 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
EgoLocate: Real-time Motion Capture, Localization, and Mapping with Sparse Body-mounted Sensors
May 02, 2023
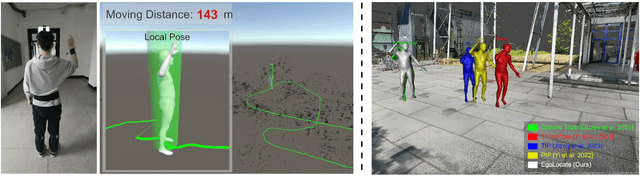
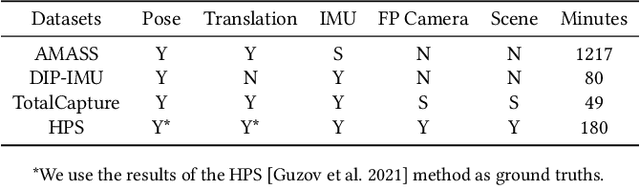
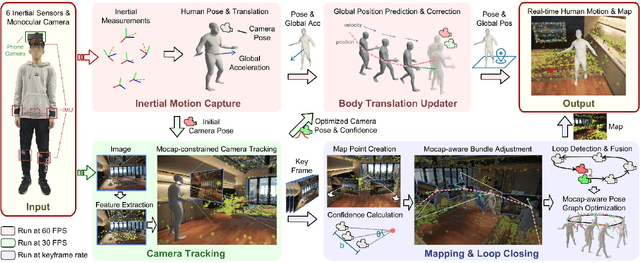

Human and environment sensing are two important topics in Computer Vision and Graphics. Human motion is often captured by inertial sensors, while the environment is mostly reconstructed using cameras. We integrate the two techniques together in EgoLocate, a system that simultaneously performs human motion capture (mocap), localization, and mapping in real time from sparse body-mounted sensors, including 6 inertial measurement units (IMUs) and a monocular phone camera. On one hand, inertial mocap suffers from large translation drift due to the lack of the global positioning signal. EgoLocate leverages image-based simultaneous localization and mapping (SLAM) techniques to locate the human in the reconstructed scene. On the other hand, SLAM often fails when the visual feature is poor. EgoLocate involves inertial mocap to provide a strong prior for the camera motion. Experiments show that localization, a key challenge for both two fields, is largely improved by our technique, compared with the state of the art of the two fields. Our codes are available for research at https://xinyu-yi.github.io/EgoLocate/.
Are Large Language Models a Threat to Digital Public Goods? Evidence from Activity on Stack Overflow
Jul 14, 2023Large language models like ChatGPT efficiently provide users with information about various topics, presenting a potential substitute for searching the web and asking people for help online. But since users interact privately with the model, these models may drastically reduce the amount of publicly available human-generated data and knowledge resources. This substitution can present a significant problem in securing training data for future models. In this work, we investigate how the release of ChatGPT changed human-generated open data on the web by analyzing the activity on Stack Overflow, the leading online Q\&A platform for computer programming. We find that relative to its Russian and Chinese counterparts, where access to ChatGPT is limited, and to similar forums for mathematics, where ChatGPT is less capable, activity on Stack Overflow significantly decreased. A difference-in-differences model estimates a 16\% decrease in weekly posts on Stack Overflow. This effect increases in magnitude over time, and is larger for posts related to the most widely used programming languages. Posts made after ChatGPT get similar voting scores than before, suggesting that ChatGPT is not merely displacing duplicate or low-quality content. These results suggest that more users are adopting large language models to answer questions and they are better substitutes for Stack Overflow for languages for which they have more training data. Using models like ChatGPT may be more efficient for solving certain programming problems, but its widespread adoption and the resulting shift away from public exchange on the web will limit the open data people and models can learn from in the future.
Beyond the Snapshot: Brain Tokenized Graph Transformer for Longitudinal Brain Functional Connectome Embedding
Jul 03, 2023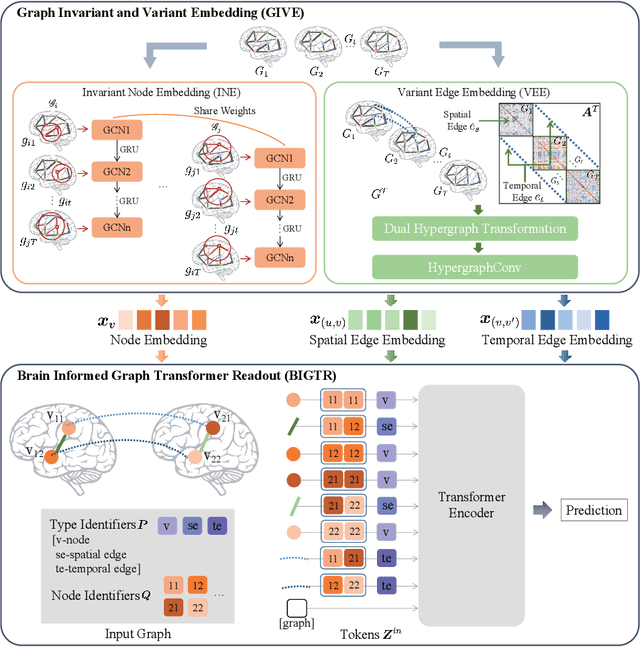
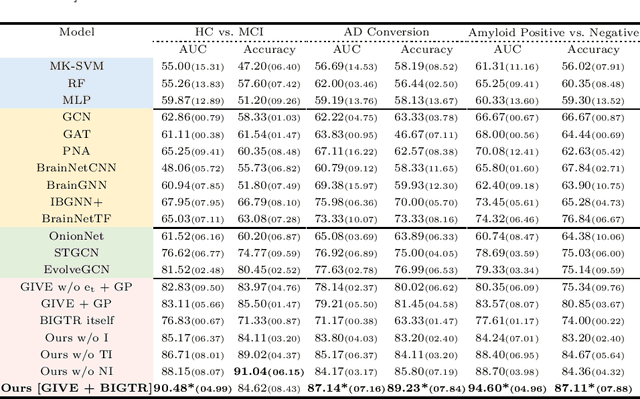
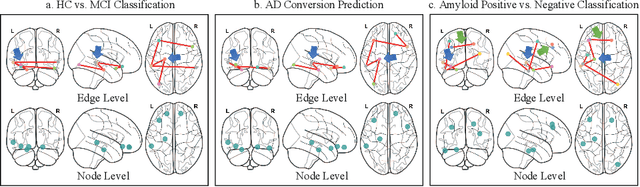
Under the framework of network-based neurodegeneration, brain functional connectome (FC)-based Graph Neural Networks (GNN) have emerged as a valuable tool for the diagnosis and prognosis of neurodegenerative diseases such as Alzheimer's disease (AD). However, these models are tailored for brain FC at a single time point instead of characterizing FC trajectory. Discerning how FC evolves with disease progression, particularly at the predementia stages such as cognitively normal individuals with amyloid deposition or individuals with mild cognitive impairment (MCI), is crucial for delineating disease spreading patterns and developing effective strategies to slow down or even halt disease advancement. In this work, we proposed the first interpretable framework for brain FC trajectory embedding with application to neurodegenerative disease diagnosis and prognosis, namely Brain Tokenized Graph Transformer (Brain TokenGT). It consists of two modules: 1) Graph Invariant and Variant Embedding (GIVE) for generation of node and spatio-temporal edge embeddings, which were tokenized for downstream processing; 2) Brain Informed Graph Transformer Readout (BIGTR) which augments previous tokens with trainable type identifiers and non-trainable node identifiers and feeds them into a standard transformer encoder to readout. We conducted extensive experiments on two public longitudinal fMRI datasets of the AD continuum for three tasks, including differentiating MCI from controls, predicting dementia conversion in MCI, and classification of amyloid positive or negative cognitively normal individuals. Based on brain FC trajectory, the proposed Brain TokenGT approach outperformed all the other benchmark models and at the same time provided excellent interpretability. The code is available at https://github.com/ZijianD/Brain-TokenGT.git
DSRM: Boost Textual Adversarial Training with Distribution Shift Risk Minimization
Jun 27, 2023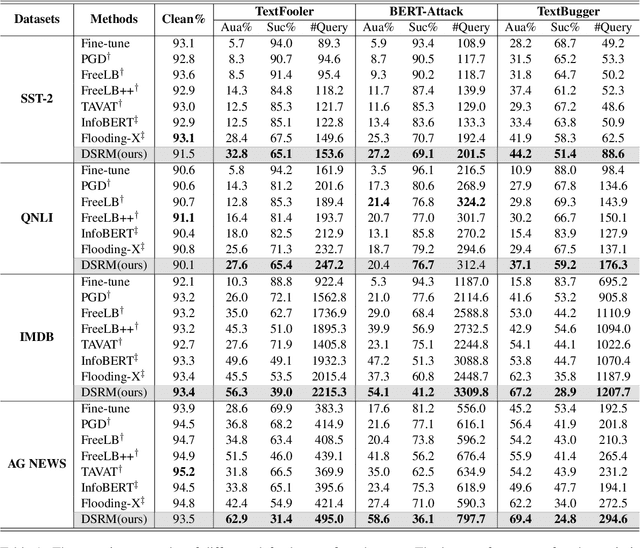
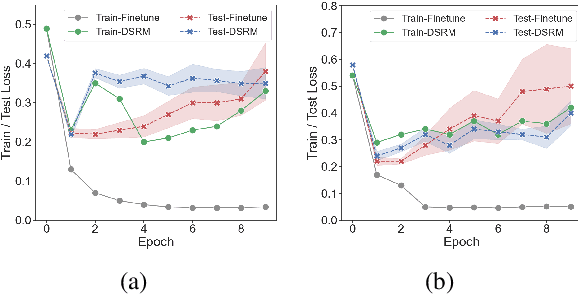
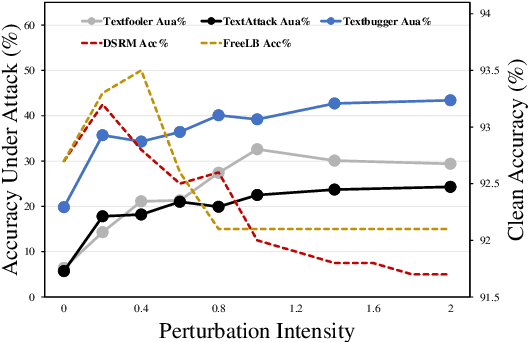
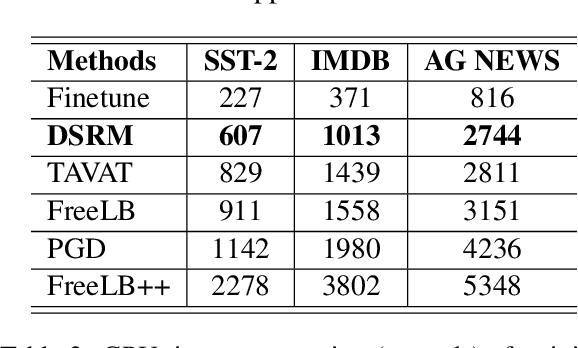
Adversarial training is one of the best-performing methods in improving the robustness of deep language models. However, robust models come at the cost of high time consumption, as they require multi-step gradient ascents or word substitutions to obtain adversarial samples. In addition, these generated samples are deficient in grammatical quality and semantic consistency, which impairs the effectiveness of adversarial training. To address these problems, we introduce a novel, effective procedure for instead adversarial training with only clean data. Our procedure, distribution shift risk minimization (DSRM), estimates the adversarial loss by perturbing the input data's probability distribution rather than their embeddings. This formulation results in a robust model that minimizes the expected global loss under adversarial attacks. Our approach requires zero adversarial samples for training and reduces time consumption by up to 70\% compared to current best-performing adversarial training methods. Experiments demonstrate that DSRM considerably improves BERT's resistance to textual adversarial attacks and achieves state-of-the-art robust accuracy on various benchmarks.
Deep Learning of Dynamical System Parameters from Return Maps as Images
Jun 20, 2023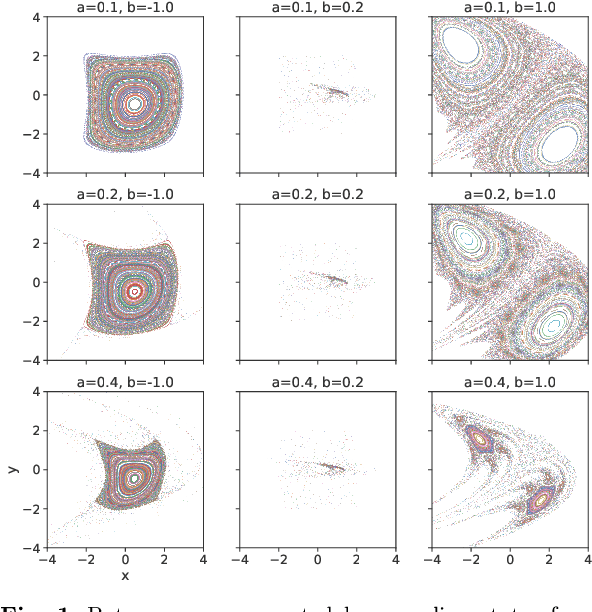
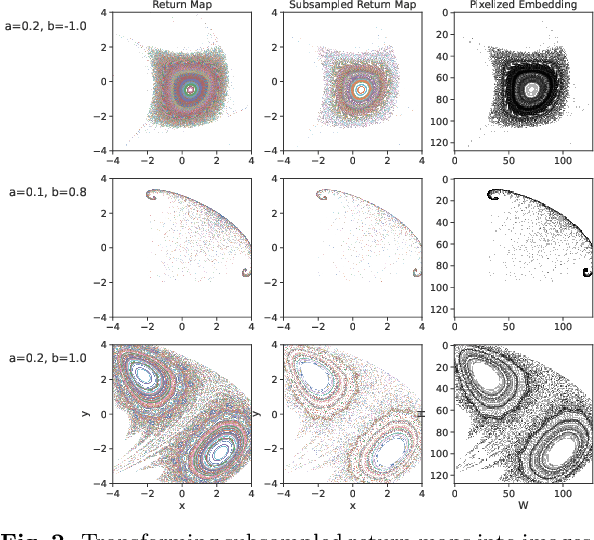
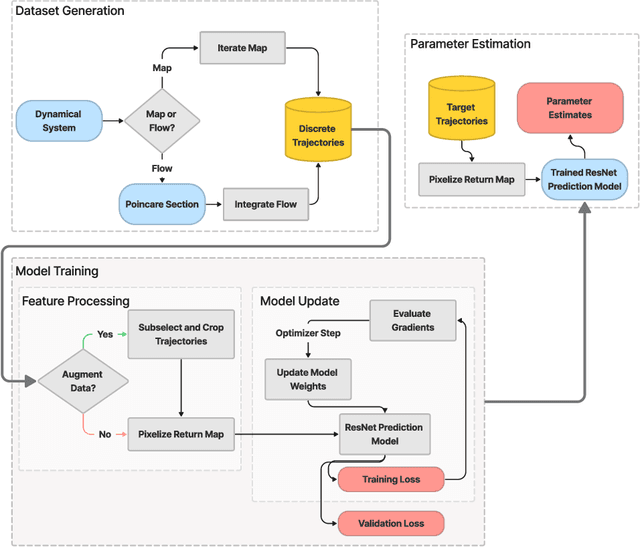
We present a novel approach to system identification (SI) using deep learning techniques. Focusing on parametric system identification (PSI), we use a supervised learning approach for estimating the parameters of discrete and continuous-time dynamical systems, irrespective of chaos. To accomplish this, we transform collections of state-space trajectory observations into image-like data to retain the state-space topology of trajectories from dynamical systems and train convolutional neural networks to estimate the parameters of dynamical systems from these images. We demonstrate that our approach can learn parameter estimation functions for various dynamical systems, and by using training-time data augmentation, we are able to learn estimation functions whose parameter estimates are robust to changes in the sample fidelity of their inputs. Once trained, these estimation models return parameter estimations for new systems with negligible time and computation costs.
A Passivity-Based Method for Accelerated Convex Optimisation
Jun 20, 2023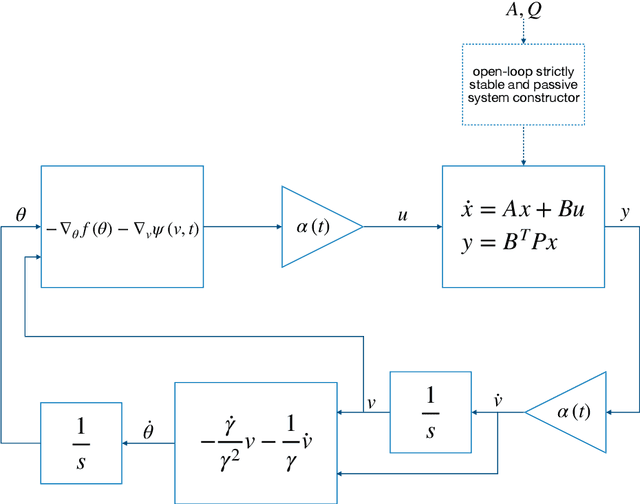
This study presents a constructive methodology for designing accelerated convex optimisation algorithms in continuous-time domain. The two key enablers are the classical concept of passivity in control theory and the time-dependent change of variables that maps the output of the internal dynamic system to the optimisation variables. The Lyapunov function associated with the optimisation dynamics is obtained as a natural consequence of specifying the internal dynamics that drives the state evolution as a passive linear time-invariant system. The passivity-based methodology provides a general framework that has the flexibility to generate convex optimisation algorithms with the guarantee of different convergence rate bounds on the objective function value. The same principle applies to the design of online parameter update algorithms for adaptive control by re-defining the output of internal dynamics to allow for the feedback interconnection with tracking error dynamics.
Neural Scene Chronology
Jun 13, 2023
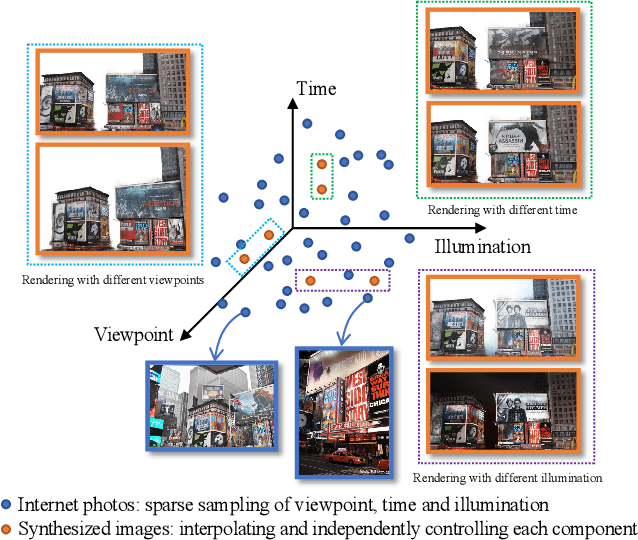
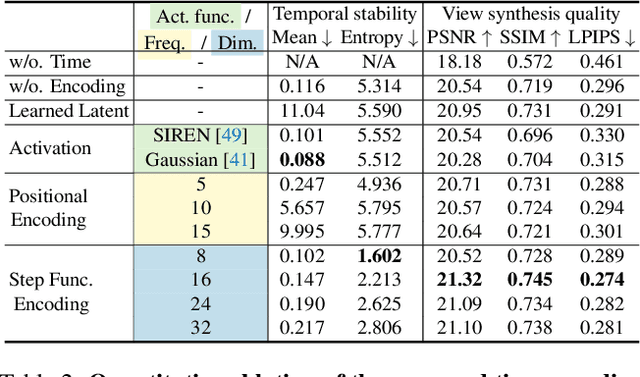
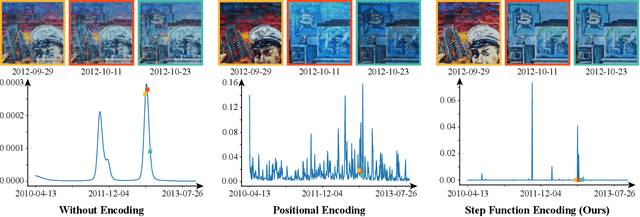
In this work, we aim to reconstruct a time-varying 3D model, capable of rendering photo-realistic renderings with independent control of viewpoint, illumination, and time, from Internet photos of large-scale landmarks. The core challenges are twofold. First, different types of temporal changes, such as illumination and changes to the underlying scene itself (such as replacing one graffiti artwork with another) are entangled together in the imagery. Second, scene-level temporal changes are often discrete and sporadic over time, rather than continuous. To tackle these problems, we propose a new scene representation equipped with a novel temporal step function encoding method that can model discrete scene-level content changes as piece-wise constant functions over time. Specifically, we represent the scene as a space-time radiance field with a per-image illumination embedding, where temporally-varying scene changes are encoded using a set of learned step functions. To facilitate our task of chronology reconstruction from Internet imagery, we also collect a new dataset of four scenes that exhibit various changes over time. We demonstrate that our method exhibits state-of-the-art view synthesis results on this dataset, while achieving independent control of viewpoint, time, and illumination.
Time-Spread Pilot-Based Channel Estimation for Backscatter Networks
May 26, 2023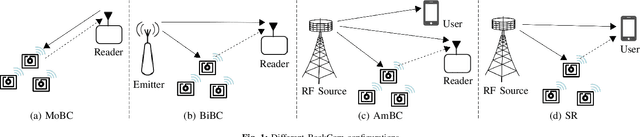
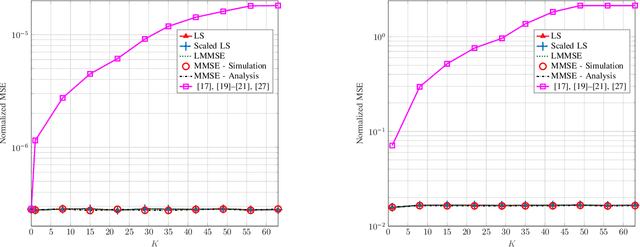
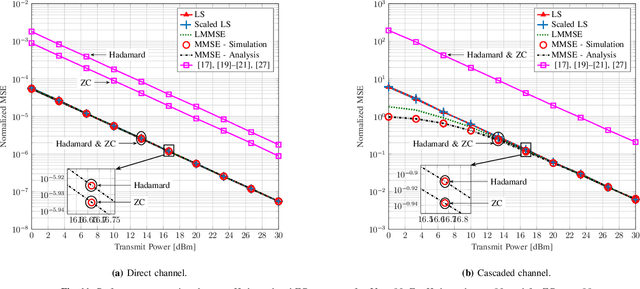
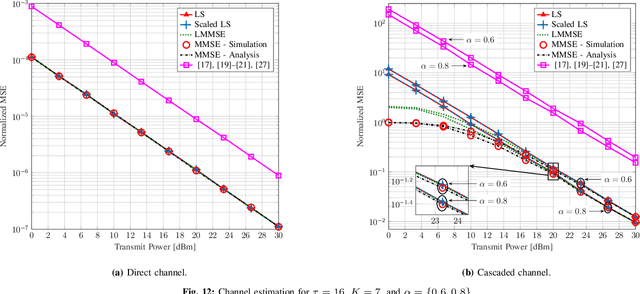
Current backscatter channel estimators employ an inefficient silent pilot transmission protocol, where tags alternate between silent and active states. To enhance performance, we propose a novel approach where tags remain active simultaneously throughout the entire training phase. This enables a one-shot estimation of both the direct and cascaded channels and accommodates various backscatter network configurations. We derive the conditions for optimal pilot sequences and also establish that the minimum variance unbiased (MVU) estimator attains the Cramer-Rao lower bound. Next, we propose new pilot designs to avoid pilot contamination. We then present several linear estimation methods, including least square (LS), scaled LS, and linear minimum mean square error (MMSE), to evaluate the performance of our proposed scheme. We also derive the analytical MMSE estimator using our proposed pilot designs. Furthermore, we adapt our method for cellular-based passive Internet-of-Things (IoT) networks with multiple tags and cellular users. Extensive numerical results and simulations are provided to validate the effectiveness of our approach. Notably, at least 10 dBm and 12 dBm power savings compared to the prior art are achieved when estimating the direct and cascaded channels. These findings underscore the practical benefits and superiority of our proposed technique.
Toward Interactive Dictation
Jul 08, 2023
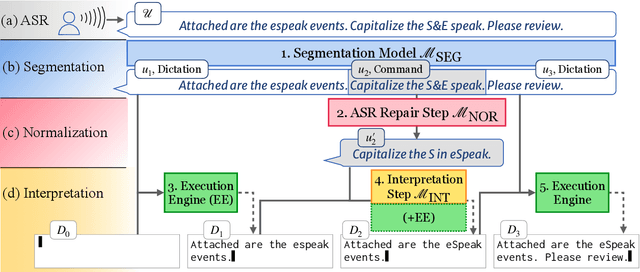
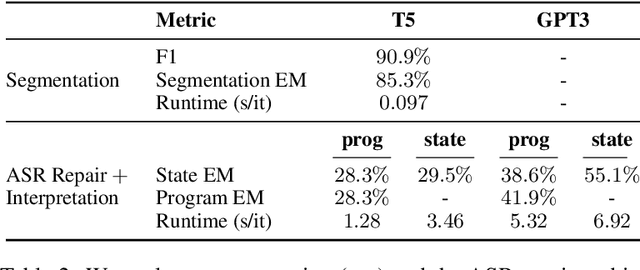
Voice dictation is an increasingly important text input modality. Existing systems that allow both dictation and editing-by-voice restrict their command language to flat templates invoked by trigger words. In this work, we study the feasibility of allowing users to interrupt their dictation with spoken editing commands in open-ended natural language. We introduce a new task and dataset, TERTiUS, to experiment with such systems. To support this flexibility in real-time, a system must incrementally segment and classify spans of speech as either dictation or command, and interpret the spans that are commands. We experiment with using large pre-trained language models to predict the edited text, or alternatively, to predict a small text-editing program. Experiments show a natural trade-off between model accuracy and latency: a smaller model achieves 30% end-state accuracy with 1.3 seconds of latency, while a larger model achieves 55% end-state accuracy with 7 seconds of latency.
Self-supervised Equality Embedded Deep Lagrange Dual for Approximate Constrained Optimization
Jun 28, 2023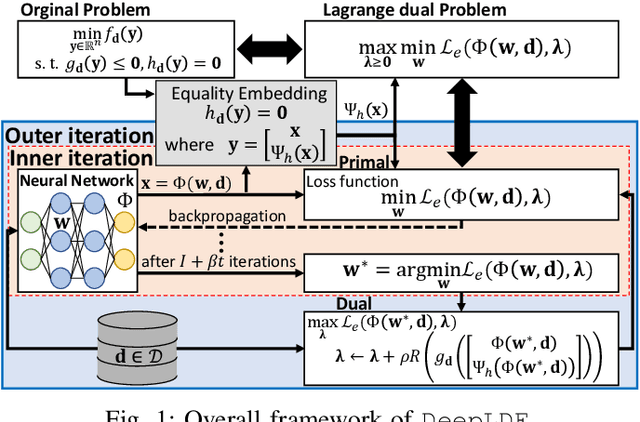
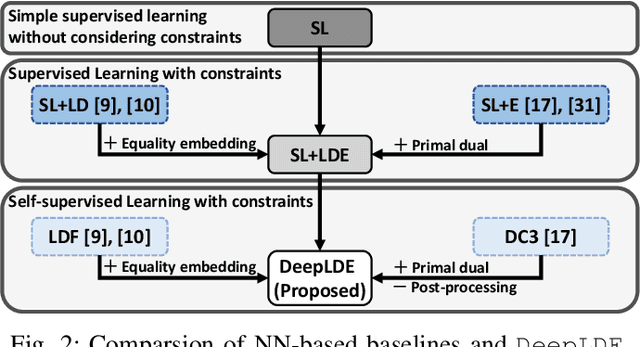
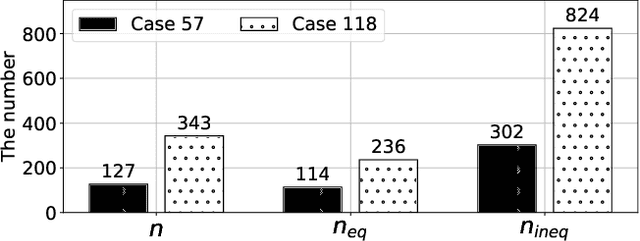
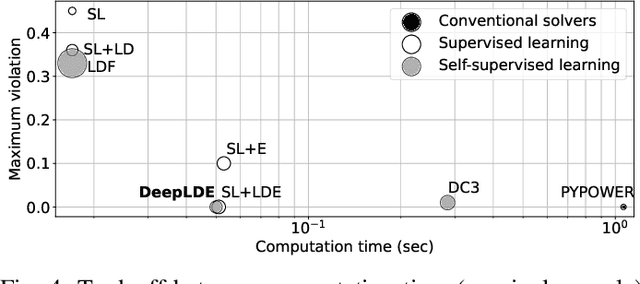
Conventional solvers are often computationally expensive for constrained optimization, particularly in large-scale and time-critical problems. While this leads to a growing interest in using neural networks (NNs) as fast optimal solution approximators, incorporating the constraints with NNs is challenging. In this regard, we propose deep Lagrange dual with equality embedding (DeepLDE), a framework that learns to find an optimal solution without using labels. To ensure feasible solutions, we embed equality constraints into the NNs and train the NNs using the primal-dual method to impose inequality constraints. Furthermore, we prove the convergence of DeepLDE and show that the primal-dual learning method alone cannot ensure equality constraints without the help of equality embedding. Simulation results on convex, non-convex, and AC optimal power flow (AC-OPF) problems show that the proposed DeepLDE achieves the smallest optimality gap among all the NN-based approaches while always ensuring feasible solutions. Furthermore, the computation time of the proposed method is about 5 to 250 times faster than DC3 and the conventional solvers in solving constrained convex, non-convex optimization, and/or AC-OPF.