 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
VS-TransGRU: A Novel Transformer-GRU-based Framework Enhanced by Visual-Semantic Fusion for Egocentric Action Anticipation
Jul 08, 2023
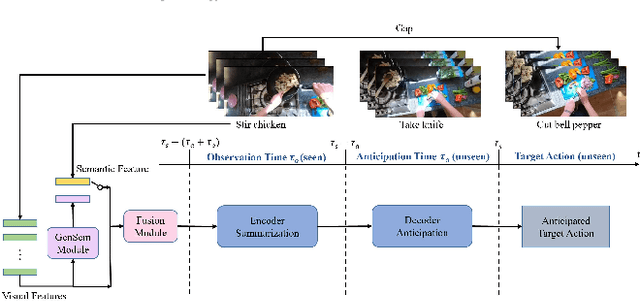
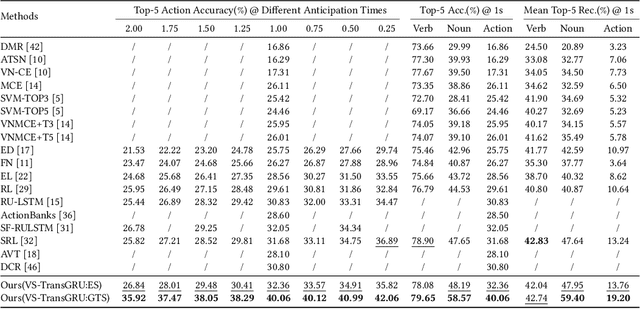

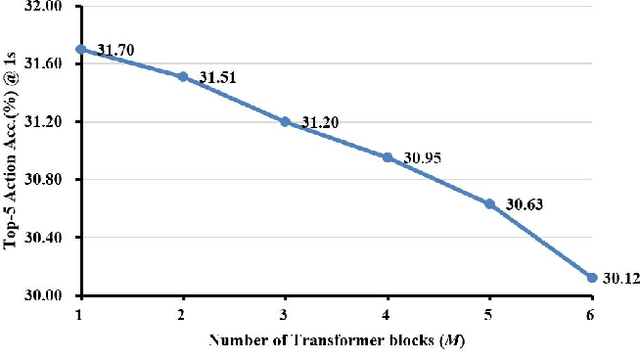
Egocentric action anticipation is a challenging task that aims to make advanced predictions of future actions from current and historical observations in the first-person view. Most existing methods focus on improving the model architecture and loss function based on the visual input and recurrent neural network to boost the anticipation performance. However, these methods, which merely consider visual information and rely on a single network architecture, gradually reach a performance plateau. In order to fully understand what has been observed and capture the dependencies between current observations and future actions well enough, we propose a novel visual-semantic fusion enhanced and Transformer GRU-based action anticipation framework in this paper. Firstly, high-level semantic information is introduced to improve the performance of action anticipation for the first time. We propose to use the semantic features generated based on the class labels or directly from the visual observations to augment the original visual features. Secondly, an effective visual-semantic fusion module is proposed to make up for the semantic gap and fully utilize the complementarity of different modalities. Thirdly, to take advantage of both the parallel and autoregressive models, we design a Transformer based encoder for long-term sequential modeling and a GRU-based decoder for flexible iteration decoding. Extensive experiments on two large-scale first-person view datasets, i.e., EPIC-Kitchens and EGTEA Gaze+, validate the effectiveness of our proposed method, which achieves new state-of-the-art performance, outperforming previous approaches by a large margin.
Serving Graph Neural Networks With Distributed Fog Servers For Smart IoT Services
Jul 04, 2023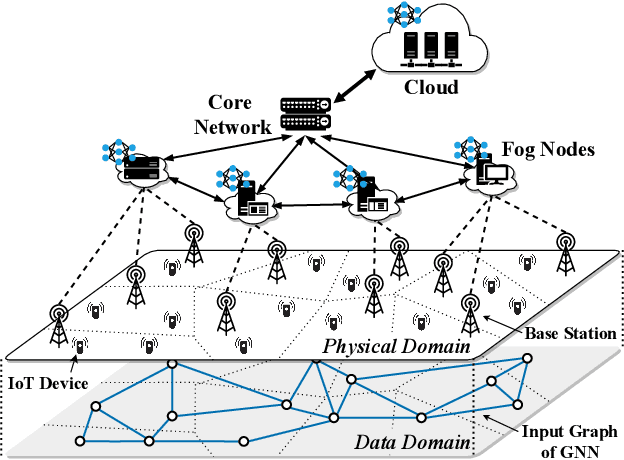
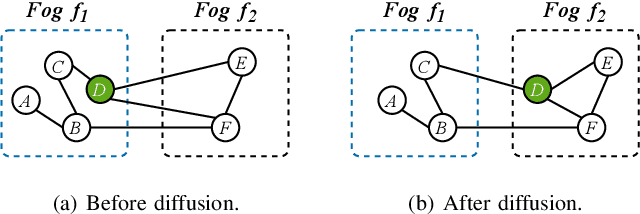
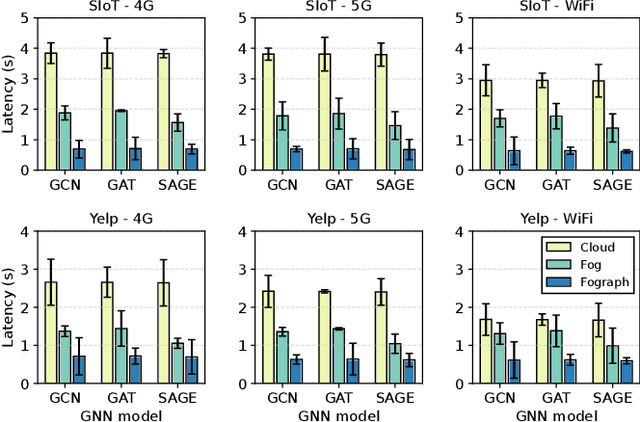
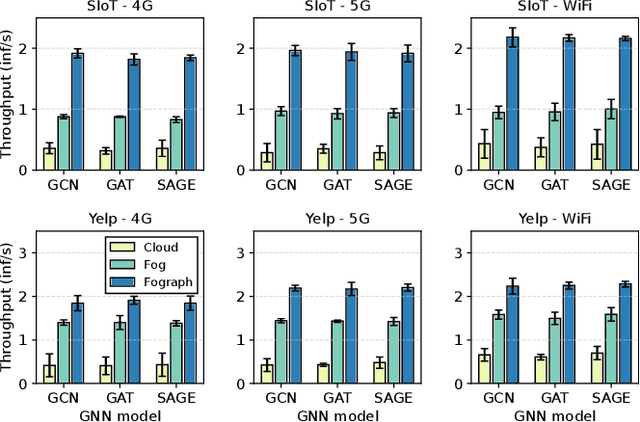
Graph Neural Networks (GNNs) have gained growing interest in miscellaneous applications owing to their outstanding ability in extracting latent representation on graph structures. To render GNN-based service for IoT-driven smart applications, traditional model serving paradigms usually resort to the cloud by fully uploading geo-distributed input data to remote datacenters. However, our empirical measurements reveal the significant communication overhead of such cloud-based serving and highlight the profound potential in applying the emerging fog computing. To maximize the architectural benefits brought by fog computing, in this paper, we present Fograph, a novel distributed real-time GNN inference framework that leverages diverse and dynamic resources of multiple fog nodes in proximity to IoT data sources. By introducing heterogeneity-aware execution planning and GNN-specific compression techniques, Fograph tailors its design to well accommodate the unique characteristics of GNN serving in fog environments. Prototype-based evaluation and case study demonstrate that Fograph significantly outperforms the state-of-the-art cloud serving and fog deployment by up to 5.39x execution speedup and 6.84x throughput improvement.
A Comprehensive Multi-scale Approach for Speech and Dynamics Synchrony in Talking Head Generation
Jul 04, 2023
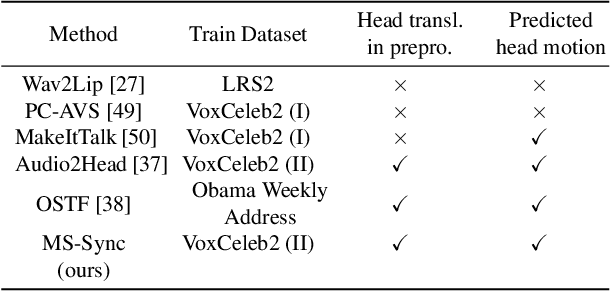
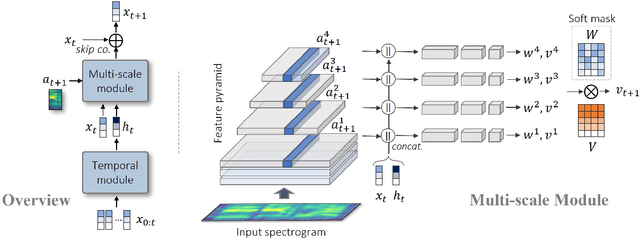
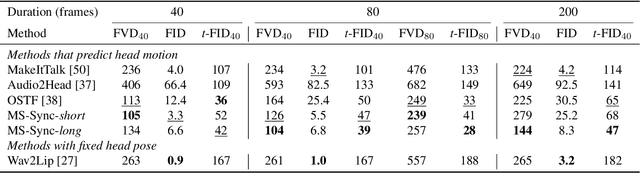
Animating still face images with deep generative models using a speech input signal is an active research topic and has seen important recent progress. However, much of the effort has been put into lip syncing and rendering quality while the generation of natural head motion, let alone the audio-visual correlation between head motion and speech, has often been neglected. In this work, we propose a multi-scale audio-visual synchrony loss and a multi-scale autoregressive GAN to better handle short and long-term correlation between speech and the dynamics of the head and lips. In particular, we train a stack of syncer models on multimodal input pyramids and use these models as guidance in a multi-scale generator network to produce audio-aligned motion unfolding over diverse time scales. Our generator operates in the facial landmark domain, which is a standard low-dimensional head representation. The experiments show significant improvements over the state of the art in head motion dynamics quality and in multi-scale audio-visual synchrony both in the landmark domain and in the image domain.
Unsupervised Quality Prediction for Improved Single-Frame and Weighted Sequential Visual Place Recognition
Jul 04, 2023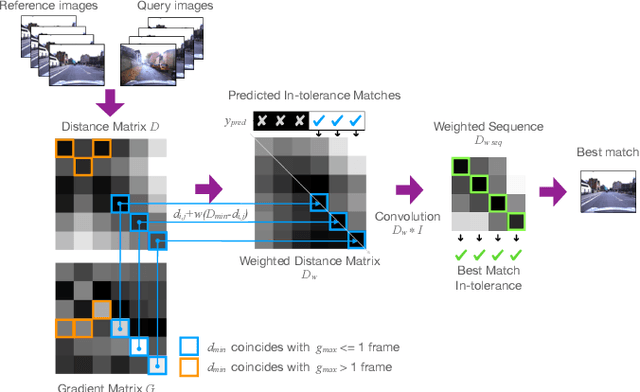
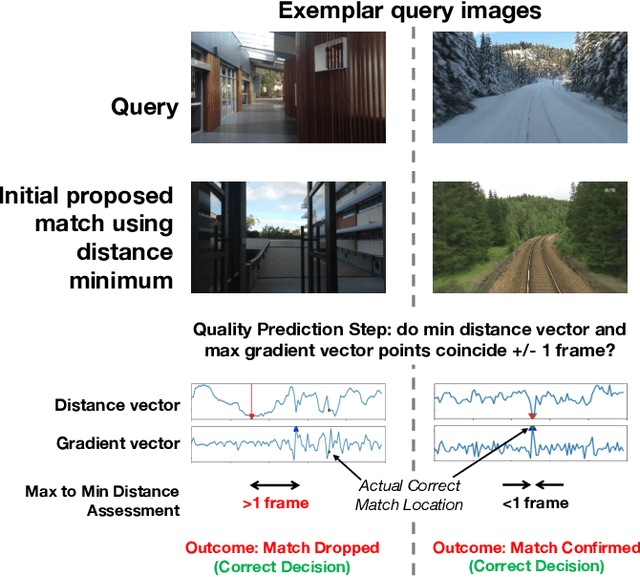
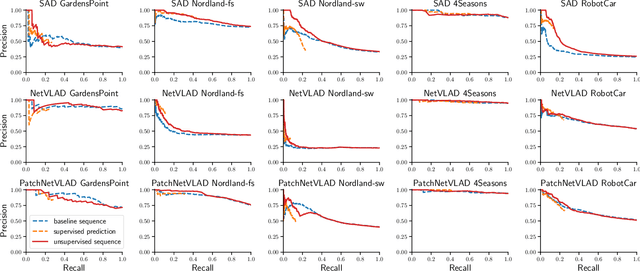
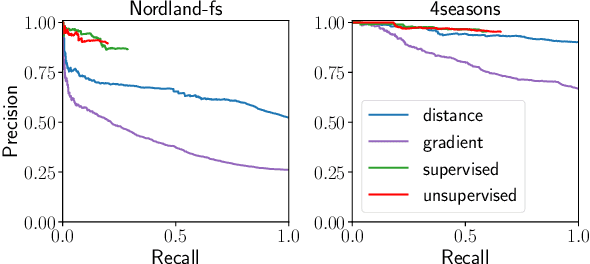
While substantial progress has been made in the absolute performance of localization and Visual Place Recognition (VPR) techniques, it is becoming increasingly clear from translating these systems into applications that other capabilities like integrity and predictability are just as important, especially for safety- or operationally-critical autonomous systems. In this research we present a new, training-free approach to predicting the likely quality of localization estimates, and a novel method for using these predictions to bias a sequence-matching process to produce additional performance gains beyond that of a naive sequence matching approach. Our combined system is lightweight, runs in real-time and is agnostic to the underlying VPR technique. On extensive experiments across four datasets and three VPR techniques, we demonstrate our system improves precision performance, especially at the high-precision/low-recall operating point. We also present ablation and analysis identifying the performance contributions of the prediction and weighted sequence matching components in isolation, and the relationship between the quality of the prediction system and the benefits of the weighted sequential matcher.
Nearly-Optimal Hierarchical Clustering for Well-Clustered Graphs
Jun 16, 2023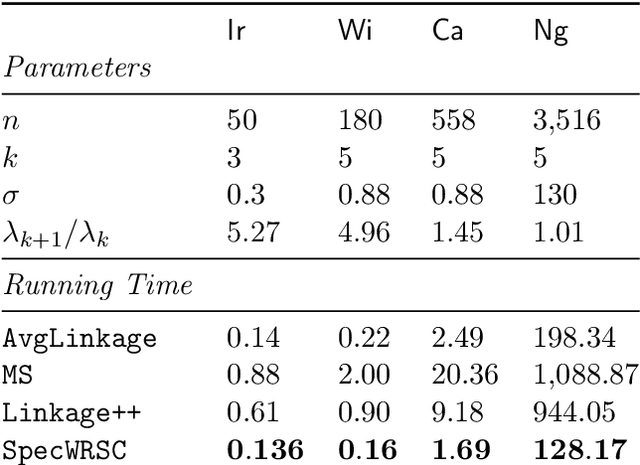
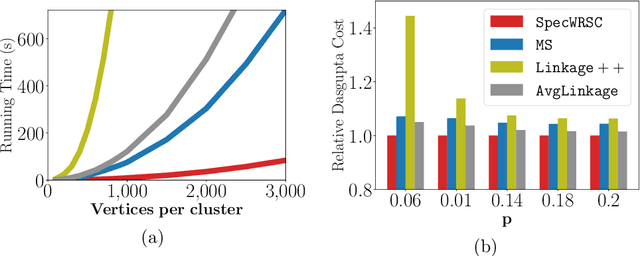
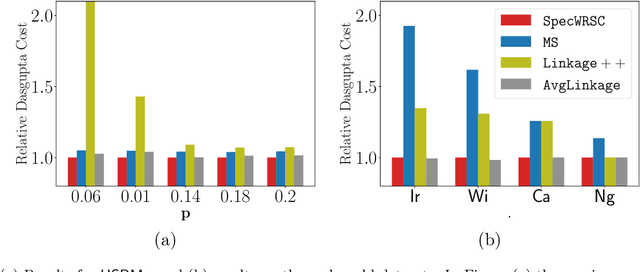
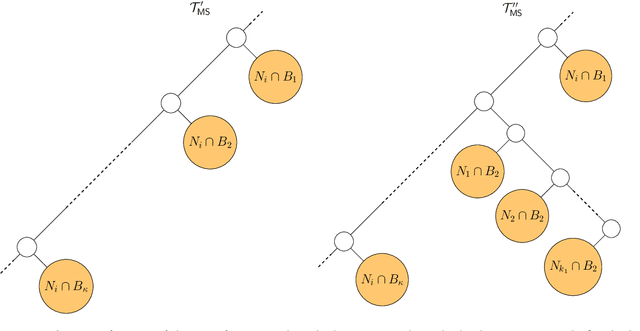
This paper presents two efficient hierarchical clustering (HC) algorithms with respect to Dasgupta's cost function. For any input graph $G$ with a clear cluster-structure, our designed algorithms run in nearly-linear time in the input size of $G$, and return an $O(1)$-approximate HC tree with respect to Dasgupta's cost function. We compare the performance of our algorithm against the previous state-of-the-art on synthetic and real-world datasets and show that our designed algorithm produces comparable or better HC trees with much lower running time.
AUTO: Adaptive Outlier Optimization for Online Test-Time OOD Detection
Mar 22, 2023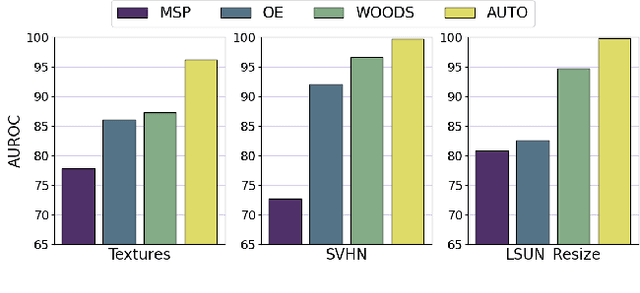
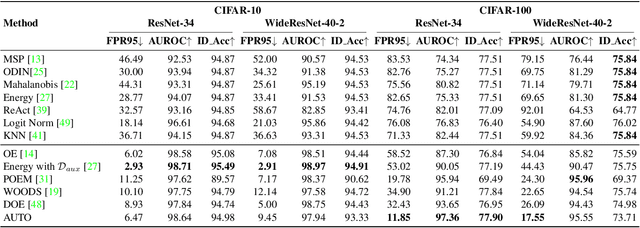
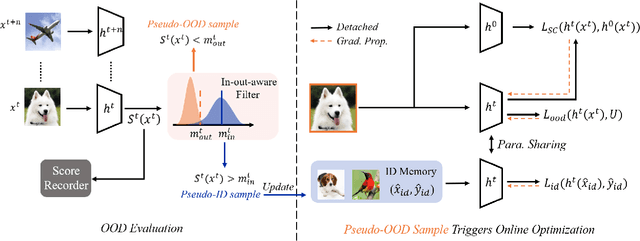
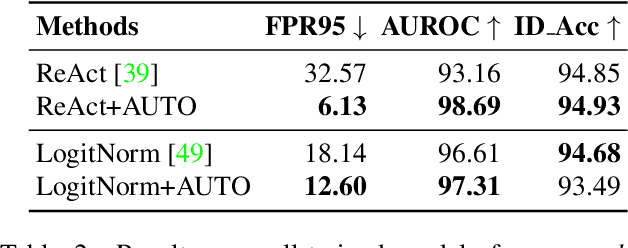
Out-of-distribution (OOD) detection is a crucial aspect of deploying machine learning models in open-world applications. Empirical evidence suggests that training with auxiliary outliers substantially improves OOD detection. However, such outliers typically exhibit a distribution gap compared to the test OOD data and do not cover all possible test OOD scenarios. Additionally, incorporating these outliers introduces additional training burdens. In this paper, we introduce a novel paradigm called test-time OOD detection, which utilizes unlabeled online data directly at test time to improve OOD detection performance. While this paradigm is efficient, it also presents challenges such as catastrophic forgetting. To address these challenges, we propose adaptive outlier optimization (AUTO), which consists of an in-out-aware filter, an ID memory bank, and a semantically-consistent objective. AUTO adaptively mines pseudo-ID and pseudo-OOD samples from test data, utilizing them to optimize networks in real time during inference. Extensive results on CIFAR-10, CIFAR-100, and ImageNet benchmarks demonstrate that AUTO significantly enhances OOD detection performance.
Centralized control for multi-agent RL in a complex Real-Time-Strategy game
Apr 25, 2023


Multi-agent Reinforcement learning (MARL) studies the behaviour of multiple learning agents that coexist in a shared environment. MARL is more challenging than single-agent RL because it involves more complex learning dynamics: the observations and rewards of each agent are functions of all other agents. In the context of MARL, Real-Time Strategy (RTS) games represent very challenging environments where multiple players interact simultaneously and control many units of different natures all at once. In fact, RTS games are so challenging for the current RL methods, that just being able to tackle them with RL is interesting. This project provides the end-to-end experience of applying RL in the Lux AI v2 Kaggle competition, where competitors design agents to control variable-sized fleets of units and tackle a multi-variable optimization, resource gathering, and allocation problem in a 1v1 scenario against other competitors. We use a centralized approach for training the RL agents, and report multiple design decisions along the process. We provide the source code of the project: https://github.com/roger-creus/centralized-control-lux.
DOMINO: Visual Causal Reasoning with Time-Dependent Phenomena
Mar 12, 2023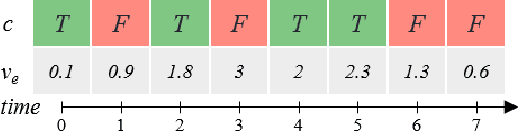
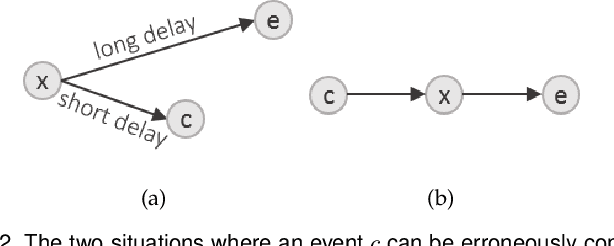
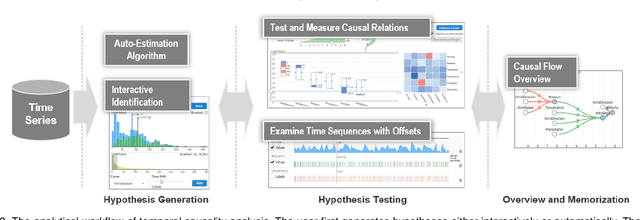
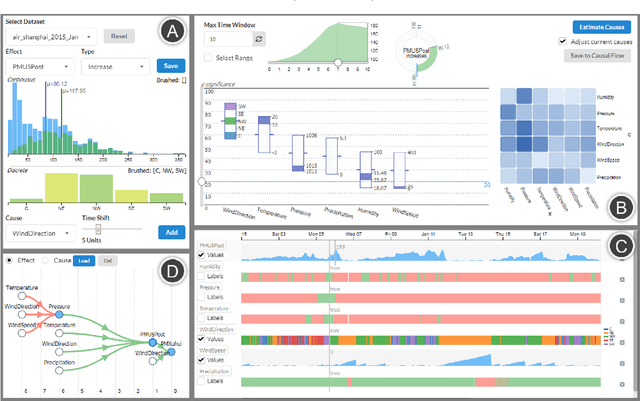
Current work on using visual analytics to determine causal relations among variables has mostly been based on the concept of counterfactuals. As such the derived static causal networks do not take into account the effect of time as an indicator. However, knowing the time delay of a causal relation can be crucial as it instructs how and when actions should be taken. Yet, similar to static causality, deriving causal relations from observational time-series data, as opposed to designed experiments, is not a straightforward process. It can greatly benefit from human insight to break ties and resolve errors. We hence propose a set of visual analytics methods that allow humans to participate in the discovery of causal relations associated with windows of time delay. Specifically, we leverage a well-established method, logic-based causality, to enable analysts to test the significance of potential causes and measure their influences toward a certain effect. Furthermore, since an effect can be a cause of other effects, we allow users to aggregate different temporal cause-effect relations found with our method into a visual flow diagram to enable the discovery of temporal causal networks. To demonstrate the effectiveness of our methods we constructed a prototype system named DOMINO and showcase it via a number of case studies using real-world datasets. Finally, we also used DOMINO to conduct several evaluations with human analysts from different science domains in order to gain feedback on the utility of our system in practical scenarios.
Intelligent Robotic Sonographer: Mutual Information-based Disentangled Reward Learning from Few Demonstrations
Jul 07, 2023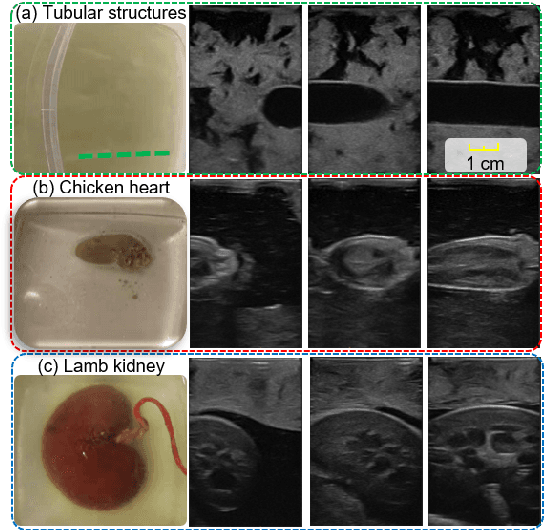
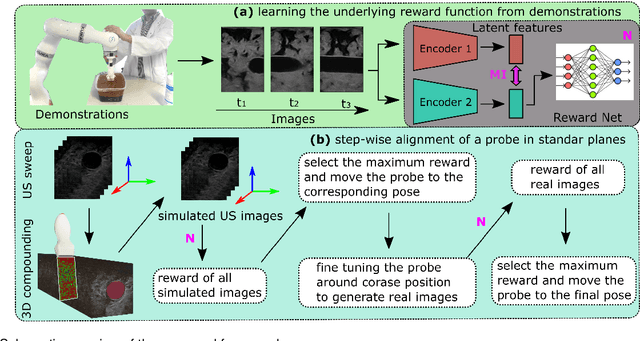
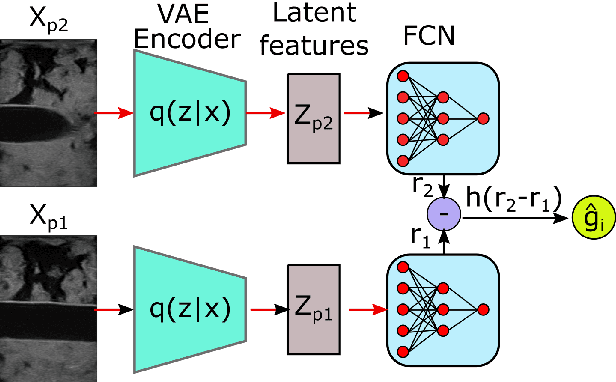
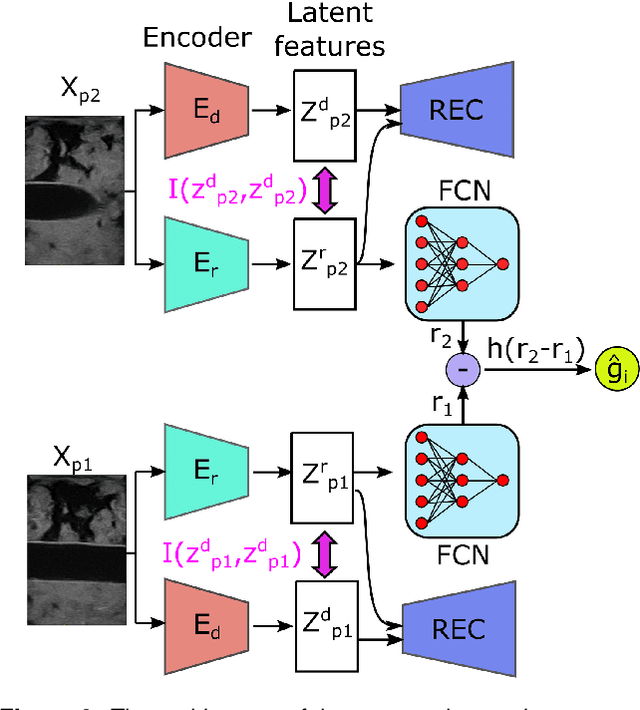
Ultrasound (US) imaging is widely used for biometric measurement and diagnosis of internal organs due to the advantages of being real-time and radiation-free. However, due to high inter-operator variability, resulting images highly depend on operators' experience. In this work, an intelligent robotic sonographer is proposed to autonomously "explore" target anatomies and navigate a US probe to a relevant 2D plane by learning from expert. The underlying high-level physiological knowledge from experts is inferred by a neural reward function, using a ranked pairwise image comparisons approach in a self-supervised fashion. This process can be referred to as understanding the "language of sonography". Considering the generalization capability to overcome inter-patient variations, mutual information is estimated by a network to explicitly extract the task-related and domain features in latent space. Besides, a Gaussian distribution-based filter is developed to automatically evaluate and take the quality of the expert's demonstrations into account. The robotic localization is carried out in coarse-to-fine mode based on the predicted reward associated to B-mode images. To demonstrate the performance of the proposed approach, representative experiments for the "line" target and "point" target are performed on vascular phantom and two ex-vivo animal organ phantoms (chicken heart and lamb kidney), respectively. The results demonstrated that the proposed advanced framework can robustly work on different kinds of known and unseen phantoms.
Balanced Filtering via Non-Disclosive Proxies
Jul 05, 2023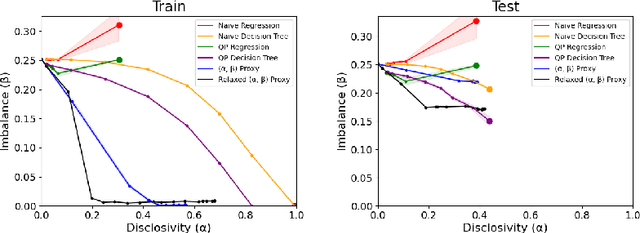
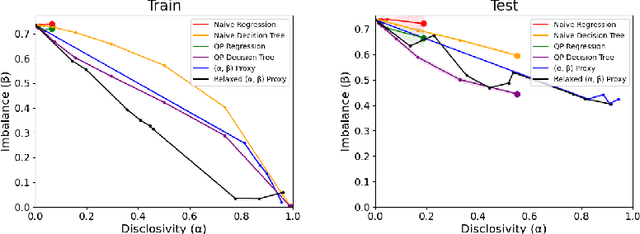
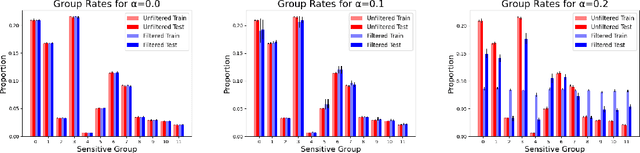
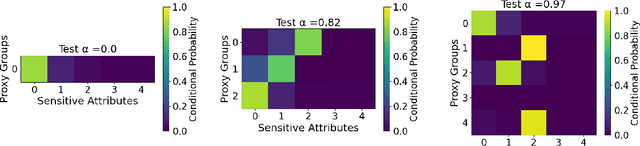
We study the problem of non-disclosively collecting a sample of data that is balanced with respect to sensitive groups when group membership is unavailable or prohibited from use at collection time. Specifically, our collection mechanism does not reveal significantly more about group membership of any individual sample than can be ascertained from base rates alone. To do this, we adopt a fairness pipeline perspective, in which a learner can use a small set of labeled data to train a proxy function that can later be used for this filtering task. We then associate the range of the proxy function with sampling probabilities; given a new candidate, we classify it using our proxy function, and then select it for our sample with probability proportional to the sampling probability corresponding to its proxy classification. Importantly, we require that the proxy classification itself not reveal significant information about the sensitive group membership of any individual sample (i.e., it should be sufficiently non-disclosive). We show that under modest algorithmic assumptions, we find such a proxy in a sample- and oracle-efficient manner. Finally, we experimentally evaluate our algorithm and analyze generalization properties.