 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A System for Differentiation of Schizophrenia and Bipolar Disorder based on rsfMRI
Jul 01, 2023
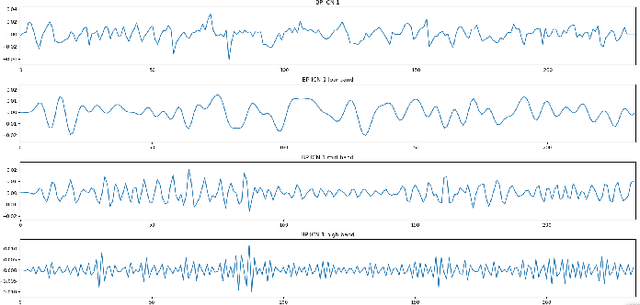
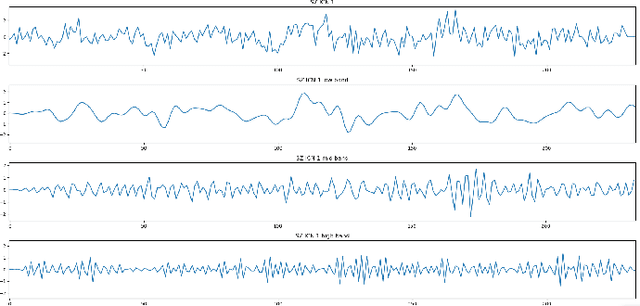
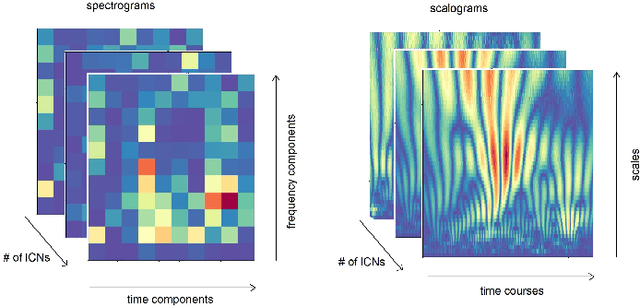
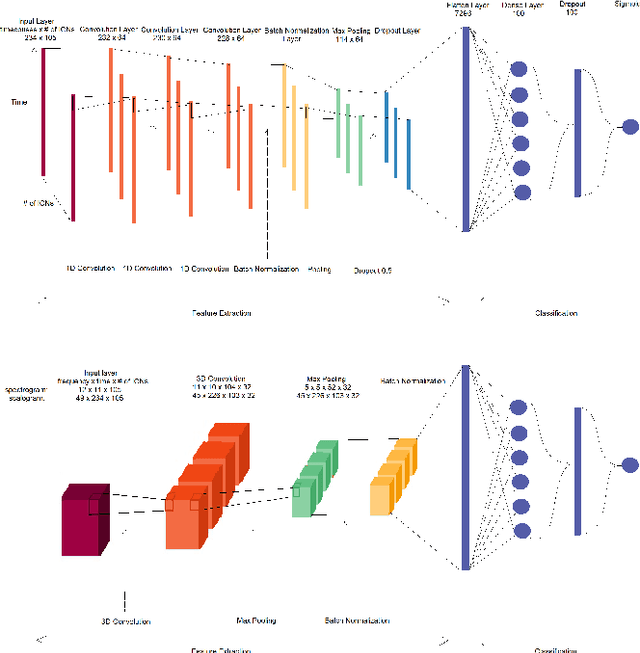
Schizophrenia and bipolar disorder are debilitating psychiatric illnesses that can be challenging to diagnose accurately. The similarities between the diseases make it difficult to differentiate between them using traditional diagnostic tools. Recently, resting-state functional magnetic resonance imaging (rsfMRI) has emerged as a promising tool for the diagnosis of psychiatric disorders. This paper presents several methods for differentiating schizophrenia and bipolar disorder based on features extracted from rsfMRI data. The system that achieved the best results, uses 1D Convolutional Neural Networks to analyze patterns of Intrinsic Connectivity time courses obtained from rsfMRI and potentially identify biomarkers that distinguish between the two disorders. We evaluate the system's performance on a large dataset of patients with schizophrenia and bipolar disorder and demonstrate that the system achieves a 0.7078 Area Under Curve (AUC) score in differentiating patients with these disorders. Our results suggest that rsfMRI-based classification systems have great potential for improving the accuracy of psychiatric diagnoses and may ultimately lead to more effective treatments for patients with this disorder.
Hiding in Plain Sight: Differential Privacy Noise Exploitation for Evasion-resilient Localized Poisoning Attacks in Multiagent Reinforcement Learning
Jul 01, 2023
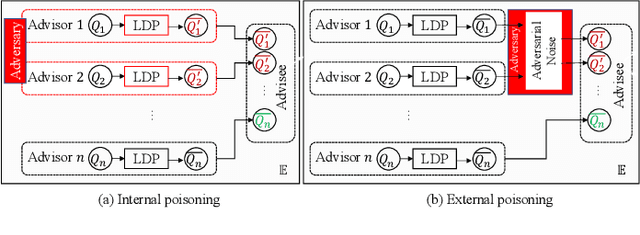
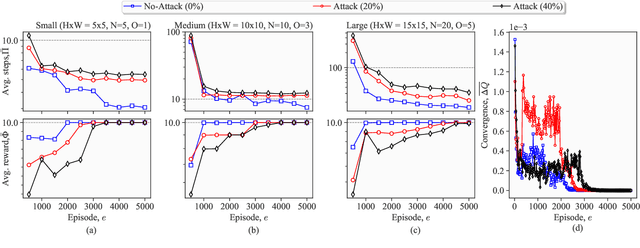

Lately, differential privacy (DP) has been introduced in cooperative multiagent reinforcement learning (CMARL) to safeguard the agents' privacy against adversarial inference during knowledge sharing. Nevertheless, we argue that the noise introduced by DP mechanisms may inadvertently give rise to a novel poisoning threat, specifically in the context of private knowledge sharing during CMARL, which remains unexplored in the literature. To address this shortcoming, we present an adaptive, privacy-exploiting, and evasion-resilient localized poisoning attack (PeLPA) that capitalizes on the inherent DP-noise to circumvent anomaly detection systems and hinder the optimal convergence of the CMARL model. We rigorously evaluate our proposed PeLPA attack in diverse environments, encompassing both non-adversarial and multiple-adversarial contexts. Our findings reveal that, in a medium-scale environment, the PeLPA attack with attacker ratios of 20% and 40% can lead to an increase in average steps to goal by 50.69% and 64.41%, respectively. Furthermore, under similar conditions, PeLPA can result in a 1.4x and 1.6x computational time increase in optimal reward attainment and a 1.18x and 1.38x slower convergence for attacker ratios of 20% and 40%, respectively.
Continuous time recurrent neural networks: overview and application to forecasting blood glucose in the intensive care unit
Apr 14, 2023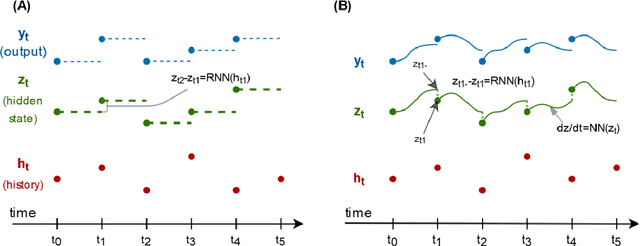
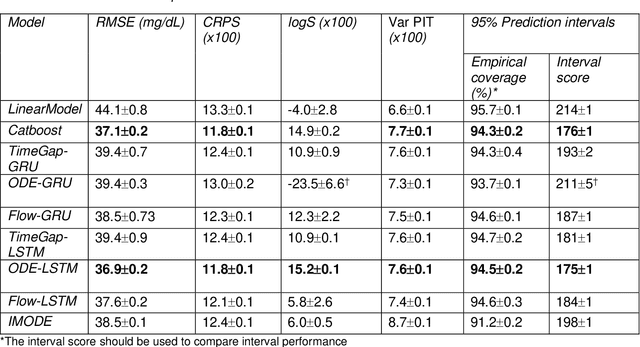

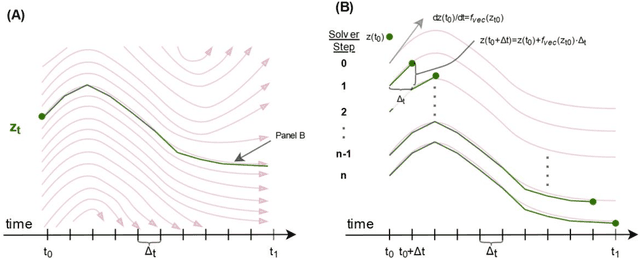
Irregularly measured time series are common in many of the applied settings in which time series modelling is a key statistical tool, including medicine. This provides challenges in model choice, often necessitating imputation or similar strategies. Continuous time autoregressive recurrent neural networks (CTRNNs) are a deep learning model that account for irregular observations through incorporating continuous evolution of the hidden states between observations. This is achieved using a neural ordinary differential equation (ODE) or neural flow layer. In this manuscript, we give an overview of these models, including the varying architectures that have been proposed to account for issues such as ongoing medical interventions. Further, we demonstrate the application of these models to probabilistic forecasting of blood glucose in a critical care setting using electronic medical record and simulated data. The experiments confirm that addition of a neural ODE or neural flow layer generally improves the performance of autoregressive recurrent neural networks in the irregular measurement setting. However, several CTRNN architecture are outperformed by an autoregressive gradient boosted tree model (Catboost), with only a long short-term memory (LSTM) and neural ODE based architecture (ODE-LSTM) achieving comparable performance on probabilistic forecasting metrics such as the continuous ranked probability score (ODE-LSTM: 0.118$\pm$0.001; Catboost: 0.118$\pm$0.001), ignorance score (0.152$\pm$0.008; 0.149$\pm$0.002) and interval score (175$\pm$1; 176$\pm$1).
Irregular Change Detection in Sparse Bi-Temporal Point Clouds using Learned Place Recognition Descriptors and Point-to-Voxel Comparison
Jul 04, 2023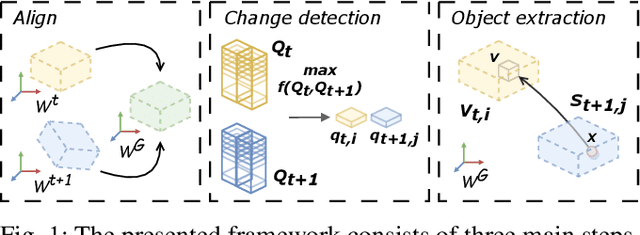
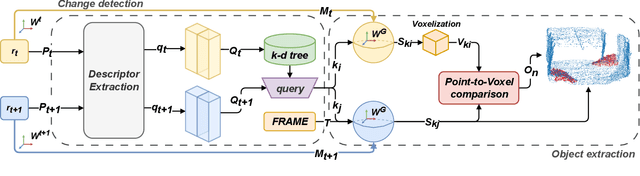
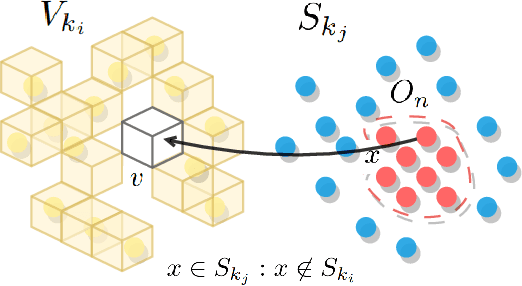
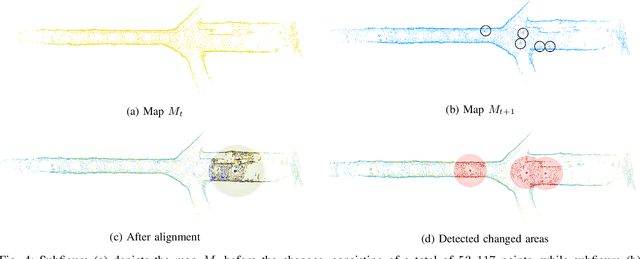
Change detection and irregular object extraction in 3D point clouds is a challenging task that is of high importance not only for autonomous navigation but also for updating existing digital twin models of various industrial environments. This article proposes an innovative approach for change detection in 3D point clouds using deep learned place recognition descriptors and irregular object extraction based on voxel-to-point comparison. The proposed method first aligns the bi-temporal point clouds using a map-merging algorithm in order to establish a common coordinate frame. Then, it utilizes deep learning techniques to extract robust and discriminative features from the 3D point cloud scans, which are used to detect changes between consecutive point cloud frames and therefore find the changed areas. Finally, the altered areas are sampled and compared between the two time instances to extract any obstructions that caused the area to change. The proposed method was successfully evaluated in real-world field experiments, where it was able to detect different types of changes in 3D point clouds, such as object or muck-pile addition and displacement, showcasing the effectiveness of the approach. The results of this study demonstrate important implications for various applications, including safety and security monitoring in construction sites, mapping and exploration and suggests potential future research directions in this field.
Knowledge-Aware Audio-Grounded Generative Slot Filling for Limited Annotated Data
Jul 04, 2023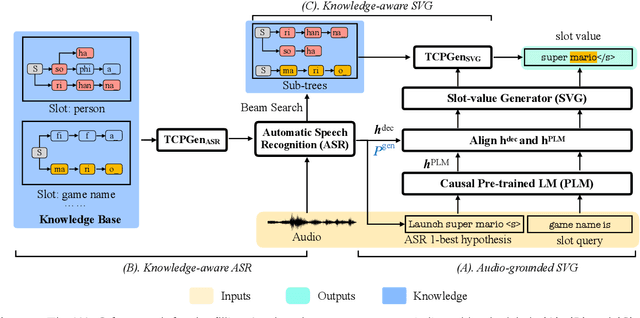
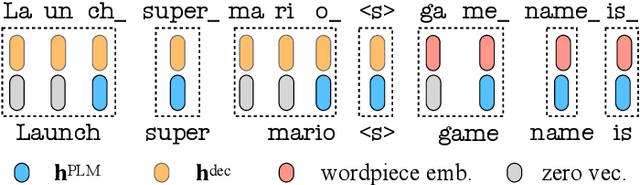

Manually annotating fine-grained slot-value labels for task-oriented dialogue (ToD) systems is an expensive and time-consuming endeavour. This motivates research into slot-filling methods that operate with limited amounts of labelled data. Moreover, the majority of current work on ToD is based solely on text as the input modality, neglecting the additional challenges of imperfect automatic speech recognition (ASR) when working with spoken language. In this work, we propose a Knowledge-Aware Audio-Grounded generative slot-filling framework, termed KA2G, that focuses on few-shot and zero-shot slot filling for ToD with speech input. KA2G achieves robust and data-efficient slot filling for speech-based ToD by 1) framing it as a text generation task, 2) grounding text generation additionally in the audio modality, and 3) conditioning on available external knowledge (e.g. a predefined list of possible slot values). We show that combining both modalities within the KA2G framework improves the robustness against ASR errors. Further, the knowledge-aware slot-value generator in KA2G, implemented via a pointer generator mechanism, particularly benefits few-shot and zero-shot learning. Experiments, conducted on the standard speech-based single-turn SLURP dataset and a multi-turn dataset extracted from a commercial ToD system, display strong and consistent gains over prior work, especially in few-shot and zero-shot setups.
A Proximal Algorithm for Network Slimming
Jul 02, 2023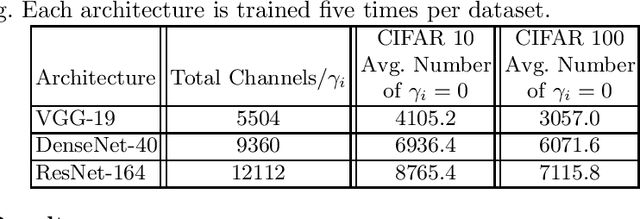
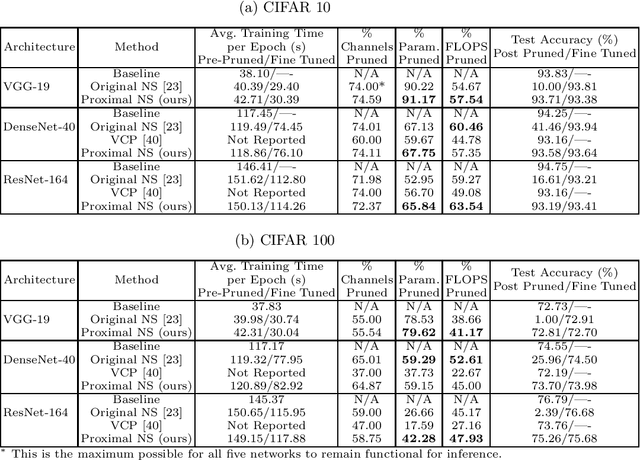
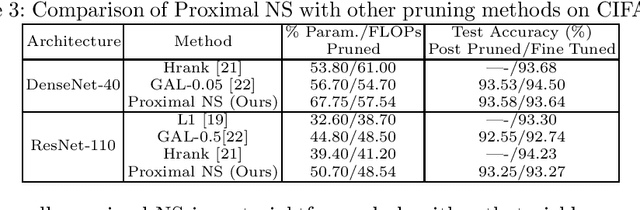
As a popular channel pruning method for convolutional neural networks (CNNs), network slimming (NS) has a three-stage process: (1) it trains a CNN with $\ell_1$ regularization applied to the scaling factors of the batch normalization layers; (2) it removes channels whose scaling factors are below a chosen threshold; and (3) it retrains the pruned model to recover the original accuracy. This time-consuming, three-step process is a result of using subgradient descent to train CNNs. Because subgradient descent does not exactly train CNNs towards sparse, accurate structures, the latter two steps are necessary. Moreover, subgradient descent does not have any convergence guarantee. Therefore, we develop an alternative algorithm called proximal NS. Our proposed algorithm trains CNNs towards sparse, accurate structures, so identifying a scaling factor threshold is unnecessary and fine tuning the pruned CNNs is optional. Using Kurdyka-{\L}ojasiewicz assumptions, we establish global convergence of proximal NS. Lastly, we validate the efficacy of the proposed algorithm on VGGNet, DenseNet and ResNet on CIFAR 10/100. Our experiments demonstrate that after one round of training, proximal NS yields a CNN with competitive accuracy and compression.
Online Heavy-tailed Change-point detection
Jul 03, 2023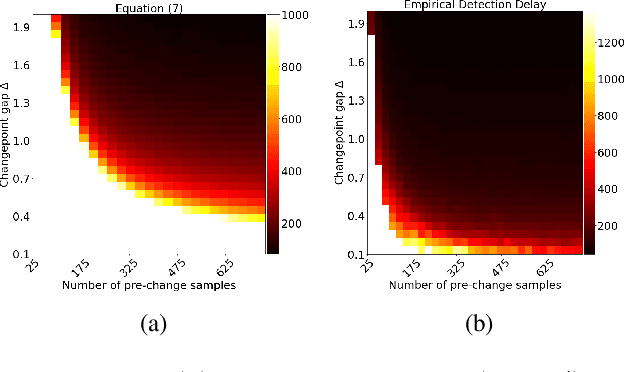
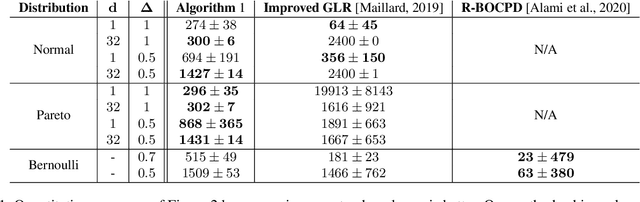
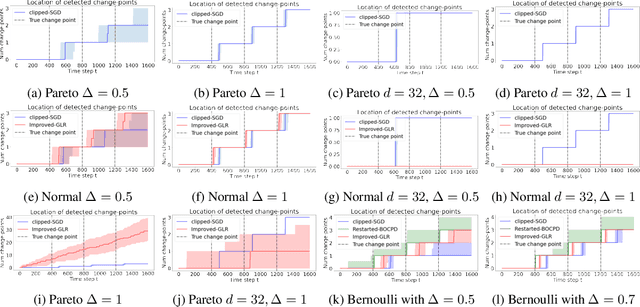

We study algorithms for online change-point detection (OCPD), where samples that are potentially heavy-tailed, are presented one at a time and a change in the underlying mean must be detected as early as possible. We present an algorithm based on clipped Stochastic Gradient Descent (SGD), that works even if we only assume that the second moment of the data generating process is bounded. We derive guarantees on worst-case, finite-sample false-positive rate (FPR) over the family of all distributions with bounded second moment. Thus, our method is the first OCPD algorithm that guarantees finite-sample FPR, even if the data is high dimensional and the underlying distributions are heavy-tailed. The technical contribution of our paper is to show that clipped-SGD can estimate the mean of a random vector and simultaneously provide confidence bounds at all confidence values. We combine this robust estimate with a union bound argument and construct a sequential change-point algorithm with finite-sample FPR guarantees. We show empirically that our algorithm works well in a variety of situations, whether the underlying data are heavy-tailed, light-tailed, high dimensional or discrete. No other algorithm achieves bounded FPR theoretically or empirically, over all settings we study simultaneously.
Neural 3D Scene Reconstruction from Multi-view Images without 3D Supervision
Jul 03, 2023
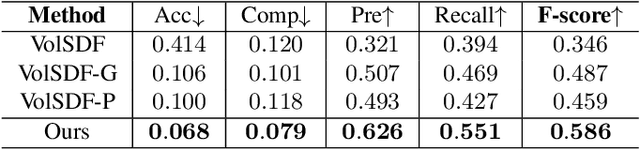
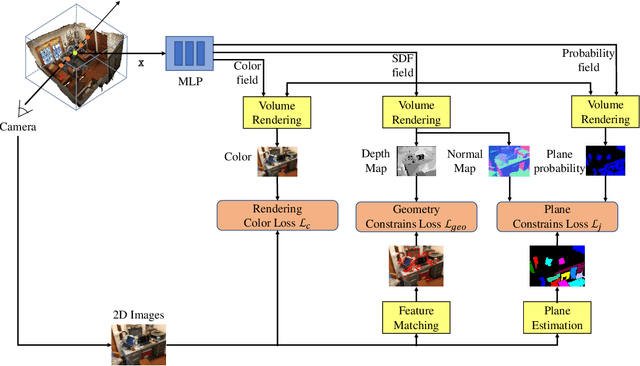
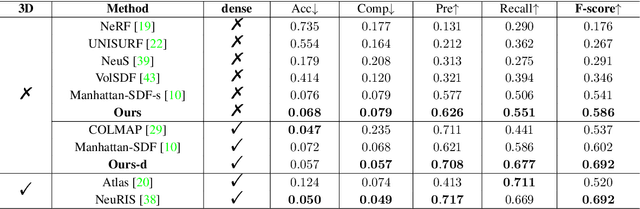
Neural scene reconstruction methods have achieved impressive performance in reconstructing complex geometry and low-textured regions in large scenes. However, these methods heavily rely on 3D supervised information which is costly and time-consuming to obtain in the real world. In this paper, we propose a novel neural reconstruction method that reconstructs scenes without 3D supervision. We perform differentiable volume rendering for scene reconstruction by using accessible 2D images as supervision. We impose geometry to improve the reconstruction quality of complex geometry regions in the scenes, and impose plane constraints to improve the reconstruction quality of low-textured regions in the scenes. Specifically, we introduce a signed distance function (SDF) field, a color field, and a probability field to represent the scene, and optimize the fields under the differentiable ray marching to reconstruct the scene. Besides, we impose geometric constraints that project 3D points on the surface to similar-looking regions with similar features in different views. We also impose plane constraints to make large planes keep parallel or vertical to the wall or floor. These two constraints help to reconstruct accurate and smooth geometry structures of the scene. Without 3D supervision information, our method achieves competitive reconstruction compared with some existing methods that use 3D information as supervision on the ScanNet dataset.
ChatGPT vs. Google: A Comparative Study of Search Performance and User Experience
Jul 03, 2023
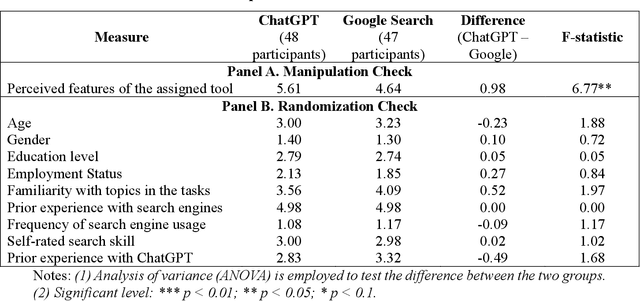
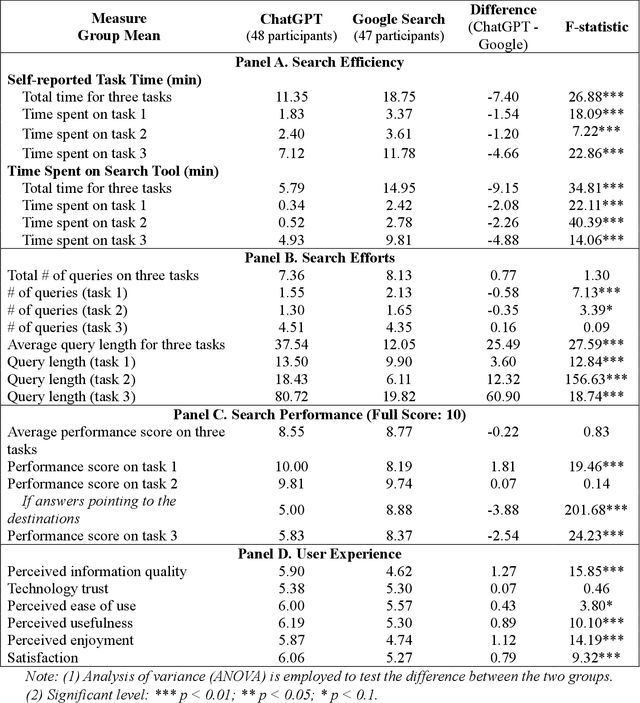
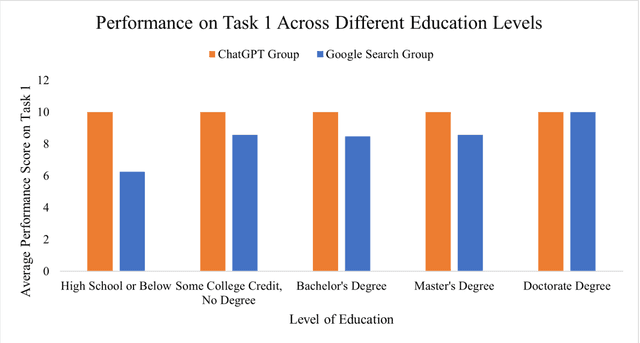
The advent of ChatGPT, a large language model-powered chatbot, has prompted questions about its potential implications for traditional search engines. In this study, we investigate the differences in user behavior when employing search engines and chatbot tools for information-seeking tasks. We carry out a randomized online experiment, dividing participants into two groups: one using a ChatGPT-like tool and the other using a Google Search-like tool. Our findings reveal that the ChatGPT group consistently spends less time on all tasks, with no significant difference in overall task performance between the groups. Notably, ChatGPT levels user search performance across different education levels and excels in answering straightforward questions and providing general solutions but falls short in fact-checking tasks. Users perceive ChatGPT's responses as having higher information quality compared to Google Search, despite displaying a similar level of trust in both tools. Furthermore, participants using ChatGPT report significantly better user experiences in terms of usefulness, enjoyment, and satisfaction, while perceived ease of use remains comparable between the two tools. However, ChatGPT may also lead to overreliance and generate or replicate misinformation, yielding inconsistent results. Our study offers valuable insights for search engine management and highlights opportunities for integrating chatbot technologies into search engine designs.
Spatio-Temporal Surrogates for Interaction of a Jet with High Explosives: Part I -- Analysis with a Small Sample Size
Jul 03, 2023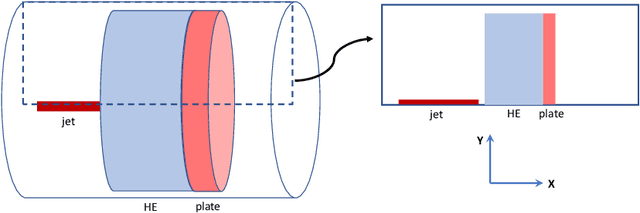
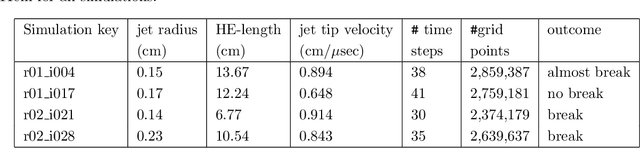
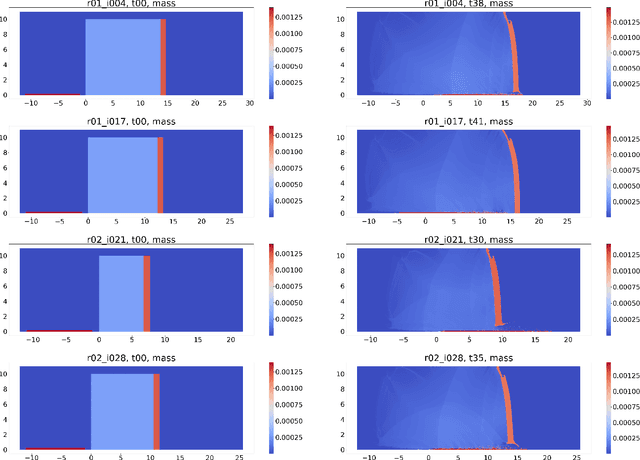
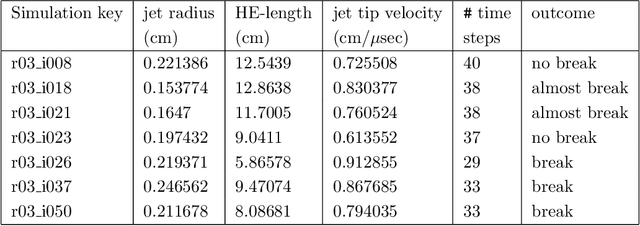
Computer simulations, especially of complex phenomena, can be expensive, requiring high-performance computing resources. Often, to understand a phenomenon, multiple simulations are run, each with a different set of simulation input parameters. These data are then used to create an interpolant, or surrogate, relating the simulation outputs to the corresponding inputs. When the inputs and outputs are scalars, a simple machine learning model can suffice. However, when the simulation outputs are vector valued, available at locations in two or three spatial dimensions, often with a temporal component, creating a surrogate is more challenging. In this report, we use a two-dimensional problem of a jet interacting with high explosives to understand how we can build high-quality surrogates. The characteristics of our data set are unique - the vector-valued outputs from each simulation are available at over two million spatial locations; each simulation is run for a relatively small number of time steps; the size of the computational domain varies with each simulation; and resource constraints limit the number of simulations we can run. We show how we analyze these extremely large data-sets, set the parameters for the algorithms used in the analysis, and use simple ways to improve the accuracy of the spatio-temporal surrogates without substantially increasing the number of simulations required.