 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Timely and Massive Communication in 6G: Pragmatics, Learning, and Inference
Jun 30, 2023
5G has expanded the traditional focus of wireless systems to embrace two new connectivity types: ultra-reliable low latency and massive communication. The technology context at the dawn of 6G is different from the past one for 5G, primarily due to the growing intelligence at the communicating nodes. This has driven the set of relevant communication problems beyond reliable transmission towards semantic and pragmatic communication. This paper puts the evolution of low-latency and massive communication towards 6G in the perspective of these new developments. At first, semantic/pragmatic communication problems are presented by drawing parallels to linguistics. We elaborate upon the relation of semantic communication to the information-theoretic problems of source/channel coding, while generalized real-time communication is put in the context of cyber-physical systems and real-time inference. The evolution of massive access towards massive closed-loop communication is elaborated upon, enabling interactive communication, learning, and cooperation among wireless sensors and actuators.
Empirical Interpretation of the Relationship Between Speech Acoustic Context and Emotion Recognition
Jun 30, 2023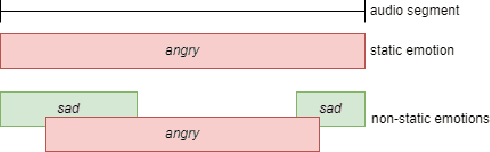
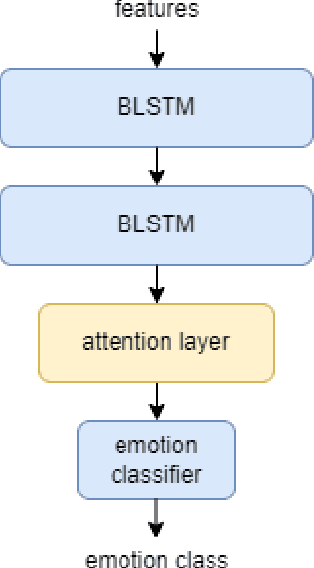
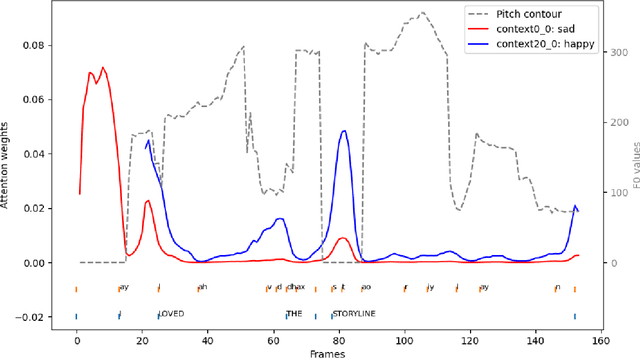
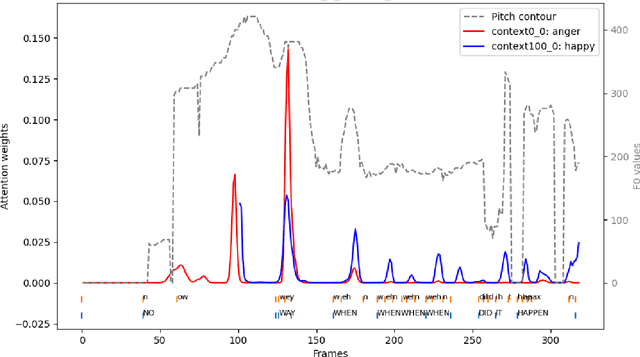
Speech emotion recognition (SER) is vital for obtaining emotional intelligence and understanding the contextual meaning of speech. Variations of consonant-vowel (CV) phonemic boundaries can enrich acoustic context with linguistic cues, which impacts SER. In practice, speech emotions are treated as single labels over an acoustic segment for a given time duration. However, phone boundaries within speech are not discrete events, therefore the perceived emotion state should also be distributed over potentially continuous time-windows. This research explores the implication of acoustic context and phone boundaries on local markers for SER using an attention-based approach. The benefits of using a distributed approach to speech emotion understanding are supported by the results of cross-corpora analysis experiments. Experiments where phones and words are mapped to the attention vectors along with the fundamental frequency to observe the overlapping distributions and thereby the relationship between acoustic context and emotion. This work aims to bridge psycholinguistic theory research with computational modelling for SER.
Exploring the Potential of Integrated Optical Sensing and Communication (IOSAC) Systems with Si Waveguides for Future Networks
Jun 27, 2023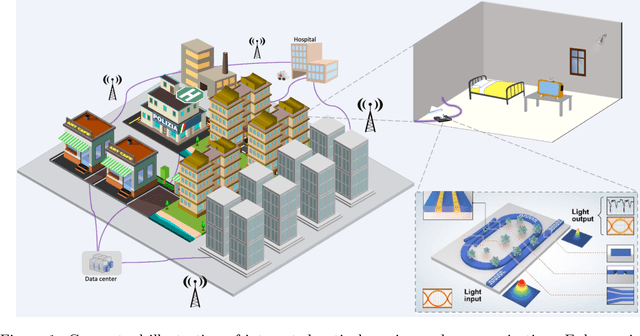
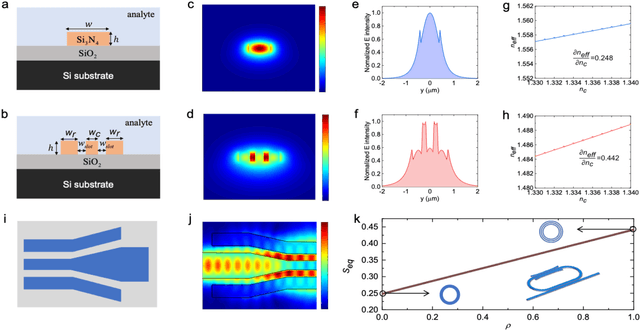
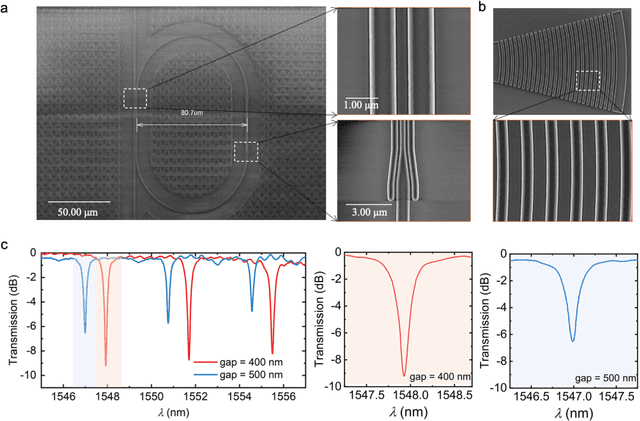
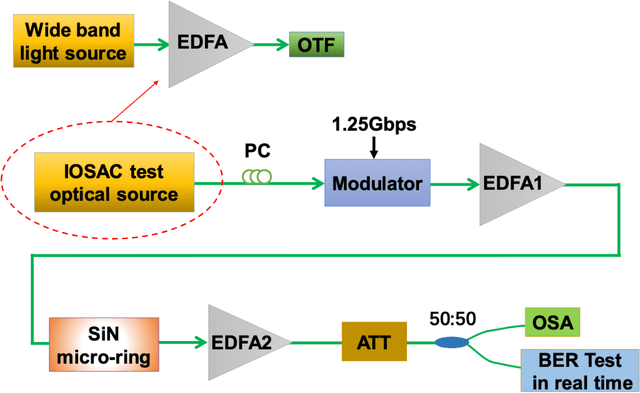
Advanced silicon photonic technologies enable integrated optical sensing and communication (IOSAC) in real time for the emerging application requirements of simultaneous sensing and communication for next-generation networks. Here, we propose and demonstrate the IOSAC system on the silicon nitride (SiN) photonics platform. The IOSAC devices based on microring resonators are capable of monitoring the variation of analytes, transmitting the information to the terminal along with the modulated optical signal in real-time, and replacing bulk optics in high-precision and high-speed applications. By directly integrating SiN ring resonators with optical communication networks, simultaneous sensing and optical communication are demonstrated by an optical signal transmission experimental system using especially filtering amplified spontaneous emission spectra. The refractive index (RI) sensing ring with a sensitivity of 172 nm/RIU, a figure of merit (FOM) of 1220, and a detection limit (DL) of 8.2*10-6 RIU is demonstrated. Simultaneously, the 1.25 Gbps optical on-off-keying (OOK) signal is transmitted at the concentration of different NaCl solutions, which indicates the bit-error-ratio (BER) decreases with the increase in concentration. The novel IOSAC technology shows the potential to realize high-performance simultaneous biosensing and communication in real time and further accelerate the development of IoT and 6G networks.
Beyond Intuition, a Framework for Applying GPs to Real-World Data
Jul 06, 2023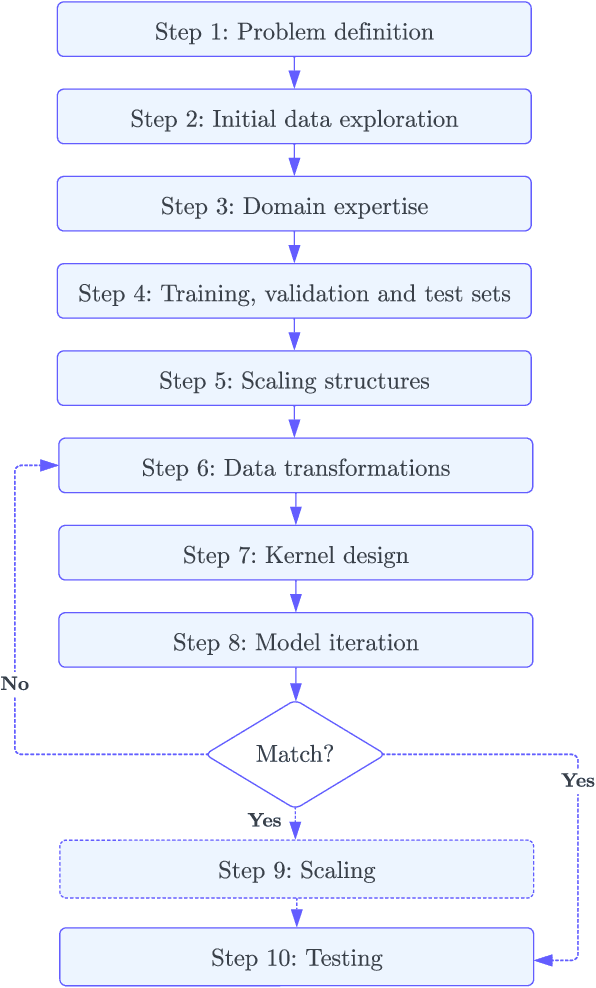
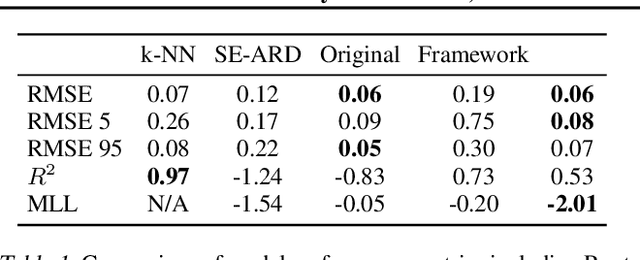
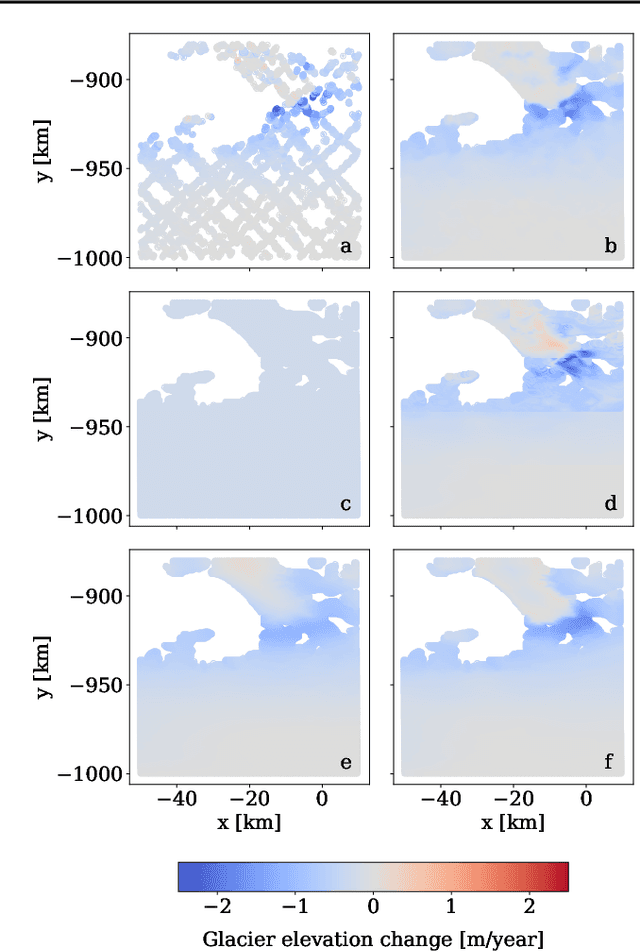
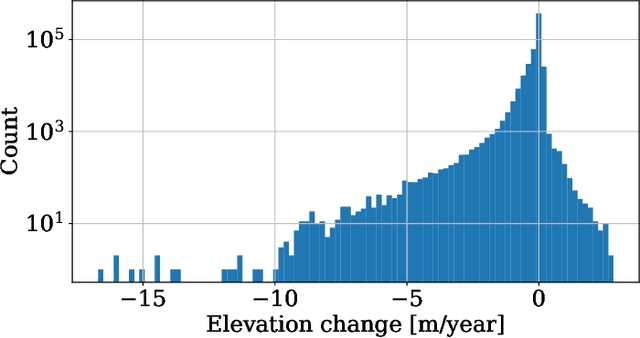
Gaussian Processes (GPs) offer an attractive method for regression over small, structured and correlated datasets. However, their deployment is hindered by computational costs and limited guidelines on how to apply GPs beyond simple low-dimensional datasets. We propose a framework to identify the suitability of GPs to a given problem and how to set up a robust and well-specified GP model. The guidelines formalise the decisions of experienced GP practitioners, with an emphasis on kernel design and options for computational scalability. The framework is then applied to a case study of glacier elevation change yielding more accurate results at test time.
Dataset Distillation Meets Provable Subset Selection
Jul 16, 2023
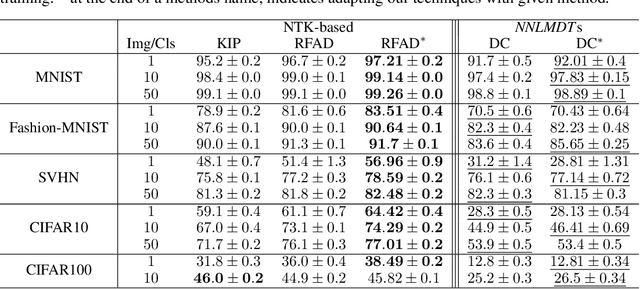
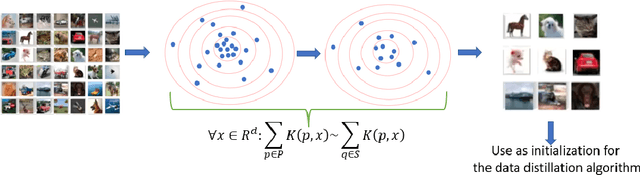
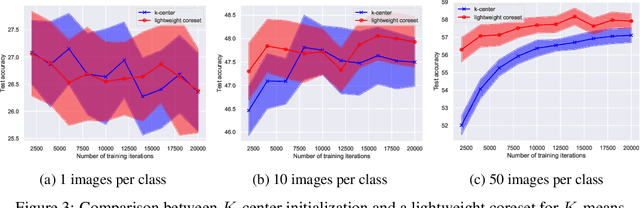
Deep learning has grown tremendously over recent years, yielding state-of-the-art results in various fields. However, training such models requires huge amounts of data, increasing the computational time and cost. To address this, dataset distillation was proposed to compress a large training dataset into a smaller synthetic one that retains its performance -- this is usually done by (1) uniformly initializing a synthetic set and (2) iteratively updating/learning this set according to a predefined loss by uniformly sampling instances from the full data. In this paper, we improve both phases of dataset distillation: (1) we present a provable, sampling-based approach for initializing the distilled set by identifying important and removing redundant points in the data, and (2) we further merge the idea of data subset selection with dataset distillation, by training the distilled set on ``important'' sampled points during the training procedure instead of randomly sampling the next batch. To do so, we define the notion of importance based on the relative contribution of instances with respect to two different loss functions, i.e., one for the initialization phase (a kernel fitting function for kernel ridge regression and $K$-means based loss function for any other distillation method), and the relative cross-entropy loss (or any other predefined loss) function for the training phase. Finally, we provide experimental results showing how our method can latch on to existing dataset distillation techniques and improve their performance.
EasyTPP: Towards Open Benchmarking the Temporal Point Processes
Jul 16, 2023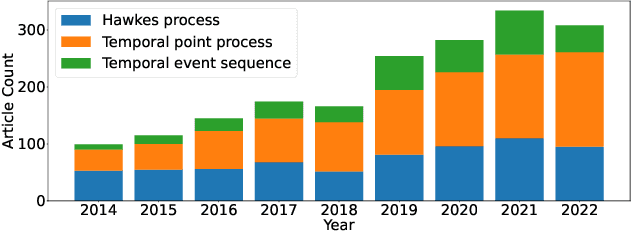
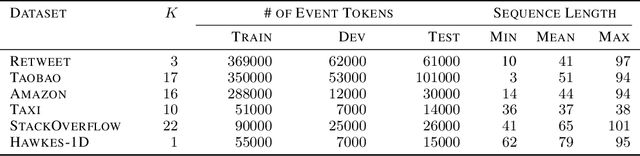

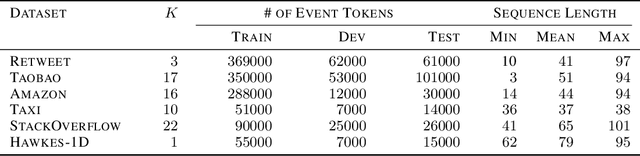
Continuous-time event sequences play a vital role in real-world domains such as healthcare, finance, online shopping, social networks, and so on. To model such data, temporal point processes (TPPs) have emerged as the most advanced generative models, making a significant impact in both academic and application communities. Despite the emergence of many powerful models in recent years, there is still no comprehensive benchmark to evaluate them. This lack of standardization impedes researchers and practitioners from comparing methods and reproducing results, potentially slowing down progress in this field. In this paper, we present EasyTPP, which aims to establish a central benchmark for evaluating TPPs. Compared to previous work that also contributed datasets, our EasyTPP has three unique contributions to the community: (i) a comprehensive implementation of eight highly cited neural TPPs with the integration of commonly used evaluation metrics and datasets; (ii) a standardized benchmarking pipeline for a transparent and thorough comparison of different methods on different datasets; (iii) a universal framework supporting multiple ML libraries (e.g., PyTorch and TensorFlow) as well as custom implementations. Our benchmark is open-sourced: all the data and implementation can be found at this \href{https://github.com/ant-research/EasyTemporalPointProcess}{\textcolor{blue}{Github repository}}\footnote{\url{https://github.com/ant-research/EasyTemporalPointProcess}.}. We will actively maintain this benchmark and welcome contributions from other researchers and practitioners. Our benchmark will help promote reproducible research in this field, thus accelerating research progress as well as making more significant real-world impacts.
Fast Quantum Algorithm for Attention Computation
Jul 16, 2023Large language models (LLMs) have demonstrated exceptional performance across a wide range of tasks. These models, powered by advanced deep learning techniques, have revolutionized the field of natural language processing (NLP) and have achieved remarkable results in various language-related tasks. LLMs have excelled in tasks such as machine translation, sentiment analysis, question answering, text generation, text classification, language modeling, and more. They have proven to be highly effective in capturing complex linguistic patterns, understanding context, and generating coherent and contextually relevant text. The attention scheme plays a crucial role in the architecture of large language models (LLMs). It is a fundamental component that enables the model to capture and utilize contextual information during language processing tasks effectively. Making the attention scheme computation faster is one of the central questions to speed up the LLMs computation. It is well-known that quantum machine has certain computational advantages compared to the classical machine. However, it is currently unknown whether quantum computing can aid in LLM. In this work, we focus on utilizing Grover's Search algorithm to compute a sparse attention computation matrix efficiently. We achieve a polynomial quantum speed-up over the classical method. Moreover, the attention matrix outputted by our quantum algorithm exhibits an extra low-rank structure that will be useful in obtaining a faster training algorithm for LLMs. Additionally, we present a detailed analysis of the algorithm's error analysis and time complexity within the context of computing the attention matrix.
S-Omninet: Structured Data Enhanced Universal Multimodal Learning Architecture
Jul 01, 2023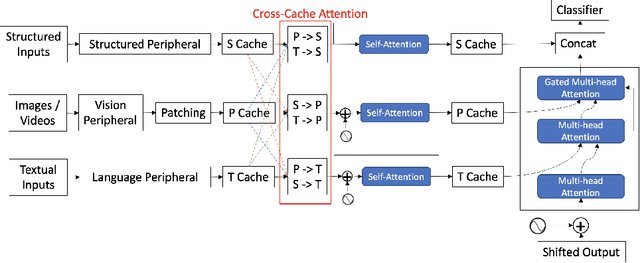
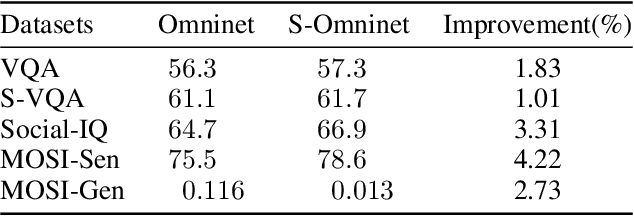
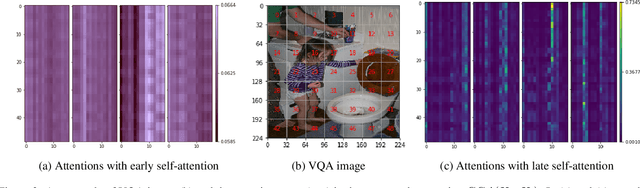
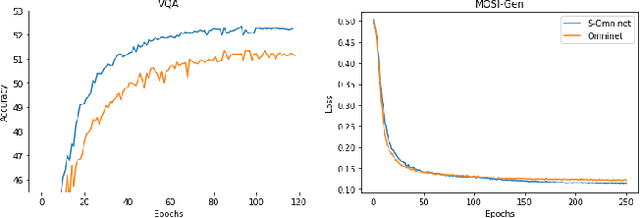
Multimodal multitask learning has attracted an increasing interest in recent years. Singlemodal models have been advancing rapidly and have achieved astonishing results on various tasks across multiple domains. Multimodal learning offers opportunities for further improvements by integrating data from multiple modalities. Many methods are proposed to learn on a specific type of multimodal data, such as vision and language data. A few of them are designed to handle several modalities and tasks at a time. In this work, we extend and improve Omninet, an architecture that is capable of handling multiple modalities and tasks at a time, by introducing cross-cache attention, integrating patch embeddings for vision inputs, and supporting structured data. The proposed Structured-data-enhanced Omninet (S-Omninet) is a universal model that is capable of learning from structured data of various dimensions effectively with unstructured data through cross-cache attention, which enables interactions among spatial, temporal, and structured features. We also enhance spatial representations in a spatial cache with patch embeddings. We evaluate the proposed model on several multimodal datasets and demonstrate a significant improvement over the baseline, Omninet.
Multi-Channel Feature Extraction for Virtual Histological Staining of Photon Absorption Remote Sensing Images
Jul 04, 2023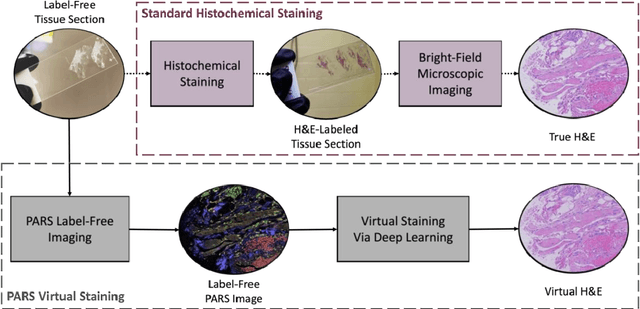
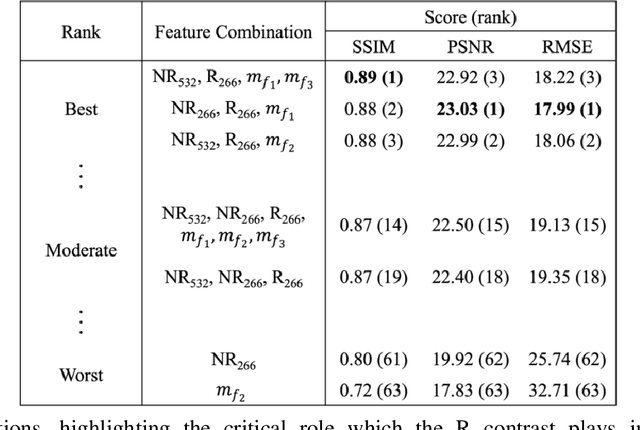
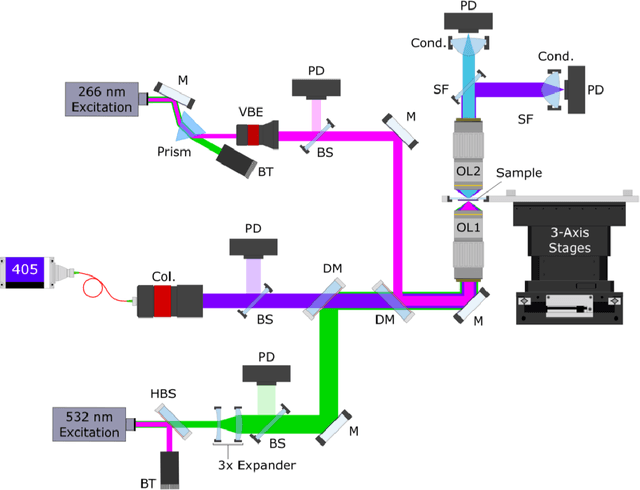
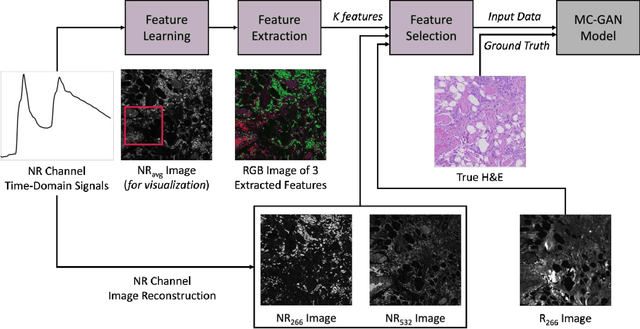
Accurate and fast histological staining is crucial in histopathology, impacting diagnostic precision and reliability. Traditional staining methods are time-consuming and subjective, causing delays in diagnosis. Digital pathology plays a vital role in advancing and optimizing histology processes to improve efficiency and reduce turnaround times. This study introduces a novel deep learning-based framework for virtual histological staining using photon absorption remote sensing (PARS) images. By extracting features from PARS time-resolved signals using a variant of the K-means method, valuable multi-modal information is captured. The proposed multi-channel cycleGAN (MC-GAN) model expands on the traditional cycleGAN framework, allowing the inclusion of additional features. Experimental results reveal that specific combinations of features outperform the conventional channels by improving the labeling of tissue structures prior to model training. Applied to human skin and mouse brain tissue, the results underscore the significance of choosing the optimal combination of features, as it reveals a substantial visual and quantitative concurrence between the virtually stained and the gold standard chemically stained hematoxylin and eosin (H&E) images, surpassing the performance of other feature combinations. Accurate virtual staining is valuable for reliable diagnostic information, aiding pathologists in disease classification, grading, and treatment planning. This study aims to advance label-free histological imaging and opens doors for intraoperative microscopy applications.
TrickVOS: A Bag of Tricks for Video Object Segmentation
Jun 28, 2023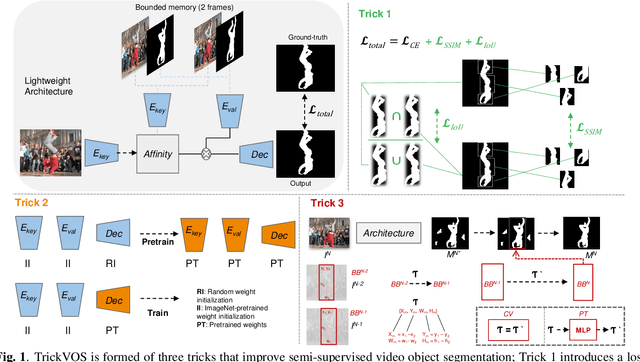
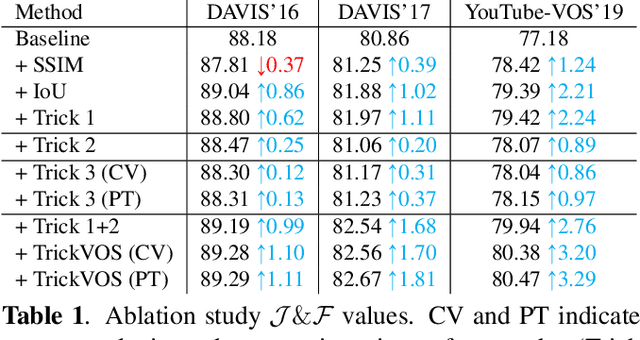
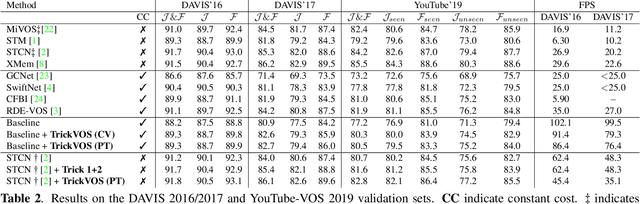

Space-time memory (STM) network methods have been dominant in semi-supervised video object segmentation (SVOS) due to their remarkable performance. In this work, we identify three key aspects where we can improve such methods; i) supervisory signal, ii) pretraining and iii) spatial awareness. We then propose TrickVOS; a generic, method-agnostic bag of tricks addressing each aspect with i) a structure-aware hybrid loss, ii) a simple decoder pretraining regime and iii) a cheap tracker that imposes spatial constraints in model predictions. Finally, we propose a lightweight network and show that when trained with TrickVOS, it achieves competitive results to state-of-the-art methods on DAVIS and YouTube benchmarks, while being one of the first STM-based SVOS methods that can run in real-time on a mobile device.