 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Leveraging Denoised Abstract Meaning Representation for Grammatical Error Correction
Jul 05, 2023
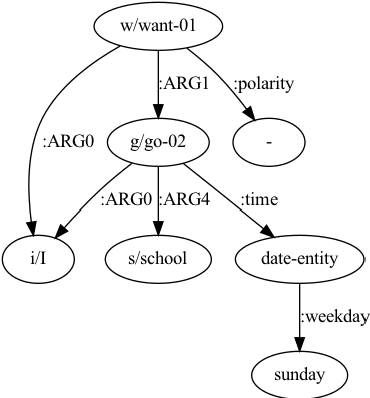
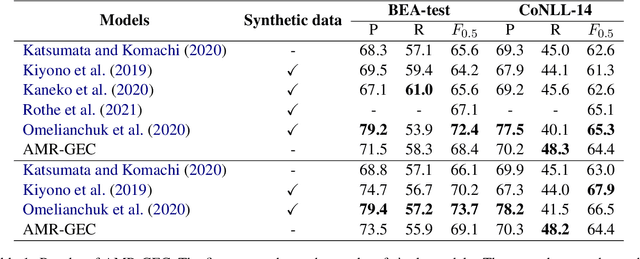
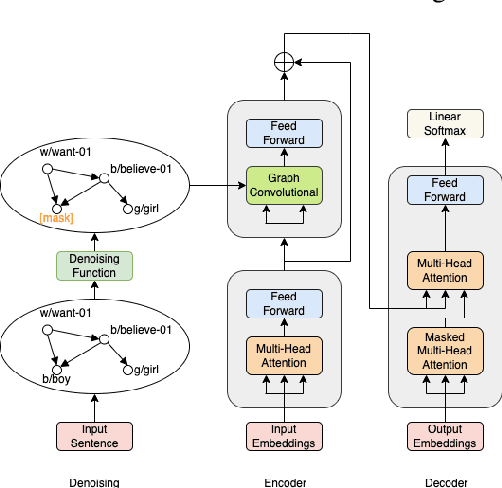
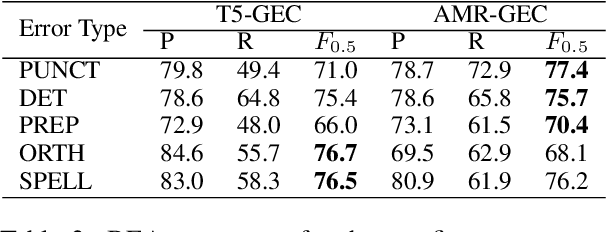
Grammatical Error Correction (GEC) is the task of correcting errorful sentences into grammatically correct, semantically consistent, and coherent sentences. Popular GEC models either use large-scale synthetic corpora or use a large number of human-designed rules. The former is costly to train, while the latter requires quite a lot of human expertise. In recent years, AMR, a semantic representation framework, has been widely used by many natural language tasks due to its completeness and flexibility. A non-negligible concern is that AMRs of grammatically incorrect sentences may not be exactly reliable. In this paper, we propose the AMR-GEC, a seq-to-seq model that incorporates denoised AMR as additional knowledge. Specifically, We design a semantic aggregated GEC model and explore denoising methods to get AMRs more reliable. Experiments on the BEA-2019 shared task and the CoNLL-2014 shared task have shown that AMR-GEC performs comparably to a set of strong baselines with a large number of synthetic data. Compared with the T5 model with synthetic data, AMR-GEC can reduce the training time by 32\% while inference time is comparable. To the best of our knowledge, we are the first to incorporate AMR for grammatical error correction.
SAR ATR under Limited Training Data Via MobileNetV3
Jun 27, 2023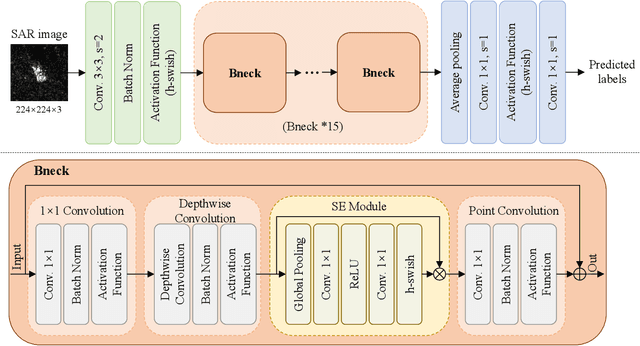
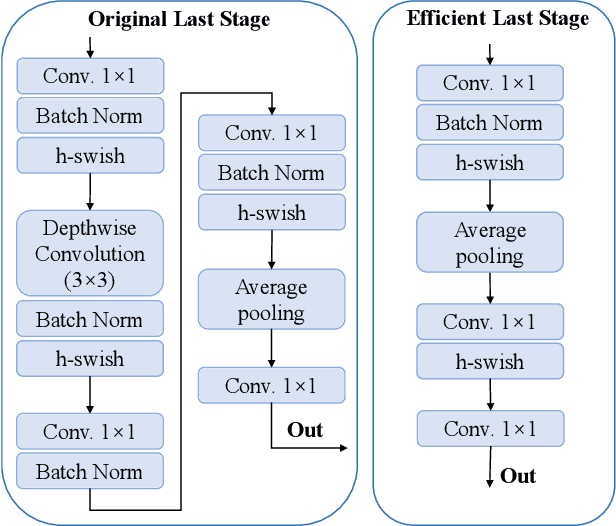

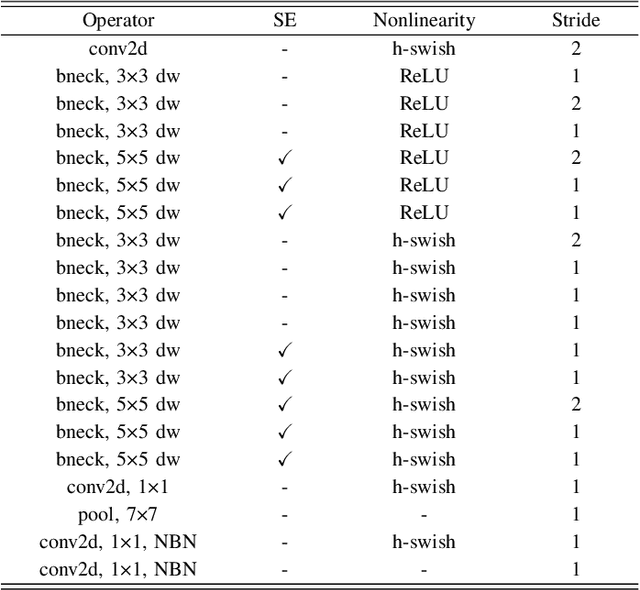
In recent years, deep learning has been widely used to solve the bottleneck problem of synthetic aperture radar (SAR) automatic target recognition (ATR). However, most current methods rely heavily on a large number of training samples and have many parameters which lead to failure under limited training samples. In practical applications, the SAR ATR method needs not only superior performance under limited training data but also real-time performance. Therefore, we try to use a lightweight network for SAR ATR under limited training samples, which has fewer parameters, less computational effort, and shorter inference time than normal networks. At the same time, the lightweight network combines the advantages of existing lightweight networks and uses a combination of MnasNet and NetAdapt algorithms to find the optimal neural network architecture for a given problem. Through experiments and comparisons under the moving and stationary target acquisition and recognition (MSTAR) dataset, the lightweight network is validated to have excellent recognition performance for SAR ATR on limited training samples and be very computationally small, reflecting the great potential of this network structure for practical applications.
Localized Text-to-Image Generation for Free via Cross Attention Control
Jun 26, 2023
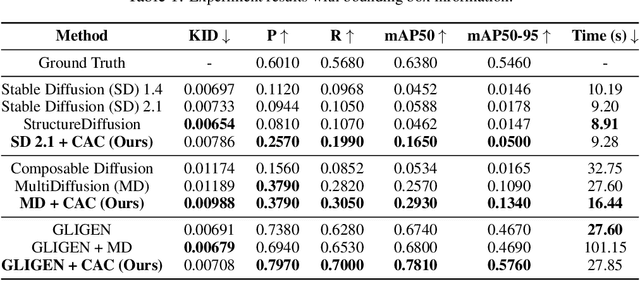
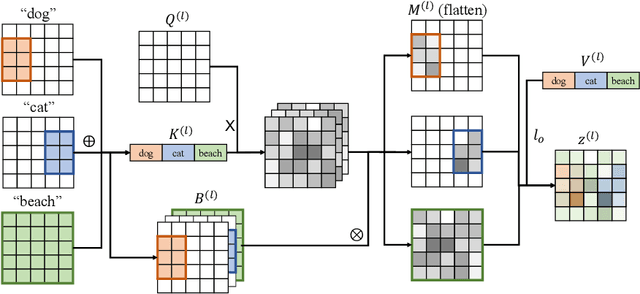

Despite the tremendous success in text-to-image generative models, localized text-to-image generation (that is, generating objects or features at specific locations in an image while maintaining a consistent overall generation) still requires either explicit training or substantial additional inference time. In this work, we show that localized generation can be achieved by simply controlling cross attention maps during inference. With no additional training, model architecture modification or inference time, our proposed cross attention control (CAC) provides new open-vocabulary localization abilities to standard text-to-image models. CAC also enhances models that are already trained for localized generation when deployed at inference time. Furthermore, to assess localized text-to-image generation performance automatically, we develop a standardized suite of evaluations using large pretrained recognition models. Our experiments show that CAC improves localized generation performance with various types of location information ranging from bounding boxes to semantic segmentation maps, and enhances the compositional capability of state-of-the-art text-to-image generative models.
ZJU ReLER Submission for EPIC-KITCHEN Challenge 2023: Semi-Supervised Video Object Segmentation
Jul 10, 2023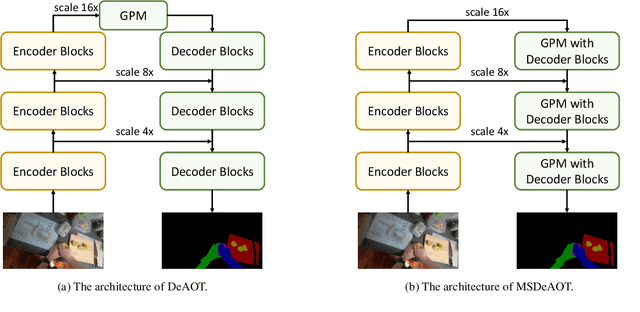


The Associating Objects with Transformers (AOT) framework has exhibited exceptional performance in a wide range of complex scenarios for video object segmentation. In this study, we introduce MSDeAOT, a variant of the AOT series that incorporates transformers at multiple feature scales. Leveraging the hierarchical Gated Propagation Module (GPM), MSDeAOT efficiently propagates object masks from previous frames to the current frame using a feature scale with a stride of 16. Additionally, we employ GPM in a more refined feature scale with a stride of 8, leading to improved accuracy in detecting and tracking small objects. Through the implementation of test-time augmentations and model ensemble techniques, we achieve the top-ranking position in the EPIC-KITCHEN VISOR Semi-supervised Video Object Segmentation Challenge.
Gradient Surgery for One-shot Unlearning on Generative Model
Jul 10, 2023

Recent regulation on right-to-be-forgotten emerges tons of interest in unlearning pre-trained machine learning models. While approximating a straightforward yet expensive approach of retrain-from-scratch, recent machine unlearning methods unlearn a sample by updating weights to remove its influence on the weight parameters. In this paper, we introduce a simple yet effective approach to remove a data influence on the deep generative model. Inspired by works in multi-task learning, we propose to manipulate gradients to regularize the interplay of influence among samples by projecting gradients onto the normal plane of the gradients to be retained. Our work is agnostic to statistics of the removal samples, outperforming existing baselines while providing theoretical analysis for the first time in unlearning a generative model.
Towards Safe Self-Distillation of Internet-Scale Text-to-Image Diffusion Models
Jul 12, 2023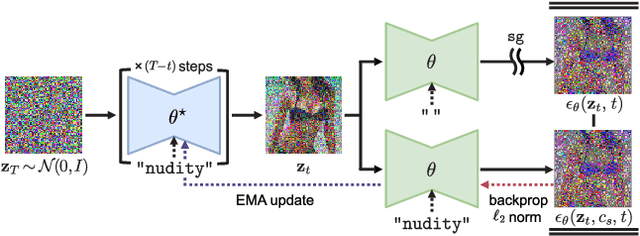
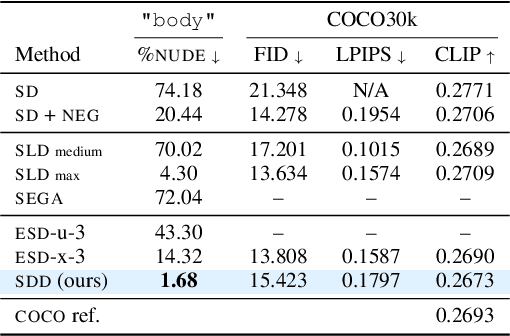
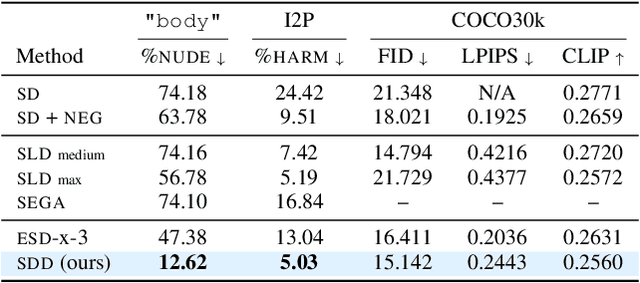

Large-scale image generation models, with impressive quality made possible by the vast amount of data available on the Internet, raise social concerns that these models may generate harmful or copyrighted content. The biases and harmfulness arise throughout the entire training process and are hard to completely remove, which have become significant hurdles to the safe deployment of these models. In this paper, we propose a method called SDD to prevent problematic content generation in text-to-image diffusion models. We self-distill the diffusion model to guide the noise estimate conditioned on the target removal concept to match the unconditional one. Compared to the previous methods, our method eliminates a much greater proportion of harmful content from the generated images without degrading the overall image quality. Furthermore, our method allows the removal of multiple concepts at once, whereas previous works are limited to removing a single concept at a time.
ClusterFusion: Real-time Relative Positioning and Dense Reconstruction for UAV Cluster
Apr 11, 2023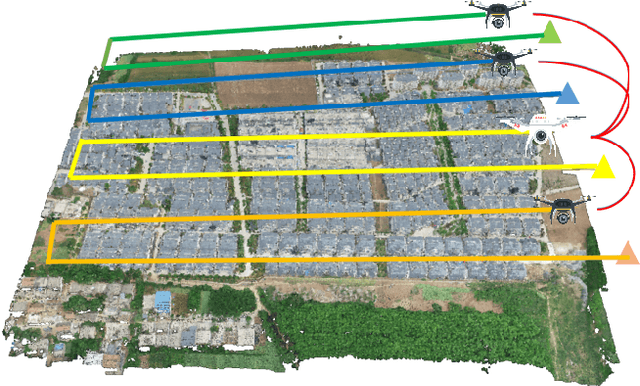

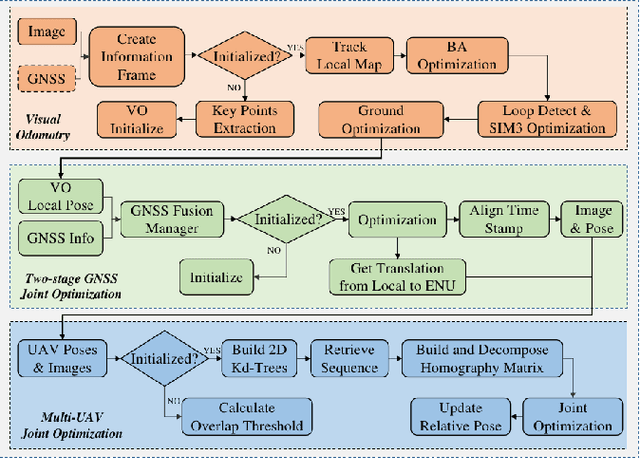
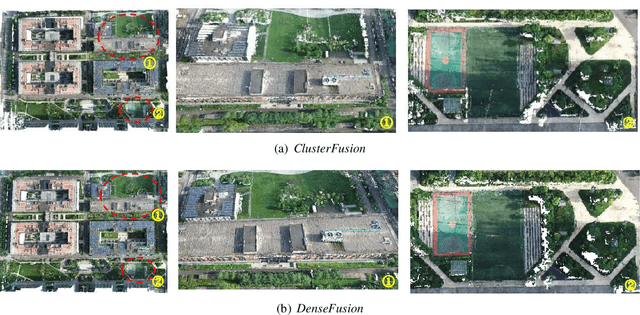
As robotics technology advances, dense point cloud maps are increasingly in demand. However, dense reconstruction using a single unmanned aerial vehicle (UAV) suffers from limitations in flight speed and battery power, resulting in slow reconstruction and low coverage. Cluster UAV systems offer greater flexibility and wider coverage for map building. Existing methods of cluster UAVs face challenges with accurate relative positioning, scale drift, and high-speed dense point cloud map generation. To address these issues, we propose a cluster framework for large-scale dense reconstruction and real-time collaborative localization. The front-end of the framework is an improved visual odometry which can effectively handle large-scale scenes. Collaborative localization between UAVs is enabled through a two-stage joint optimization algorithm and a relative pose optimization algorithm, effectively achieving accurate relative positioning of UAVs and mitigating scale drift. Estimated poses are used to achieve real-time dense reconstruction and fusion of point cloud maps. To evaluate the performance of our proposed method, we conduct qualitative and quantitative experiments on real-world data. The results demonstrate that our framework can effectively suppress scale drift and generate large-scale dense point cloud maps in real-time, with the reconstruction speed increasing as more UAVs are added to the system.
Time-series Anomaly Detection based on Difference Subspace between Signal Subspaces
Apr 05, 2023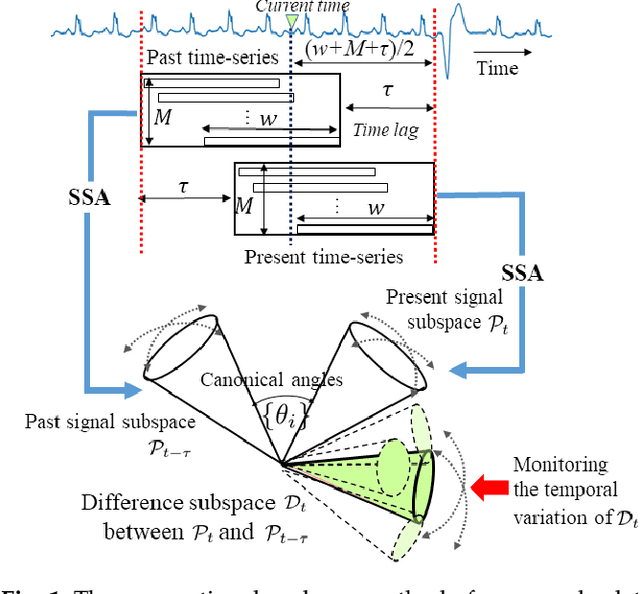
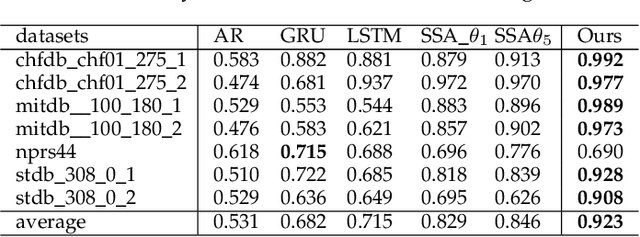
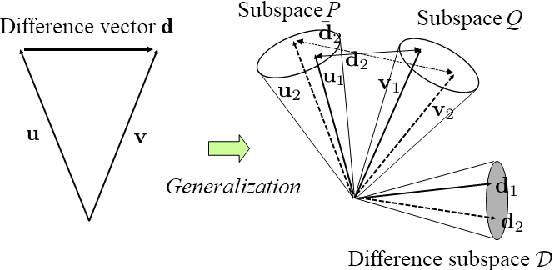
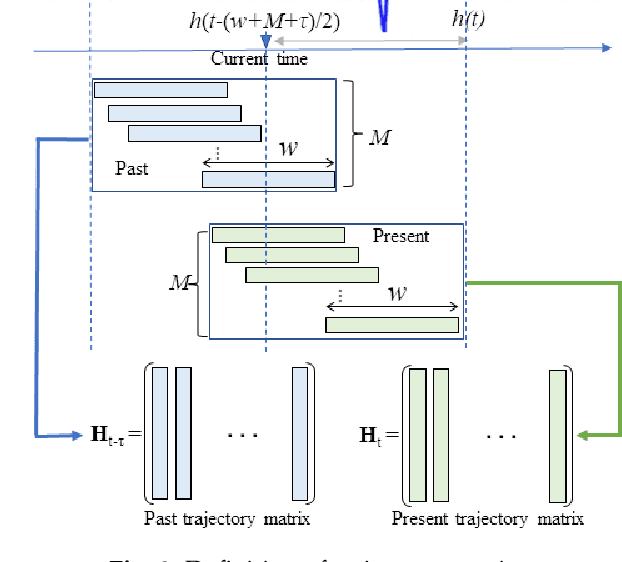
This paper proposes a new method for anomaly detection in time-series data by incorporating the concept of difference subspace into the singular spectrum analysis (SSA). The key idea is to monitor slight temporal variations of the difference subspace between two signal subspaces corresponding to the past and present time-series data, as anomaly score. It is a natural generalization of the conventional SSA-based method which measures the minimum angle between the two signal subspaces as the degree of changes. By replacing the minimum angle with the difference subspace, our method boosts the performance while using the SSA-based framework as it can capture the whole structural difference between the two subspaces in its magnitude and direction. We demonstrate our method's effectiveness through performance evaluations on public time-series datasets.
Test-time Detection and Repair of Adversarial Samples via Masked Autoencoder
Apr 02, 2023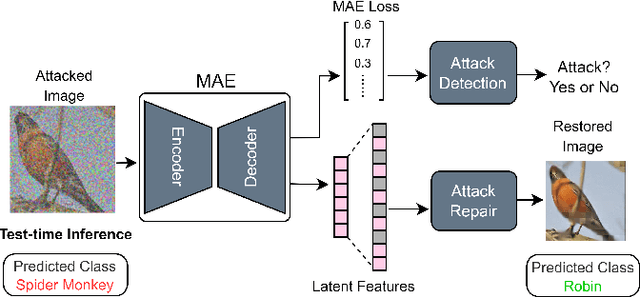
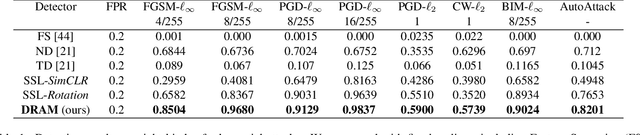
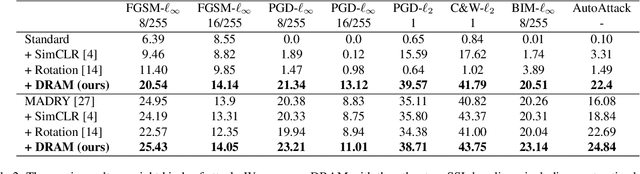
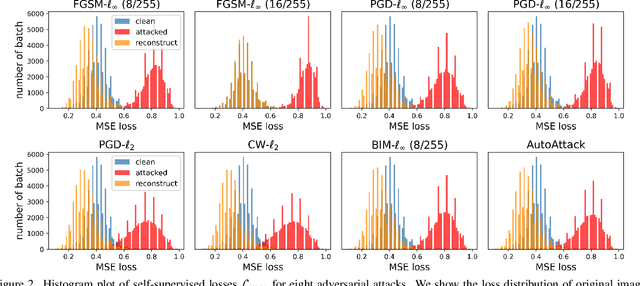
Training-time defenses, known as adversarial training, incur high training costs and do not generalize to unseen attacks. Test-time defenses solve these issues but most existing test-time defenses require adapting the model weights, therefore they do not work on frozen models and complicate model memory management. The only test-time defense that does not adapt model weights aims to adapt the input with self-supervision tasks. However, we empirically found these self-supervision tasks are not sensitive enough to detect adversarial attacks accurately. In this paper, we propose DRAM, a novel defense method to detect and repair adversarial samples at test time via Masked autoencoder (MAE). We demonstrate how to use MAE losses to build a Kolmogorov-Smirnov test to detect adversarial samples. Moreover, we use the MAE losses to calculate input reversal vectors that repair adversarial samples resulting from previously unseen attacks. Results on large-scale ImageNet dataset show that, compared to all detection baselines evaluated, DRAM achieves the best detection rate (82% on average) on all eight adversarial attacks evaluated. For attack repair, DRAM improves the robust accuracy by 6% ~ 41% for standard ResNet50 and 3% ~ 8% for robust ResNet50 compared with the baselines that use contrastive learning and rotation prediction.
Self-Supervised Learning with Lie Symmetries for Partial Differential Equations
Jul 11, 2023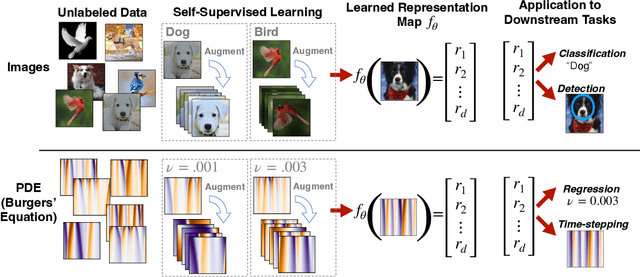
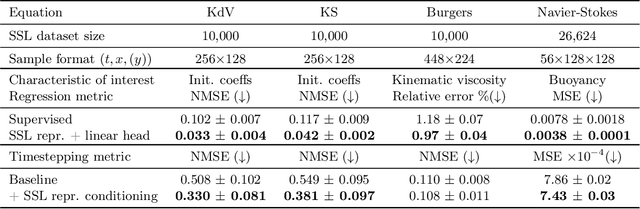
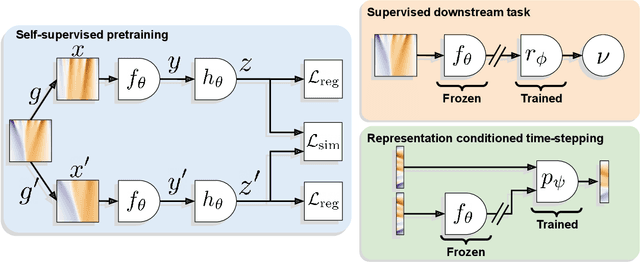

Machine learning for differential equations paves the way for computationally efficient alternatives to numerical solvers, with potentially broad impacts in science and engineering. Though current algorithms typically require simulated training data tailored to a given setting, one may instead wish to learn useful information from heterogeneous sources, or from real dynamical systems observations that are messy or incomplete. In this work, we learn general-purpose representations of PDEs from heterogeneous data by implementing joint embedding methods for self-supervised learning (SSL), a framework for unsupervised representation learning that has had notable success in computer vision. Our representation outperforms baseline approaches to invariant tasks, such as regressing the coefficients of a PDE, while also improving the time-stepping performance of neural solvers. We hope that our proposed methodology will prove useful in the eventual development of general-purpose foundation models for PDEs.