 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Automatic Design of Semantic Similarity Ensembles Using Grammatical Evolution
Jul 03, 2023

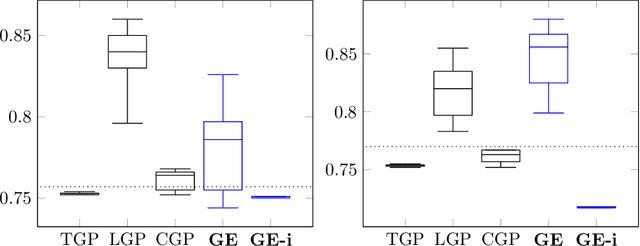
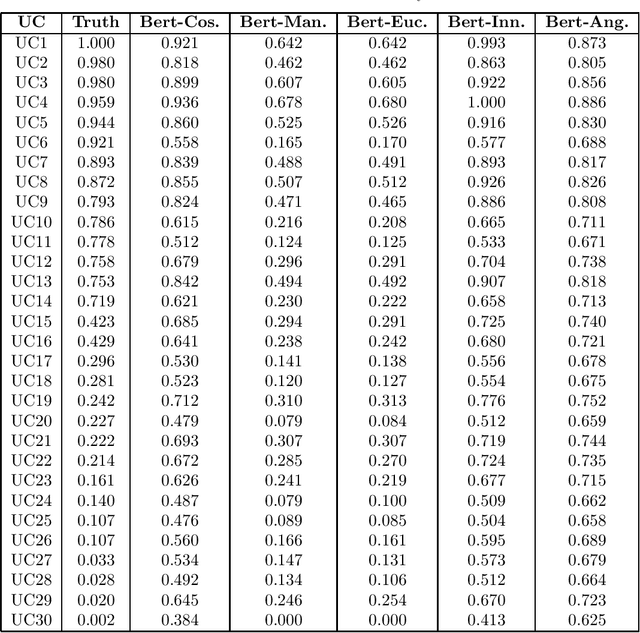
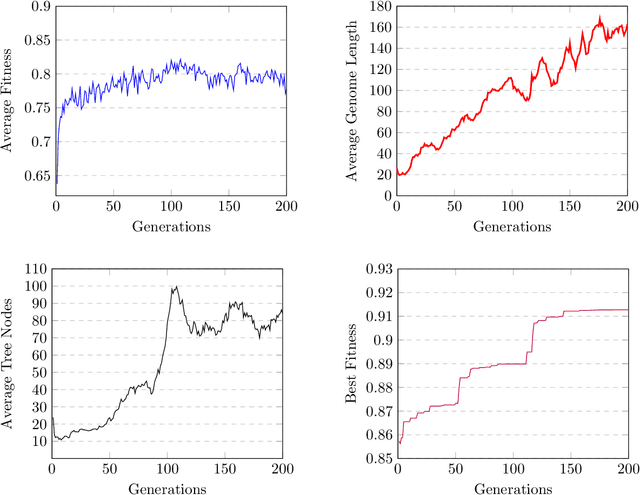
Semantic similarity measures are widely used in natural language processing to catalyze various computer-related tasks. However, no single semantic similarity measure is the most appropriate for all tasks, and researchers often use ensemble strategies to ensure performance. This research work proposes a method for automatically designing semantic similarity ensembles. In fact, our proposed method uses grammatical evolution, for the first time, to automatically select and aggregate measures from a pool of candidates to create an ensemble that maximizes correlation to human judgment. The method is evaluated on several benchmark datasets and compared to state-of-the-art ensembles, showing that it can significantly improve similarity assessment accuracy and outperform existing methods in some cases. As a result, our research demonstrates the potential of using grammatical evolution to automatically compare text and prove the benefits of using ensembles for semantic similarity tasks.
Re-ReND: Real-time Rendering of NeRFs across Devices
Mar 15, 2023
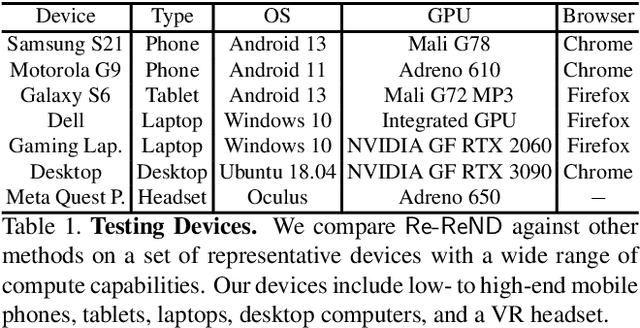
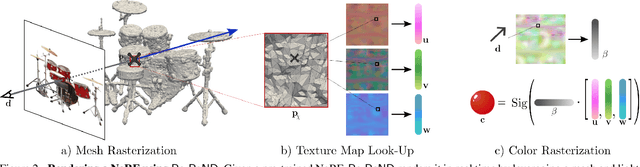
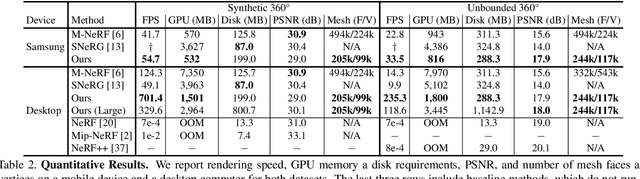
This paper proposes a novel approach for rendering a pre-trained Neural Radiance Field (NeRF) in real-time on resource-constrained devices. We introduce Re-ReND, a method enabling Real-time Rendering of NeRFs across Devices. Re-ReND is designed to achieve real-time performance by converting the NeRF into a representation that can be efficiently processed by standard graphics pipelines. The proposed method distills the NeRF by extracting the learned density into a mesh, while the learned color information is factorized into a set of matrices that represent the scene's light field. Factorization implies the field is queried via inexpensive MLP-free matrix multiplications, while using a light field allows rendering a pixel by querying the field a single time-as opposed to hundreds of queries when employing a radiance field. Since the proposed representation can be implemented using a fragment shader, it can be directly integrated with standard rasterization frameworks. Our flexible implementation can render a NeRF in real-time with low memory requirements and on a wide range of resource-constrained devices, including mobiles and AR/VR headsets. Notably, we find that Re-ReND can achieve over a 2.6-fold increase in rendering speed versus the state-of-the-art without perceptible losses in quality.
Data Structures for Density Estimation
Jun 20, 2023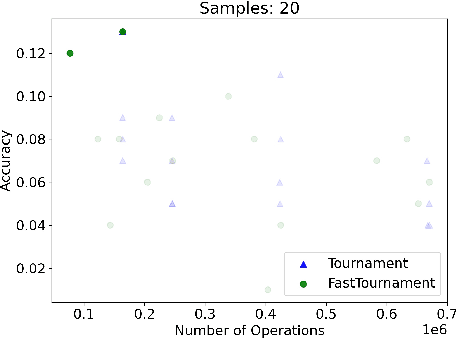
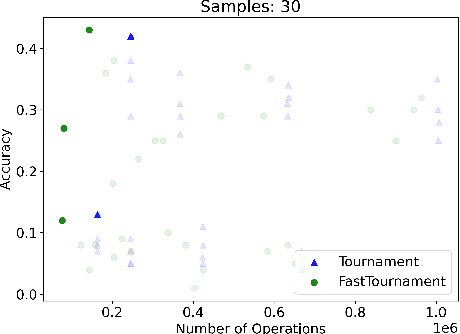
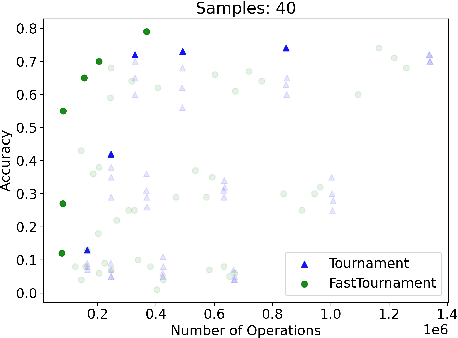
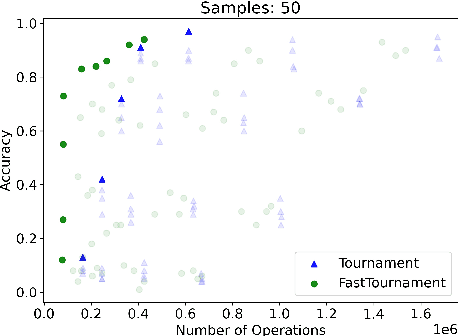
We study statistical/computational tradeoffs for the following density estimation problem: given $k$ distributions $v_1, \ldots, v_k$ over a discrete domain of size $n$, and sampling access to a distribution $p$, identify $v_i$ that is "close" to $p$. Our main result is the first data structure that, given a sublinear (in $n$) number of samples from $p$, identifies $v_i$ in time sublinear in $k$. We also give an improved version of the algorithm of Acharya et al. (2018) that reports $v_i$ in time linear in $k$. The experimental evaluation of the latter algorithm shows that it achieves a significant reduction in the number of operations needed to achieve a given accuracy compared to prior work.
Of Spiky SVDs and Music Recommendation
Jun 30, 2023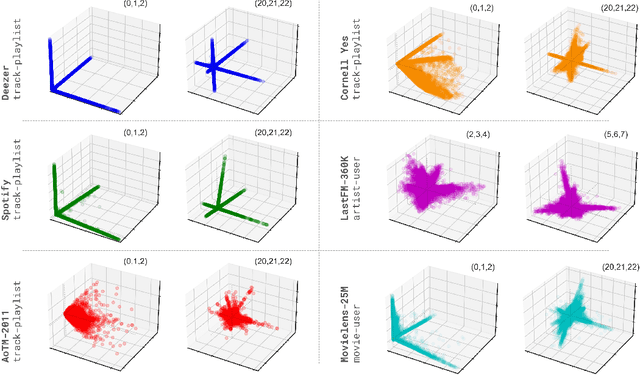

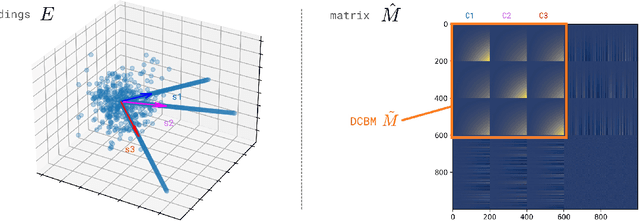

The truncated singular value decomposition is a widely used methodology in music recommendation for direct similar-item retrieval or embedding musical items for downstream tasks. This paper investigates a curious effect that we show naturally occurring on many recommendation datasets: spiking formations in the embedding space. We first propose a metric to quantify this spiking organization's strength, then mathematically prove its origin tied to underlying communities of items of varying internal popularity. With this new-found theoretical understanding, we finally open the topic with an industrial use case of estimating how music embeddings' top-k similar items will change over time under the addition of data.
Achieving RGB-D level Segmentation Performance from a Single ToF Camera
Jun 30, 2023
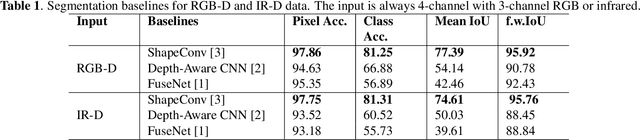
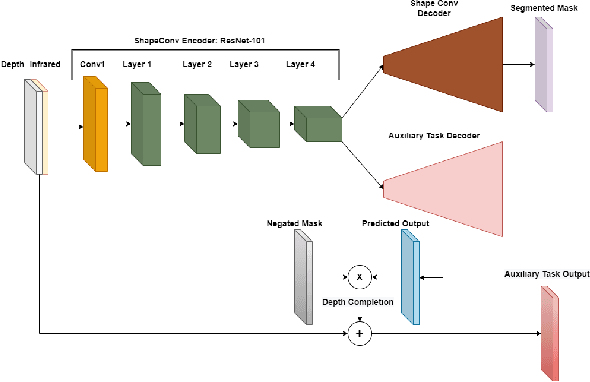
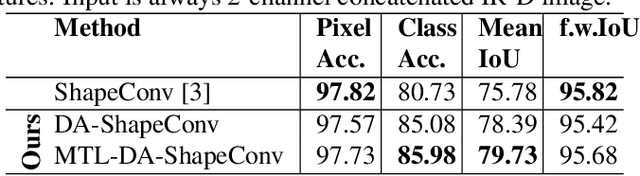
Depth is a very important modality in computer vision, typically used as complementary information to RGB, provided by RGB-D cameras. In this work, we show that it is possible to obtain the same level of accuracy as RGB-D cameras on a semantic segmentation task using infrared (IR) and depth images from a single Time-of-Flight (ToF) camera. In order to fuse the IR and depth modalities of the ToF camera, we introduce a method utilizing depth-specific convolutions in a multi-task learning framework. In our evaluation on an in-car segmentation dataset, we demonstrate the competitiveness of our method against the more costly RGB-D approaches.
ADASSM: Adversarial Data Augmentation in Statistical Shape Models From Images
Jul 10, 2023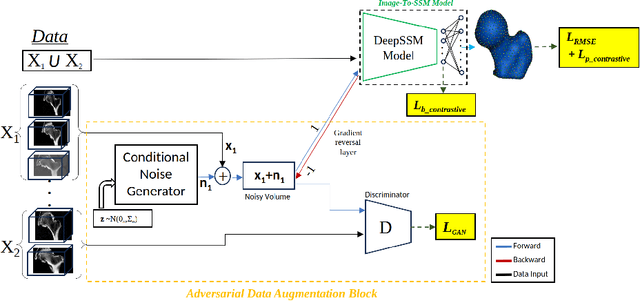
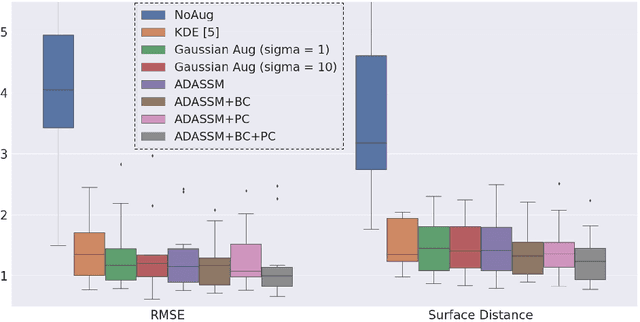
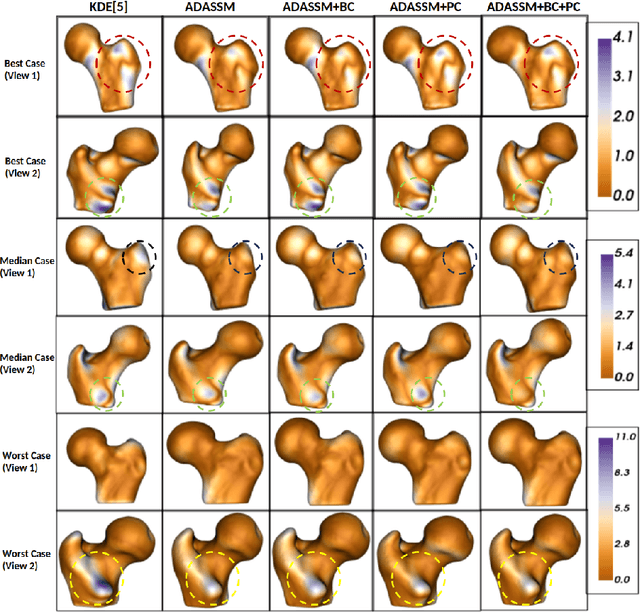
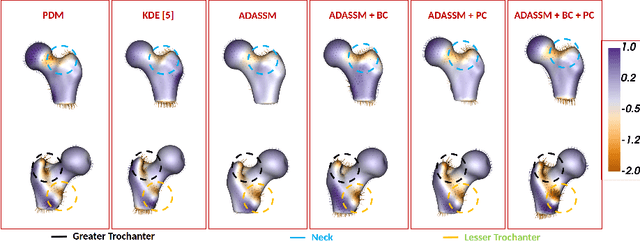
Statistical shape models (SSM) have been well-established as an excellent tool for identifying variations in the morphology of anatomy across the underlying population. Shape models use consistent shape representation across all the samples in a given cohort, which helps to compare shapes and identify the variations that can detect pathologies and help in formulating treatment plans. In medical imaging, computing these shape representations from CT/MRI scans requires time-intensive preprocessing operations, including but not limited to anatomy segmentation annotations, registration, and texture denoising. Deep learning models have demonstrated exceptional capabilities in learning shape representations directly from volumetric images, giving rise to highly effective and efficient Image-to-SSM. Nevertheless, these models are data-hungry and due to the limited availability of medical data, deep learning models tend to overfit. Offline data augmentation techniques, that use kernel density estimation based (KDE) methods for generating shape-augmented samples, have successfully aided Image-to-SSM networks in achieving comparable accuracy to traditional SSM methods. However, these augmentation methods focus on shape augmentation, whereas deep learning models exhibit image-based texture bias results in sub-optimal models. This paper introduces a novel strategy for on-the-fly data augmentation for the Image-to-SSM framework by leveraging data-dependent noise generation or texture augmentation. The proposed framework is trained as an adversary to the Image-to-SSM network, augmenting diverse and challenging noisy samples. Our approach achieves improved accuracy by encouraging the model to focus on the underlying geometry rather than relying solely on pixel values.
Joint Communications and Sensing Hybrid Beamforming Design via Deep Unfolding
Jul 10, 2023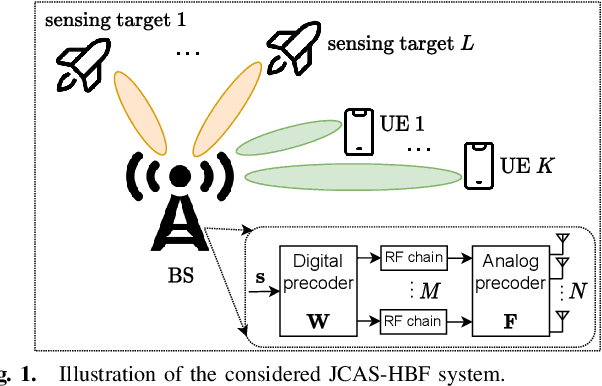
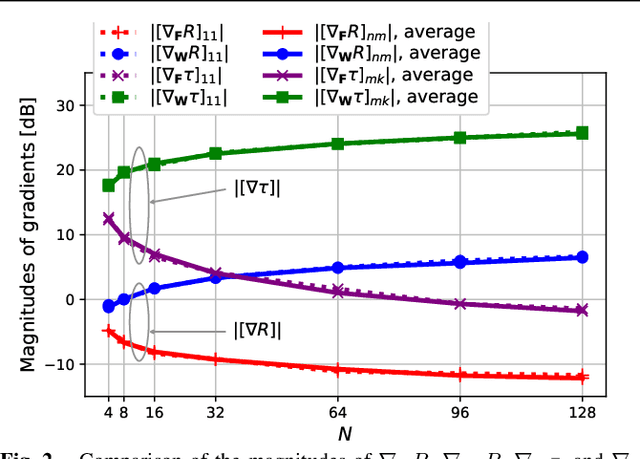
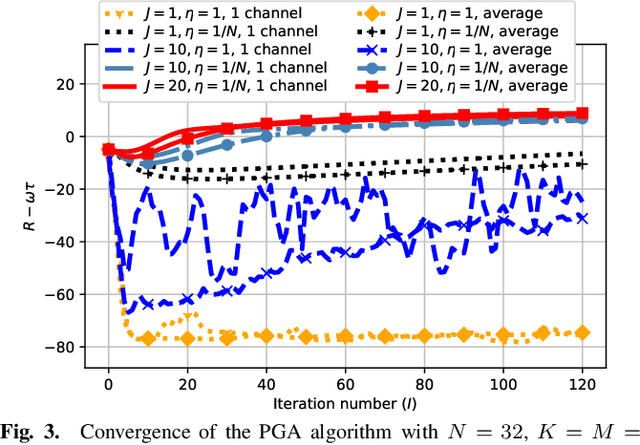
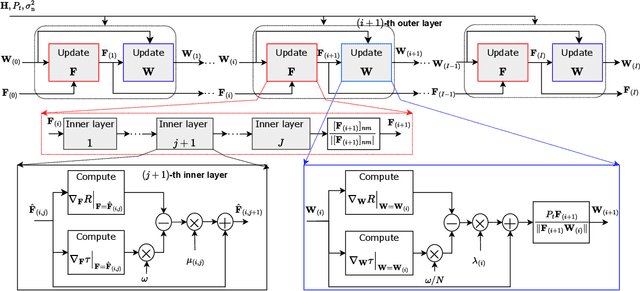
Joint communications and sensing (JCAS) is envisioned as a key feature in future wireless communications networks. In massive MIMO-JCAS systems, hybrid beamforming (HBF) is typically employed to achieve satisfactory beamforming gains with reasonable hardware cost and power consumption. Due to the coupling of the analog and digital precoders in HBF and the dual objective in JCAS, JCAS-HBF design problems are very challenging and usually require highly complex algorithms. In this paper, we propose a fast HBF design for JCAS based on deep unfolding to optimize a tradeoff between the communications rate and sensing accuracy. We first derive closed-form expressions for the gradients of the communications and sensing objectives with respect to the precoders and demonstrate that the magnitudes of the gradients pertaining to the analog precoder are typically smaller than those associated with the digital precoder. Based on this observation, we propose a modified projected gradient ascent (PGA) method with significantly improved convergence. We then develop a deep unfolded PGA scheme that efficiently optimizes the communications-sensing performance tradeoff with fast convergence thanks to the well-trained hyperparameters. In doing so, we preserve the interpretability and flexibility of the optimizer while leveraging data to improve performance. Finally, our simulations demonstrate the potential of the proposed deep unfolded method, which achieves up to 33.5% higher communications sum rate and 2.5 dB lower beampattern error compared with the conventional design based on successive convex approximation and Riemannian manifold optimization. Furthermore, it attains up to a 65% reduction in run time and computational complexity with respect to the PGA procedure without unfolding.
Model-Driven Engineering for Artificial Intelligence -- A Systematic Literature Review
Jul 10, 2023

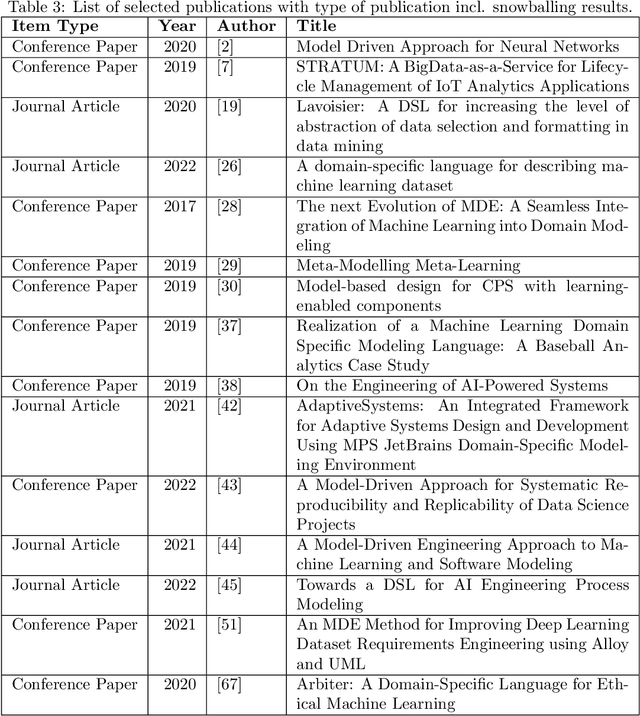
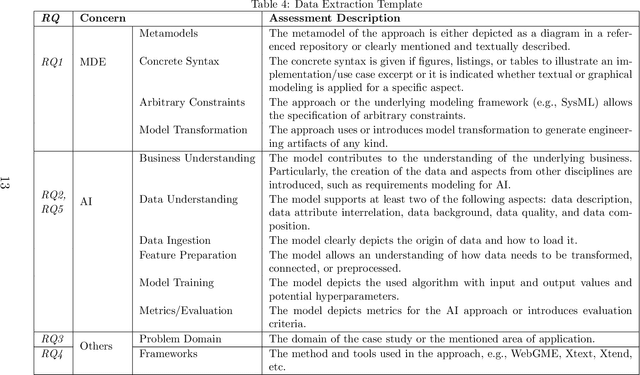
Objective: This study aims to investigate the existing body of knowledge in the field of Model-Driven Engineering MDE in support of AI (MDE4AI) to sharpen future research further and define the current state of the art. Method: We conducted a Systemic Literature Review (SLR), collecting papers from five major databases resulting in 703 candidate studies, eventually retaining 15 primary studies. Each primary study will be evaluated and discussed with respect to the adoption of (1) MDE principles and practices and (2) the phases of AI development support aligned with the stages of the CRISP-DM methodology. Results: The study's findings show that the pillar concepts of MDE (metamodel, concrete syntax and model transformation), are leveraged to define domain-specific languages (DSL) explicitly addressing AI concerns. Different MDE technologies are used, leveraging different language workbenches. The most prominent AI-related concerns are training and modeling of the AI algorithm, while minor emphasis is given to the time-consuming preparation of the data sets. Early project phases that support interdisciplinary communication of requirements, such as the CRISP-DM \textit{Business Understanding} phase, are rarely reflected. Conclusion: The study found that the use of MDE for AI is still in its early stages, and there is no single tool or method that is widely used. Additionally, current approaches tend to focus on specific stages of development rather than providing support for the entire development process. As a result, the study suggests several research directions to further improve the use of MDE for AI and to guide future research in this area.
Streaming egocentric action anticipation: An evaluation scheme and approach
Jun 29, 2023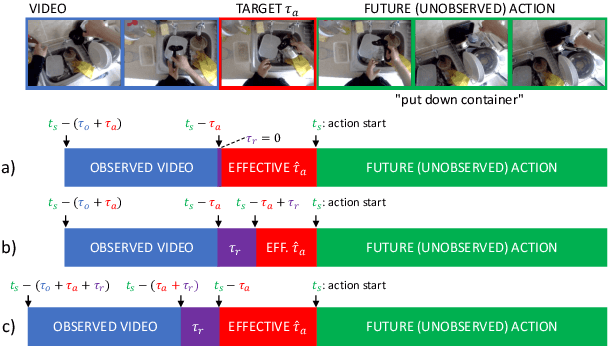
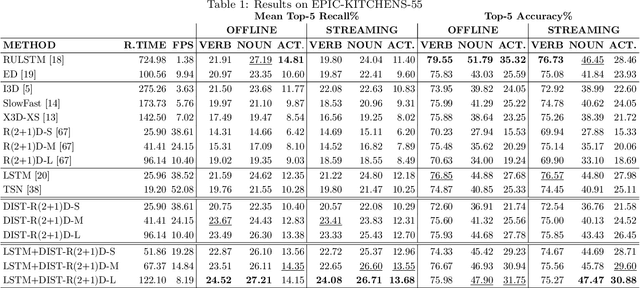
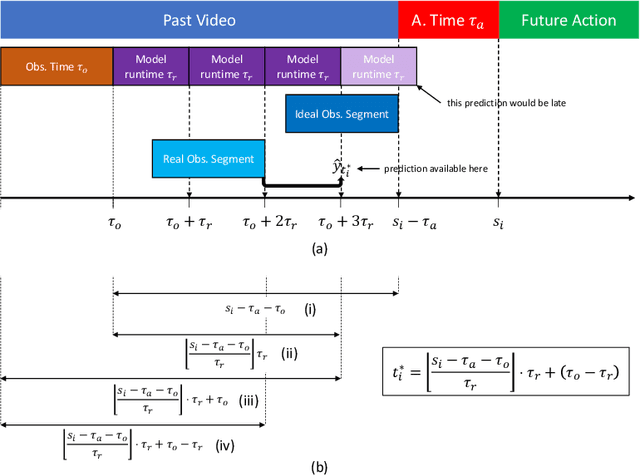
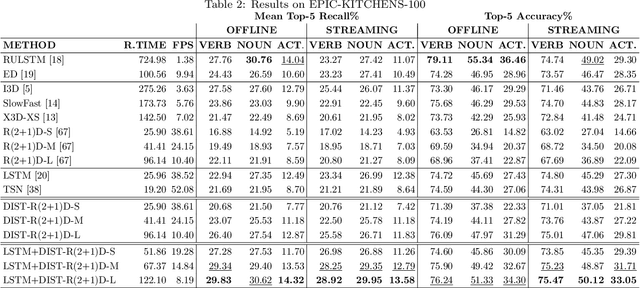
Egocentric action anticipation aims to predict the future actions the camera wearer will perform from the observation of the past. While predictions about the future should be available before the predicted events take place, most approaches do not pay attention to the computational time required to make such predictions. As a result, current evaluation schemes assume that predictions are available right after the input video is observed, i.e., presuming a negligible runtime, which may lead to overly optimistic evaluations. We propose a streaming egocentric action evaluation scheme which assumes that predictions are performed online and made available only after the model has processed the current input segment, which depends on its runtime. To evaluate all models considering the same prediction horizon, we hence propose that slower models should base their predictions on temporal segments sampled ahead of time. Based on the observation that model runtime can affect performance in the considered streaming evaluation scenario, we further propose a lightweight action anticipation model based on feed-forward 3D CNNs which is optimized using knowledge distillation techniques with a novel past-to-future distillation loss. Experiments on the three popular datasets EPIC-KITCHENS-55, EPIC-KITCHENS-100 and EGTEA Gaze+ show that (i) the proposed evaluation scheme induces a different ranking on state-of-the-art methods as compared to classic evaluations, (ii) lightweight approaches tend to outmatch more computationally expensive ones, and (iii) the proposed model based on feed-forward 3D CNNs and knowledge distillation outperforms current art in the streaming egocentric action anticipation scenario.
Nonsmooth Control Barrier Functions for Obstacle Avoidance between Convex Regions
Jun 23, 2023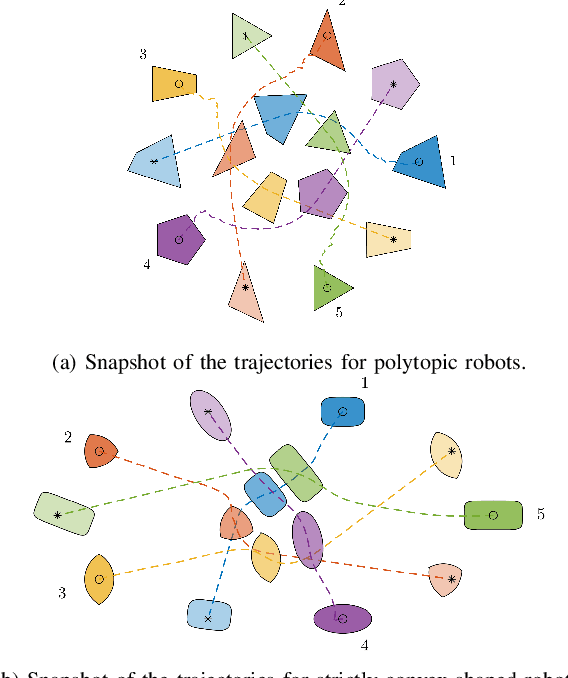
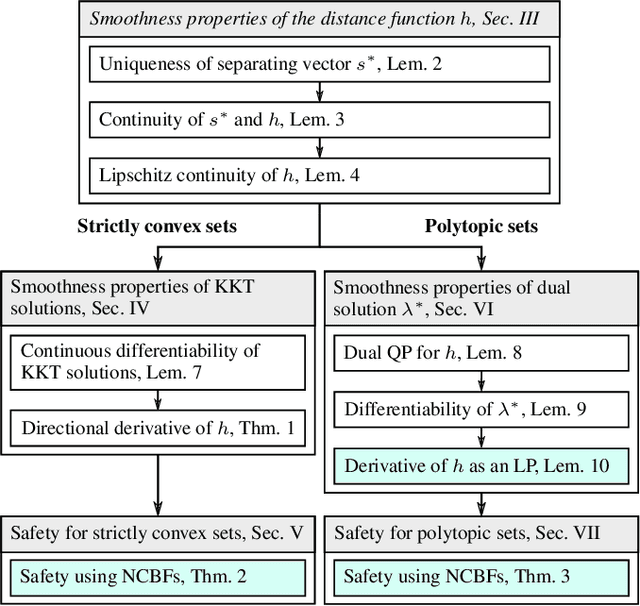
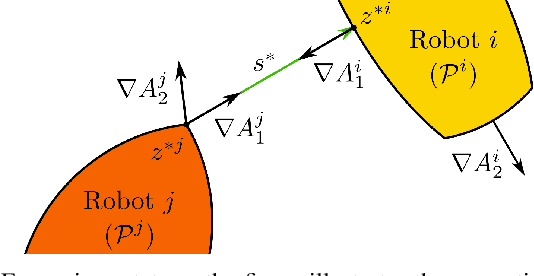
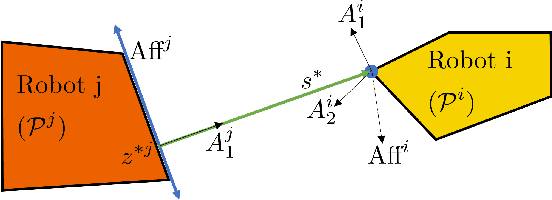
In this paper, we focus on non-conservative obstacle avoidance between robots with control affine dynamics with strictly convex and polytopic shapes. The core challenge for this obstacle avoidance problem is that the minimum distance between strictly convex regions or polytopes is generally implicit and non-smooth, such that distance constraints cannot be enforced directly in the optimization problem. To handle this challenge, we employ non-smooth control barrier functions to reformulate the avoidance problem in the dual space, with the positivity of the minimum distance between robots equivalently expressed using a quadratic program. Our approach is proven to guarantee system safety. We theoretically analyze the smoothness properties of the minimum distance quadratic program and its KKT conditions. We validate our approach by demonstrating computationally-efficient obstacle avoidance for multi-agent robotic systems with strictly convex and polytopic shapes. To our best knowledge, this is the first time a real-time QP problem can be formulated for general non-conservative avoidance between strictly convex shapes and polytopes.