 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Self-Supervised Learning with Lie Symmetries for Partial Differential Equations
Jul 11, 2023
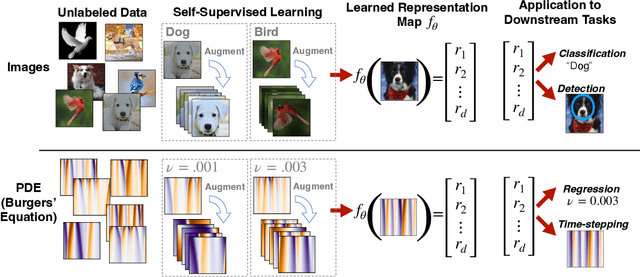
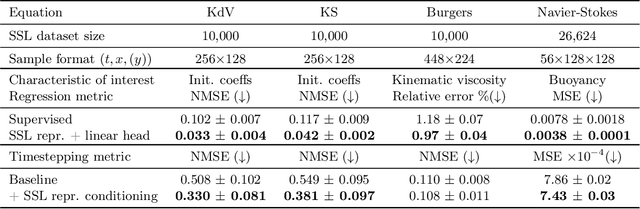
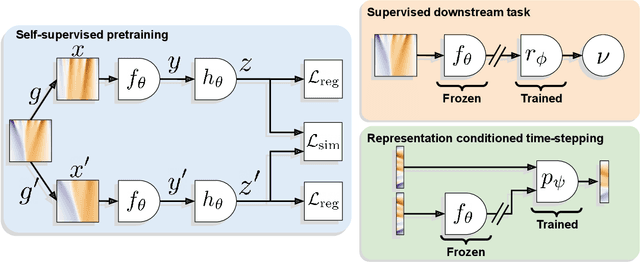

Machine learning for differential equations paves the way for computationally efficient alternatives to numerical solvers, with potentially broad impacts in science and engineering. Though current algorithms typically require simulated training data tailored to a given setting, one may instead wish to learn useful information from heterogeneous sources, or from real dynamical systems observations that are messy or incomplete. In this work, we learn general-purpose representations of PDEs from heterogeneous data by implementing joint embedding methods for self-supervised learning (SSL), a framework for unsupervised representation learning that has had notable success in computer vision. Our representation outperforms baseline approaches to invariant tasks, such as regressing the coefficients of a PDE, while also improving the time-stepping performance of neural solvers. We hope that our proposed methodology will prove useful in the eventual development of general-purpose foundation models for PDEs.
Real-time Safety Assessment of Dynamic Systems in Non-stationary Environments: A Review of Methods and Techniques
Apr 25, 2023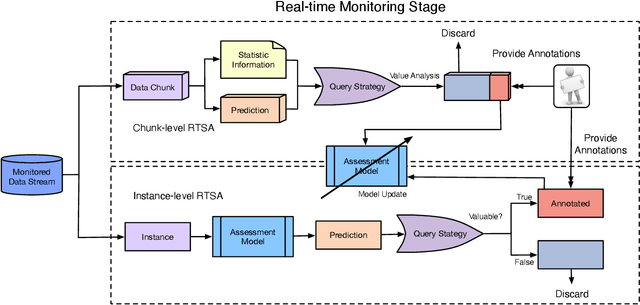
Real-time safety assessment (RTSA) of dynamic systems is a critical task that has significant implications for various fields such as industrial and transportation applications, especially in non-stationary environments. However, the absence of a comprehensive review of real-time safety assessment methods in non-stationary environments impedes the progress and refinement of related methods. In this paper, a review of methods and techniques for RTSA tasks in non-stationary environments is provided. Specifically, the background and significance of RTSA approaches in non-stationary environments are firstly highlighted. We then present a problem description that covers the definition, classification, and main challenges. We review recent developments in related technologies such as online active learning, online semi-supervised learning, online transfer learning, and online anomaly detection. Finally, we discuss future outlooks and potential directions for further research. Our review aims to provide a comprehensive and up-to-date overview of real-time safety assessment methods in non-stationary environments, which can serve as a valuable resource for researchers and practitioners in this field.
Knowledge-infused Deep Learning Enables Interpretable Landslide Forecasting
Jul 18, 2023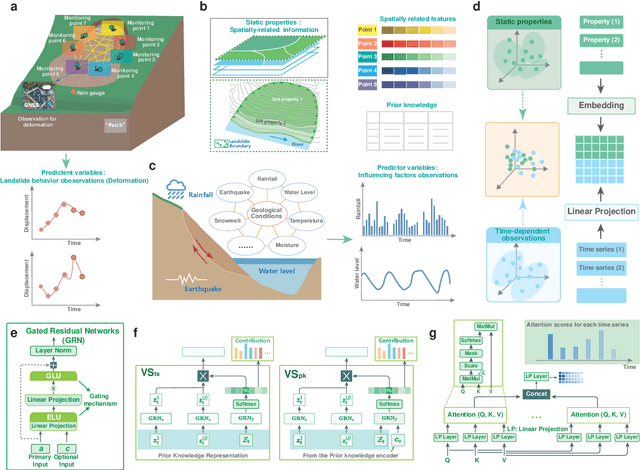
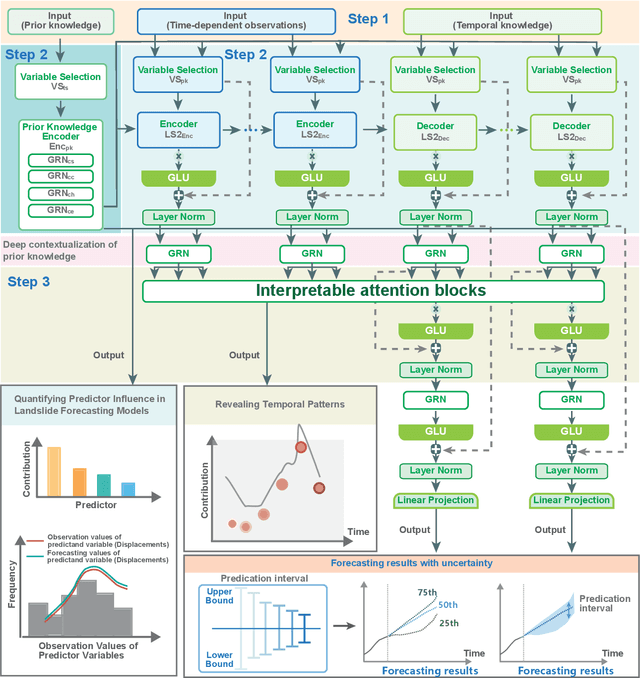
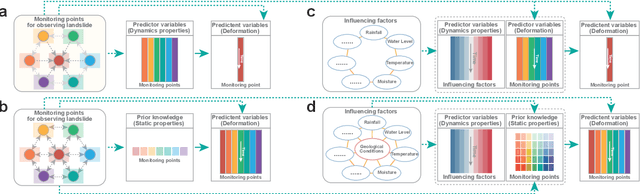
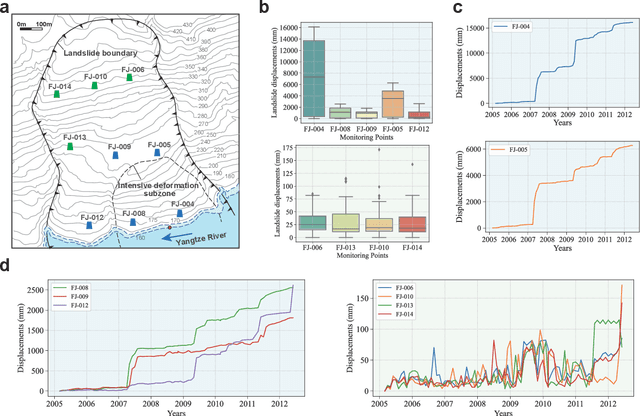
Forecasting how landslides will evolve over time or whether they will fail is a challenging task due to a variety of factors, both internal and external. Despite their considerable potential to address these challenges, deep learning techniques lack interpretability, undermining the credibility of the forecasts they produce. The recent development of transformer-based deep learning offers untapped possibilities for forecasting landslides with unprecedented interpretability and nonlinear feature learning capabilities. Here, we present a deep learning pipeline that is capable of predicting landslide behavior holistically, which employs a transformer-based network called LFIT to learn complex nonlinear relationships from prior knowledge and multiple source data, identifying the most relevant variables, and demonstrating a comprehensive understanding of landslide evolution and temporal patterns. By integrating prior knowledge, we provide improvement in holistic landslide forecasting, enabling us to capture diverse responses to various influencing factors in different local landslide areas. Using deformation observations as proxies for measuring the kinetics of landslides, we validate our approach by training models to forecast reservoir landslides in the Three Gorges Reservoir and creeping landslides on the Tibetan Plateau. When prior knowledge is incorporated, we show that interpretable landslide forecasting effectively identifies influential factors across various landslides. It further elucidates how local areas respond to these factors, making landslide behavior and trends more interpretable and predictable. The findings from this study will contribute to understanding landslide behavior in a new way and make the proposed approach applicable to other complex disasters influenced by internal and external factors in the future.
UniTabE: Pretraining a Unified Tabular Encoder for Heterogeneous Tabular Data
Jul 18, 2023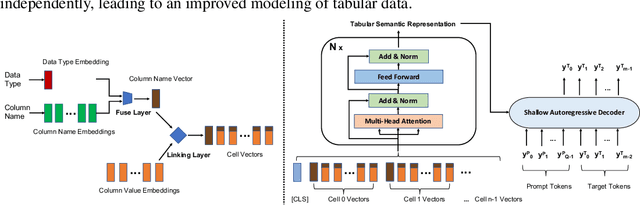
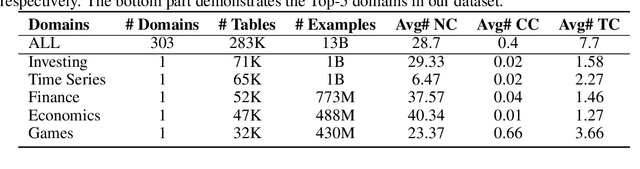
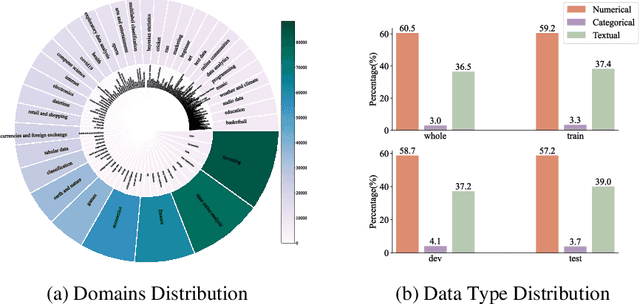

Recent advancements in Natural Language Processing (NLP) have witnessed the groundbreaking impact of pretrained models, yielding impressive outcomes across various tasks. This study seeks to extend the power of pretraining methodologies to tabular data, a domain traditionally overlooked, yet inherently challenging due to the plethora of table schemas intrinsic to different tasks. The primary research questions underpinning this work revolve around the adaptation to heterogeneous table structures, the establishment of a universal pretraining protocol for tabular data, the generalizability and transferability of learned knowledge across tasks, the adaptation to diverse downstream applications, and the incorporation of incremental columns over time. In response to these challenges, we introduce UniTabE, a pioneering method designed to process tables in a uniform manner, devoid of constraints imposed by specific table structures. UniTabE's core concept relies on representing each basic table element with a module, termed TabUnit. This is subsequently followed by a Transformer encoder to refine the representation. Moreover, our model is designed to facilitate pretraining and finetuning through the utilization of free-form prompts. In order to implement the pretraining phase, we curated an expansive tabular dataset comprising approximately 13 billion samples, meticulously gathered from the Kaggle platform. Rigorous experimental testing and analyses were performed under a myriad of scenarios to validate the effectiveness of our methodology. The experimental results demonstrate UniTabE's superior performance against several baseline models across a multitude of benchmark datasets. This, therefore, underscores UniTabE's potential to significantly enhance the semantic representation of tabular data, thereby marking a significant stride in the field of tabular data analysis.
A comparison of short-term probabilistic forecasts for the incidence of COVID-19 using mechanistic and statistical time series models
May 01, 2023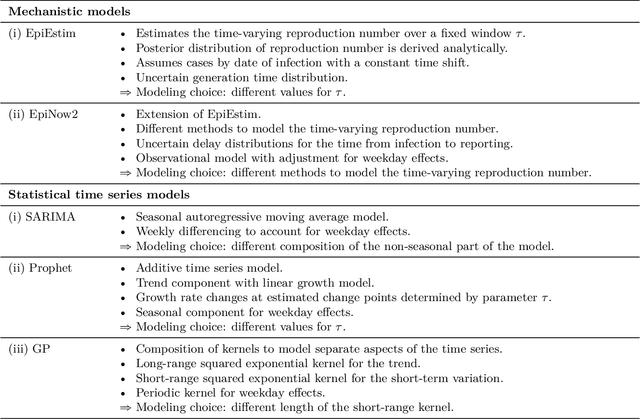
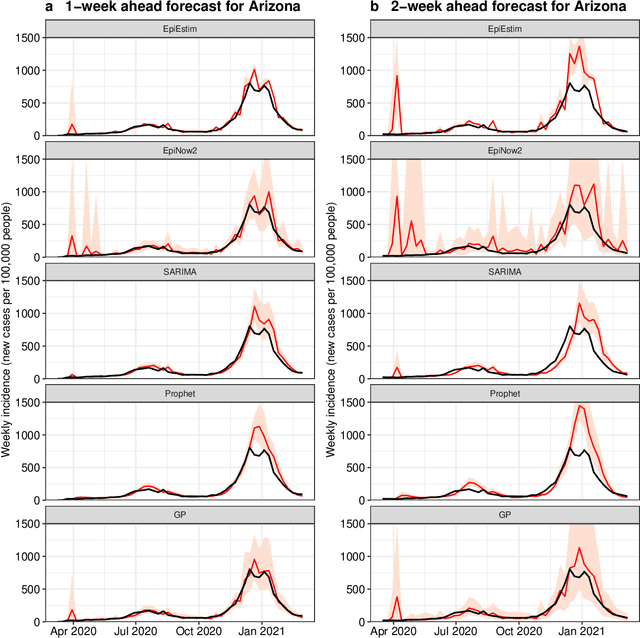

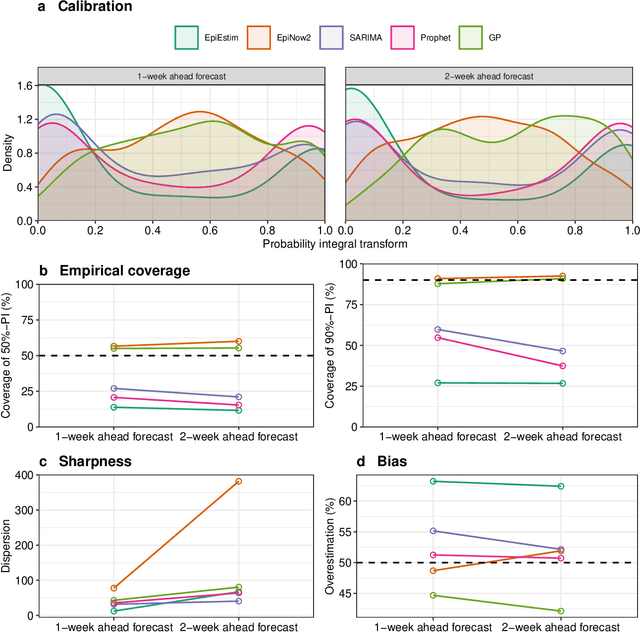
Short-term forecasts of infectious disease spread are a critical component in risk evaluation and public health decision making. While different models for short-term forecasting have been developed, open questions about their relative performance remain. Here, we compare short-term probabilistic forecasts of popular mechanistic models based on the renewal equation with forecasts of statistical time series models. Our empirical comparison is based on data of the daily incidence of COVID-19 across six large US states over the first pandemic year. We find that, on average, probabilistic forecasts from statistical time series models are overall at least as accurate as forecasts from mechanistic models. Moreover, statistical time series models better capture volatility. Our findings suggest that domain knowledge, which is integrated into mechanistic models by making assumptions about disease dynamics, does not improve short-term forecasts of disease incidence. We note, however, that forecasting is often only one of many objectives and thus mechanistic models remain important, for example, to model the impact of vaccines or the emergence of new variants.
Incorporating Structured Sentences with Time-enhanced BERT for Fully-inductive Temporal Relation Prediction
Apr 10, 2023
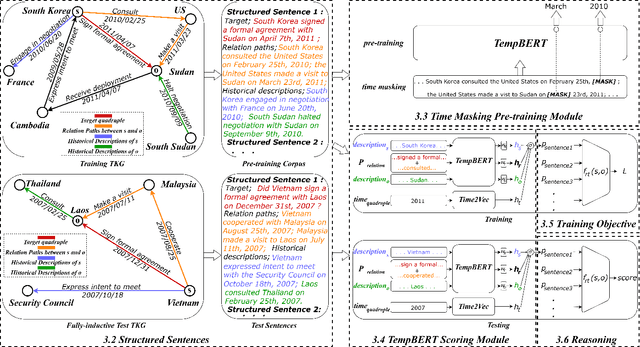
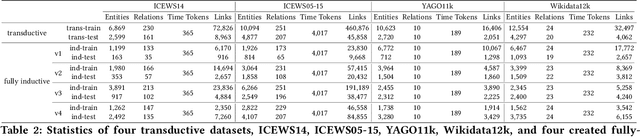
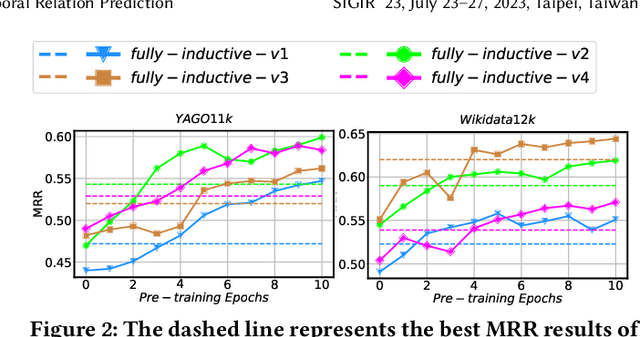
Temporal relation prediction in incomplete temporal knowledge graphs (TKGs) is a popular temporal knowledge graph completion (TKGC) problem in both transductive and inductive settings. Traditional embedding-based TKGC models (TKGE) rely on structured connections and can only handle a fixed set of entities, i.e., the transductive setting. In the inductive setting where test TKGs contain emerging entities, the latest methods are based on symbolic rules or pre-trained language models (PLMs). However, they suffer from being inflexible and not time-specific, respectively. In this work, we extend the fully-inductive setting, where entities in the training and test sets are totally disjoint, into TKGs and take a further step towards a more flexible and time-sensitive temporal relation prediction approach SST-BERT, incorporating Structured Sentences with Time-enhanced BERT. Our model can obtain the entity history and implicitly learn rules in the semantic space by encoding structured sentences, solving the problem of inflexibility. We propose to use a time masking MLM task to pre-train BERT in a corpus rich in temporal tokens specially generated for TKGs, enhancing the time sensitivity of SST-BERT. To compute the probability of occurrence of a target quadruple, we aggregate all its structured sentences from both temporal and semantic perspectives into a score. Experiments on the transductive datasets and newly generated fully-inductive benchmarks show that SST-BERT successfully improves over state-of-the-art baselines.
Hybrid Variational Autoencoder for Time Series Forecasting
Mar 13, 2023
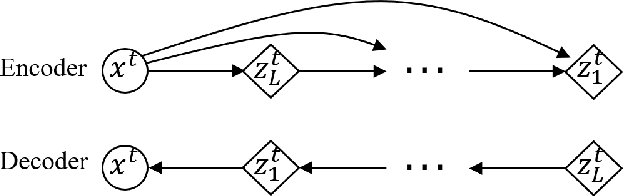
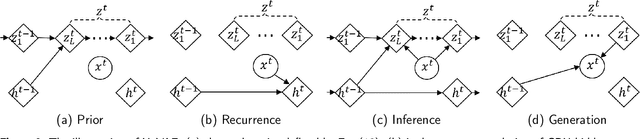
Variational autoencoders (VAE) are powerful generative models that learn the latent representations of input data as random variables. Recent studies show that VAE can flexibly learn the complex temporal dynamics of time series and achieve more promising forecasting results than deterministic models. However, a major limitation of existing works is that they fail to jointly learn the local patterns (e.g., seasonality and trend) and temporal dynamics of time series for forecasting. Accordingly, we propose a novel hybrid variational autoencoder (HyVAE) to integrate the learning of local patterns and temporal dynamics by variational inference for time series forecasting. Experimental results on four real-world datasets show that the proposed HyVAE achieves better forecasting results than various counterpart methods, as well as two HyVAE variants that only learn the local patterns or temporal dynamics of time series, respectively.
Classifying Crime Types using Judgment Documents from Social Media
Jun 29, 2023
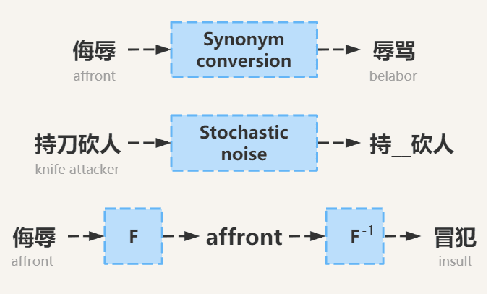
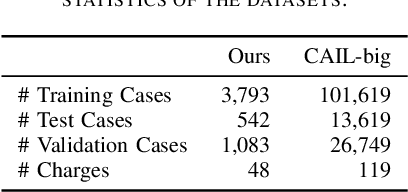
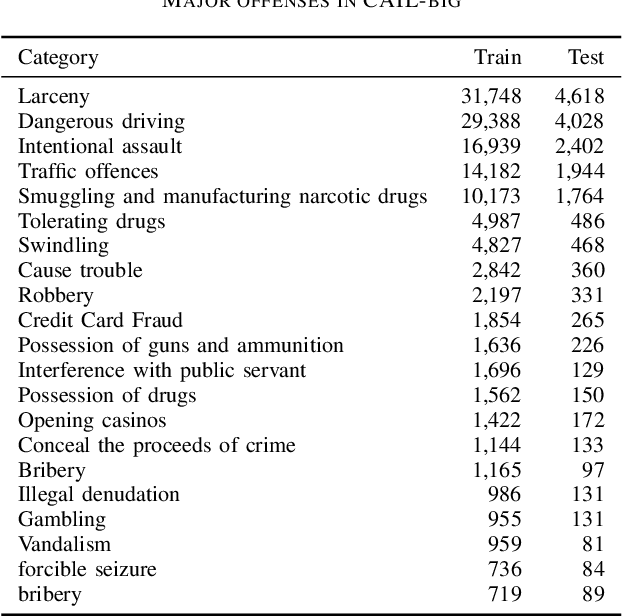
The task of determining crime types based on criminal behavior facts has become a very important and meaningful task in social science. But the problem facing the field now is that the data samples themselves are unevenly distributed, due to the nature of the crime itself. At the same time, data sets in the judicial field are less publicly available, and it is not practical to produce large data sets for direct training. This article proposes a new training model to solve this problem through NLP processing methods. We first propose a Crime Fact Data Preprocessing Module (CFDPM), which can balance the defects of uneven data set distribution by generating new samples. Then we use a large open source dataset (CAIL-big) as our pretraining dataset and a small dataset collected by ourselves for Fine-tuning, giving it good generalization ability to unfamiliar small datasets. At the same time, we use the improved Bert model with dynamic masking to improve the model. Experiments show that the proposed method achieves state-of-the-art results on the present dataset. At the same time, the effectiveness of module CFDPM is proved by experiments. This article provides a valuable methodology contribution for classifying social science texts such as criminal behaviors. Extensive experiments on public benchmarks show that the proposed method achieves new state-of-the-art results.
Airway Label Prediction in Video Bronchoscopy: Capturing Temporal Dependencies Utilizing Anatomical Knowledge
Jul 17, 2023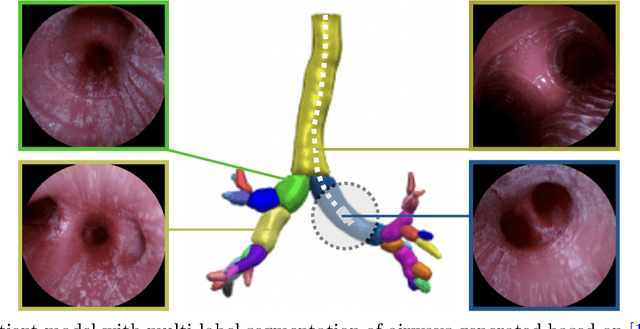
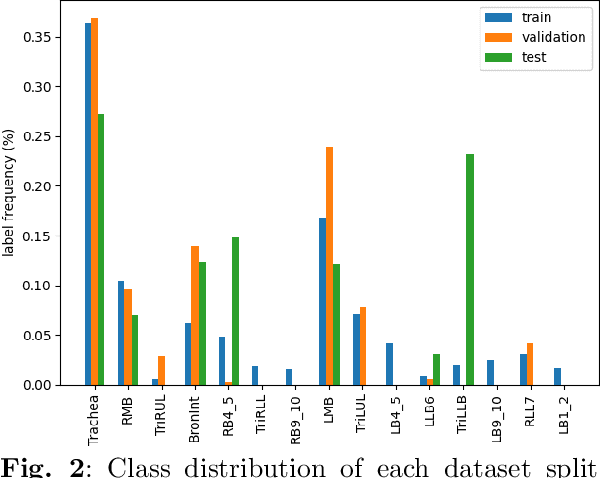
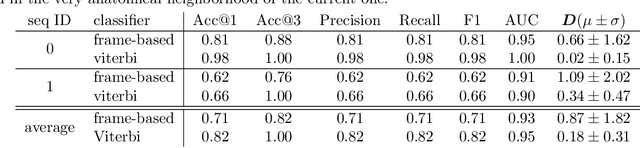
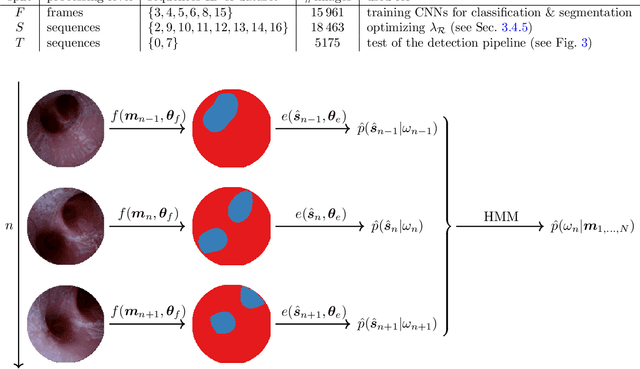
Purpose: Navigation guidance is a key requirement for a multitude of lung interventions using video bronchoscopy. State-of-the-art solutions focus on lung biopsies using electromagnetic tracking and intraoperative image registration w.r.t. preoperative CT scans for guidance. The requirement of patient-specific CT scans hampers the utilisation of navigation guidance for other applications such as intensive care units. Methods: This paper addresses navigation guidance solely incorporating bronchosopy video data. In contrast to state-of-the-art approaches we entirely omit the use of electromagnetic tracking and patient-specific CT scans. Guidance is enabled by means of topological bronchoscope localization w.r.t. an interpatient airway model. Particularly, we take maximally advantage of anatomical constraints of airway trees being sequentially traversed. This is realized by incorporating sequences of CNN-based airway likelihoods into a Hidden Markov Model. Results: Our approach is evaluated based on multiple experiments inside a lung phantom model. With the consideration of temporal context and use of anatomical knowledge for regularization, we are able to improve the accuracy up to to 0.98 compared to 0.81 (weighted F1: 0.98 compared to 0.81) for a classification based on individual frames. Conclusion: We combine CNN-based single image classification of airway segments with anatomical constraints and temporal HMM-based inference for the first time. Our approach renders vision-only guidance for bronchoscopy interventions in the absence of electromagnetic tracking and patient-specific CT scans possible.
Divide&Classify: Fine-Grained Classification for City-Wide Visual Place Recognition
Jul 17, 2023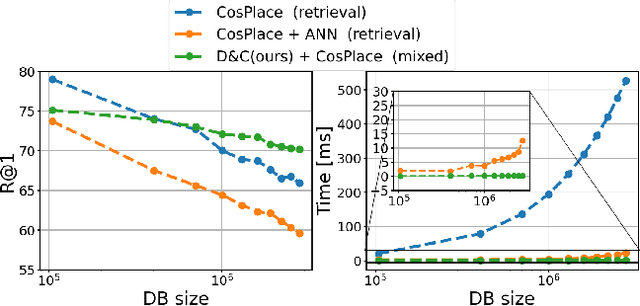
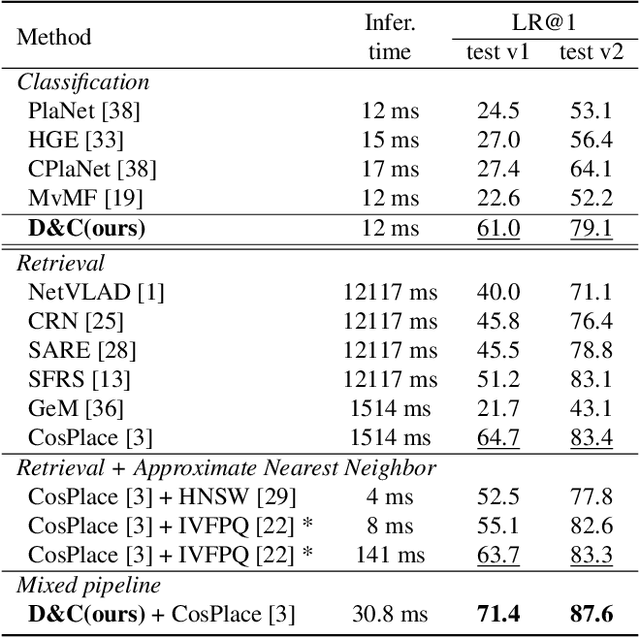
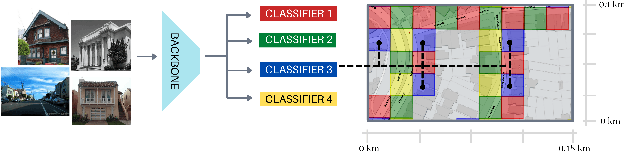
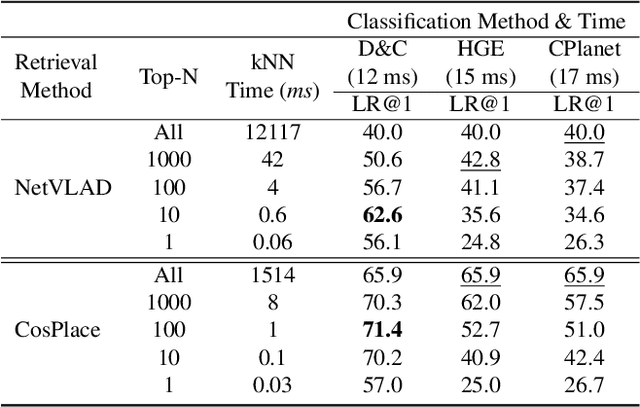
Visual Place recognition is commonly addressed as an image retrieval problem. However, retrieval methods are impractical to scale to large datasets, densely sampled from city-wide maps, since their dimension impact negatively on the inference time. Using approximate nearest neighbour search for retrieval helps to mitigate this issue, at the cost of a performance drop. In this paper we investigate whether we can effectively approach this task as a classification problem, thus bypassing the need for a similarity search. We find that existing classification methods for coarse, planet-wide localization are not suitable for the fine-grained and city-wide setting. This is largely due to how the dataset is split into classes, because these methods are designed to handle a sparse distribution of photos and as such do not consider the visual aliasing problem across neighbouring classes that naturally arises in dense scenarios. Thus, we propose a partitioning scheme that enables a fast and accurate inference, preserving a simple learning procedure, and a novel inference pipeline based on an ensemble of novel classifiers that uses the prototypes learned via an angular margin loss. Our method, Divide&Classify (D&C), enjoys the fast inference of classification solutions and an accuracy competitive with retrieval methods on the fine-grained, city-wide setting. Moreover, we show that D&C can be paired with existing retrieval pipelines to speed up computations by over 20 times while increasing their recall, leading to new state-of-the-art results.