 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
End-to-End Learnable Multi-Scale Feature Compression for VCM
Jul 16, 2023
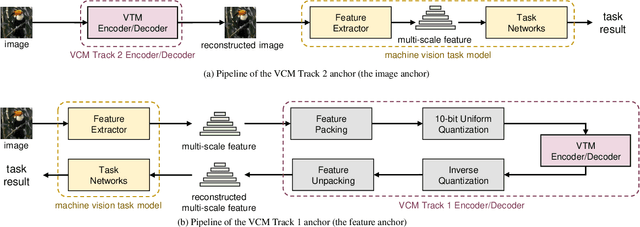
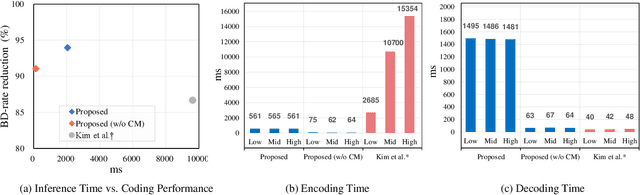
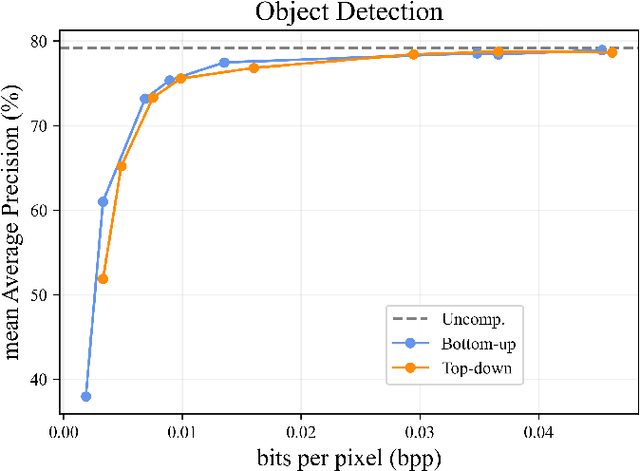
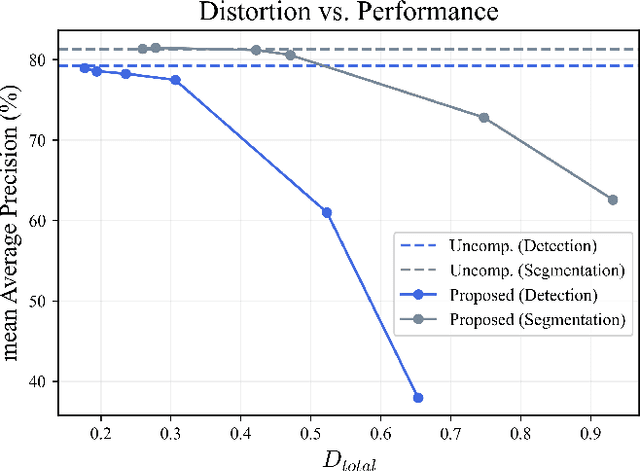
The proliferation of deep learning-based machine vision applications has given rise to a new type of compression, so called video coding for machine (VCM). VCM differs from traditional video coding in that it is optimized for machine vision performance instead of human visual quality. In the feature compression track of MPEG-VCM, multi-scale features extracted from images are subject to compression. Recent feature compression works have demonstrated that the versatile video coding (VVC) standard-based approach can achieve a BD-rate reduction of up to 96% against MPEG-VCM feature anchor. However, it is still sub-optimal as VVC was not designed for extracted features but for natural images. Moreover, the high encoding complexity of VVC makes it difficult to design a lightweight encoder without sacrificing performance. To address these challenges, we propose a novel multi-scale feature compression method that enables both the end-to-end optimization on the extracted features and the design of lightweight encoders. The proposed model combines a learnable compressor with a multi-scale feature fusion network so that the redundancy in the multi-scale features is effectively removed. Instead of simply cascading the fusion network and the compression network, we integrate the fusion and encoding processes in an interleaved way. Our model first encodes a larger-scale feature to obtain a latent representation and then fuses the latent with a smaller-scale feature. This process is successively performed until the smallest-scale feature is fused and then the encoded latent at the final stage is entropy-coded for transmission. The results show that our model outperforms previous approaches by at least 52% BD-rate reduction and has $\times5$ to $\times27$ times less encoding time for object detection...
MaGNAS: A Mapping-Aware Graph Neural Architecture Search Framework for Heterogeneous MPSoC Deployment
Jul 16, 2023Graph Neural Networks (GNNs) are becoming increasingly popular for vision-based applications due to their intrinsic capacity in modeling structural and contextual relations between various parts of an image frame. On another front, the rising popularity of deep vision-based applications at the edge has been facilitated by the recent advancements in heterogeneous multi-processor Systems on Chips (MPSoCs) that enable inference under real-time, stringent execution requirements. By extension, GNNs employed for vision-based applications must adhere to the same execution requirements. Yet contrary to typical deep neural networks, the irregular flow of graph learning operations poses a challenge to running GNNs on such heterogeneous MPSoC platforms. In this paper, we propose a novel unified design-mapping approach for efficient processing of vision GNN workloads on heterogeneous MPSoC platforms. Particularly, we develop MaGNAS, a mapping-aware Graph Neural Architecture Search framework. MaGNAS proposes a GNN architectural design space coupled with prospective mapping options on a heterogeneous SoC to identify model architectures that maximize on-device resource efficiency. To achieve this, MaGNAS employs a two-tier evolutionary search to identify optimal GNNs and mapping pairings that yield the best performance trade-offs. Through designing a supernet derived from the recent Vision GNN (ViG) architecture, we conducted experiments on four (04) state-of-the-art vision datasets using both (i) a real hardware SoC platform (NVIDIA Xavier AGX) and (ii) a performance/cost model simulator for DNN accelerators. Our experimental results demonstrate that MaGNAS is able to provide 1.57x latency speedup and is 3.38x more energy-efficient for several vision datasets executed on the Xavier MPSoC vs. the GPU-only deployment while sustaining an average 0.11% accuracy reduction from the baseline.
A Comparative Analysis Between the Additive and the Multiplicative Extended Kalman Filter for Satellite Attitude Determination
Jul 12, 2023The general consensus is that the Multiplicative Extended Kalman Filter (MEKF) is superior to the Additive Extended Kalman Filter (AEKF) based on a wealth of theoretical evidence. This paper deals with a practical comparison between the two filters in simulation with the goal of verifying if the previous theoretical foundations are true. The AEKF and MEKF are two variants of the Extended Kalman Filter that differ in their approach to linearizing the system dynamics. The AEKF uses an additive correction term to update the state estimate, while the MEKF uses a multiplicative correction term. The two also differ in the state of which they use. The AEKF uses the quaternion as its state while the MEKF uses the Gibbs vector as its state. The results show that the MEKF consistently outperforms the AEKF in terms of estimation accuracy with lower uncertainty. The AEKF is more computationally efficient, but the difference is so low that it is almost negligible and it has no effect on a real-time application. Overall, the results suggest that the MEKF is a better choise for satellite attitude estimation due to its superior estimation accuracy and lower uncertainty, which agrees with the statements from previous work
Unveiling the Invisible: Enhanced Detection and Analysis of Deteriorated Areas in Solar PV Modules Using Unsupervised Sensing Algorithms and 3D Augmented Reality
Jul 12, 2023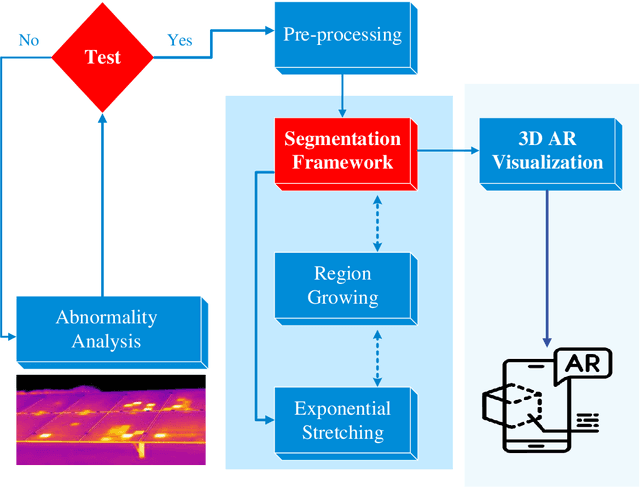

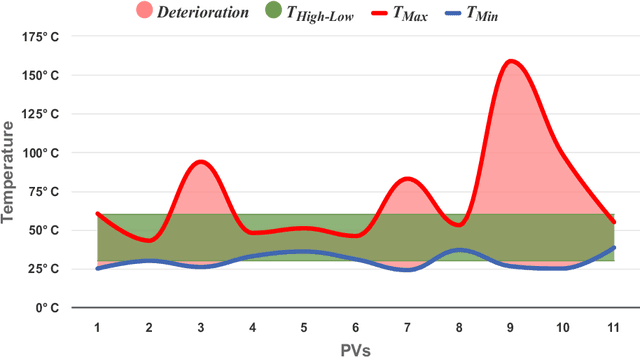
Solar Photovoltaic (PV) is increasingly being used to address the global concern of energy security. However, hot spot and snail trails in PV modules caused mostly by crakes reduce their efficiency and power capacity. This article presents a groundbreaking methodology for automatically identifying and analyzing anomalies like hot spots and snail trails in Solar Photovoltaic (PV) modules, leveraging unsupervised sensing algorithms and 3D Augmented Reality (AR) visualization. By transforming the traditional methods of diagnosis and repair, our approach not only enhances efficiency but also substantially cuts down the cost of PV system maintenance. Validated through computer simulations and real-world image datasets, the proposed framework accurately identifies dirty regions, emphasizing the critical role of regular maintenance in optimizing the power capacity of solar PV modules. Our immediate objective is to leverage drone technology for real-time, automatic solar panel detection, significantly boosting the efficacy of PV maintenance. The proposed methodology could revolutionize solar PV maintenance, enabling swift, precise anomaly detection without human intervention. This could result in significant cost savings, heightened energy production, and improved overall performance of solar PV systems. Moreover, the novel combination of unsupervised sensing algorithms with 3D AR visualization heralds new opportunities for further research and development in solar PV maintenance.
Temporal Label-Refinement for Weakly-Supervised Audio-Visual Event Localization
Jul 12, 2023Audio-Visual Event Localization (AVEL) is the task of temporally localizing and classifying \emph{audio-visual events}, i.e., events simultaneously visible and audible in a video. In this paper, we solve AVEL in a weakly-supervised setting, where only video-level event labels (their presence/absence, but not their locations in time) are available as supervision for training. Our idea is to use a base model to estimate labels on the training data at a finer temporal resolution than at the video level and re-train the model with these labels. I.e., we determine the subset of labels for each \emph{slice} of frames in a training video by (i) replacing the frames outside the slice with those from a second video having no overlap in video-level labels, and (ii) feeding this synthetic video into the base model to extract labels for just the slice in question. To handle the out-of-distribution nature of our synthetic videos, we propose an auxiliary objective for the base model that induces more reliable predictions of the localized event labels as desired. Our three-stage pipeline outperforms several existing AVEL methods with no architectural changes and improves performance on a related weakly-supervised task as well.
A Survey From Distributed Machine Learning to Distributed Deep Learning
Jul 11, 2023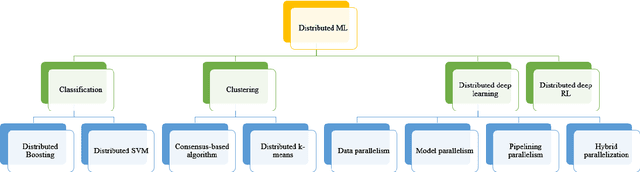
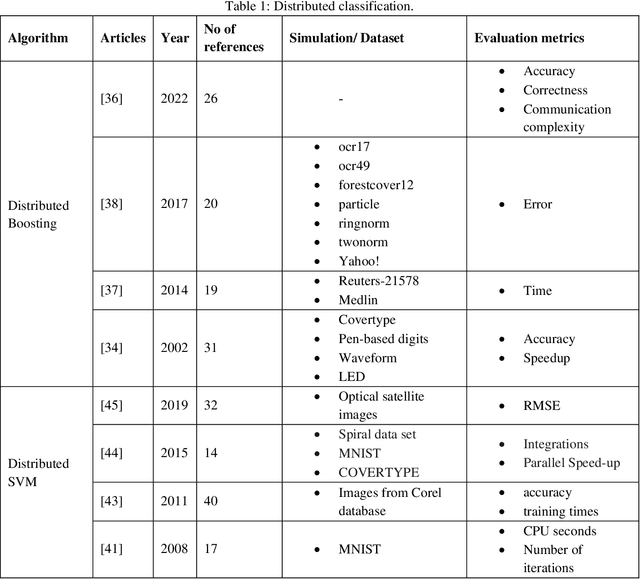
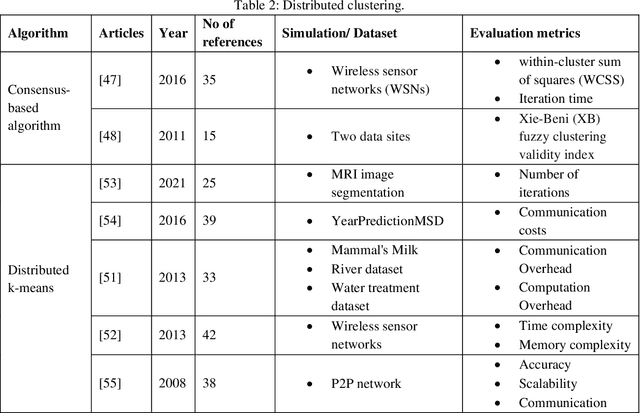
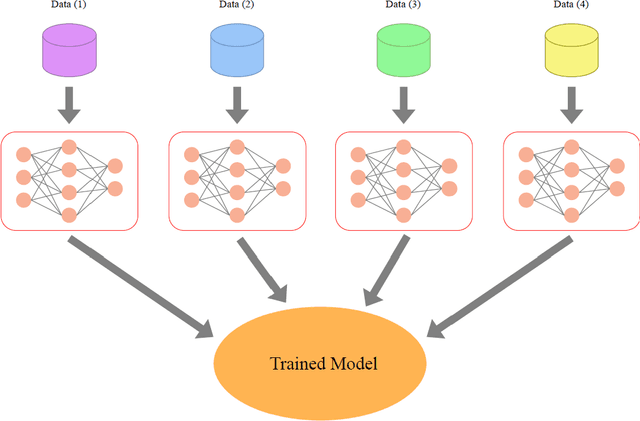
Artificial intelligence has achieved significant success in handling complex tasks in recent years. This success is due to advances in machine learning algorithms and hardware acceleration. In order to obtain more accurate results and solve more complex problems, algorithms must be trained with more data. This huge amount of data could be time-consuming to process and require a great deal of computation. This solution could be achieved by distributing the data and algorithm across several machines, which is known as distributed machine learning. There has been considerable effort put into distributed machine learning algorithms, and different methods have been proposed so far. In this article, we present a comprehensive summary of the current state-of-the-art in the field through the review of these algorithms. We divide this algorithms in classification and clustering (traditional machine learning), deep learning and deep reinforcement learning groups. Distributed deep learning has gained more attention in recent years and most of studies worked on this algorithms. As a result, most of the articles we discussed here belong to this category. Based on our investigation of algorithms, we highlight limitations that should be addressed in future research.
Tracking Most Significant Shifts in Nonparametric Contextual Bandits
Jul 11, 2023
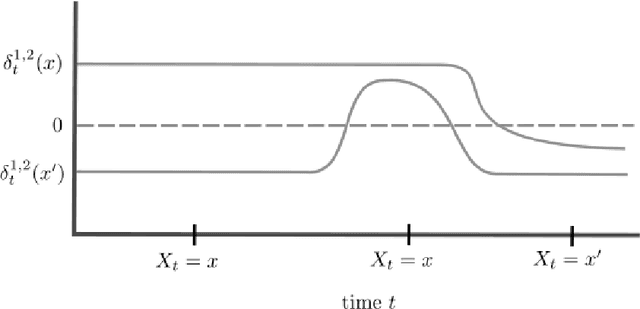
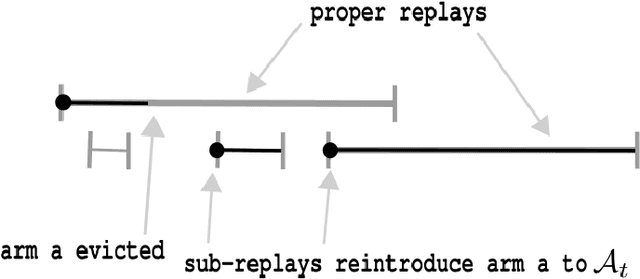
We study nonparametric contextual bandits where Lipschitz mean reward functions may change over time. We first establish the minimax dynamic regret rate in this less understood setting in terms of number of changes $L$ and total-variation $V$, both capturing all changes in distribution over context space, and argue that state-of-the-art procedures are suboptimal in this setting. Next, we tend to the question of an adaptivity for this setting, i.e. achieving the minimax rate without knowledge of $L$ or $V$. Quite importantly, we posit that the bandit problem, viewed locally at a given context $X_t$, should not be affected by reward changes in other parts of context space $\cal X$. We therefore propose a notion of change, which we term experienced significant shifts, that better accounts for locality, and thus counts considerably less changes than $L$ and $V$. Furthermore, similar to recent work on non-stationary MAB (Suk & Kpotufe, 2022), experienced significant shifts only count the most significant changes in mean rewards, e.g., severe best-arm changes relevant to observed contexts. Our main result is to show that this more tolerant notion of change can in fact be adapted to.
Differentially Private Statistical Inference through $β$-Divergence One Posterior Sampling
Jul 11, 2023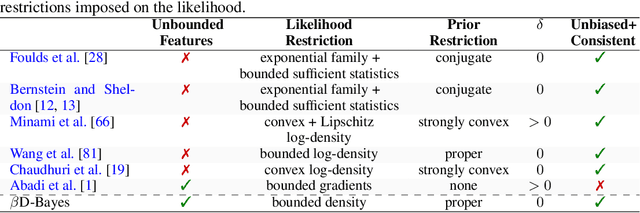
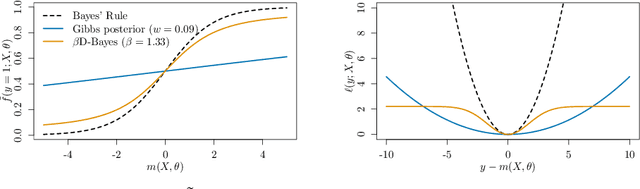
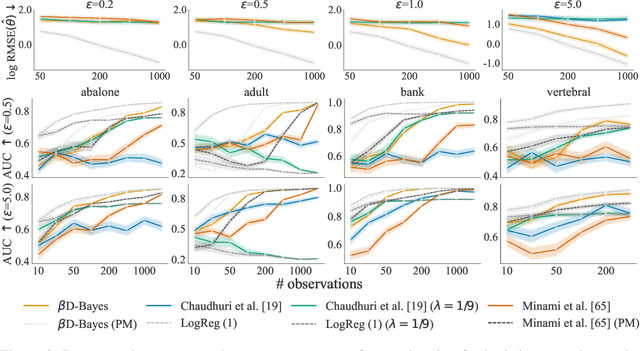
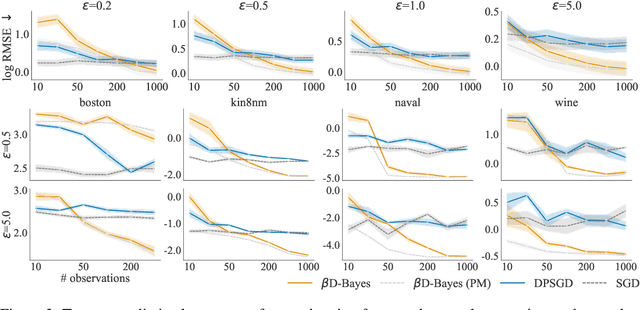
Differential privacy guarantees allow the results of a statistical analysis involving sensitive data to be released without compromising the privacy of any individual taking part. Achieving such guarantees generally requires the injection of noise, either directly into parameter estimates or into the estimation process. Instead of artificially introducing perturbations, sampling from Bayesian posterior distributions has been shown to be a special case of the exponential mechanism, producing consistent, and efficient private estimates without altering the data generative process. The application of current approaches has, however, been limited by their strong bounding assumptions which do not hold for basic models, such as simple linear regressors. To ameliorate this, we propose $\beta$D-Bayes, a posterior sampling scheme from a generalised posterior targeting the minimisation of the $\beta$-divergence between the model and the data generating process. This provides private estimation that is generally applicable without requiring changes to the underlying model and consistently learns the data generating parameter. We show that $\beta$D-Bayes produces more precise inference estimation for the same privacy guarantees, and further facilitates differentially private estimation via posterior sampling for complex classifiers and continuous regression models such as neural networks for the first time.
Deep Probabilistic Movement Primitives with a Bayesian Aggregator
Jul 11, 2023
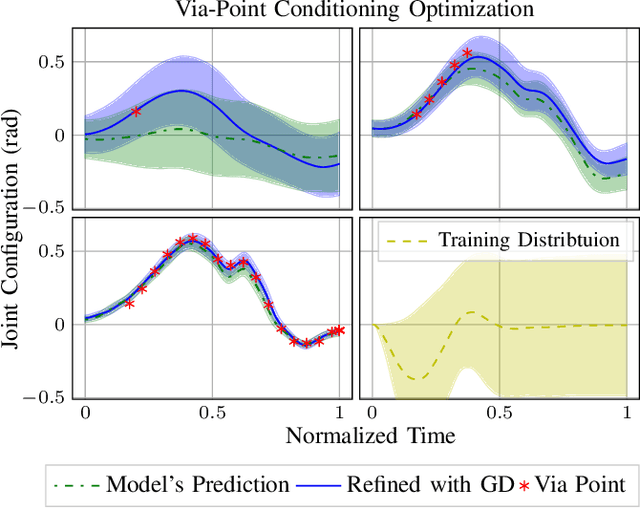
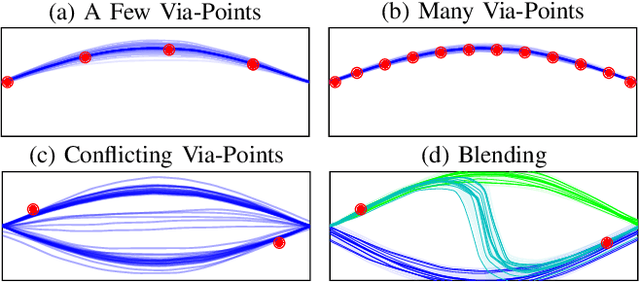
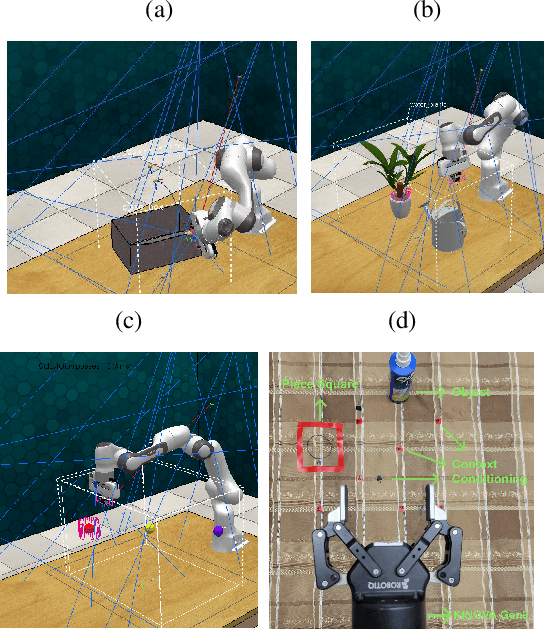
Movement primitives are trainable parametric models that reproduce robotic movements starting from a limited set of demonstrations. Previous works proposed simple linear models that exhibited high sample efficiency and generalization power by allowing temporal modulation of movements (reproducing movements faster or slower), blending (merging two movements into one), via-point conditioning (constraining a movement to meet some particular via-points) and context conditioning (generation of movements based on an observed variable, e.g., position of an object). Previous works have proposed neural network-based motor primitive models, having demonstrated their capacity to perform tasks with some forms of input conditioning or time-modulation representations. However, there has not been a single unified deep motor primitive's model proposed that is capable of all previous operations, limiting neural motor primitive's potential applications. This paper proposes a deep movement primitive architecture that encodes all the operations above and uses a Bayesian context aggregator that allows a more sound context conditioning and blending. Our results demonstrate our approach can scale to reproduce complex motions on a larger variety of input choices compared to baselines while maintaining operations of linear movement primitives provide.
Generalized NOMP for Line Spectrum Estimation and Detection from Coarsely Quantized Samples
Jul 02, 2023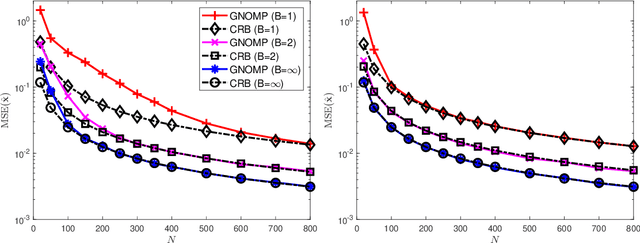
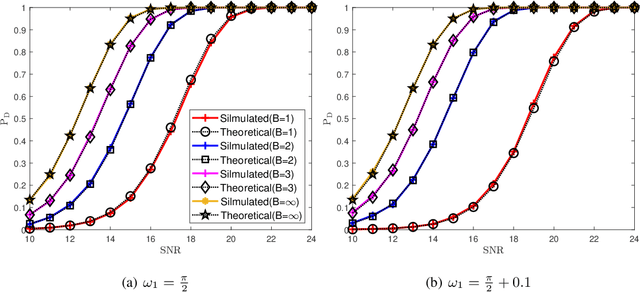
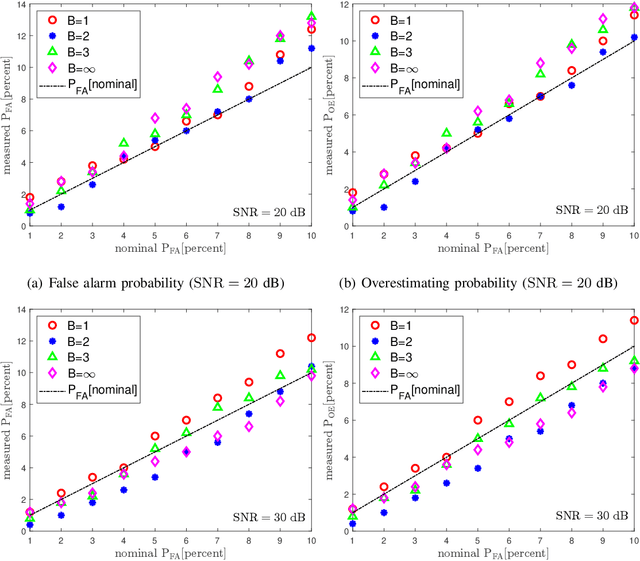
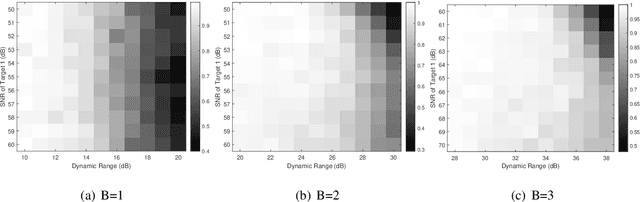
As radar systems accompanied by large numbers of antennas and scale up in bandwidth, the cost and power consumption of high-precision (e.g., 10-12 bits) analog-to-digital converter (ADC) become the limiting factor. As a remedy, line spectral estimation and detection (LSE\&D) from low resolution (e.g., 1-4 bits) quantization has been gradually drawn attention in recent years. As low resolution quantization reduces the dynamic range (DR) of the receiver, the theoretical detection probabilities for the multiple targets (especially for the weakest target) are analyzed, which reveals the effects of low resolution on weak signal detection and provides the guidelines for system design. The computation complexities of current methods solve the line spectral estimation from coarsely quantized samples are often high. In this paper, we propose a fast generalized Newtonized orthogonal matching pursuit (GNOMP) which has superior estimation accuracy and maintains a constant false alarm rate (CFAR) behaviour. Besides, such an approach are easily extended to handle the other measurement scenarios such as sign measurements from time-varying thresholds, compressive setting, multisnapshot setting, multidimensional setting and unknown noise variance. Substantial numerical simulations are conducted to demonstrate the effectiveness of GNOMP in terms of estimating accuracy, detection probability and running time. Besides, real data are also provided to demonstrate the effectiveness of the GNOMP.