 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Co-Optimization of Environment and Policies for Decentralized Multi-Agent Navigation
Mar 21, 2024
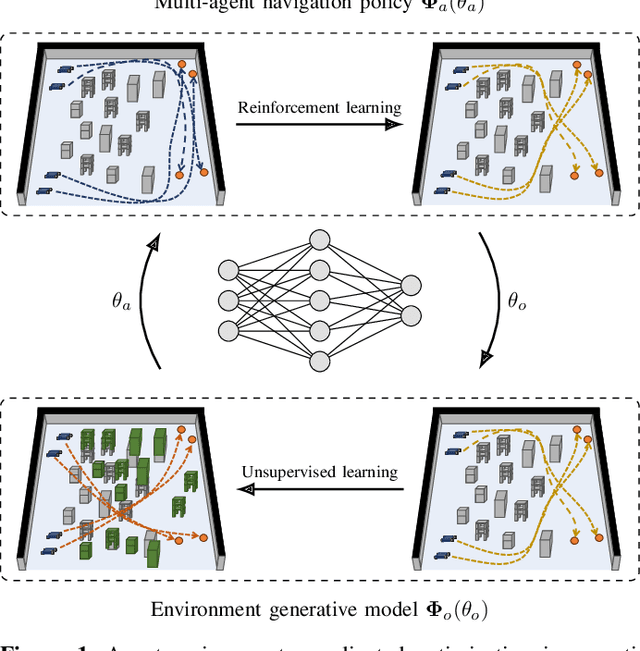
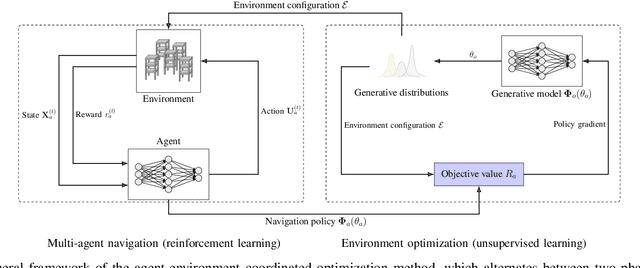
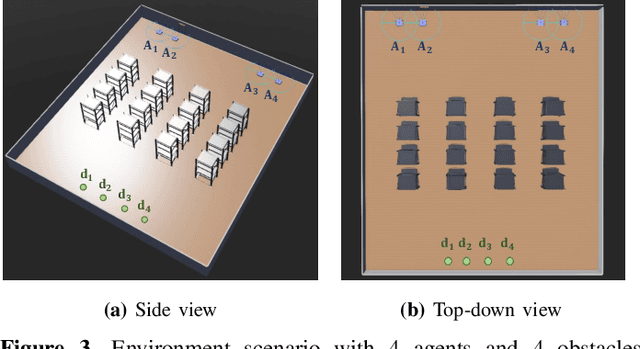
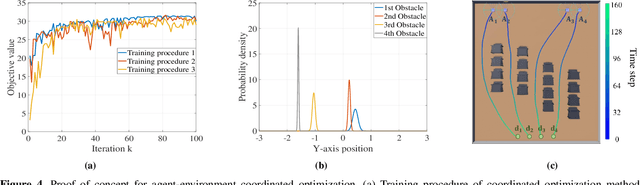
This work views the multi-agent system and its surrounding environment as a co-evolving system, where the behavior of one affects the other. The goal is to take both agent actions and environment configurations as decision variables, and optimize these two components in a coordinated manner to improve some measure of interest. Towards this end, we consider the problem of decentralized multi-agent navigation in cluttered environments. By introducing two sub-objectives of multi-agent navigation and environment optimization, we propose an $\textit{agent-environment co-optimization}$ problem and develop a $\textit{coordinated algorithm}$ that alternates between these sub-objectives to search for an optimal synthesis of agent actions and obstacle configurations in the environment; ultimately, improving the navigation performance. Due to the challenge of explicitly modeling the relation between agents, environment and performance, we leverage policy gradient to formulate a model-free learning mechanism within the coordinated framework. A formal convergence analysis shows that our coordinated algorithm tracks the local minimum trajectory of an associated time-varying non-convex optimization problem. Extensive numerical results corroborate theoretical findings and show the benefits of co-optimization over baselines. Interestingly, the results also indicate that optimized environment configurations are able to offer structural guidance that is key to de-conflicting agents in motion.
Estimating Physical Information Consistency of Channel Data Augmentation for Remote Sensing Images
Mar 21, 2024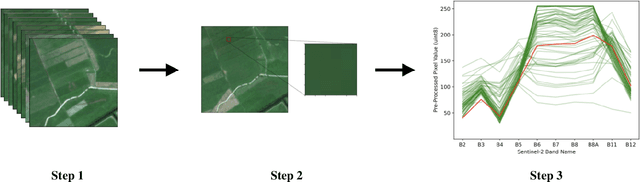
The application of data augmentation for deep learning (DL) methods plays an important role in achieving state-of-the-art results in supervised, semi-supervised, and self-supervised image classification. In particular, channel transformations (e.g., solarize, grayscale, brightness adjustments) are integrated into data augmentation pipelines for remote sensing (RS) image classification tasks. However, contradicting beliefs exist about their proper applications to RS images. A common point of critique is that the application of channel augmentation techniques may lead to physically inconsistent spectral data (i.e., pixel signatures). To shed light on the open debate, we propose an approach to estimate whether a channel augmentation technique affects the physical information of RS images. To this end, the proposed approach estimates a score that measures the alignment of a pixel signature within a time series that can be naturally subject to deviations caused by factors such as acquisition conditions or phenological states of vegetation. We compare the scores associated with original and augmented pixel signatures to evaluate the physical consistency. Experimental results on a multi-label image classification task show that channel augmentations yielding a score that exceeds the expected deviation of original pixel signatures can not improve the performance of a baseline model trained without augmentation.
Safeguarding Medical Image Segmentation Datasets against Unauthorized Training via Contour- and Texture-Aware Perturbations
Mar 21, 2024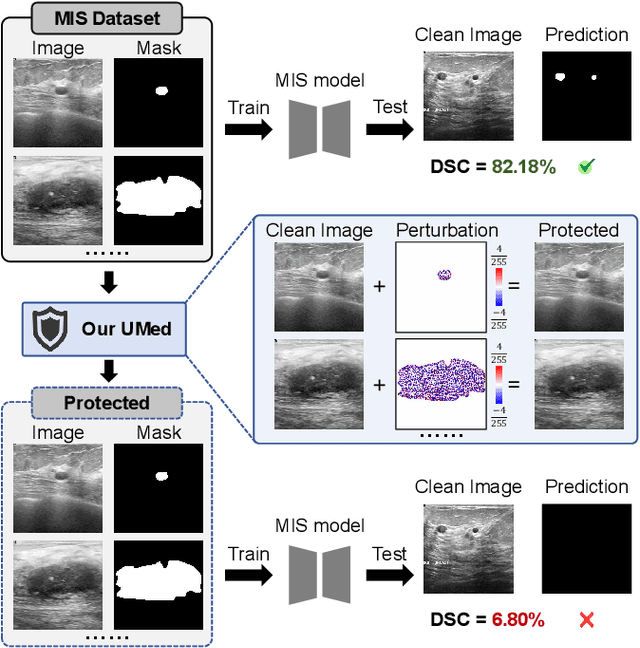
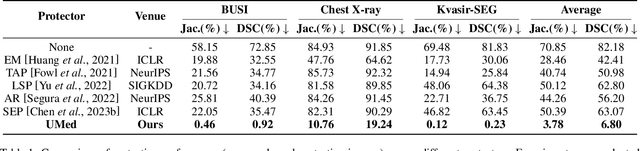
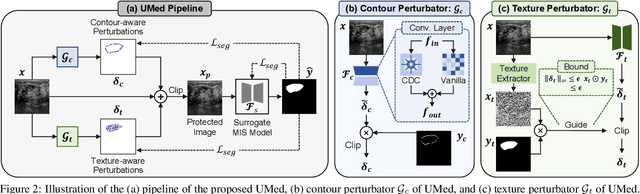
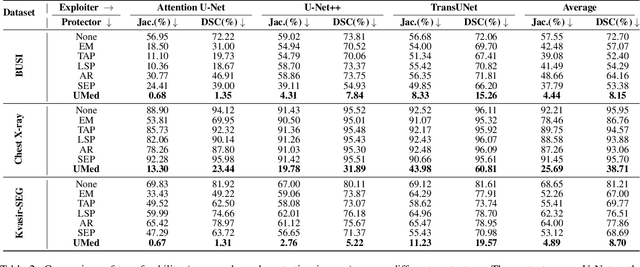
The widespread availability of publicly accessible medical images has significantly propelled advancements in various research and clinical fields. Nonetheless, concerns regarding unauthorized training of AI systems for commercial purposes and the duties of patient privacy protection have led numerous institutions to hesitate to share their images. This is particularly true for medical image segmentation (MIS) datasets, where the processes of collection and fine-grained annotation are time-intensive and laborious. Recently, Unlearnable Examples (UEs) methods have shown the potential to protect images by adding invisible shortcuts. These shortcuts can prevent unauthorized deep neural networks from generalizing. However, existing UEs are designed for natural image classification and fail to protect MIS datasets imperceptibly as their protective perturbations are less learnable than important prior knowledge in MIS, e.g., contour and texture features. To this end, we propose an Unlearnable Medical image generation method, termed UMed. UMed integrates the prior knowledge of MIS by injecting contour- and texture-aware perturbations to protect images. Given that our target is to only poison features critical to MIS, UMed requires only minimal perturbations within the ROI and its contour to achieve greater imperceptibility (average PSNR is 50.03) and protective performance (clean average DSC degrades from 82.18% to 6.80%).
Weak Supervision with Arbitrary Single Frame for Micro- and Macro-expression Spotting
Mar 21, 2024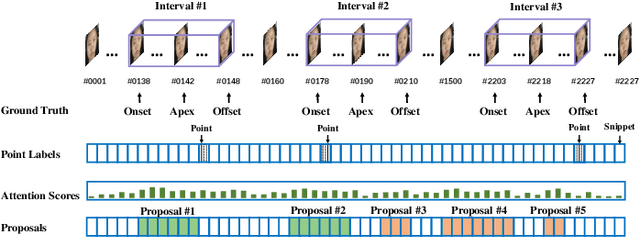
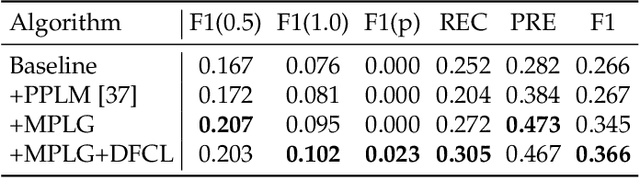
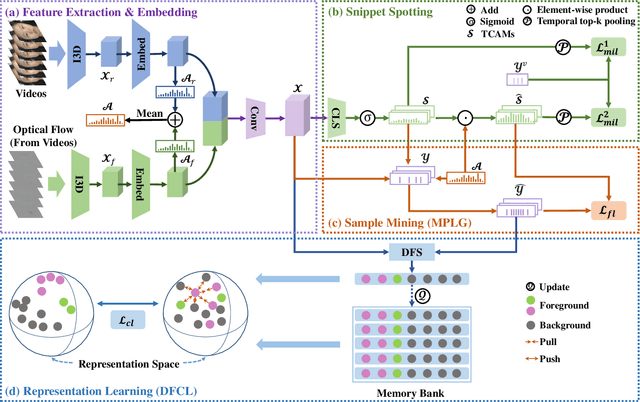
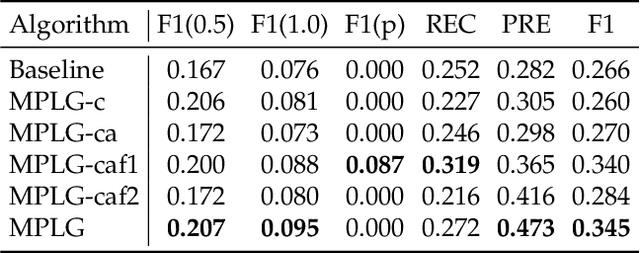
Frame-level micro- and macro-expression spotting methods require time-consuming frame-by-frame observation during annotation. Meanwhile, video-level spotting lacks sufficient information about the location and number of expressions during training, resulting in significantly inferior performance compared with fully-supervised spotting. To bridge this gap, we propose a point-level weakly-supervised expression spotting (PWES) framework, where each expression requires to be annotated with only one random frame (i.e., a point). To mitigate the issue of sparse label distribution, the prevailing solution is pseudo-label mining, which, however, introduces new problems: localizing contextual background snippets results in inaccurate boundaries and discarding foreground snippets leads to fragmentary predictions. Therefore, we design the strategies of multi-refined pseudo label generation (MPLG) and distribution-guided feature contrastive learning (DFCL) to address these problems. Specifically, MPLG generates more reliable pseudo labels by merging class-specific probabilities, attention scores, fused features, and point-level labels. DFCL is utilized to enhance feature similarity for the same categories and feature variability for different categories while capturing global representations across the entire datasets. Extensive experiments on the CAS(ME)^2, CAS(ME)^3, and SAMM-LV datasets demonstrate PWES achieves promising performance comparable to that of recent fully-supervised methods.
A Fourier Transform Framework for Domain Adaptation
Mar 21, 2024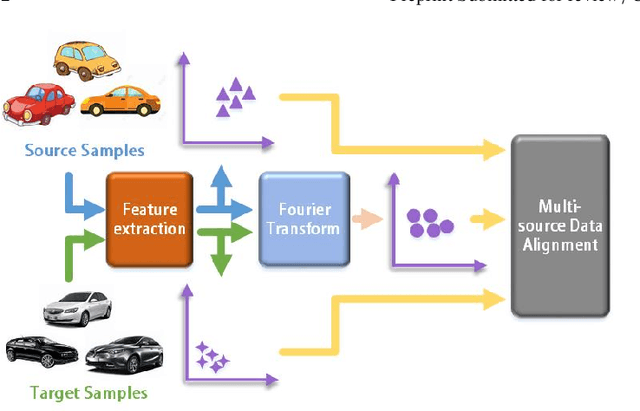
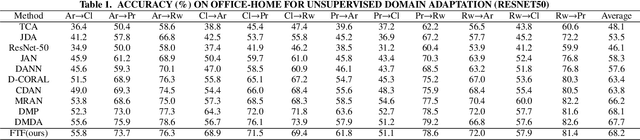
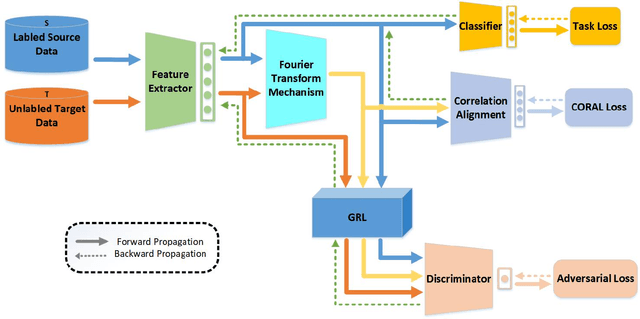

By using unsupervised domain adaptation (UDA), knowledge can be transferred from a label-rich source domain to a target domain that contains relevant information but lacks labels. Many existing UDA algorithms suffer from directly using raw images as input, resulting in models that overly focus on redundant information and exhibit poor generalization capability. To address this issue, we attempt to improve the performance of unsupervised domain adaptation by employing the Fourier method (FTF).Specifically, FTF is inspired by the amplitude of Fourier spectra, which primarily preserves low-level statistical information. In FTF, we effectively incorporate low-level information from the target domain into the source domain by fusing the amplitudes of both domains in the Fourier domain. Additionally, we observe that extracting features from batches of images can eliminate redundant information while retaining class-specific features relevant to the task. Building upon this observation, we apply the Fourier Transform at the data stream level for the first time. To further align multiple sources of data, we introduce the concept of correlation alignment. To evaluate the effectiveness of our FTF method, we conducted evaluations on four benchmark datasets for domain adaptation, including Office-31, Office-Home, ImageCLEF-DA, and Office-Caltech. Our results demonstrate superior performance.
Time-bound Contextual Bio-ID Generation for Minimalist Wearables
Mar 01, 2024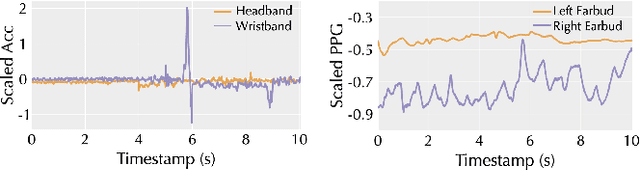
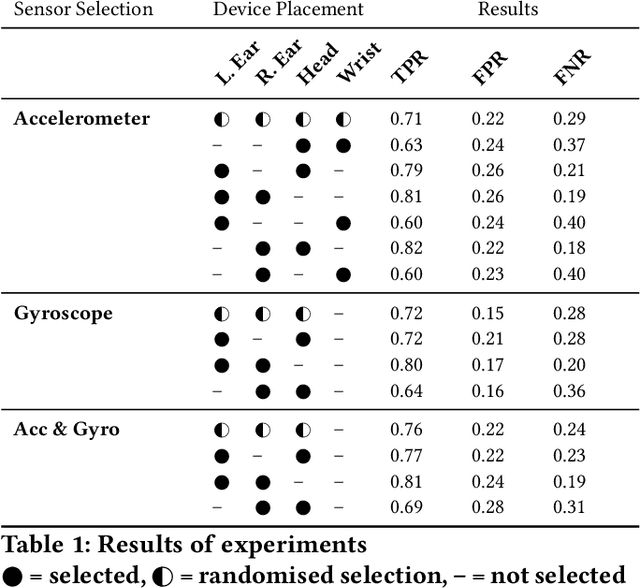
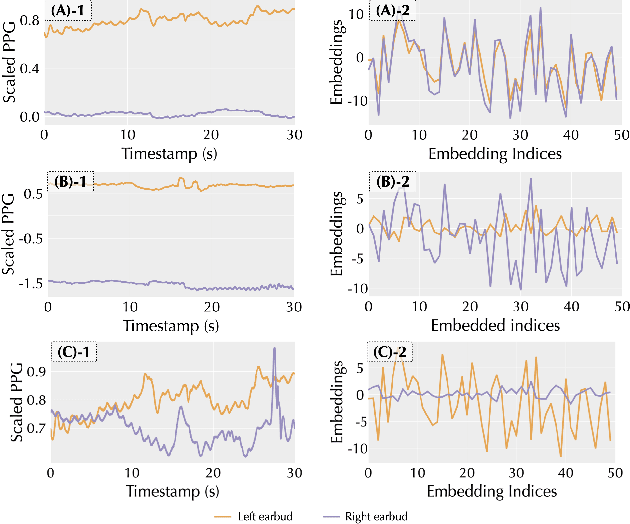
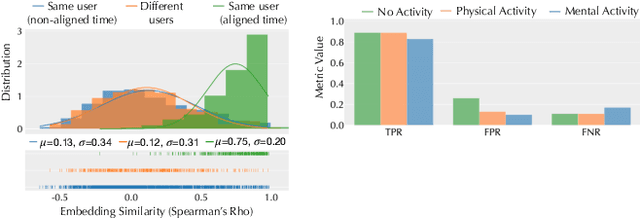
As wearable devices become increasingly miniaturized and powerful, a new opportunity arises for instant and dynamic device-to-device collaboration and human-to-device interaction. However, this progress presents a unique challenge: these minimalist wearables lack inherent mechanisms for real-time authentication, posing significant risks to data privacy and overall security. To address this, we introduce Proteus that realizes an innovative concept of time-bound contextual bio-IDs, which are generated from on-device sensor data and embedded into a common latent space. These bio-IDs act as a time-bound unique user identifier that can be used to identify the wearer in a certain context. Proteus enables dynamic and contextual device collaboration as well as robust human-to-device interaction. Our evaluations demonstrate the effectiveness of our method, particularly in the context of minimalist wearables.
A Convex Formulation of Frictional Contact for the Material Point Method and Rigid Bodies
Mar 20, 2024
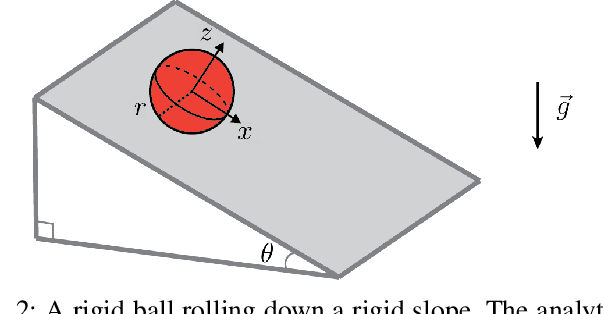
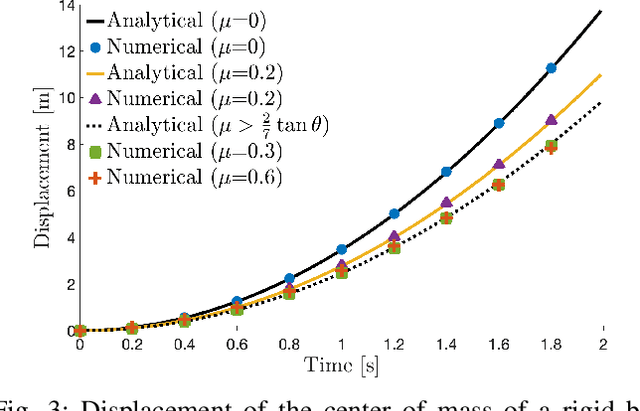

In this paper, we introduce a novel convex formulation that seamlessly integrates the Material Point Method (MPM) with articulated rigid body dynamics in frictional contact scenarios. We extend the linear corotational hyperelastic model into the realm of elastoplasticity and include an efficient return mapping algorithm. This approach is particularly effective for MPM simulations involving significant deformation and topology changes, while preserving the convexity of the optimization problem. Our method ensures global convergence, enabling the use of large simulation time steps without compromising robustness. We have validated our approach through rigorous testing and performance evaluations, highlighting its superior capabilities in managing complex simulations relevant to robotics. Compared to previous MPM based robotic simulators, our method significantly improves the stability of contact resolution -- a critical factor in robot manipulation tasks. We make our method available in the open-source robotics toolkit, Drake.
Look Before You Leap: Socially Acceptable High-Speed Ground Robot Navigation in Crowded Hallways
Mar 20, 2024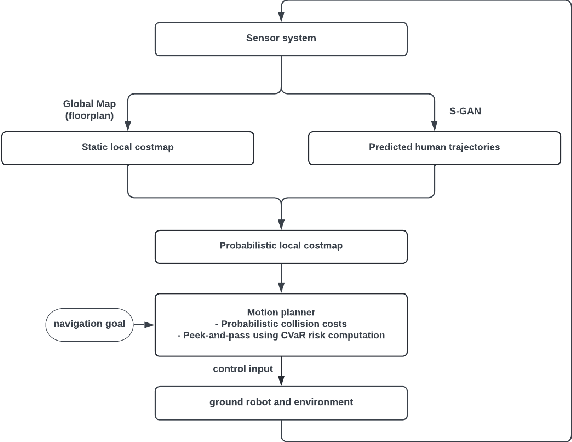
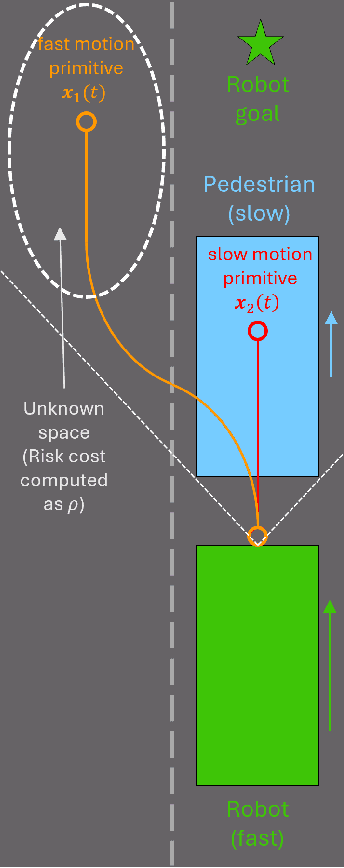
To operate safely and efficiently, autonomous warehouse/delivery robots must be able to accomplish tasks while navigating in dynamic environments and handling the large uncertainties associated with the motions/behaviors of other robots and/or humans. A key scenario in such environments is the hallway problem, where robots must operate in the same narrow corridor as human traffic going in one or both directions. Traditionally, robot planners have tended to focus on socially acceptable behavior in the hallway scenario at the expense of performance. This paper proposes a planner that aims to address the consequent "robot freezing problem" in hallways by allowing for "peek-and-pass" maneuvers. We then go on to demonstrate in simulation how this planner improves robot time to goal without violating social norms. Finally, we show initial hardware demonstrations of this planner in the real world.
The Power of Few: Accelerating and Enhancing Data Reweighting with Coreset Selection
Mar 20, 2024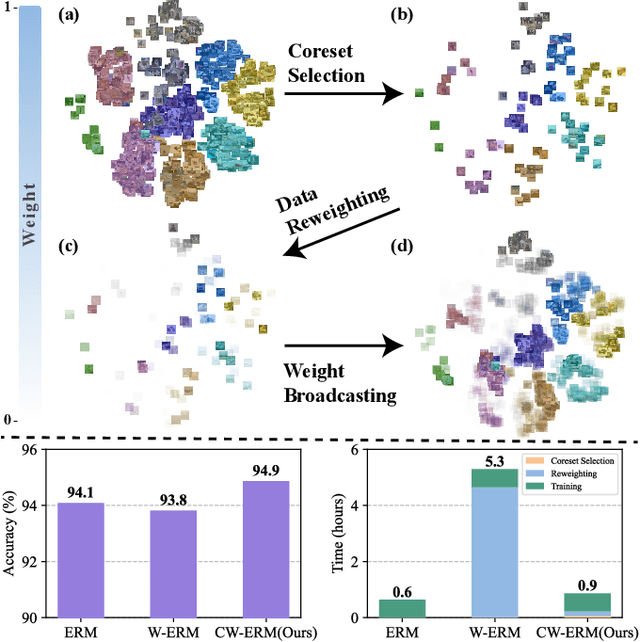
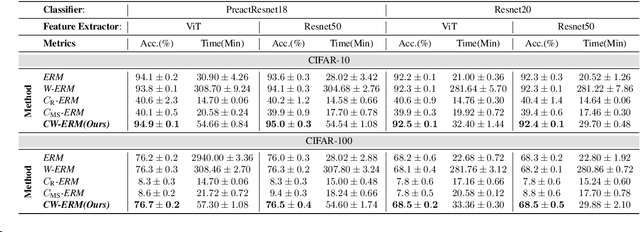
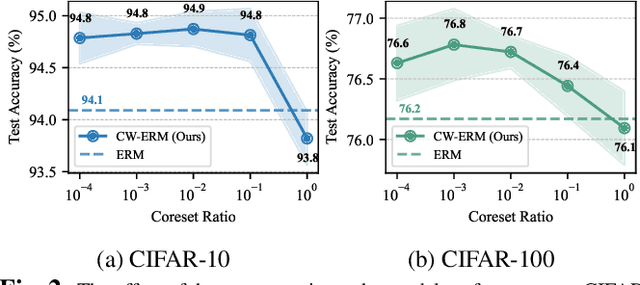
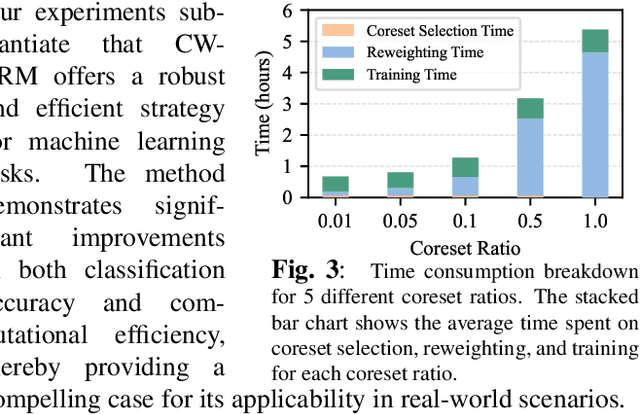
As machine learning tasks continue to evolve, the trend has been to gather larger datasets and train increasingly larger models. While this has led to advancements in accuracy, it has also escalated computational costs to unsustainable levels. Addressing this, our work aims to strike a delicate balance between computational efficiency and model accuracy, a persisting challenge in the field. We introduce a novel method that employs core subset selection for reweighting, effectively optimizing both computational time and model performance. By focusing on a strategically selected coreset, our approach offers a robust representation, as it efficiently minimizes the influence of outliers. The re-calibrated weights are then mapped back to and propagated across the entire dataset. Our experimental results substantiate the effectiveness of this approach, underscoring its potential as a scalable and precise solution for model training.
Pfeed: Generating near real-time personalized feeds using precomputed embedding similarities
Mar 06, 2024In personalized recommender systems, embeddings are often used to encode customer actions and items, and retrieval is then performed in the embedding space using approximate nearest neighbor search. However, this approach can lead to two challenges: 1) user embeddings can restrict the diversity of interests captured and 2) the need to keep them up-to-date requires an expensive, real-time infrastructure. In this paper, we propose a method that overcomes these challenges in a practical, industrial setting. The method dynamically updates customer profiles and composes a feed every two minutes, employing precomputed embeddings and their respective similarities. We tested and deployed this method to personalise promotional items at Bol, one of the largest e-commerce platforms of the Netherlands and Belgium. The method enhanced customer engagement and experience, leading to a significant 4.9% uplift in conversions.