 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Incorporating Structured Sentences with Time-enhanced BERT for Fully-inductive Temporal Relation Prediction
Apr 10, 2023

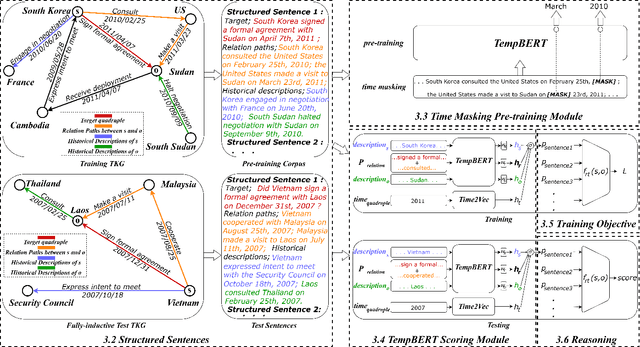
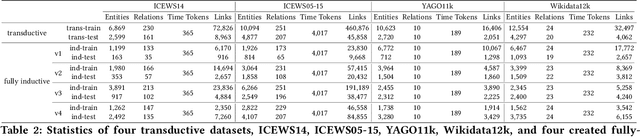
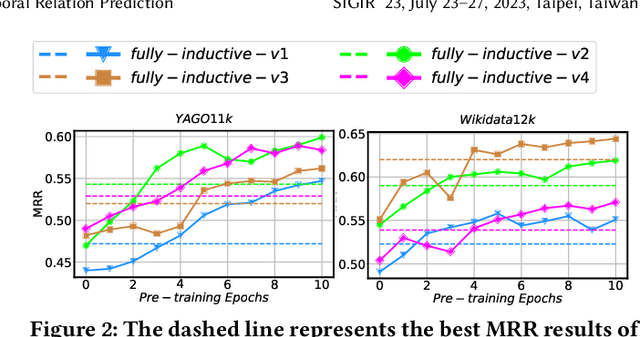
Temporal relation prediction in incomplete temporal knowledge graphs (TKGs) is a popular temporal knowledge graph completion (TKGC) problem in both transductive and inductive settings. Traditional embedding-based TKGC models (TKGE) rely on structured connections and can only handle a fixed set of entities, i.e., the transductive setting. In the inductive setting where test TKGs contain emerging entities, the latest methods are based on symbolic rules or pre-trained language models (PLMs). However, they suffer from being inflexible and not time-specific, respectively. In this work, we extend the fully-inductive setting, where entities in the training and test sets are totally disjoint, into TKGs and take a further step towards a more flexible and time-sensitive temporal relation prediction approach SST-BERT, incorporating Structured Sentences with Time-enhanced BERT. Our model can obtain the entity history and implicitly learn rules in the semantic space by encoding structured sentences, solving the problem of inflexibility. We propose to use a time masking MLM task to pre-train BERT in a corpus rich in temporal tokens specially generated for TKGs, enhancing the time sensitivity of SST-BERT. To compute the probability of occurrence of a target quadruple, we aggregate all its structured sentences from both temporal and semantic perspectives into a score. Experiments on the transductive datasets and newly generated fully-inductive benchmarks show that SST-BERT successfully improves over state-of-the-art baselines.
Mitosis Detection from Partial Annotation by Dataset Generation via Frame-Order Flipping
Jul 09, 2023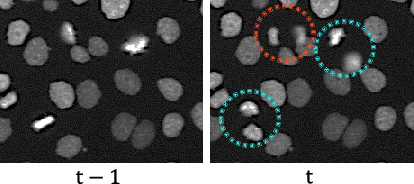
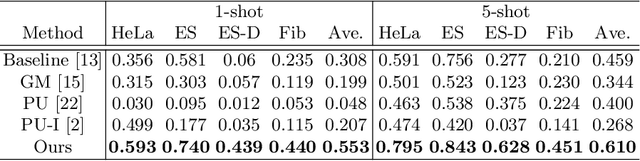
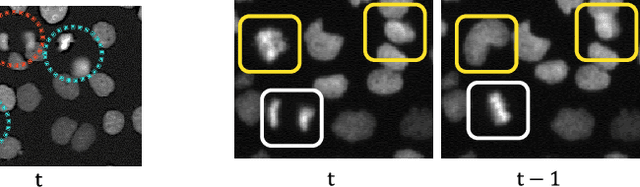
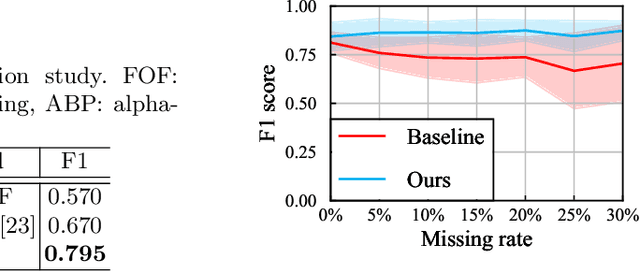
Detection of mitosis events plays an important role in biomedical research. Deep-learning-based mitosis detection methods have achieved outstanding performance with a certain amount of labeled data. However, these methods require annotations for each imaging condition. Collecting labeled data involves time-consuming human labor. In this paper, we propose a mitosis detection method that can be trained with partially annotated sequences. The base idea is to generate a fully labeled dataset from the partial labels and train a mitosis detection model with the generated dataset. First, we generate an image pair not containing mitosis events by frame-order flipping. Then, we paste mitosis events to the image pair by alpha-blending pasting and generate a fully labeled dataset. We demonstrate the performance of our method on four datasets, and we confirm that our method outperforms other comparisons which use partially labeled sequences.
Length of Stay prediction for Hospital Management using Domain Adaptation
Jun 29, 2023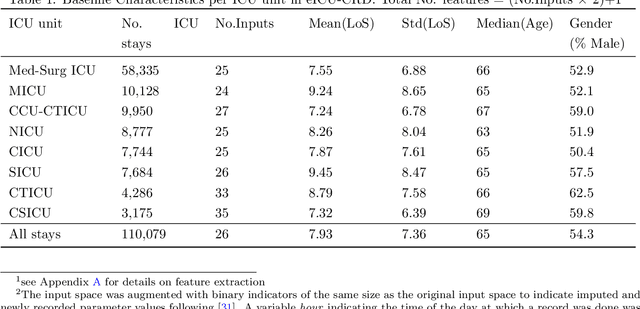
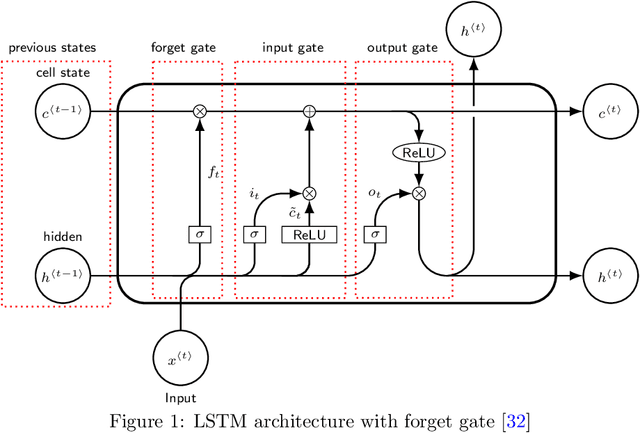
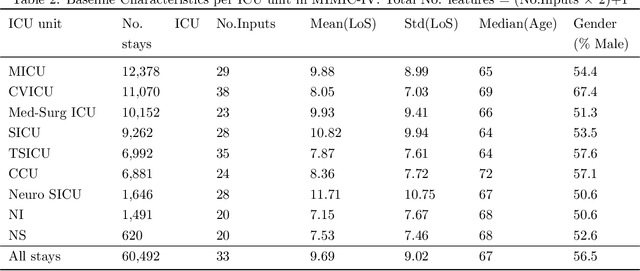
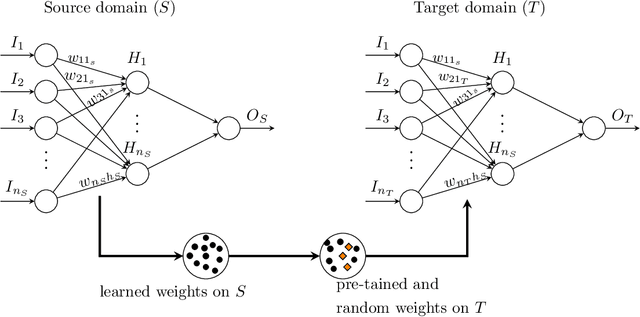
Inpatient length of stay (LoS) is an important managerial metric which if known in advance can be used to efficiently plan admissions, allocate resources and improve care. Using historical patient data and machine learning techniques, LoS prediction models can be developed. Ethically, these models can not be used for patient discharge in lieu of unit heads but are of utmost necessity for hospital management systems in charge of effective hospital planning. Therefore, the design of the prediction system should be adapted to work in a true hospital setting. In this study, we predict early hospital LoS at the granular level of admission units by applying domain adaptation to leverage information learned from a potential source domain. Time-varying data from 110,079 and 60,492 patient stays to 8 and 9 intensive care units were respectively extracted from eICU-CRD and MIMIC-IV. These were fed into a Long-Short Term Memory and a Fully connected network to train a source domain model, the weights of which were transferred either partially or fully to initiate training in target domains. Shapley Additive exPlanations (SHAP) algorithms were used to study the effect of weight transfer on model explanability. Compared to the benchmark, the proposed weight transfer model showed statistically significant gains in prediction accuracy (between 1% and 5%) as well as computation time (up to 2hrs) for some target domains. The proposed method thus provides an adapted clinical decision support system for hospital management that can ease processes of data access via ethical committee, computation infrastructures and time.
Spatiotemporal Besov Priors for Bayesian Inverse Problems
Jun 28, 2023
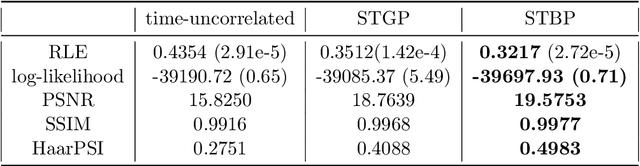
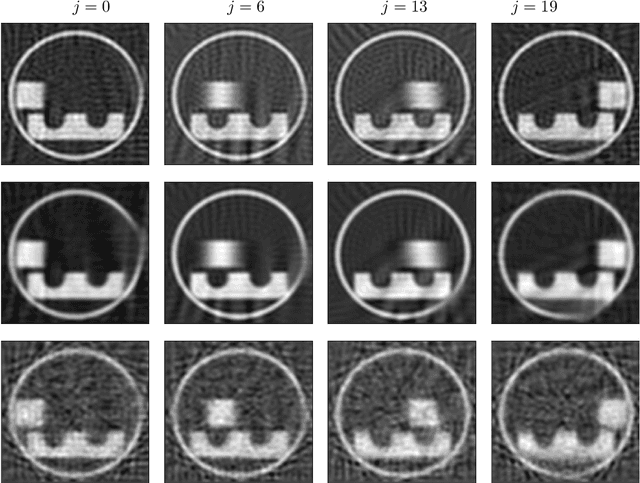
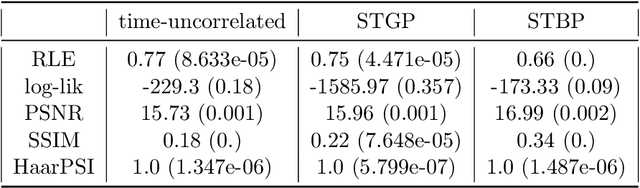
Fast development in science and technology has driven the need for proper statistical tools to capture special data features such as abrupt changes or sharp contrast. Many applications in the data science seek spatiotemporal reconstruction from a sequence of time-dependent objects with discontinuity or singularity, e.g. dynamic computerized tomography (CT) images with edges. Traditional methods based on Gaussian processes (GP) may not provide satisfactory solutions since they tend to offer over-smooth prior candidates. Recently, Besov process (BP) defined by wavelet expansions with random coefficients has been proposed as a more appropriate prior for this type of Bayesian inverse problems. While BP outperforms GP in imaging analysis to produce edge-preserving reconstructions, it does not automatically incorporate temporal correlation inherited in the dynamically changing images. In this paper, we generalize BP to the spatiotemporal domain (STBP) by replacing the random coefficients in the series expansion with stochastic time functions following Q-exponential process which governs the temporal correlation strength. Mathematical and statistical properties about STBP are carefully studied. A white-noise representation of STBP is also proposed to facilitate the point estimation through maximum a posterior (MAP) and the uncertainty quantification (UQ) by posterior sampling. Two limited-angle CT reconstruction examples and a highly non-linear inverse problem involving Navier-Stokes equation are used to demonstrate the advantage of the proposed STBP in preserving spatial features while accounting for temporal changes compared with the classic STGP and a time-uncorrelated approach.
HCLAS-X: Hierarchical and Cascaded Lyrics Alignment System Using Multimodal Cross-Correlation
Jul 10, 2023In this work, we address the challenge of lyrics alignment, which involves aligning the lyrics and vocal components of songs. This problem requires the alignment of two distinct modalities, namely text and audio. To overcome this challenge, we propose a model that is trained in a supervised manner, utilizing the cross-correlation matrix of latent representations between vocals and lyrics. Our system is designed in a hierarchical and cascaded manner. It predicts synced time first on a sentence-level and subsequently on a word-level. This design enables the system to process long sequences, as the cross-correlation uses quadratic memory with respect to sequence length. In our experiments, we demonstrate that our proposed system achieves a significant improvement in mean average error, showcasing its robustness in comparison to the previous state-of-the-art model. Additionally, we conduct a qualitative analysis of the system after successfully deploying it in several music streaming services.
RLTF: Reinforcement Learning from Unit Test Feedback
Jul 10, 2023
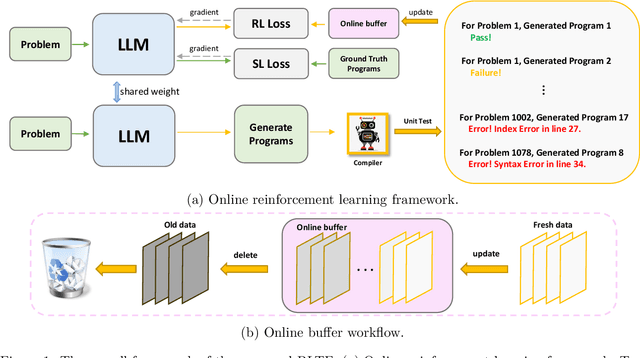

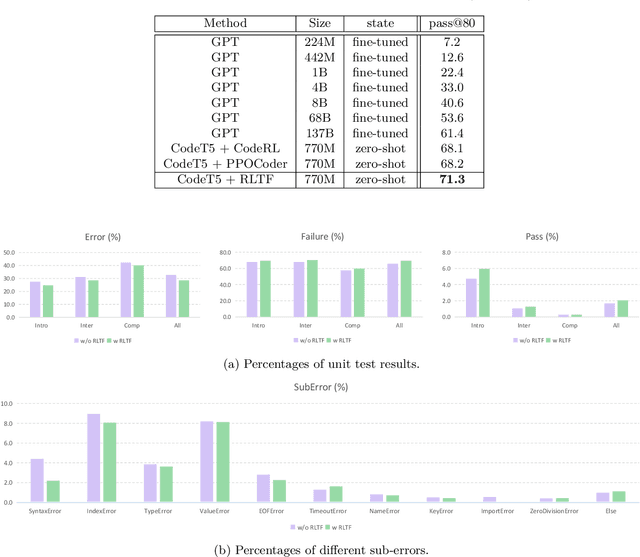
The goal of program synthesis, or code generation, is to generate executable code based on given descriptions. Recently, there has been an increasing number of studies employing reinforcement learning (RL) to improve the performance of large language models (LLMs) for code. However, these RL methods have only used offline frameworks, limiting their exploration of new sample spaces. Additionally, current approaches that utilize unit test signals are rather simple, not accounting for specific error locations within the code. To address these issues, we proposed RLTF, i.e., Reinforcement Learning from Unit Test Feedback, a novel online RL framework with unit test feedback of multi-granularity for refining code LLMs. Our approach generates data in real-time during training and simultaneously utilizes fine-grained feedback signals to guide the model towards producing higher-quality code. Extensive experiments show that RLTF achieves state-of-the-art performance on the APPS and the MBPP benchmarks. Our code can be found at: https://github.com/Zyq-scut/RLTF.
Optimal Robot Path Planning In a Collaborative Human-Robot Team with Intermittent Human Availability
Jul 10, 2023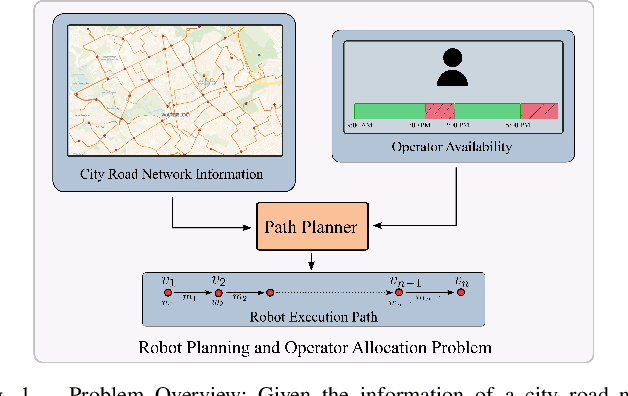
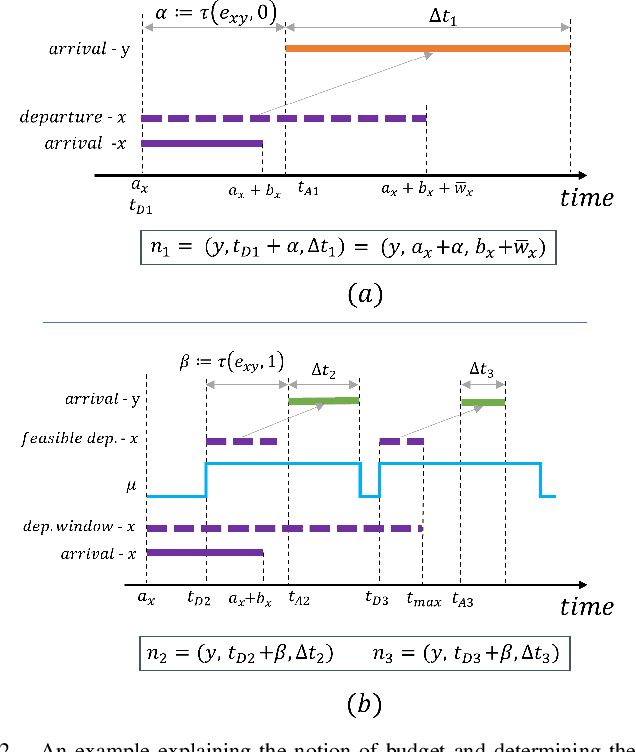
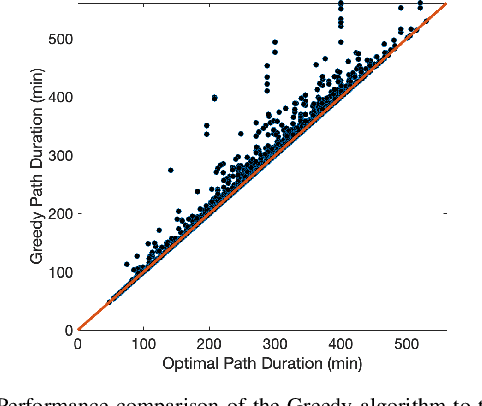
This paper presents a solution for the problem of optimal planning for a robot in a collaborative human-robot team, where the human supervisor is intermittently available to assist the robot in completing tasks more quickly. Specifically, we address the challenge of computing the fastest path between two configurations in an environment with time constraints on how long the robot can wait for assistance. To solve this problem, we propose a novel approach that utilizes the concepts of budget and critical departure times, which enables us to obtain optimal solutions while scaling to larger problem instances than existing methods. We demonstrate the effectiveness of our approach by comparing it with several baseline algorithms on a city road network and analyzing the quality of the solutions obtained. Our work contributes to the field of robot planning by addressing the critical issue of incorporating human assistance and environmental restrictions, which has significant implications for real-world applications.
4D Agnostic Real-Time Facial Animation Pipeline for Desktop Scenarios
Apr 06, 2023


We present a high-precision real-time facial animation pipeline suitable for animators to use on their desktops. This pipeline is about to be launched in FACEGOOD's Avatary\footnote{https://www.avatary.com/} software, which will accelerate animators' productivity. The pipeline differs from professional head-mounted facial capture solutions in that it only requires the use of a consumer-grade 3D camera on the desk to achieve high-precision real-time facial capture. The system enables animators to create high-quality facial animations with ease and speed, while reducing the cost and complexity of traditional facial capture solutions. Our approach has the potential to revolutionize the way facial animation is done in the entertainment industry.
Deep Learning Method for Cell-Wise Object Tracking, Velocity Estimation and Projection of Sensor Data over Time
Jun 18, 2023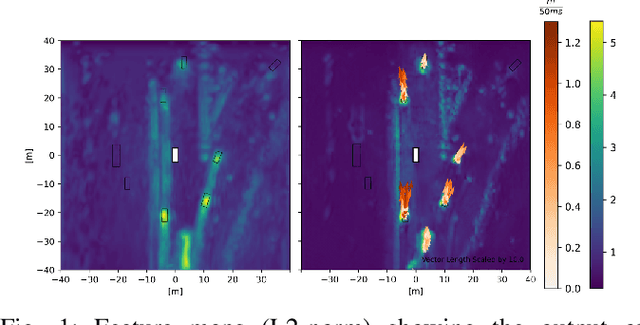
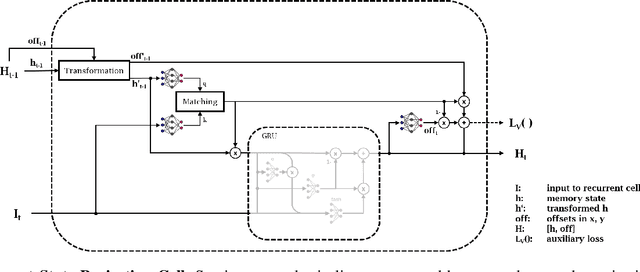
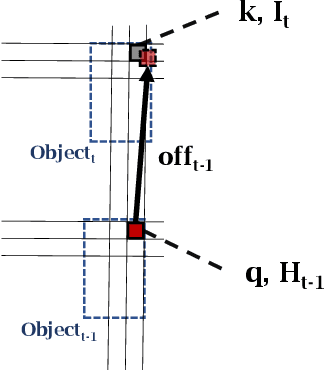
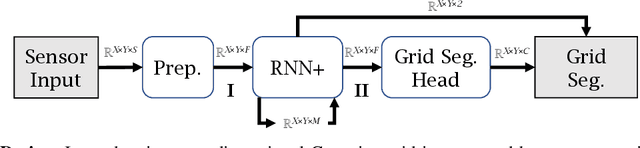
Current Deep Learning methods for environment segmentation and velocity estimation rely on Convolutional Recurrent Neural Networks to exploit spatio-temporal relationships within obtained sensor data. These approaches derive scene dynamics implicitly by correlating novel input and memorized data utilizing ConvNets. We show how ConvNets suffer from architectural restrictions for this task. Based on these findings, we then provide solutions to various issues on exploiting spatio-temporal correlations in a sequence of sensor recordings by presenting a novel Recurrent Neural Network unit utilizing Transformer mechanisms. Within this unit, object encodings are tracked across consecutive frames by correlating key-query pairs derived from sensor inputs and memory states, respectively. We then use resulting tracking patterns to obtain scene dynamics and regress velocities. In a last step, the memory state of the Recurrent Neural Network is projected based on extracted velocity estimates to resolve aforementioned spatio-temporal misalignment.
FreeCOS: Self-Supervised Learning from Fractals and Unlabeled Images for Curvilinear Object Segmentation
Jul 14, 2023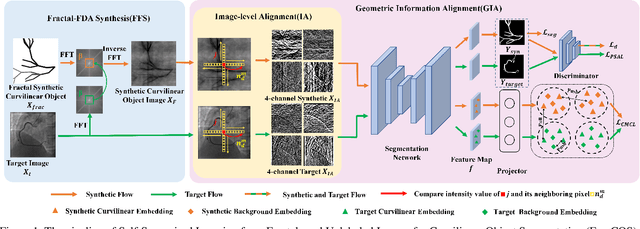
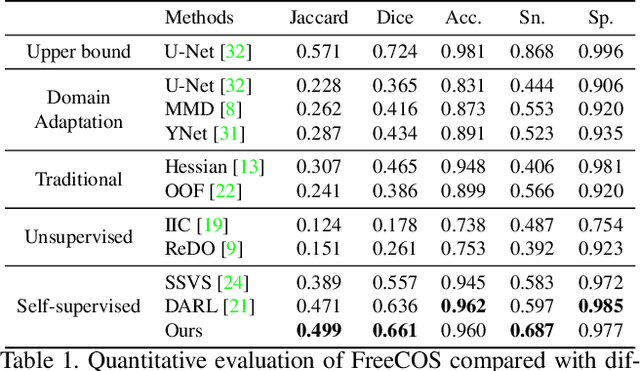
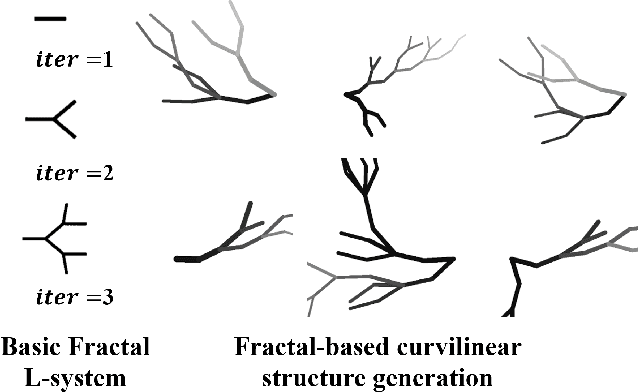
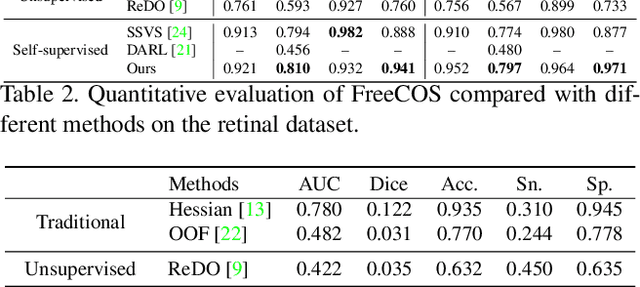
Curvilinear object segmentation is critical for many applications. However, manually annotating curvilinear objects is very time-consuming and error-prone, yielding insufficiently available annotated datasets for existing supervised methods and domain adaptation methods. This paper proposes a self-supervised curvilinear object segmentation method that learns robust and distinctive features from fractals and unlabeled images (FreeCOS). The key contributions include a novel Fractal-FDA synthesis (FFS) module and a geometric information alignment (GIA) approach. FFS generates curvilinear structures based on the parametric Fractal L-system and integrates the generated structures into unlabeled images to obtain synthetic training images via Fourier Domain Adaptation. GIA reduces the intensity differences between the synthetic and unlabeled images by comparing the intensity order of a given pixel to the values of its nearby neighbors. Such image alignment can explicitly remove the dependency on absolute intensity values and enhance the inherent geometric characteristics which are common in both synthetic and real images. In addition, GIA aligns features of synthetic and real images via the prediction space adaptation loss (PSAL) and the curvilinear mask contrastive loss (CMCL). Extensive experimental results on four public datasets, i.e., XCAD, DRIVE, STARE and CrackTree demonstrate that our method outperforms the state-of-the-art unsupervised methods, self-supervised methods and traditional methods by a large margin. The source code of this work is available at https://github.com/TY-Shi/FreeCOS.