 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Zero-DeepSub: Zero-Shot Deep Subspace Reconstruction for Rapid Multiparametric Quantitative MRI Using 3D-QALAS
Jul 04, 2023
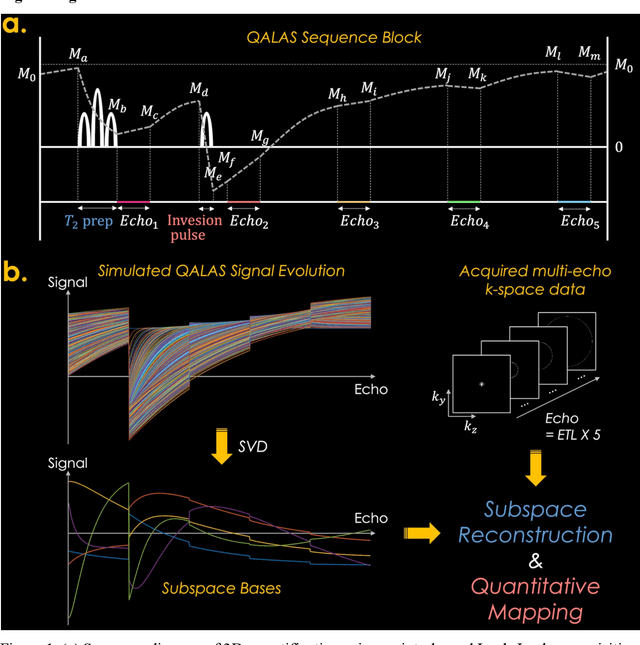
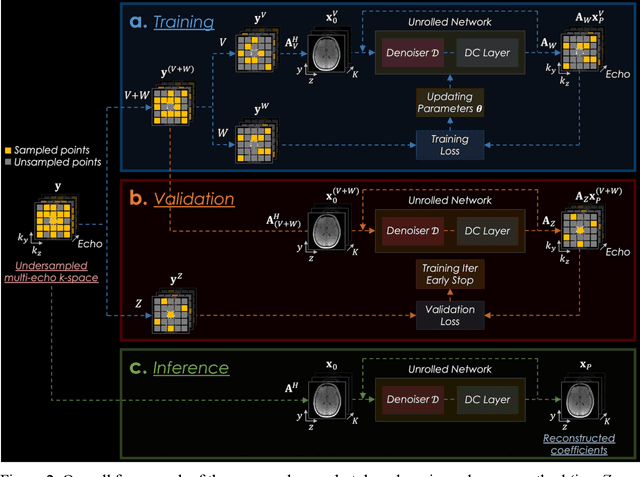
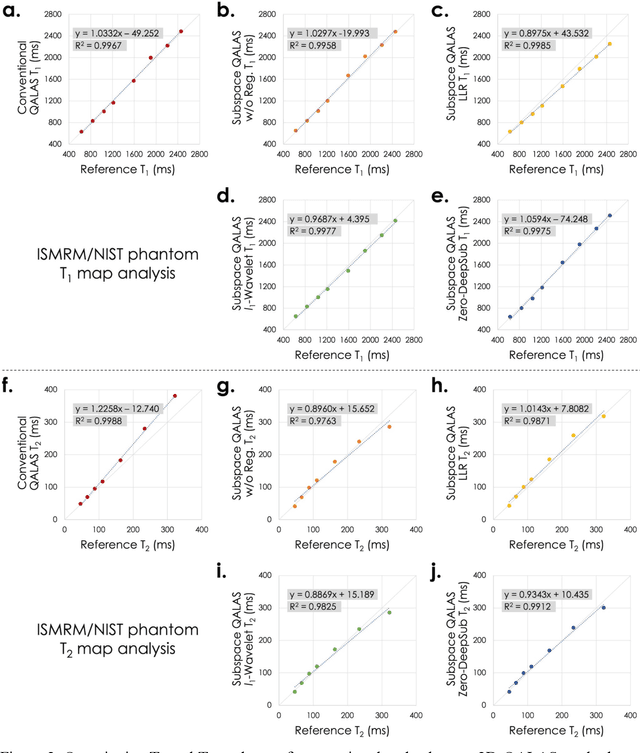
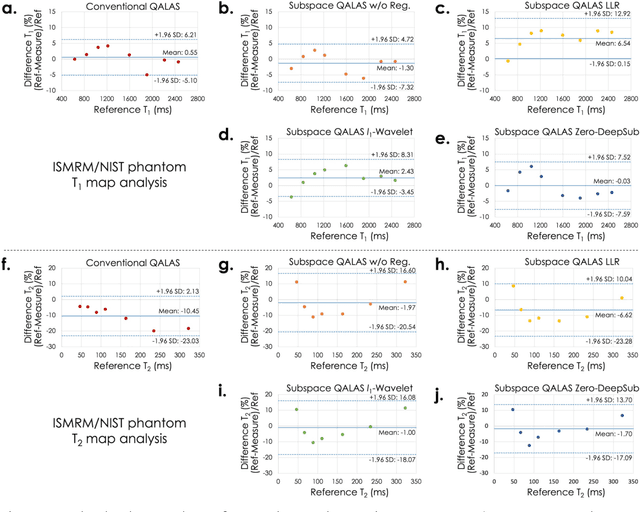
Purpose: To develop and evaluate methods for 1) reconstructing 3D-quantification using an interleaved Look-Locker acquisition sequence with T2 preparation pulse (3D-QALAS) time-series images using a low-rank subspace method, which enables accurate and rapid T1 and T2 mapping, and 2) improving the fidelity of subspace QALAS by combining scan-specific deep-learning-based reconstruction and subspace modeling. Methods: A low-rank subspace method for 3D-QALAS (i.e., subspace QALAS) and zero-shot deep-learning subspace method (i.e., Zero-DeepSub) were proposed for rapid and high fidelity T1 and T2 mapping and time-resolved imaging using 3D-QALAS. Using an ISMRM/NIST system phantom, the accuracy of the T1 and T2 maps estimated using the proposed methods was evaluated by comparing them with reference techniques. The reconstruction performance of the proposed subspace QALAS using Zero-DeepSub was evaluated in vivo and compared with conventional QALAS at high reduction factors of up to 9-fold. Results: Phantom experiments showed that subspace QALAS had good linearity with respect to the reference methods while reducing biases compared to conventional QALAS, especially for T2 maps. Moreover, in vivo results demonstrated that subspace QALAS had better g-factor maps and could reduce voxel blurring, noise, and artifacts compared to conventional QALAS and showed robust performance at up to 9-fold acceleration with Zero-DeepSub, which enabled whole-brain T1, T2, and PD mapping at 1 mm isotropic resolution within 2 min of scan time. Conclusion: The proposed subspace QALAS along with Zero-DeepSub enabled high fidelity and rapid whole-brain multiparametric quantification and time-resolved imaging.
Scope Restriction for Scalable Real-Time Railway Rescheduling: An Exploratory Study
May 05, 2023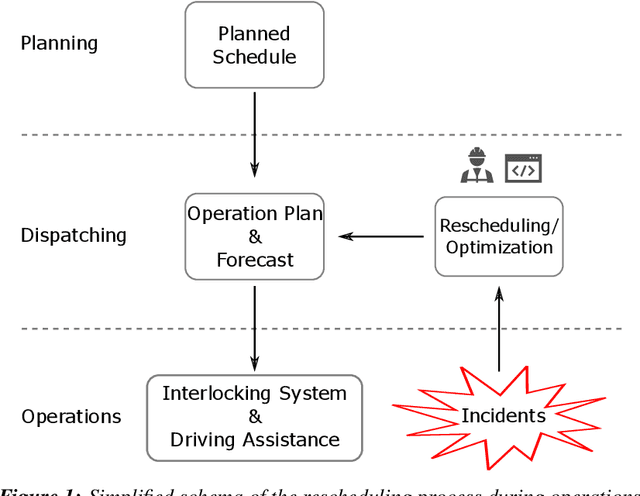

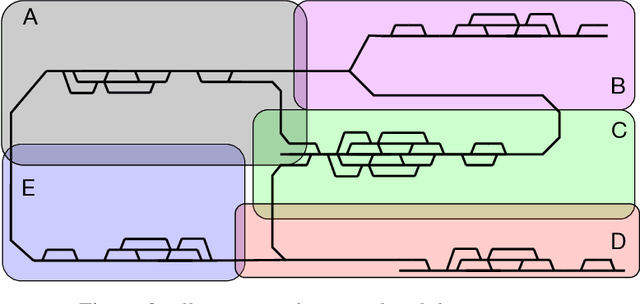
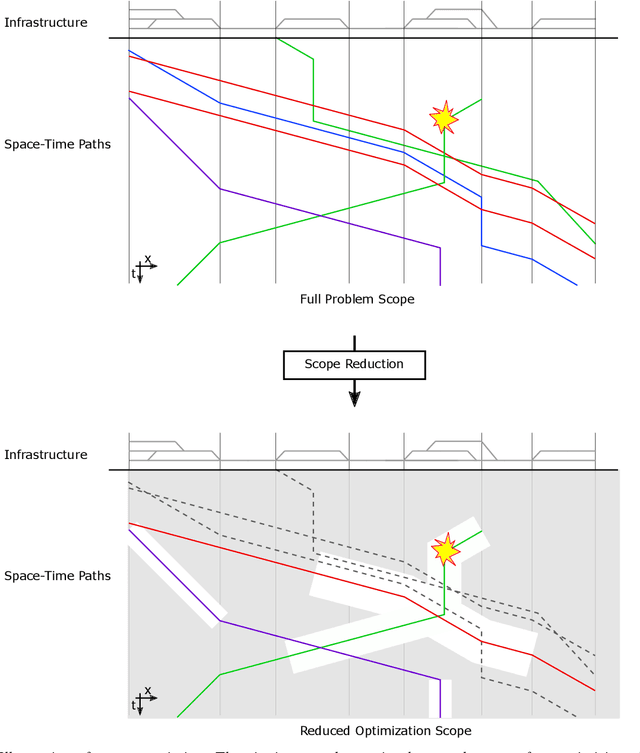
With the aim to stimulate future research, we describe an exploratory study of a railway rescheduling problem. A widely used approach in practice and state of the art is to decompose these complex problems by geographical scope. Instead, we propose defining a core problem that restricts a rescheduling problem in response to a disturbance to only trains that need to be rescheduled, hence restricting the scope in both time and space. In this context, the difficulty resides in defining a scoper that can predict a subset of train services that will be affected by a given disturbance. We report preliminary results using the Flatland simulation environment that highlights the potential and challenges of this idea. We provide an extensible playground open-source implementation based on the Flatland railway environment and Answer-Set Programming.
Racial Bias Trends in the Text of US Legal Opinions
Jul 04, 2023Although there is widespread recognition of racial bias in US law, it is unclear how such bias appears in the language of law, namely judicial opinions, and whether it varies across time period or region. Building upon approaches for measuring implicit racial bias in large-scale corpora, we approximate GloVe word embeddings for over 6 million US federal and state court cases from 1860 to 2009. We find strong evidence of racial bias across nearly all regions and time periods, as traditionally Black names are more closely associated with pre-classified "unpleasant" terms whereas traditionally White names are more closely associated with pre-classified "pleasant" terms. We also test whether legal opinions before 1950 exhibit more implicit racial bias than those after 1950, as well as whether opinions from Southern states exhibit less change in racial bias than those from Northeastern states. We do not find evidence of elevated bias in legal opinions before 1950, or evidence that legal opinions from Northeastern states show greater change in racial bias over time compared to Southern states. These results motivate further research into institutionalized racial bias.
Robust Test-Time Adaptation in Dynamic Scenarios
Mar 24, 2023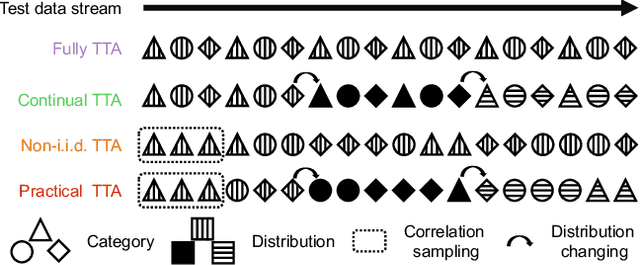

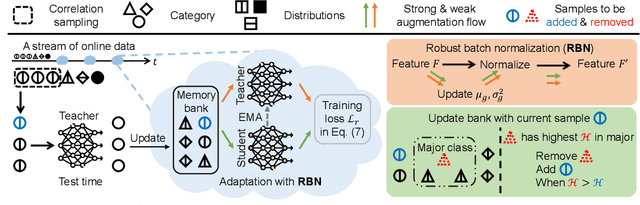
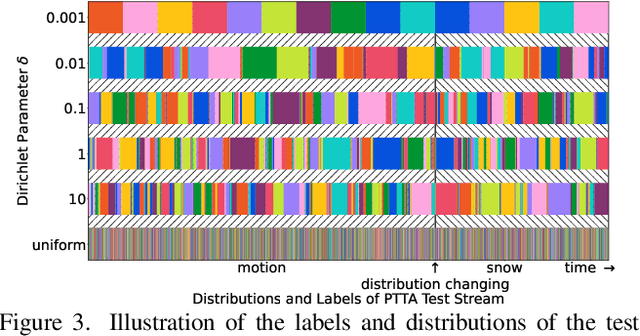
Test-time adaptation (TTA) intends to adapt the pretrained model to test distributions with only unlabeled test data streams. Most of the previous TTA methods have achieved great success on simple test data streams such as independently sampled data from single or multiple distributions. However, these attempts may fail in dynamic scenarios of real-world applications like autonomous driving, where the environments gradually change and the test data is sampled correlatively over time. In this work, we explore such practical test data streams to deploy the model on the fly, namely practical test-time adaptation (PTTA). To do so, we elaborate a Robust Test-Time Adaptation (RoTTA) method against the complex data stream in PTTA. More specifically, we present a robust batch normalization scheme to estimate the normalization statistics. Meanwhile, a memory bank is utilized to sample category-balanced data with consideration of timeliness and uncertainty. Further, to stabilize the training procedure, we develop a time-aware reweighting strategy with a teacher-student model. Extensive experiments prove that RoTTA enables continual testtime adaptation on the correlatively sampled data streams. Our method is easy to implement, making it a good choice for rapid deployment. The code is publicly available at https://github.com/BIT-DA/RoTTA
Online Time-Optimal Trajectory Planning on Three-Dimensional Race Tracks
Apr 21, 2023
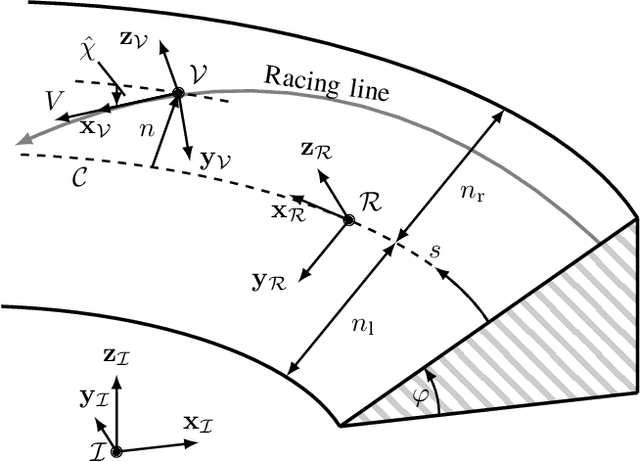
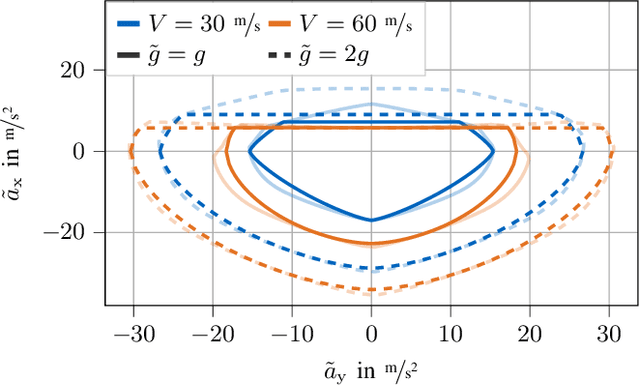
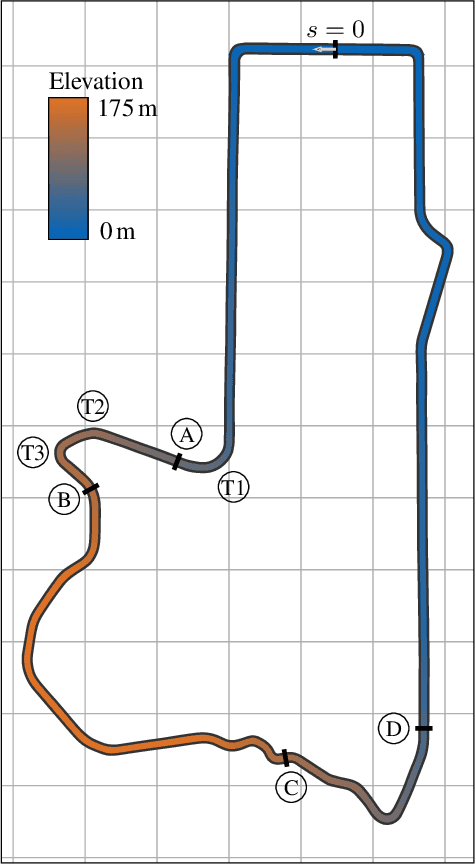
We propose an online planning approach for racing that generates the time-optimal trajectory for the upcoming track section. The resulting trajectory takes the current vehicle state, effects caused by \acl{3D} track geometries, and speed limits dictated by the race rules into account. In each planning step, an optimal control problem is solved, making a quasi-steady-state assumption with a point mass model constrained by gg-diagrams. For its online applicability, we propose an efficient representation of the gg-diagrams and identify negligible terms to reduce the computational effort. We demonstrate that the online planning approach can reproduce the lap times of an offline-generated racing line during single vehicle racing. Moreover, it finds a new time-optimal solution when a deviation from the original racing line is necessary, e.g., during an overtaking maneuver. Motivated by the application in a rule-based race, we also consider the scenario of a speed limit lower than the current vehicle velocity. We introduce an initializable slack variable to generate feasible trajectories despite the constraint violation while reducing the velocity to comply with the rules.
Sparse annotation strategies for segmentation of short axis cardiac MRI
Jul 24, 2023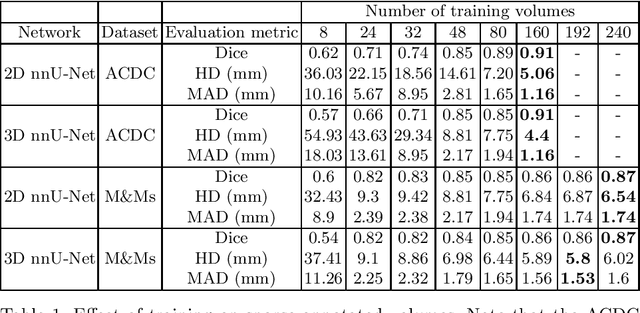
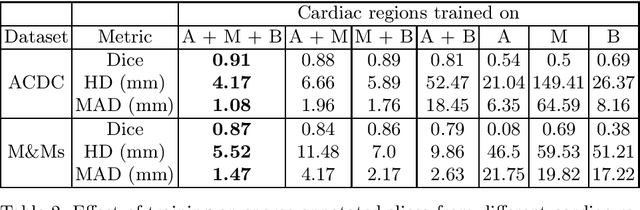
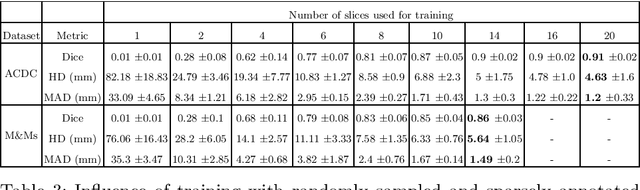
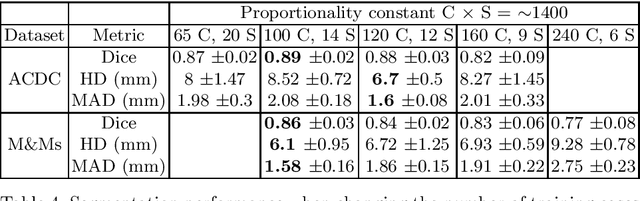
Short axis cardiac MRI segmentation is a well-researched topic, with excellent results achieved by state-of-the-art models in a supervised setting. However, annotating MRI volumes is time-consuming and expensive. Many different approaches (e.g. transfer learning, data augmentation, few-shot learning, etc.) have emerged in an effort to use fewer annotated data and still achieve similar performance as a fully supervised model. Nevertheless, to the best of our knowledge, none of these works focus on which slices of MRI volumes are most important to annotate for yielding the best segmentation results. In this paper, we investigate the effects of training with sparse volumes, i.e. reducing the number of cases annotated, and sparse annotations, i.e. reducing the number of slices annotated per case. We evaluate the segmentation performance using the state-of-the-art nnU-Net model on two public datasets to identify which slices are the most important to annotate. We have shown that training on a significantly reduced dataset (48 annotated volumes) can give a Dice score greater than 0.85 and results comparable to using the full dataset (160 and 240 volumes for each dataset respectively). In general, training on more slice annotations provides more valuable information compared to training on more volumes. Further, annotating slices from the middle of volumes yields the most beneficial results in terms of segmentation performance, and the apical region the worst. When evaluating the trade-off between annotating volumes against slices, annotating as many slices as possible instead of annotating more volumes is a better strategy.
Statler: State-Maintaining Language Models for Embodied Reasoning
Jul 03, 2023
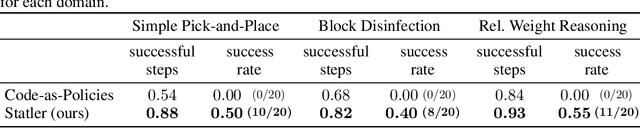
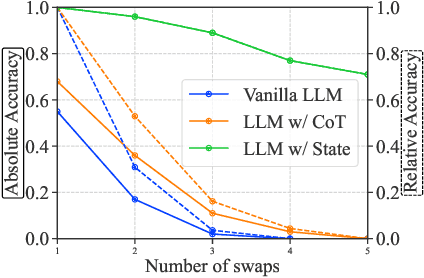
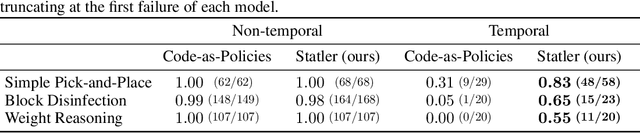
Large language models (LLMs) provide a promising tool that enable robots to perform complex robot reasoning tasks. However, the limited context window of contemporary LLMs makes reasoning over long time horizons difficult. Embodied tasks such as those that one might expect a household robot to perform typically require that the planner consider information acquired a long time ago (e.g., properties of the many objects that the robot previously encountered in the environment). Attempts to capture the world state using an LLM's implicit internal representation is complicated by the paucity of task- and environment-relevant information available in a robot's action history, while methods that rely on the ability to convey information via the prompt to the LLM are subject to its limited context window. In this paper, we propose Statler, a framework that endows LLMs with an explicit representation of the world state as a form of ``memory'' that is maintained over time. Integral to Statler is its use of two instances of general LLMs -- a world-model reader and a world-model writer -- that interface with and maintain the world state. By providing access to this world state ``memory'', Statler improves the ability of existing LLMs to reason over longer time horizons without the constraint of context length. We evaluate the effectiveness of our approach on three simulated table-top manipulation domains and a real robot domain, and show that it improves the state-of-the-art in LLM-based robot reasoning. Project website: https://statler-lm.github.io/
Dynamic Graph Attention for Anomaly Detection in Heterogeneous Sensor Networks
Jul 07, 2023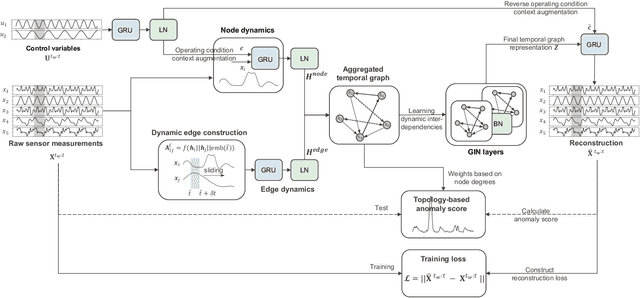
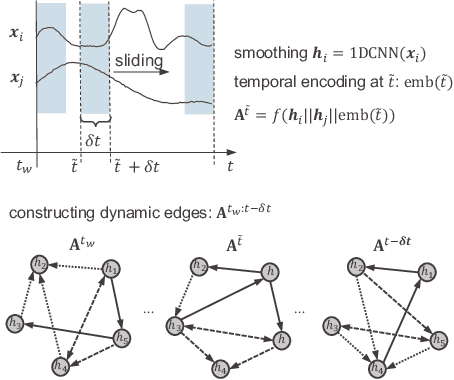
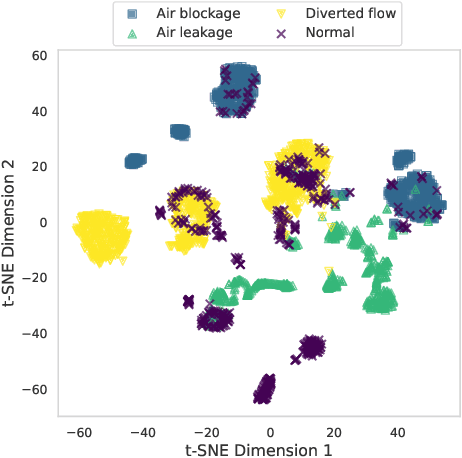
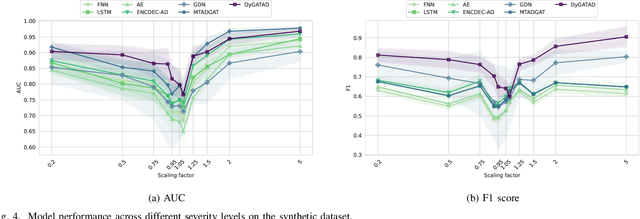
In the era of digital transformation, systems monitored by the Industrial Internet of Things (IIoTs) generate large amounts of Multivariate Time Series (MTS) data through heterogeneous sensor networks. While this data facilitates condition monitoring and anomaly detection, the increasing complexity and interdependencies within the sensor network pose significant challenges for anomaly detection. Despite progress in this field, much of the focus has been on point anomalies and contextual anomalies, with lesser attention paid to collective anomalies. A less addressed but common variant of collective anomalies is when the abnormal collective behavior is caused by shifts in interrelationships within the system. This can be due to abnormal environmental conditions like overheating, improper operational settings resulting from cyber-physical attacks, or system-level faults. To address these challenges, this paper proposes DyGATAD (Dynamic Graph Attention for Anomaly Detection), a graph-based anomaly detection framework that leverages the attention mechanism to construct a continuous graph representation of multivariate time series by inferring dynamic edges between time series. DyGATAD incorporates an operating condition-aware reconstruction combined with a topology-based anomaly score, thereby enhancing the detection ability of relationship shifts. We evaluate the performance of DyGATAD using both a synthetic dataset with controlled varying fault severity levels and an industrial-scale multiphase flow facility benchmark featuring various fault types with different detection difficulties. Our proposed approach demonstrated superior performance in collective anomaly detection for sensor networks, showing particular strength in early-stage fault detection, even in the case of faults with minimal severity.
Identifiability of direct effects from summary causal graphs
Jun 29, 2023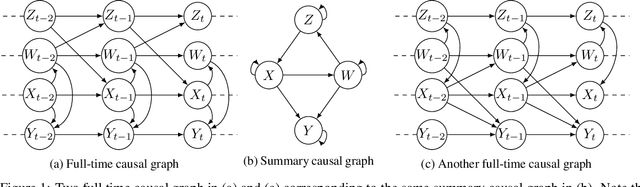
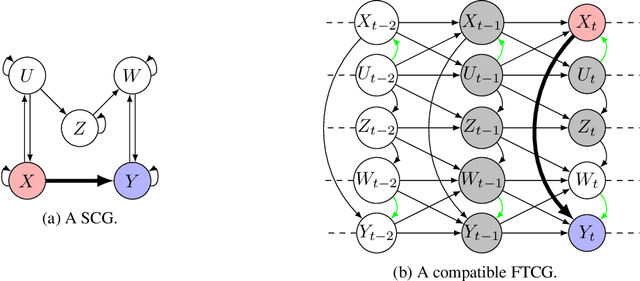
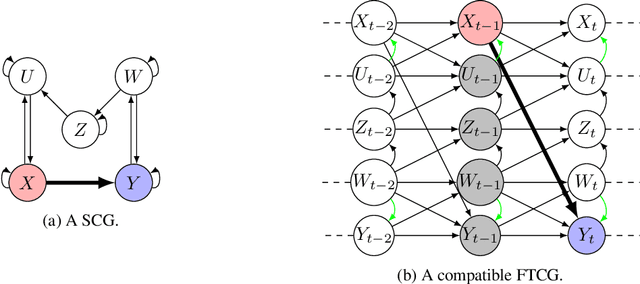
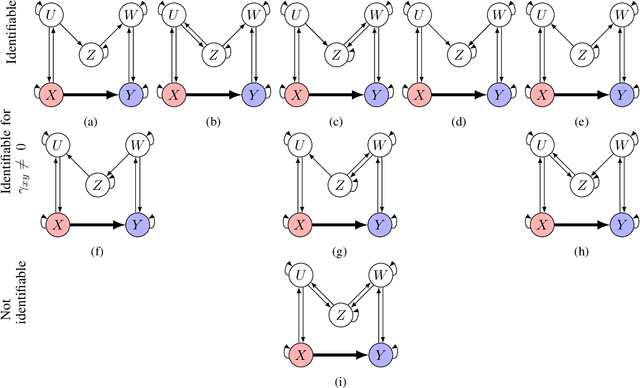
Dynamic structural causal models (SCMs) are a powerful framework for reasoning in dynamic systems about direct effects which measure how a change in one variable affects another variable while holding all other variables constant. The causal relations in a dynamic structural causal model can be qualitatively represented with a full-time causal graph. Assuming linearity and causal sufficiency and given the full-time causal graph, the direct causal effect is always identifiable and can be estimated from data by adjusting on any set of variables given by the so-called single-door criterion. However, in many application such a graph is not available for various reasons but nevertheless experts have access to an abstraction of the full-time causal graph which represents causal relations between time series while omitting temporal information. This paper presents a complete identifiability result which characterizes all cases for which the direct effect is graphically identifiable from summary causal graphs and gives two sound finite adjustment sets that can be used to estimate the direct effect whenever it is identifiable.
EsaNet: Environment Semantics Enabled Physical Layer Authentication
Jul 18, 2023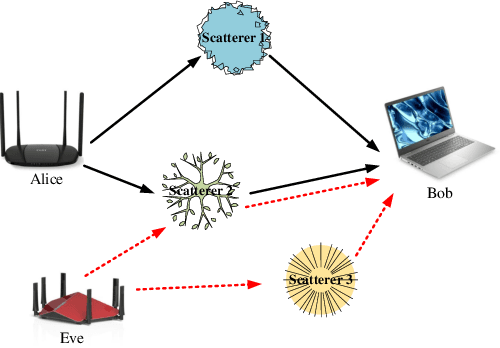
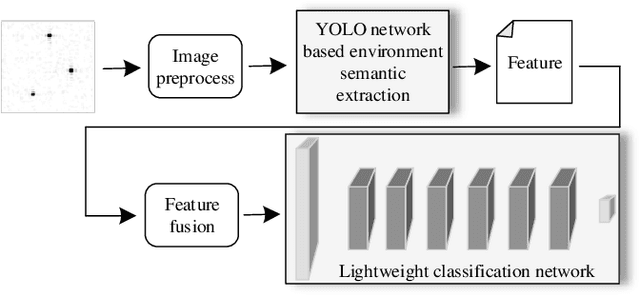
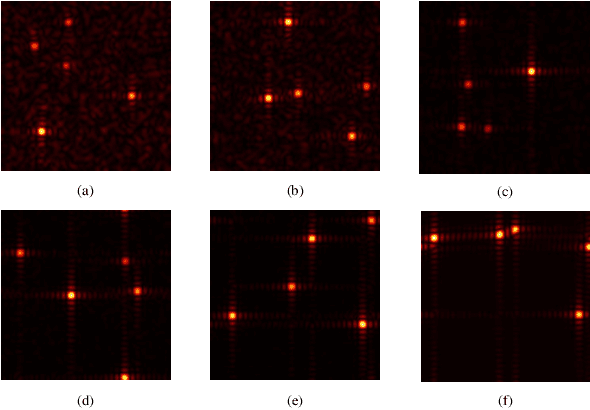
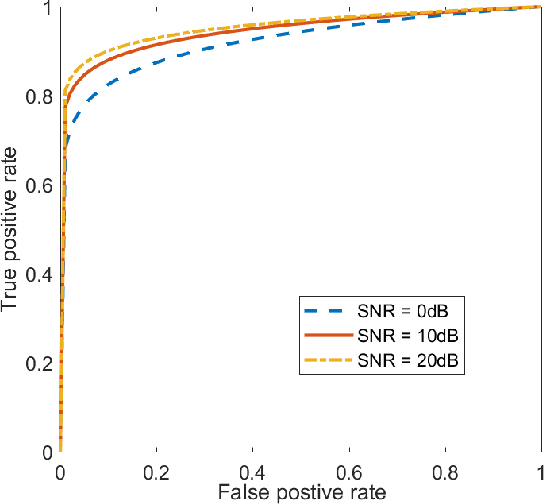
Wireless networks are vulnerable to physical layer spoofing attacks due to the wireless broadcast nature, thus, integrating communications and security (ICAS) is urgently needed for 6G endogenous security. In this letter, we propose an environment semantics enabled physical layer authentication network based on deep learning, namely EsaNet, to authenticate the spoofing from the underlying wireless protocol. Specifically, the frequency independent wireless channel fingerprint (FiFP) is extracted from the channel state information (CSI) of a massive multi-input multi-output (MIMO) system based on environment semantics knowledge. Then, we transform the received signal into a two-dimensional red green blue (RGB) image and apply the you only look once (YOLO), a single-stage object detection network, to quickly capture the FiFP. Next, a lightweight classification network is designed to distinguish the legitimate from the illegitimate users. Finally, the experimental results show that the proposed EsaNet can effectively detect physical layer spoofing attacks and is robust in time-varying wireless environments.