 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Event Camera-based Visual Odometry for Dynamic Motion Tracking of a Legged Robot Using Adaptive Time Surface
May 15, 2023

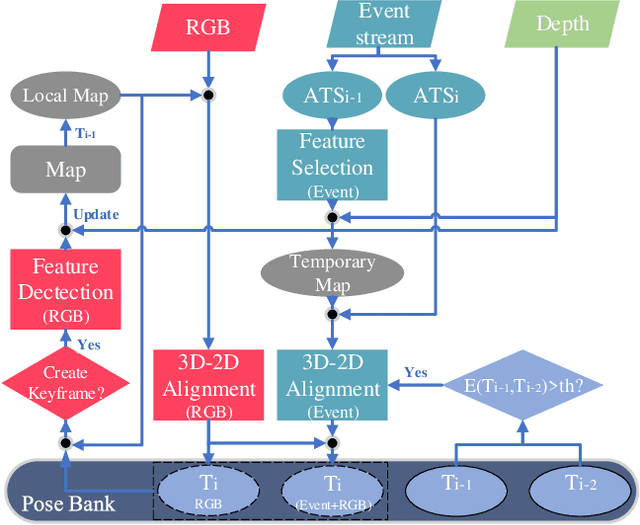
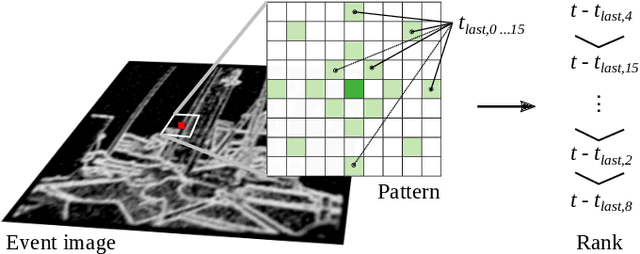

Our paper proposes a direct sparse visual odometry method that combines event and RGB-D data to estimate the pose of agile-legged robots during dynamic locomotion and acrobatic behaviors. Event cameras offer high temporal resolution and dynamic range, which can eliminate the issue of blurred RGB images during fast movements. This unique strength holds a potential for accurate pose estimation of agile-legged robots, which has been a challenging problem to tackle. Our framework leverages the benefits of both RGB-D and event cameras to achieve robust and accurate pose estimation, even during dynamic maneuvers such as jumping and landing a quadruped robot, the Mini-Cheetah. Our major contributions are threefold: Firstly, we introduce an adaptive time surface (ATS) method that addresses the whiteout and blackout issue in conventional time surfaces by formulating pixel-wise decay rates based on scene complexity and motion speed. Secondly, we develop an effective pixel selection method that directly samples from event data and applies sample filtering through ATS, enabling us to pick pixels on distinct features. Lastly, we propose a nonlinear pose optimization formula that simultaneously performs 3D-2D alignment on both RGB-based and event-based maps and images, allowing the algorithm to fully exploit the benefits of both data streams. We extensively evaluate the performance of our framework on both public datasets and our own quadruped robot dataset, demonstrating its effectiveness in accurately estimating the pose of agile robots during dynamic movements.
Sparse Graphical Linear Dynamical Systems
Jul 06, 2023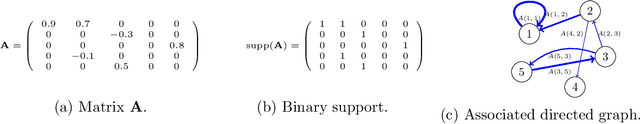
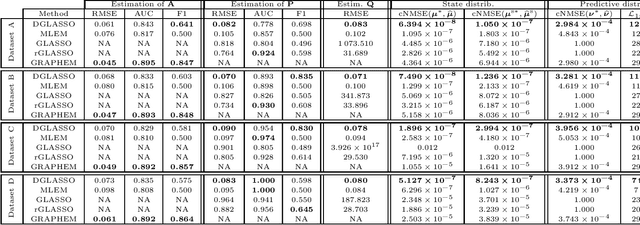
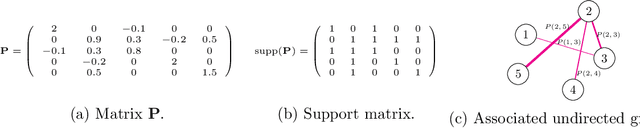
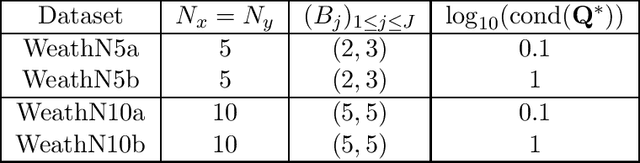
Time-series datasets are central in numerous fields of science and engineering, such as biomedicine, Earth observation, and network analysis. Extensive research exists on state-space models (SSMs), which are powerful mathematical tools that allow for probabilistic and interpretable learning on time series. Estimating the model parameters in SSMs is arguably one of the most complicated tasks, and the inclusion of prior knowledge is known to both ease the interpretation but also to complicate the inferential tasks. Very recent works have attempted to incorporate a graphical perspective on some of those model parameters, but they present notable limitations that this work addresses. More generally, existing graphical modeling tools are designed to incorporate either static information, focusing on statistical dependencies among independent random variables (e.g., graphical Lasso approach), or dynamic information, emphasizing causal relationships among time series samples (e.g., graphical Granger approaches). However, there are no joint approaches combining static and dynamic graphical modeling within the context of SSMs. This work proposes a novel approach to fill this gap by introducing a joint graphical modeling framework that bridges the static graphical Lasso model and a causal-based graphical approach for the linear-Gaussian SSM. We present DGLASSO (Dynamic Graphical Lasso), a new inference method within this framework that implements an efficient block alternating majorization-minimization algorithm. The algorithm's convergence is established by departing from modern tools from nonlinear analysis. Experimental validation on synthetic and real weather variability data showcases the effectiveness of the proposed model and inference algorithm.
POA: Passable Obstacles Aware Path-planning Algorithm for Navigation of a Two-wheeled Robot in Highly Cluttered Environments
Jul 16, 2023
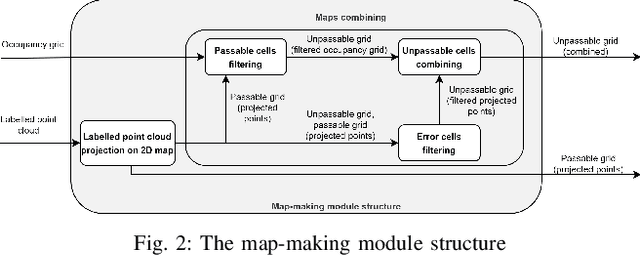
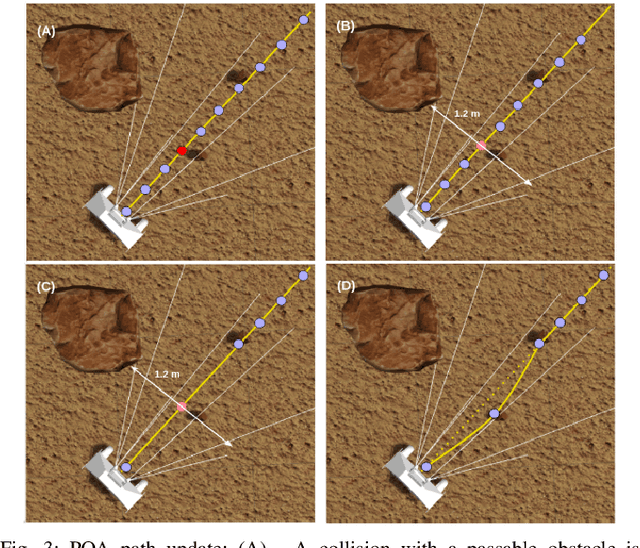

This paper focuses on Passable Obstacles Aware (POA) planner - a novel navigation method for two-wheeled robots in a highly cluttered environment. The navigation algorithm detects and classifies objects to distinguish two types of obstacles - passable and unpassable. Our algorithm allows two-wheeled robots to find a path through passable obstacles. Such a solution helps the robot working in areas inaccessible to standard path planners and find optimal trajectories in scenarios with a high number of objects in the robot's vicinity. The POA planner can be embedded into other planning algorithms and enables them to build a path through obstacles. Our method decreases path length and the total travel time to the final destination up to 43% and 39%, respectively, comparing to standard path planners such as GVD, A*, and RRT*
Exploring a Gradient-based Explainable AI Technique for Time-Series Data: A Case Study of Assessing Stroke Rehabilitation Exercises
May 08, 2023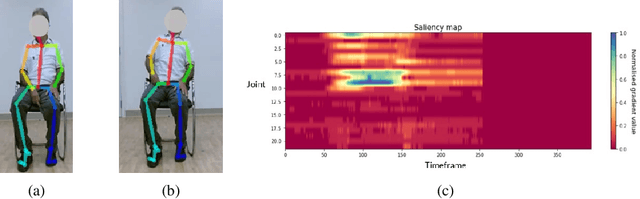


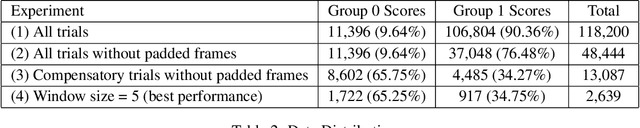
Explainable artificial intelligence (AI) techniques are increasingly being explored to provide insights into why AI and machine learning (ML) models provide a certain outcome in various applications. However, there has been limited exploration of explainable AI techniques on time-series data, especially in the healthcare context. In this paper, we describe a threshold-based method that utilizes a weakly supervised model and a gradient-based explainable AI technique (i.e. saliency map) and explore its feasibility to identify salient frames of time-series data. Using the dataset from 15 post-stroke survivors performing three upper-limb exercises and labels on whether a compensatory motion is observed or not, we implemented a feed-forward neural network model and utilized gradients of each input on model outcomes to identify salient frames that involve compensatory motions. According to the evaluation using frame-level annotations, our approach achieved a recall of 0.96 and an F2-score of 0.91. Our results demonstrated the potential of a gradient-based explainable AI technique (e.g. saliency map) for time-series data, such as highlighting the frames of a video that therapists should focus on reviewing and reducing the efforts on frame-level labeling for model training.
Multi-IMU with Online Self-Consistency for Freehand 3D Ultrasound Reconstruction
Jul 19, 2023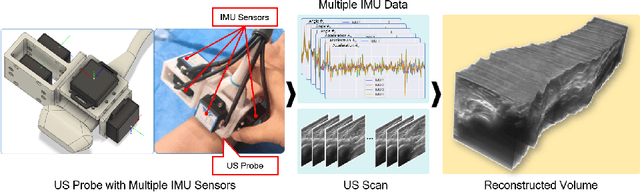
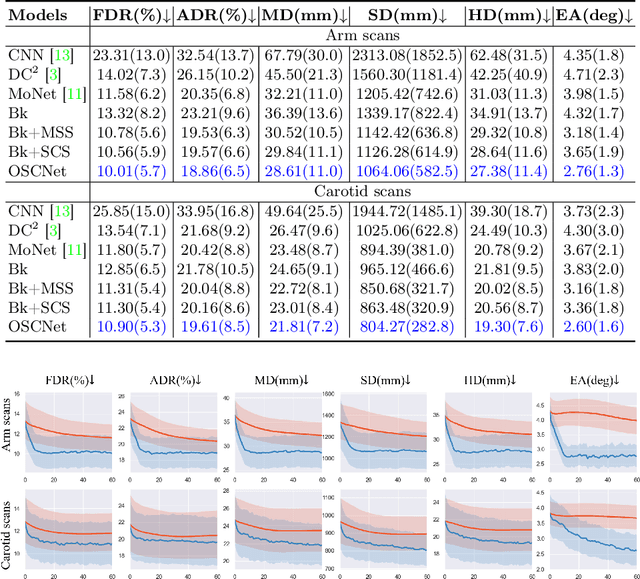
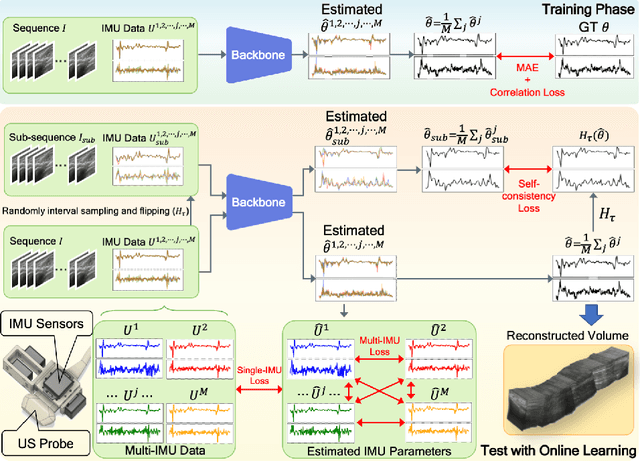
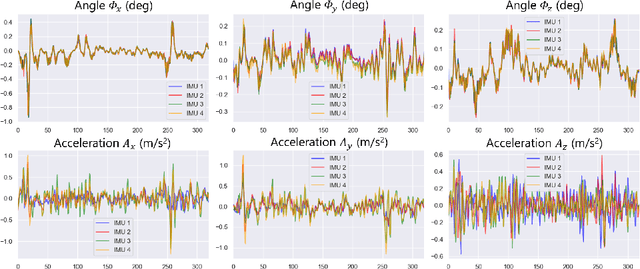
Ultrasound (US) imaging is a popular tool in clinical diagnosis, offering safety, repeatability, and real-time capabilities. Freehand 3D US is a technique that provides a deeper understanding of scanned regions without increasing complexity. However, estimating elevation displacement and accumulation error remains challenging, making it difficult to infer the relative position using images alone. The addition of external lightweight sensors has been proposed to enhance reconstruction performance without adding complexity, which has been shown to be beneficial. We propose a novel online self-consistency network (OSCNet) using multiple inertial measurement units (IMUs) to improve reconstruction performance. OSCNet utilizes a modal-level self-supervised strategy to fuse multiple IMU information and reduce differences between reconstruction results obtained from each IMU data. Additionally, a sequence-level self-consistency strategy is proposed to improve the hierarchical consistency of prediction results among the scanning sequence and its sub-sequences. Experiments on large-scale arm and carotid datasets with multiple scanning tactics demonstrate that our OSCNet outperforms previous methods, achieving state-of-the-art reconstruction performance.
Explaining Autonomous Driving Actions with Visual Question Answering
Jul 19, 2023
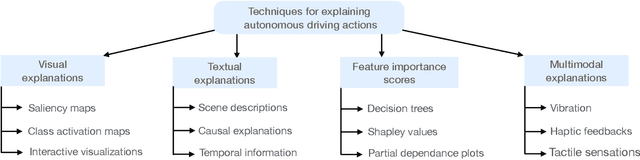
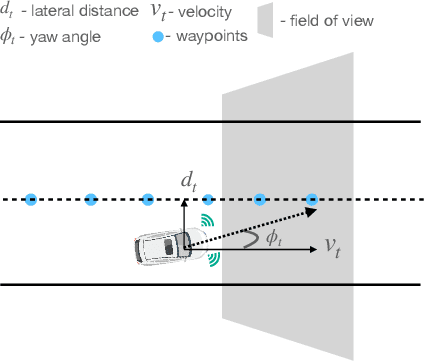
The end-to-end learning ability of self-driving vehicles has achieved significant milestones over the last decade owing to rapid advances in deep learning and computer vision algorithms. However, as autonomous driving technology is a safety-critical application of artificial intelligence (AI), road accidents and established regulatory principles necessitate the need for the explainability of intelligent action choices for self-driving vehicles. To facilitate interpretability of decision-making in autonomous driving, we present a Visual Question Answering (VQA) framework, which explains driving actions with question-answering-based causal reasoning. To do so, we first collect driving videos in a simulation environment using reinforcement learning (RL) and extract consecutive frames from this log data uniformly for five selected action categories. Further, we manually annotate the extracted frames using question-answer pairs as justifications for the actions chosen in each scenario. Finally, we evaluate the correctness of the VQA-predicted answers for actions on unseen driving scenes. The empirical results suggest that the VQA mechanism can provide support to interpret real-time decisions of autonomous vehicles and help enhance overall driving safety.
Measuring and Modeling Uncertainty Degree for Monocular Depth Estimation
Jul 19, 2023
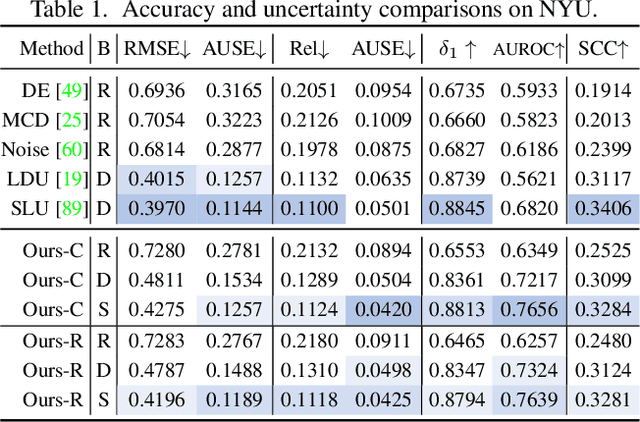
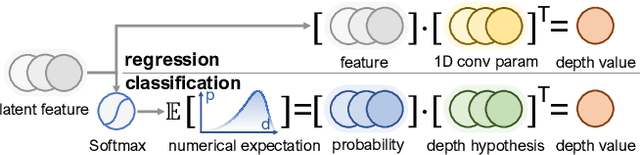
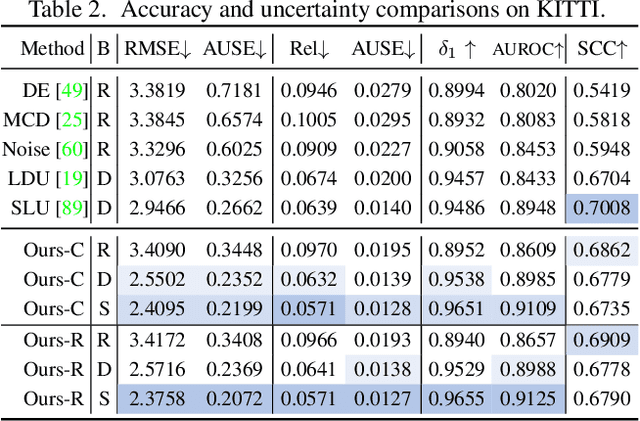
Effectively measuring and modeling the reliability of a trained model is essential to the real-world deployment of monocular depth estimation (MDE) models. However, the intrinsic ill-posedness and ordinal-sensitive nature of MDE pose major challenges to the estimation of uncertainty degree of the trained models. On the one hand, utilizing current uncertainty modeling methods may increase memory consumption and are usually time-consuming. On the other hand, measuring the uncertainty based on model accuracy can also be problematic, where uncertainty reliability and prediction accuracy are not well decoupled. In this paper, we propose to model the uncertainty of MDE models from the perspective of the inherent probability distributions originating from the depth probability volume and its extensions, and to assess it more fairly with more comprehensive metrics. By simply introducing additional training regularization terms, our model, with surprisingly simple formations and without requiring extra modules or multiple inferences, can provide uncertainty estimations with state-of-the-art reliability, and can be further improved when combined with ensemble or sampling methods. A series of experiments demonstrate the effectiveness of our methods.
A Fast and Map-Free Model for Trajectory Prediction in Traffics
Jul 19, 2023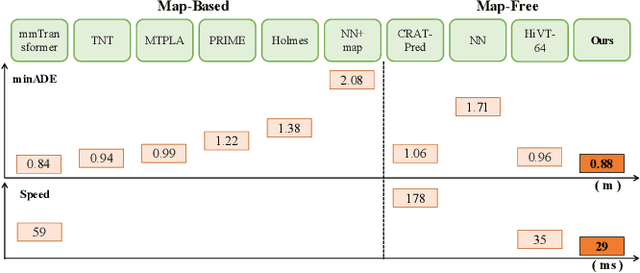
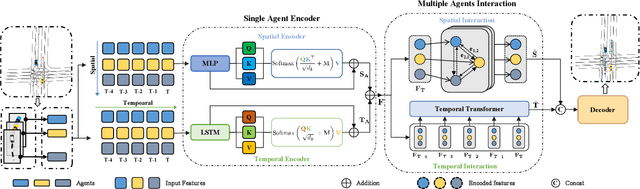
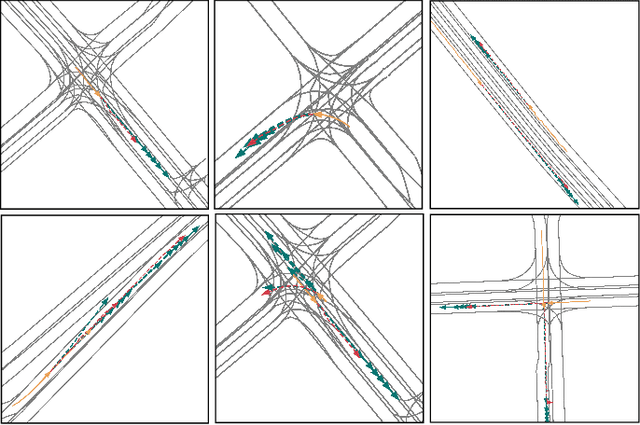
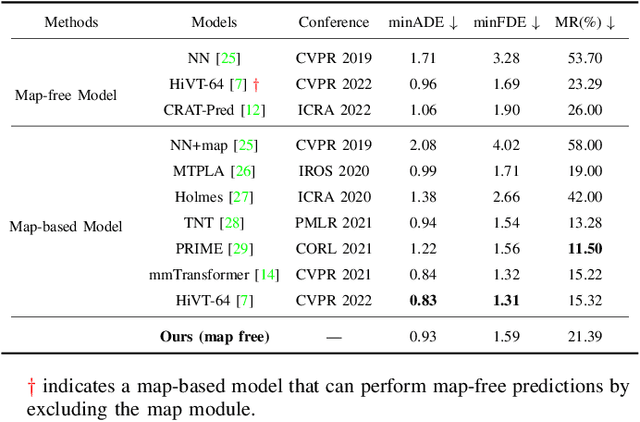
To handle the two shortcomings of existing methods, (i)nearly all models rely on high-definition (HD) maps, yet the map information is not always available in real traffic scenes and HD map-building is expensive and time-consuming and (ii) existing models usually focus on improving prediction accuracy at the expense of reducing computing efficiency, yet the efficiency is crucial for various real applications, this paper proposes an efficient trajectory prediction model that is not dependent on traffic maps. The core idea of our model is encoding single-agent's spatial-temporal information in the first stage and exploring multi-agents' spatial-temporal interactions in the second stage. By comprehensively utilizing attention mechanism, LSTM, graph convolution network and temporal transformer in the two stages, our model is able to learn rich dynamic and interaction information of all agents. Our model achieves the highest performance when comparing with existing map-free methods and also exceeds most map-based state-of-the-art methods on the Argoverse dataset. In addition, our model also exhibits a faster inference speed than the baseline methods.
Whole-Body Dynamic Telelocomotion: A Step-to-Step Dynamics Approach to Human Walking Reference Generation
Jul 21, 2023
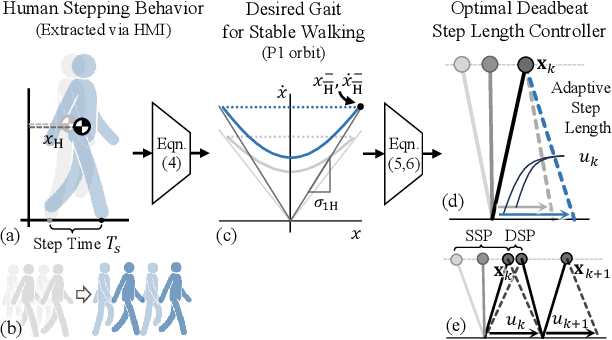
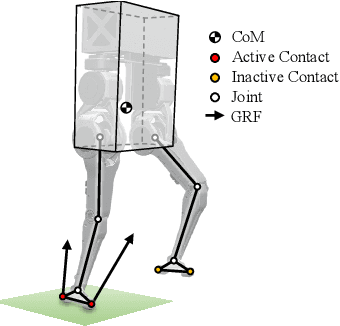
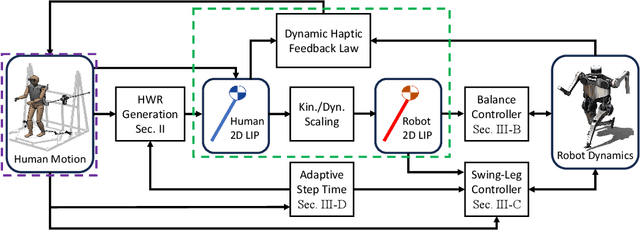
Teleoperated humanoid robots hold significant potential as physical avatars for humans in hazardous and inaccessible environments, with the goal of channeling human intelligence and sensorimotor skills through these robotic counterparts. Precise coordination between humans and robots is crucial for accomplishing whole-body behaviors involving locomotion and manipulation. To progress successfully, dynamic synchronization between humans and humanoid robots must be achieved. This work enhances advancements in whole-body dynamic telelocomotion, addressing challenges in robustness. By embedding the hybrid and underactuated nature of bipedal walking into a virtual human walking interface, we achieve dynamically consistent walking gait generation. Additionally, we integrate a reactive robot controller into a whole-body dynamic telelocomotion framework. Thus, allowing the realization of telelocomotion behaviors on the full-body dynamics of a bipedal robot. Real-time telelocomotion simulation experiments validate the effectiveness of our methods, demonstrating that a trained human pilot can dynamically synchronize with a simulated bipedal robot, achieving sustained locomotion, controlling walking speeds within the range of 0.0 m/s to 0.3 m/s, and enabling backward walking for distances of up to 2.0 m. This research contributes to advancing teleoperated humanoid robots and paves the way for future developments in synchronized locomotion between humans and bipedal robots.
Training Latency Minimization for Model-Splitting Allowed Federated Edge Learning
Jul 21, 2023
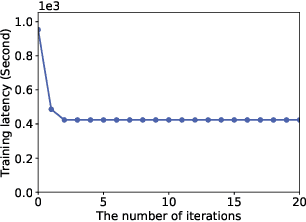

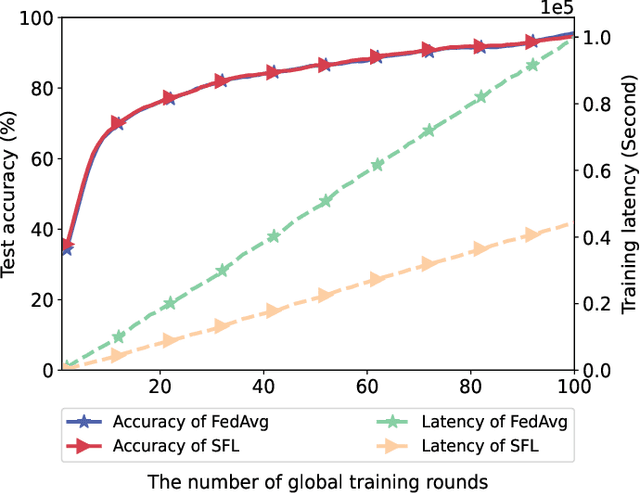
To alleviate the shortage of computing power faced by clients in training deep neural networks (DNNs) using federated learning (FL), we leverage the edge computing and split learning to propose a model-splitting allowed FL (SFL) framework, with the aim to minimize the training latency without loss of test accuracy. Under the synchronized global update setting, the latency to complete a round of global training is determined by the maximum latency for the clients to complete a local training session. Therefore, the training latency minimization problem (TLMP) is modelled as a minimizing-maximum problem. To solve this mixed integer nonlinear programming problem, we first propose a regression method to fit the quantitative-relationship between the cut-layer and other parameters of an AI-model, and thus, transform the TLMP into a continuous problem. Considering that the two subproblems involved in the TLMP, namely, the cut-layer selection problem for the clients and the computing resource allocation problem for the parameter-server are relative independence, an alternate-optimization-based algorithm with polynomial time complexity is developed to obtain a high-quality solution to the TLMP. Extensive experiments are performed on a popular DNN-model EfficientNetV2 using dataset MNIST, and the results verify the validity and improved performance of the proposed SFL framework.