 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Vox-Fusion++: Voxel-based Neural Implicit Dense Tracking and Mapping with Multi-maps
Mar 19, 2024
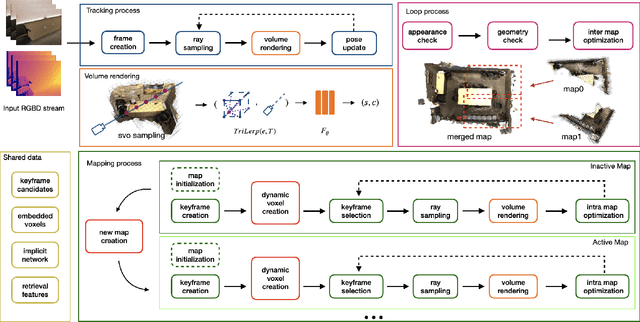
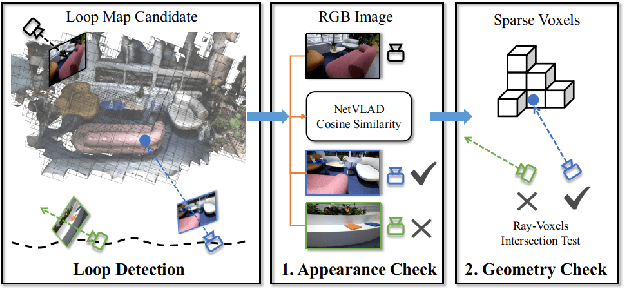


In this paper, we introduce Vox-Fusion++, a multi-maps-based robust dense tracking and mapping system that seamlessly fuses neural implicit representations with traditional volumetric fusion techniques. Building upon the concept of implicit mapping and positioning systems, our approach extends its applicability to real-world scenarios. Our system employs a voxel-based neural implicit surface representation, enabling efficient encoding and optimization of the scene within each voxel. To handle diverse environments without prior knowledge, we incorporate an octree-based structure for scene division and dynamic expansion. To achieve real-time performance, we propose a high-performance multi-process framework. This ensures the system's suitability for applications with stringent time constraints. Additionally, we adopt the idea of multi-maps to handle large-scale scenes, and leverage loop detection and hierarchical pose optimization strategies to reduce long-term pose drift and remove duplicate geometry. Through comprehensive evaluations, we demonstrate that our method outperforms previous methods in terms of reconstruction quality and accuracy across various scenarios. We also show that our Vox-Fusion++ can be used in augmented reality and collaborative mapping applications. Our source code will be publicly available at \url{https://github.com/zju3dv/Vox-Fusion_Plus_Plus}
RATSF: Empowering Customer Service Volume Management through Retrieval-Augmented Time-Series Forecasting
Mar 07, 2024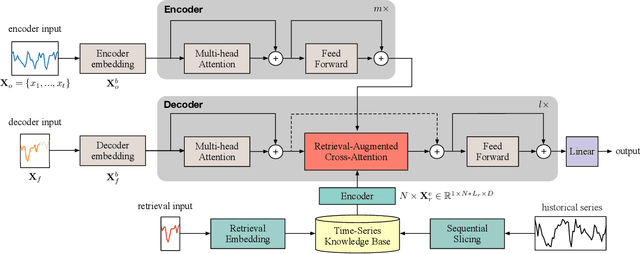
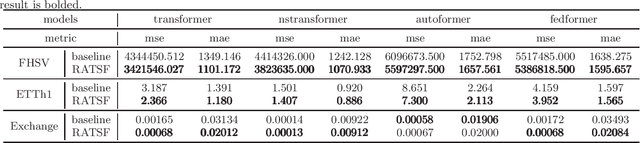
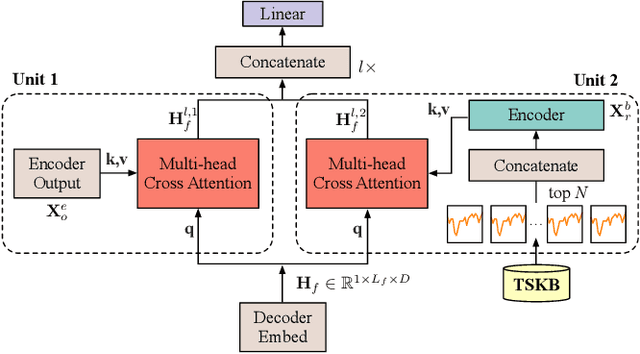

An efficient customer service management system hinges on precise forecasting of service volume. In this scenario, where data non-stationarity is pronounced, successful forecasting heavily relies on identifying and leveraging similar historical data rather than merely summarizing periodic patterns. Existing models based on RNN or Transformer architectures often struggle with this flexible and effective utilization. To address this challenge, we propose an efficient and adaptable cross-attention module termed RACA, which effectively leverages historical segments in forecasting task, and we devised a precise representation scheme for querying historical sequences, coupled with the design of a knowledge repository. These critical components collectively form our Retrieval-Augmented Temporal Sequence Forecasting framework (RATSF). RATSF not only significantly enhances performance in the context of Fliggy hotel service volume forecasting but, more crucially, can be seamlessly integrated into other Transformer-based time-series forecasting models across various application scenarios. Extensive experimentation has validated the effectiveness and generalizability of this system design across multiple diverse contexts.
Simple Graph Condensation
Mar 22, 2024The burdensome training costs on large-scale graphs have aroused significant interest in graph condensation, which involves tuning Graph Neural Networks (GNNs) on a small condensed graph for use on the large-scale original graph. Existing methods primarily focus on aligning key metrics between the condensed and original graphs, such as gradients, distribution and trajectory of GNNs, yielding satisfactory performance on downstream tasks. However, these complex metrics necessitate intricate computations and can potentially disrupt the optimization process of the condensation graph, making the condensation process highly demanding and unstable. Motivated by the recent success of simplified models in various fields, we propose a simplified approach to metric alignment in graph condensation, aiming to reduce unnecessary complexity inherited from GNNs. In our approach, we eliminate external parameters and exclusively retain the target condensed graph during the condensation process. Following the hierarchical aggregation principles of GNNs, we introduce the Simple Graph Condensation (SimGC) framework, which aligns the condensed graph with the original graph from the input layer to the prediction layer, guided by a pre-trained Simple Graph Convolution (SGC) model on the original graph. As a result, both graphs possess the similar capability to train GNNs. This straightforward yet effective strategy achieves a significant speedup of up to 10 times compared to existing graph condensation methods while performing on par with state-of-the-art baselines. Comprehensive experiments conducted on seven benchmark datasets demonstrate the effectiveness of SimGC in prediction accuracy, condensation time, and generalization capability. Our code will be made publicly available.
Invisible Needle Detection in Ultrasound: Leveraging Mechanism-Induced Vibration
Mar 21, 2024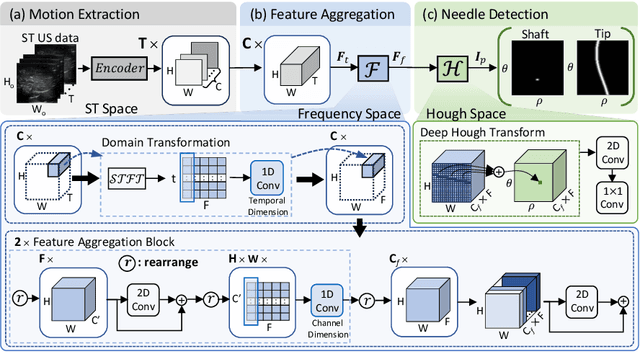
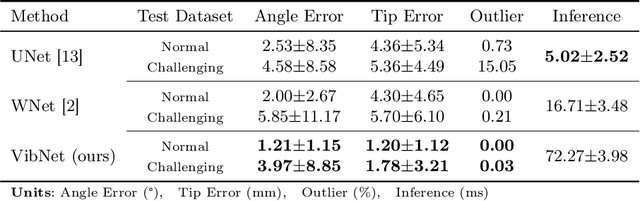
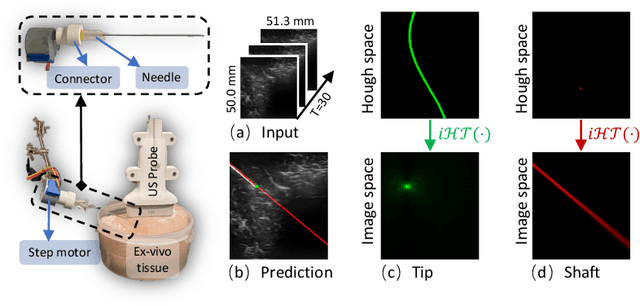
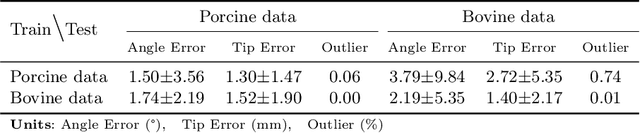
In clinical applications that involve ultrasound-guided intervention, the visibility of the needle can be severely impeded due to steep insertion and strong distractors such as speckle noise and anatomical occlusion. To address this challenge, we propose VibNet, a learning-based framework tailored to enhance the robustness and accuracy of needle detection in ultrasound images, even when the target becomes invisible to the naked eye. Inspired by Eulerian Video Magnification techniques, we utilize an external step motor to induce low-amplitude periodic motion on the needle. These subtle vibrations offer the potential to generate robust frequency features for detecting the motion patterns around the needle. To robustly and precisely detect the needle leveraging these vibrations, VibNet integrates learning-based Short-Time-Fourier-Transform and Hough-Transform modules to achieve successive sub-goals, including motion feature extraction in the spatiotemporal space, frequency feature aggregation, and needle detection in the Hough space. Based on the results obtained on distinct ex vivo porcine and bovine tissue samples, the proposed algorithm exhibits superior detection performance with efficient computation and generalization capability.
MULDE: Multiscale Log-Density Estimation via Denoising Score Matching for Video Anomaly Detection
Mar 21, 2024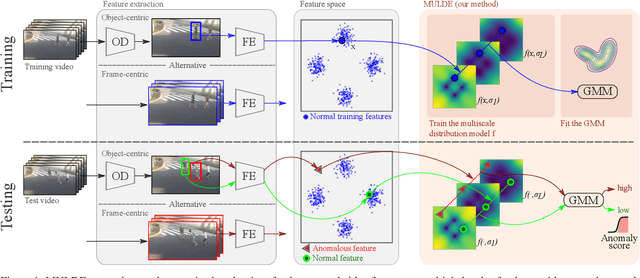
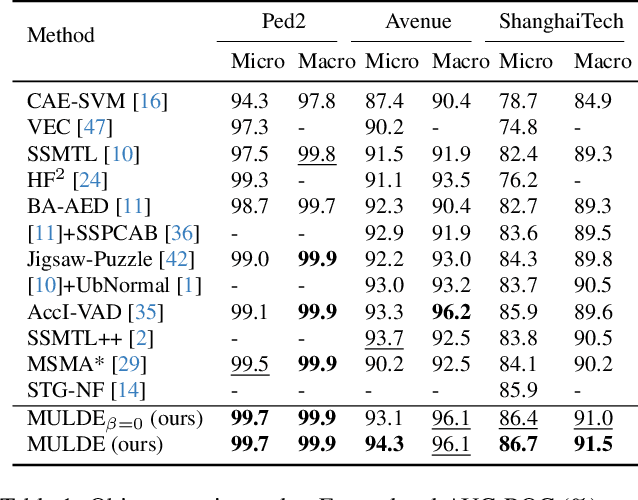
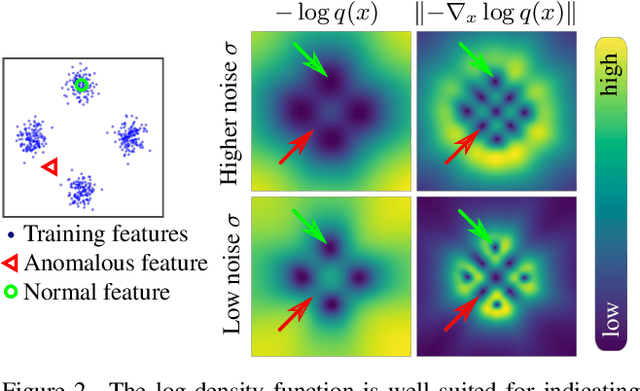
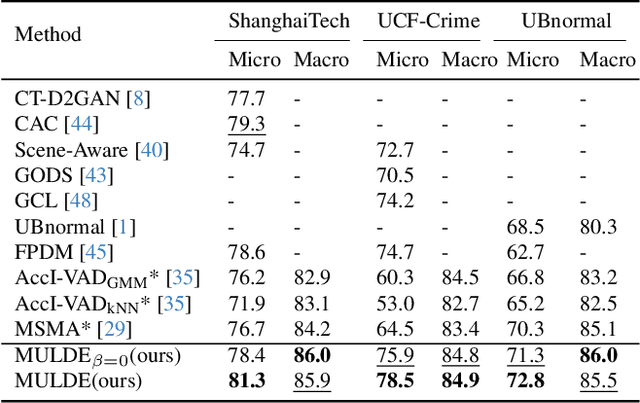
We propose a novel approach to video anomaly detection: we treat feature vectors extracted from videos as realizations of a random variable with a fixed distribution and model this distribution with a neural network. This lets us estimate the likelihood of test videos and detect video anomalies by thresholding the likelihood estimates. We train our video anomaly detector using a modification of denoising score matching, a method that injects training data with noise to facilitate modeling its distribution. To eliminate hyperparameter selection, we model the distribution of noisy video features across a range of noise levels and introduce a regularizer that tends to align the models for different levels of noise. At test time, we combine anomaly indications at multiple noise scales with a Gaussian mixture model. Running our video anomaly detector induces minimal delays as inference requires merely extracting the features and forward-propagating them through a shallow neural network and a Gaussian mixture model. Our experiments on five popular video anomaly detection benchmarks demonstrate state-of-the-art performance, both in the object-centric and in the frame-centric setup.
SpikingResformer: Bridging ResNet and Vision Transformer in Spiking Neural Networks
Mar 21, 2024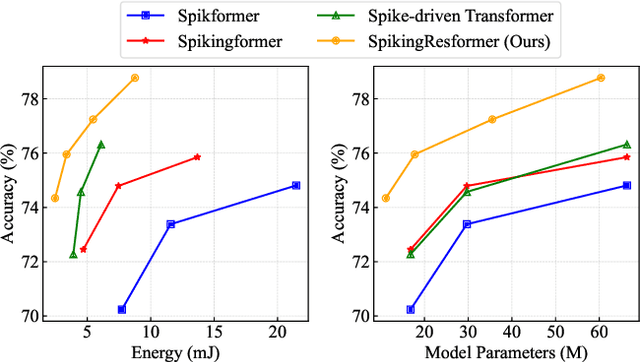

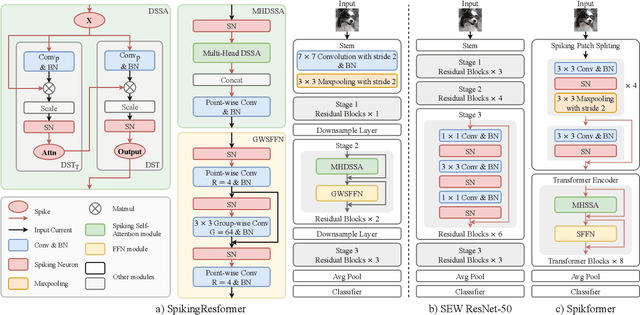
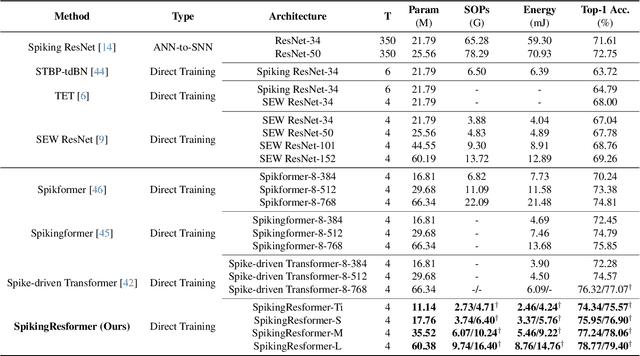
The remarkable success of Vision Transformers in Artificial Neural Networks (ANNs) has led to a growing interest in incorporating the self-attention mechanism and transformer-based architecture into Spiking Neural Networks (SNNs). While existing methods propose spiking self-attention mechanisms that are compatible with SNNs, they lack reasonable scaling methods, and the overall architectures proposed by these methods suffer from a bottleneck in effectively extracting local features. To address these challenges, we propose a novel spiking self-attention mechanism named Dual Spike Self-Attention (DSSA) with a reasonable scaling method. Based on DSSA, we propose a novel spiking Vision Transformer architecture called SpikingResformer, which combines the ResNet-based multi-stage architecture with our proposed DSSA to improve both performance and energy efficiency while reducing parameters. Experimental results show that SpikingResformer achieves higher accuracy with fewer parameters and lower energy consumption than other spiking Vision Transformer counterparts. Notably, our SpikingResformer-L achieves 79.40% top-1 accuracy on ImageNet with 4 time-steps, which is the state-of-the-art result in the SNN field.
SoftPatch: Unsupervised Anomaly Detection with Noisy Data
Mar 21, 2024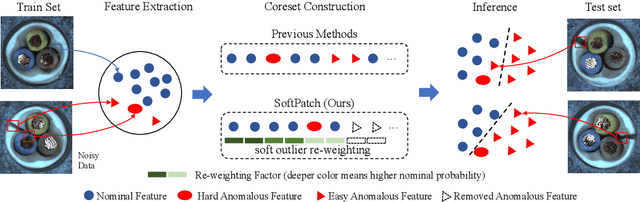
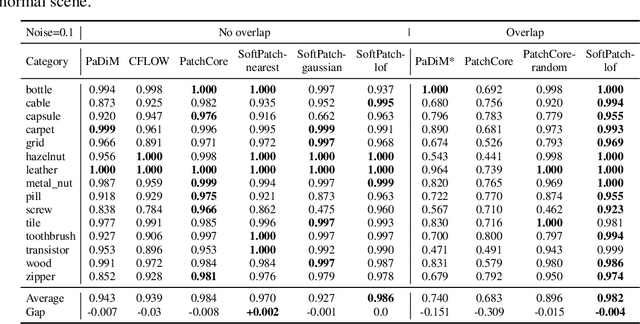
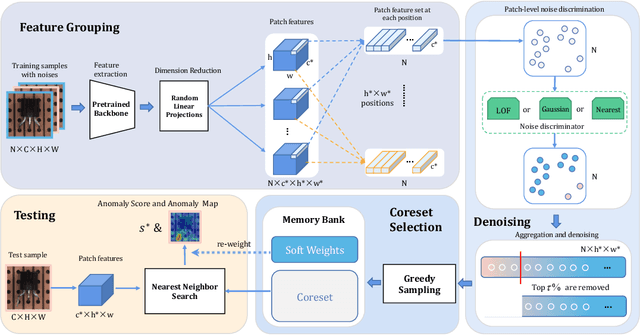

Although mainstream unsupervised anomaly detection (AD) algorithms perform well in academic datasets, their performance is limited in practical application due to the ideal experimental setting of clean training data. Training with noisy data is an inevitable problem in real-world anomaly detection but is seldom discussed. This paper considers label-level noise in image sensory anomaly detection for the first time. To solve this problem, we proposed a memory-based unsupervised AD method, SoftPatch, which efficiently denoises the data at the patch level. Noise discriminators are utilized to generate outlier scores for patch-level noise elimination before coreset construction. The scores are then stored in the memory bank to soften the anomaly detection boundary. Compared with existing methods, SoftPatch maintains a strong modeling ability of normal data and alleviates the overconfidence problem in coreset. Comprehensive experiments in various noise scenes demonstrate that SoftPatch outperforms the state-of-the-art AD methods on the MVTecAD and BTAD benchmarks and is comparable to those methods under the setting without noise.
* 36th Conference on Neural Information Processing Systems
From Handcrafted Features to LLMs: A Brief Survey for Machine Translation Quality Estimation
Mar 21, 2024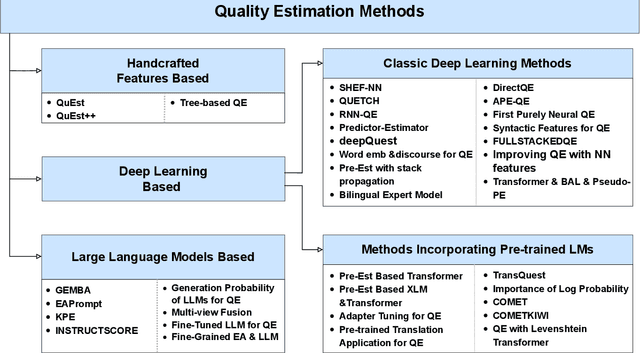
Machine Translation Quality Estimation (MTQE) is the task of estimating the quality of machine-translated text in real time without the need for reference translations, which is of great importance for the development of MT. After two decades of evolution, QE has yielded a wealth of results. This article provides a comprehensive overview of QE datasets, annotation methods, shared tasks, methodologies, challenges, and future research directions. It begins with an introduction to the background and significance of QE, followed by an explanation of the concepts and evaluation metrics for word-level QE, sentence-level QE, document-level QE, and explainable QE. The paper categorizes the methods developed throughout the history of QE into those based on handcrafted features, deep learning, and Large Language Models (LLMs), with a further division of deep learning-based methods into classic deep learning and those incorporating pre-trained language models (LMs). Additionally, the article details the advantages and limitations of each method and offers a straightforward comparison of different approaches. Finally, the paper discusses the current challenges in QE research and provides an outlook on future research directions.
Protein Conformation Generation via Force-Guided SE(3) Diffusion Models
Mar 21, 2024
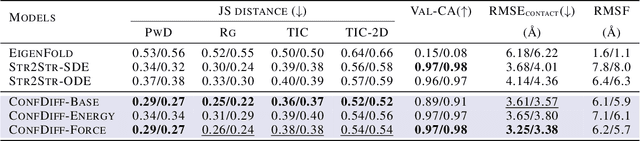
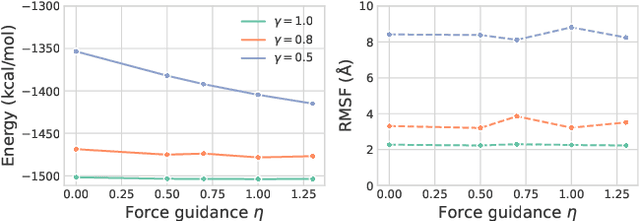
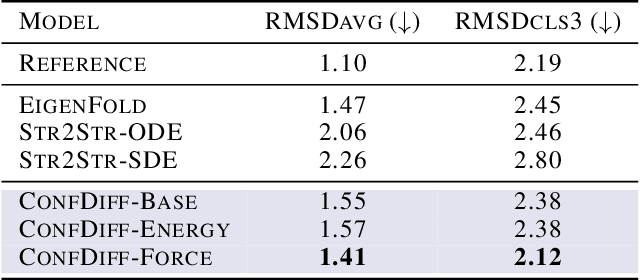
The conformational landscape of proteins is crucial to understanding their functionality in complex biological processes. Traditional physics-based computational methods, such as molecular dynamics (MD) simulations, suffer from rare event sampling and long equilibration time problems, hindering their applications in general protein systems. Recently, deep generative modeling techniques, especially diffusion models, have been employed to generate novel protein conformations. However, existing score-based diffusion methods cannot properly incorporate important physical prior knowledge to guide the generation process, causing large deviations in the sampled protein conformations from the equilibrium distribution. In this paper, to overcome these limitations, we propose a force-guided SE(3) diffusion model, ConfDiff, for protein conformation generation. By incorporating a force-guided network with a mixture of data-based score models, ConfDiff can can generate protein conformations with rich diversity while preserving high fidelity. Experiments on a variety of protein conformation prediction tasks, including 12 fast-folding proteins and the Bovine Pancreatic Trypsin Inhibitor (BPTI), demonstrate that our method surpasses the state-of-the-art method.
Pfeed: Generating near real-time personalized feeds using precomputed embedding similarities
Mar 06, 2024In personalized recommender systems, embeddings are often used to encode customer actions and items, and retrieval is then performed in the embedding space using approximate nearest neighbor search. However, this approach can lead to two challenges: 1) user embeddings can restrict the diversity of interests captured and 2) the need to keep them up-to-date requires an expensive, real-time infrastructure. In this paper, we propose a method that overcomes these challenges in a practical, industrial setting. The method dynamically updates customer profiles and composes a feed every two minutes, employing precomputed embeddings and their respective similarities. We tested and deployed this method to personalise promotional items at Bol, one of the largest e-commerce platforms of the Netherlands and Belgium. The method enhanced customer engagement and experience, leading to a significant 4.9% uplift in conversions.