 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Low bit rate binaural link for improved ultra low-latency low-complexity multichannel speech enhancement in Hearing Aids
Jul 17, 2023
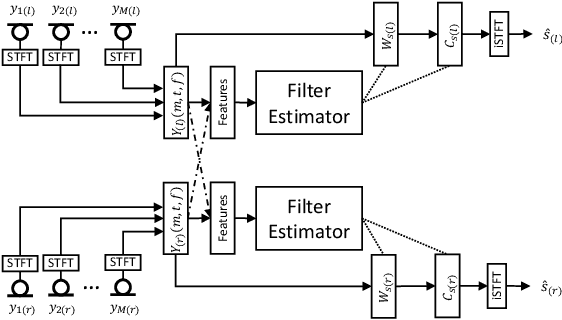
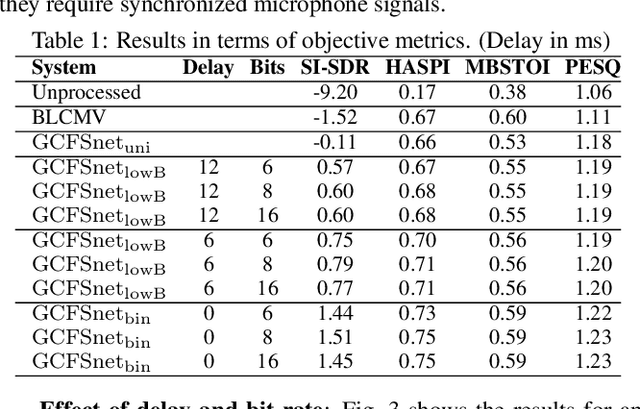
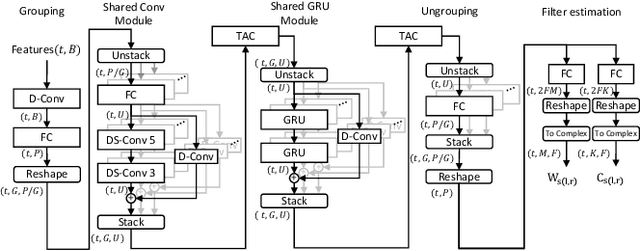

Speech enhancement in hearing aids is a challenging task since the hardware limits the number of possible operations and the latency needs to be in the range of only a few milliseconds. We propose a deep-learning model compatible with these limitations, which we refer to as Group-Communication Filter-and-Sum Network (GCFSnet). GCFSnet is a causal multiple-input single output enhancement model using filter-and-sum processing in the time-frequency domain and a multi-frame deep post filter. All filters are complex-valued and are estimated by a deep-learning model using weight-sharing through Group Communication and quantization-aware training for reducing model size and computational footprint. For a further increase in performance, a low bit rate binaural link for delayed binaural features is proposed to use binaural information while retaining a latency of 2ms. The performance of an oracle binaural LCMV beamformer in non-low-latency configuration can be matched even by a unilateral configuration of the GCFSnet in terms of objective metrics.
Forward Laplacian: A New Computational Framework for Neural Network-based Variational Monte Carlo
Jul 17, 2023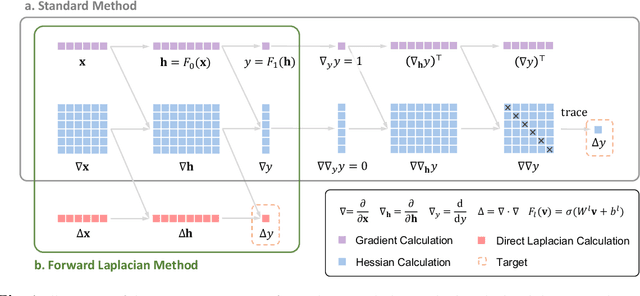
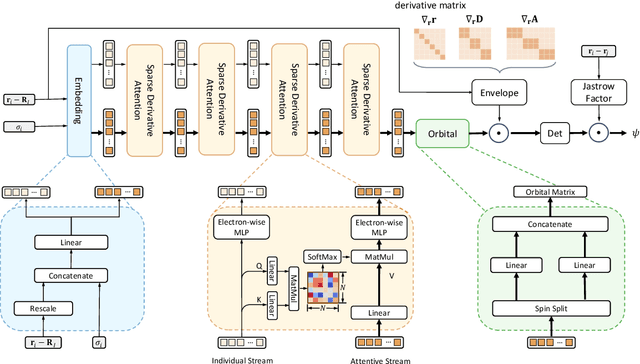
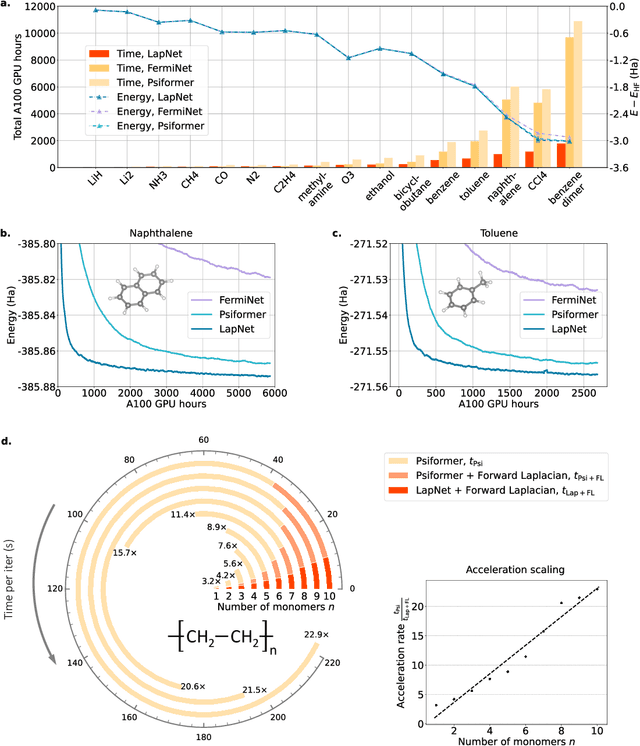
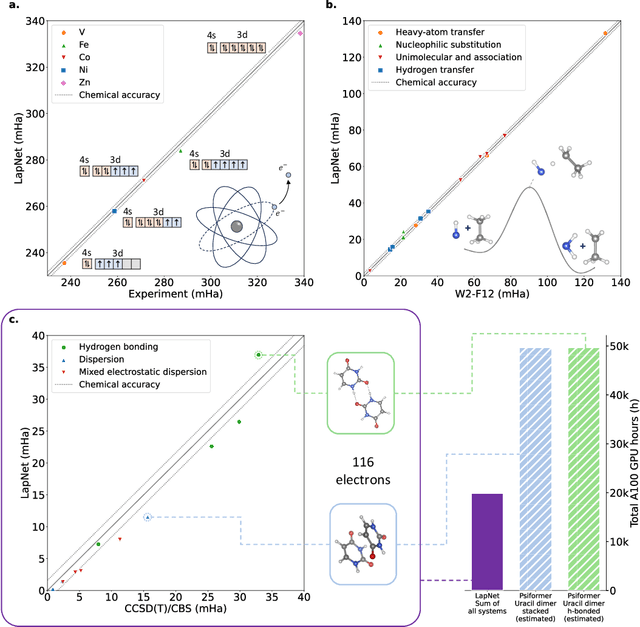
Neural network-based variational Monte Carlo (NN-VMC) has emerged as a promising cutting-edge technique of ab initio quantum chemistry. However, the high computational cost of existing approaches hinders their applications in realistic chemistry problems. Here, we report the development of a new NN-VMC method that achieves a remarkable speed-up by more than one order of magnitude, thereby greatly extending the applicability of NN-VMC to larger systems. Our key design is a novel computational framework named Forward Laplacian, which computes the Laplacian associated with neural networks, the bottleneck of NN-VMC, through an efficient forward propagation process. We then demonstrate that Forward Laplacian is not only versatile but also facilitates more developments of acceleration methods across various aspects, including optimization for sparse derivative matrix and efficient neural network design. Empirically, our approach enables NN-VMC to investigate a broader range of atoms, molecules and chemical reactions for the first time, providing valuable references to other ab initio methods. The results demonstrate a great potential in applying deep learning methods to solve general quantum mechanical problems.
Measuring Faithfulness in Chain-of-Thought Reasoning
Jul 17, 2023

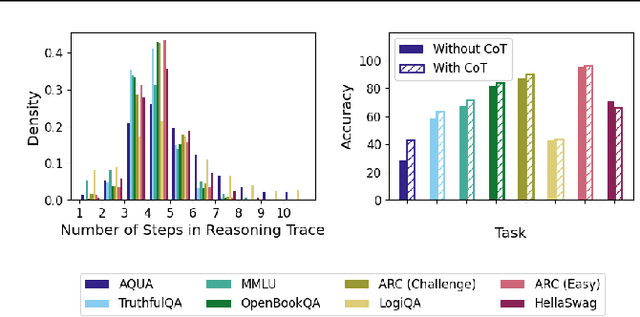
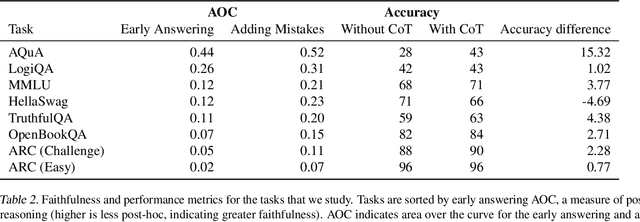
Large language models (LLMs) perform better when they produce step-by-step, "Chain-of-Thought" (CoT) reasoning before answering a question, but it is unclear if the stated reasoning is a faithful explanation of the model's actual reasoning (i.e., its process for answering the question). We investigate hypotheses for how CoT reasoning may be unfaithful, by examining how the model predictions change when we intervene on the CoT (e.g., by adding mistakes or paraphrasing it). Models show large variation across tasks in how strongly they condition on the CoT when predicting their answer, sometimes relying heavily on the CoT and other times primarily ignoring it. CoT's performance boost does not seem to come from CoT's added test-time compute alone or from information encoded via the particular phrasing of the CoT. As models become larger and more capable, they produce less faithful reasoning on most tasks we study. Overall, our results suggest that CoT can be faithful if the circumstances such as the model size and task are carefully chosen.
Synthetic Lagrangian Turbulence by Generative Diffusion Models
Jul 17, 2023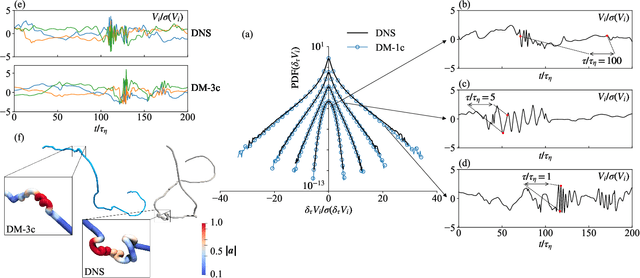
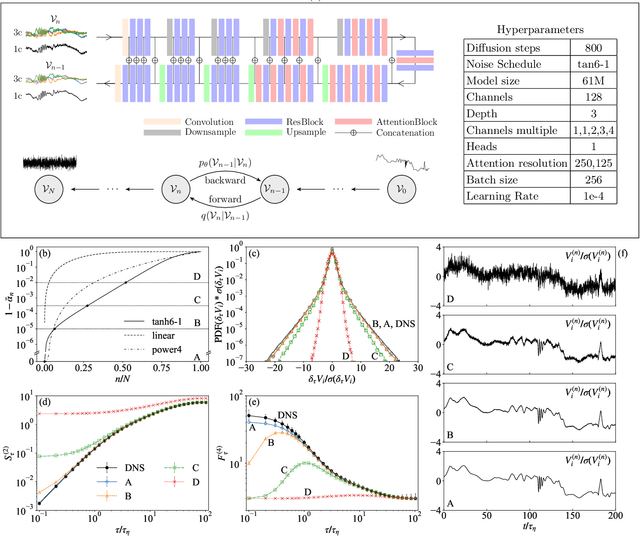
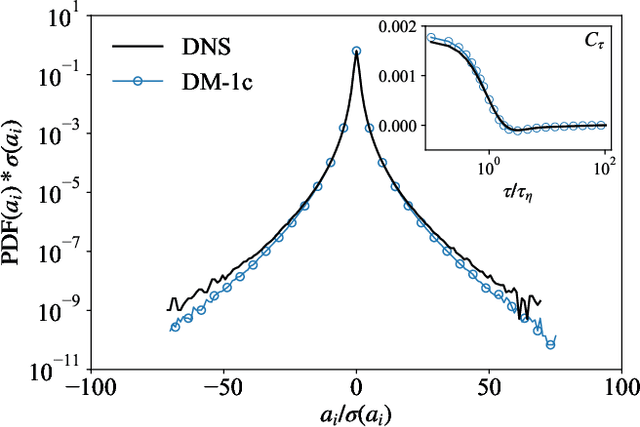
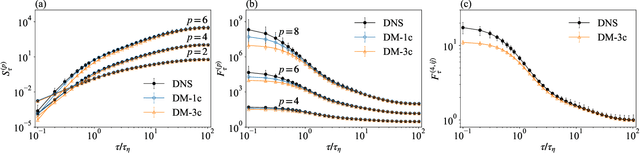
Lagrangian turbulence lies at the core of numerous applied and fundamental problems related to the physics of dispersion and mixing in engineering, bio-fluids, atmosphere, oceans, and astrophysics. Despite exceptional theoretical, numerical, and experimental efforts conducted over the past thirty years, no existing models are capable of faithfully reproducing statistical and topological properties exhibited by particle trajectories in turbulence. We propose a machine learning approach, based on a state-of-the-art Diffusion Model, to generate single-particle trajectories in three-dimensional turbulence at high Reynolds numbers, thereby bypassing the need for direct numerical simulations or experiments to obtain reliable Lagrangian data. Our model demonstrates the ability to quantitatively reproduce all relevant statistical benchmarks over the entire range of time scales, including the presence of fat tails distribution for the velocity increments, anomalous power law, and enhancement of intermittency around the dissipative scale. The model exhibits good generalizability for extreme events, achieving unprecedented intensity and rarity. This paves the way for producing synthetic high-quality datasets for pre-training various downstream applications of Lagrangian turbulence.
SAM-DA: UAV Tracks Anything at Night with SAM-Powered Domain Adaptation
Jul 03, 2023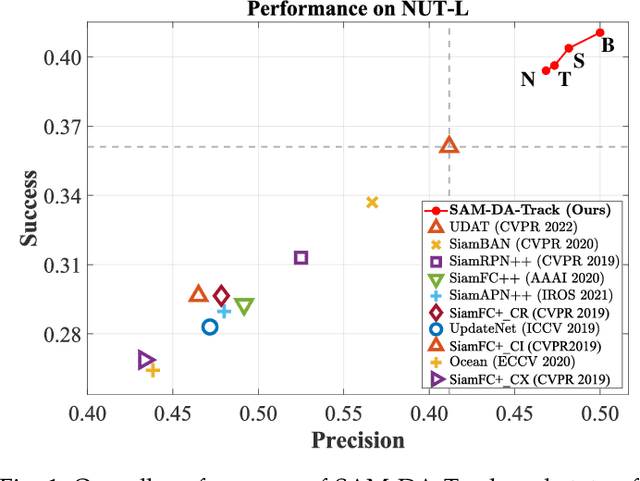

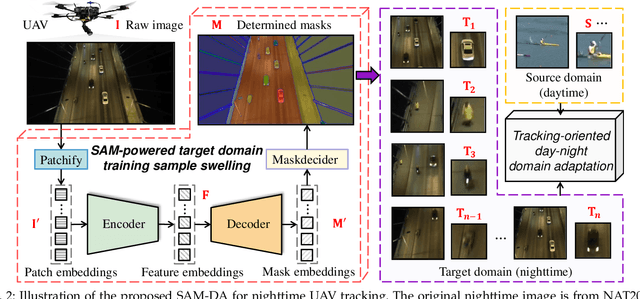

Domain adaptation (DA) has demonstrated significant promise for real-time nighttime unmanned aerial vehicle (UAV) tracking. However, the state-of-the-art (SOTA) DA still lacks the potential object with accurate pixel-level location and boundary to generate the high-quality target domain training sample. This key issue constrains the transfer learning of the real-time daytime SOTA trackers for challenging nighttime UAV tracking. Recently, the notable Segment Anything Model (SAM) has achieved remarkable zero-shot generalization ability to discover abundant potential objects due to its huge data-driven training approach. To solve the aforementioned issue, this work proposes a novel SAM-powered DA framework for real-time nighttime UAV tracking, i.e., SAM-DA. Specifically, an innovative SAM-powered target domain training sample swelling is designed to determine enormous high-quality target domain training samples from every single raw nighttime image. This novel one-to-many method significantly expands the high-quality target domain training sample for DA. Comprehensive experiments on extensive nighttime UAV videos prove the robustness and domain adaptability of SAM-DA for nighttime UAV tracking. Especially, compared to the SOTA DA, SAM-DA can achieve better performance with fewer raw nighttime images, i.e., the fewer-better training. This economized training approach facilitates the quick validation and deployment of algorithms for UAVs. The code is available at https://github.com/vision4robotics/SAM-DA.
Temporal Label-Refinement for Weakly-Supervised Audio-Visual Event Localization
Jul 19, 2023Audio-Visual Event Localization (AVEL) is the task of temporally localizing and classifying \emph{audio-visual events}, i.e., events simultaneously visible and audible in a video. In this paper, we solve AVEL in a weakly-supervised setting, where only video-level event labels (their presence/absence, but not their locations in time) are available as supervision for training. Our idea is to use a base model to estimate labels on the training data at a finer temporal resolution than at the video level and re-train the model with these labels. I.e., we determine the subset of labels for each \emph{slice} of frames in a training video by (i) replacing the frames outside the slice with those from a second video having no overlap in video-level labels, and (ii) feeding this synthetic video into the base model to extract labels for just the slice in question. To handle the out-of-distribution nature of our synthetic videos, we propose an auxiliary objective for the base model that induces more reliable predictions of the localized event labels as desired. Our three-stage pipeline outperforms several existing AVEL methods with no architectural changes and improves performance on a related weakly-supervised task as well.
Dynamic Observation Policies in Observation Cost-Sensitive Reinforcement Learning
Jul 05, 2023Reinforcement learning (RL) has been shown to learn sophisticated control policies for complex tasks including games, robotics, heating and cooling systems and text generation. The action-perception cycle in RL, however, generally assumes that a measurement of the state of the environment is available at each time step without a cost. In applications such as deep-sea and planetary robot exploration, materials design and medicine, however, there can be a high cost associated with measuring, or even approximating, the state of the environment. In this paper, we survey the recently growing literature that adopts the perspective that an RL agent might not need, or even want, a costly measurement at each time step. Within this context, we propose the Deep Dynamic Multi-Step Observationless Agent (DMSOA), contrast it with the literature and empirically evaluate it on OpenAI gym and Atari Pong environments. Our results, show that DMSOA learns a better policy with fewer decision steps and measurements than the considered alternative from the literature.
Set Learning for Accurate and Calibrated Models
Jul 05, 2023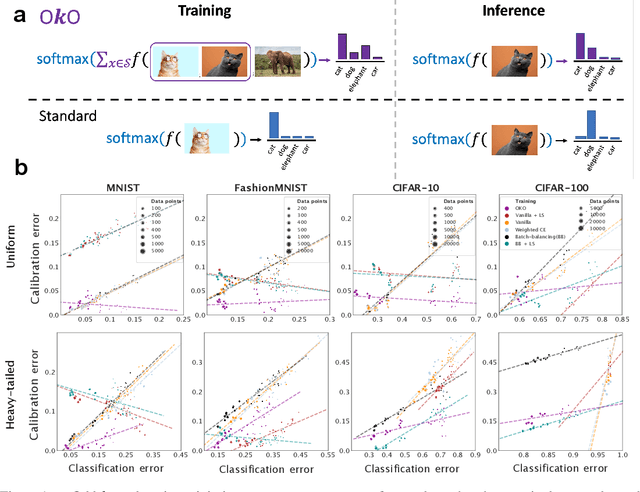
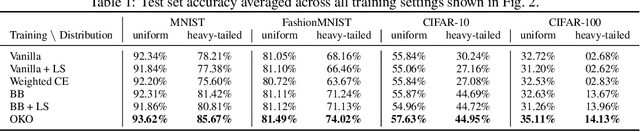
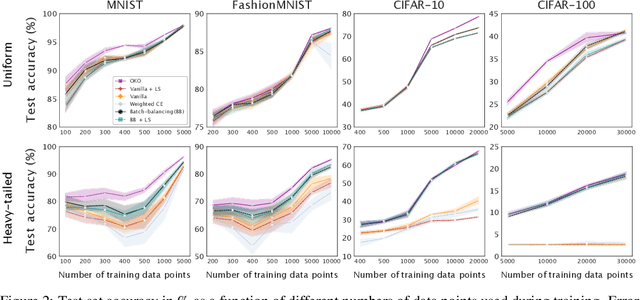
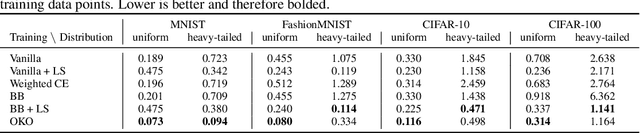
Model overconfidence and poor calibration are common in machine learning and difficult to account for when applying standard empirical risk minimization. In this work, we propose a novel method to alleviate these problems that we call odd-$k$-out learning (OKO), which minimizes the cross-entropy error for sets rather than for single examples. This naturally allows the model to capture correlations across data examples and achieves both better accuracy and calibration, especially in limited training data and class-imbalanced regimes. Perhaps surprisingly, OKO often yields better calibration even when training with hard labels and dropping any additional calibration parameter tuning, such as temperature scaling. We provide theoretical justification, establishing that OKO naturally yields better calibration, and provide extensive experimental analyses that corroborate our theoretical findings. We emphasize that OKO is a general framework that can be easily adapted to many settings and the trained model can be applied to single examples at inference time, without introducing significant run-time overhead or architecture changes.
From NeurODEs to AutoencODEs: a mean-field control framework for width-varying Neural Networks
Jul 05, 2023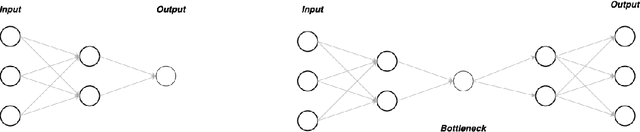

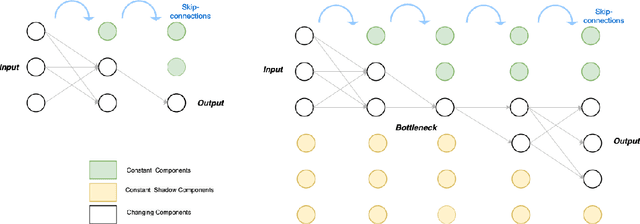
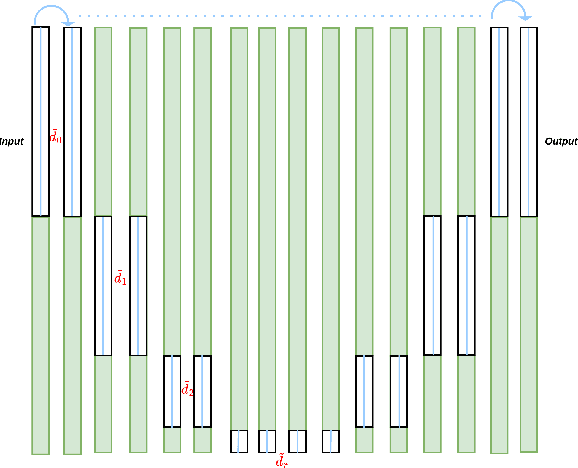
In our work, we build upon the established connection between Residual Neural Networks (ResNets) and continuous-time control systems known as NeurODEs. By construction, NeurODEs have been limited to constant-width layers, making them unsuitable for modeling deep learning architectures with width-varying layers. In this paper, we propose a continuous-time Autoencoder, which we call AutoencODE, and we extend to this case the mean-field control framework already developed for usual NeurODEs. In this setting, we tackle the case of low Tikhonov regularization, resulting in potentially non-convex cost landscapes. While the global results obtained for high Tikhonov regularization may not hold globally, we show that many of them can be recovered in regions where the loss function is locally convex. Inspired by our theoretical findings, we develop a training method tailored to this specific type of Autoencoders with residual connections, and we validate our approach through numerical experiments conducted on various examples.
Do DL models and training environments have an impact on energy consumption?
Jul 18, 2023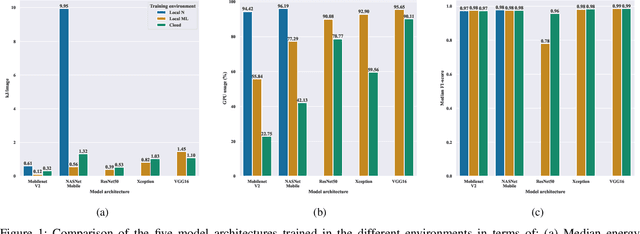
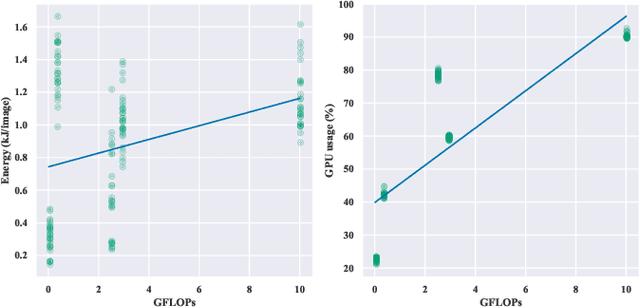
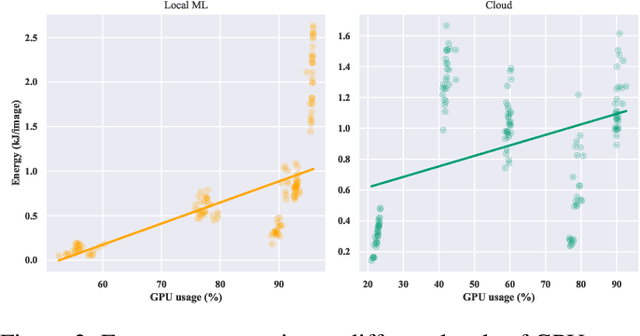
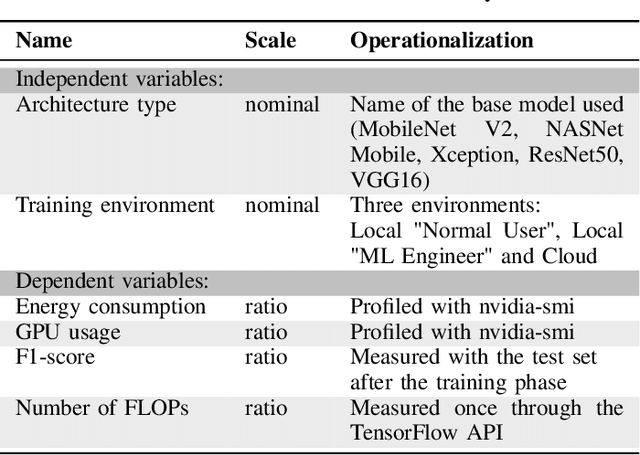
Current research in the computer vision field mainly focuses on improving Deep Learning (DL) correctness and inference time performance. However, there is still little work on the huge carbon footprint that has training DL models. This study aims to analyze the impact of the model architecture and training environment when training greener computer vision models. We divide this goal into two research questions. First, we analyze the effects of model architecture on achieving greener models while keeping correctness at optimal levels. Second, we study the influence of the training environment on producing greener models. To investigate these relationships, we collect multiple metrics related to energy efficiency and model correctness during the models' training. Then, we outline the trade-offs between the measured energy efficiency and the models' correctness regarding model architecture, and their relationship with the training environment. We conduct this research in the context of a computer vision system for image classification. In conclusion, we show that selecting the proper model architecture and training environment can reduce energy consumption dramatically (up to 98.83%) at the cost of negligible decreases in correctness. Also, we find evidence that GPUs should scale with the models' computational complexity for better energy efficiency.