 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
OO-dMVMT: A Deep Multi-view Multi-task Classification Framework for Real-time 3D Hand Gesture Classification and Segmentation
Apr 12, 2023
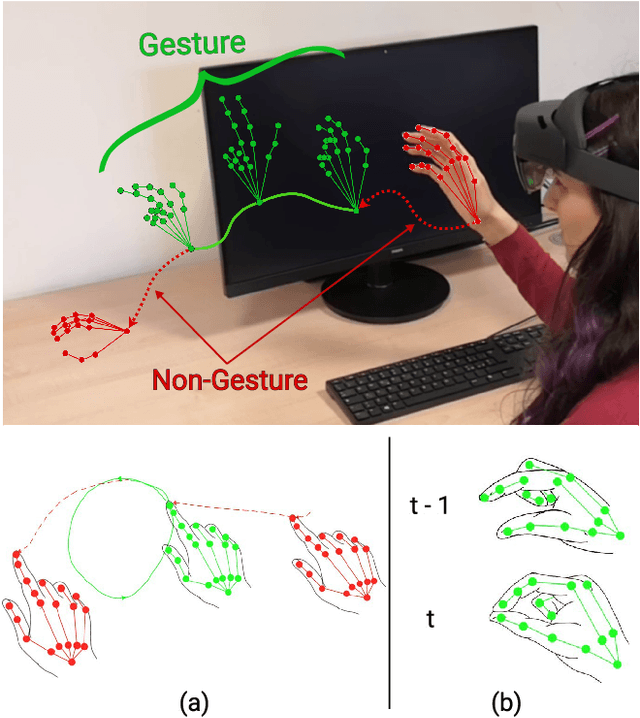
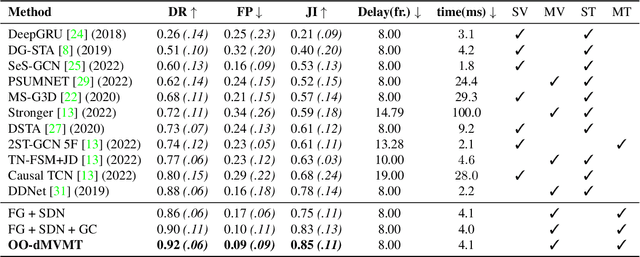
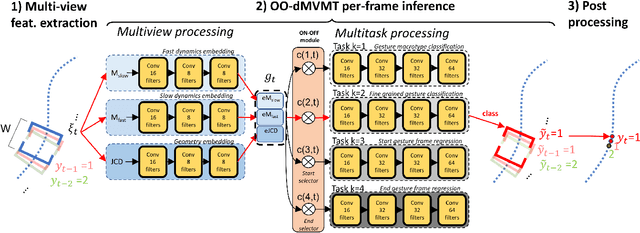
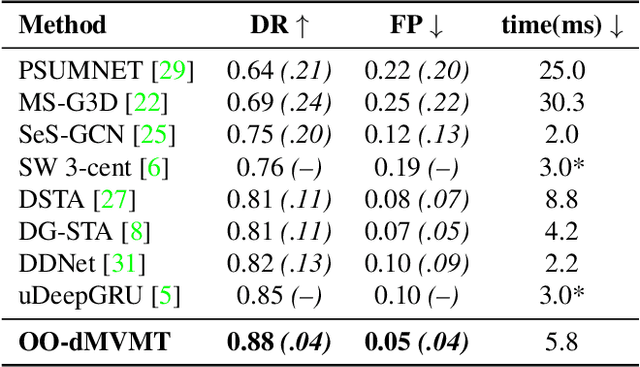
Continuous mid-air hand gesture recognition based on captured hand pose streams is fundamental for human-computer interaction, particularly in AR / VR. However, many of the methods proposed to recognize heterogeneous hand gestures are tested only on the classification task, and the real-time low-latency gesture segmentation in a continuous stream is not well addressed in the literature. For this task, we propose the On-Off deep Multi-View Multi-Task paradigm (OO-dMVMT). The idea is to exploit multiple time-local views related to hand pose and movement to generate rich gesture descriptions, along with using heterogeneous tasks to achieve high accuracy. OO-dMVMT extends the classical MVMT paradigm, where all of the multiple tasks have to be active at each time, by allowing specific tasks to switch on/off depending on whether they can apply to the input. We show that OO-dMVMT defines the new SotA on continuous/online 3D skeleton-based gesture recognition in terms of gesture classification accuracy, segmentation accuracy, false positives, and decision latency while maintaining real-time operation.
A Fast Maximum $k$-Plex Algorithm Parameterized by the Degeneracy Gap
Jun 23, 2023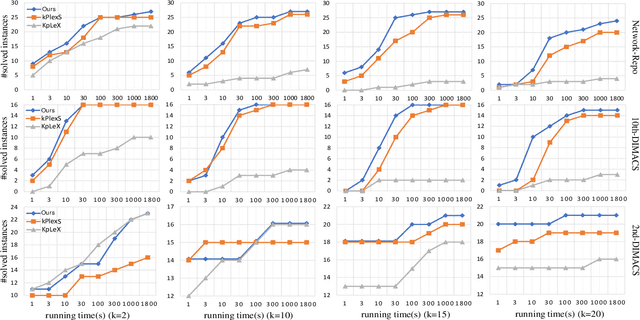
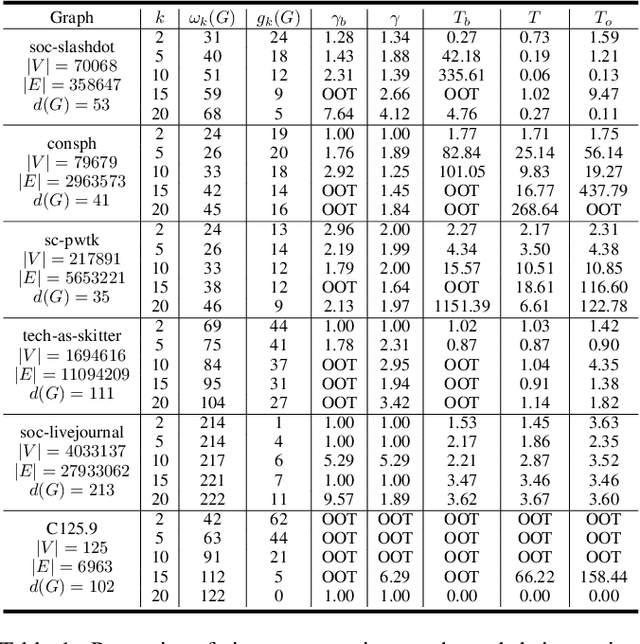
Given a graph, the $k$-plex is a vertex set in which each vertex is not adjacent to at most $k-1$ other vertices in the set. The maximum $k$-plex problem, which asks for the largest $k$-plex from a given graph, is an important but computationally challenging problem in applications like graph search and community detection. So far, there is a number of empirical algorithms without sufficient theoretical explanations on the efficiency. We try to bridge this gap by defining a novel parameter of the input instance, $g_k(G)$, the gap between the degeneracy bound and the size of maximum $k$-plex in the given graph, and presenting an exact algorithm parameterized by $g_k(G)$. In other words, we design an algorithm with running time polynomial in the size of input graph and exponential in $g_k(G)$ where $k$ is a constant. Usually, $g_k(G)$ is small and bounded by $O(\log{(|V|)})$ in real-world graphs, indicating that the algorithm runs in polynomial time. We also carry out massive experiments and show that the algorithm is competitive with the state-of-the-art solvers. Additionally, for large $k$ values such as $15$ and $20$, our algorithm has superior performance over existing algorithms.
Transgressing the boundaries: towards a rigorous understanding of deep learning and its (non-)robustness
Jul 05, 2023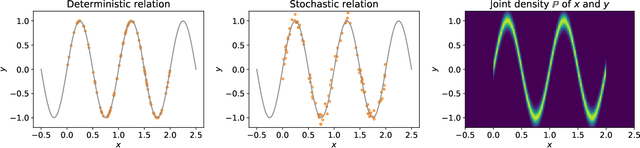
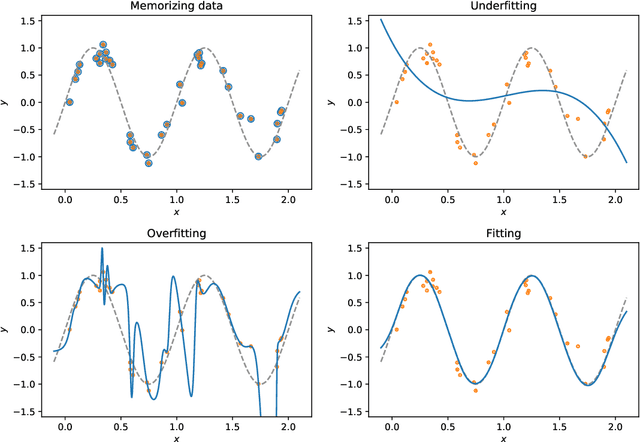
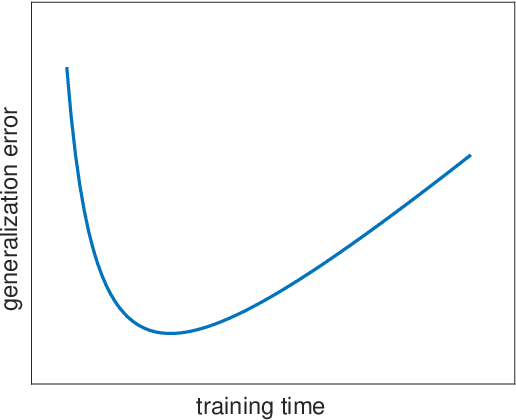
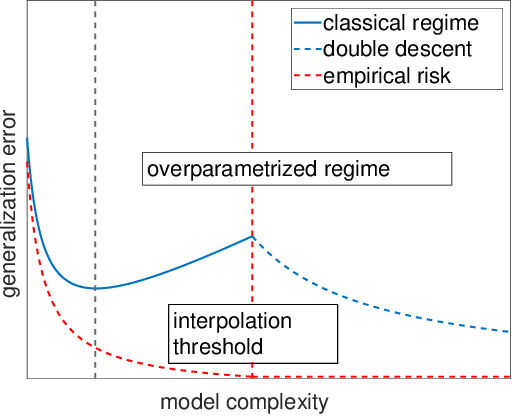
The recent advances in machine learning in various fields of applications can be largely attributed to the rise of deep learning (DL) methods and architectures. Despite being a key technology behind autonomous cars, image processing, speech recognition, etc., a notorious problem remains the lack of theoretical understanding of DL and related interpretability and (adversarial) robustness issues. Understanding the specifics of DL, as compared to, say, other forms of nonlinear regression methods or statistical learning, is interesting from a mathematical perspective, but at the same time it is of crucial importance in practice: treating neural networks as mere black boxes might be sufficient in certain cases, but many applications require waterproof performance guarantees and a deeper understanding of what could go wrong and why it could go wrong. It is probably fair to say that, despite being mathematically well founded as a method to approximate complicated functions, DL is mostly still more like modern alchemy that is firmly in the hands of engineers and computer scientists. Nevertheless, it is evident that certain specifics of DL that could explain its success in applications demands systematic mathematical approaches. In this work, we review robustness issues of DL and particularly bridge concerns and attempts from approximation theory to statistical learning theory. Further, we review Bayesian Deep Learning as a means for uncertainty quantification and rigorous explainability.
Utilizing ChatGPT Generated Data to Retrieve Depression Symptoms from Social Media
Jul 05, 2023In this work, we present the contribution of the BLUE team in the eRisk Lab task on searching for symptoms of depression. The task consists of retrieving and ranking Reddit social media sentences that convey symptoms of depression from the BDI-II questionnaire. Given that synthetic data provided by LLMs have been proven to be a reliable method for augmenting data and fine-tuning downstream models, we chose to generate synthetic data using ChatGPT for each of the symptoms of the BDI-II questionnaire. We designed a prompt such that the generated data contains more richness and semantic diversity than the BDI-II responses for each question and, at the same time, contains emotional and anecdotal experiences that are specific to the more intimate way of sharing experiences on Reddit. We perform semantic search and rank the sentences' relevance to the BDI-II symptoms by cosine similarity. We used two state-of-the-art transformer-based models for embedding the social media posts, the original and generated responses of the BDI-II, MentalRoBERTa and a variant of MPNet. Our results show that an approach using for sentence embeddings a model that is designed for semantic search outperforms the model pre-trained on mental health data. Furthermore, the generated synthetic data were proved too specific for this task, the approach simply relying on the BDI-II responses had the best performance.
Using Random Effects Machine Learning Algorithms to Identify Vulnerability to Depression
Jul 05, 2023Background: Reliable prediction of clinical progression over time can improve the outcomes of depression. Little work has been done integrating various risk factors for depression, to determine the combinations of factors with the greatest utility for identifying which individuals are at the greatest risk. Method: This study demonstrates that data-driven machine learning (ML) methods such as RE-EM (Random Effects/Expectation Maximization) trees and MERF (Mixed Effects Random Forest) can be applied to reliably identify variables that have the greatest utility for classifying subgroups at greatest risk for depression. 185 young adults completed measures of depression risk, including rumination, worry, negative cognitive styles, cognitive and coping flexibilities, and negative life events, along with symptoms of depression. We trained RE-EM trees and MERF algorithms and compared them to traditional linear mixed models (LMMs) predicting depressive symptoms prospectively and concurrently with cross-validation. Results: Our results indicated that the RE-EM tree and MERF methods model complex interactions, identify subgroups of individuals and predict depression severity comparable to LMM. Further, machine learning models determined that brooding, negative life events, negative cognitive styles, and perceived control were the most relevant predictors of future depression levels. Conclusions: Random effects machine learning models have the potential for high clinical utility and can be leveraged for interventions to reduce vulnerability to depression.
Robust Target Localization in 2D: A Value-at-Risk Approach
Jul 05, 2023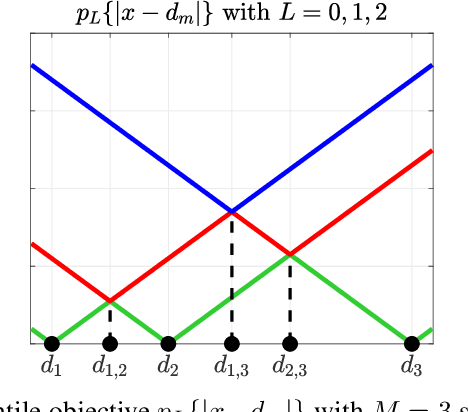
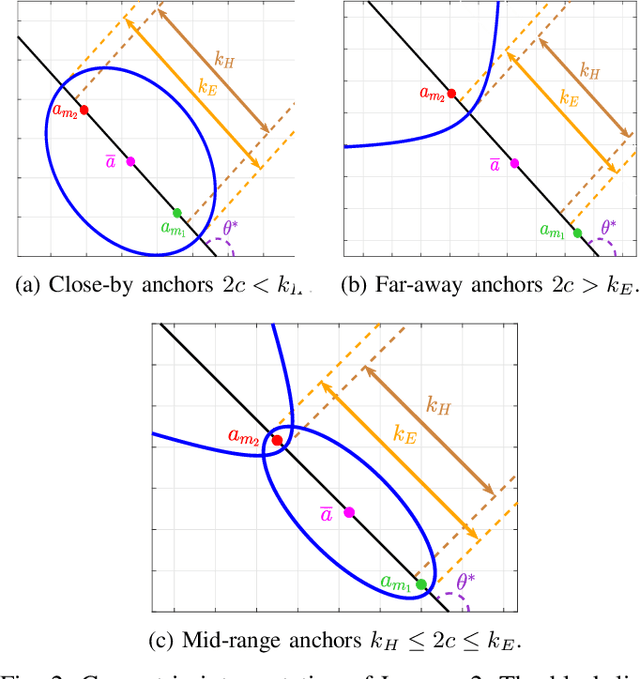
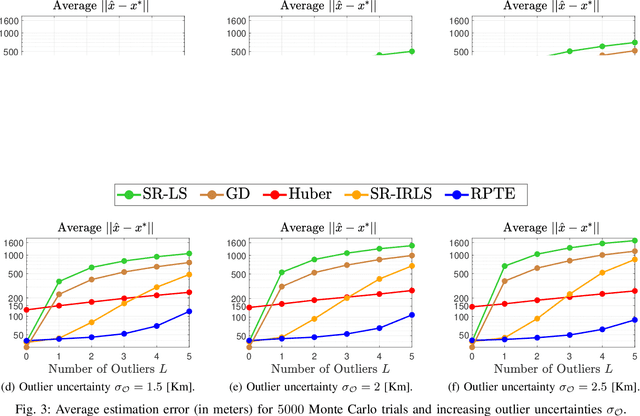
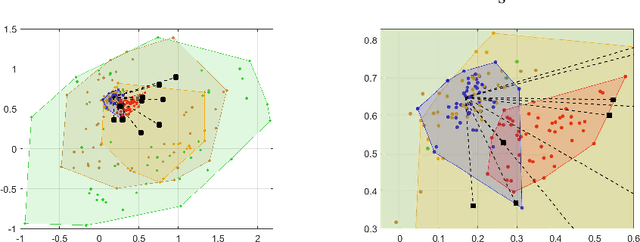
This paper consider considers the problem of locating a two dimensional target from range-measurements containing outliers. Assuming that the number of outlier is known, we formulate the problem of minimizing inlier losses while ignoring outliers. This leads to a combinatorial, non-convex, non-smooth problem involving the percentile function. Using the framework of risk analysis from Rockafellar et al., we start by interpreting this formulation as a Value-at-risk (VaR) problem from portfolio optimization. To the best of our knowledge, this is the first time that a localization problem was formulated using risk analysis theory. To study the VaR formulation, we start by designing a majorizer set that contains any solution of a general percentile problem. This set is useful because, when applied to a localization scenario in 2D, it allows to majorize the solution set in terms of singletons, circumferences, ellipses and hyperbolas. Using know parametrization of these curves, we propose a grid method for the original non-convex problem. So we reduce the task of optimizing the VaR objective to that of efficiently sampling the proposed majorizer set. We compare our algorithm with four benchmarks in target localization. Numerical simulations show that our method is fast while, on average, improving the accuracy of the best benchmarks by at least 100m in a 1 Km$^2$ area.
NOMA for STAR-RIS Assisted UAV Networks
Jul 05, 2023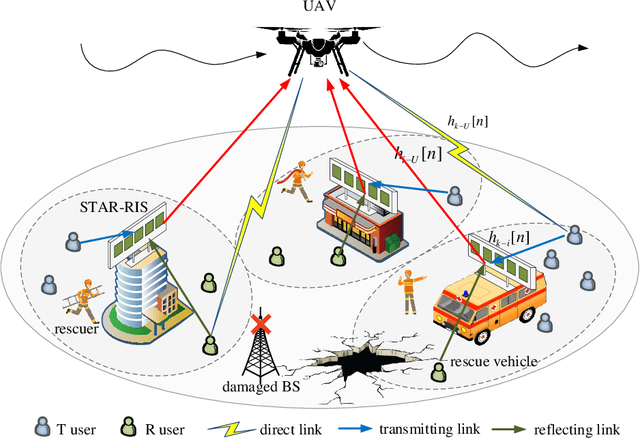
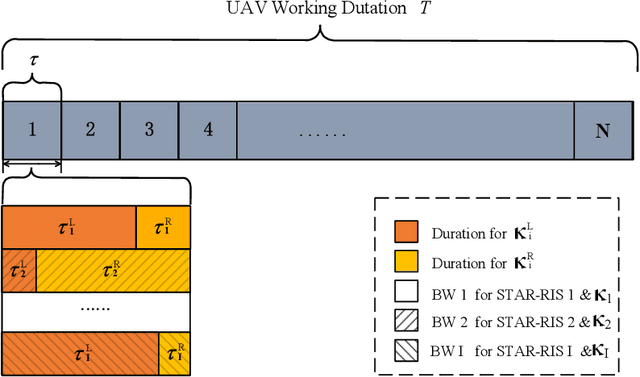
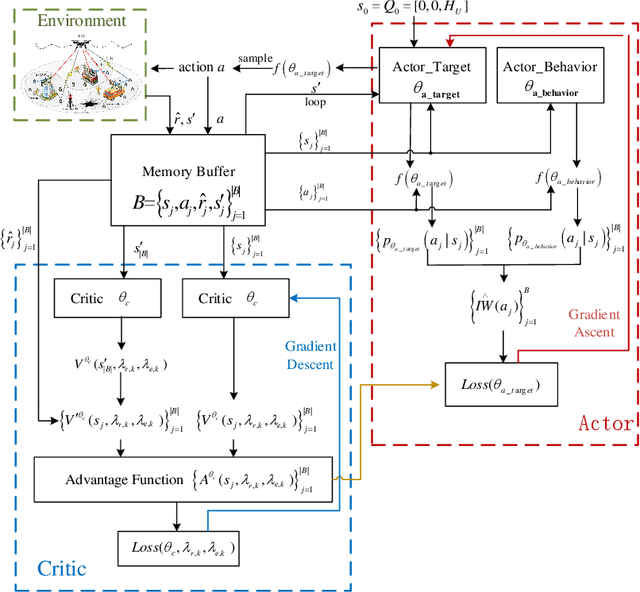
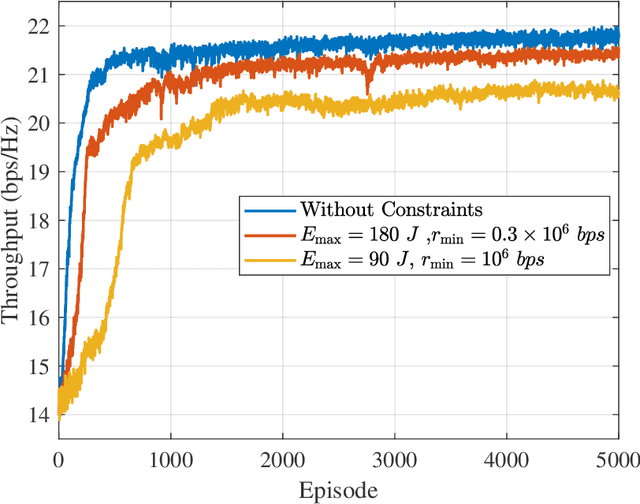
This paper proposes a novel simultaneously transmitting and reflecting reconfigurable intelligent surface (STAR-RIS) assisted unmanned aerial vehicle (UAV) non-orthogonal multiple access (NOMA) emergency communication network. Multiple STAR-RISs are deployed to provide additional and intelligent transmission links between trapped users and UAV-mounted base station (BS). Each user selects the nearest STAR-RIS for uploading data, and NOMA is employed for users located at the same side of the same STAR-RIS. Considering piratical requirements of post-disaster emergency communications, we formulate a throughput maximization problem subject to constraints on minimum average rate and maximum energy consumption, where the UAV trajectory, STAR-RIS passive beamforming, and time and power allocation are jointly optimized. Furthermore, we propose a Lagrange based reward constrained proximal policy optimization (LRCPPO) algorithm, which provides an adaptive method for solving the long-term optimization problem with cumulative constraints. Specifically, using Lagrange relaxation, the original problem is transformed into an unconstrained problem with a two-layer structure. The inner layer is solved by penalized reward based proximal policy optimization (PPO) algorithm. In the outer layer, Lagrange multipliers are updated by gradient descent. Numerical results show the proposed algorithm can effectively improve network performance while satisfying the constraints well. It also demonstrates the superiority of the proposed STAR-RIS assisted UAV NOMA network architecture over the benchmark schemes employing reflecting-only RISs and orthogonal multiple access.
Approaching Test Time Augmentation in the Context of Uncertainty Calibration for Deep Neural Networks
Apr 11, 2023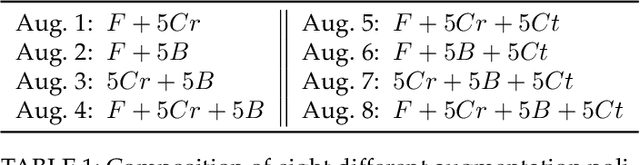
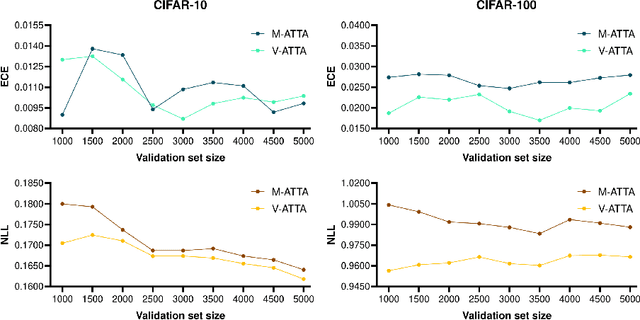
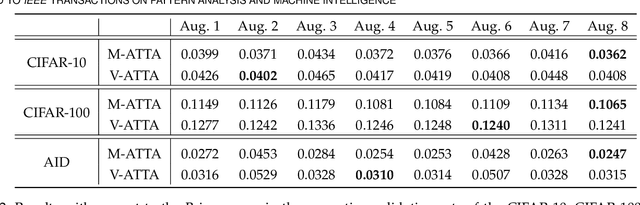
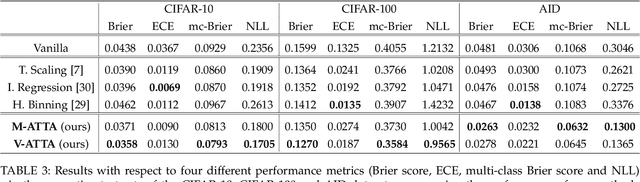
With the rise of Deep Neural Networks, machine learning systems are nowadays ubiquitous in a number of real-world applications, which bears the need for highly reliable models. This requires a thorough look not only at the accuracy of such systems, but also to their predictive uncertainty. Hence, we propose a novel technique (with two different variations, named M-ATTA and V-ATTA) based on test time augmentation, to improve the uncertainty calibration of deep models for image classification. Unlike other test time augmentation approaches, M/V-ATTA improves uncertainty calibration without affecting the model's accuracy, by leveraging an adaptive weighting system. We evaluate the performance of the technique with respect to different metrics of uncertainty calibration. Empirical results, obtained on CIFAR-10, CIFAR-100, as well as on the benchmark Aerial Image Dataset, indicate that the proposed approach outperforms state-of-the-art calibration techniques, while maintaining the baseline classification performance. Code for M/V-ATTA available at: https://github.com/pedrormconde/MV-ATTA.
Improving Online Continual Learning Performance and Stability with Temporal Ensembles
Jul 03, 2023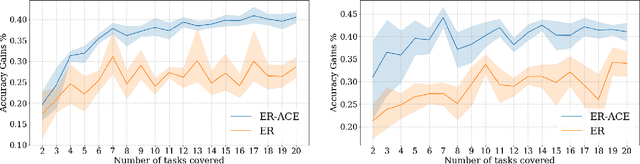
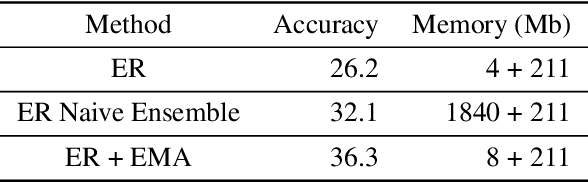
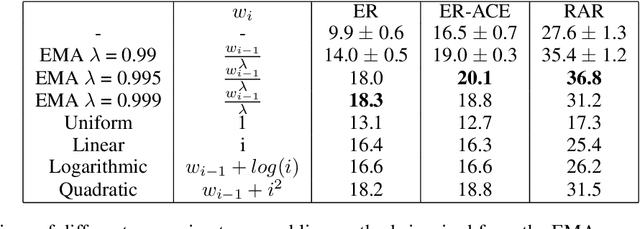
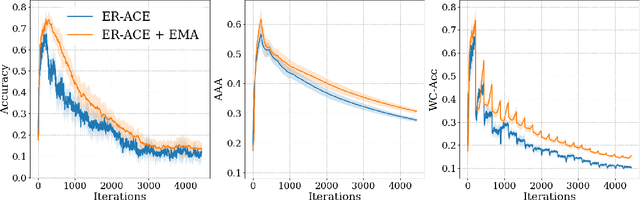
Neural networks are very effective when trained on large datasets for a large number of iterations. However, when they are trained on non-stationary streams of data and in an online fashion, their performance is reduced (1) by the online setup, which limits the availability of data, (2) due to catastrophic forgetting because of the non-stationary nature of the data. Furthermore, several recent works (Caccia et al., 2022; Lange et al., 2023) arXiv:2205.13452 showed that replay methods used in continual learning suffer from the stability gap, encountered when evaluating the model continually (rather than only on task boundaries). In this article, we study the effect of model ensembling as a way to improve performance and stability in online continual learning. We notice that naively ensembling models coming from a variety of training tasks increases the performance in online continual learning considerably. Starting from this observation, and drawing inspirations from semi-supervised learning ensembling methods, we use a lightweight temporal ensemble that computes the exponential moving average of the weights (EMA) at test time, and show that it can drastically increase the performance and stability when used in combination with several methods from the literature.
A Systematic Survey in Geometric Deep Learning for Structure-based Drug Design
Jul 03, 2023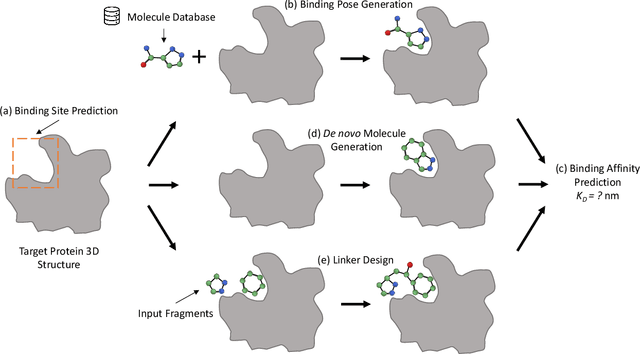
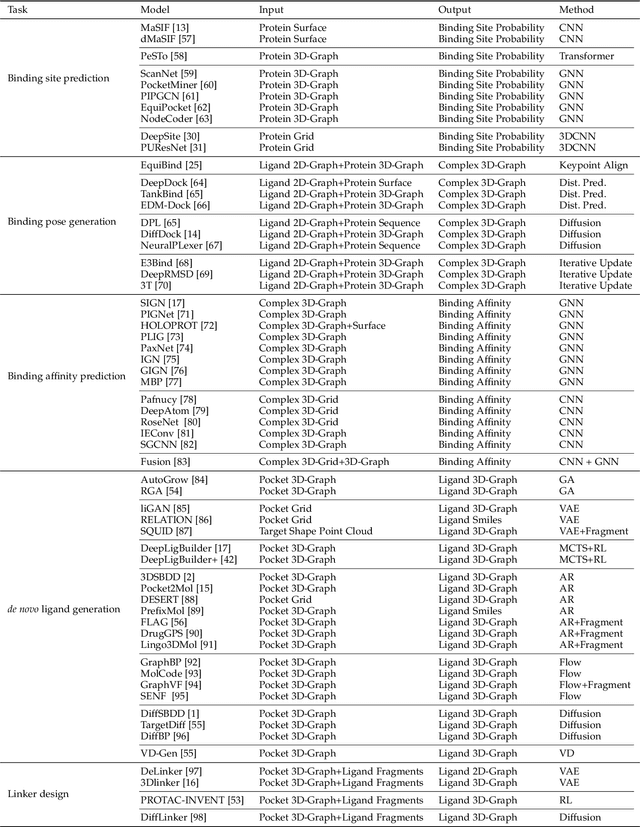
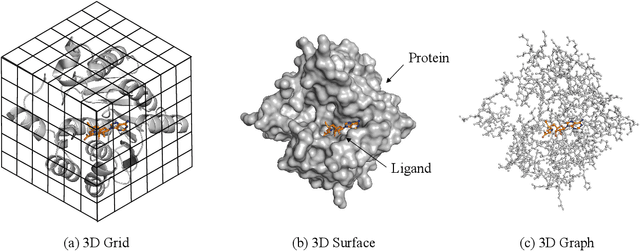
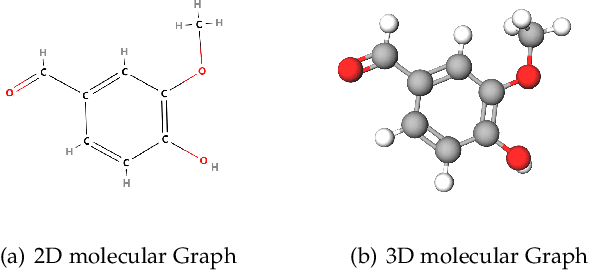
Structure-based drug design (SBDD), which utilizes the three-dimensional geometry of proteins to identify potential drug candidates, is becoming increasingly vital in drug discovery. However, traditional methods based on physiochemical modeling and experts' domain knowledge are time-consuming and laborious. The recent advancements in geometric deep learning, which integrates and processes 3D geometric data, coupled with the availability of accurate protein 3D structure predictions from tools like AlphaFold, have significantly propelled progress in structure-based drug design. In this paper, we systematically review the recent progress of geometric deep learning for structure-based drug design. We start with a brief discussion of the mainstream tasks in structure-based drug design, commonly used 3D protein representations and representative predictive/generative models. Then we delve into detailed reviews for each task (binding site prediction, binding pose generation, \emph{de novo} molecule generation, linker design, and binding affinity prediction), including the problem setup, representative methods, datasets, and evaluation metrics. Finally, we conclude this survey with the current challenges and highlight potential opportunities of geometric deep learning for structure-based drug design.We curate a GitHub repo containing the related papers \url{https://github.com/zaixizhang/Awesome-SBDD}.