databases resulting in 703 candidate studies, eventually retaining 15 primary studies. Each primary study will be evaluated and discussed with respect to the adoption of (1) MDE principles and practices and (2) the phases of AI development support aligned with the stages of the CRISP-DM methodology. Results: The study's findings show that the pillar concepts of MDE (metamodel, concrete syntax and model transformation), are leveraged to define domain-specific languages (DSL) explicitly addressing AI concerns. Different MDE technologies are used, leveraging different language workbenches. The most prominent AI-related concerns are training and modeling of the AI algorithm, while minor emphasis is given to the time-consuming preparation of the data sets. Early project phases that support interdisciplinary communication of requirements, such as the CRISP-DM \textit{Business Understanding} phase, are rarely reflected. Conclusion: The study found that the use of MDE for AI is still in its early stages, and there is no single tool or method that is widely used. Additionally, current approaches tend to focus on specific stages of development rather than providing support for the entire development process. As a result, the study suggests several research directions to further improve the use of MDE for AI and to guide future research in this area.
Joint Communications and Sensing Hybrid Beamforming Design via Deep Unfolding
Jul 10, 2023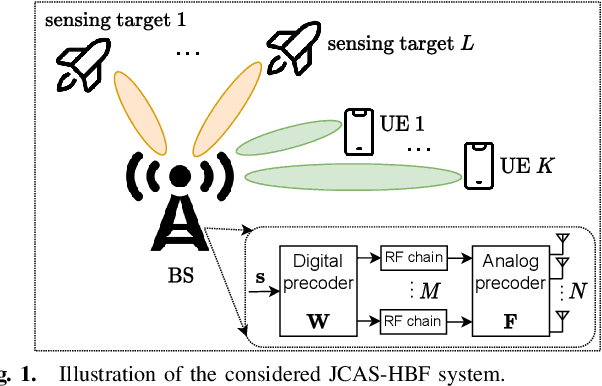
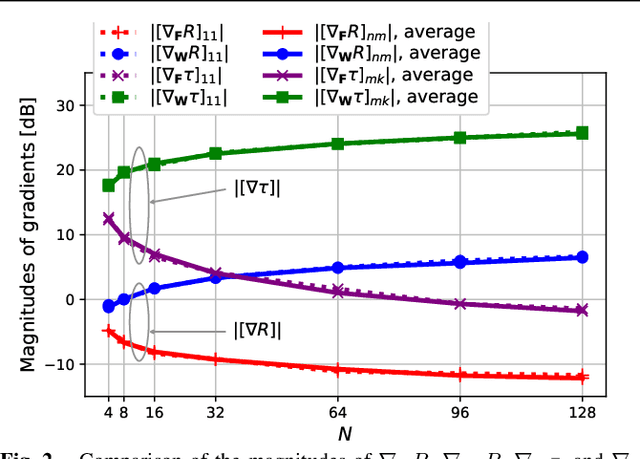
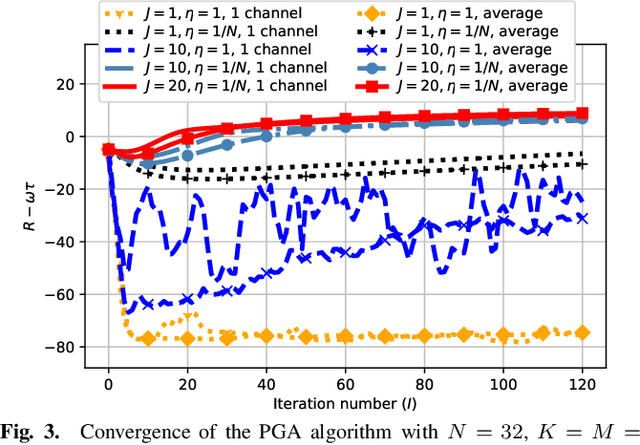
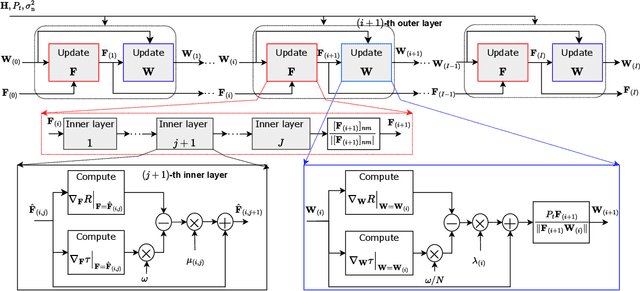
Joint communications and sensing (JCAS) is envisioned as a key feature in future wireless communications networks. In massive MIMO-JCAS systems, hybrid beamforming (HBF) is typically employed to achieve satisfactory beamforming gains with reasonable hardware cost and power consumption. Due to the coupling of the analog and digital precoders in HBF and the dual objective in JCAS, JCAS-HBF design problems are very challenging and usually require highly complex algorithms. In this paper, we propose a fast HBF design for JCAS based on deep unfolding to optimize a tradeoff between the communications rate and sensing accuracy. We first derive closed-form expressions for the gradients of the communications and sensing objectives with respect to the precoders and demonstrate that the magnitudes of the gradients pertaining to the analog precoder are typically smaller than those associated with the digital precoder. Based on this observation, we propose a modified projected gradient ascent (PGA) method with significantly improved convergence. We then develop a deep unfolded PGA scheme that efficiently optimizes the communications-sensing performance tradeoff with fast convergence thanks to the well-trained hyperparameters. In doing so, we preserve the interpretability and flexibility of the optimizer while leveraging data to improve performance. Finally, our simulations demonstrate the potential of the proposed deep unfolded method, which achieves up to 33.5% higher communications sum rate and 2.5 dB lower beampattern error compared with the conventional design based on successive convex approximation and Riemannian manifold optimization. Furthermore, it attains up to a 65% reduction in run time and computational complexity with respect to the PGA procedure without unfolding.
Weighted Siamese Network to Predict the Time to Onset of Alzheimer's Disease from MRI Images
Apr 14, 2023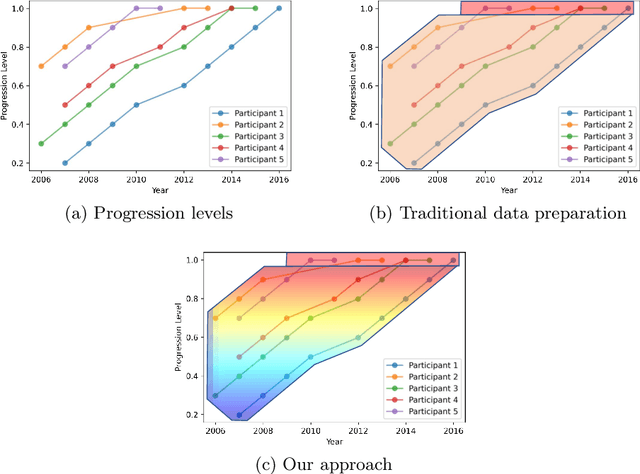

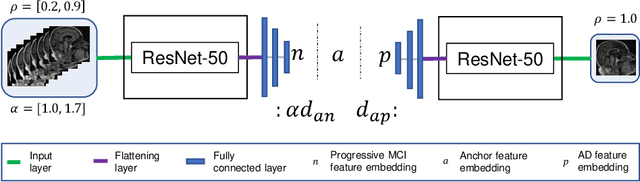

Alzheimer's Disease (AD), which is the most common cause of dementia, is a progressive disease preceded by Mild Cognitive Impairment (MCI). Early detection of the disease is crucial for making treatment decisions. However, most of the literature on computer-assisted detection of AD focuses on classifying brain images into one of three major categories: healthy, MCI, and AD; or categorising MCI patients into one of (1) progressive: those who progress from MCI to AD at a future examination time during a given study period, and (2) stable: those who stay as MCI and never progress to AD. This misses the opportunity to accurately identify the trajectory of progressive MCI patients. In this paper, we revisit the brain image classification task for AD identification and re-frame it as an ordinal classification task to predict how close a patient is to the severe AD stage. To this end, we select progressive MCI patients from the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset and construct an ordinal dataset with a prediction target that indicates the time to progression to AD. We train a siamese network model to predict the time to onset of AD based on MRI brain images. We also propose a weighted variety of siamese networks and compare its performance to a baseline model. Our evaluations show that incorporating a weighting factor to siamese networks brings considerable performance gain at predicting how close input brain MRI images are to progressing to AD.
Monolingual and Cross-Lingual Knowledge Transfer for Topic Classification
Jul 04, 2023This article investigates the knowledge transfer from the RuQTopics dataset. This Russian topical dataset combines a large sample number (361,560 single-label, 170,930 multi-label) with extensive class coverage (76 classes). We have prepared this dataset from the "Yandex Que" raw data. By evaluating the RuQTopics - trained models on the six matching classes of the Russian MASSIVE subset, we have proved that the RuQTopics dataset is suitable for real-world conversational tasks, as the Russian-only models trained on this dataset consistently yield an accuracy around 85\% on this subset. We also have figured out that for the multilingual BERT, trained on the RuQTopics and evaluated on the same six classes of MASSIVE (for all MASSIVE languages), the language-wise accuracy closely correlates (Spearman correlation 0.773 with p-value 2.997e-11) with the approximate size of the pretraining BERT's data for the corresponding language. At the same time, the correlation of the language-wise accuracy with the linguistical distance from Russian is not statistically significant.
Learning ECG signal features without backpropagation
Jul 04, 2023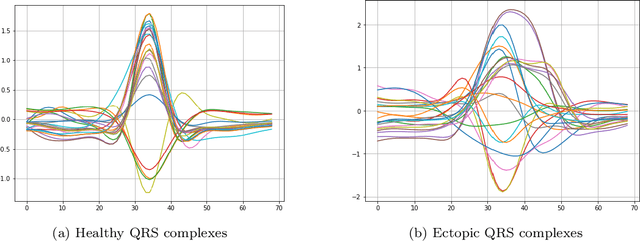
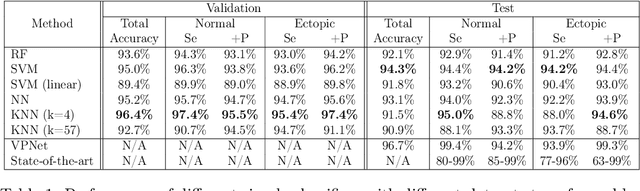
Representation learning has become a crucial area of research in machine learning, as it aims to discover efficient ways of representing raw data with useful features to increase the effectiveness, scope and applicability of downstream tasks such as classification and prediction. In this paper, we propose a novel method to generate representations for time series-type data. This method relies on ideas from theoretical physics to construct a compact representation in a data-driven way, and it can capture both the underlying structure of the data and task-specific information while still remaining intuitive, interpretable and verifiable. This novel methodology aims to identify linear laws that can effectively capture a shared characteristic among samples belonging to a specific class. By subsequently utilizing these laws to generate a classifier-agnostic representation in a forward manner, they become applicable in a generalized setting. We demonstrate the effectiveness of our approach on the task of ECG signal classification, achieving state-of-the-art performance.
Learning Discrete Weights and Activations Using the Local Reparameterization Trick
Jul 04, 2023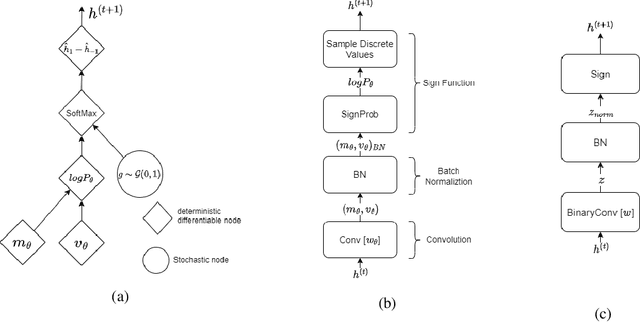
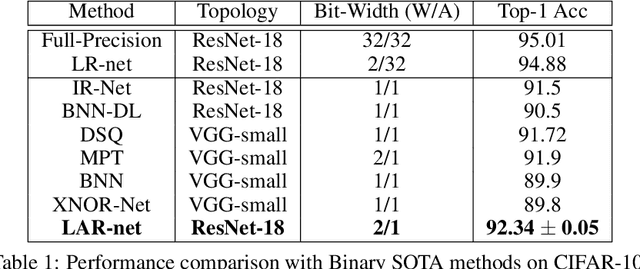
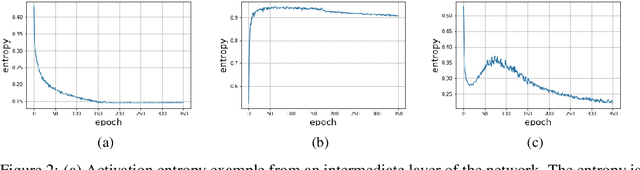
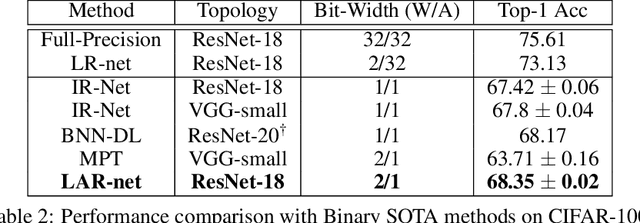
In computer vision and machine learning, a crucial challenge is to lower the computation and memory demands for neural network inference. A commonplace solution to address this challenge is through the use of binarization. By binarizing the network weights and activations, one can significantly reduce computational complexity by substituting the computationally expensive floating operations with faster bitwise operations. This leads to a more efficient neural network inference that can be deployed on low-resource devices. In this work, we extend previous approaches that trained networks with discrete weights using the local reparameterization trick to also allow for discrete activations. The original approach optimized a distribution over the discrete weights and uses the central limit theorem to approximate the pre-activation with a continuous Gaussian distribution. Here we show that the probabilistic modeling can also allow effective training of networks with discrete activation as well. This further reduces runtime and memory footprint at inference time with state-of-the-art results for networks with binary activations.
Evaluation and Optimization of Rendering Techniques for Autonomous Driving Simulation
Jun 27, 2023
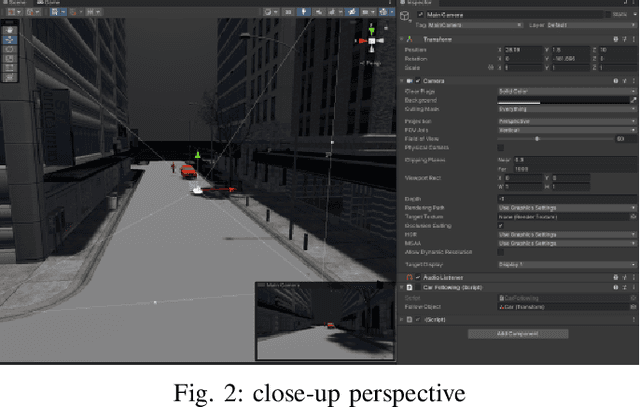
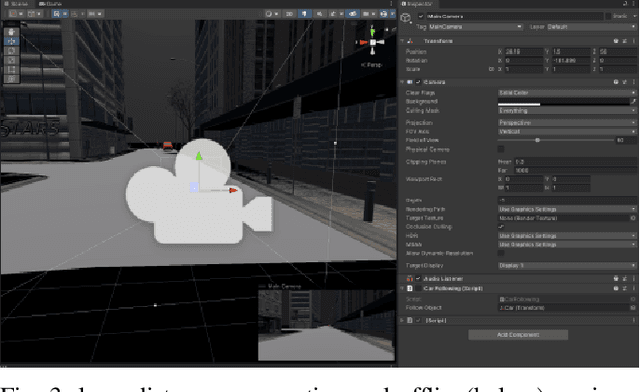

In order to meet the demand for higher scene rendering quality from some autonomous driving teams (such as those focused on CV), we have decided to use an offline simulation industrial rendering framework instead of real-time rendering in our autonomous driving simulator. Our plan is to generate lower-quality scenes using a game engine, extract them, and then use an IQA algorithm to validate the improvement in scene quality achieved through offline rendering. The improved scenes will then be used for training.
Effects of data time lag in a decision-making system using machine learning for pork price prediction
May 09, 2023Spain is the third-largest producer of pork meat in the world, and many farms in several regions depend on the evolution of this market. However, the current pricing system is unfair, as some actors have better market information than others. In this context, historical pricing is an easy-to-find and affordable data source that can help all agents to be better informed. However, the time lag in data acquisition can affect their pricing decisions. In this paper, we study the effect that data acquisition delay has on a price prediction system using multiple prediction algorithms. We describe the integration of the best proposal into a decision support system prototype and test it in a real-case scenario. Specifically, we use public data from the most important regional pork meat markets in Spain published by the Ministry of Agriculture with a two-week delay and subscription-based data of the same markets obtained on the same day. The results show that the error difference between the best public and data subscription models is 0.6 Euro cents in favor of the data without delay. The market dimension makes these differences significant in the supply chain, giving pricing agents a better tool to negotiate market prices.
You Only Segment Once: Towards Real-Time Panoptic Segmentation
Mar 26, 2023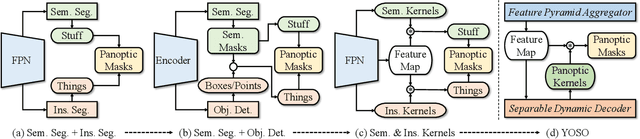
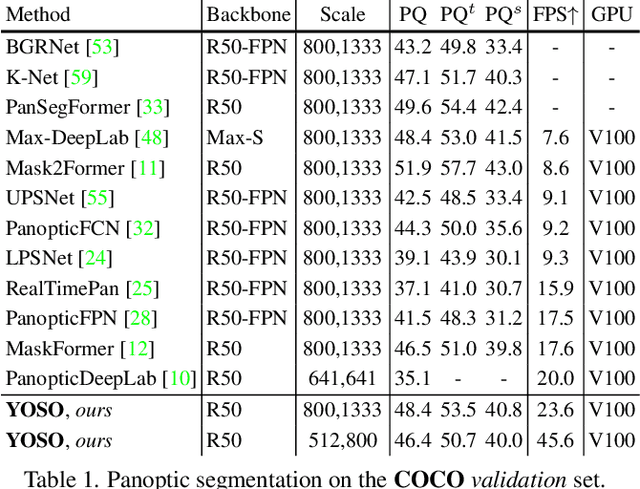
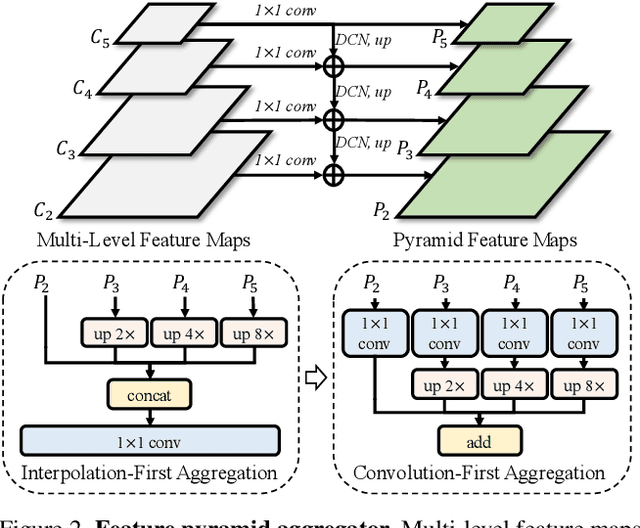
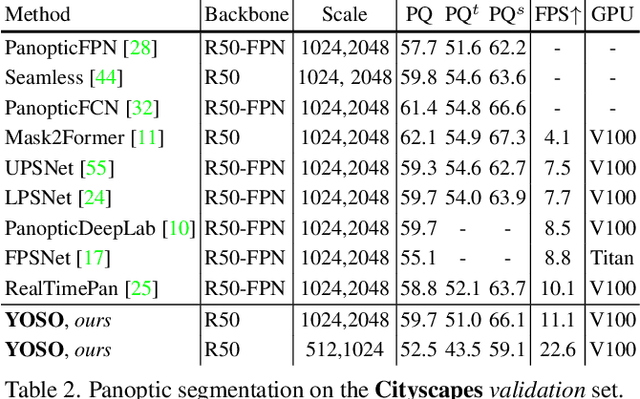
In this paper, we propose YOSO, a real-time panoptic segmentation framework. YOSO predicts masks via dynamic convolutions between panoptic kernels and image feature maps, in which you only need to segment once for both instance and semantic segmentation tasks. To reduce the computational overhead, we design a feature pyramid aggregator for the feature map extraction, and a separable dynamic decoder for the panoptic kernel generation. The aggregator re-parameterizes interpolation-first modules in a convolution-first way, which significantly speeds up the pipeline without any additional costs. The decoder performs multi-head cross-attention via separable dynamic convolution for better efficiency and accuracy. To the best of our knowledge, YOSO is the first real-time panoptic segmentation framework that delivers competitive performance compared to state-of-the-art models. Specifically, YOSO achieves 46.4 PQ, 45.6 FPS on COCO; 52.5 PQ, 22.6 FPS on Cityscapes; 38.0 PQ, 35.4 FPS on ADE20K; and 34.1 PQ, 7.1 FPS on Mapillary Vistas. Code is available at https://github.com/hujiecpp/YOSO.
Explainable AI for Time Series via Virtual Inspection Layers
Mar 11, 2023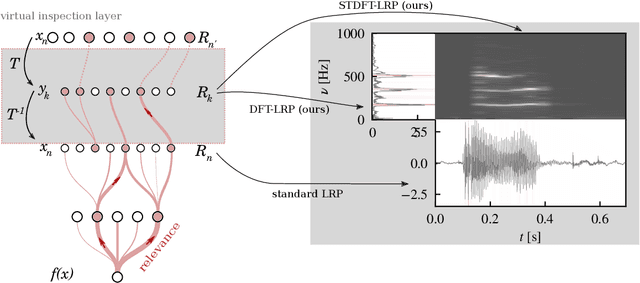
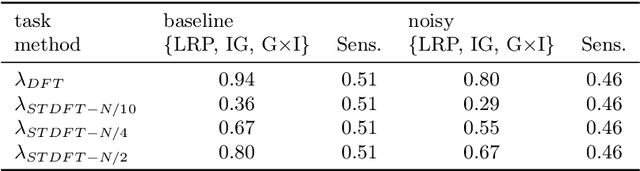
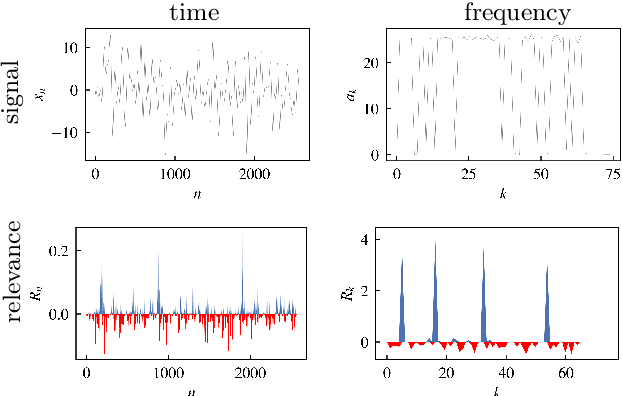
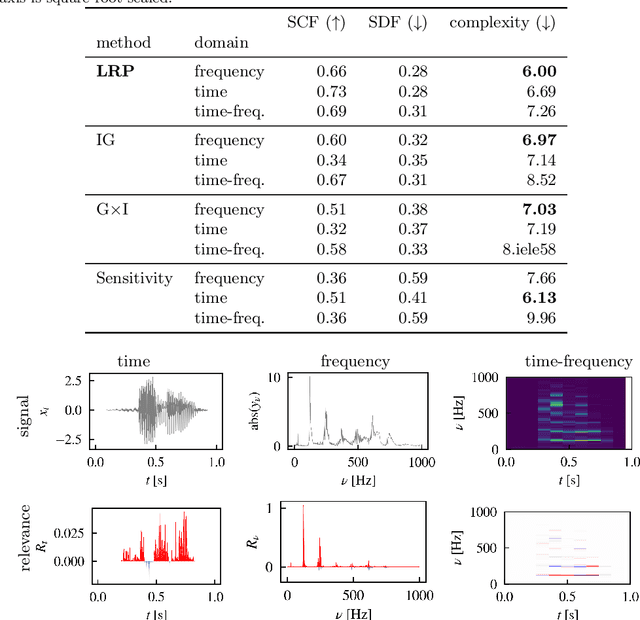
The field of eXplainable Artificial Intelligence (XAI) has greatly advanced in recent years, but progress has mainly been made in computer vision and natural language processing. For time series, where the input is often not interpretable, only limited research on XAI is available. In this work, we put forward a virtual inspection layer, that transforms the time series to an interpretable representation and allows to propagate relevance attributions to this representation via local XAI methods like layer-wise relevance propagation (LRP). In this way, we extend the applicability of a family of XAI methods to domains (e.g. speech) where the input is only interpretable after a transformation. Here, we focus on the Fourier transformation which is prominently applied in the interpretation of time series and LRP and refer to our method as DFT-LRP. We demonstrate the usefulness of DFT-LRP in various time series classification settings like audio and electronic health records. We showcase how DFT-LRP reveals differences in the classification strategies of models trained in different domains (e.g., time vs. frequency domain) or helps to discover how models act on spurious correlations in the data.