 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Ticket-BERT: Labeling Incident Management Tickets with Language Models
Jun 30, 2023
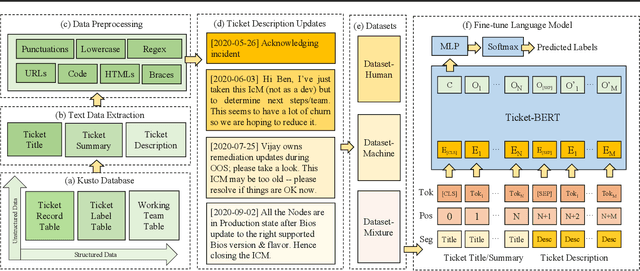
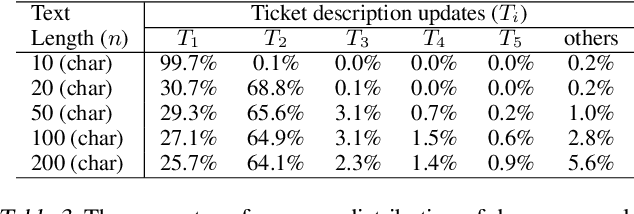
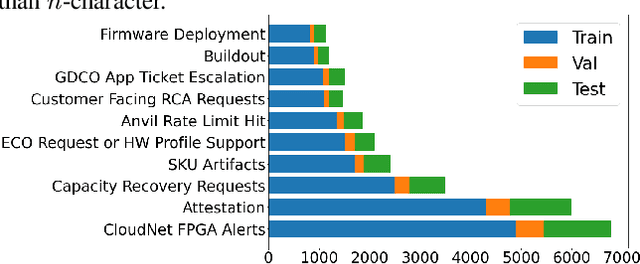

An essential aspect of prioritizing incident tickets for resolution is efficiently labeling tickets with fine-grained categories. However, ticket data is often complex and poses several unique challenges for modern machine learning methods: (1) tickets are created and updated either by machines with pre-defined algorithms or by engineers with domain expertise that share different protocols, (2) tickets receive frequent revisions that update ticket status by modifying all or parts of ticket descriptions, and (3) ticket labeling is time-sensitive and requires knowledge updates and new labels per the rapid software and hardware improvement lifecycle. To handle these issues, we introduce Ticket- BERT which trains a simple yet robust language model for labeling tickets using our proposed ticket datasets. Experiments demonstrate the superiority of Ticket-BERT over baselines and state-of-the-art text classifiers on Azure Cognitive Services. We further encapsulate Ticket-BERT with an active learning cycle and deploy it on the Microsoft IcM system, which enables the model to quickly finetune on newly-collected tickets with a few annotations.
Voting-based Multimodal Automatic Deception Detection
Jun 30, 2023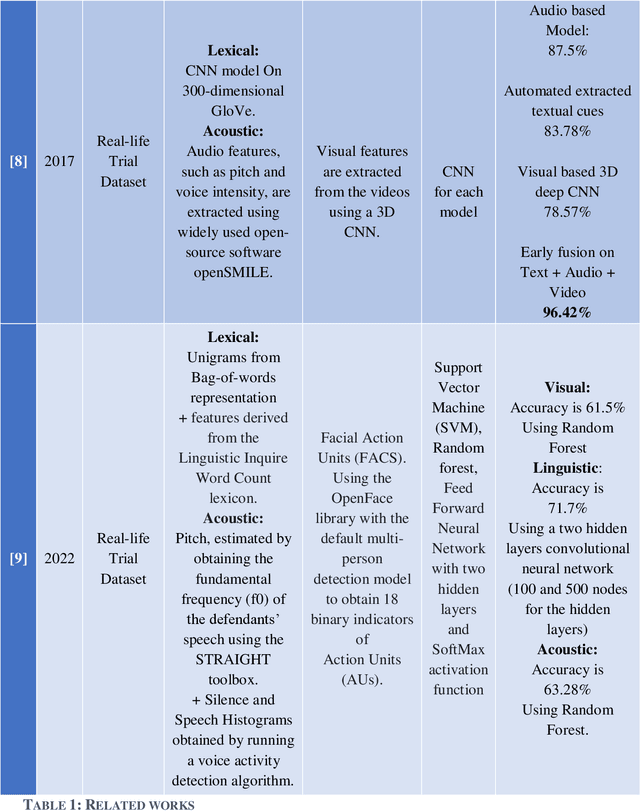
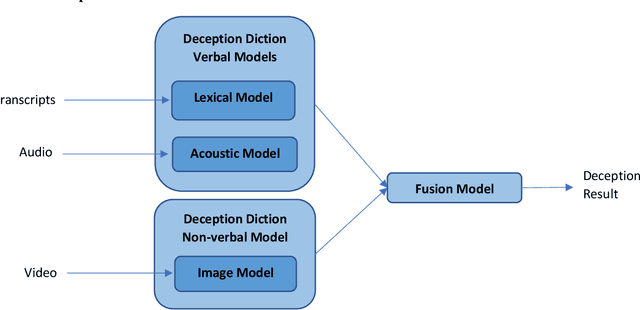
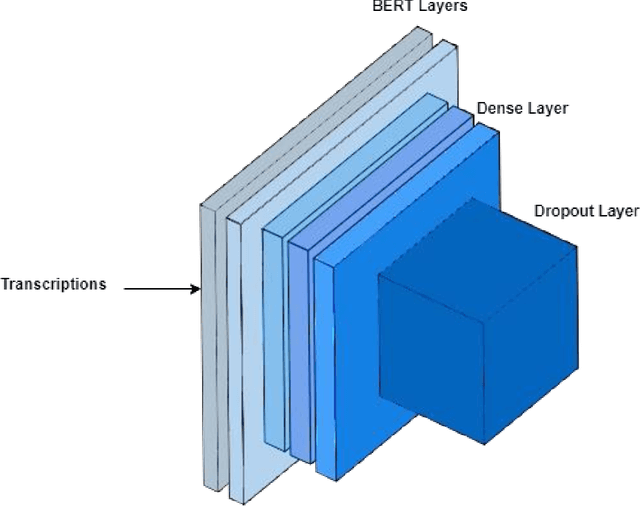
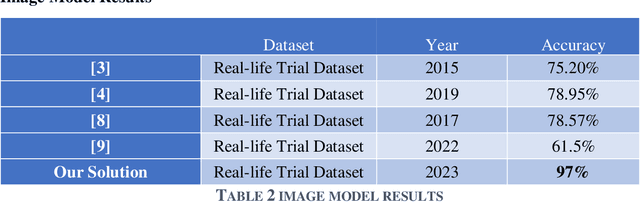
Automatic Deception Detection has been a hot research topic for a long time, using machine learning and deep learning to automatically detect deception, brings new light to this old field. In this paper, we proposed a voting-based method for automatic deception detection from videos using audio, visual and lexical features. Experiments were done on two datasets, the Real-life trial dataset by Michigan University and the Miami University deception detection dataset. Video samples were split into frames of images, audio, and manuscripts. Our Voting-based Multimodal proposed solution consists of three models. The first model is CNN for detecting deception from images, the second model is Support Vector Machine (SVM) on Mel spectrograms for detecting deception from audio and the third model is Word2Vec on Support Vector Machine (SVM) for detecting deception from manuscripts. Our proposed solution outperforms state of the art. Best results achieved on images, audio and text were 97%, 96%, 92% respectively on Real-Life Trial Dataset, and 97%, 82%, 73% on video, audio and text respectively on Miami University Deception Detection.
Projection-based first-order constrained optimization solver for robotics
Jun 30, 2023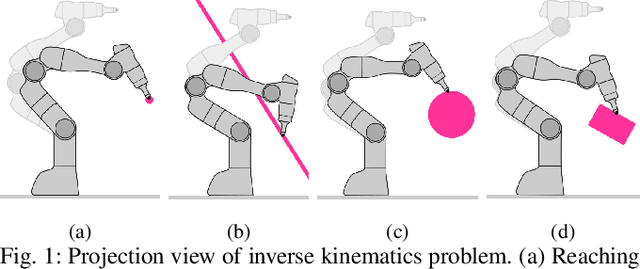
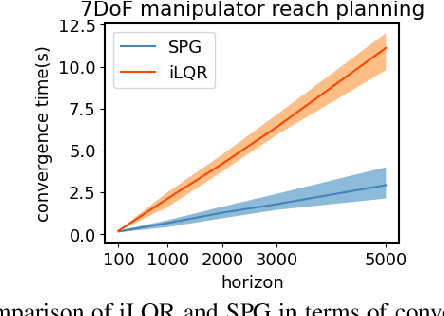
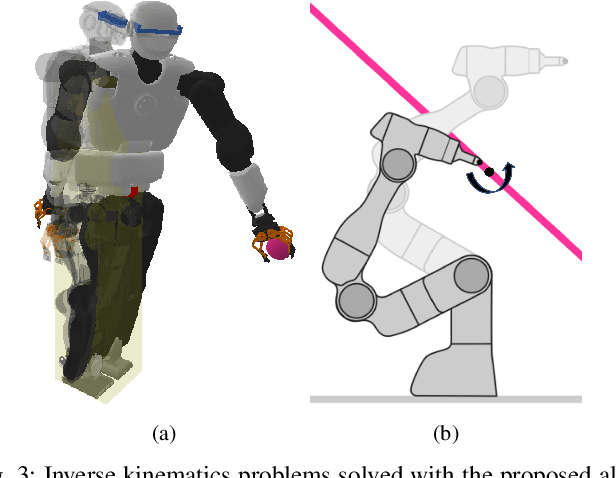
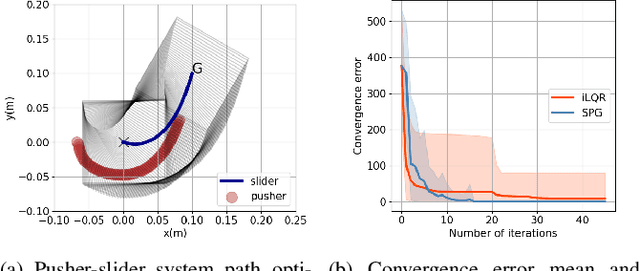
Robot programming tools ranging from inverse kinematics (IK) to model predictive control (MPC) are most often described as constrained optimization problems. Even though there are currently many commercially-available second-order solvers, robotics literature recently focused on efficient implementations and improvements over these solvers for real-time robotic applications. However, most often, these implementations stay problem-specific and are not easy to access or implement, or do not exploit the geometric aspect of the robotics problems. In this work, we propose to solve these problems using a fast, easy-to-implement first-order method that fully exploits the geometric constraints via Euclidean projections, called Augmented Lagrangian Spectral Projected Gradient Descent (ALSPG). We show that 1. using projections instead of full constraints and gradients improves the performance of the solver and 2. ALSPG stays competitive to the standard second-order methods such as iLQR in the unconstrained case. We showcase these results with IK and motion planning problems on simulated examples and with an MPC problem on a 7-axis manipulator experiment.
Parameter Identification for Partial Differential Equations with Spatiotemporal Varying Coefficients
Jun 30, 2023
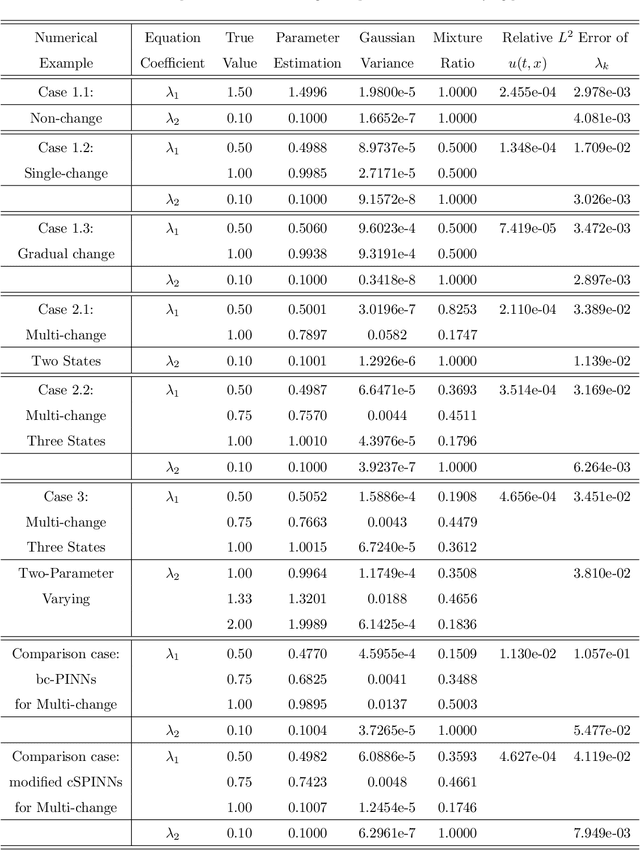
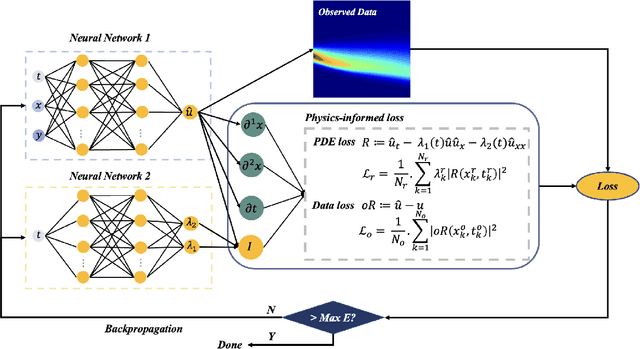
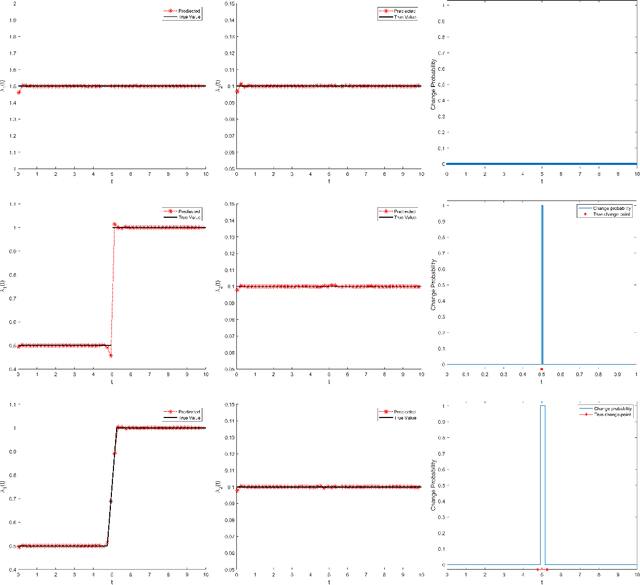
To comprehend complex systems with multiple states, it is imperative to reveal the identity of these states by system outputs. Nevertheless, the mathematical models describing these systems often exhibit nonlinearity so that render the resolution of the parameter inverse problem from the observed spatiotemporal data a challenging endeavor. Starting from the observed data obtained from such systems, we propose a novel framework that facilitates the investigation of parameter identification for multi-state systems governed by spatiotemporal varying parametric partial differential equations. Our framework consists of two integral components: a constrained self-adaptive physics-informed neural network, encompassing a sub-network, as our methodology for parameter identification, and a finite mixture model approach to detect regions of probable parameter variations. Through our scheme, we can precisely ascertain the unknown varying parameters of the complex multi-state system, thereby accomplishing the inversion of the varying parameters. Furthermore, we have showcased the efficacy of our framework on two numerical cases: the 1D Burgers' equation with time-varying parameters and the 2D wave equation with a space-varying parameter.
UW-ProCCaps: UnderWater Progressive Colourisation with Capsules
Jul 03, 2023Underwater images are fundamental for studying and understanding the status of marine life. We focus on reducing the memory space required for image storage while the memory space consumption in the collecting phase limits the time lasting of this phase leading to the need for more image collection campaigns. We present a novel machine-learning model that reconstructs the colours of underwater images from their luminescence channel, thus saving 2/3 of the available storage space. Our model specialises in underwater colour reconstruction and consists of an encoder-decoder architecture. The encoder is composed of a convolutional encoder and a parallel specialised classifier trained with webly-supervised data. The encoder and the decoder use layers of capsules to capture the features of the entities in the image. The colour reconstruction process recalls the progressive and the generative adversarial training procedures. The progressive training gives the ground for a generative adversarial routine focused on the refining of colours giving the image bright and saturated colours which bring the image back to life. We validate the model both qualitatively and quantitatively on four benchmark datasets. This is the first attempt at colour reconstruction in greyscale underwater images. Extensive results on four benchmark datasets demonstrate that our solution outperforms state-of-the-art (SOTA) solutions. We also demonstrate that the generated colourisation enhances the quality of images compared to enhancement models at the SOTA.
Real-time SLAM Pipeline in Dynamics Environment
Mar 04, 2023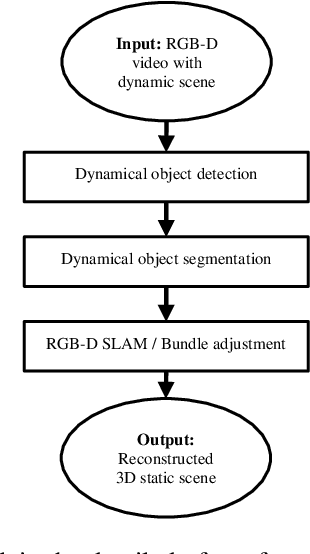
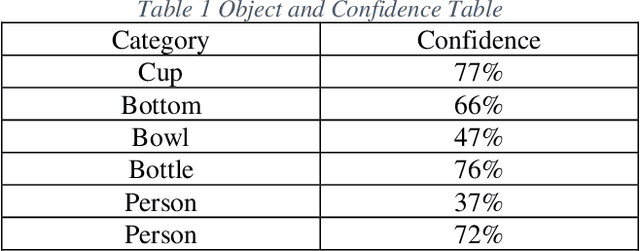

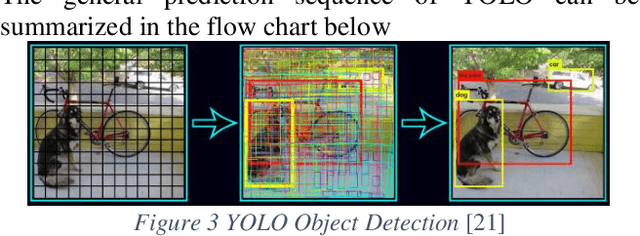
Inspired by the recent success of application of dense data approach by using ORB-SLAM and RGB-D SLAM, we propose a better pipeline of real-time SLAM in dynamics environment. Different from previous SLAM which can only handle static scenes, we are presenting a solution which use RGB-D SLAM as well as YOLO real-time object detection to segment and remove dynamic scene and then construct static scene 3D. We gathered a dataset which allows us to jointly consider semantics, geometry, and physics and thus enables us to reconstruct the static scene while filtering out all dynamic objects.
DiversiGATE: A Comprehensive Framework for Reliable Large Language Models
Jun 26, 2023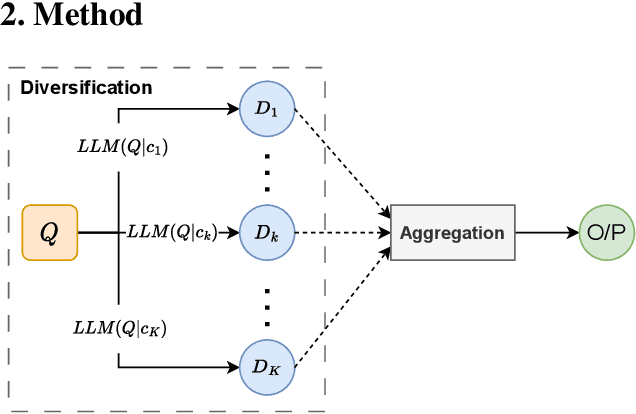


In this paper, we introduce DiversiGATE, a unified framework that consolidates diverse methodologies for LLM verification. The proposed framework comprises two main components: Diversification and Aggregation which provide a holistic perspective on existing verification approaches, such as Self-Consistency, Math Prompter and WebGPT. Furthermore, we propose a novel `SelfLearner' model that conforms to the DiversiGATE framework which can learn from its own outputs and refine its performance over time, leading to improved accuracy. To evaluate the effectiveness of SelfLearner, we conducted a rigorous series of experiments, including tests on synthetic data as well as on popular arithmetic reasoning benchmarks such as GSM8K. Our results demonstrate that our approach outperforms traditional LLMs, achieving a considerable 54.8% -> 61.8% improvement on the GSM8K benchmark.
SDRCNN: A single-scale dense residual connected convolutional neural network for pansharpening
Jul 01, 2023
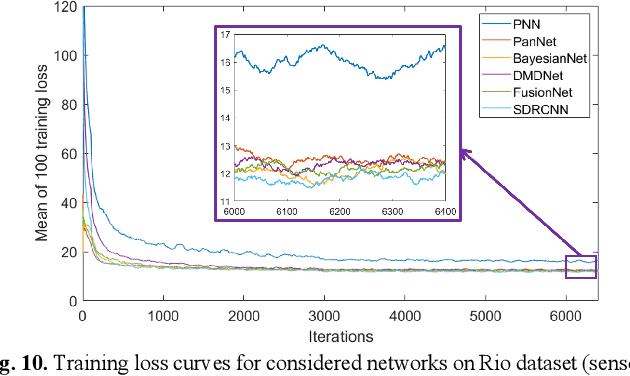


Pansharpening is a process of fusing a high spatial resolution panchromatic image and a low spatial resolution multispectral image to create a high-resolution multispectral image. A novel single-branch, single-scale lightweight convolutional neural network, named SDRCNN, is developed in this study. By using a novel dense residual connected structure and convolution block, SDRCNN achieved a better trade-off between accuracy and efficiency. The performance of SDRCNN was tested using four datasets from the WorldView-3, WorldView-2 and QuickBird satellites. The compared methods include eight traditional methods (i.e., GS, GSA, PRACS, BDSD, SFIM, GLP-CBD, CDIF and LRTCFPan) and five lightweight deep learning methods (i.e., PNN, PanNet, BayesianNet, DMDNet and FusionNet). Based on a visual inspection of the pansharpened images created and the associated absolute residual maps, SDRCNN exhibited least spatial detail blurring and spectral distortion, amongst all the methods considered. The values of the quantitative evaluation metrics were closest to their ideal values when SDRCNN was used. The processing time of SDRCNN was also the shortest among all methods tested. Finally, the effectiveness of each component in the SDRCNN was demonstrated in ablation experiments. All of these confirmed the superiority of SDRCNN.
DreamIdentity: Improved Editability for Efficient Face-identity Preserved Image Generation
Jul 01, 2023
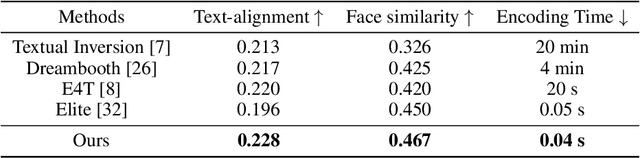
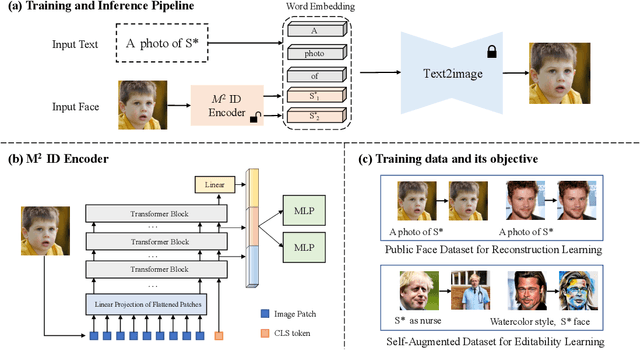

While large-scale pre-trained text-to-image models can synthesize diverse and high-quality human-centric images, an intractable problem is how to preserve the face identity for conditioned face images. Existing methods either require time-consuming optimization for each face-identity or learning an efficient encoder at the cost of harming the editability of models. In this work, we present an optimization-free method for each face identity, meanwhile keeping the editability for text-to-image models. Specifically, we propose a novel face-identity encoder to learn an accurate representation of human faces, which applies multi-scale face features followed by a multi-embedding projector to directly generate the pseudo words in the text embedding space. Besides, we propose self-augmented editability learning to enhance the editability of models, which is achieved by constructing paired generated face and edited face images using celebrity names, aiming at transferring mature ability of off-the-shelf text-to-image models in celebrity faces to unseen faces. Extensive experiments show that our methods can generate identity-preserved images under different scenes at a much faster speed.
SysNoise: Exploring and Benchmarking Training-Deployment System Inconsistency
Jul 01, 2023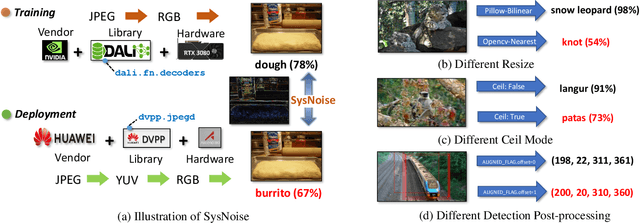

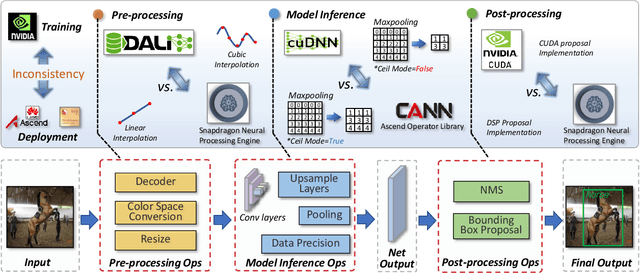
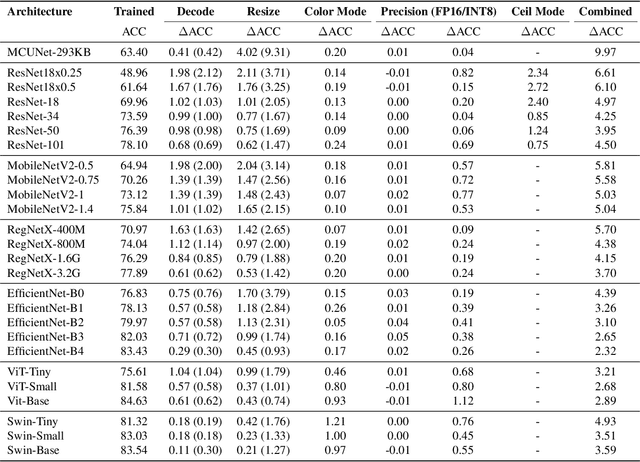
Extensive studies have shown that deep learning models are vulnerable to adversarial and natural noises, yet little is known about model robustness on noises caused by different system implementations. In this paper, we for the first time introduce SysNoise, a frequently occurred but often overlooked noise in the deep learning training-deployment cycle. In particular, SysNoise happens when the source training system switches to a disparate target system in deployments, where various tiny system mismatch adds up to a non-negligible difference. We first identify and classify SysNoise into three categories based on the inference stage; we then build a holistic benchmark to quantitatively measure the impact of SysNoise on 20+ models, comprehending image classification, object detection, instance segmentation and natural language processing tasks. Our extensive experiments revealed that SysNoise could bring certain impacts on model robustness across different tasks and common mitigations like data augmentation and adversarial training show limited effects on it. Together, our findings open a new research topic and we hope this work will raise research attention to deep learning deployment systems accounting for model performance. We have open-sourced the benchmark and framework at https://modeltc.github.io/systemnoise_web.
* Proceedings of Machine Learning and Systems. 2023 Mar 18