 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FourierHandFlow: Neural 4D Hand Representation Using Fourier Query Flow
Jul 16, 2023
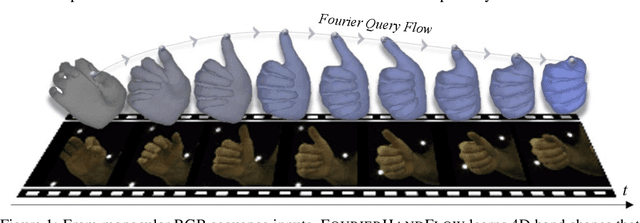

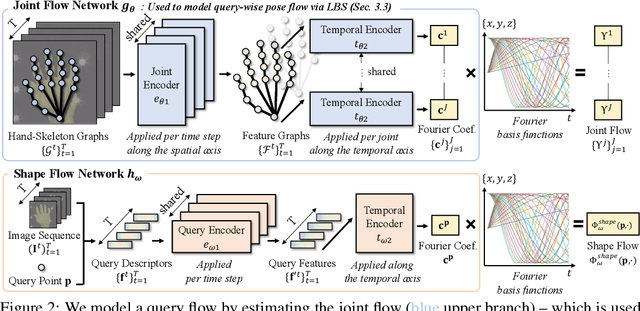

Recent 4D shape representations model continuous temporal evolution of implicit shapes by (1) learning query flows without leveraging shape and articulation priors or (2) decoding shape occupancies separately for each time value. Thus, they do not effectively capture implicit correspondences between articulated shapes or regularize jittery temporal deformations. In this work, we present FourierHandFlow, which is a spatio-temporally continuous representation for human hands that combines a 3D occupancy field with articulation-aware query flows represented as Fourier series. Given an input RGB sequence, we aim to learn a fixed number of Fourier coefficients for each query flow to guarantee smooth and continuous temporal shape dynamics. To effectively model spatio-temporal deformations of articulated hands, we compose our 4D representation based on two types of Fourier query flow: (1) pose flow that models query dynamics influenced by hand articulation changes via implicit linear blend skinning and (2) shape flow that models query-wise displacement flow. In the experiments, our method achieves state-of-the-art results on video-based 4D reconstruction while being computationally more efficient than the existing 3D/4D implicit shape representations. We additionally show our results on motion inter- and extrapolation and texture transfer using the learned correspondences of implicit shapes. To the best of our knowledge, FourierHandFlow is the first neural 4D continuous hand representation learned from RGB videos. The code will be publicly accessible.
Bivariate DeepKriging for Large-scale Spatial Interpolation of Wind Fields
Jul 16, 2023High spatial resolution wind data are essential for a wide range of applications in climate, oceanographic and meteorological studies. Large-scale spatial interpolation or downscaling of bivariate wind fields having velocity in two dimensions is a challenging task because wind data tend to be non-Gaussian with high spatial variability and heterogeneity. In spatial statistics, cokriging is commonly used for predicting bivariate spatial fields. However, the cokriging predictor is not optimal except for Gaussian processes. Additionally, cokriging is computationally prohibitive for large datasets. In this paper, we propose a method, called bivariate DeepKriging, which is a spatially dependent deep neural network (DNN) with an embedding layer constructed by spatial radial basis functions for bivariate spatial data prediction. We then develop a distribution-free uncertainty quantification method based on bootstrap and ensemble DNN. Our proposed approach outperforms the traditional cokriging predictor with commonly used covariance functions, such as the linear model of co-regionalization and flexible bivariate Mat\'ern covariance. We demonstrate the computational efficiency and scalability of the proposed DNN model, with computations that are, on average, 20 times faster than those of conventional techniques. We apply the bivariate DeepKriging method to the wind data over the Middle East region at 506,771 locations. The prediction performance of the proposed method is superior over the cokriging predictors and dramatically reduces computation time.
Real-time instance segmentation with polygons using an Intersection-over-Union loss
May 09, 2023
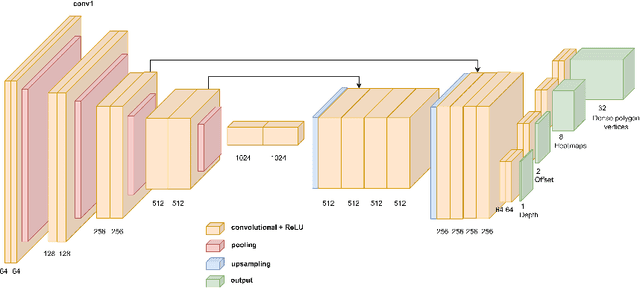
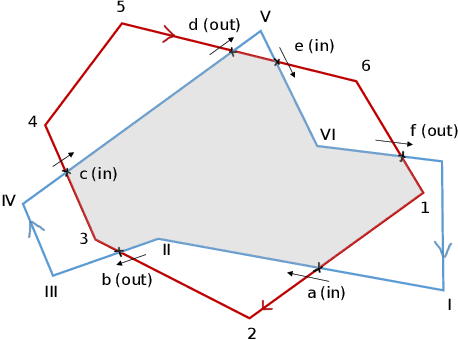
Predicting a binary mask for an object is more accurate but also more computationally expensive than a bounding box. Polygonal masks as developed in CenterPoly can be a good compromise. In this paper, we improve over CenterPoly by enhancing the classical regression L1 loss with a novel region-based loss and a novel order loss, as well as with a new training process for the vertices prediction head. Moreover, the previous methods that predict polygonal masks use different coordinate systems, but it is not clear if one is better than another, if we abstract the architecture requirement. We therefore investigate their impact on the prediction. We also use a new evaluation protocol with oracle predictions for the detection head, to further isolate the segmentation process and better compare the polygonal masks with binary masks. Our instance segmentation method is trained and tested with challenging datasets containing urban scenes, with a high density of road users. Experiments show, in particular, that using a combination of a regression loss and a region-based loss allows significant improvements on the Cityscapes and IDD test set compared to CenterPoly. Moreover the inference stage remains fast enough to reach real-time performance with an average of 0.045 s per frame for 2048$\times$1024 images on a single RTX 2070 GPU. The code is available $\href{https://github.com/KatiaJDL/CenterPoly-v2}{\text{here}}$.
Study on the Correlation between Objective Evaluations and Subjective Speech Quality and Intelligibility
Jul 10, 2023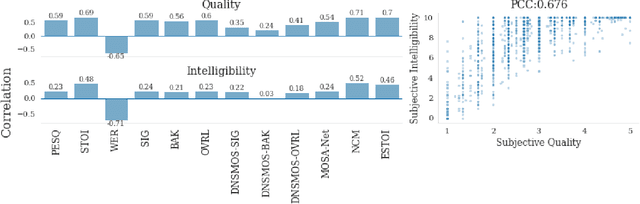
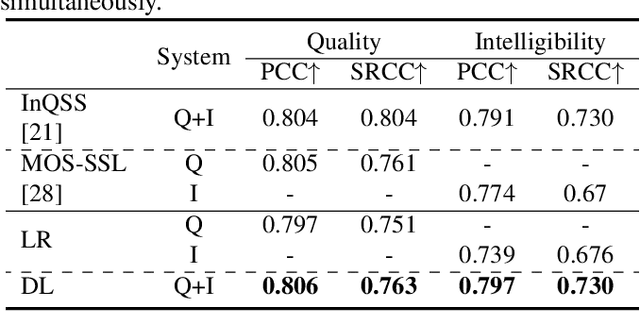
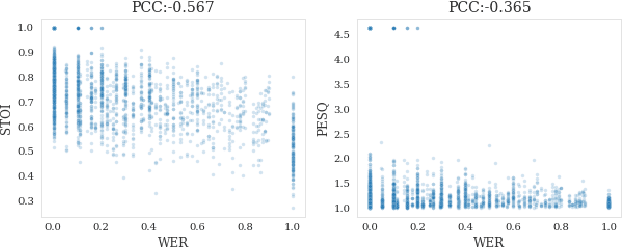
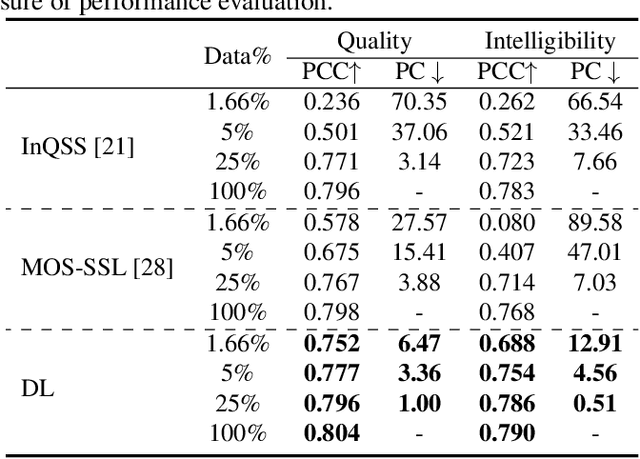
Subjective tests are the gold standard for evaluating speech quality and intelligibility, but they are time-consuming and expensive. Thus, objective measures that align with human perceptions are crucial. This study evaluates the correlation between commonly used objective measures and subjective speech quality and intelligibility using a Chinese speech dataset. Moreover, new objective measures are proposed combining current objective measures using deep learning techniques to predict subjective quality and intelligibility. The proposed deep learning model reduces the amount of training data without significantly impacting prediction performance. We interpret the deep learning model to understand how objective measures reflect subjective quality and intelligibility. We also explore the impact of including subjective speech quality ratings on speech intelligibility prediction. Our findings offer valuable insights into the relationship between objective measures and human perceptions.
Impact of Feature Encoding on Malware Classification Explainability
Jul 10, 2023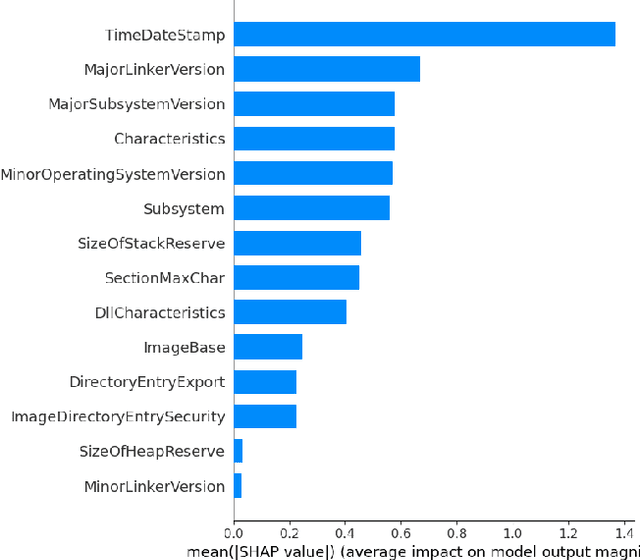
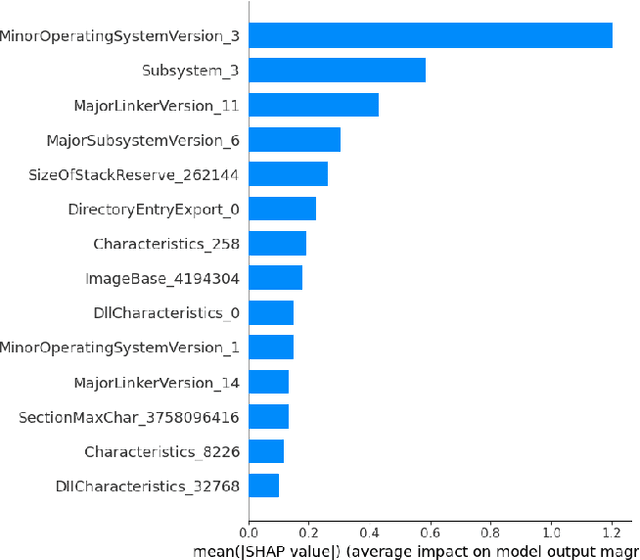
This paper investigates the impact of feature encoding techniques on the explainability of XAI (Explainable Artificial Intelligence) algorithms. Using a malware classification dataset, we trained an XGBoost model and compared the performance of two feature encoding methods: Label Encoding (LE) and One Hot Encoding (OHE). Our findings reveal a marginal performance loss when using OHE instead of LE. However, the more detailed explanations provided by OHE compensated for this loss. We observed that OHE enables deeper exploration of details in both global and local contexts, facilitating more comprehensive answers. Additionally, we observed that using OHE resulted in smaller explanation files and reduced analysis time for human analysts. These findings emphasize the significance of considering feature encoding techniques in XAI research and suggest potential for further exploration by incorporating additional encoding methods and innovative visualization approaches.
Hiding in Plain Sight: Differential Privacy Noise Exploitation for Evasion-resilient Localized Poisoning Attacks in Multiagent Reinforcement Learning
Jul 13, 2023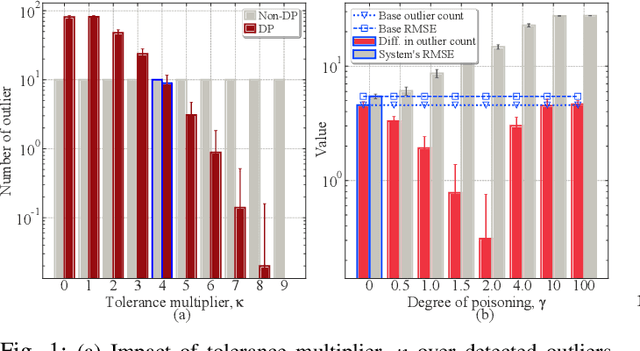
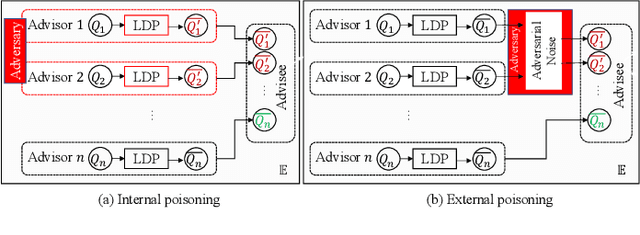
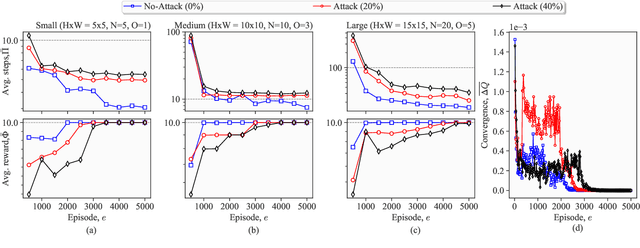

Lately, differential privacy (DP) has been introduced in cooperative multiagent reinforcement learning (CMARL) to safeguard the agents' privacy against adversarial inference during knowledge sharing. Nevertheless, we argue that the noise introduced by DP mechanisms may inadvertently give rise to a novel poisoning threat, specifically in the context of private knowledge sharing during CMARL, which remains unexplored in the literature. To address this shortcoming, we present an adaptive, privacy-exploiting, and evasion-resilient localized poisoning attack (PeLPA) that capitalizes on the inherent DP-noise to circumvent anomaly detection systems and hinder the optimal convergence of the CMARL model. We rigorously evaluate our proposed PeLPA attack in diverse environments, encompassing both non-adversarial and multiple-adversarial contexts. Our findings reveal that, in a medium-scale environment, the PeLPA attack with attacker ratios of 20% and 40% can lead to an increase in average steps to goal by 50.69% and 64.41%, respectively. Furthermore, under similar conditions, PeLPA can result in a 1.4x and 1.6x computational time increase in optimal reward attainment and a 1.18x and 1.38x slower convergence for attacker ratios of 20% and 40%, respectively.
Efficient Task Offloading Algorithm for Digital Twin in Edge/Cloud Computing Environment
Jul 13, 2023
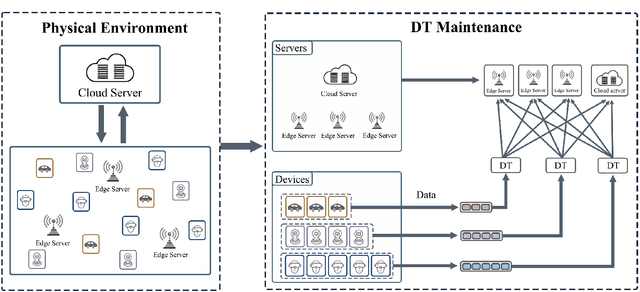
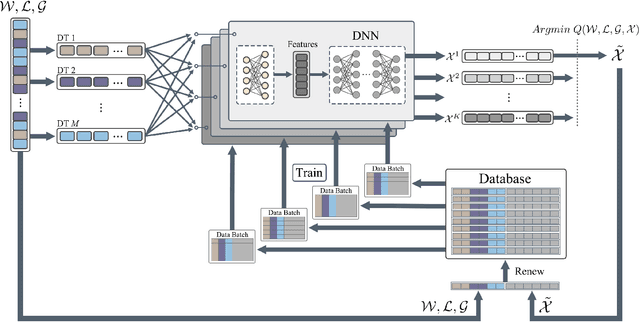
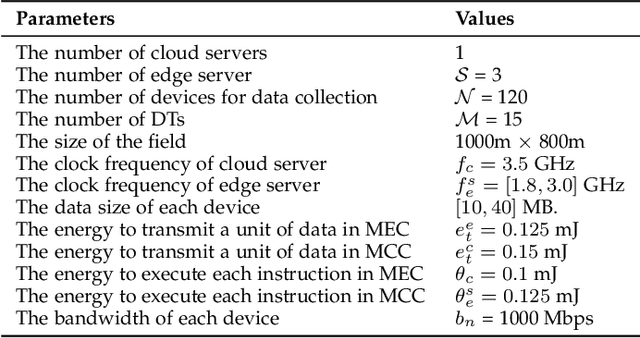
In the era of Internet of Things (IoT), Digital Twin (DT) is envisioned to empower various areas as a bridge between physical objects and the digital world. Through virtualization and simulation techniques, multiple functions can be achieved by leveraging computing resources. In this process, Mobile Cloud Computing (MCC) and Mobile Edge Computing (MEC) have become two of the key factors to achieve real-time feedback. However, current works only considered edge servers or cloud servers in the DT system models. Besides, The models ignore the DT with not only one data resource. In this paper, we propose a new DT system model considering a heterogeneous MEC/MCC environment. Each DT in the model is maintained in one of the servers via multiple data collection devices. The offloading decision-making problem is also considered and a new offloading scheme is proposed based on Distributed Deep Learning (DDL). Simulation results demonstrate that our proposed algorithm can effectively and efficiently decrease the system's average latency and energy consumption. Significant improvement is achieved compared with the baselines under the dynamic environment of DTs.
Guided Linear Upsampling
Jul 13, 2023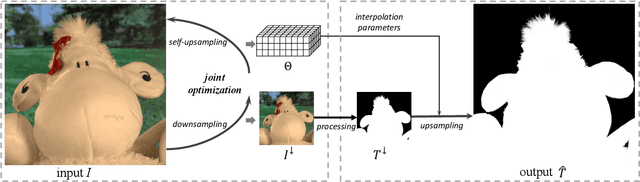
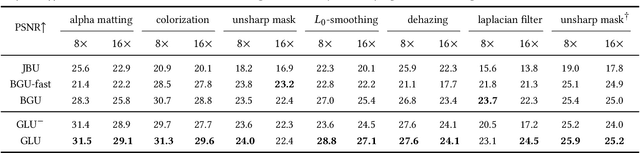
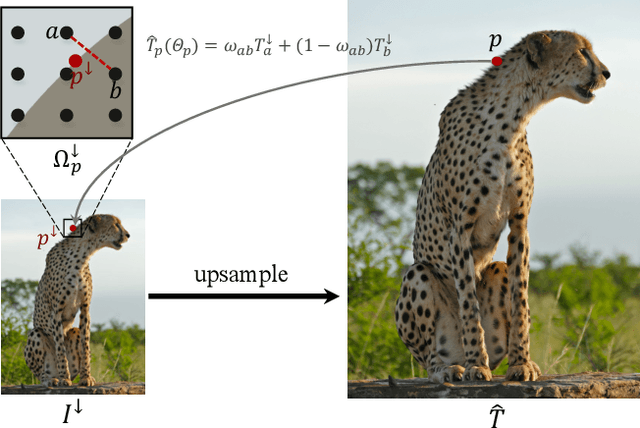
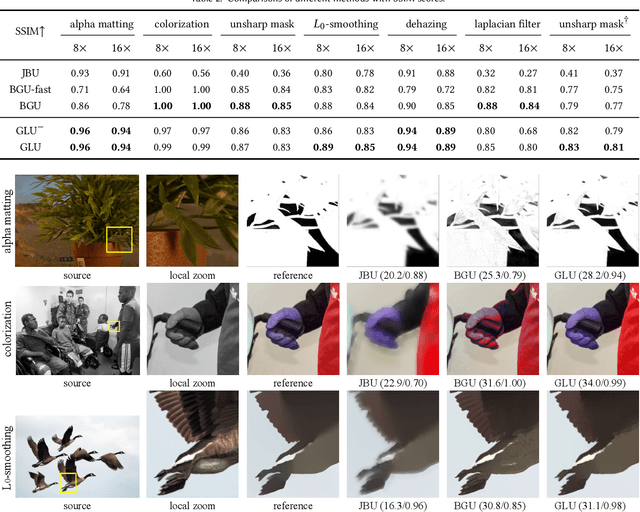
Guided upsampling is an effective approach for accelerating high-resolution image processing. In this paper, we propose a simple yet effective guided upsampling method. Each pixel in the high-resolution image is represented as a linear interpolation of two low-resolution pixels, whose indices and weights are optimized to minimize the upsampling error. The downsampling can be jointly optimized in order to prevent missing small isolated regions. Our method can be derived from the color line model and local color transformations. Compared to previous methods, our method can better preserve detail effects while suppressing artifacts such as bleeding and blurring. It is efficient, easy to implement, and free of sensitive parameters. We evaluate the proposed method with a wide range of image operators, and show its advantages through quantitative and qualitative analysis. We demonstrate the advantages of our method for both interactive image editing and real-time high-resolution video processing. In particular, for interactive editing, the joint optimization can be precomputed, thus allowing for instant feedback without hardware acceleration.
Blocks2World: Controlling Realistic Scenes with Editable Primitives
Jul 13, 2023
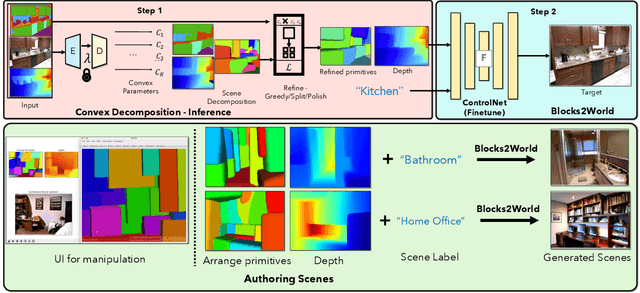


We present Blocks2World, a novel method for 3D scene rendering and editing that leverages a two-step process: convex decomposition of images and conditioned synthesis. Our technique begins by extracting 3D parallelepipeds from various objects in a given scene using convex decomposition, thus obtaining a primitive representation of the scene. These primitives are then utilized to generate paired data through simple ray-traced depth maps. The next stage involves training a conditioned model that learns to generate images from the 2D-rendered convex primitives. This step establishes a direct mapping between the 3D model and its 2D representation, effectively learning the transition from a 3D model to an image. Once the model is fully trained, it offers remarkable control over the synthesis of novel and edited scenes. This is achieved by manipulating the primitives at test time, including translating or adding them, thereby enabling a highly customizable scene rendering process. Our method provides a fresh perspective on 3D scene rendering and editing, offering control and flexibility. It opens up new avenues for research and applications in the field, including authoring and data augmentation.
SecureFalcon: The Next Cyber Reasoning System for Cyber Security
Jul 13, 2023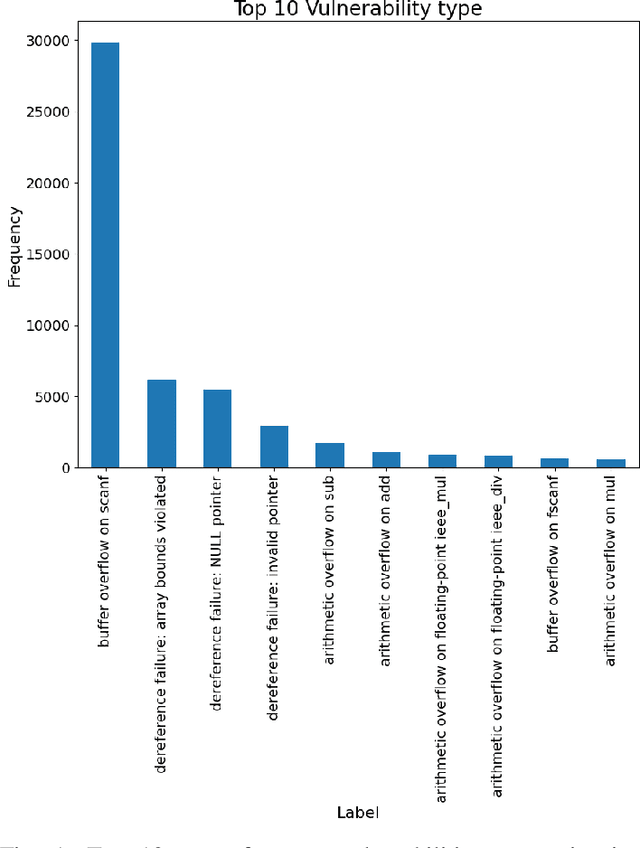
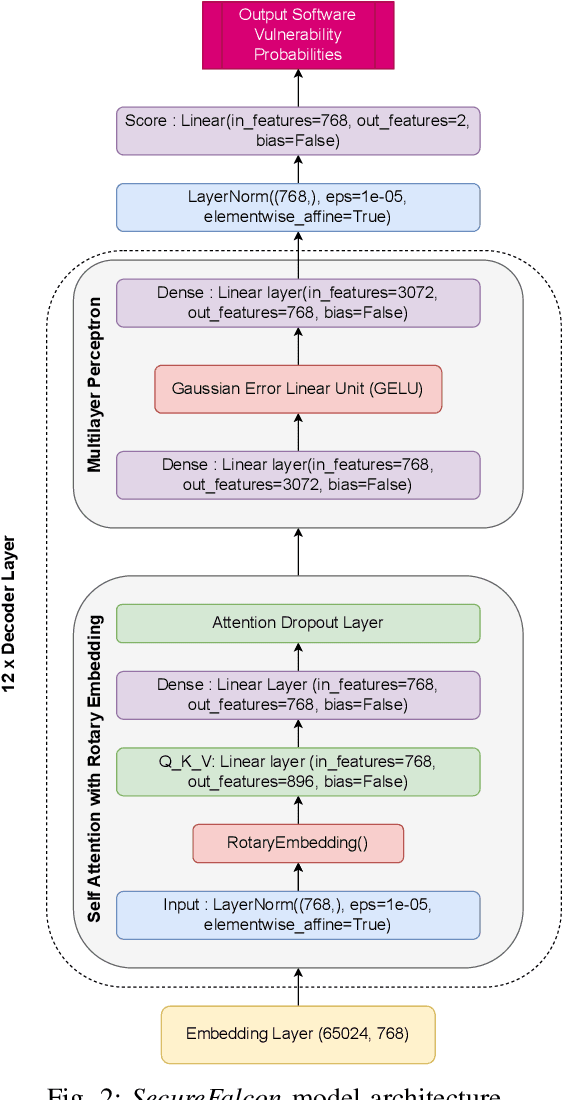
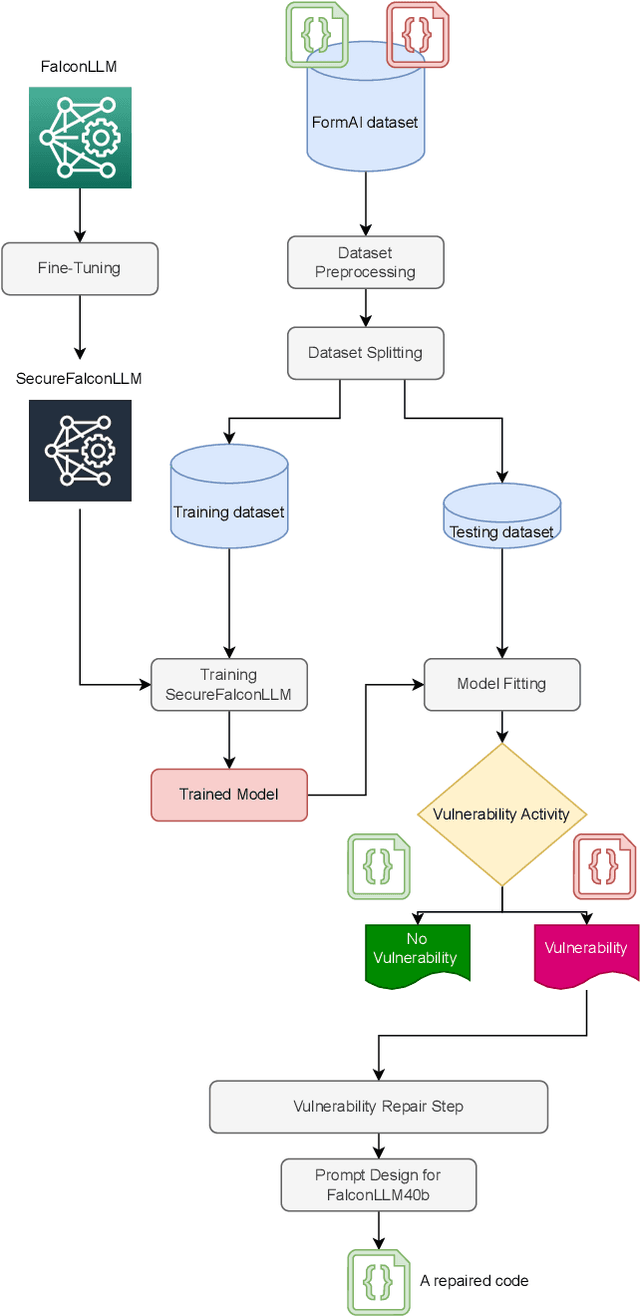
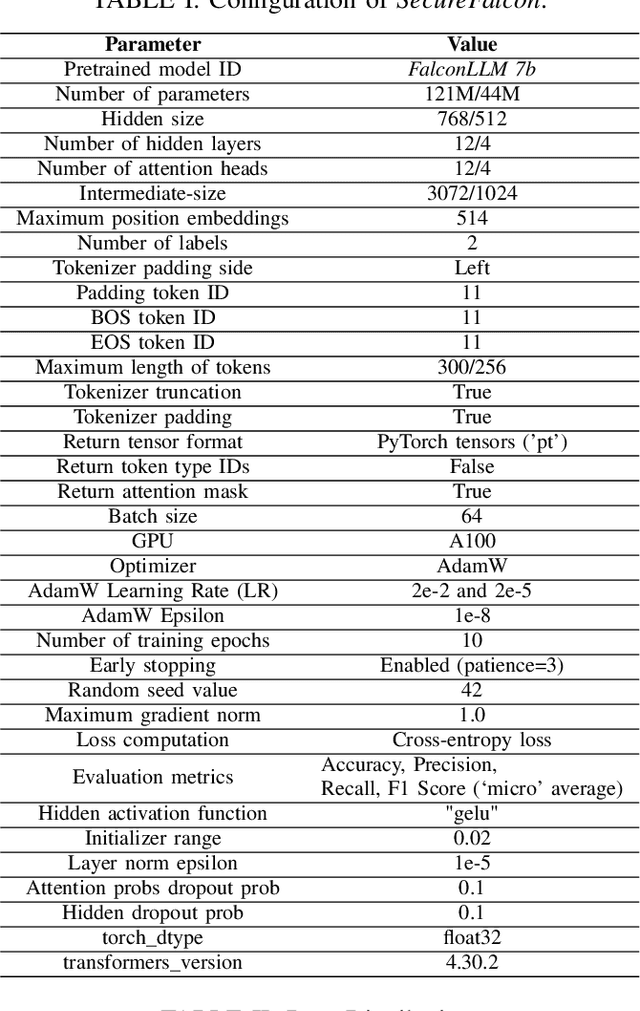
Software vulnerabilities leading to various detriments such as crashes, data loss, and security breaches, significantly hinder the quality, affecting the market adoption of software applications and systems. Although traditional methods such as automated software testing, fault localization, and repair have been intensively studied, static analysis tools are most commonly used and have an inherent false positives rate, posing a solid challenge to developer productivity. Large Language Models (LLMs) offer a promising solution to these persistent issues. Among these, FalconLLM has shown substantial potential in identifying intricate patterns and complex vulnerabilities, hence crucial in software vulnerability detection. In this paper, for the first time, FalconLLM is being fine-tuned for cybersecurity applications, thus introducing SecureFalcon, an innovative model architecture built upon FalconLLM. SecureFalcon is trained to differentiate between vulnerable and non-vulnerable C code samples. We build a new training dataset, FormAI, constructed thanks to Generative Artificial Intelligence (AI) and formal verification to evaluate its performance. SecureFalcon achieved an impressive 94% accuracy rate in detecting software vulnerabilities, emphasizing its significant potential to redefine software vulnerability detection methods in cybersecurity.