 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MAE-DFER: Efficient Masked Autoencoder for Self-supervised Dynamic Facial Expression Recognition
Jul 05, 2023
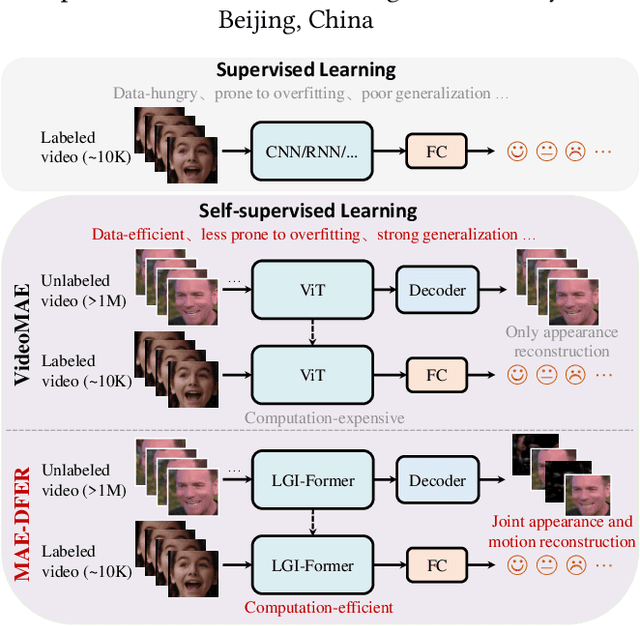
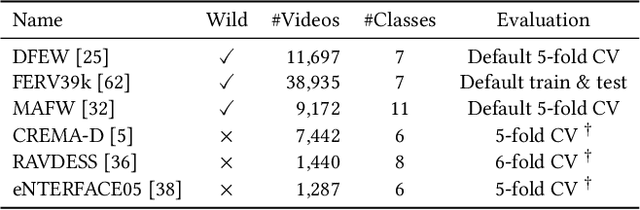
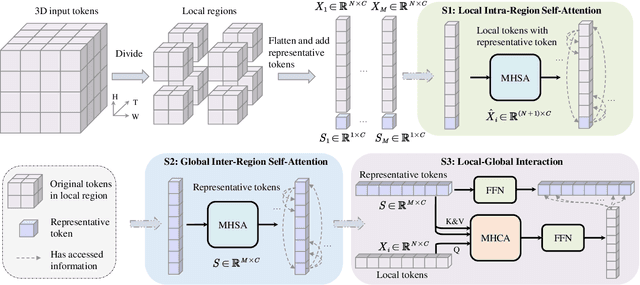
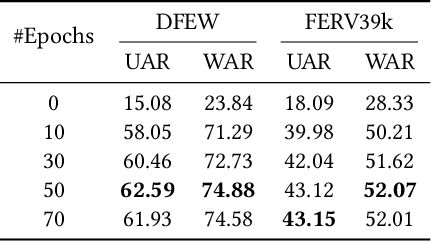
Dynamic facial expression recognition (DFER) is essential to the development of intelligent and empathetic machines. Prior efforts in this field mainly fall into supervised learning paradigm, which is restricted by the limited labeled data in existing datasets. Inspired by recent unprecedented success of masked autoencoders (e.g., VideoMAE), this paper proposes MAE-DFER, a novel self-supervised method which leverages large-scale self-supervised pre-training on abundant unlabeled data to advance the development of DFER. Since the vanilla Vision Transformer (ViT) employed in VideoMAE requires substantial computation during fine-tuning, MAE-DFER develops an efficient local-global interaction Transformer (LGI-Former) as the encoder. LGI-Former first constrains self-attention in local spatiotemporal regions and then utilizes a small set of learnable representative tokens to achieve efficient local-global information exchange, thus avoiding the expensive computation of global space-time self-attention in ViT. Moreover, in addition to the standalone appearance content reconstruction in VideoMAE, MAE-DFER also introduces explicit facial motion modeling to encourage LGI-Former to excavate both static appearance and dynamic motion information. Extensive experiments on six datasets show that MAE-DFER consistently outperforms state-of-the-art supervised methods by significant margins, verifying that it can learn powerful dynamic facial representations via large-scale self-supervised pre-training. Besides, it has comparable or even better performance than VideoMAE, while largely reducing the computational cost (about 38\% FLOPs). We believe MAE-DFER has paved a new way for the advancement of DFER and can inspire more relavant research in this field and even other related tasks. Codes and models are publicly available at https://github.com/sunlicai/MAE-DFER.
Surge Routing: Event-informed Multiagent Reinforcement Learning for Autonomous Rideshare
Jul 05, 2023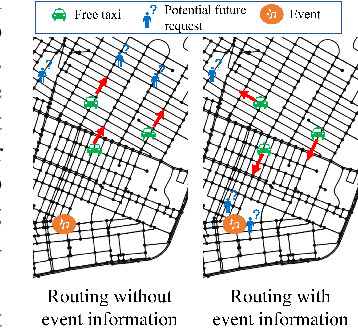

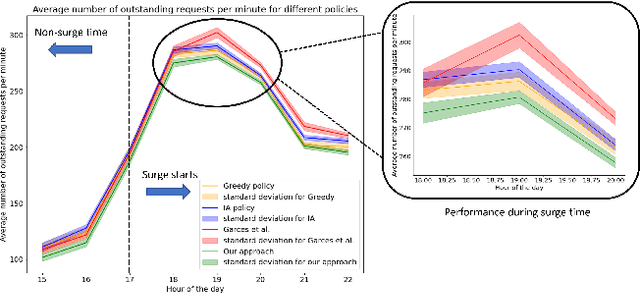
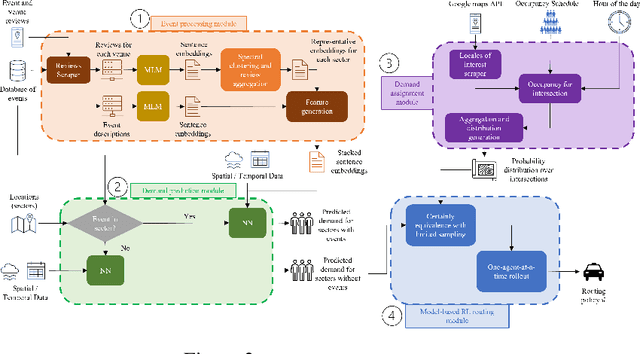
Large events such as conferences, concerts and sports games, often cause surges in demand for ride services that are not captured in average demand patterns, posing unique challenges for routing algorithms. We propose a learning framework for an autonomous fleet of taxis that scrapes event data from the internet to predict and adapt to surges in demand and generates cooperative routing and pickup policies that service a higher number of requests than other routing protocols. We achieve this through a combination of (i) an event processing framework that scrapes the internet for event information and generates dense vector representations that can be used as input features for a neural network that predicts demand; (ii) a two neural network system that predicts hourly demand over the entire map, using these dense vector representations; (iii) a probabilistic approach that leverages locale occupancy schedules to map publicly available demand data over sectors to discretized street intersections; and finally, (iv) a scalable model-based reinforcement learning framework that uses the predicted demand over intersections to anticipate surges and route taxis using one-agent-at-a-time rollout with limited sampling certainty equivalence. We learn routing and pickup policies using real NYC ride share data for 2022 and information for more than 2000 events across 300 unique venues in Manhattan. We test our approach with a fleet of 100 taxis on a map with 38 different sectors (2235 street intersections). Our experimental results demonstrate that our method obtains routing policies that service $6$ more requests on average per minute (around $360$ more requests per hour) than other model-based RL frameworks and other classical algorithms in operations research when dealing with surge demand conditions.
Real-Time Semantic Segmentation using Hyperspectral Images for Mapping Unstructured and Unknown Environments
Mar 27, 2023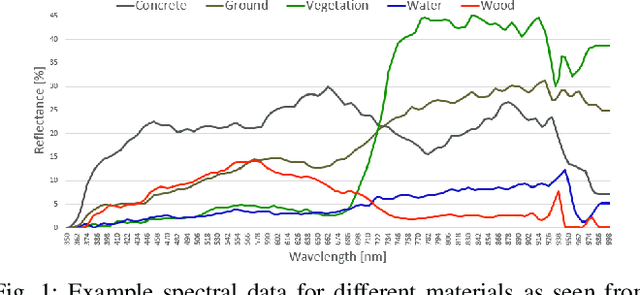
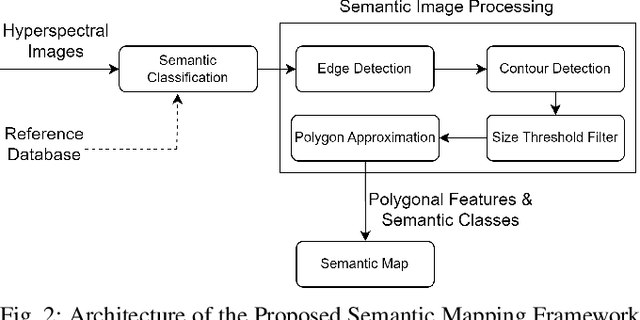


Autonomous navigation in unstructured off-road environments is greatly improved by semantic scene understanding. Conventional image processing algorithms are difficult to implement and lack robustness due to a lack of structure and high variability across off-road environments. The use of neural networks and machine learning can overcome the previous challenges but they require large labeled data sets for training. In our work we propose the use of hyperspectral images for real-time pixel-wise semantic classification and segmentation, without the need of any prior training data. The resulting segmented image is processed to extract, filter, and approximate objects as polygons, using a polygon approximation algorithm. The resulting polygons are then used to generate a semantic map of the environment. Using our framework. we show the capability to add new semantic classes in run-time for classification. The proposed methodology is also shown to operate in real-time and produce outputs at a frequency of 1Hz, using high resolution hyperspectral images.
Power Beacon Energy Consumption Minimization in Wireless Powered Backscatter Communication Networks
Jun 09, 2023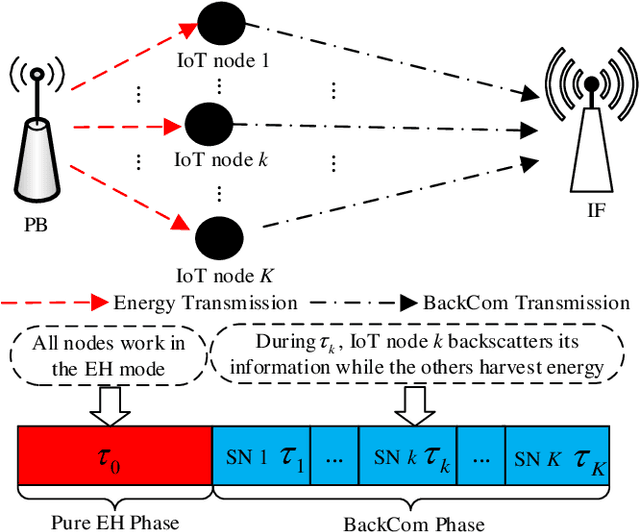

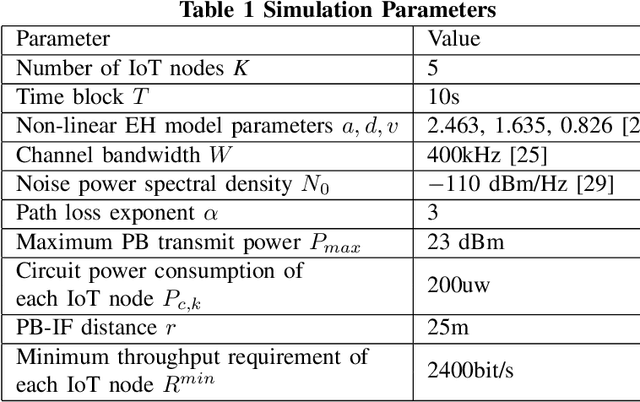
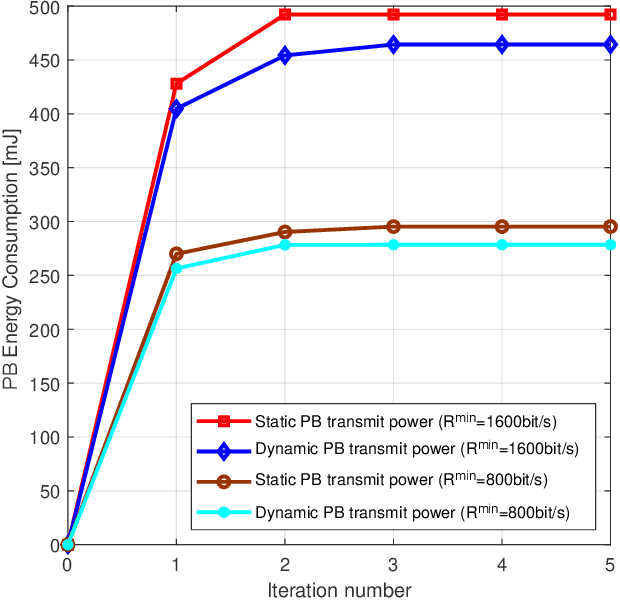
Internet-of-Things (IoT) networks are expected to support the wireless connection of massive energy limited IoT nodes. The emerging wireless powered backscatter communications (WPBC) enable IoT nodes to harvest energy from the incident radio frequency signals transmitted by a power beacon (PB) to support their circuit operation, but the energy consumption of the PB (a potentially high cost borne by the network operator) has not been sufficiently studied for WPBC. In this paper, we aim to minimize the energy consumption of the PB while satisfying the throughput requirement per IoT node by jointly optimizing the time division multiple access (TDMA) time slot duration and backscatter reflection coefficient of each IoT node and the PB transmit power per time slot. As the formulated joint optimization problem is non-convex, we transform it into a convex problem by using auxiliary variables, then employ the Lagrange dual method to obtain the optimal solutions. To reduce the implementation complexity required for adjusting the PB's transmit power every time slot, we keep the PB transmit power constant in each time block and solve the corresponding PB energy consumption minimization problem by using auxiliary variables, the block coordinated decent method and the successive convex approximation technique. Based on the above solutions, two iterative algorithms are proposed for the dynamic PB transmit power scheme and the static PB transmit power scheme. The simulation results show that the dynamic PB transmit power scheme and the static PB transmit power scheme both achieve a lower PB energy consumption than the benchmark schemes, and the former achieves the lowest PB energy consumption.
Two-stage Autoencoder Neural Network for 3D Speech Enhancement
Jun 08, 2023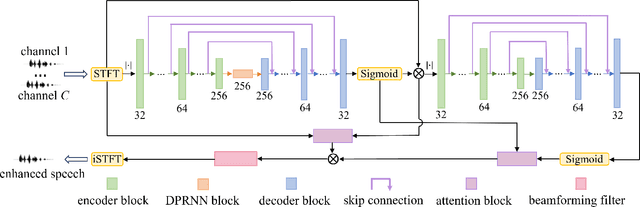
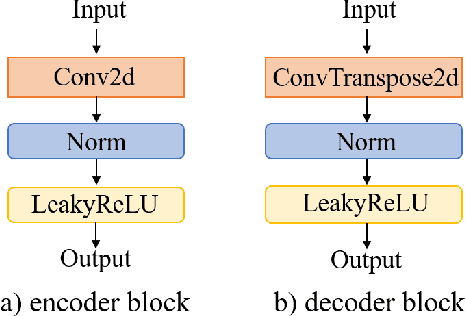
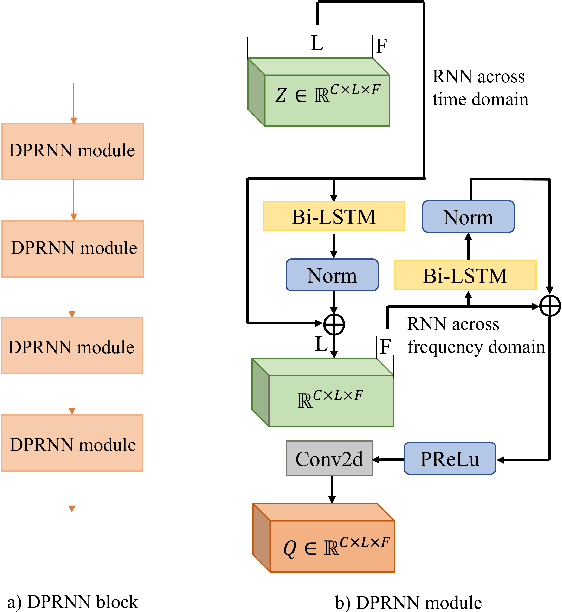
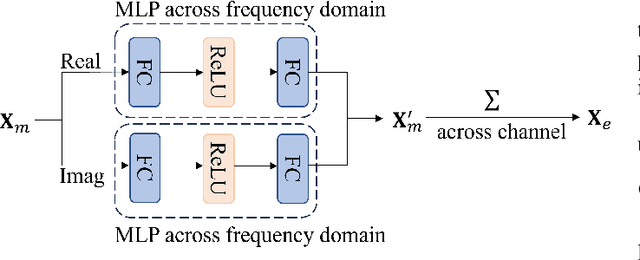
3D speech enhancement has attracted much attention in recent years with the development of augmented reality technology. Traditional denoising convolutional autoencoders have limitations in extracting dynamic voice information. In this paper, we propose a two-stage autoencoder neural network for 3D speech enhancement. We incorporate a dual-path recurrent neural network block into the convolutional autoencoder to iteratively apply time-domain and frequency-domain modeling in an alternate fashion. And an attention mechanism for fusing the high-dimension features is proposed. We also introduce a loss function to simultaneously optimize the network in the time-frequency and time domains. Experimental results show that our system outperforms the state-of-the-art systems on the dataset of ICASSP L3DAS23 challenge.
Multi-Objective Hull Form Optimization with CAD Engine-based Deep Learning Physics for 3D Flow Prediction
Jun 22, 2023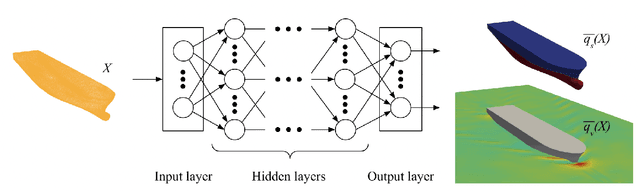
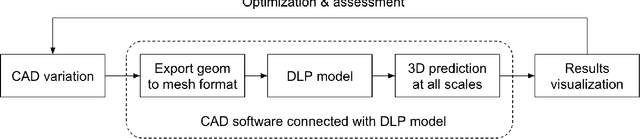
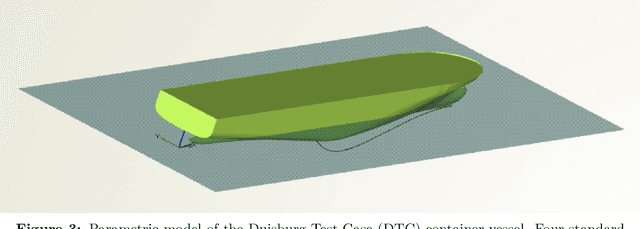

In this work, we propose a built-in Deep Learning Physics Optimization (DLPO) framework to set up a shape optimization study of the Duisburg Test Case (DTC) container vessel. We present two different applications: (1) sensitivity analysis to detect the most promising generic basis hull shapes, and (2) multi-objective optimization to quantify the trade-off between optimal hull forms. DLPO framework allows for the evaluation of design iterations automatically in an end-to-end manner. We achieved these results by coupling Extrality's Deep Learning Physics (DLP) model to a CAD engine and an optimizer. Our proposed DLP model is trained on full 3D volume data coming from RANS simulations, and it can provide accurate and high-quality 3D flow predictions in real-time, which makes it a good evaluator to perform optimization of new container vessel designs w.r.t the hydrodynamic efficiency. In particular, it is able to recover the forces acting on the vessel by integration on the hull surface with a mean relative error of 3.84\% \pm 2.179\% on the total resistance. Each iteration takes only 20 seconds, thus leading to a drastic saving of time and engineering efforts, while delivering valuable insight into the performance of the vessel, including RANS-like detailed flow information. We conclude that DLPO framework is a promising tool to accelerate the ship design process and lead to more efficient ships with better hydrodynamic performance.
TKN: Transformer-based Keypoint Prediction Network For Real-time Video Prediction
Mar 20, 2023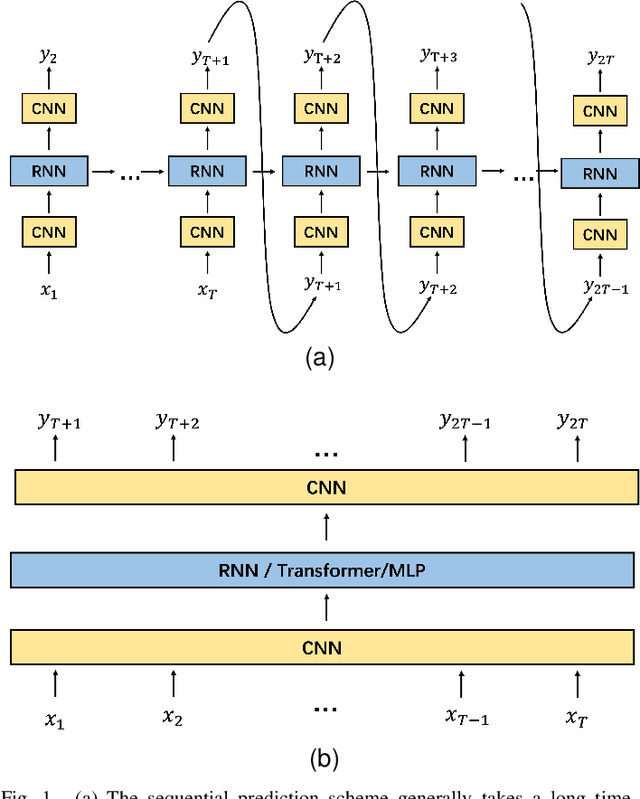
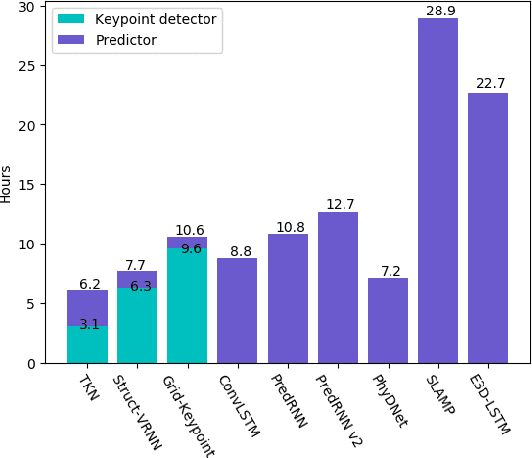

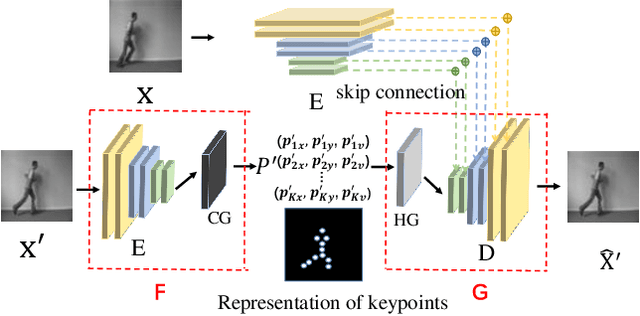
Video prediction is a complex time-series forecasting task with great potential in many use cases. However, conventional methods overemphasize accuracy while ignoring the slow prediction speed caused by complicated model structures that learn too much redundant information with excessive GPU memory consumption. Furthermore, conventional methods mostly predict frames sequentially (frame-by-frame) and thus are hard to accelerate. Consequently, valuable use cases such as real-time danger prediction and warning cannot achieve fast enough inference speed to be applicable in reality. Therefore, we propose a transformer-based keypoint prediction neural network (TKN), an unsupervised learning method that boost the prediction process via constrained information extraction and parallel prediction scheme. TKN is the first real-time video prediction solution to our best knowledge, while significantly reducing computation costs and maintaining other performance. Extensive experiments on KTH and Human3.6 datasets demonstrate that TKN predicts 11 times faster than existing methods while reducing memory consumption by 17.4% and achieving state-of-the-art prediction performance on average.
Dynamic Implicit Image Function for Efficient Arbitrary-Scale Image Representation
Jun 21, 2023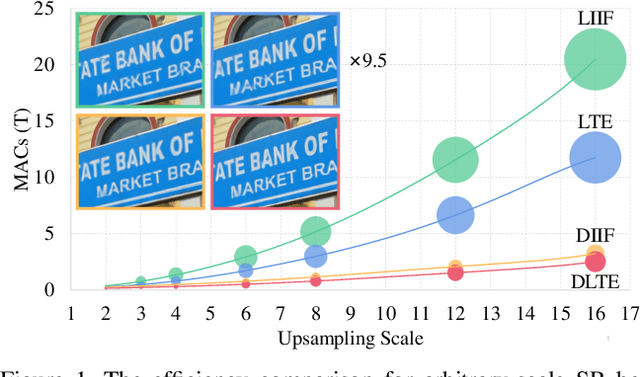
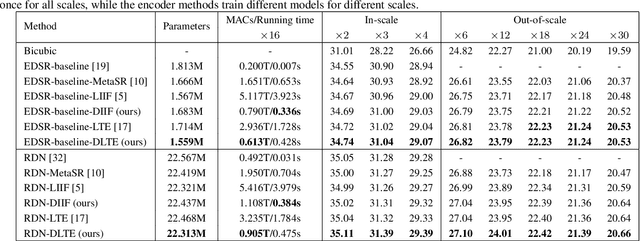

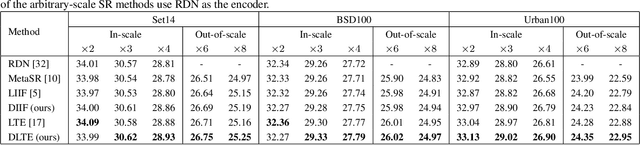
Recent years have witnessed the remarkable success of implicit neural representation methods. The recent work Local Implicit Image Function (LIIF) has achieved satisfactory performance for continuous image representation, where pixel values are inferred from a neural network in a continuous spatial domain. However, the computational cost of such implicit arbitrary-scale super-resolution (SR) methods increases rapidly as the scale factor increases, which makes arbitrary-scale SR time-consuming. In this paper, we propose Dynamic Implicit Image Function (DIIF), which is a fast and efficient method to represent images with arbitrary resolution. Instead of taking an image coordinate and the nearest 2D deep features as inputs to predict its pixel value, we propose a coordinate grouping and slicing strategy, which enables the neural network to perform decoding from coordinate slices to pixel value slices. We further propose a Coarse-to-Fine Multilayer Perceptron (C2F-MLP) to perform decoding with dynamic coordinate slicing, where the number of coordinates in each slice varies as the scale factor varies. With dynamic coordinate slicing, DIIF significantly reduces the computational cost when encountering arbitrary-scale SR. Experimental results demonstrate that DIIF can be integrated with implicit arbitrary-scale SR methods and achieves SOTA SR performance with significantly superior computational efficiency, thereby opening a path for real-time arbitrary-scale image representation. Our code can be found at https://github.com/HeZongyao/DIIF.
Adaptive Ensemble Q-learning: Minimizing Estimation Bias via Error Feedback
Jun 20, 2023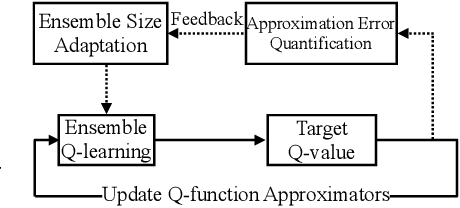
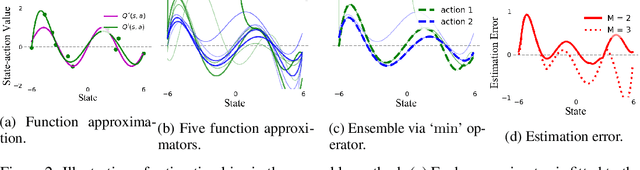
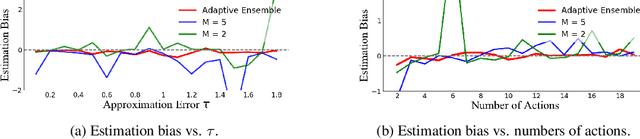
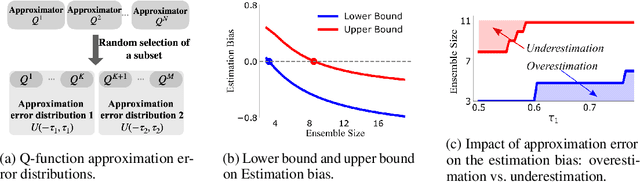
The ensemble method is a promising way to mitigate the overestimation issue in Q-learning, where multiple function approximators are used to estimate the action values. It is known that the estimation bias hinges heavily on the ensemble size (i.e., the number of Q-function approximators used in the target), and that determining the `right' ensemble size is highly nontrivial, because of the time-varying nature of the function approximation errors during the learning process. To tackle this challenge, we first derive an upper bound and a lower bound on the estimation bias, based on which the ensemble size is adapted to drive the bias to be nearly zero, thereby coping with the impact of the time-varying approximation errors accordingly. Motivated by the theoretic findings, we advocate that the ensemble method can be combined with Model Identification Adaptive Control (MIAC) for effective ensemble size adaptation. Specifically, we devise Adaptive Ensemble Q-learning (AdaEQ), a generalized ensemble method with two key steps: (a) approximation error characterization which serves as the feedback for flexibly controlling the ensemble size, and (b) ensemble size adaptation tailored towards minimizing the estimation bias. Extensive experiments are carried out to show that AdaEQ can improve the learning performance than the existing methods for the MuJoCo benchmark.
Static Background Removal in Vehicular Radar: Filtering in Azimuth-Elevation-Doppler Domain
Jul 04, 2023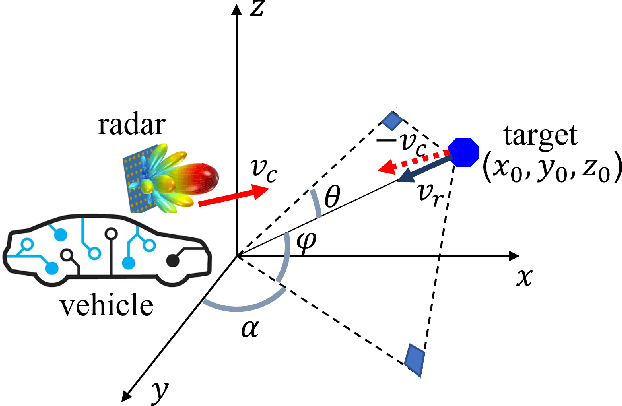
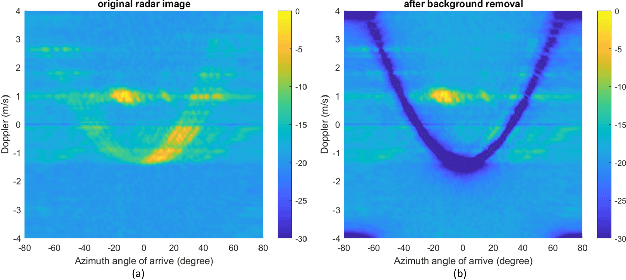
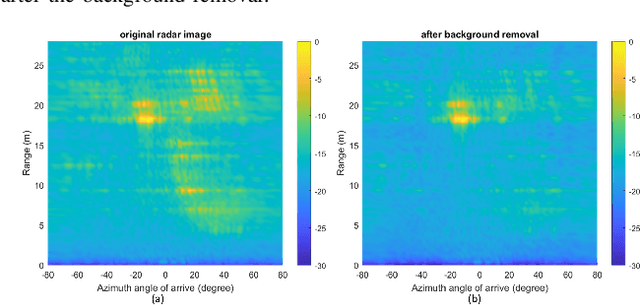
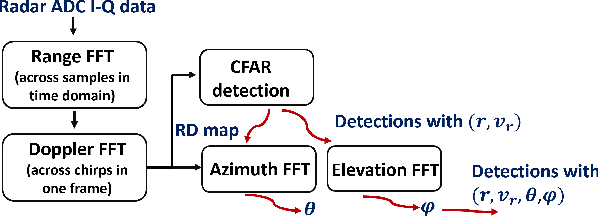
A significant challenge in autonomous driving systems lies in image understanding within complex environments, particularly dense traffic scenarios. An effective solution to this challenge involves removing the background or static objects from the scene, so as to enhance the detection of moving targets as key component of improving overall system performance. In this paper, we present an efficient algorithm for background removal in automotive radar applications, specifically utilizing a frequency-modulated continuous wave (FMCW) radar. Our proposed algorithm follows a three-step approach, encompassing radar signal preprocessing, three-dimensional (3D) ego-motion estimation, and notch filter-based background removal in the azimuth-elevation-Doppler domain. To begin, we model the received signal of the FMCW multiple-input multiple-output (MIMO) radar and develop a signal processing framework for extracting four-dimensional (4D) point clouds. Subsequently, we introduce a robust 3D ego-motion estimation algorithm that accurately estimates radar ego-motion speed, accounting for Doppler ambiguity, by processing the point clouds. Additionally, our algorithm leverages the relationship between Doppler velocity, azimuth angle, elevation angle, and radar ego-motion speed to identify the spectrum belonging to background clutter. Subsequently, we employ notch filters to effectively filter out the background clutter. The performance of our algorithm is evaluated using both simulated data and extensive experiments with real-world data. The results demonstrate its effectiveness in efficiently removing background clutter and enhacing perception within complex environments. By offering a fast and computationally efficient solution, our approach effectively addresses challenges posed by non-homogeneous environments and real-time processing requirements.