 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Dynamic-Resolution Model Learning for Object Pile Manipulation
Jun 30, 2023
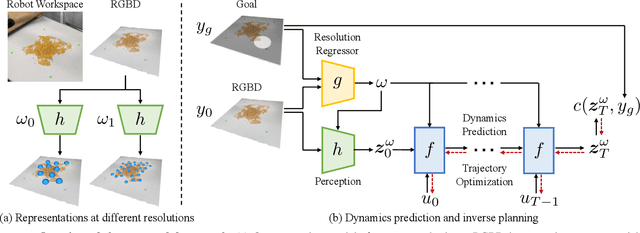

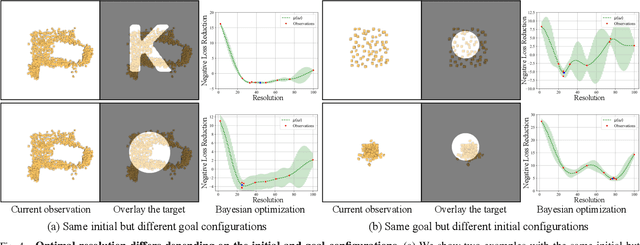
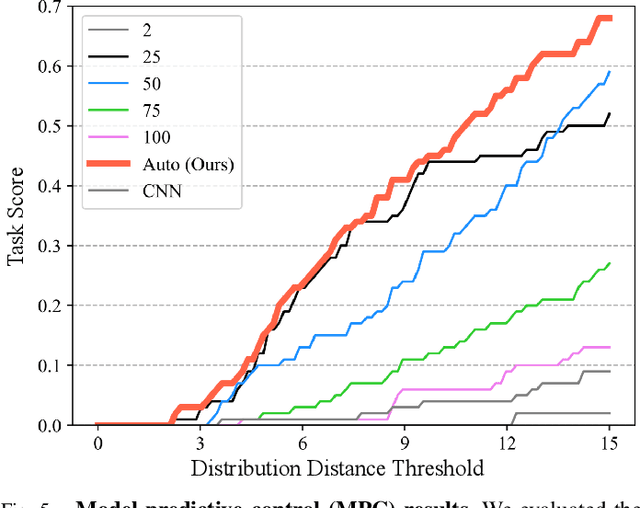
Dynamics models learned from visual observations have shown to be effective in various robotic manipulation tasks. One of the key questions for learning such dynamics models is what scene representation to use. Prior works typically assume representation at a fixed dimension or resolution, which may be inefficient for simple tasks and ineffective for more complicated tasks. In this work, we investigate how to learn dynamic and adaptive representations at different levels of abstraction to achieve the optimal trade-off between efficiency and effectiveness. Specifically, we construct dynamic-resolution particle representations of the environment and learn a unified dynamics model using graph neural networks (GNNs) that allows continuous selection of the abstraction level. During test time, the agent can adaptively determine the optimal resolution at each model-predictive control (MPC) step. We evaluate our method in object pile manipulation, a task we commonly encounter in cooking, agriculture, manufacturing, and pharmaceutical applications. Through comprehensive evaluations both in the simulation and the real world, we show that our method achieves significantly better performance than state-of-the-art fixed-resolution baselines at the gathering, sorting, and redistribution of granular object piles made with various instances like coffee beans, almonds, corn, etc.
Self-Adjusting Weighted Expected Improvement for Bayesian Optimization
Jun 30, 2023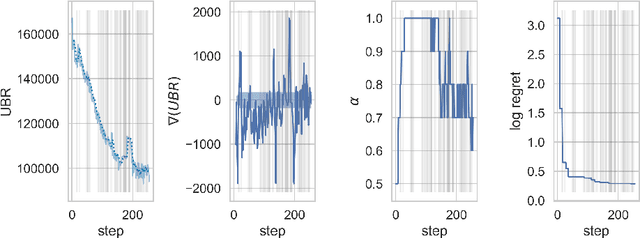
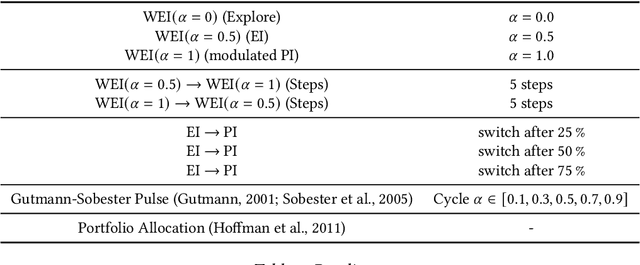
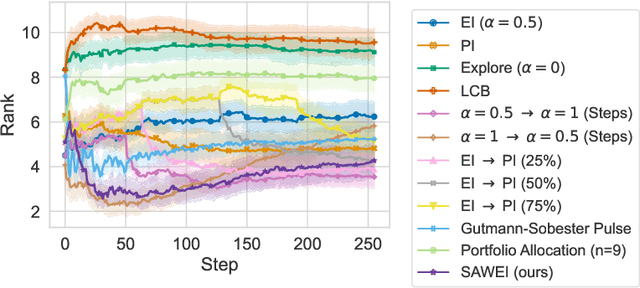
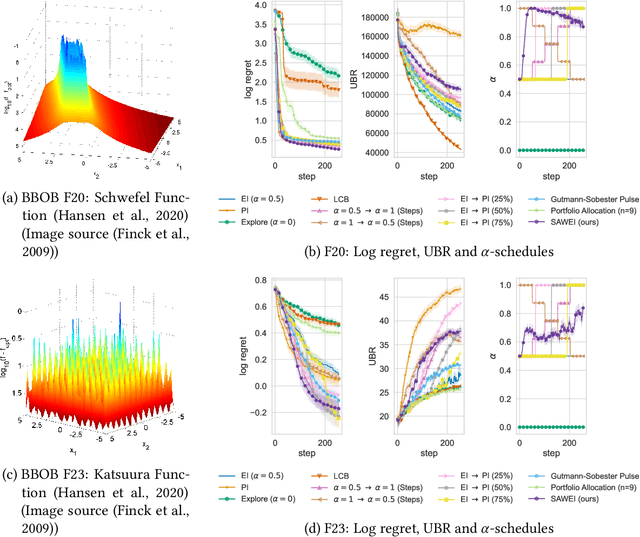
Bayesian Optimization (BO) is a class of surrogate-based, sample-efficient algorithms for optimizing black-box problems with small evaluation budgets. The BO pipeline itself is highly configurable with many different design choices regarding the initial design, surrogate model, and acquisition function (AF). Unfortunately, our understanding of how to select suitable components for a problem at hand is very limited. In this work, we focus on the definition of the AF, whose main purpose is to balance the trade-off between exploring regions with high uncertainty and those with high promise for good solutions. We propose Self-Adjusting Weighted Expected Improvement (SAWEI), where we let the exploration-exploitation trade-off self-adjust in a data-driven manner, based on a convergence criterion for BO. On the noise-free black-box BBOB functions of the COCO benchmarking platform, our method exhibits a favorable any-time performance compared to handcrafted baselines and serves as a robust default choice for any problem structure. The suitability of our method also transfers to HPOBench. With SAWEI, we are a step closer to on-the-fly, data-driven, and robust BO designs that automatically adjust their sampling behavior to the problem at hand.
RObotic MAnipulation Network (ROMAN) -- Hybrid Hierarchical Learning for Solving Complex Sequential Tasks
Jun 30, 2023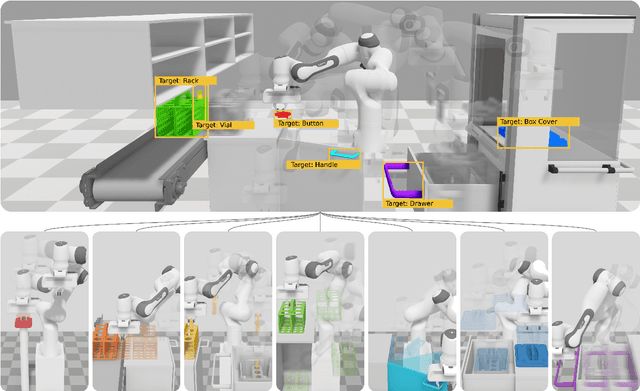
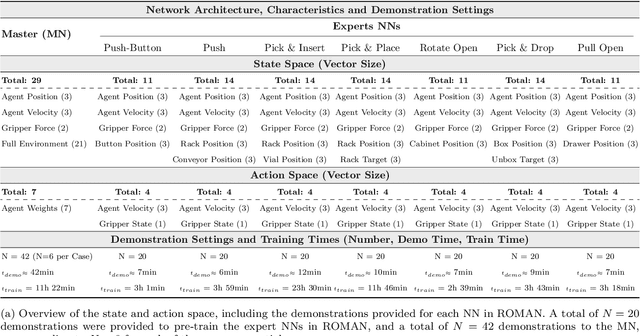
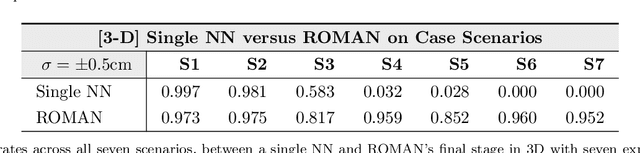
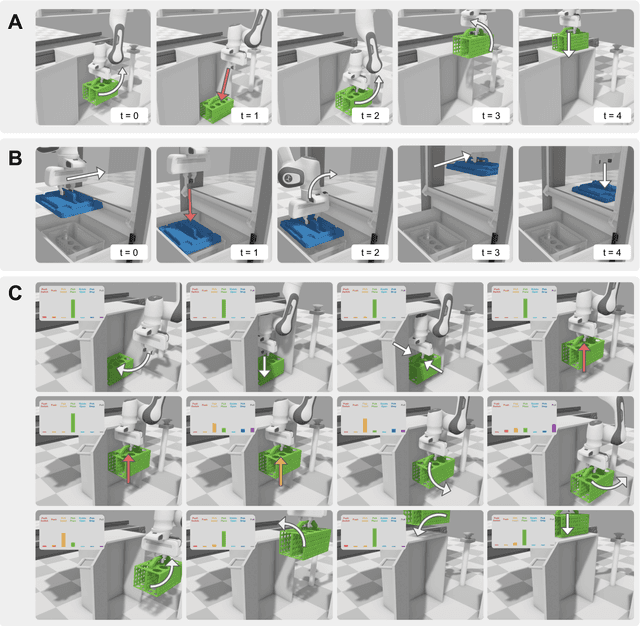
Solving long sequential tasks poses a significant challenge in embodied artificial intelligence. Enabling a robotic system to perform diverse sequential tasks with a broad range of manipulation skills is an active area of research. In this work, we present a Hybrid Hierarchical Learning framework, the Robotic Manipulation Network (ROMAN), to address the challenge of solving multiple complex tasks over long time horizons in robotic manipulation. ROMAN achieves task versatility and robust failure recovery by integrating behavioural cloning, imitation learning, and reinforcement learning. It consists of a central manipulation network that coordinates an ensemble of various neural networks, each specialising in distinct re-combinable sub-tasks to generate their correct in-sequence actions for solving complex long-horizon manipulation tasks. Experimental results show that by orchestrating and activating these specialised manipulation experts, ROMAN generates correct sequential activations for accomplishing long sequences of sophisticated manipulation tasks and achieving adaptive behaviours beyond demonstrations, while exhibiting robustness to various sensory noises. These results demonstrate the significance and versatility of ROMAN's dynamic adaptability featuring autonomous failure recovery capabilities, and highlight its potential for various autonomous manipulation tasks that demand adaptive motor skills.
Training-free Object Counting with Prompts
Jun 30, 2023
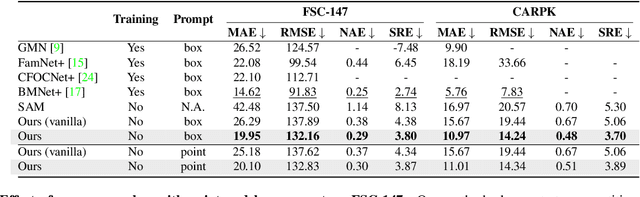

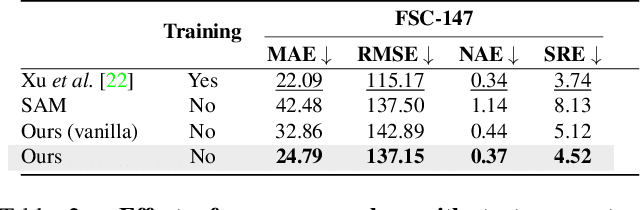
This paper tackles the problem of object counting in images. Existing approaches rely on extensive training data with point annotations for each object, making data collection labor-intensive and time-consuming. To overcome this, we propose a training-free object counter that treats the counting task as a segmentation problem. Our approach leverages the Segment Anything Model (SAM), known for its high-quality masks and zero-shot segmentation capability. However, the vanilla mask generation method of SAM lacks class-specific information in the masks, resulting in inferior counting accuracy. To overcome this limitation, we introduce a prior-guided mask generation method that incorporates three types of priors into the segmentation process, enhancing efficiency and accuracy. Additionally, we tackle the issue of counting objects specified through free-form text by proposing a two-stage approach that combines reference object selection and prior-guided mask generation. Extensive experiments on standard datasets demonstrate the competitive performance of our training-free counter compared to learning-based approaches. This paper presents a promising solution for counting objects in various scenarios without the need for extensive data collection and model training. Code is available at https://github.com/shizenglin/training-free-object-counter.
Differential Privacy May Have a Potential Optimization Effect on Some Swarm Intelligence Algorithms besides Privacy-preserving
Jun 30, 2023
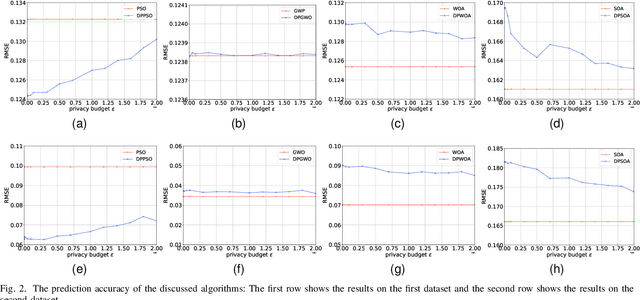
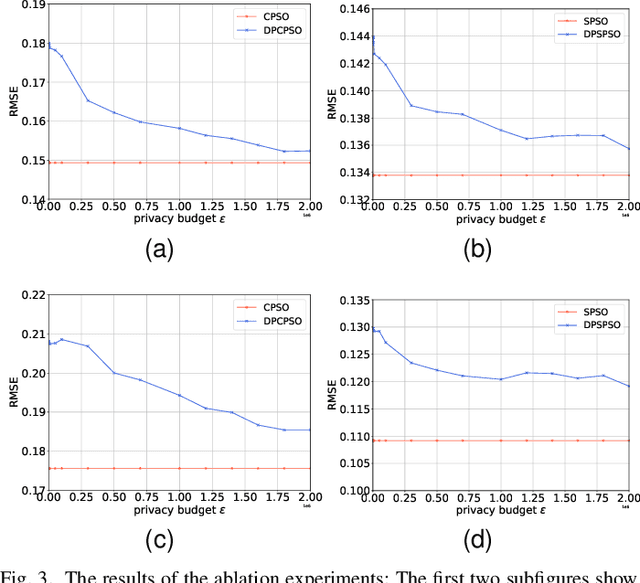
Differential privacy (DP), as a promising privacy-preserving model, has attracted great interest from researchers in recent years. Currently, the study on combination of machine learning and DP is vibrant. In contrast, another widely used artificial intelligence technique, the swarm intelligence (SI) algorithm, has received little attention in the context of DP even though it also triggers privacy concerns. For this reason, this paper attempts to combine DP and SI for the first time, and proposes a general differentially private swarm intelligence algorithm framework (DPSIAF). Based on the exponential mechanism, this framework can easily develop existing SI algorithms into the private versions. As examples, we apply the proposed DPSIAF to four popular SI algorithms, and corresponding analyses demonstrate its effectiveness. More interestingly, the experimental results show that, for our private algorithms, their performance is not strictly affected by the privacy budget, and one of the private algorithms even owns better performance than its non-private version in some cases. These findings are different from the conventional cognition, which indicates the uniqueness of SI with DP. Our study may provide a new perspective on DP, and promote the synergy between metaheuristic optimization community and privacy computing community.
Multigrid-Augmented Deep Learning for the Helmholtz Equation: Better Scalability with Compact Implicit Layers
Jun 30, 2023We present a deep learning-based iterative approach to solve the discrete heterogeneous Helmholtz equation for high wavenumbers. Combining classical iterative multigrid solvers and convolutional neural networks (CNNs) via preconditioning, we obtain a learned neural solver that is faster and scales better than a standard multigrid solver. Our approach offers three main contributions over previous neural methods of this kind. First, we construct a multilevel U-Net-like encoder-solver CNN with an implicit layer on the coarsest grid of the U-Net, where convolution kernels are inverted. This alleviates the field of view problem in CNNs and allows better scalability. Second, we improve upon the previous CNN preconditioner in terms of the number of parameters, computation time, and convergence rates. Third, we propose a multiscale training approach that enables the network to scale to problems of previously unseen dimensions while still maintaining a reasonable training procedure. Our encoder-solver architecture can be used to generalize over different slowness models of various difficulties and is efficient at solving for many right-hand sides per slowness model. We demonstrate the benefits of our novel architecture with numerical experiments on a variety of heterogeneous two-dimensional problems at high wavenumbers.
Qualitative Prediction of Multi-Agent Spatial Interactions
Jun 30, 2023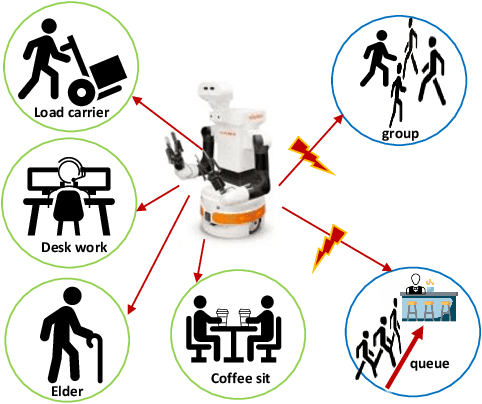
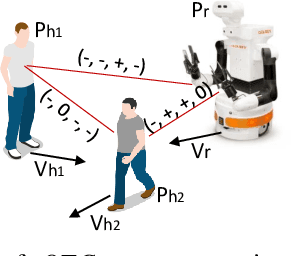
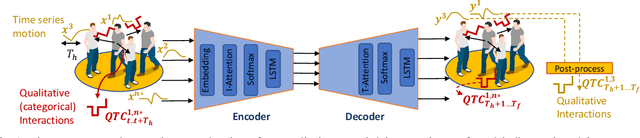

Deploying service robots in our daily life, whether in restaurants, warehouses or hospitals, calls for the need to reason on the interactions happening in dense and dynamic scenes. In this paper, we present and benchmark three new approaches to model and predict multi-agent interactions in dense scenes, including the use of an intuitive qualitative representation. The proposed solutions take into account static and dynamic context to predict individual interactions. They exploit an input- and a temporal-attention mechanism, and are tested on medium and long-term time horizons. The first two approaches integrate different relations from the so-called Qualitative Trajectory Calculus (QTC) within a state-of-the-art deep neural network to create a symbol-driven neural architecture for predicting spatial interactions. The third approach implements a purely data-driven network for motion prediction, the output of which is post-processed to predict QTC spatial interactions. Experimental results on a popular robot dataset of challenging crowded scenarios show that the purely data-driven prediction approach generally outperforms the other two. The three approaches were further evaluated on a different but related human scenarios to assess their generalisation capability.
Large Language Models (GPT) for automating feedback on programming assignments
Jun 30, 2023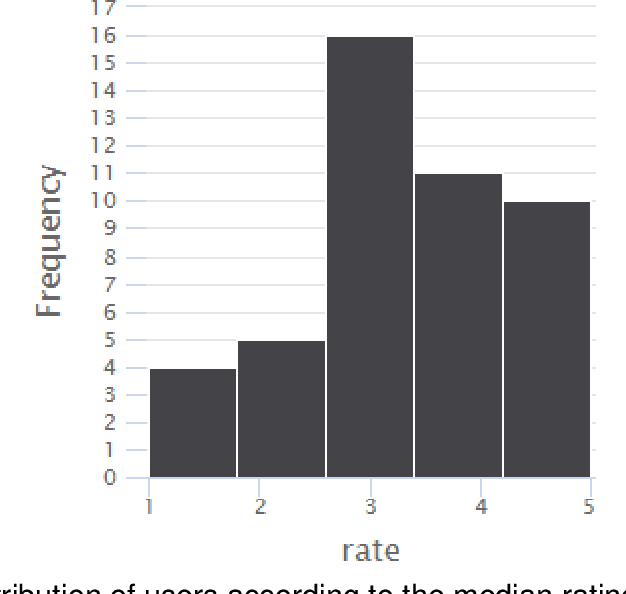
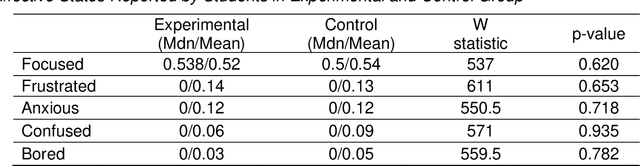
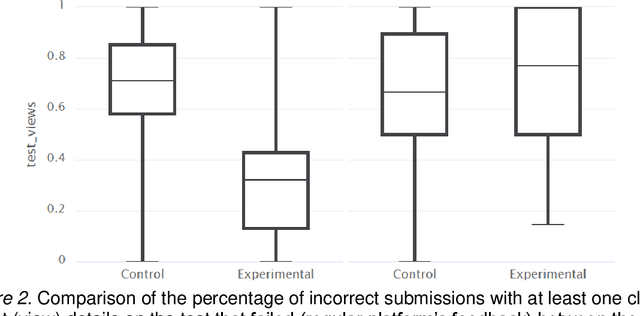
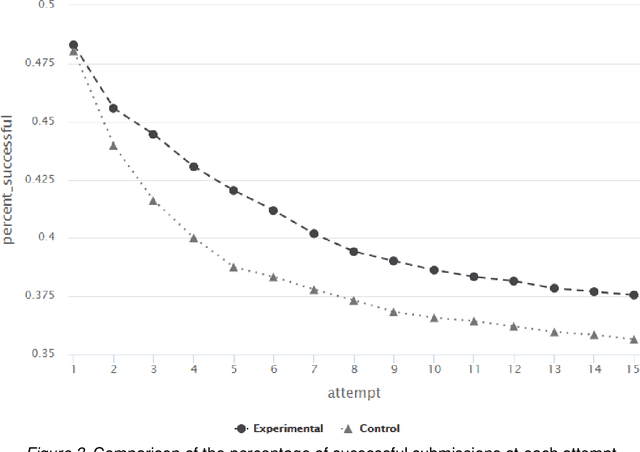
Addressing the challenge of generating personalized feedback for programming assignments is demanding due to several factors, like the complexity of code syntax or different ways to correctly solve a task. In this experimental study, we automated the process of feedback generation by employing OpenAI's GPT-3.5 model to generate personalized hints for students solving programming assignments on an automated assessment platform. Students rated the usefulness of GPT-generated hints positively. The experimental group (with GPT hints enabled) relied less on the platform's regular feedback but performed better in terms of percentage of successful submissions across consecutive attempts for tasks, where GPT hints were enabled. For tasks where the GPT feedback was made unavailable, the experimental group needed significantly less time to solve assignments. Furthermore, when GPT hints were unavailable, students in the experimental condition were initially less likely to solve the assignment correctly. This suggests potential over-reliance on GPT-generated feedback. However, students in the experimental condition were able to correct reasonably rapidly, reaching the same percentage correct after seven submission attempts. The availability of GPT hints did not significantly impact students' affective state.
Unsupervised speech intelligibility assessment with utterance level alignment distance between teacher and learner Wav2Vec-2.0 representations
Jun 15, 2023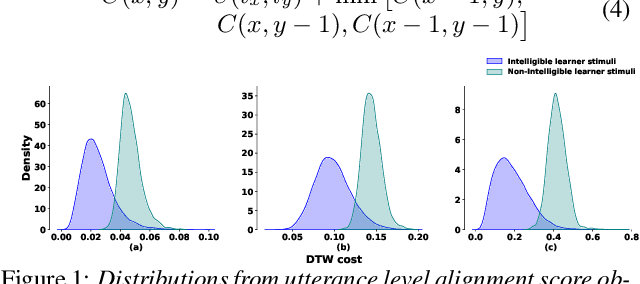
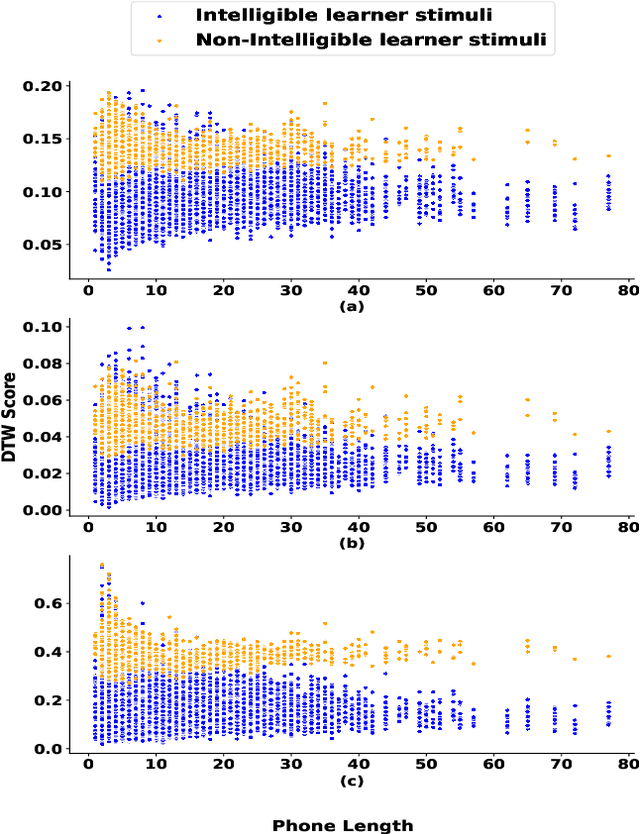
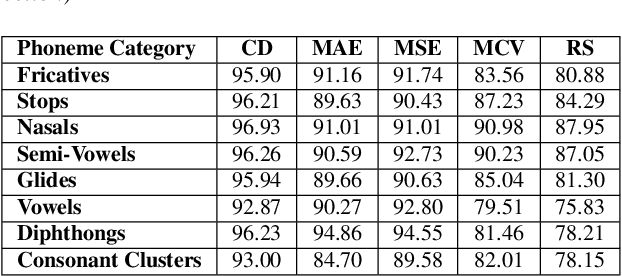
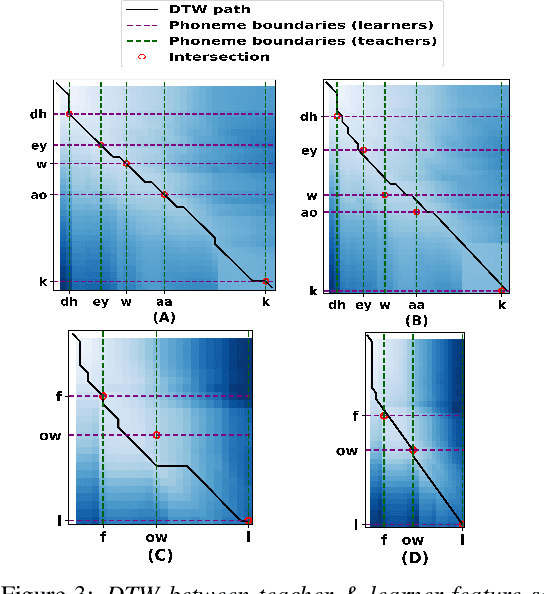
Speech intelligibility is crucial in language learning for effective communication. Thus, to develop computer-assisted language learning systems, automatic speech intelligibility detection (SID) is necessary. Most of the works have assessed the intelligibility in a supervised manner considering manual annotations, which requires cost and time; hence scalability is limited. To overcome these, this work proposes an unsupervised approach for SID. The proposed approach considers alignment distance computed with dynamic-time warping (DTW) between teacher and learner representation sequence as a measure to separate intelligible versus non-intelligible speech. We obtain the feature sequence using current state-of-the-art self-supervised representations from Wav2Vec-2.0. We found the detection accuracies as 90.37\%, 92.57\% and 96.58\%, respectively, with three alignment distance measures -- mean absolute error, mean squared error and cosine distance (equal to one minus cosine similarity).
GraMMaR: Ground-aware Motion Model for 3D Human Motion Reconstruction
Jul 01, 2023
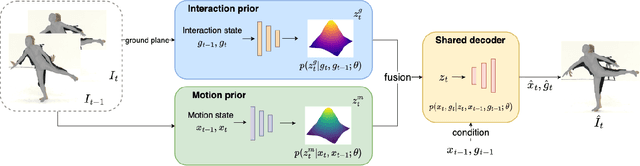
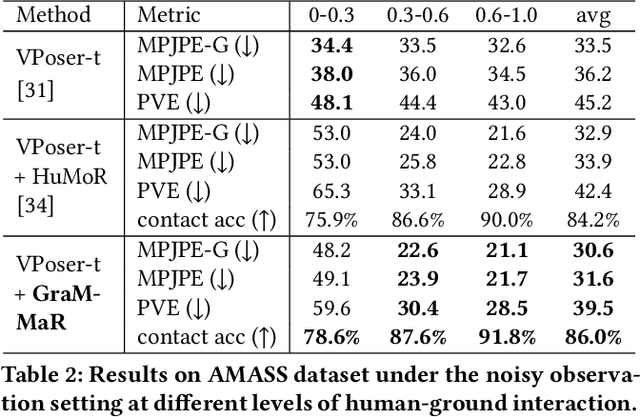
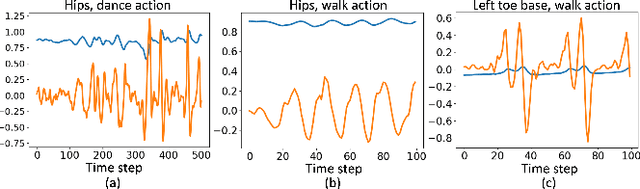
Demystifying complex human-ground interactions is essential for accurate and realistic 3D human motion reconstruction from RGB videos, as it ensures consistency between the humans and the ground plane. Prior methods have modeled human-ground interactions either implicitly or in a sparse manner, often resulting in unrealistic and incorrect motions when faced with noise and uncertainty. In contrast, our approach explicitly represents these interactions in a dense and continuous manner. To this end, we propose a novel Ground-aware Motion Model for 3D Human Motion Reconstruction, named GraMMaR, which jointly learns the distribution of transitions in both pose and interaction between every joint and ground plane at each time step of a motion sequence. It is trained to explicitly promote consistency between the motion and distance change towards the ground. After training, we establish a joint optimization strategy that utilizes GraMMaR as a dual-prior, regularizing the optimization towards the space of plausible ground-aware motions. This leads to realistic and coherent motion reconstruction, irrespective of the assumed or learned ground plane. Through extensive evaluation on the AMASS and AIST++ datasets, our model demonstrates good generalization and discriminating abilities in challenging cases including complex and ambiguous human-ground interactions. The code will be released.