 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Theoretical Guarantees of Learning Ensembling Strategies with Applications to Time Series Forecasting
May 26, 2023
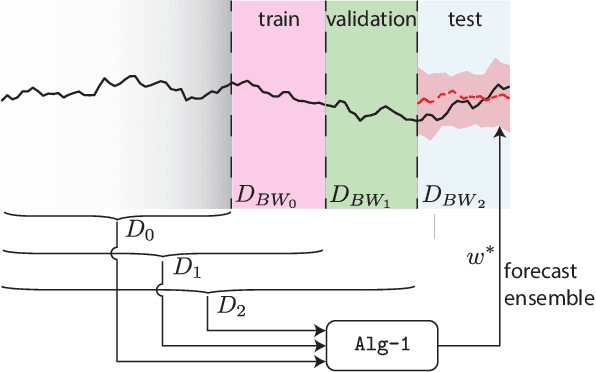
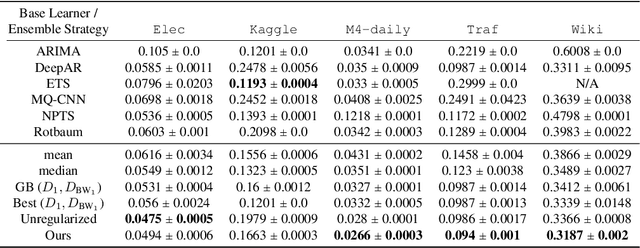
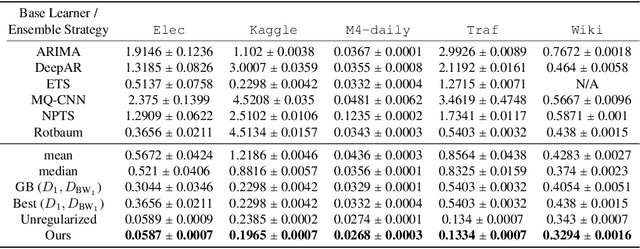
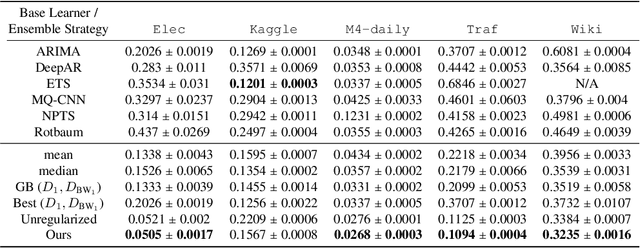
Ensembling is among the most popular tools in machine learning (ML) due to its effectiveness in minimizing variance and thus improving generalization. Most ensembling methods for black-box base learners fall under the umbrella of "stacked generalization," namely training an ML algorithm that takes the inferences from the base learners as input. While stacking has been widely applied in practice, its theoretical properties are poorly understood. In this paper, we prove a novel result, showing that choosing the best stacked generalization from a (finite or finite-dimensional) family of stacked generalizations based on cross-validated performance does not perform "much worse" than the oracle best. Our result strengthens and significantly extends the results in Van der Laan et al. (2007). Inspired by the theoretical analysis, we further propose a particular family of stacked generalizations in the context of probabilistic forecasting, each one with a different sensitivity for how much the ensemble weights are allowed to vary across items, timestamps in the forecast horizon, and quantiles. Experimental results demonstrate the performance gain of the proposed method.
A System for Differentiation of Schizophrenia and Bipolar Disorder based on rsfMRI
Jul 01, 2023
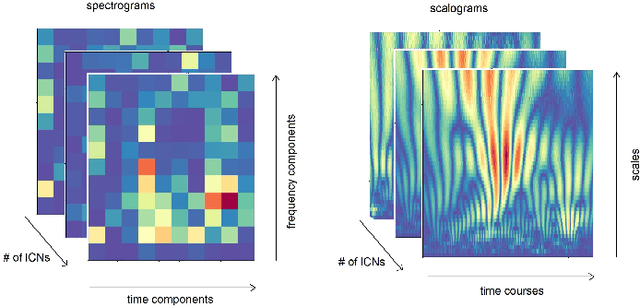
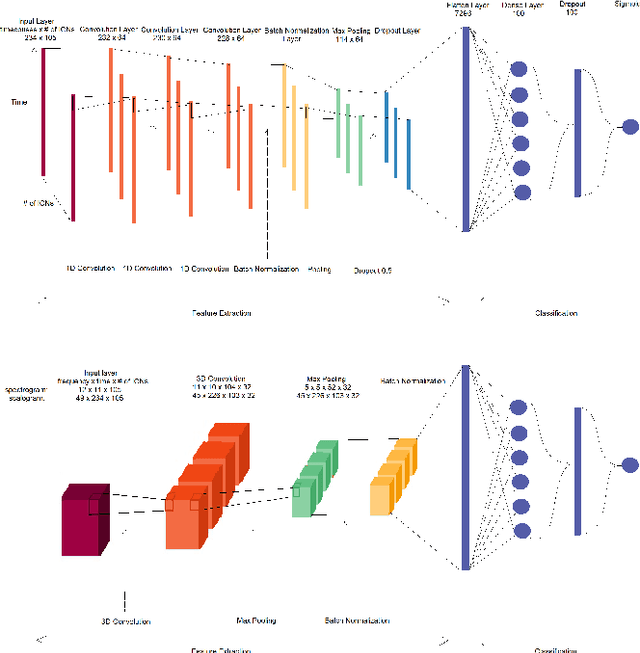
Schizophrenia and bipolar disorder are debilitating psychiatric illnesses that can be challenging to diagnose accurately. The similarities between the diseases make it difficult to differentiate between them using traditional diagnostic tools. Recently, resting-state functional magnetic resonance imaging (rsfMRI) has emerged as a promising tool for the diagnosis of psychiatric disorders. This paper presents several methods for differentiating schizophrenia and bipolar disorder based on features extracted from rsfMRI data. The system that achieved the best results, uses 1D Convolutional Neural Networks to analyze patterns of Intrinsic Connectivity time courses obtained from rsfMRI and potentially identify biomarkers that distinguish between the two disorders. We evaluate the system's performance on a large dataset of patients with schizophrenia and bipolar disorder and demonstrate that the system achieves a 0.7078 Area Under Curve (AUC) score in differentiating patients with these disorders. Our results suggest that rsfMRI-based classification systems have great potential for improving the accuracy of psychiatric diagnoses and may ultimately lead to more effective treatments for patients with this disorder.
Hiding in Plain Sight: Differential Privacy Noise Exploitation for Evasion-resilient Localized Poisoning Attacks in Multiagent Reinforcement Learning
Jul 01, 2023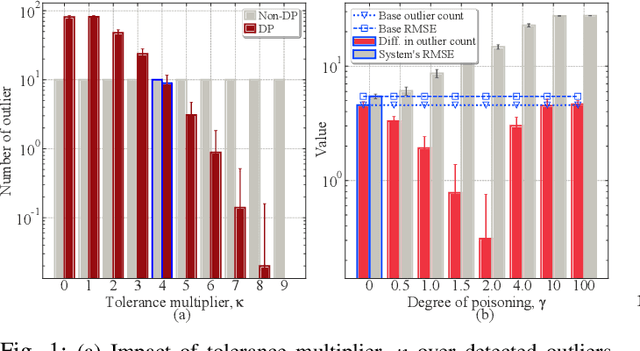
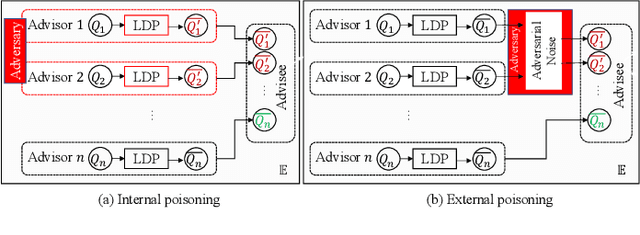
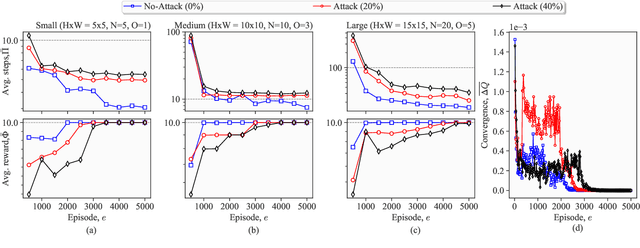

Lately, differential privacy (DP) has been introduced in cooperative multiagent reinforcement learning (CMARL) to safeguard the agents' privacy against adversarial inference during knowledge sharing. Nevertheless, we argue that the noise introduced by DP mechanisms may inadvertently give rise to a novel poisoning threat, specifically in the context of private knowledge sharing during CMARL, which remains unexplored in the literature. To address this shortcoming, we present an adaptive, privacy-exploiting, and evasion-resilient localized poisoning attack (PeLPA) that capitalizes on the inherent DP-noise to circumvent anomaly detection systems and hinder the optimal convergence of the CMARL model. We rigorously evaluate our proposed PeLPA attack in diverse environments, encompassing both non-adversarial and multiple-adversarial contexts. Our findings reveal that, in a medium-scale environment, the PeLPA attack with attacker ratios of 20% and 40% can lead to an increase in average steps to goal by 50.69% and 64.41%, respectively. Furthermore, under similar conditions, PeLPA can result in a 1.4x and 1.6x computational time increase in optimal reward attainment and a 1.18x and 1.38x slower convergence for attacker ratios of 20% and 40%, respectively.
Comparative Analysis of GPT-4 and Human Graders in Evaluating Praise Given to Students in Synthetic Dialogues
Jul 05, 2023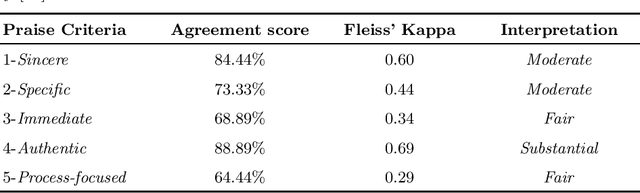
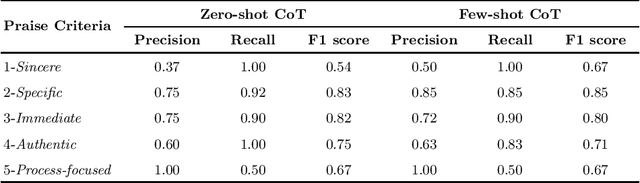
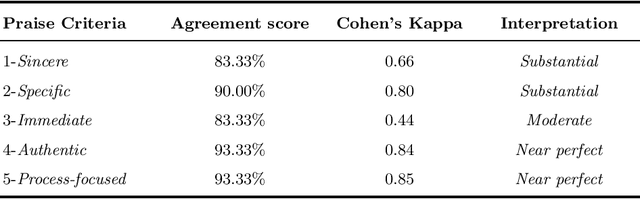
Research suggests that providing specific and timely feedback to human tutors enhances their performance. However, it presents challenges due to the time-consuming nature of assessing tutor performance by human evaluators. Large language models, such as the AI-chatbot ChatGPT, hold potential for offering constructive feedback to tutors in practical settings. Nevertheless, the accuracy of AI-generated feedback remains uncertain, with scant research investigating the ability of models like ChatGPT to deliver effective feedback. In this work-in-progress, we evaluate 30 dialogues generated by GPT-4 in a tutor-student setting. We use two different prompting approaches, the zero-shot chain of thought and the few-shot chain of thought, to identify specific components of effective praise based on five criteria. These approaches are then compared to the results of human graders for accuracy. Our goal is to assess the extent to which GPT-4 can accurately identify each praise criterion. We found that both zero-shot and few-shot chain of thought approaches yield comparable results. GPT-4 performs moderately well in identifying instances when the tutor offers specific and immediate praise. However, GPT-4 underperforms in identifying the tutor's ability to deliver sincere praise, particularly in the zero-shot prompting scenario where examples of sincere tutor praise statements were not provided. Future work will focus on enhancing prompt engineering, developing a more general tutoring rubric, and evaluating our method using real-life tutoring dialogues.
On the Universal Adversarial Perturbations for Efficient Data-free Adversarial Detection
Jun 27, 2023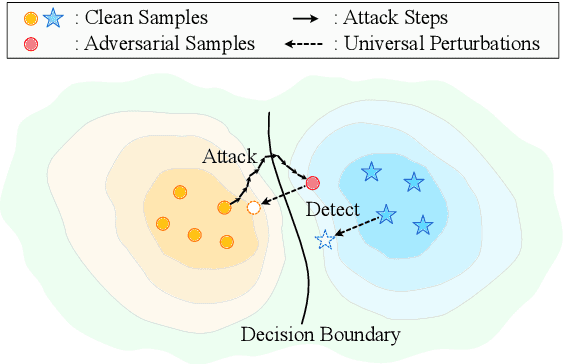


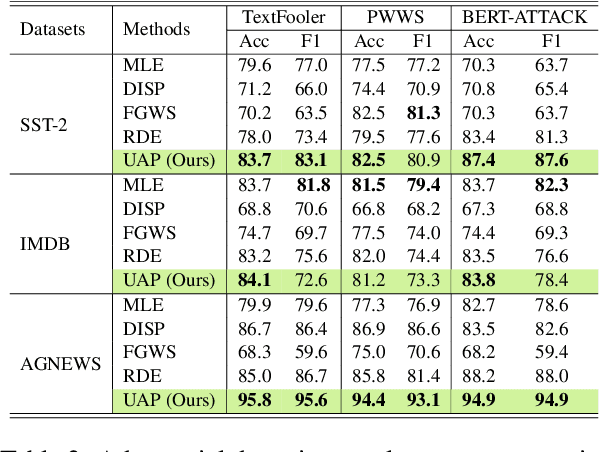
Detecting adversarial samples that are carefully crafted to fool the model is a critical step to socially-secure applications. However, existing adversarial detection methods require access to sufficient training data, which brings noteworthy concerns regarding privacy leakage and generalizability. In this work, we validate that the adversarial sample generated by attack algorithms is strongly related to a specific vector in the high-dimensional inputs. Such vectors, namely UAPs (Universal Adversarial Perturbations), can be calculated without original training data. Based on this discovery, we propose a data-agnostic adversarial detection framework, which induces different responses between normal and adversarial samples to UAPs. Experimental results show that our method achieves competitive detection performance on various text classification tasks, and maintains an equivalent time consumption to normal inference.
A Mixed-Integer Approach for Motion Planning of Nonholonomic Robots under Visible Light Communication Constraints
Jun 27, 2023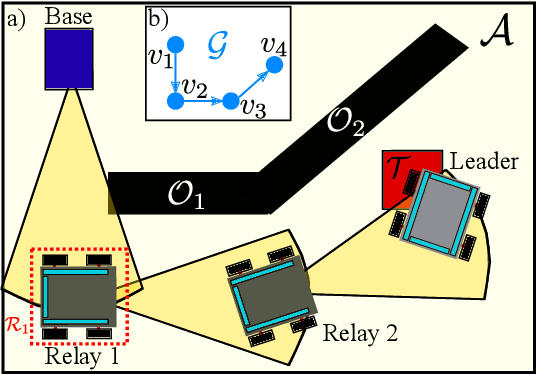
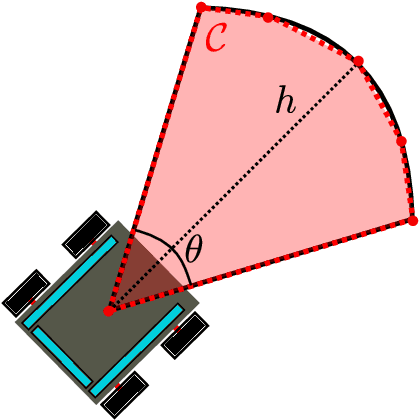
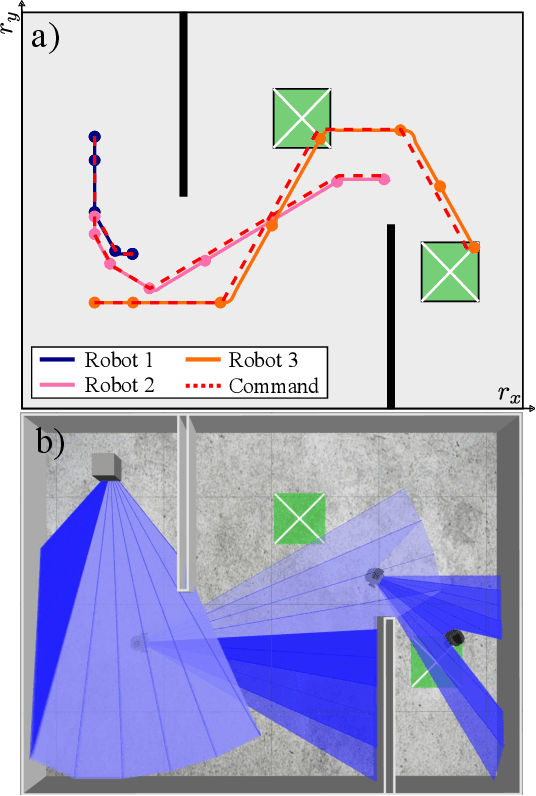
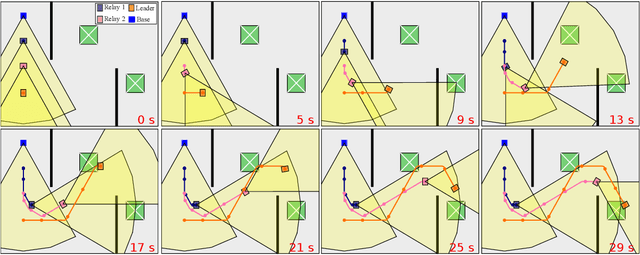
This work addresses the problem of motion planning for a group of nonholonomic robots under Visible Light Communication (VLC) connectivity requirements. In particular, we consider an inspection task performed by a Robot Chain Control System (RCCS), where a leader must visit relevant regions of an environment while the remaining robots operate as relays, maintaining the connectivity between the leader and a base station. We leverage Mixed-Integer Linear Programming (MILP) to design a trajectory planner that can coordinate the RCCS, minimizing time and control effort while also handling the issues of directed Line-Of-Sight (LOS), connectivity over directed networks, and the nonlinearity of the robots' dynamics. The efficacy of the proposal is demonstrated with realistic simulations in the Gazebo environment using the Turtlebot3 robot platform.
MLE-based Device Activity Detection under Rician Fading for Massive Grant-free Access with Perfect and Imperfect Synchronization
Jun 11, 2023
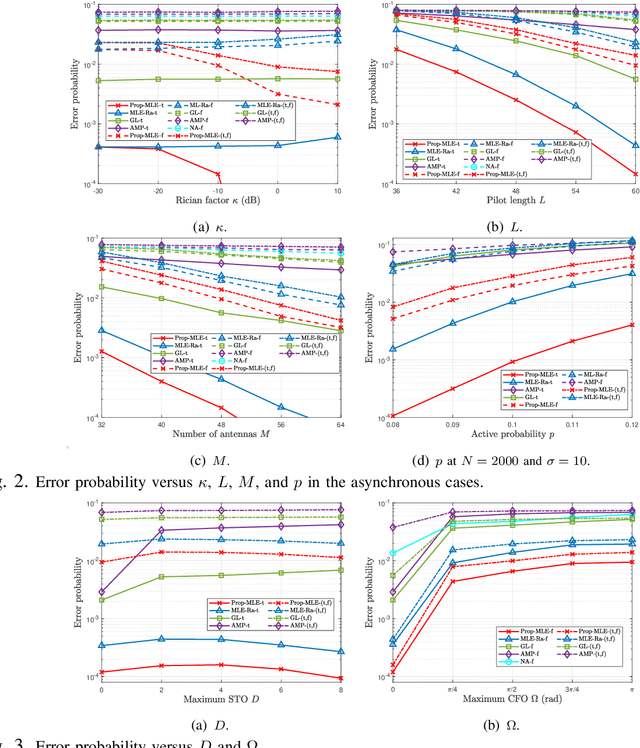
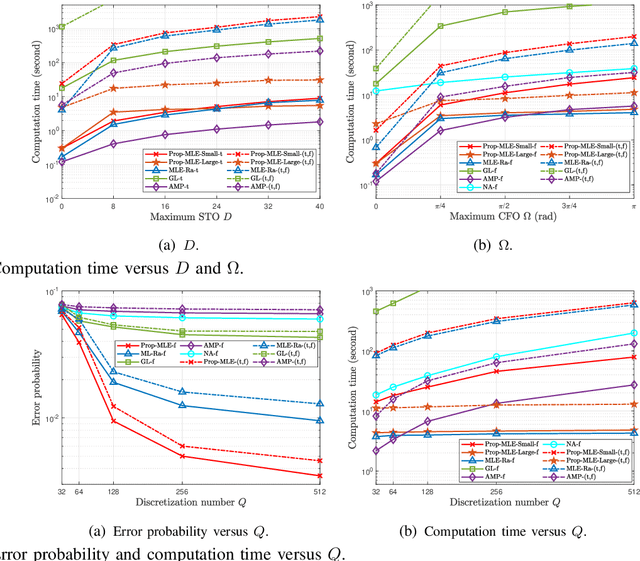
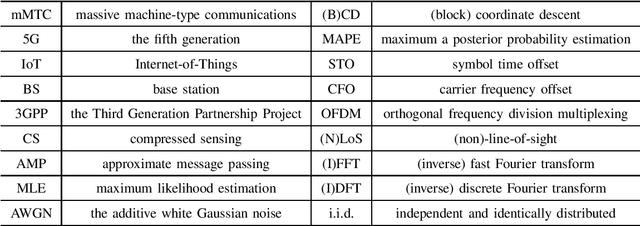
Most existing studies on massive grant-free access, proposed to support massive machine-type communications (mMTC) for the Internet of things (IoT), assume Rayleigh fading and perfect synchronization for simplicity. However, in practice, line-of-sight (LoS) components generally exist, and time and frequency synchronization are usually imperfect. This paper systematically investigates maximum likelihood estimation (MLE)-based device activity detection under Rician fading for massive grant-free access with perfect and imperfect synchronization. Specifically, we formulate device activity detection in the synchronous case and joint device activity and offset detection in three asynchronous cases (i.e., time, frequency, and time and frequency asynchronous cases) as MLE problems. In the synchronous case, we propose an iterative algorithm to obtain a stationary point of the MLE problem. In each asynchronous case, we propose two iterative algorithms with identical detection performance but different computational complexities. In particular, one is computationally efficient for small ranges of offsets, whereas the other one, relying on fast Fourier transform (FFT) and inverse FFT, is computationally efficient for large ranges of offsets. The proposed algorithms generalize the existing MLE-based methods for Rayleigh fading and perfect synchronization. Numerical results show the notable gains of the proposed algorithms over existing methods in detection accuracy and computation time.
TKN: Transformer-based Keypoint Prediction Network For Real-time Video Prediction
Mar 20, 2023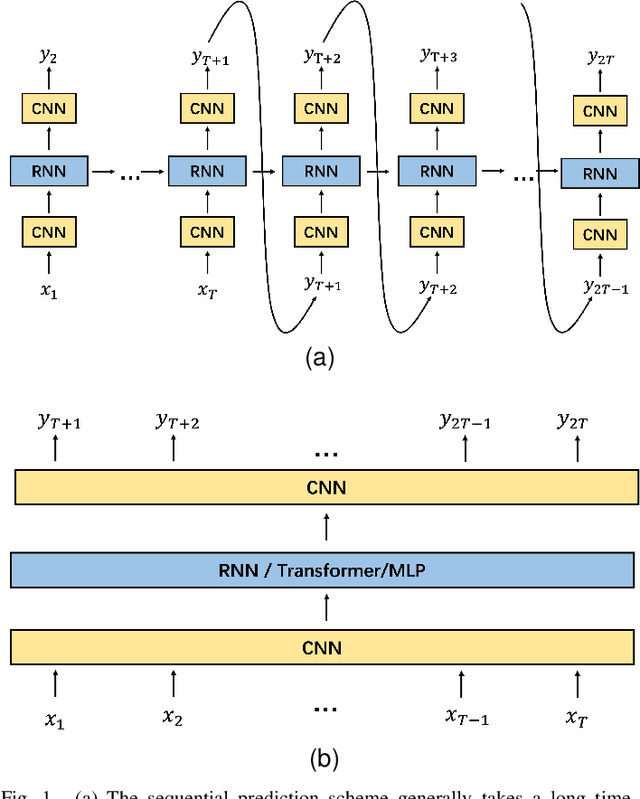
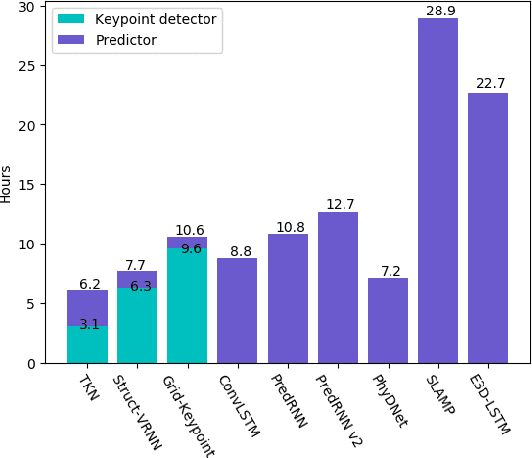

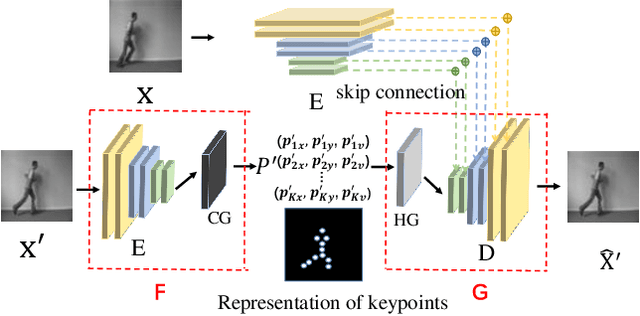
Video prediction is a complex time-series forecasting task with great potential in many use cases. However, conventional methods overemphasize accuracy while ignoring the slow prediction speed caused by complicated model structures that learn too much redundant information with excessive GPU memory consumption. Furthermore, conventional methods mostly predict frames sequentially (frame-by-frame) and thus are hard to accelerate. Consequently, valuable use cases such as real-time danger prediction and warning cannot achieve fast enough inference speed to be applicable in reality. Therefore, we propose a transformer-based keypoint prediction neural network (TKN), an unsupervised learning method that boost the prediction process via constrained information extraction and parallel prediction scheme. TKN is the first real-time video prediction solution to our best knowledge, while significantly reducing computation costs and maintaining other performance. Extensive experiments on KTH and Human3.6 datasets demonstrate that TKN predicts 11 times faster than existing methods while reducing memory consumption by 17.4% and achieving state-of-the-art prediction performance on average.
Modeling Dual Period-Varying Preferences for Takeaway Recommendation
Jun 16, 2023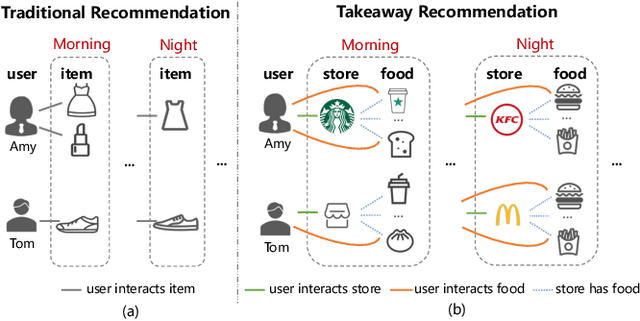
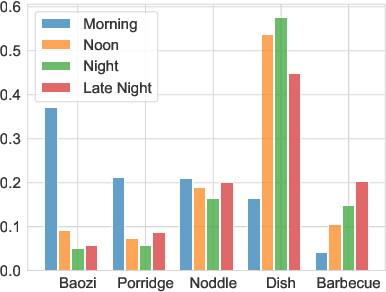
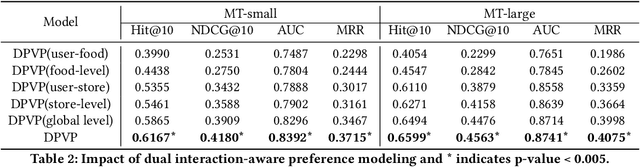
Takeaway recommender systems, which aim to accurately provide stores that offer foods meeting users' interests, have served billions of users in our daily life. Different from traditional recommendation, takeaway recommendation faces two main challenges: (1) Dual Interaction-Aware Preference Modeling. Traditional recommendation commonly focuses on users' single preferences for items while takeaway recommendation needs to comprehensively consider users' dual preferences for stores and foods. (2) Period-Varying Preference Modeling. Conventional recommendation generally models continuous changes in users' preferences from a session-level or day-level perspective. However, in practical takeaway systems, users' preferences vary significantly during the morning, noon, night, and late night periods of the day. To address these challenges, we propose a Dual Period-Varying Preference modeling (DPVP) for takeaway recommendation. Specifically, we design a dual interaction-aware module, aiming to capture users' dual preferences based on their interactions with stores and foods. Moreover, to model various preferences in different time periods of the day, we propose a time-based decomposition module as well as a time-aware gating mechanism. Extensive offline and online experiments demonstrate that our model outperforms state-of-the-art methods on real-world datasets and it is capable of modeling the dual period-varying preferences. Moreover, our model has been deployed online on Meituan Takeaway platform, leading to an average improvement in GMV (Gross Merchandise Value) of 0.70%.
Irregular Change Detection in Sparse Bi-Temporal Point Clouds using Learned Place Recognition Descriptors and Point-to-Voxel Comparison
Jul 04, 2023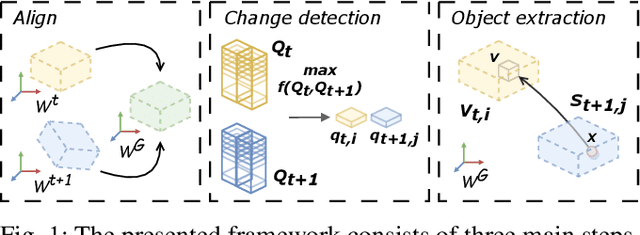
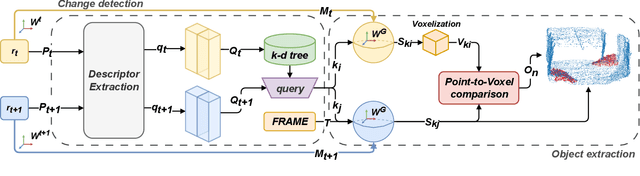
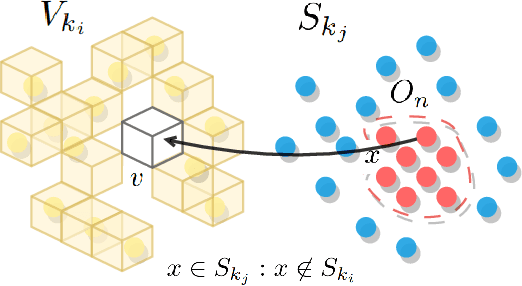
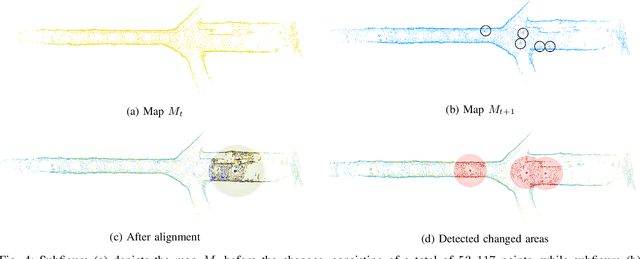
Change detection and irregular object extraction in 3D point clouds is a challenging task that is of high importance not only for autonomous navigation but also for updating existing digital twin models of various industrial environments. This article proposes an innovative approach for change detection in 3D point clouds using deep learned place recognition descriptors and irregular object extraction based on voxel-to-point comparison. The proposed method first aligns the bi-temporal point clouds using a map-merging algorithm in order to establish a common coordinate frame. Then, it utilizes deep learning techniques to extract robust and discriminative features from the 3D point cloud scans, which are used to detect changes between consecutive point cloud frames and therefore find the changed areas. Finally, the altered areas are sampled and compared between the two time instances to extract any obstructions that caused the area to change. The proposed method was successfully evaluated in real-world field experiments, where it was able to detect different types of changes in 3D point clouds, such as object or muck-pile addition and displacement, showcasing the effectiveness of the approach. The results of this study demonstrate important implications for various applications, including safety and security monitoring in construction sites, mapping and exploration and suggests potential future research directions in this field.