 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Explainable AI for Channel Estimation in Wireless Communications
Jul 03, 2023
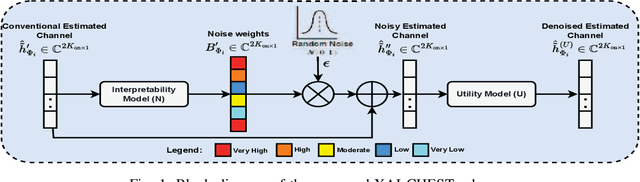
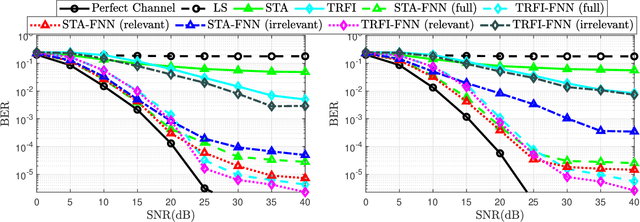
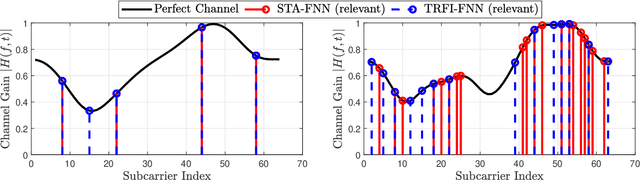

Research into 6G networks has been initiated to support a variety of critical artificial intelligence (AI) assisted applications such as autonomous driving. In such applications, AI-based decisions should be performed in a real-time manner. These decisions include resource allocation, localization, channel estimation, etc. Considering the black-box nature of existing AI-based models, it is highly challenging to understand and trust the decision-making behavior of such models. Therefore, explaining the logic behind those models through explainable AI (XAI) techniques is essential for their employment in critical applications. This manuscript proposes a novel XAI-based channel estimation (XAI-CHEST) scheme that provides detailed reasonable interpretability of the deep learning (DL) models that are employed in doubly-selective channel estimation. The aim of the proposed XAI-CHEST scheme is to identify the relevant model inputs by inducing high noise on the irrelevant ones. As a result, the behavior of the studied DL-based channel estimators can be further analyzed and evaluated based on the generated interpretations. Simulation results show that the proposed XAI-CHEST scheme provides valid interpretations of the DL-based channel estimators for different scenarios.
Patch-CNN: Training data-efficient deep learning for high-fidelity diffusion tensor estimation from minimal diffusion protocols
Jul 03, 2023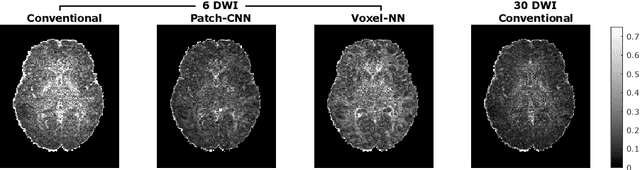
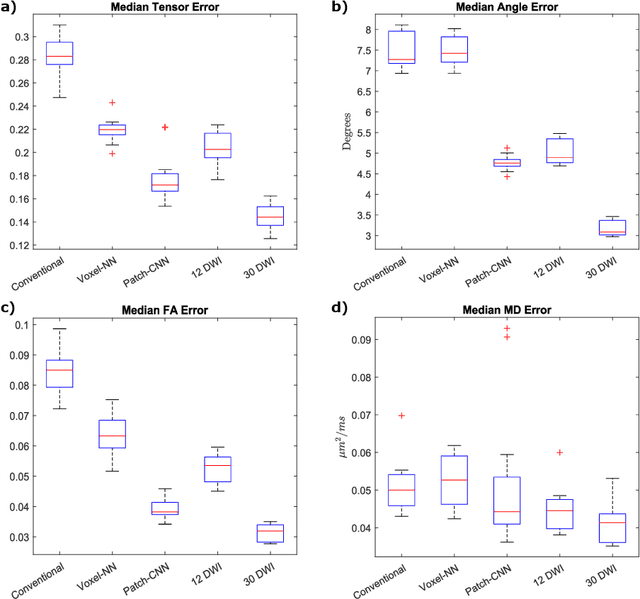
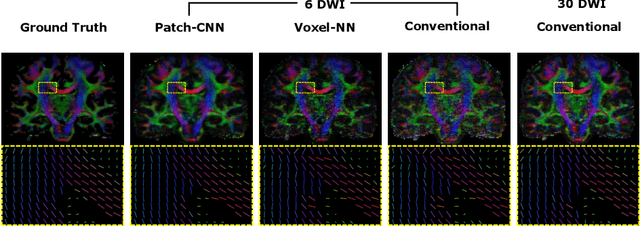
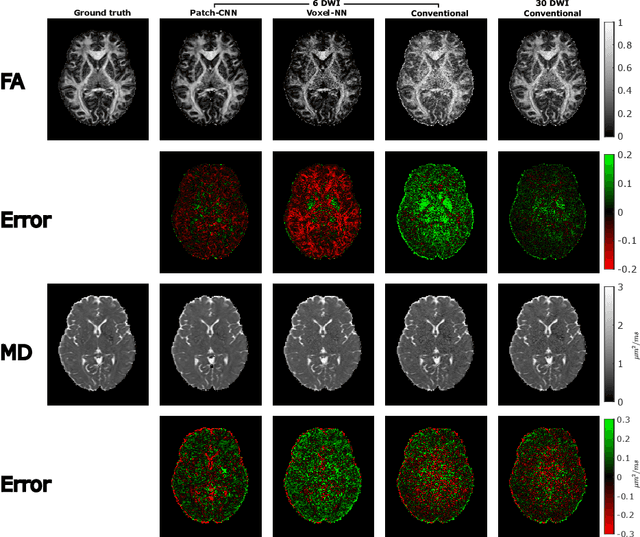
We propose a new method, Patch-CNN, for diffusion tensor (DT) estimation from only six-direction diffusion weighted images (DWI). Deep learning-based methods have been recently proposed for dMRI parameter estimation, using either voxel-wise fully-connected neural networks (FCN) or image-wise convolutional neural networks (CNN). In the acute clinical context -- where pressure of time limits the number of imaged directions to a minimum -- existing approaches either require an infeasible number of training images volumes (image-wise CNNs), or do not estimate the fibre orientations (voxel-wise FCNs) required for tractogram estimation. To overcome these limitations, we propose Patch-CNN, a neural network with a minimal (non-voxel-wise) convolutional kernel (3$\times$3$\times$3). Compared with voxel-wise FCNs, this has the advantage of allowing the network to leverage local anatomical information. Compared with image-wise CNNs, the minimal kernel vastly reduces training data demand. Evaluated against both conventional model fitting and a voxel-wise FCN, Patch-CNN, trained with a single subject is shown to improve the estimation of both scalar dMRI parameters and fibre orientation from six-direction DWIs. The improved fibre orientation estimation is shown to produce improved tractogram.
Towards Suicide Prevention from Bipolar Disorder with Temporal Symptom-Aware Multitask Learning
Jul 03, 2023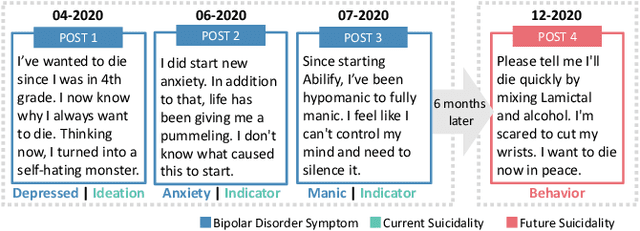
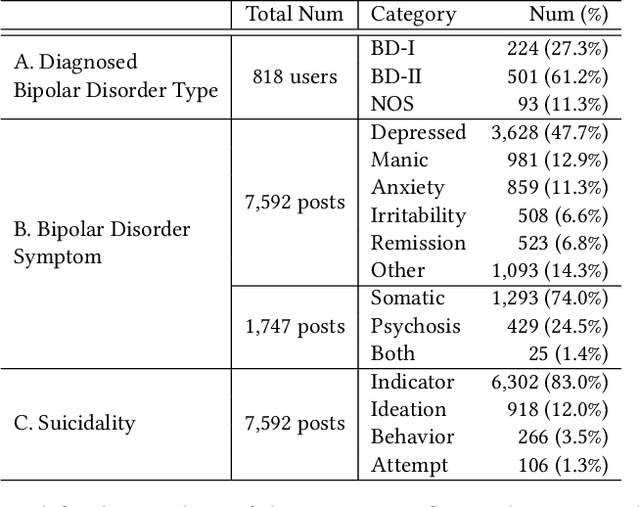
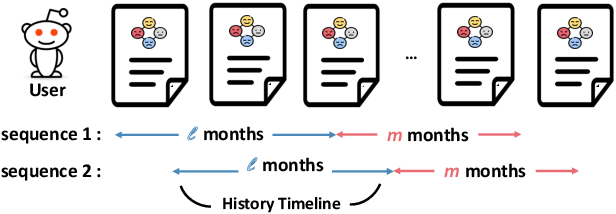
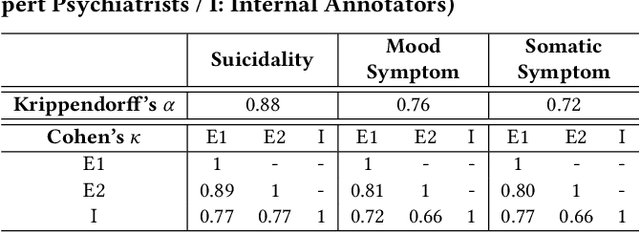
Bipolar disorder (BD) is closely associated with an increased risk of suicide. However, while the prior work has revealed valuable insight into understanding the behavior of BD patients on social media, little attention has been paid to developing a model that can predict the future suicidality of a BD patient. Therefore, this study proposes a multi-task learning model for predicting the future suicidality of BD patients by jointly learning current symptoms. We build a novel BD dataset clinically validated by psychiatrists, including 14 years of posts on bipolar-related subreddits written by 818 BD patients, along with the annotations of future suicidality and BD symptoms. We also suggest a temporal symptom-aware attention mechanism to determine which symptoms are the most influential for predicting future suicidality over time through a sequence of BD posts. Our experiments demonstrate that the proposed model outperforms the state-of-the-art models in both BD symptom identification and future suicidality prediction tasks. In addition, the proposed temporal symptom-aware attention provides interpretable attention weights, helping clinicians to apprehend BD patients more comprehensively and to provide timely intervention by tracking mental state progression.
* KDD 2023 accepted
VINECS: Video-based Neural Character Skinning
Jul 03, 2023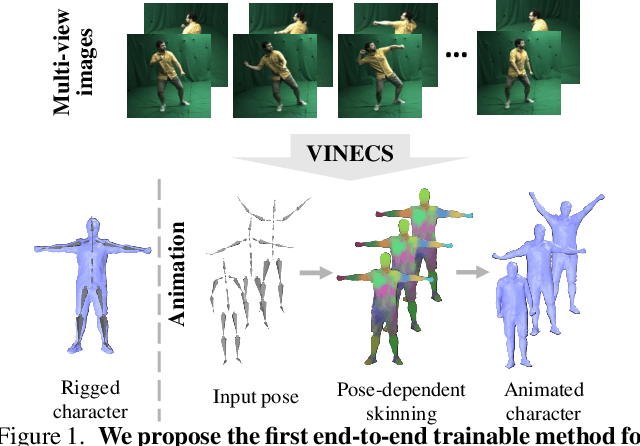
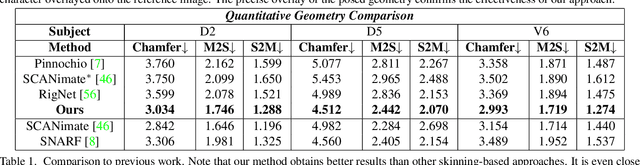
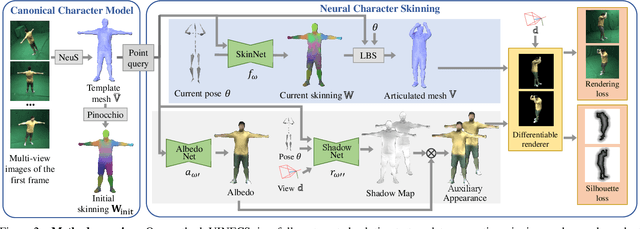
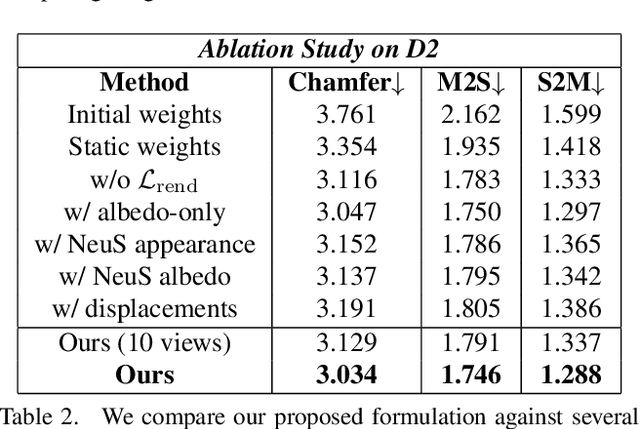
Rigging and skinning clothed human avatars is a challenging task and traditionally requires a lot of manual work and expertise. Recent methods addressing it either generalize across different characters or focus on capturing the dynamics of a single character observed under different pose configurations. However, the former methods typically predict solely static skinning weights, which perform poorly for highly articulated poses, and the latter ones either require dense 3D character scans in different poses or cannot generate an explicit mesh with vertex correspondence over time. To address these challenges, we propose a fully automated approach for creating a fully rigged character with pose-dependent skinning weights, which can be solely learned from multi-view video. Therefore, we first acquire a rigged template, which is then statically skinned. Next, a coordinate-based MLP learns a skinning weights field parameterized over the position in a canonical pose space and the respective pose. Moreover, we introduce our pose- and view-dependent appearance field allowing us to differentiably render and supervise the posed mesh using multi-view imagery. We show that our approach outperforms state-of-the-art while not relying on dense 4D scans.
Capturing Local Temperature Evolution during Additive Manufacturing through Fourier Neural Operators
Jul 04, 2023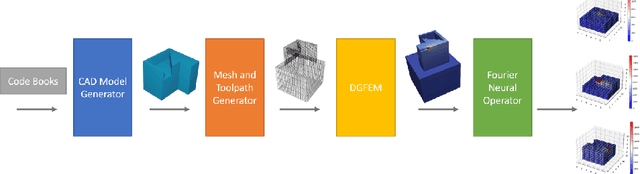
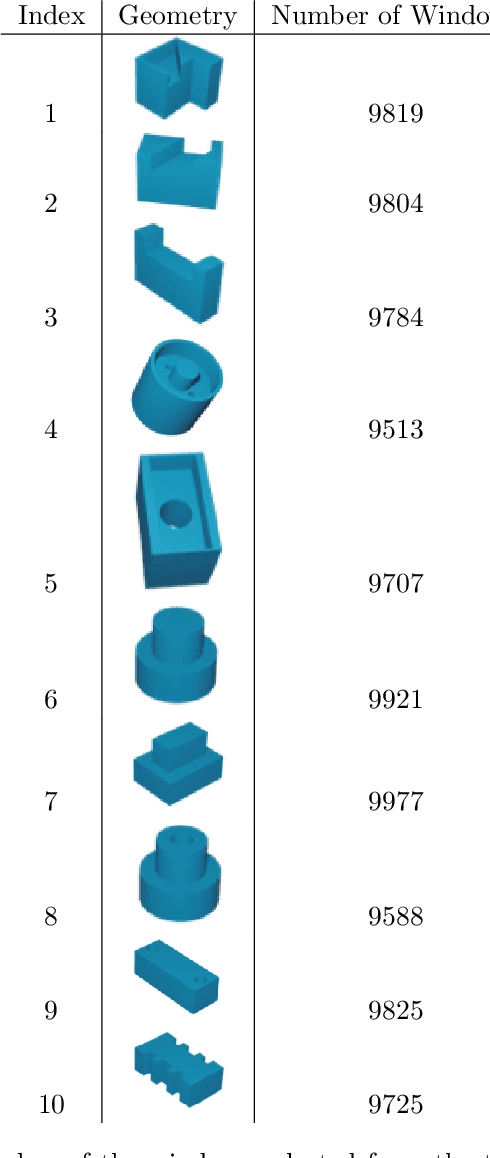

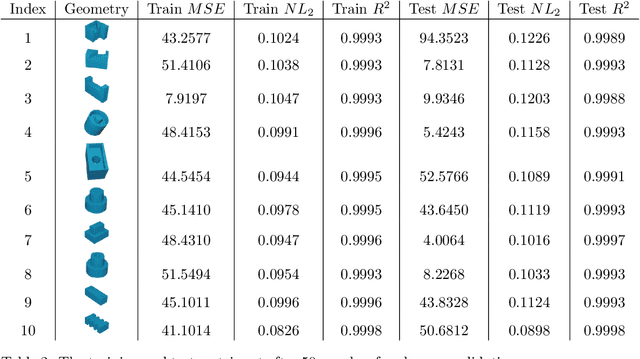
High-fidelity, data-driven models that can quickly simulate thermal behavior during additive manufacturing (AM) are crucial for improving the performance of AM technologies in multiple areas, such as part design, process planning, monitoring, and control. However, the complexities of part geometries make it challenging for current models to maintain high accuracy across a wide range of geometries. Additionally, many models report a low mean square error (MSE) across the entire domain (part). However, in each time step, most areas of the domain do not experience significant changes in temperature, except for the heat-affected zones near recent depositions. Therefore, the MSE-based fidelity measurement of the models may be overestimated. This paper presents a data-driven model that uses Fourier Neural Operator to capture the local temperature evolution during the additive manufacturing process. In addition, the authors propose to evaluate the model using the $R^2$ metric, which provides a relative measure of the model's performance compared to using mean temperature as a prediction. The model was tested on numerical simulations based on the Discontinuous Galerkin Finite Element Method for the Direct Energy Deposition process, and the results demonstrate that the model achieves high fidelity as measured by $R^2$ and maintains generalizability to geometries that were not included in the training process.
Knowledge Graph for NLG in the context of conversational agents
Jul 04, 2023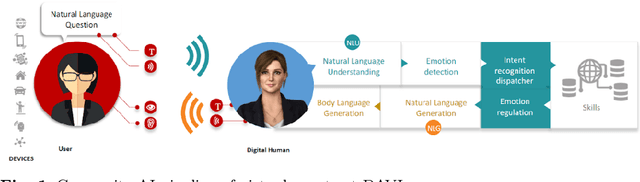
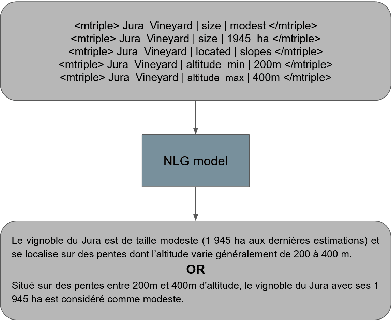
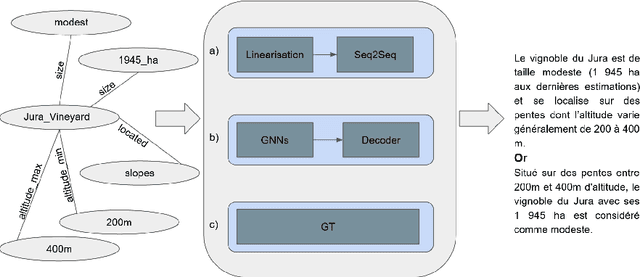
The use of knowledge graphs (KGs) enhances the accuracy and comprehensiveness of the responses provided by a conversational agent. While generating answers during conversations consists in generating text from these KGs, it is still regarded as a challenging task that has gained significant attention in recent years. In this document, we provide a review of different architectures used for knowledge graph-to-text generation including: Graph Neural Networks, the Graph Transformer, and linearization with seq2seq models. We discuss the advantages and limitations of each architecture and conclude that the choice of architecture will depend on the specific requirements of the task at hand. We also highlight the importance of considering constraints such as execution time and model validity, particularly in the context of conversational agents. Based on these constraints and the availability of labeled data for the domains of DAVI, we choose to use seq2seq Transformer-based models (PLMs) for the Knowledge Graph-to-Text Generation task. We aim to refine benchmark datasets of kg-to-text generation on PLMs and to explore the emotional and multilingual dimensions in our future work. Overall, this review provides insights into the different approaches for knowledge graph-to-text generation and outlines future directions for research in this area.
S.T.A.R.-Track: Latent Motion Models for End-to-End 3D Object Tracking with Adaptive Spatio-Temporal Appearance Representations
Jun 30, 2023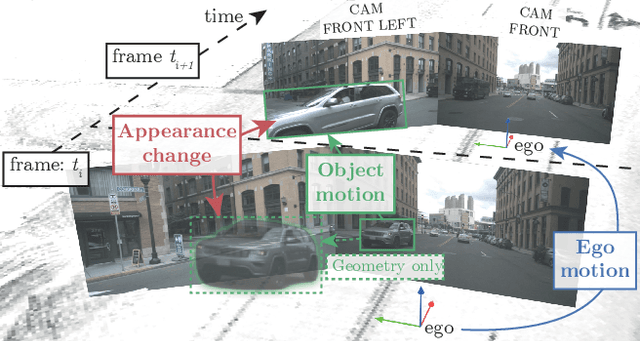
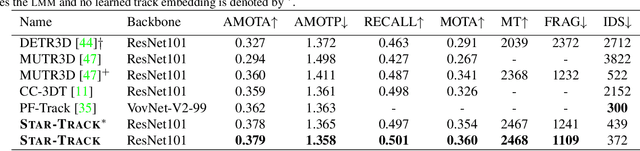
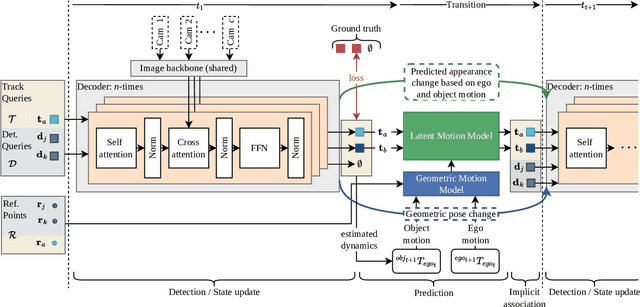
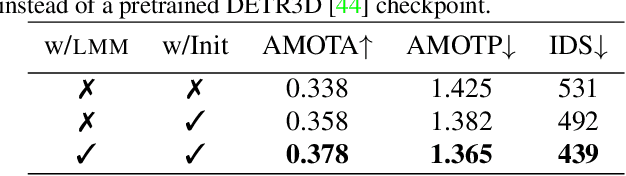
Following the tracking-by-attention paradigm, this paper introduces an object-centric, transformer-based framework for tracking in 3D. Traditional model-based tracking approaches incorporate the geometric effect of object- and ego motion between frames with a geometric motion model. Inspired by this, we propose S.T.A.R.-Track, which uses a novel latent motion model (LMM) to additionally adjust object queries to account for changes in viewing direction and lighting conditions directly in the latent space, while still modeling the geometric motion explicitly. Combined with a novel learnable track embedding that aids in modeling the existence probability of tracks, this results in a generic tracking framework that can be integrated with any query-based detector. Extensive experiments on the nuScenes benchmark demonstrate the benefits of our approach, showing state-of-the-art performance for DETR3D-based trackers while drastically reducing the number of identity switches of tracks at the same time.
Theoretical Analysis of Heterodyne Rydberg Atomic Receiver Sensitivity Based on Transit Relaxation Effect and Frequency Detuning
Jun 30, 2023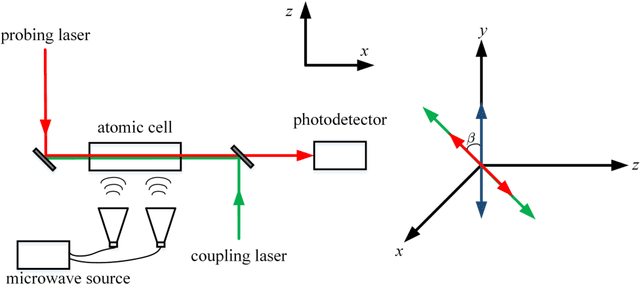
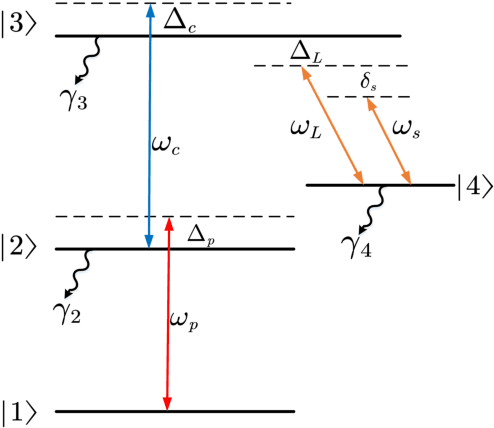
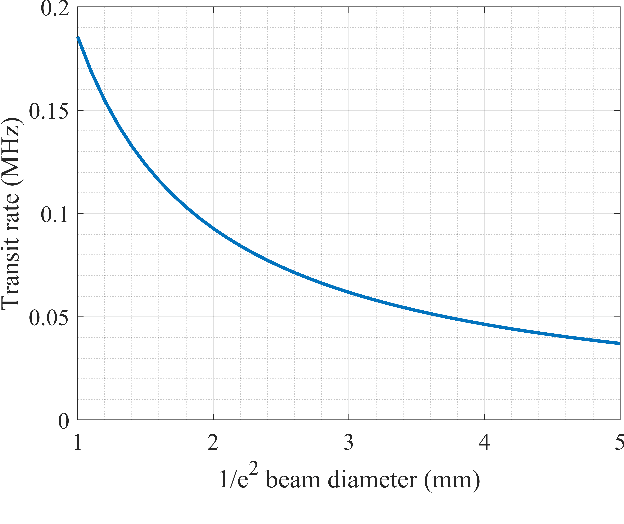
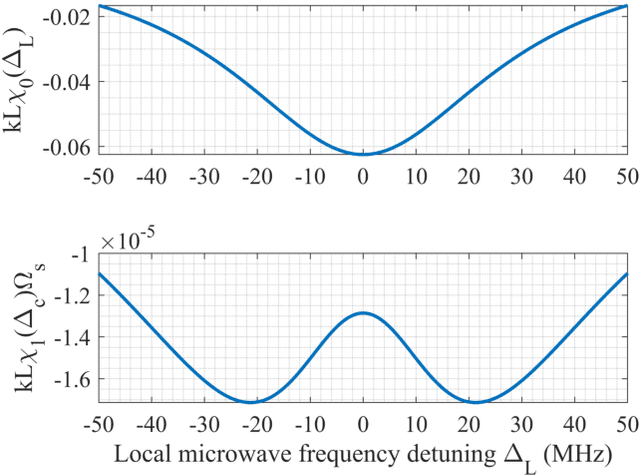
We conduct a theoretical investigation into the impacts of local microwave electric field frequency detuning, laser frequency detuning, and transit relaxation rate on enhancing heterodyne Rydberg atomic receiver sensitivity. To optimize the output signal amplitude given the input microwave signal, we derive the steady-state solutions of the atomic density matrix. Numerical results show that laser frequency detuning and local microwave electric field frequency detuning can improve the system detection sensitivity, which can help the system achieve extra sensitivity gain. It also shows that the heterodyne Rydberg atomic receiver can detect weak microwave signals continuously over a wide frequency range with the same sensitivity or even more sensitivity than the resonance case. To evaluate the transit relaxation effect, a modified Liouville equation is used. We find that the transition relaxation rate increases the time it takes to reach steady state and decreases the sensitivity of the system detection.
Contextual Dynamic Pricing with Strategic Buyers
Jul 08, 2023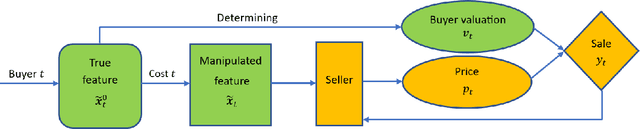
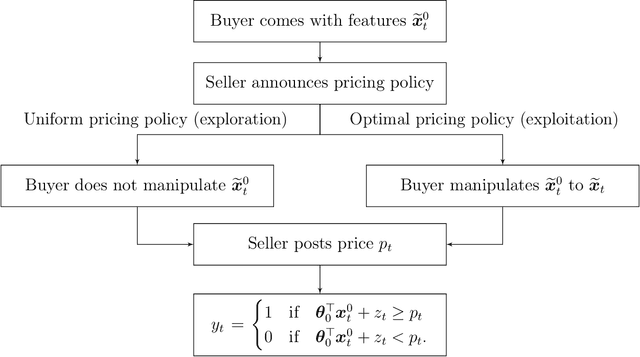
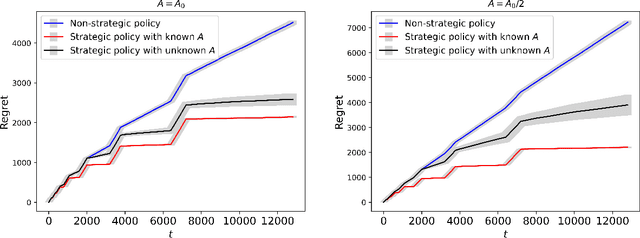
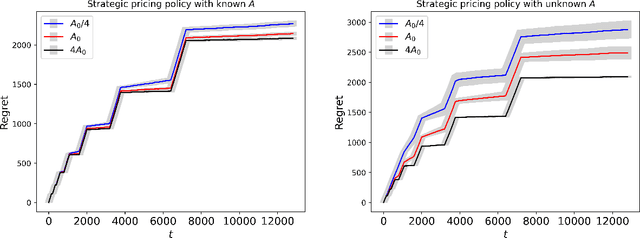
Personalized pricing, which involves tailoring prices based on individual characteristics, is commonly used by firms to implement a consumer-specific pricing policy. In this process, buyers can also strategically manipulate their feature data to obtain a lower price, incurring certain manipulation costs. Such strategic behavior can hinder firms from maximizing their profits. In this paper, we study the contextual dynamic pricing problem with strategic buyers. The seller does not observe the buyer's true feature, but a manipulated feature according to buyers' strategic behavior. In addition, the seller does not observe the buyers' valuation of the product, but only a binary response indicating whether a sale happens or not. Recognizing these challenges, we propose a strategic dynamic pricing policy that incorporates the buyers' strategic behavior into the online learning to maximize the seller's cumulative revenue. We first prove that existing non-strategic pricing policies that neglect the buyers' strategic behavior result in a linear $\Omega(T)$ regret with $T$ the total time horizon, indicating that these policies are not better than a random pricing policy. We then establish that our proposed policy achieves a sublinear regret upper bound of $O(\sqrt{T})$. Importantly, our policy is not a mere amalgamation of existing dynamic pricing policies and strategic behavior handling algorithms. Our policy can also accommodate the scenario when the marginal cost of manipulation is unknown in advance. To account for it, we simultaneously estimate the valuation parameter and the cost parameter in the online pricing policy, which is shown to also achieve an $O(\sqrt{T})$ regret bound. Extensive experiments support our theoretical developments and demonstrate the superior performance of our policy compared to other pricing policies that are unaware of the strategic behaviors.
Unsupervised Deep Learning for IoT Time Series
Feb 21, 2023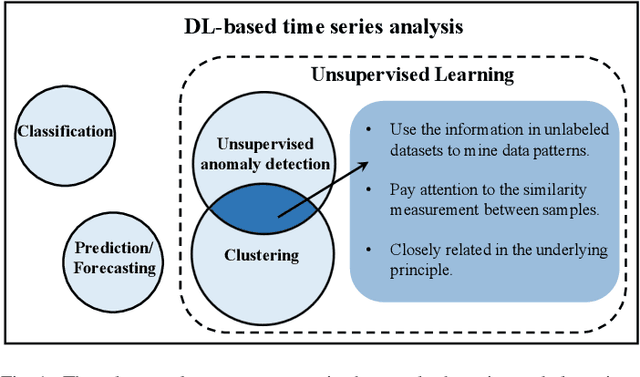
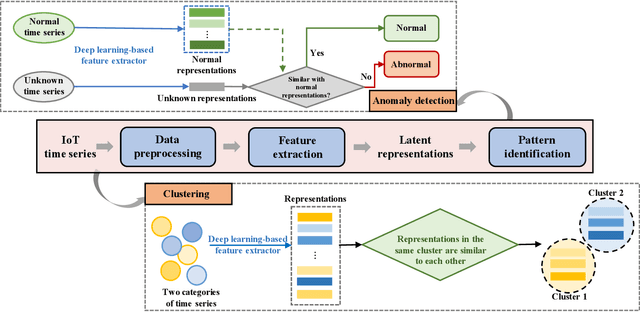
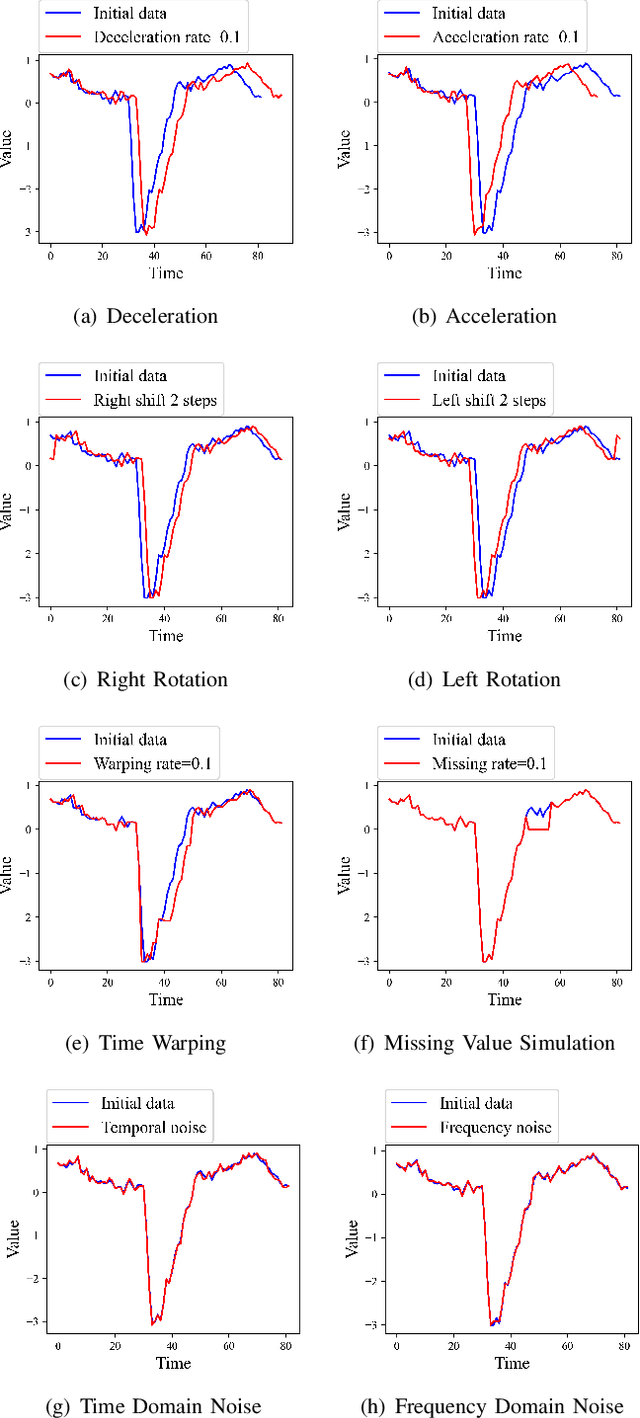
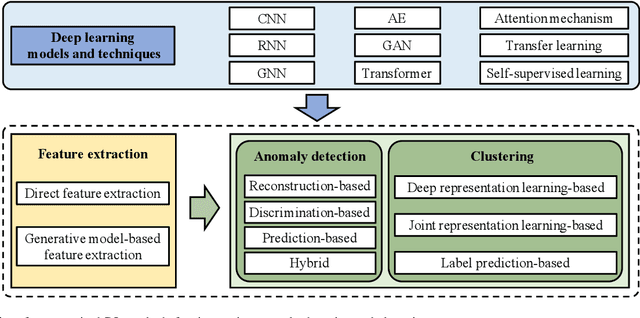
IoT time series analysis has found numerous applications in a wide variety of areas, ranging from health informatics to network security. Nevertheless, the complex spatial temporal dynamics and high dimensionality of IoT time series make the analysis increasingly challenging. In recent years, the powerful feature extraction and representation learning capabilities of deep learning (DL) have provided an effective means for IoT time series analysis. However, few existing surveys on time series have systematically discussed unsupervised DL-based methods. To fill this void, we investigate unsupervised deep learning for IoT time series, i.e., unsupervised anomaly detection and clustering, under a unified framework. We also discuss the application scenarios, public datasets, existing challenges, and future research directions in this area.
* 22 pages, 8 figures, has been published by IEEE Internet of Things Journal