 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Optimizing Task Waiting Times in Dynamic Vehicle Routing
Jul 08, 2023
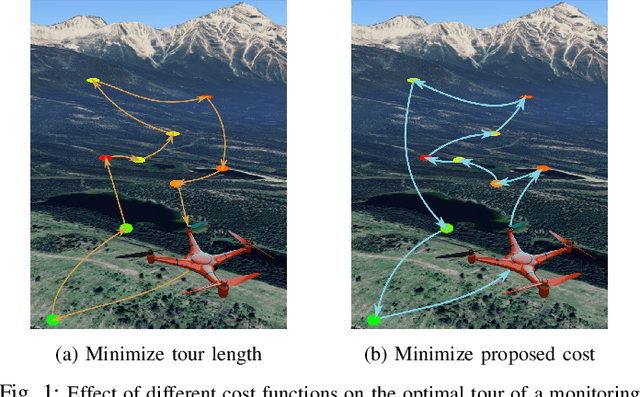

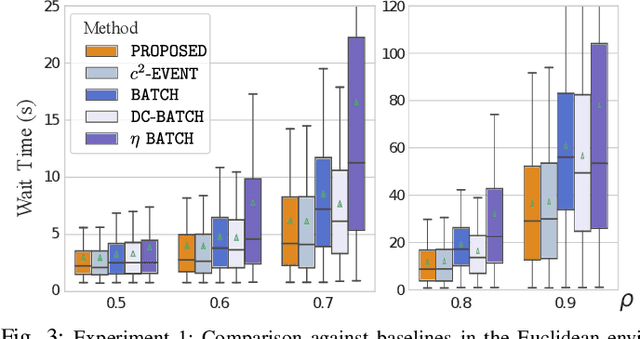
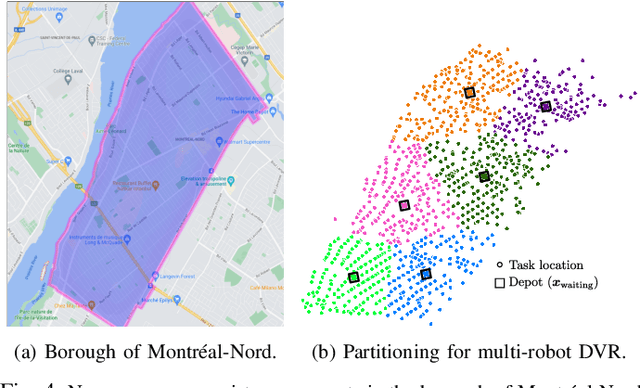
We study the problem of deploying a fleet of mobile robots to service tasks that arrive stochastically over time and at random locations in an environment. This is known as the Dynamic Vehicle Routing Problem (DVRP) and requires robots to allocate incoming tasks among themselves and find an optimal sequence for each robot. State-of-the-art approaches only consider average wait times and focus on high-load scenarios where the arrival rate of tasks approaches the limit of what can be handled by the robots while keeping the queue of unserviced tasks bounded, i.e., stable. To ensure stability, these approaches repeatedly compute minimum distance tours over a set of newly arrived tasks. This paper is aimed at addressing the missing policies for moderate-load scenarios, where quality of service can be improved by prioritizing long-waiting tasks. We introduce a novel DVRP policy based on a cost function that takes the $p$-norm over accumulated wait times and show it guarantees stability even in high-load scenarios. We demonstrate that the proposed policy outperforms the state-of-the-art in both mean and $95^{th}$ percentile wait times in moderate-load scenarios through simulation experiments in the Euclidean plane as well as using real-world data for city scale service requests.
RObotic MAnipulation Network (ROMAN) $\unicode{x2013}$ Hybrid Hierarchical Learning for Solving Complex Sequential Tasks
Jul 07, 2023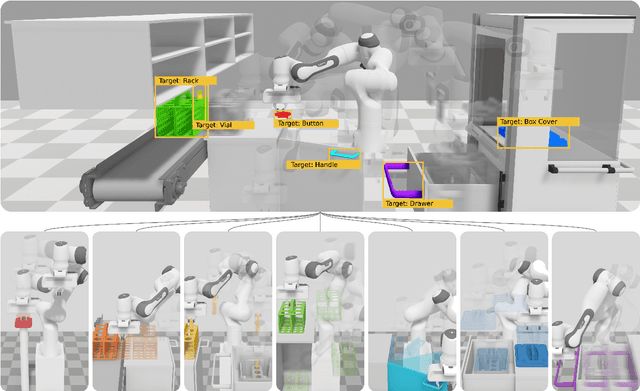
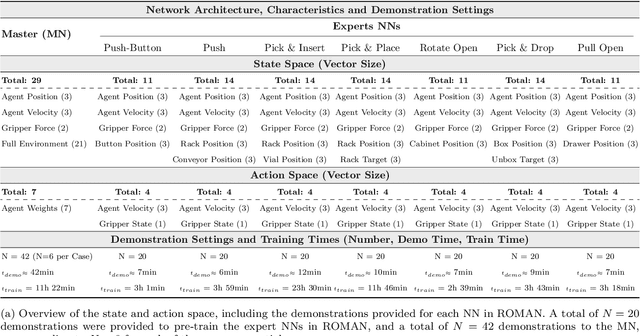
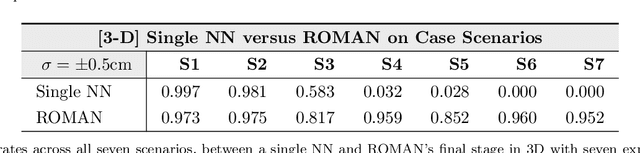
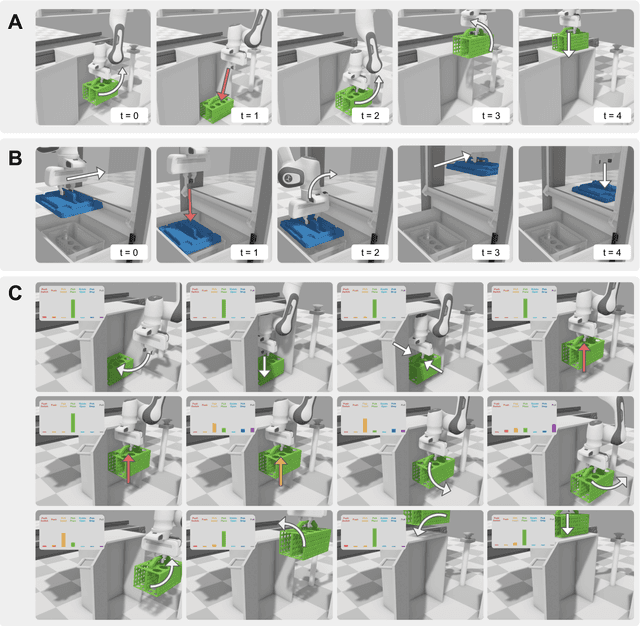
Solving long sequential tasks poses a significant challenge in embodied artificial intelligence. Enabling a robotic system to perform diverse sequential tasks with a broad range of manipulation skills is an active area of research. In this work, we present a Hybrid Hierarchical Learning framework, the Robotic Manipulation Network (ROMAN), to address the challenge of solving multiple complex tasks over long time horizons in robotic manipulation. ROMAN achieves task versatility and robust failure recovery by integrating behavioural cloning, imitation learning, and reinforcement learning. It consists of a central manipulation network that coordinates an ensemble of various neural networks, each specialising in distinct re-combinable sub-tasks to generate their correct in-sequence actions for solving complex long-horizon manipulation tasks. Experimental results show that by orchestrating and activating these specialised manipulation experts, ROMAN generates correct sequential activations for accomplishing long sequences of sophisticated manipulation tasks and achieving adaptive behaviours beyond demonstrations, while exhibiting robustness to various sensory noises. These results demonstrate the significance and versatility of ROMAN's dynamic adaptability featuring autonomous failure recovery capabilities, and highlight its potential for various autonomous manipulation tasks that demand adaptive motor skills.
Enhancing Adversarial Training via Reweighting Optimization Trajectory
Jul 07, 2023
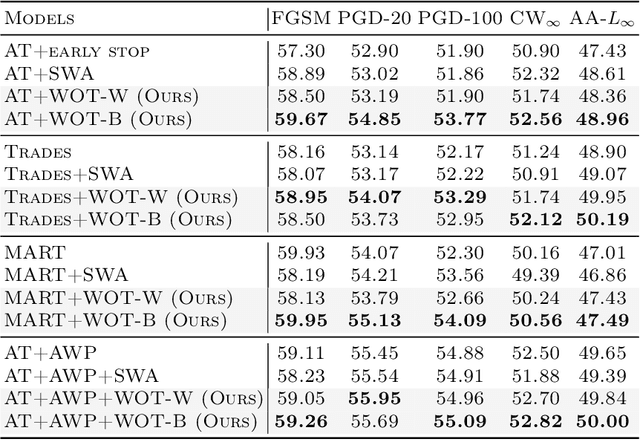
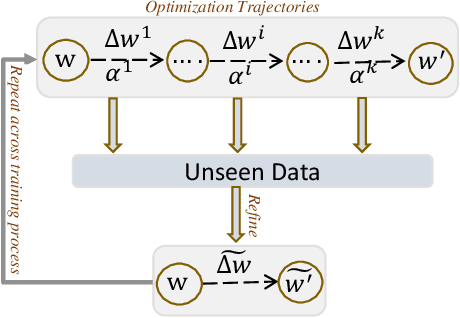
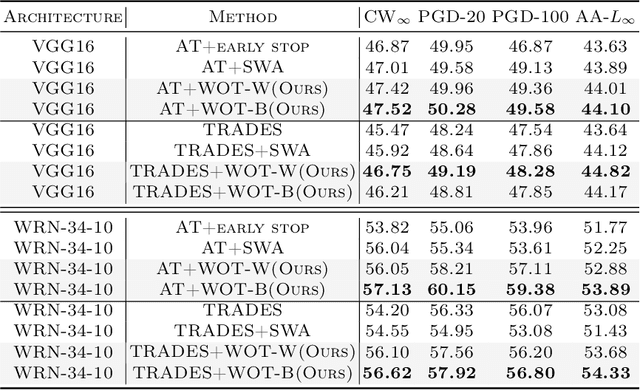
Despite the fact that adversarial training has become the de facto method for improving the robustness of deep neural networks, it is well-known that vanilla adversarial training suffers from daunting robust overfitting, resulting in unsatisfactory robust generalization. A number of approaches have been proposed to address these drawbacks such as extra regularization, adversarial weights perturbation, and training with more data over the last few years. However, the robust generalization improvement is yet far from satisfactory. In this paper, we approach this challenge with a brand new perspective -- refining historical optimization trajectories. We propose a new method named \textbf{Weighted Optimization Trajectories (WOT)} that leverages the optimization trajectories of adversarial training in time. We have conducted extensive experiments to demonstrate the effectiveness of WOT under various state-of-the-art adversarial attacks. Our results show that WOT integrates seamlessly with the existing adversarial training methods and consistently overcomes the robust overfitting issue, resulting in better adversarial robustness. For example, WOT boosts the robust accuracy of AT-PGD under AA-$L_{\infty}$ attack by 1.53\% $\sim$ 6.11\% and meanwhile increases the clean accuracy by 0.55\%$\sim$5.47\% across SVHN, CIFAR-10, CIFAR-100, and Tiny-ImageNet datasets.
* Accepted by ECML 2023
The Ethical Implications of Generative Audio Models: A Systematic Literature Review
Jul 07, 2023Generative audio models typically focus their applications in music and speech generation, with recent models having human-like quality in their audio output. This paper conducts a systematic literature review of 884 papers in the area of generative audio models in order to both quantify the degree to which researchers in the field are considering potential negative impacts and identify the types of ethical implications researchers in this area need to consider. Though 65% of generative audio research papers note positive potential impacts of their work, less than 10% discuss any negative impacts. This jarringly small percentage of papers considering negative impact is particularly worrying because the issues brought to light by the few papers doing so are raising serious ethical implications and concerns relevant to the broader field such as the potential for fraud, deep-fakes, and copyright infringement. By quantifying this lack of ethical consideration in generative audio research and identifying key areas of potential harm, this paper lays the groundwork for future work in the field at a critical point in time in order to guide more conscientious research as this field progresses.
Predicting Outcomes in Long COVID Patients with Spatiotemporal Attention
Jul 07, 2023Long COVID is a general term of post-acute sequelae of COVID-19. Patients with long COVID can endure long-lasting symptoms including fatigue, headache, dyspnea and anosmia, etc. Identifying the cohorts with severe long-term complications in COVID-19 could benefit the treatment planning and resource arrangement. However, due to the heterogeneous phenotype presented in long COVID patients, it is difficult to predict their outcomes from their longitudinal data. In this study, we proposed a spatiotemporal attention mechanism to weigh feature importance jointly from the temporal dimension and feature space. Considering that medical examinations can have interchangeable orders in adjacent time points, we restricted the learning of short-term dependency with a Local-LSTM and the learning of long-term dependency with the joint spatiotemporal attention. We also compared the proposed method with several state-of-the-art methods and a method in clinical practice. The methods are evaluated on a hard-to-acquire clinical dataset of patients with long COVID. Experimental results show the Local-LSTM with joint spatiotemporal attention outperformed related methods in outcome prediction. The proposed method provides a clinical tool for the severity assessment of long COVID.
Do DL models and training environments have an impact on energy consumption?
Jul 07, 2023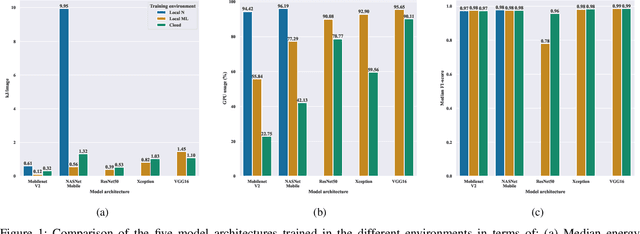
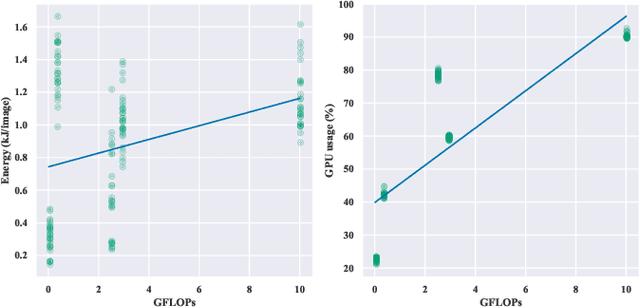
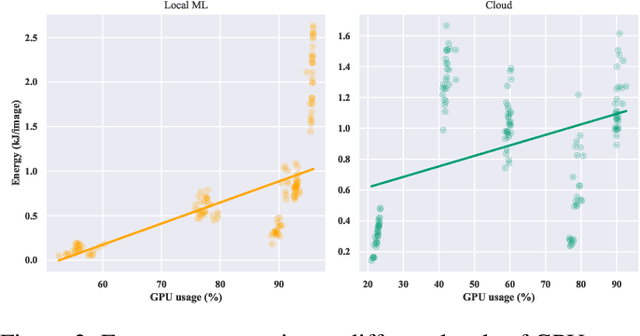
Current research in the computer vision field mainly focuses on improving Deep Learning (DL) correctness and inference time performance. However, there is still little work on the huge carbon footprint that has training DL models. This study aims to analyze the impact of the model architecture and training environment when training greener computer vision models. We divide this goal into two research questions. First, we analyze the effects of model architecture on achieving greener models while keeping correctness at optimal levels. Second, we study the influence of the training environment on producing greener models. To investigate these relationships, we collect multiple metrics related to energy efficiency and model correctness during the models' training. Then, we outline the trade-offs between the measured energy efficiency and the models' correctness regarding model architecture, and their relationship with the training environment. We conduct this research in the context of a computer vision system for image classification. In conclusion, we show that selecting the proper model architecture and training environment can reduce energy consumption dramatically (up to 98.83\%) at the cost of negligible decreases in correctness. Also, we find evidence that GPUs should scale with the models' computational complexity for better energy efficiency.
Open-World Pose Transfer via Sequential Test-Time Adaption
Mar 20, 2023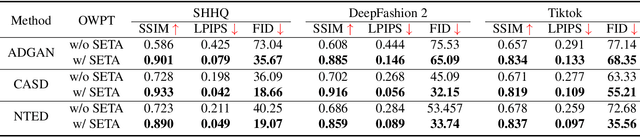
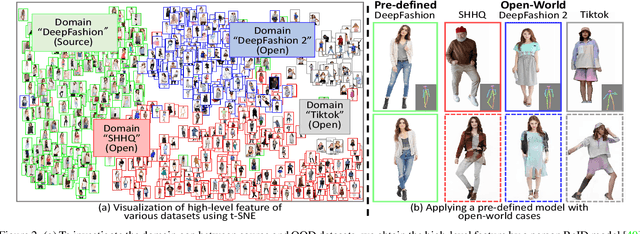
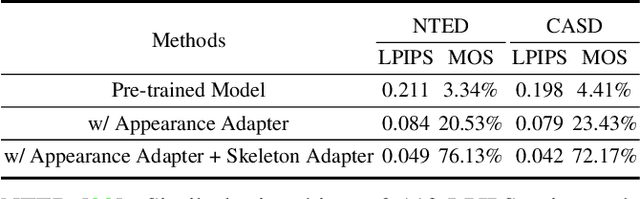
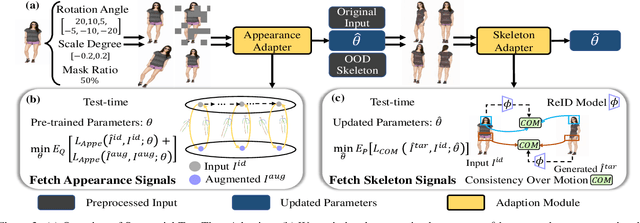
Pose transfer aims to transfer a given person into a specified posture, has recently attracted considerable attention. A typical pose transfer framework usually employs representative datasets to train a discriminative model, which is often violated by out-of-distribution (OOD) instances. Recently, test-time adaption (TTA) offers a feasible solution for OOD data by using a pre-trained model that learns essential features with self-supervision. However, those methods implicitly make an assumption that all test distributions have a unified signal that can be learned directly. In open-world conditions, the pose transfer task raises various independent signals: OOD appearance and skeleton, which need to be extracted and distributed in speciality. To address this point, we develop a SEquential Test-time Adaption (SETA). In the test-time phrase, SETA extracts and distributes external appearance texture by augmenting OOD data for self-supervised training. To make non-Euclidean similarity among different postures explicit, SETA uses the image representations derived from a person re-identification (Re-ID) model for similarity computation. By addressing implicit posture representation in the test-time sequentially, SETA greatly improves the generalization performance of current pose transfer models. In our experiment, we first show that pose transfer can be applied to open-world applications, including Tiktok reenactment and celebrity motion synthesis.
Flexible and Fully Quantized Ultra-Lightweight TinyissimoYOLO for Ultra-Low-Power Edge Systems
Jul 12, 2023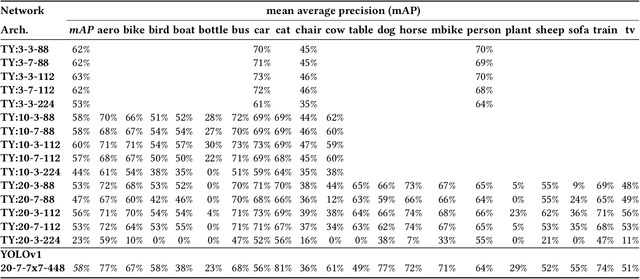
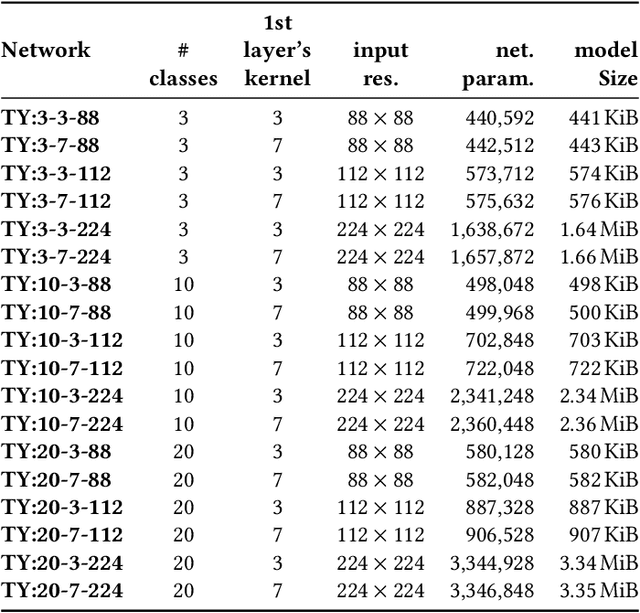

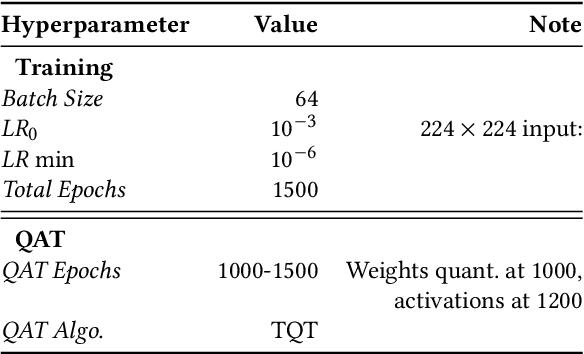
This paper deploys and explores variants of TinyissimoYOLO, a highly flexible and fully quantized ultra-lightweight object detection network designed for edge systems with a power envelope of a few milliwatts. With experimental measurements, we present a comprehensive characterization of the network's detection performance, exploring the impact of various parameters, including input resolution, number of object classes, and hidden layer adjustments. We deploy variants of TinyissimoYOLO on state-of-the-art ultra-low-power extreme edge platforms, presenting an in-depth a comparison on latency, energy efficiency, and their ability to efficiently parallelize the workload. In particular, the paper presents a comparison between a novel parallel RISC-V processor (GAP9 from Greenwaves) with and without use of its on-chip hardware accelerator, an ARM Cortex-M7 core (STM32H7 from ST Microelectronics), two ARM Cortex-M4 cores (STM32L4 from STM and Apollo4b from Ambiq), and a multi-core platform with a CNN hardware accelerator (Analog Devices MAX78000). Experimental results show that the GAP9's hardware accelerator achieves the lowest inference latency and energy at 2.12ms and 150uJ respectively, which is around 2x faster and 20% more efficient than the next best platform, the MAX78000. The hardware accelerator of GAP9 can even run an increased resolution version of TinyissimoYOLO with 112x112 pixels and 10 detection classes within 3.2ms, consuming 245uJ. To showcase the competitiveness of a versatile general-purpose system we also deployed and profiled a multi-core implementation on GAP9 at different operating points, achieving 11.3ms with the lowest-latency and 490uJ with the most energy-efficient configuration. With this paper, we demonstrate the suitability and flexibility of TinyissimoYOLO on state-of-the-art detection datasets for real-time ultra-low-power edge inference.
Guided Bottom-Up Interactive Constraint Acquisition
Jul 12, 2023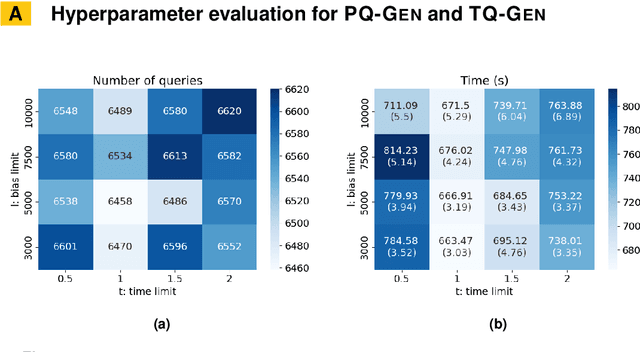
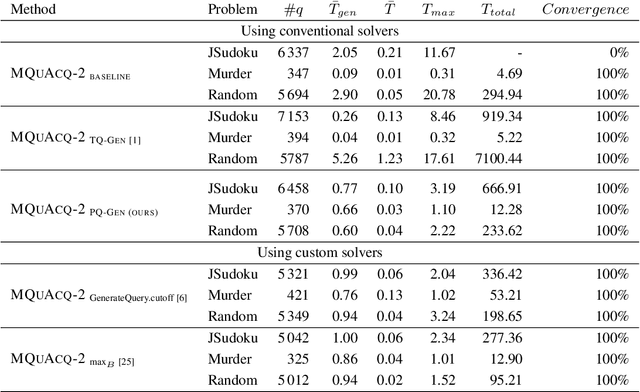
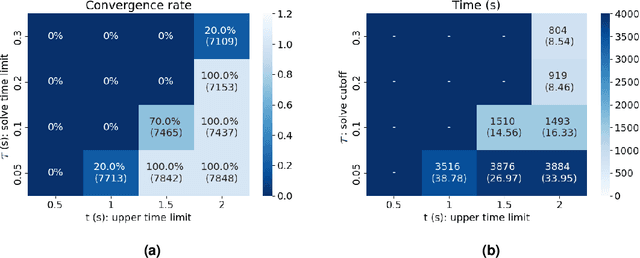
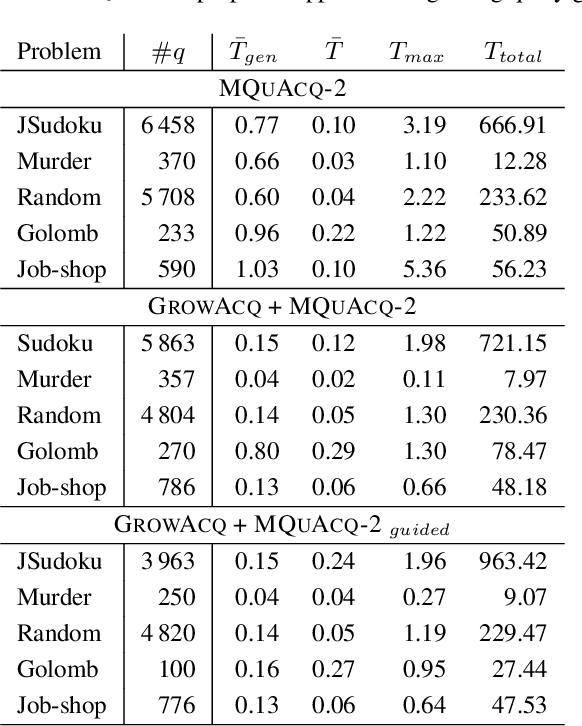
Constraint Acquisition (CA) systems can be used to assist in the modeling of constraint satisfaction problems. In (inter)active CA, the system is given a set of candidate constraints and posts queries to the user with the goal of finding the right constraints among the candidates. Current interactive CA algorithms suffer from at least two major bottlenecks. First, in order to converge, they require a large number of queries to be asked to the user. Second, they cannot handle large sets of candidate constraints, since these lead to large waiting times for the user. For this reason, the user must have fairly precise knowledge about what constraints the system should consider. In this paper, we alleviate these bottlenecks by presenting two novel methods that improve the efficiency of CA. First, we introduce a bottom-up approach named GrowAcq that reduces the maximum waiting time for the user and allows the system to handle much larger sets of candidate constraints. It also reduces the total number of queries for problems in which the target constraint network is not sparse. Second, we propose a probability-based method to guide query generation and show that it can significantly reduce the number of queries required to converge. We also propose a new technique that allows the use of openly accessible CP solvers in query generation, removing the dependency of existing methods on less well-maintained custom solvers that are not publicly available. Experimental results show that our proposed methods outperform state-of-the-art CA methods, reducing the number of queries by up to 60%. Our methods work well even in cases where the set of candidate constraints is 50 times larger than the ones commonly used in the literature.
SSVEP-Based BCI Wheelchair Control System
Jul 12, 2023
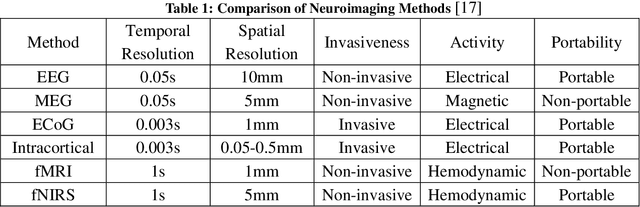
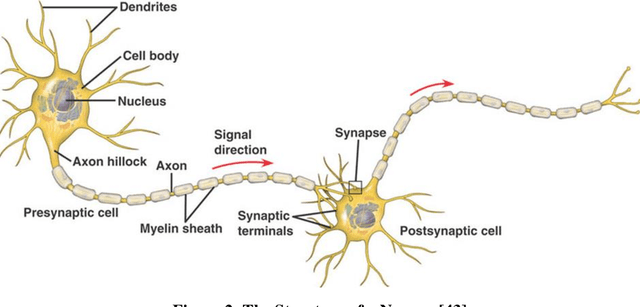

A brain-computer interface (BCI) is a system that allows a person to communicate or control the surroundings without depending on the brain's normal output pathways of peripheral nerves and muscles. A lot of successful applications have arisen utilizing the advantages of BCI to assist disabled people with so-called assistive technology. Considering using BCI has fewer limitations and huge potential, this project has been proposed to control the movement of an electronic wheelchair via brain signals. The goal of this project is to help disabled people, especially paralyzed people suffering from motor disabilities, improve their life qualities. In order to realize the project stated above, Steady-State Visual Evoked Potential (SSVEP) is involved. It can be easily elicited in the visual cortical with the same frequency as the one is being focused by the subject. There are two important parts in this project. One is to process the EEG signals and another one is to make a visual stimulator using hardware. The EEG signals are processed in Matlab using the algorithm of Butterworth Infinite Impulse Response (IIR) bandpass filter (for preprocessing) and Fast Fourier Transform (FFT) (for feature extraction). Besides, a harmonics-based classification method is proposed and applied in the classification part. Moreover, the design of the visual stimulator combines LEDs as flickers and LCDs as information displayers on one panel. Microcontrollers are employed to control the SSVEP visual stimuli panel. This project is evaluated by subjects with different races and ages. Experimental results show the system is easy to be operated and it can achieve approximately a minimum 1-second time delay. So it demonstrates that this SSVEP-based BCI-controlled wheelchair has a huge potential to be applied to disabled people in the future.