 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hybrid Control Policy for Artificial Pancreas via Ensemble Deep Reinforcement Learning
Jul 13, 2023
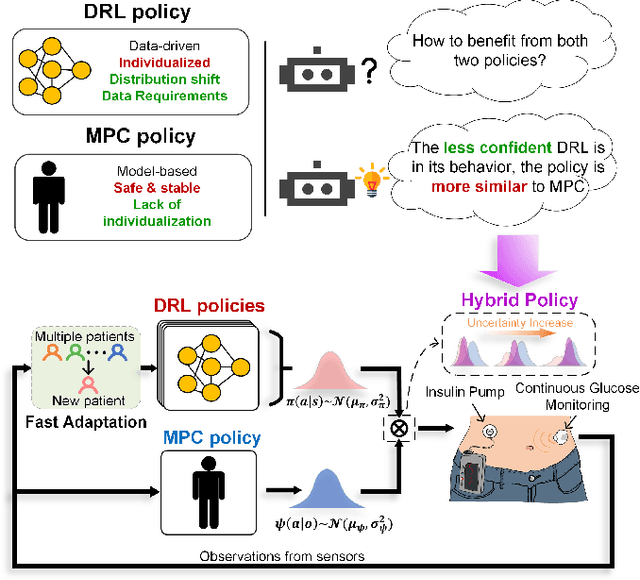
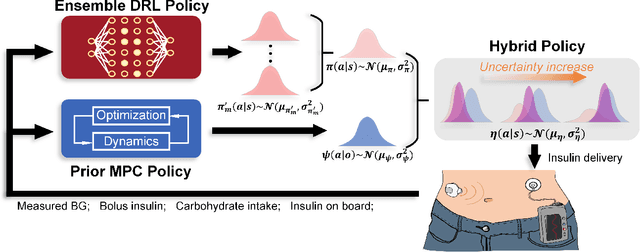
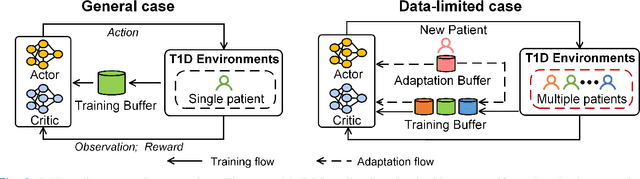
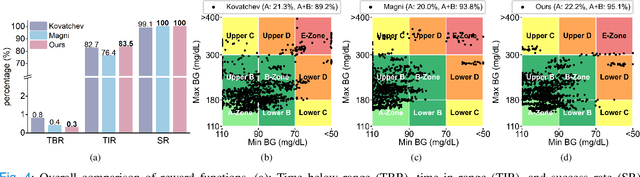
Objective: The artificial pancreas (AP) has shown promising potential in achieving closed-loop glucose control for individuals with type 1 diabetes mellitus (T1DM). However, designing an effective control policy for the AP remains challenging due to the complex physiological processes, delayed insulin response, and inaccurate glucose measurements. While model predictive control (MPC) offers safety and stability through the dynamic model and safety constraints, it lacks individualization and is adversely affected by unannounced meals. Conversely, deep reinforcement learning (DRL) provides personalized and adaptive strategies but faces challenges with distribution shifts and substantial data requirements. Methods: We propose a hybrid control policy for the artificial pancreas (HyCPAP) to address the above challenges. HyCPAP combines an MPC policy with an ensemble DRL policy, leveraging the strengths of both policies while compensating for their respective limitations. To facilitate faster deployment of AP systems in real-world settings, we further incorporate meta-learning techniques into HyCPAP, leveraging previous experience and patient-shared knowledge to enable fast adaptation to new patients with limited available data. Results: We conduct extensive experiments using the FDA-accepted UVA/Padova T1DM simulator across three scenarios. Our approaches achieve the highest percentage of time spent in the desired euglycemic range and the lowest occurrences of hypoglycemia. Conclusion: The results clearly demonstrate the superiority of our methods for closed-loop glucose management in individuals with T1DM. Significance: The study presents novel control policies for AP systems, affirming the great potential of proposed methods for efficient closed-loop glucose control.
Time-Spread Pilot-Based Channel Estimation for Backscatter Networks
May 26, 2023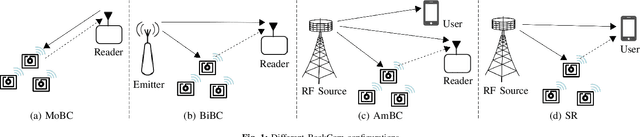
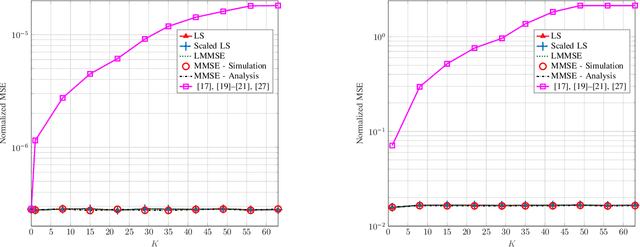
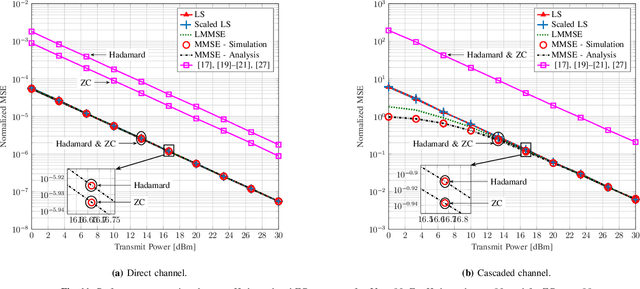
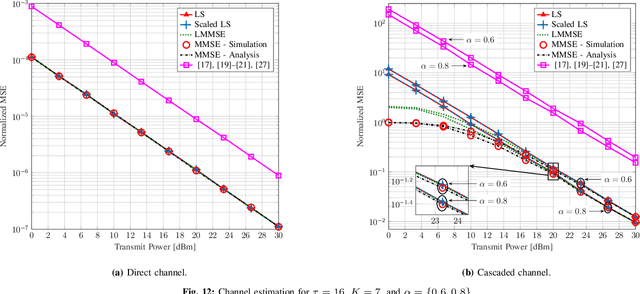
Current backscatter channel estimators employ an inefficient silent pilot transmission protocol, where tags alternate between silent and active states. To enhance performance, we propose a novel approach where tags remain active simultaneously throughout the entire training phase. This enables a one-shot estimation of both the direct and cascaded channels and accommodates various backscatter network configurations. We derive the conditions for optimal pilot sequences and also establish that the minimum variance unbiased (MVU) estimator attains the Cramer-Rao lower bound. Next, we propose new pilot designs to avoid pilot contamination. We then present several linear estimation methods, including least square (LS), scaled LS, and linear minimum mean square error (MMSE), to evaluate the performance of our proposed scheme. We also derive the analytical MMSE estimator using our proposed pilot designs. Furthermore, we adapt our method for cellular-based passive Internet-of-Things (IoT) networks with multiple tags and cellular users. Extensive numerical results and simulations are provided to validate the effectiveness of our approach. Notably, at least 10 dBm and 12 dBm power savings compared to the prior art are achieved when estimating the direct and cascaded channels. These findings underscore the practical benefits and superiority of our proposed technique.
HYDRA: Hybrid Robot Actions for Imitation Learning
Jun 29, 2023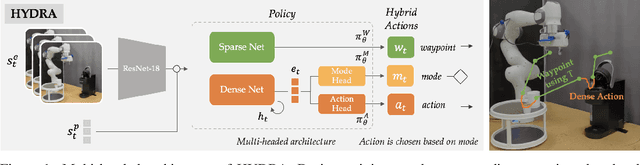

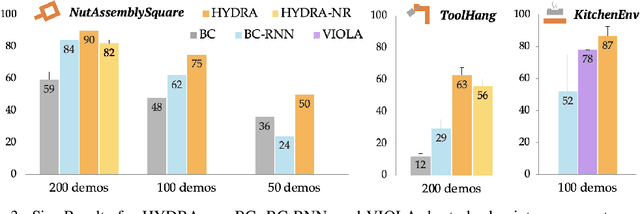
Imitation Learning (IL) is a sample efficient paradigm for robot learning using expert demonstrations. However, policies learned through IL suffer from state distribution shift at test time, due to compounding errors in action prediction which lead to previously unseen states. Choosing an action representation for the policy that minimizes this distribution shift is critical in imitation learning. Prior work propose using temporal action abstractions to reduce compounding errors, but they often sacrifice policy dexterity or require domain-specific knowledge. To address these trade-offs, we introduce HYDRA, a method that leverages a hybrid action space with two levels of action abstractions: sparse high-level waypoints and dense low-level actions. HYDRA dynamically switches between action abstractions at test time to enable both coarse and fine-grained control of a robot. In addition, HYDRA employs action relabeling to increase the consistency of actions in the dataset, further reducing distribution shift. HYDRA outperforms prior imitation learning methods by 30-40% on seven challenging simulation and real world environments, involving long-horizon tasks in the real world like making coffee and toasting bread. Videos are found on our website: https://tinyurl.com/3mc6793z
A Massive Scale Semantic Similarity Dataset of Historical English
Jun 30, 2023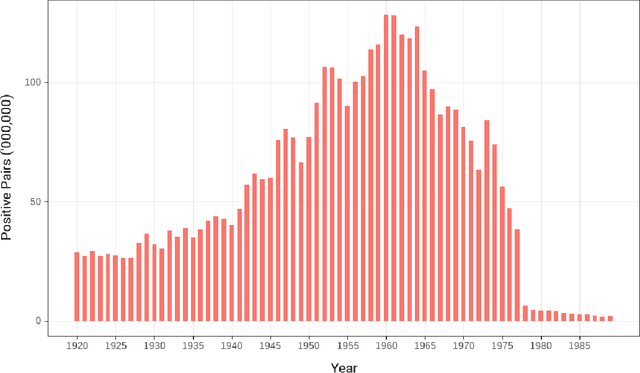


A diversity of tasks use language models trained on semantic similarity data. While there are a variety of datasets that capture semantic similarity, they are either constructed from modern web data or are relatively small datasets created in the past decade by human annotators. This study utilizes a novel source, newly digitized articles from off-copyright, local U.S. newspapers, to assemble a massive-scale semantic similarity dataset spanning 70 years from 1920 to 1989 and containing nearly 400M positive semantic similarity pairs. Historically, around half of articles in U.S. local newspapers came from newswires like the Associated Press. While local papers reproduced articles from the newswire, they wrote their own headlines, which form abstractive summaries of the associated articles. We associate articles and their headlines by exploiting document layouts and language understanding. We then use deep neural methods to detect which articles are from the same underlying source, in the presence of substantial noise and abridgement. The headlines of reproduced articles form positive semantic similarity pairs. The resulting publicly available HEADLINES dataset is significantly larger than most existing semantic similarity datasets and covers a much longer span of time. It will facilitate the application of contrastively trained semantic similarity models to a variety of tasks, including the study of semantic change across space and time.
GRAINS: Proximity Sensing of Objects in Granular Materials
Jul 12, 2023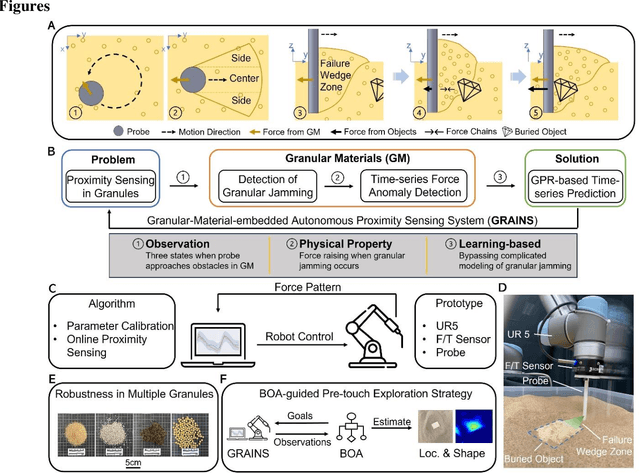
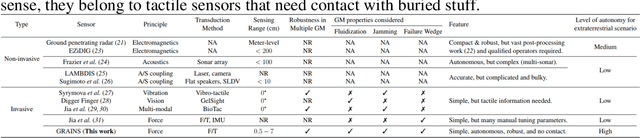
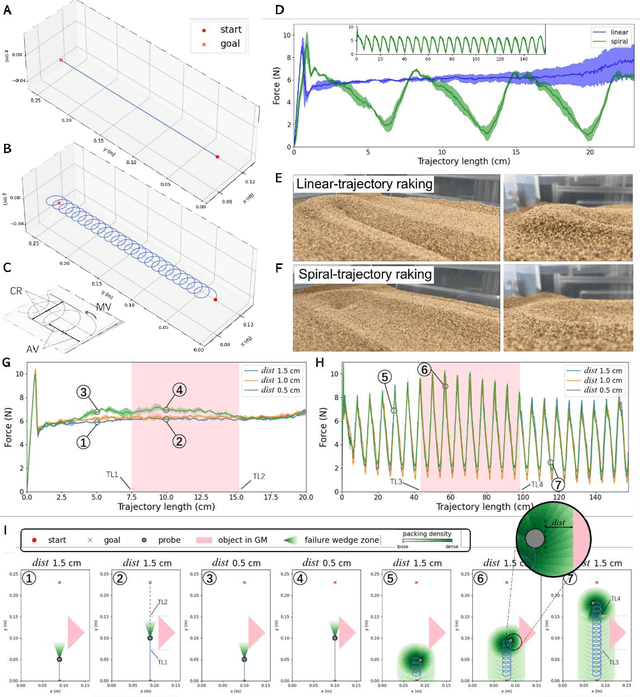
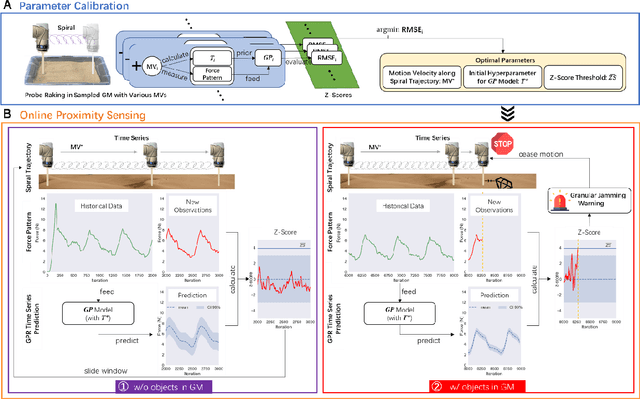
Proximity sensing detects an object's presence without contact. However, research has rarely explored proximity sensing in granular materials (GM) due to GM's lack of visual and complex properties. In this paper, we propose a granular-material-embedded autonomous proximity sensing system (GRAINS) based on three granular phenomena (fluidization, jamming, and failure wedge zone). GRAINS can automatically sense buried objects beneath GM in real-time manner (at least ~20 hertz) and perceive them 0.5 ~ 7 centimeters ahead in different granules without the use of vision or touch. We introduce a new spiral trajectory for the probe raking in GM, combining linear and circular motions, inspired by a common granular fluidization technique. Based on the observation of force-raising when granular jamming occurs in the failure wedge zone in front of the probe during its raking, we employ Gaussian process regression to constantly learn and predict the force patterns and detect the force anomaly resulting from granular jamming to identify the proximity sensing of buried objects. Finally, we apply GRAINS to a Bayesian-optimization-algorithm-guided exploration strategy to successfully localize underground objects and outline their distribution using proximity sensing without contact or digging. This work offers a simple yet reliable method with potential for safe operation in building habitation infrastructure on an alien planet without human intervention.
ConvNeXt-ChARM: ConvNeXt-based Transform for Efficient Neural Image Compression
Jul 12, 2023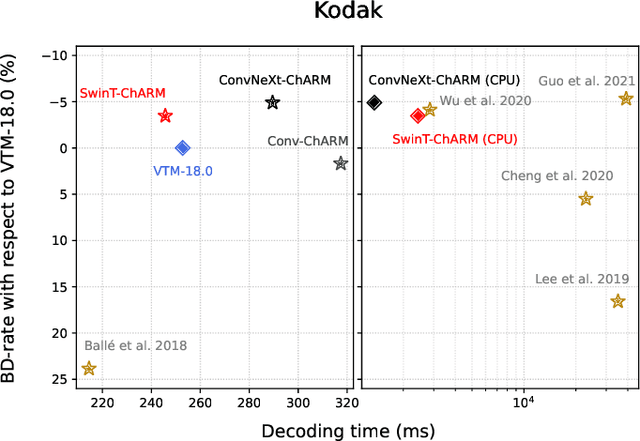
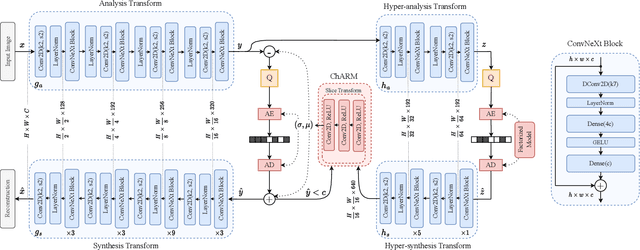
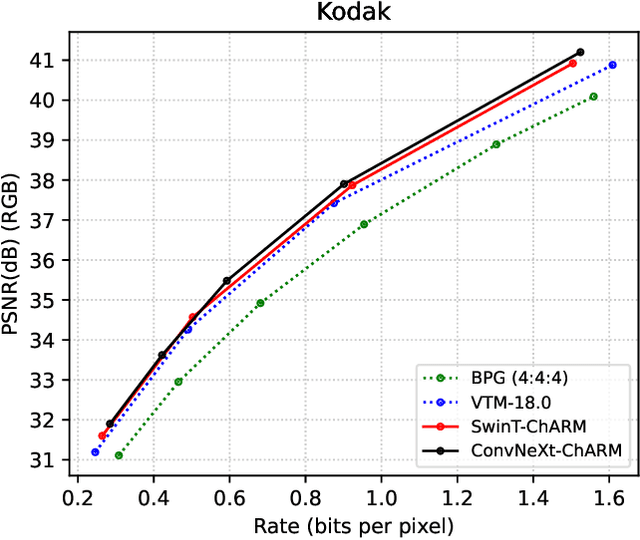
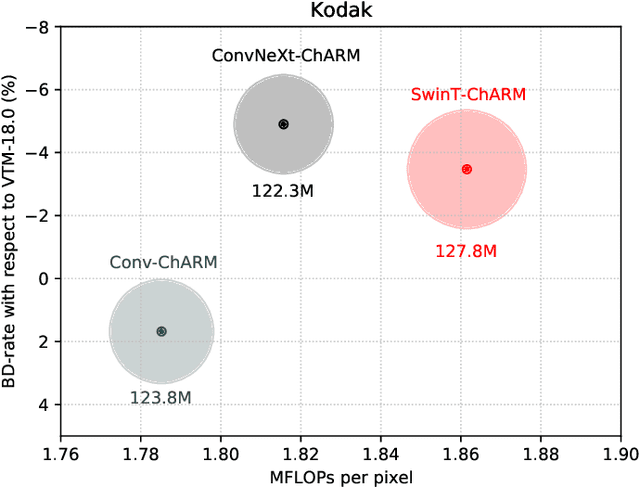
Over the last few years, neural image compression has gained wide attention from research and industry, yielding promising end-to-end deep neural codecs outperforming their conventional counterparts in rate-distortion performance. Despite significant advancement, current methods, including attention-based transform coding, still need to be improved in reducing the coding rate while preserving the reconstruction fidelity, especially in non-homogeneous textured image areas. Those models also require more parameters and a higher decoding time. To tackle the above challenges, we propose ConvNeXt-ChARM, an efficient ConvNeXt-based transform coding framework, paired with a compute-efficient channel-wise auto-regressive prior to capturing both global and local contexts from the hyper and quantized latent representations. The proposed architecture can be optimized end-to-end to fully exploit the context information and extract compact latent representation while reconstructing higher-quality images. Experimental results on four widely-used datasets showed that ConvNeXt-ChARM brings consistent and significant BD-rate (PSNR) reductions estimated on average to 5.24% and 1.22% over the versatile video coding (VVC) reference encoder (VTM-18.0) and the state-of-the-art learned image compression method SwinT-ChARM, respectively. Moreover, we provide model scaling studies to verify the computational efficiency of our approach and conduct several objective and subjective analyses to bring to the fore the performance gap between the next generation ConvNet, namely ConvNeXt, and Swin Transformer.
Automatically Reconciling the Trade-off between Prediction Accuracy and Earliness in Prescriptive Business Process Monitoring
Jul 12, 2023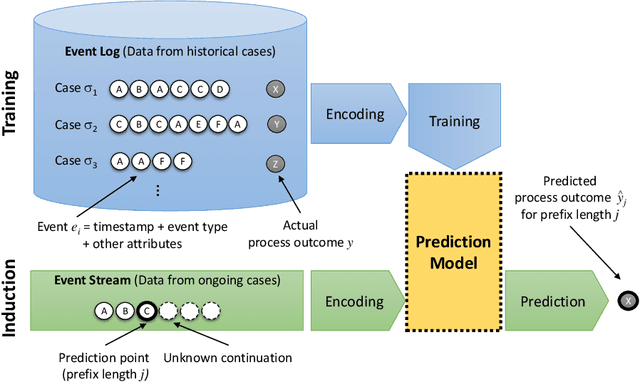

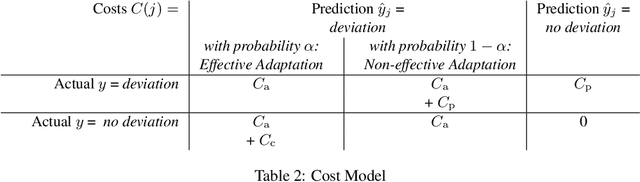
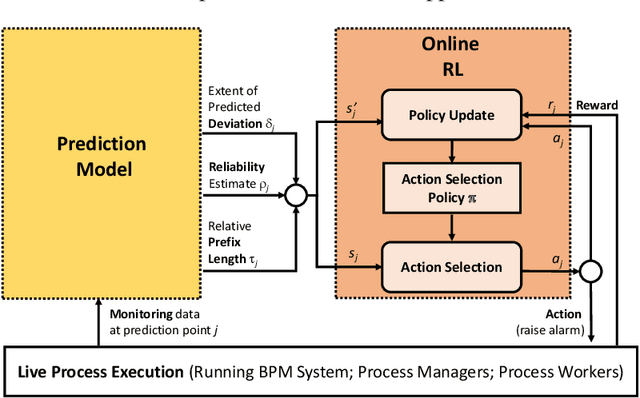
Prescriptive business process monitoring provides decision support to process managers on when and how to adapt an ongoing business process to prevent or mitigate an undesired process outcome. We focus on the problem of automatically reconciling the trade-off between prediction accuracy and prediction earliness in determining when to adapt. Adaptations should happen sufficiently early to provide enough lead time for the adaptation to become effective. However, earlier predictions are typically less accurate than later predictions. This means that acting on less accurate predictions may lead to unnecessary adaptations or missed adaptations. Different approaches were presented in the literature to reconcile the trade-off between prediction accuracy and earliness. So far, these approaches were compared with different baselines, and evaluated using different data sets or even confidential data sets. This limits the comparability and replicability of the approaches and makes it difficult to choose a concrete approach in practice. We perform a comparative evaluation of the main alternative approaches for reconciling the trade-off between prediction accuracy and earliness. Using four public real-world event log data sets and two types of prediction models, we assess and compare the cost savings of these approaches. The experimental results indicate which criteria affect the effectiveness of an approach and help us state initial recommendations for the selection of a concrete approach in practice.
Kriging-Based 3-D Spectrum Awareness for Radio Dynamic Zones Using Aerial Spectrum Sensors
Jul 12, 2023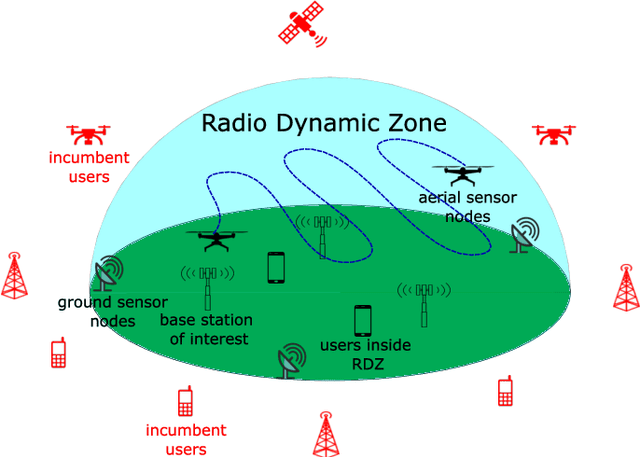
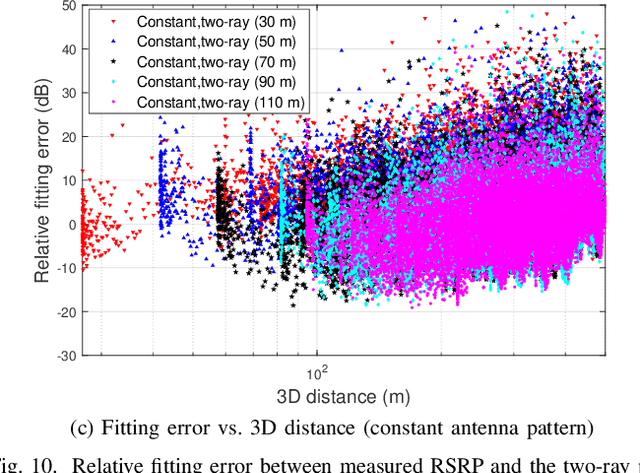
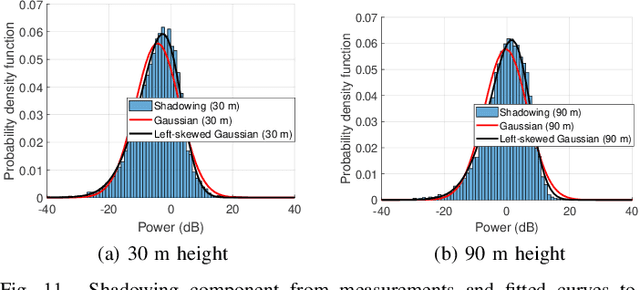
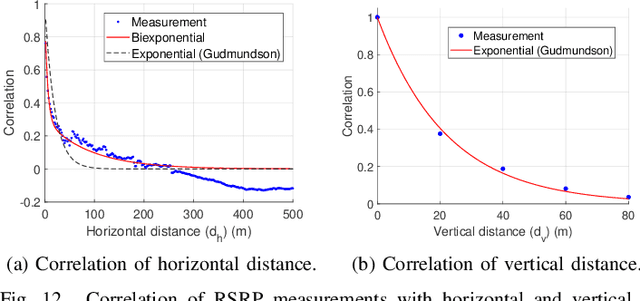
Radio dynamic zones (RDZs) are geographical areas within which dedicated spectrum resources are monitored and controlled to enable the development and testing of new spectrum technologies. Real-time spectrum awareness within an RDZ is critical for preventing interference with nearby incumbent users of the spectrum. In this paper, we consider a 3D RDZ scenario and propose to use unmanned aerial vehicles (UAVs) equipped with spectrum sensors to create and maintain a 3D radio map of received signal power from different sources within the RDZ. In particular, we introduce a 3D Kriging interpolation technique that uses realistic 3D correlation models of the signal power extracted from extensive measurements carried out at the NSF AERPAW platform. Using C-Band signal measurements by a UAV at altitudes between 30 m-110 m, we first develop realistic propagation models on air-to-ground path loss, shadowing, spatial correlation, and semi-variogram, while taking into account the knowledge of antenna radiation patterns and ground reflection. Subsequently, we generate a 3D radio map of a signal source within the RDZ using the Kriging interpolation and evaluate its sensitivity to the number of measurements used and their spatial distribution. Our results show that the proposed 3D Kriging interpolation technique provides significantly better radio maps when compared with an approach that assumes perfect knowledge of path loss.
Dividing and Conquering a BlackBox to a Mixture of Interpretable Models: Route, Interpret, Repeat
Jul 12, 2023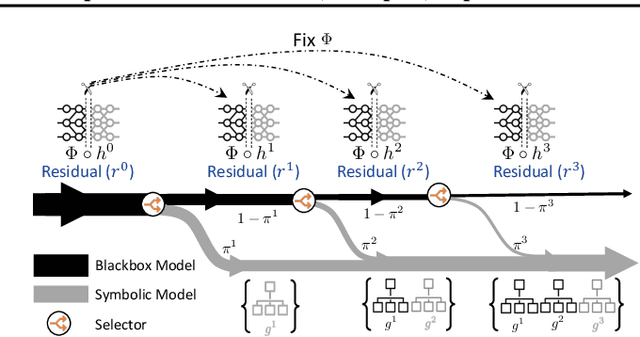

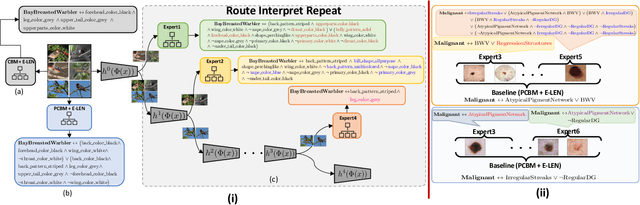
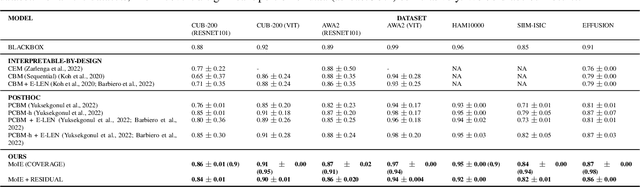
ML model design either starts with an interpretable model or a Blackbox and explains it post hoc. Blackbox models are flexible but difficult to explain, while interpretable models are inherently explainable. Yet, interpretable models require extensive ML knowledge and tend to be less flexible and underperforming than their Blackbox variants. This paper aims to blur the distinction between a post hoc explanation of a Blackbox and constructing interpretable models. Beginning with a Blackbox, we iteratively carve out a mixture of interpretable experts (MoIE) and a residual network. Each interpretable model specializes in a subset of samples and explains them using First Order Logic (FOL), providing basic reasoning on concepts from the Blackbox. We route the remaining samples through a flexible residual. We repeat the method on the residual network until all the interpretable models explain the desired proportion of data. Our extensive experiments show that our route, interpret, and repeat approach (1) identifies a diverse set of instance-specific concepts with high concept completeness via MoIE without compromising in performance, (2) identifies the relatively ``harder'' samples to explain via residuals, (3) outperforms the interpretable by-design models by significant margins during test-time interventions, and (4) fixes the shortcut learned by the original Blackbox. The code for MoIE is publicly available at: \url{https://github.com/batmanlab/ICML-2023-Route-interpret-repeat}
* appeared as v5 of arXiv:2302.10289 which was replaced in error, which drifted into a different work, accepted in ICML 2023
Adaptive Student's t-distribution with method of moments moving estimator for nonstationary time series
Apr 12, 2023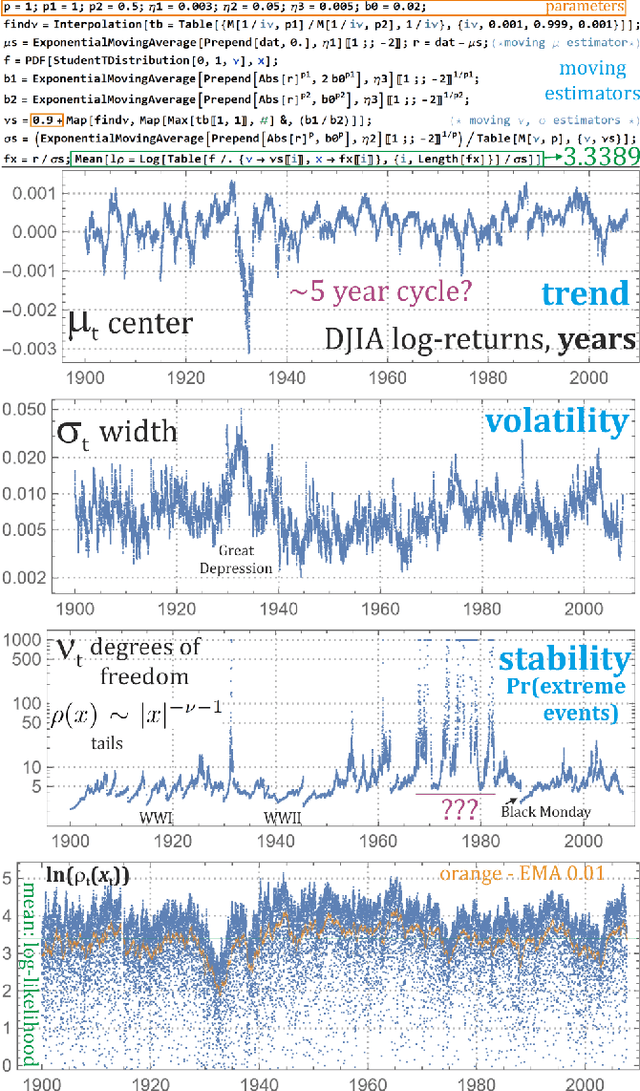
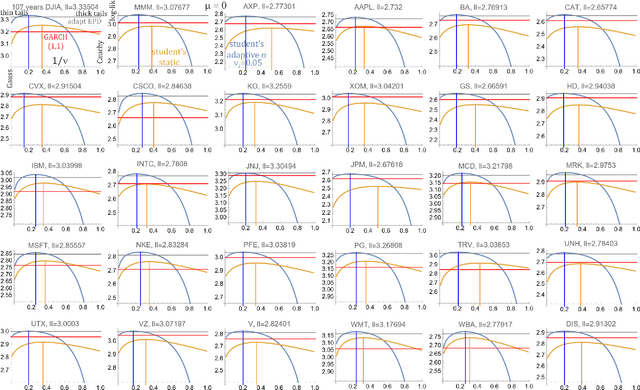
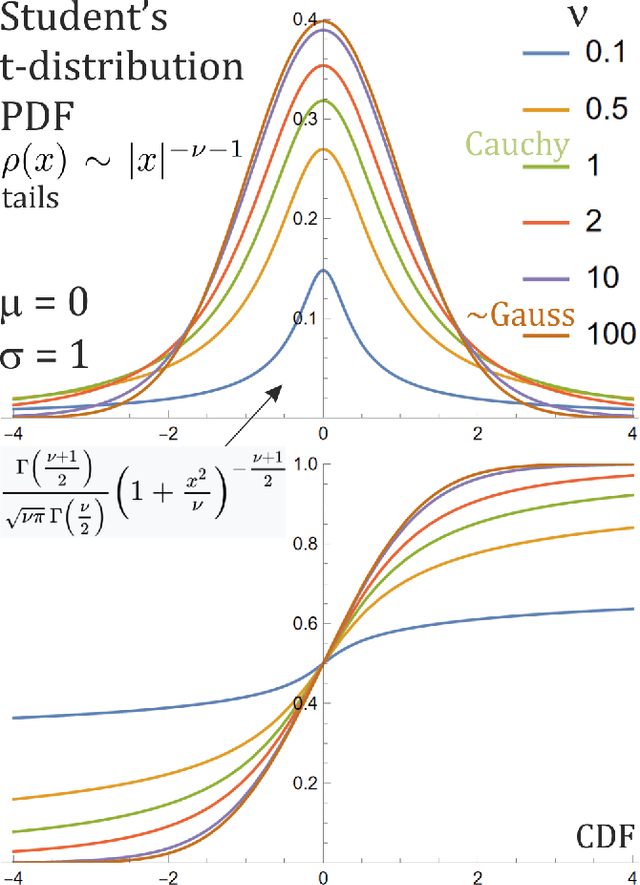
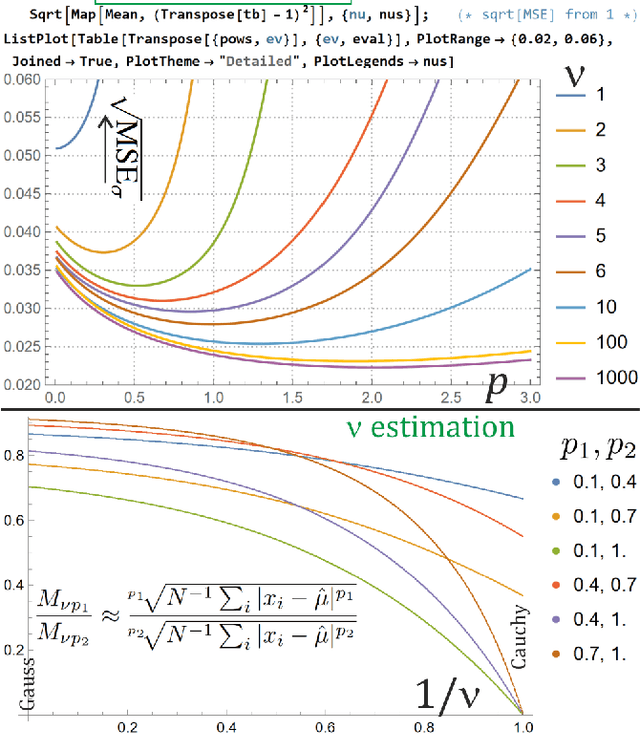
The real life time series are usually nonstationary, bringing a difficult question of model adaptation. Classical approaches like ARMA-ARCH assume arbitrary type of dependence. To avoid such bias, we will focus on recently proposed agnostic philosophy of moving estimator: in time $t$ finding parameters optimizing e.g. $F_t=\sum_{\tau<t} (1-\eta)^{t-\tau} \ln(\rho_\theta (x_\tau))$ moving log-likelihood, evolving in time. It allows for example to estimate parameters using inexpensive exponential moving averages (EMA), like absolute central moments $E[|x-\mu|^p]$ evolving for one or multiple powers $p\in\mathbb{R}^+$ using $m_{p,t+1} = m_{p,t} + \eta (|x_t-\mu_t|^p-m_{p,t})$. Application of such general adaptive methods of moments will be presented on Student's t-distribution, popular especially in economical applications, here applied to log-returns of DJIA companies. While standard ARMA-ARCH approaches provide evolution of $\mu$ and $\sigma$, here we also get evolution of $\nu$ describing $\rho(x)\sim |x|^{-\nu-1}$ tail shape, probability of extreme events - which might turn out catastrophic, destabilizing the market.