 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Coupled Gradient Flows for Strategic Non-Local Distribution Shift
Jul 03, 2023
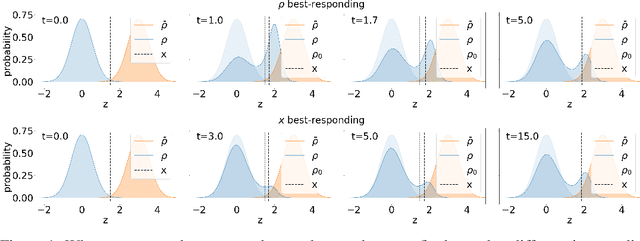

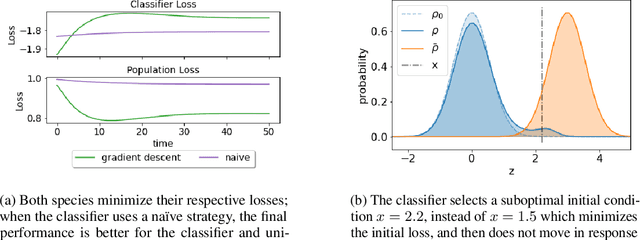
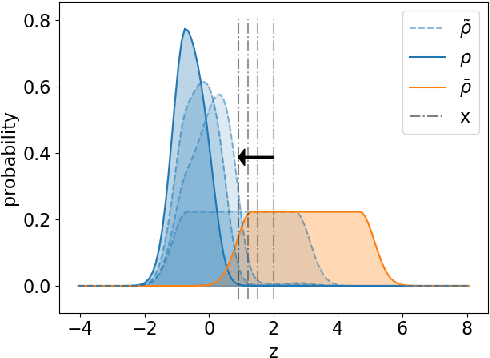
We propose a novel framework for analyzing the dynamics of distribution shift in real-world systems that captures the feedback loop between learning algorithms and the distributions on which they are deployed. Prior work largely models feedback-induced distribution shift as adversarial or via an overly simplistic distribution-shift structure. In contrast, we propose a coupled partial differential equation model that captures fine-grained changes in the distribution over time by accounting for complex dynamics that arise due to strategic responses to algorithmic decision-making, non-local endogenous population interactions, and other exogenous sources of distribution shift. We consider two common settings in machine learning: cooperative settings with information asymmetries, and competitive settings where a learner faces strategic users. For both of these settings, when the algorithm retrains via gradient descent, we prove asymptotic convergence of the retraining procedure to a steady-state, both in finite and in infinite dimensions, obtaining explicit rates in terms of the model parameters. To do so we derive new results on the convergence of coupled PDEs that extends what is known on multi-species systems. Empirically, we show that our approach captures well-documented forms of distribution shifts like polarization and disparate impacts that simpler models cannot capture.
Evaluation of Environmental Conditions on Object Detection using Oriented Bounding Boxes for AR Applications
Jun 29, 2023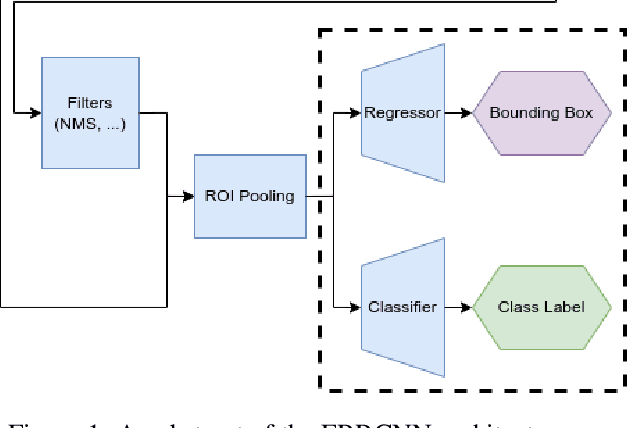
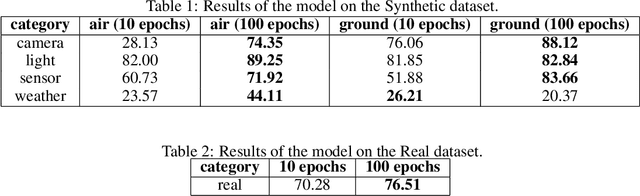
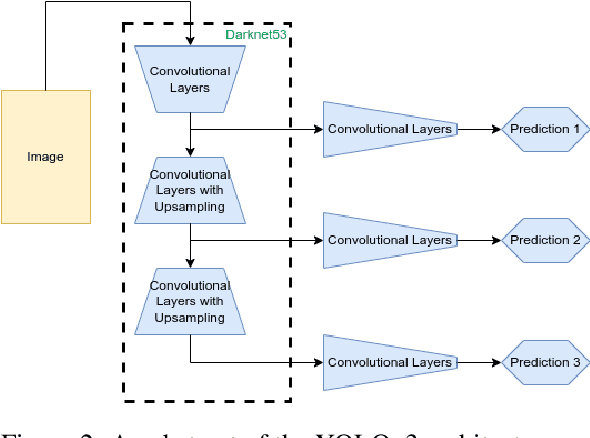

The objective of augmented reality (AR) is to add digital content to natural images and videos to create an interactive experience between the user and the environment. Scene analysis and object recognition play a crucial role in AR, as they must be performed quickly and accurately. In this study, a new approach is proposed that involves using oriented bounding boxes with a detection and recognition deep network to improve performance and processing time. The approach is evaluated using two datasets: a real image dataset (DOTA dataset) commonly used for computer vision tasks, and a synthetic dataset that simulates different environmental, lighting, and acquisition conditions. The focus of the evaluation is on small objects, which are difficult to detect and recognise. The results indicate that the proposed approach tends to produce better Average Precision and greater accuracy for small objects in most of the tested conditions.
Predicting Music Hierarchies with a Graph-Based Neural Decoder
Jun 29, 2023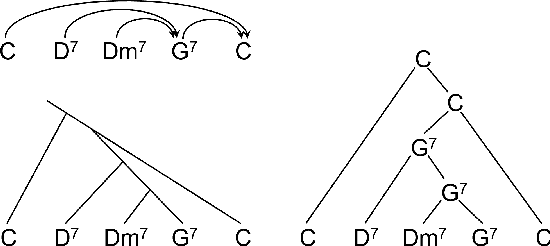
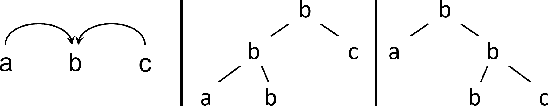
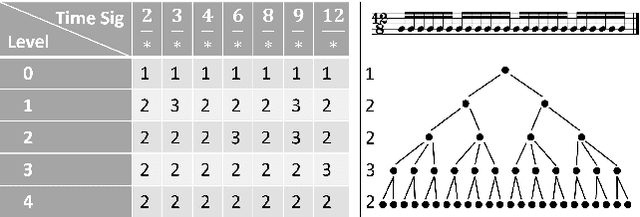
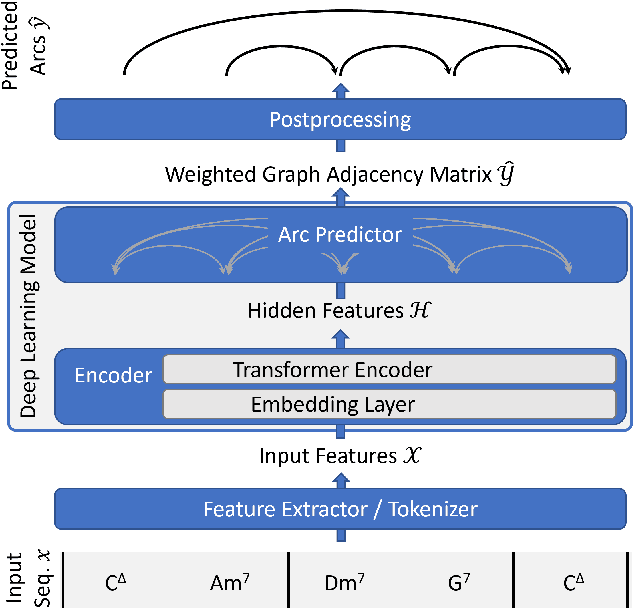
This paper describes a data-driven framework to parse musical sequences into dependency trees, which are hierarchical structures used in music cognition research and music analysis. The parsing involves two steps. First, the input sequence is passed through a transformer encoder to enrich it with contextual information. Then, a classifier filters the graph of all possible dependency arcs to produce the dependency tree. One major benefit of this system is that it can be easily integrated into modern deep-learning pipelines. Moreover, since it does not rely on any particular symbolic grammar, it can consider multiple musical features simultaneously, make use of sequential context information, and produce partial results for noisy inputs. We test our approach on two datasets of musical trees -- time-span trees of monophonic note sequences and harmonic trees of jazz chord sequences -- and show that our approach outperforms previous methods.
Diagnosis Uncertain Models For Medical Risk Prediction
Jun 29, 2023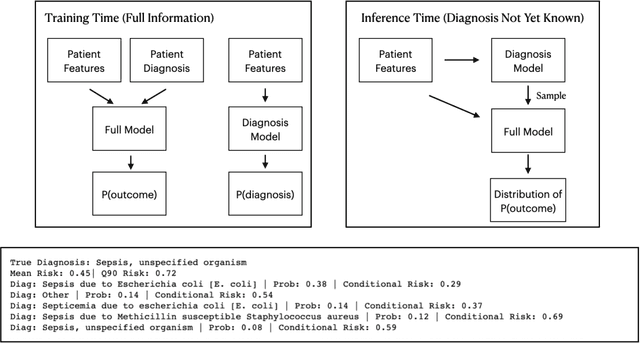
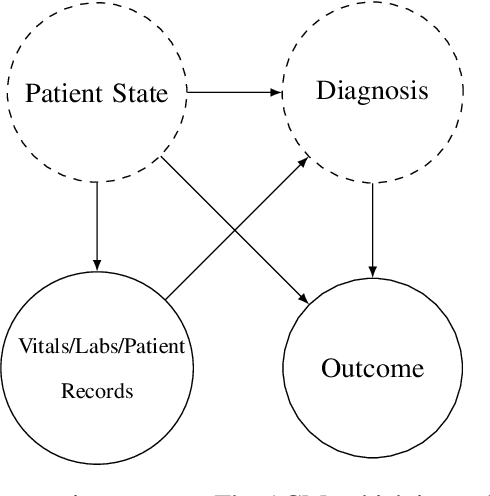
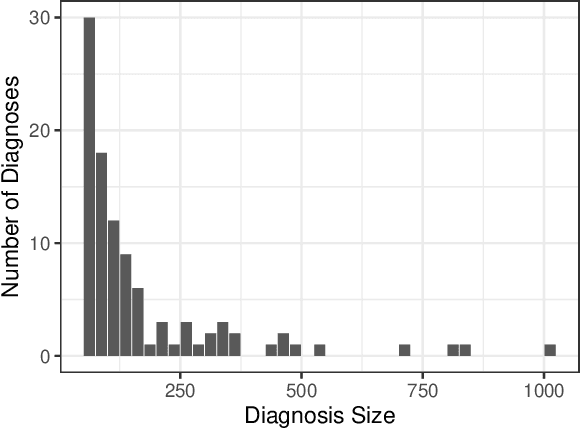
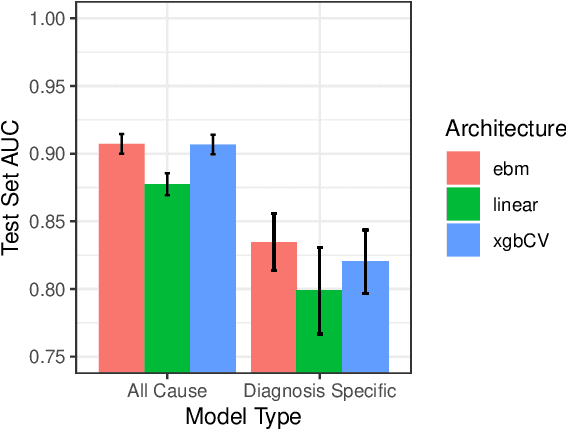
We consider a patient risk models which has access to patient features such as vital signs, lab values, and prior history but does not have access to a patient's diagnosis. For example, this occurs in a model deployed at intake time for triage purposes. We show that such `all-cause' risk models have good generalization across diagnoses but have a predictable failure mode. When the same lab/vital/history profiles can result from diagnoses with different risk profiles (e.g. E.coli vs. MRSA) the risk estimate is a probability weighted average of these two profiles. This leads to an under-estimation of risk for rare but highly risky diagnoses. We propose a fix for this problem by explicitly modeling the uncertainty in risk prediction coming from uncertainty in patient diagnoses. This gives practitioners an interpretable way to understand patient risk beyond a single risk number.
Generative Modeling of Time-Dependent Densities via Optimal Transport and Projection Pursuit
Apr 19, 2023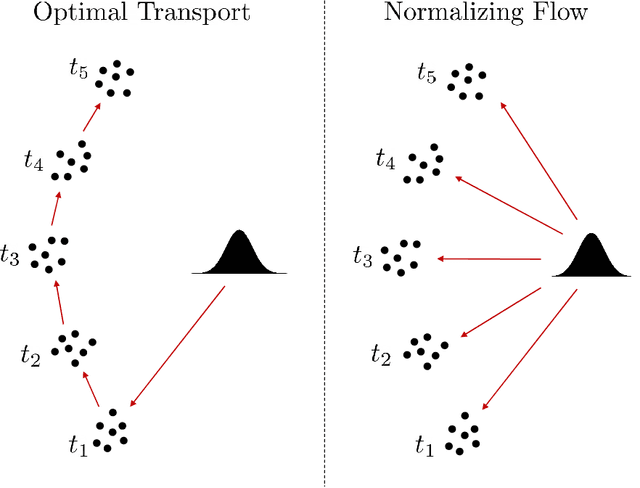
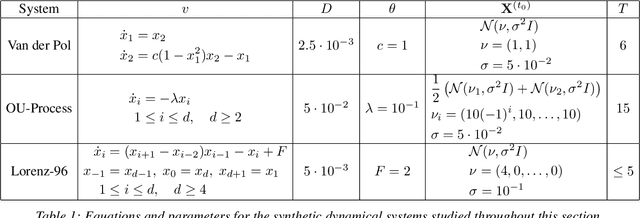
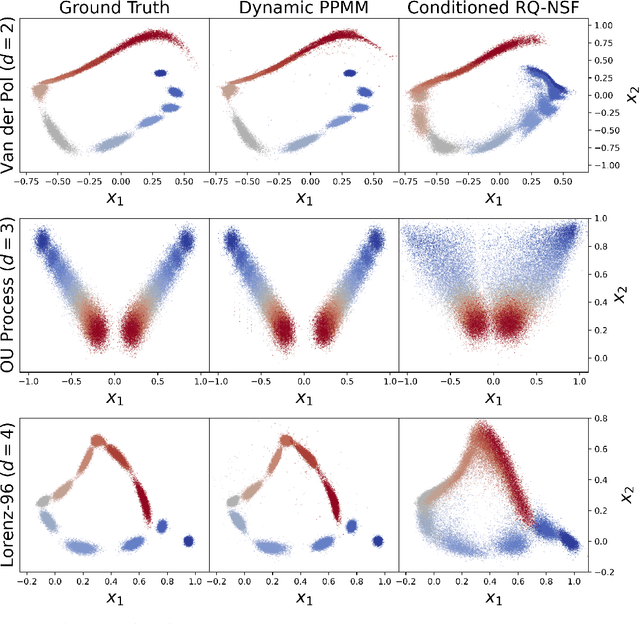

Motivated by the computational difficulties incurred by popular deep learning algorithms for the generative modeling of temporal densities, we propose a cheap alternative which requires minimal hyperparameter tuning and scales favorably to high dimensional problems. In particular, we use a projection-based optimal transport solver [Meng et al., 2019] to join successive samples and subsequently use transport splines [Chewi et al., 2020] to interpolate the evolving density. When the sampling frequency is sufficiently high, the optimal maps are close to the identity and are thus computationally efficient to compute. Moreover, the training process is highly parallelizable as all optimal maps are independent and can thus be learned simultaneously. Finally, the approach is based solely on numerical linear algebra rather than minimizing a nonconvex objective function, allowing us to easily analyze and control the algorithm. We present several numerical experiments on both synthetic and real-world datasets to demonstrate the efficiency of our method. In particular, these experiments show that the proposed approach is highly competitive compared with state-of-the-art normalizing flows conditioned on time across a wide range of dimensionalities.
LTE SFBC MIMO Transmitter Modelling and Performance Evaluation
Jul 07, 2023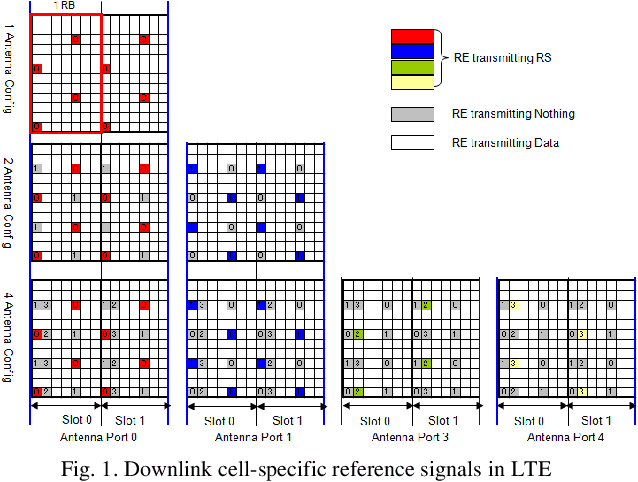
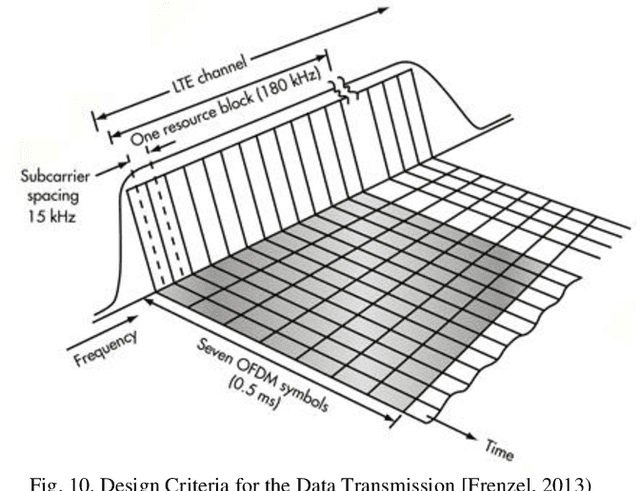
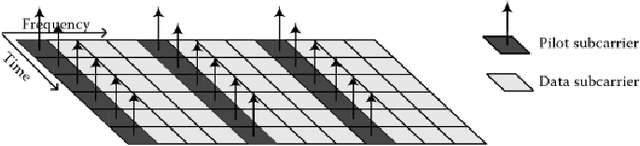
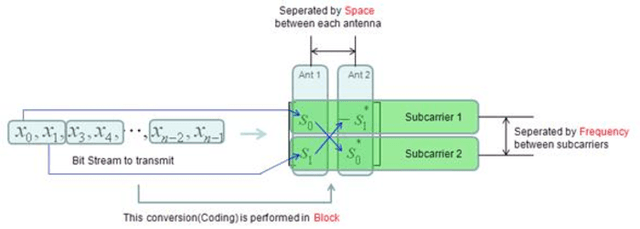
High data rates are one of the most prevalent requirements in current mobile communications. To cover this and other high standards regarding performance, increasing coverage, capacity, and reliability, numerous works have proposed the development of systems employing the combination of several techniques such as Multiple Input Multiple Output (MIMO) wireless technologies with Orthogonal Frequency Division Multiplexing (OFDM) in the evolving 4G wireless communications. Our proposed system is based on the 2x2 MIMO antenna technique, which is defined to enhance the performance of radio communication systems in terms of capacity and spectral efficiency, and the OFDM technique, which can be implemented using two types of sub-carrier mapping modes: Space-Time Block Coding and Space Frequency Block Code. SFBC has been considered in our developed model. The main advantage of SFBC over STBC is that SFBC encodes two modulated symbols over two subcarriers of the same OFDM symbol, whereas STBC encodes two modulated symbols over two subcarriers of the same OFDM symbol; thus, the coding is performed in the frequency domain. Our solution aims to demonstrate the performance analysis of the Space Frequency Block Codes scheme, increasing the Signal Noise Ratio (SNR) at the receiver and decreasing the Bit Error Rate (BER) through the use of 4 QAM, 16 QAM and 64QAM modulation over a 2x2 MIMO channel for an LTE downlink transmission, in different channel radio environments. In this work, an analytical tool to evaluate the performance of SFBC - Orthogonal Frequency Division Multiplexing, using two transmit antennas and two receive antennas has been implemented, and the analysis using the average SNR has been considered as a sufficient statistic to describe the performance of SFBC in the 3GPP Long Term Evolution system over Multiple Input Multiple Output channels.
Neural Abstraction-Based Controller Synthesis and Deployment
Jul 07, 2023Abstraction-based techniques are an attractive approach for synthesizing correct-by-construction controllers to satisfy high-level temporal requirements. A main bottleneck for successful application of these techniques is the memory requirement, both during controller synthesis and in controller deployment. We propose memory-efficient methods for mitigating the high memory demands of the abstraction-based techniques using neural network representations. To perform synthesis for reach-avoid specifications, we propose an on-the-fly algorithm that relies on compressed neural network representations of the forward and backward dynamics of the system. In contrast to usual applications of neural representations, our technique maintains soundness of the end-to-end process. To ensure this, we correct the output of the trained neural network such that the corrected output representations are sound with respect to the finite abstraction. For deployment, we provide a novel training algorithm to find a neural network representation of the synthesized controller and experimentally show that the controller can be correctly represented as a combination of a neural network and a look-up table that requires a substantially smaller memory. We demonstrate experimentally that our approach significantly reduces the memory requirements of abstraction-based methods. For the selected benchmarks, our approach reduces the memory requirements respectively for the synthesis and deployment by a factor of $1.31\times 10^5$ and $7.13\times 10^3$ on average, and up to $7.54\times 10^5$ and $3.18\times 10^4$. Although this reduction is at the cost of increased off-line computations to train the neural networks, all the steps of our approach are parallelizable and can be implemented on machines with higher number of processing units to reduce the required computational time.
Representation Sparsification with Hybrid Thresholding for Fast SPLADE-based Document Retrieval
Jun 20, 2023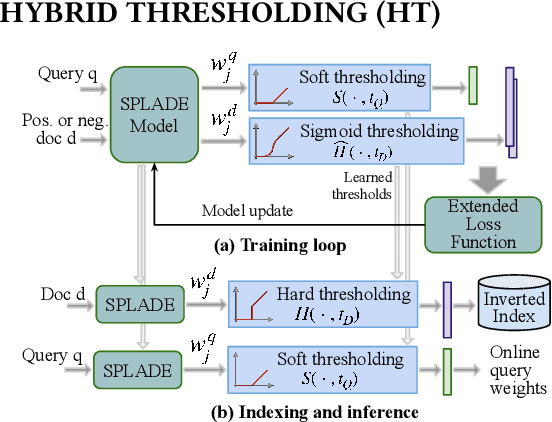
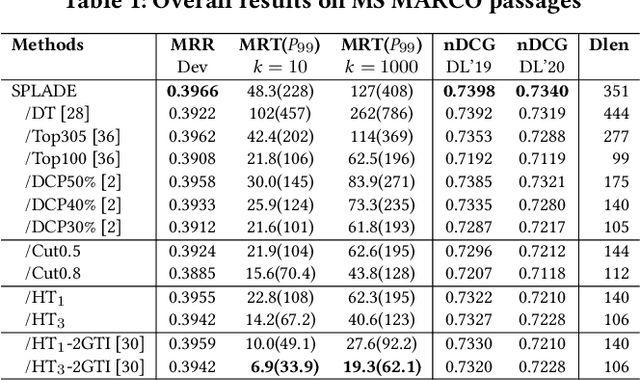
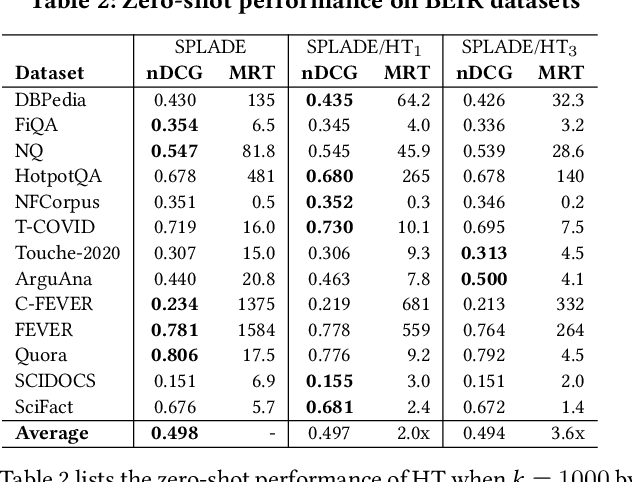
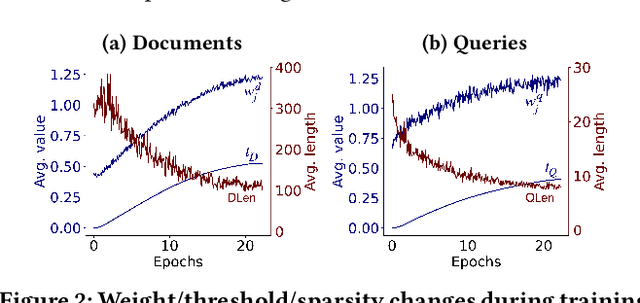
Learned sparse document representations using a transformer-based neural model has been found to be attractive in both relevance effectiveness and time efficiency. This paper describes a representation sparsification scheme based on hard and soft thresholding with an inverted index approximation for faster SPLADE-based document retrieval. It provides analytical and experimental results on the impact of this learnable hybrid thresholding scheme.
* This paper is published in SIGIR'23
Modeling Dual Period-Varying Preferences for Takeaway Recommendation
Jun 16, 2023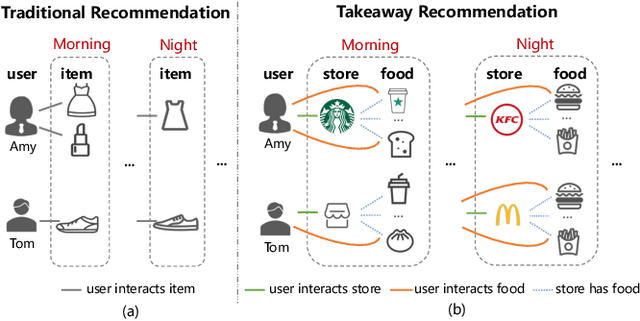
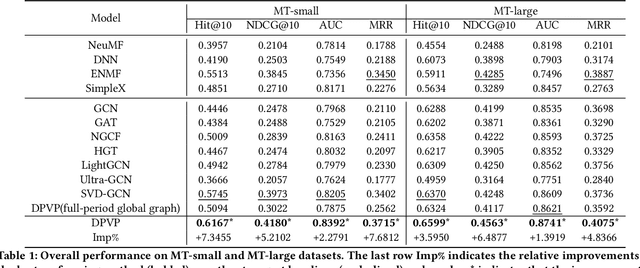
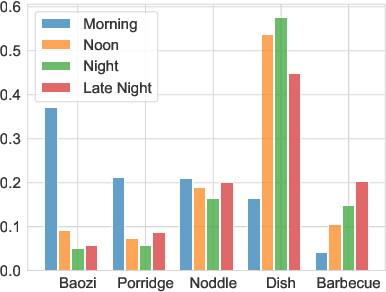
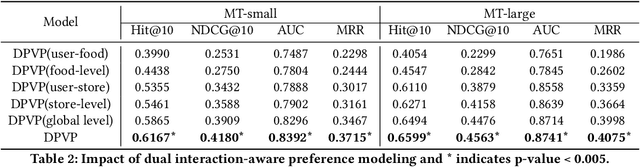
Takeaway recommender systems, which aim to accurately provide stores that offer foods meeting users' interests, have served billions of users in our daily life. Different from traditional recommendation, takeaway recommendation faces two main challenges: (1) Dual Interaction-Aware Preference Modeling. Traditional recommendation commonly focuses on users' single preferences for items while takeaway recommendation needs to comprehensively consider users' dual preferences for stores and foods. (2) Period-Varying Preference Modeling. Conventional recommendation generally models continuous changes in users' preferences from a session-level or day-level perspective. However, in practical takeaway systems, users' preferences vary significantly during the morning, noon, night, and late night periods of the day. To address these challenges, we propose a Dual Period-Varying Preference modeling (DPVP) for takeaway recommendation. Specifically, we design a dual interaction-aware module, aiming to capture users' dual preferences based on their interactions with stores and foods. Moreover, to model various preferences in different time periods of the day, we propose a time-based decomposition module as well as a time-aware gating mechanism. Extensive offline and online experiments demonstrate that our model outperforms state-of-the-art methods on real-world datasets and it is capable of modeling the dual period-varying preferences. Moreover, our model has been deployed online on Meituan Takeaway platform, leading to an average improvement in GMV (Gross Merchandise Value) of 0.70%.
MLE-based Device Activity Detection under Rician Fading for Massive Grant-free Access with Perfect and Imperfect Synchronization
Jun 11, 2023
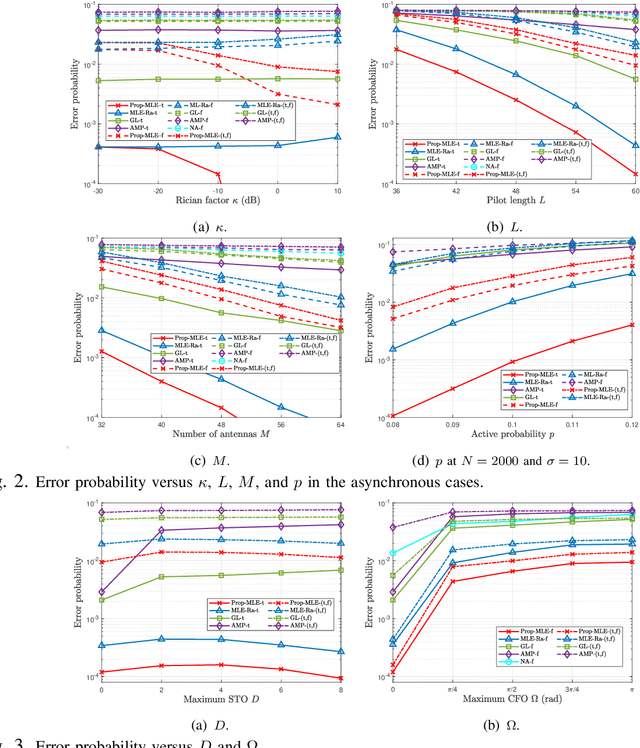
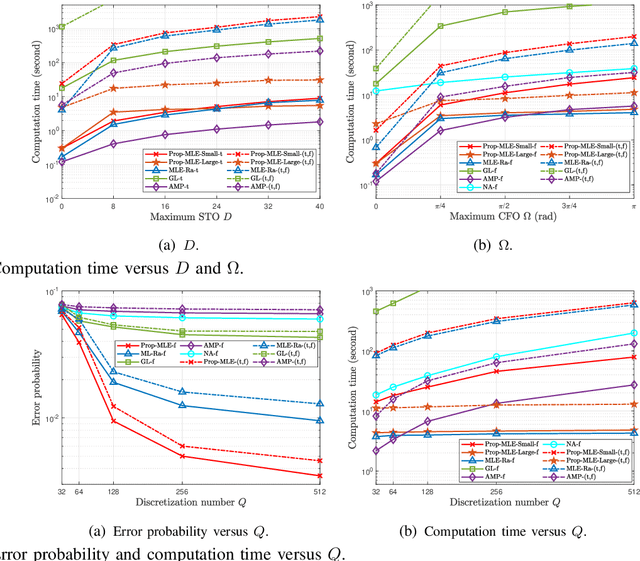
Most existing studies on massive grant-free access, proposed to support massive machine-type communications (mMTC) for the Internet of things (IoT), assume Rayleigh fading and perfect synchronization for simplicity. However, in practice, line-of-sight (LoS) components generally exist, and time and frequency synchronization are usually imperfect. This paper systematically investigates maximum likelihood estimation (MLE)-based device activity detection under Rician fading for massive grant-free access with perfect and imperfect synchronization. Specifically, we formulate device activity detection in the synchronous case and joint device activity and offset detection in three asynchronous cases (i.e., time, frequency, and time and frequency asynchronous cases) as MLE problems. In the synchronous case, we propose an iterative algorithm to obtain a stationary point of the MLE problem. In each asynchronous case, we propose two iterative algorithms with identical detection performance but different computational complexities. In particular, one is computationally efficient for small ranges of offsets, whereas the other one, relying on fast Fourier transform (FFT) and inverse FFT, is computationally efficient for large ranges of offsets. The proposed algorithms generalize the existing MLE-based methods for Rayleigh fading and perfect synchronization. Numerical results show the notable gains of the proposed algorithms over existing methods in detection accuracy and computation time.