 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Provably Efficient UCB-type Algorithms For Learning Predictive State Representations
Jul 01, 2023
The general sequential decision-making problem, which includes Markov decision processes (MDPs) and partially observable MDPs (POMDPs) as special cases, aims at maximizing a cumulative reward by making a sequence of decisions based on a history of observations and actions over time. Recent studies have shown that the sequential decision-making problem is statistically learnable if it admits a low-rank structure modeled by predictive state representations (PSRs). Despite these advancements, existing approaches typically involve oracles or steps that are not computationally efficient. On the other hand, the upper confidence bound (UCB) based approaches, which have served successfully as computationally efficient methods in bandits and MDPs, have not been investigated for more general PSRs, due to the difficulty of optimistic bonus design in these more challenging settings. This paper proposes the first known UCB-type approach for PSRs, featuring a novel bonus term that upper bounds the total variation distance between the estimated and true models. We further characterize the sample complexity bounds for our designed UCB-type algorithms for both online and offline PSRs. In contrast to existing approaches for PSRs, our UCB-type algorithms enjoy computational efficiency, last-iterate guaranteed near-optimal policy, and guaranteed model accuracy.
Sparse-Input Neural Network using Group Concave Regularization
Jul 01, 2023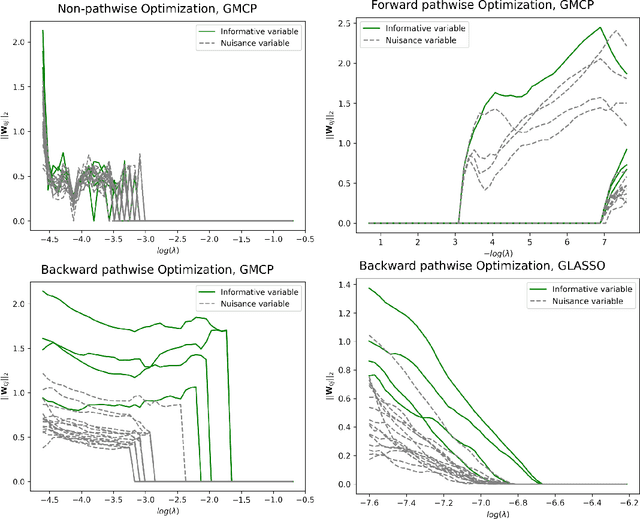
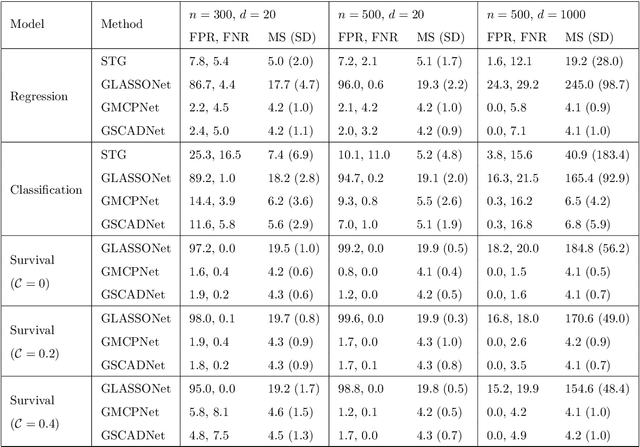
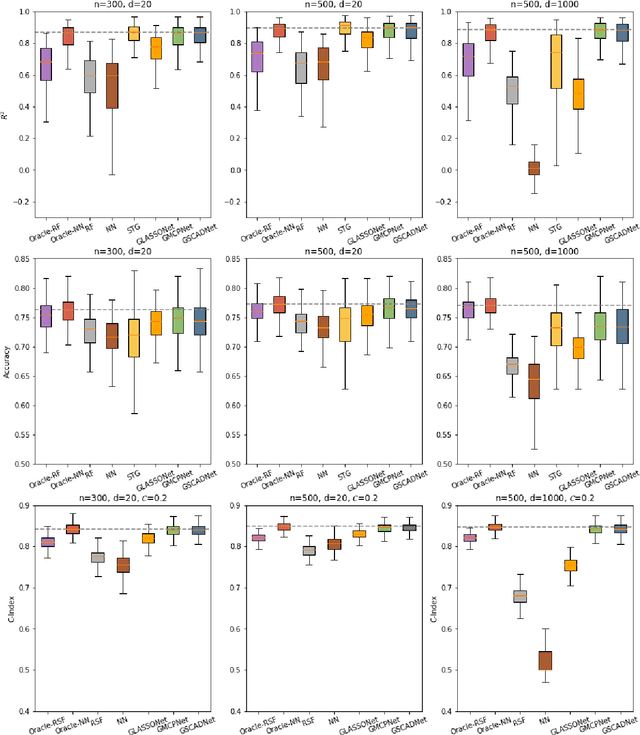
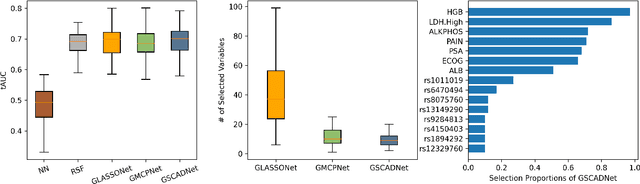
Simultaneous feature selection and non-linear function estimation are challenging, especially in high-dimensional settings where the number of variables exceeds the available sample size in modeling. In this article, we investigate the problem of feature selection in neural networks. Although the group LASSO has been utilized to select variables for learning with neural networks, it tends to select unimportant variables into the model to compensate for its over-shrinkage. To overcome this limitation, we propose a framework of sparse-input neural networks using group concave regularization for feature selection in both low-dimensional and high-dimensional settings. The main idea is to apply a proper concave penalty to the $l_2$ norm of weights from all outgoing connections of each input node, and thus obtain a neural net that only uses a small subset of the original variables. In addition, we develop an effective algorithm based on backward path-wise optimization to yield stable solution paths, in order to tackle the challenge of complex optimization landscapes. Our extensive simulation studies and real data examples demonstrate satisfactory finite sample performances of the proposed estimator, in feature selection and prediction for modeling continuous, binary, and time-to-event outcomes.
STG4Traffic: A Survey and Benchmark of Spatial-Temporal Graph Neural Networks for Traffic Prediction
Jul 02, 2023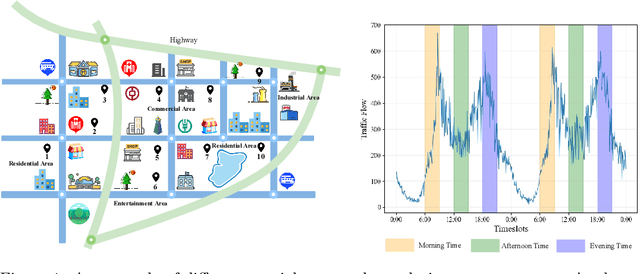


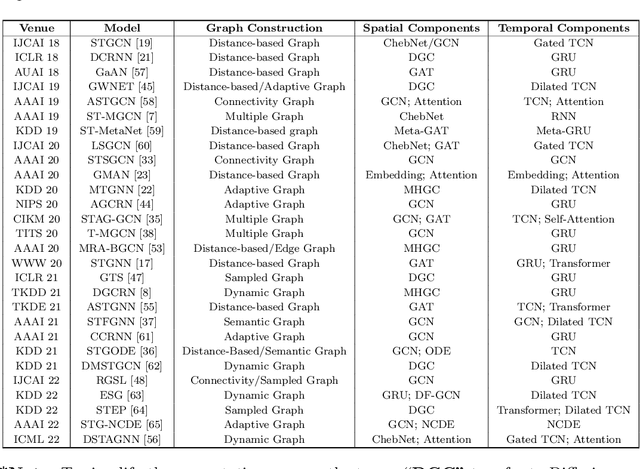
Traffic prediction has been an active research topic in the domain of spatial-temporal data mining. Accurate real-time traffic prediction is essential to improve the safety, stability, and versatility of smart city systems, i.e., traffic control and optimal routing. The complex and highly dynamic spatial-temporal dependencies make effective predictions still face many challenges. Recent studies have shown that spatial-temporal graph neural networks exhibit great potential applied to traffic prediction, which combines sequential models with graph convolutional networks to jointly model temporal and spatial correlations. However, a survey study of graph learning, spatial-temporal graph models for traffic, as well as a fair comparison of baseline models are pending and unavoidable issues. In this paper, we first provide a systematic review of graph learning strategies and commonly used graph convolution algorithms. Then we conduct a comprehensive analysis of the strengths and weaknesses of recently proposed spatial-temporal graph network models. Furthermore, we build a study called STG4Traffic using the deep learning framework PyTorch to establish a standardized and scalable benchmark on two types of traffic datasets. We can evaluate their performance by personalizing the model settings with uniform metrics. Finally, we point out some problems in the current study and discuss future directions. Source codes are available at https://github.com/trainingl/STG4Traffic.
More Synergy, Less Redundancy: Exploiting Joint Mutual Information for Self-Supervised Learning
Jul 02, 2023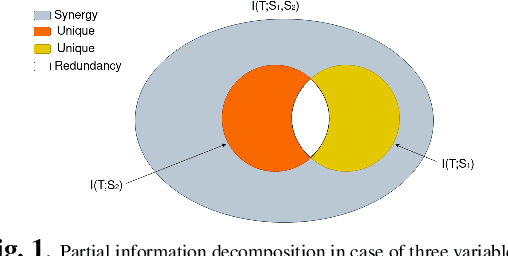
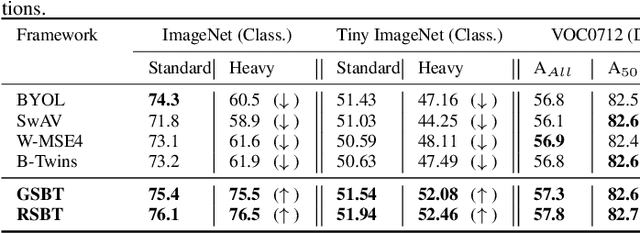
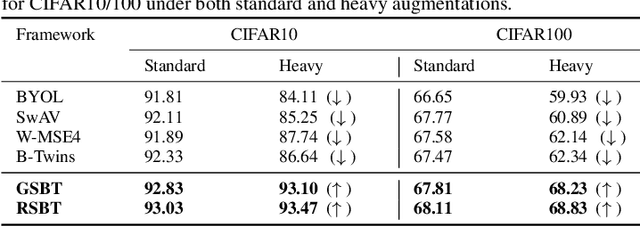
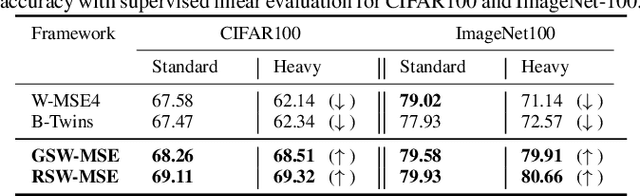
Self-supervised learning (SSL) is now a serious competitor for supervised learning, even though it does not require data annotation. Several baselines have attempted to make SSL models exploit information about data distribution, and less dependent on the augmentation effect. However, there is no clear consensus on whether maximizing or minimizing the mutual information between representations of augmentation views practically contribute to improvement or degradation in performance of SSL models. This paper is a fundamental work where, we investigate role of mutual information in SSL, and reformulate the problem of SSL in the context of a new perspective on mutual information. To this end, we consider joint mutual information from the perspective of partial information decomposition (PID) as a key step in \textbf{reliable multivariate information measurement}. PID enables us to decompose joint mutual information into three important components, namely, unique information, redundant information and synergistic information. Our framework aims for minimizing the redundant information between views and the desired target representation while maximizing the synergistic information at the same time. Our experiments lead to a re-calibration of two redundancy reduction baselines, and a proposal for a new SSL training protocol. Extensive experimental results on multiple datasets and two downstream tasks show the effectiveness of this framework.
Path Planning with Potential Field-Based Obstacle Avoidance in a 3D Environment by an Unmanned Aerial Vehicle
Jun 28, 2023

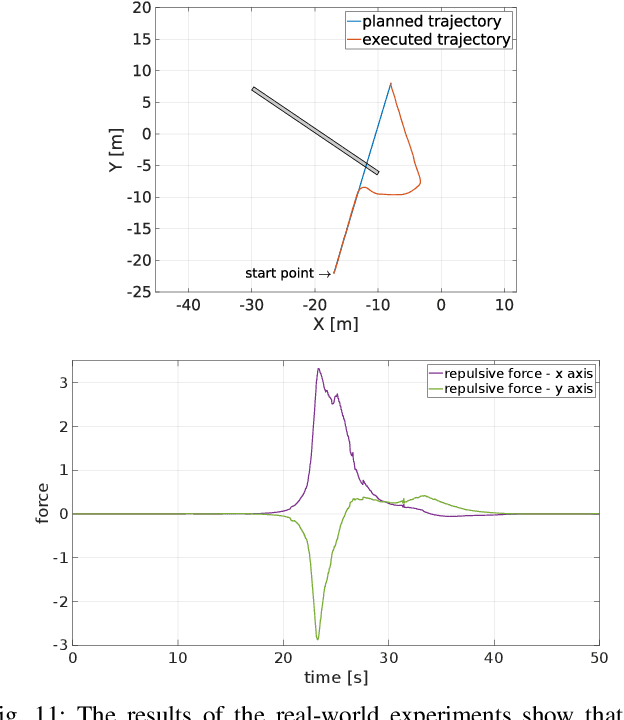
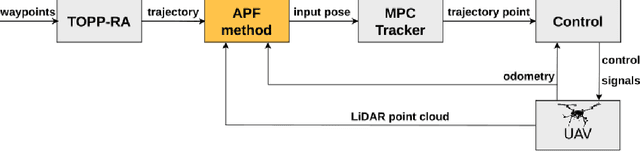
In this paper we address the problem of path planning in an unknown environment with an aerial robot. The main goal is to safely follow the planned trajectory by avoiding obstacles. The proposed approach is suitable for aerial vehicles equipped with 3D sensors, such as LiDARs. It performs obstacle avoidance in real time and on an on-board computer. We present a novel algorithm based on the conventional Artifcial Potential Field (APF) that corrects the planned trajectory to avoid obstacles. To this end, our modifed algorithm uses a rotation-based component to avoid local minima. The smooth trajectory following, achieved with the MPC tracker, allows us to quickly change and re-plan the UAV trajectory. Comparative experiments in simulation have shown that our approach solves local minima problems in trajectory planning and generates more effcient paths to avoid potential collisions with static obstacles compared to the original APF method.
Recommender Systems for Online and Mobile Social Networks: A survey
Jun 28, 2023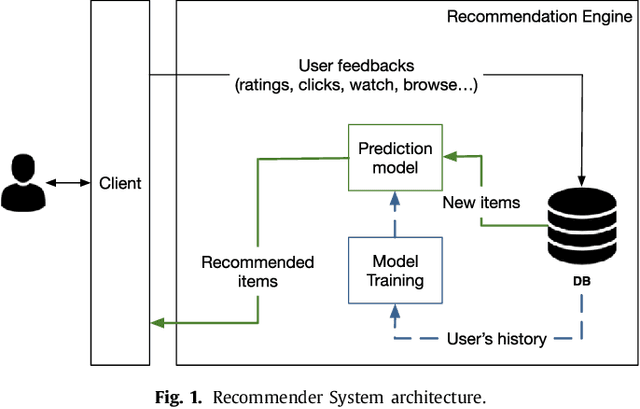

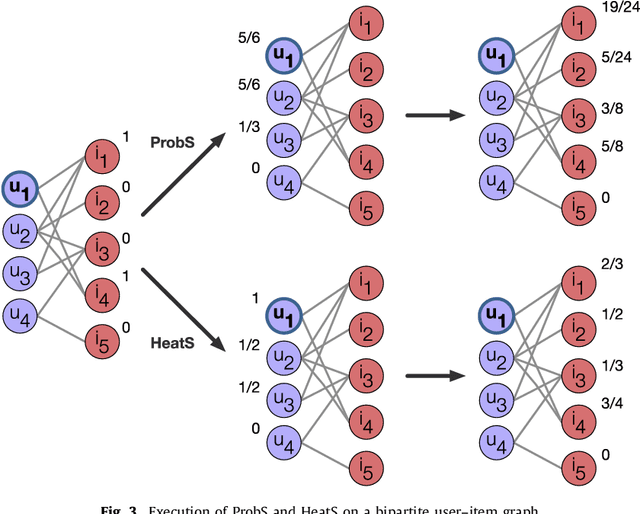
Recommender Systems (RS) currently represent a fundamental tool in online services, especially with the advent of Online Social Networks (OSN). In this case, users generate huge amounts of contents and they can be quickly overloaded by useless information. At the same time, social media represent an important source of information to characterize contents and users' interests. RS can exploit this information to further personalize suggestions and improve the recommendation process. In this paper we present a survey of Recommender Systems designed and implemented for Online and Mobile Social Networks, highlighting how the use of social context information improves the recommendation task, and how standard algorithms must be enhanced and optimized to run in a fully distributed environment, as opportunistic networks. We describe advantages and drawbacks of these systems in terms of algorithms, target domains, evaluation metrics and performance evaluations. Eventually, we present some open research challenges in this area.
Align With Purpose: Optimize Desired Properties in CTC Models with a General Plug-and-Play Framework
Jul 06, 2023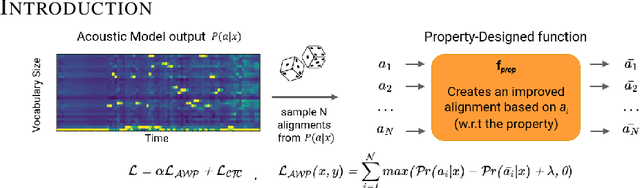

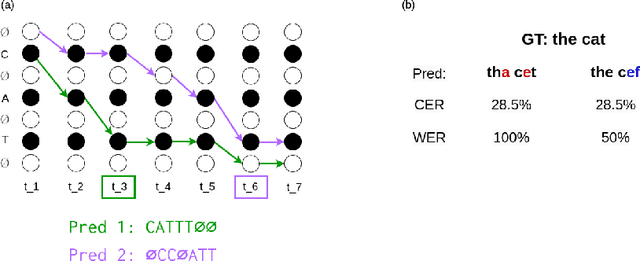
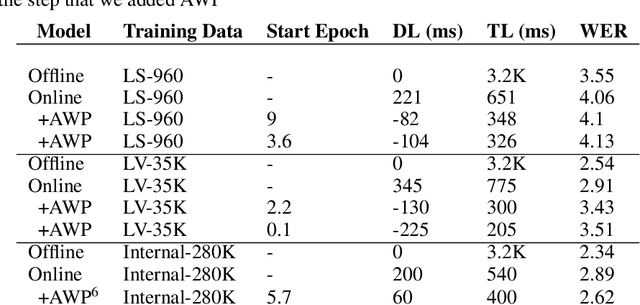
Connectionist Temporal Classification (CTC) is a widely used criterion for training supervised sequence-to-sequence (seq2seq) models. It enables learning the relations between input and output sequences, termed alignments, by marginalizing over perfect alignments (that yield the ground truth), at the expense of imperfect alignments. This binary differentiation of perfect and imperfect alignments falls short of capturing other essential alignment properties that hold significance in other real-world applications. Here we propose $\textit{Align With Purpose}$, a $\textbf{general Plug-and-Play framework}$ for enhancing a desired property in models trained with the CTC criterion. We do that by complementing the CTC with an additional loss term that prioritizes alignments according to a desired property. Our method does not require any intervention in the CTC loss function, enables easy optimization of a variety of properties, and allows differentiation between both perfect and imperfect alignments. We apply our framework in the domain of Automatic Speech Recognition (ASR) and show its generality in terms of property selection, architectural choice, and scale of training dataset (up to 280,000 hours). To demonstrate the effectiveness of our framework, we apply it to two unrelated properties: emission time and word error rate (WER). For the former, we report an improvement of up to 570ms in latency optimization with a minor reduction in WER, and for the latter, we report a relative improvement of 4.5% WER over the baseline models. To the best of our knowledge, these applications have never been demonstrated to work on a scale of data as large as ours. Notably, our method can be implemented using only a few lines of code, and can be extended to other alignment-free loss functions and to domains other than ASR.
Sentence-level Event Detection without Triggers via Prompt Learning and Machine Reading Comprehension
Jun 25, 2023The traditional way of sentence-level event detection involves two important subtasks: trigger identification and trigger classifications, where the identified event trigger words are used to classify event types from sentences. However, trigger classification highly depends on abundant annotated trigger words and the accuracy of trigger identification. In a real scenario, annotating trigger words is time-consuming and laborious. For this reason, we propose a trigger-free event detection model, which transforms event detection into a two-tower model based on machine reading comprehension and prompt learning. Compared to existing trigger-based and trigger-free methods, experimental studies on two event detection benchmark datasets (ACE2005 and MAVEN) have shown that the proposed approach can achieve competitive performance.
Real-Time Semantic Segmentation using Hyperspectral Images for Mapping Unstructured and Unknown Environments
Mar 27, 2023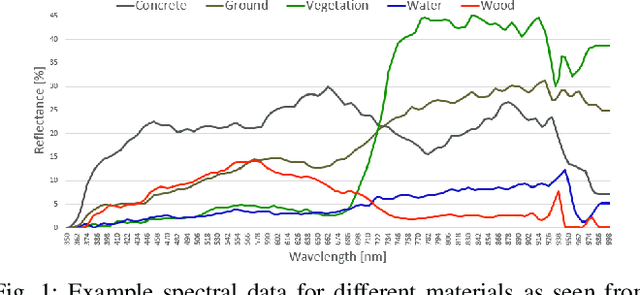
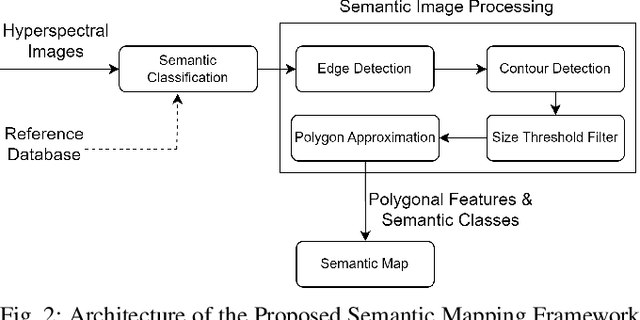


Autonomous navigation in unstructured off-road environments is greatly improved by semantic scene understanding. Conventional image processing algorithms are difficult to implement and lack robustness due to a lack of structure and high variability across off-road environments. The use of neural networks and machine learning can overcome the previous challenges but they require large labeled data sets for training. In our work we propose the use of hyperspectral images for real-time pixel-wise semantic classification and segmentation, without the need of any prior training data. The resulting segmented image is processed to extract, filter, and approximate objects as polygons, using a polygon approximation algorithm. The resulting polygons are then used to generate a semantic map of the environment. Using our framework. we show the capability to add new semantic classes in run-time for classification. The proposed methodology is also shown to operate in real-time and produce outputs at a frequency of 1Hz, using high resolution hyperspectral images.
Characterizing the Emotion Carriers of COVID-19 Misinformation and Their Impact on Vaccination Outcomes in India and the United States
Jun 24, 2023
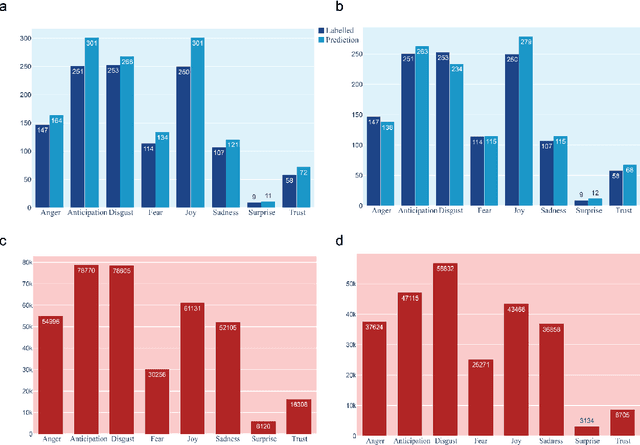
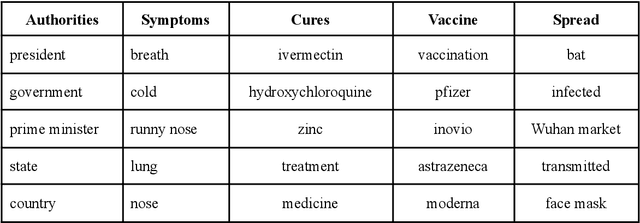
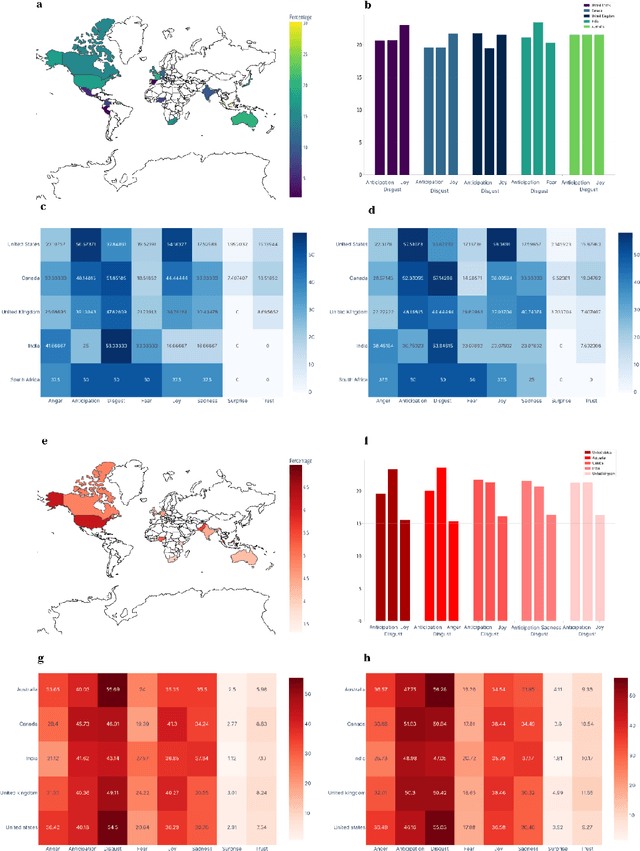
The COVID-19 Infodemic had an unprecedented impact on health behaviors and outcomes at a global scale. While many studies have focused on a qualitative and quantitative understanding of misinformation, including sentiment analysis, there is a gap in understanding the emotion-carriers of misinformation and their differences across geographies. In this study, we characterized emotion carriers and their impact on vaccination rates in India and the United States. A manually labelled dataset was created from 2.3 million tweets and collated with three publicly available datasets (CoAID, AntiVax, CMU) to train deep learning models for misinformation classification. Misinformation labelled tweets were further analyzed for behavioral aspects by leveraging Plutchik Transformers to determine the emotion for each tweet. Time series analysis was conducted to study the impact of misinformation on spatial and temporal characteristics. Further, categorical classification was performed using transformer models to assign categories for the misinformation tweets. Word2Vec+BiLSTM was the best model for misinformation classification, with an F1-score of 0.92. The US had the highest proportion of misinformation tweets (58.02%), followed by the UK (10.38%) and India (7.33%). Disgust, anticipation, and anger were associated with an increased prevalence of misinformation tweets. Disgust was the predominant emotion associated with misinformation tweets in the US, while anticipation was the predominant emotion in India. For India, the misinformation rate exhibited a lead relationship with vaccination, while in the US it lagged behind vaccination. Our study deciphered that emotions acted as differential carriers of misinformation across geography and time. These carriers can be monitored to develop strategic interventions for countering misinformation, leading to improved public health.