 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Low-Complexity Beamforming Design for Beyond-Diagonal RIS aided Multi-User Networks
Jul 19, 2023
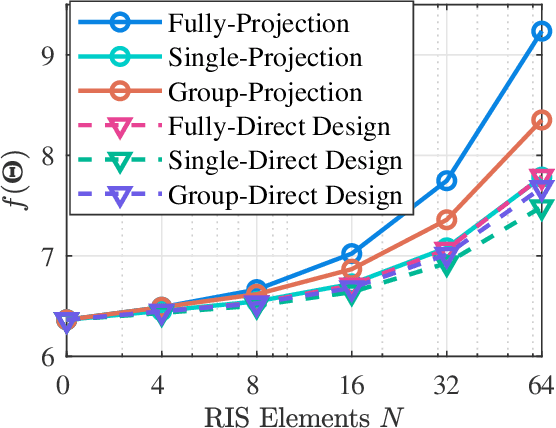
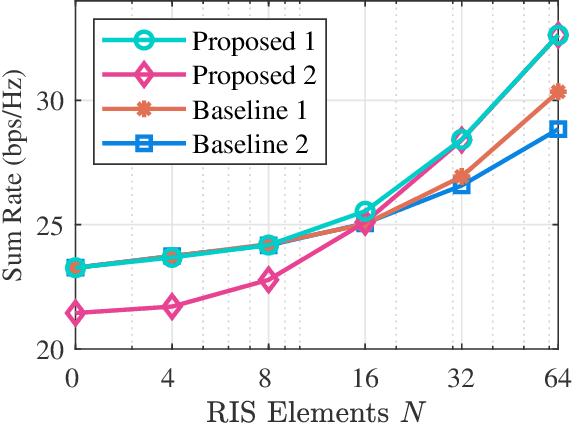
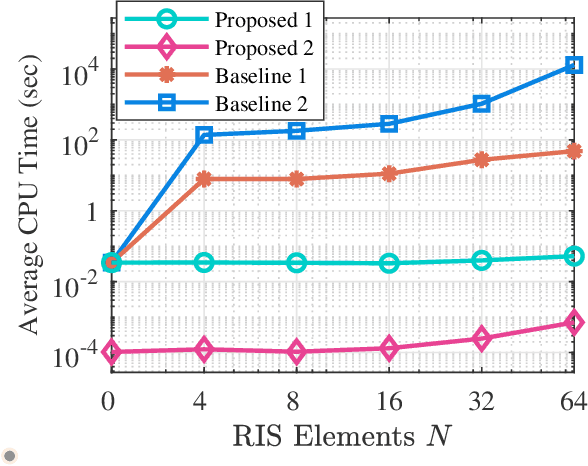
Beyond-diagonal reconfigurable intelligent surface (BD-RIS) has been proposed recently as a novel and generalized RIS architecture that offers enhanced wave manipulation flexibility and large coverage expansion. However, the beyond-diagonal mathematical model in BD-RIS inevitably introduces additional optimization challenges in beamforming design. In this letter, we derive a closed-form solution for the BD-RIS passive beamforming matrix that maximizes the sum of the effective channel gains among users. We further propose a computationally efficient two-stage beamforming framework to jointly design the active beamforming at the base station and passive beamforming at the BD-RIS to enhance the sum-rate for a BD-RIS aided multi-user multi-antenna network.Numerical results show that our proposed algorithm achieves a higher sum-rate while requiring less computation time compared to state-of-the-art algorithms. The proposed algorithm paves the way for practical beamforming design in BD-RIS aided wireless networks.
Amortised Design Optimization for Item Response Theory
Jul 19, 2023Item Response Theory (IRT) is a well known method for assessing responses from humans in education and psychology. In education, IRT is used to infer student abilities and characteristics of test items from student responses. Interactions with students are expensive, calling for methods that efficiently gather information for inferring student abilities. Methods based on Optimal Experimental Design (OED) are computationally costly, making them inapplicable for interactive applications. In response, we propose incorporating amortised experimental design into IRT. Here, the computational cost is shifted to a precomputing phase by training a Deep Reinforcement Learning (DRL) agent with synthetic data. The agent is trained to select optimally informative test items for the distribution of students, and to conduct amortised inference conditioned on the experiment outcomes. During deployment the agent estimates parameters from data, and suggests the next test item for the student, in close to real-time, by taking into account the history of experiments and outcomes.
Multi-Stage Cable Routing through Hierarchical Imitation Learning
Jul 23, 2023
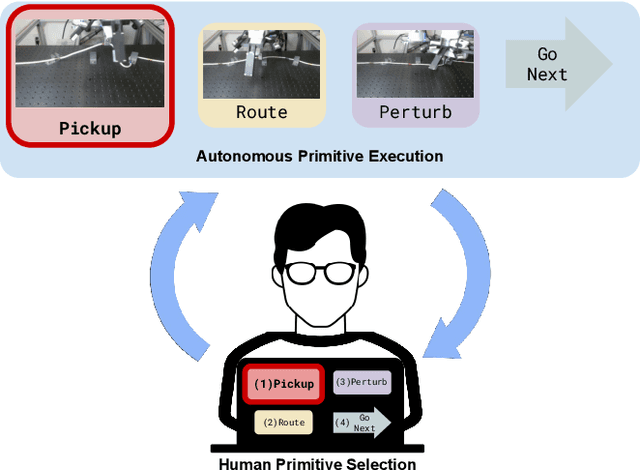

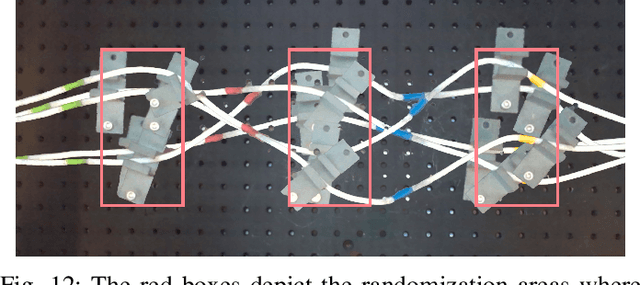
We study the problem of learning to perform multi-stage robotic manipulation tasks, with applications to cable routing, where the robot must route a cable through a series of clips. This setting presents challenges representative of complex multi-stage robotic manipulation scenarios: handling deformable objects, closing the loop on visual perception, and handling extended behaviors consisting of multiple steps that must be executed successfully to complete the entire task. In such settings, learning individual primitives for each stage that succeed with a high enough rate to perform a complete temporally extended task is impractical: if each stage must be completed successfully and has a non-negligible probability of failure, the likelihood of successful completion of the entire task becomes negligible. Therefore, successful controllers for such multi-stage tasks must be able to recover from failure and compensate for imperfections in low-level controllers by smartly choosing which controllers to trigger at any given time, retrying, or taking corrective action as needed. To this end, we describe an imitation learning system that uses vision-based policies trained from demonstrations at both the lower (motor control) and the upper (sequencing) level, present a system for instantiating this method to learn the cable routing task, and perform evaluations showing great performance in generalizing to very challenging clip placement variations. Supplementary videos, datasets, and code can be found at https://sites.google.com/view/cablerouting.
ASCON: Anatomy-aware Supervised Contrastive Learning Framework for Low-dose CT Denoising
Jul 23, 2023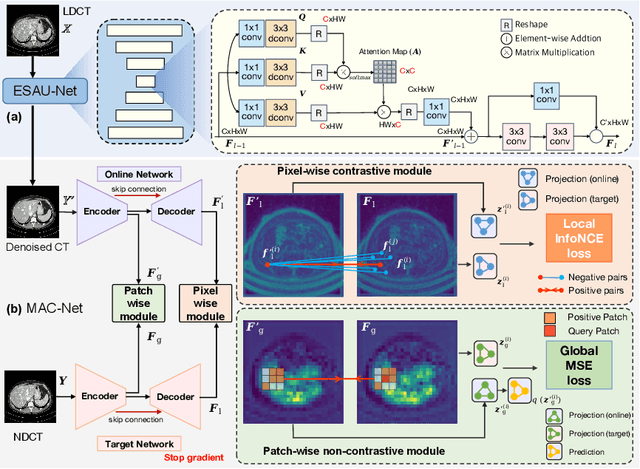
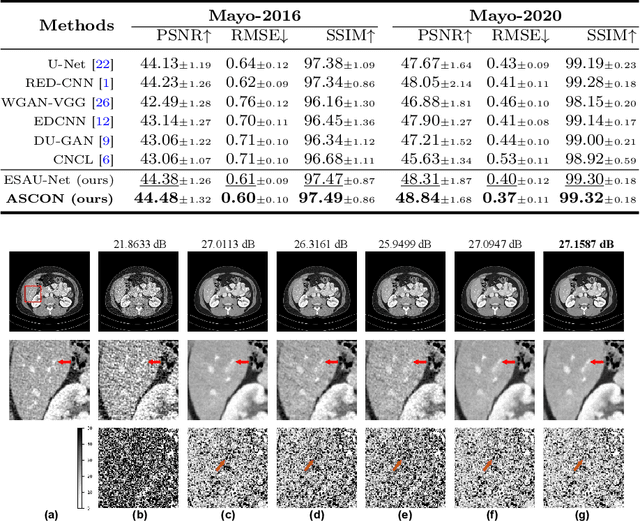
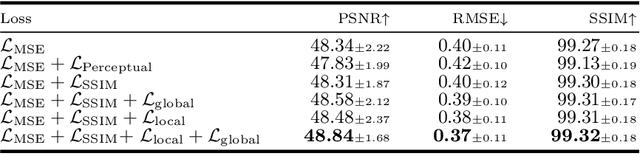

While various deep learning methods have been proposed for low-dose computed tomography (CT) denoising, most of them leverage the normal-dose CT images as the ground-truth to supervise the denoising process. These methods typically ignore the inherent correlation within a single CT image, especially the anatomical semantics of human tissues, and lack the interpretability on the denoising process. In this paper, we propose a novel Anatomy-aware Supervised CONtrastive learning framework, termed ASCON, which can explore the anatomical semantics for low-dose CT denoising while providing anatomical interpretability. The proposed ASCON consists of two novel designs: an efficient self-attention-based U-Net (ESAU-Net) and a multi-scale anatomical contrastive network (MAC-Net). First, to better capture global-local interactions and adapt to the high-resolution input, an efficient ESAU-Net is introduced by using a channel-wise self-attention mechanism. Second, MAC-Net incorporates a patch-wise non-contrastive module to capture inherent anatomical information and a pixel-wise contrastive module to maintain intrinsic anatomical consistency. Extensive experimental results on two public low-dose CT denoising datasets demonstrate superior performance of ASCON over state-of-the-art models. Remarkably, our ASCON provides anatomical interpretability for low-dose CT denoising for the first time. Source code is available at https://github.com/hao1635/ASCON.
Scale jump-aware pose graph relaxation for monocular SLAM with re-initializations
Jul 23, 2023
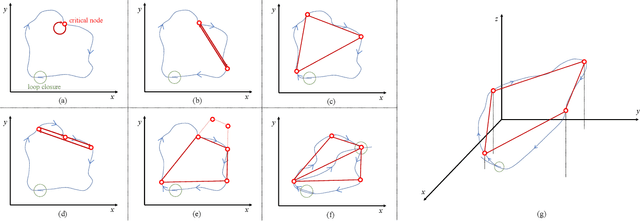
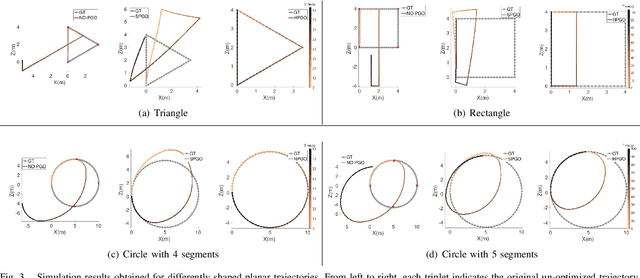
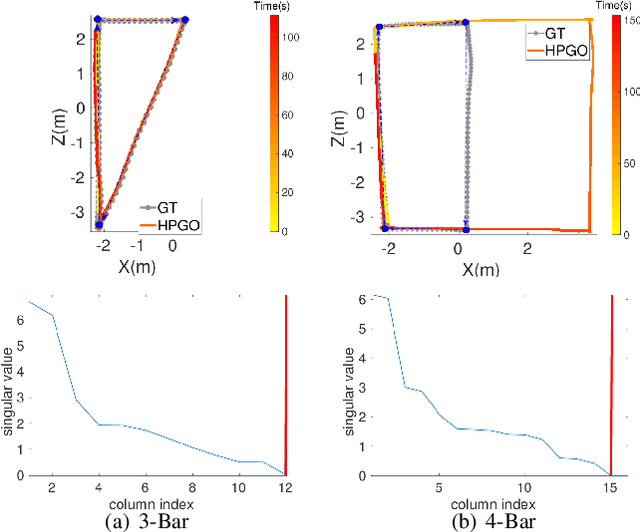
Pose graph relaxation has become an indispensable addition to SLAM enabling efficient global registration of sensor reference frames under the objective of satisfying pair-wise relative transformation constraints. The latter may be given by incremental motion estimation or global place recognition. While the latter case enables loop closures and drift compensation, care has to be taken in the monocular case in which local estimates of structure and displacements can differ from reality not just in terms of noise, but also in terms of a scale factor. Owing to the accumulation of scale propagation errors, this scale factor is drifting over time, hence scale-drift aware pose graph relaxation has been introduced. We extend this idea to cases in which the relative scale between subsequent sensor frames is unknown, a situation that can easily occur if monocular SLAM enters re-initialization and no reliable overlap between successive local maps can be identified. The approach is realized by a hybrid pose graph formulation that combines the regular similarity consistency terms with novel, scale-blind constraints. We apply the technique to the practically relevant case of small indoor service robots capable of effectuating purely rotational displacements, a condition that can easily cause tracking failures. We demonstrate that globally consistent trajectories can be recovered even if multiple re-initializations occur along the loop, and present an in-depth study of success and failure cases.
Towards Generalizable Detection of Urgency of Discussion Forum Posts
Jul 14, 2023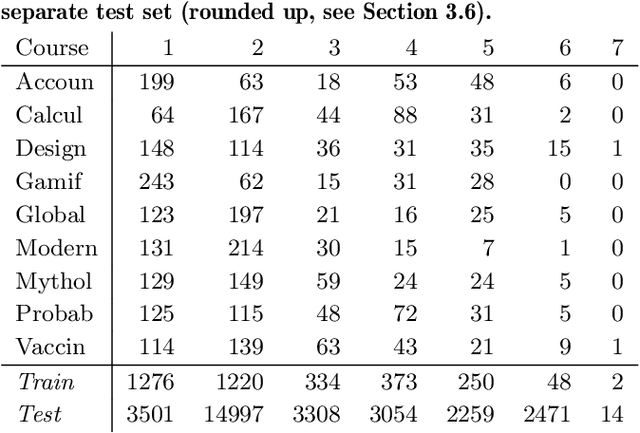
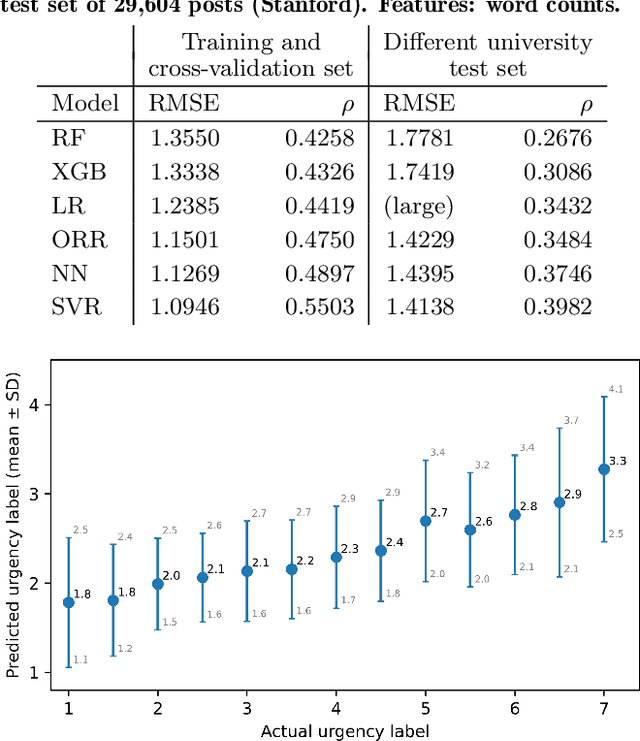
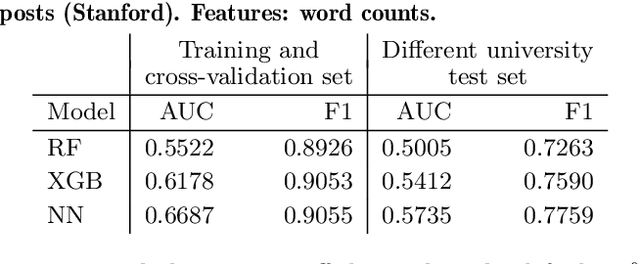
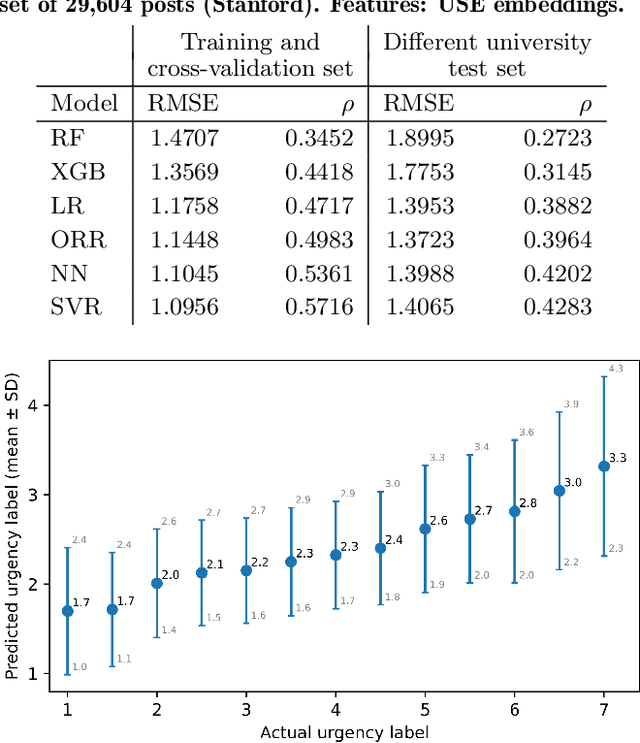
Students who take an online course, such as a MOOC, use the course's discussion forum to ask questions or reach out to instructors when encountering an issue. However, reading and responding to students' questions is difficult to scale because of the time needed to consider each message. As a result, critical issues may be left unresolved, and students may lose the motivation to continue in the course. To help address this problem, we build predictive models that automatically determine the urgency of each forum post, so that these posts can be brought to instructors' attention. This paper goes beyond previous work by predicting not just a binary decision cut-off but a post's level of urgency on a 7-point scale. First, we train and cross-validate several models on an original data set of 3,503 posts from MOOCs at University of Pennsylvania. Second, to determine the generalizability of our models, we test their performance on a separate, previously published data set of 29,604 posts from MOOCs at Stanford University. While the previous work on post urgency used only one data set, we evaluated the prediction across different data sets and courses. The best-performing model was a support vector regressor trained on the Universal Sentence Encoder embeddings of the posts, achieving an RMSE of 1.1 on the training set and 1.4 on the test set. Understanding the urgency of forum posts enables instructors to focus their time more effectively and, as a result, better support student learning.
DHC: Dual-debiased Heterogeneous Co-training Framework for Class-imbalanced Semi-supervised Medical Image Segmentation
Jul 22, 2023The volume-wise labeling of 3D medical images is expertise-demanded and time-consuming; hence semi-supervised learning (SSL) is highly desirable for training with limited labeled data. Imbalanced class distribution is a severe problem that bottlenecks the real-world application of these methods but was not addressed much. Aiming to solve this issue, we present a novel Dual-debiased Heterogeneous Co-training (DHC) framework for semi-supervised 3D medical image segmentation. Specifically, we propose two loss weighting strategies, namely Distribution-aware Debiased Weighting (DistDW) and Difficulty-aware Debiased Weighting (DiffDW), which leverage the pseudo labels dynamically to guide the model to solve data and learning biases. The framework improves significantly by co-training these two diverse and accurate sub-models. We also introduce more representative benchmarks for class-imbalanced semi-supervised medical image segmentation, which can fully demonstrate the efficacy of the class-imbalance designs. Experiments show that our proposed framework brings significant improvements by using pseudo labels for debiasing and alleviating the class imbalance problem. More importantly, our method outperforms the state-of-the-art SSL methods, demonstrating the potential of our framework for the more challenging SSL setting. Code and models are available at: https://github.com/xmed-lab/DHC.
Synthesis of Batik Motifs using a Diffusion -- Generative Adversarial Network
Jul 22, 2023Batik, a unique blend of art and craftsmanship, is a distinct artistic and technological creation for Indonesian society. Research on batik motifs is primarily focused on classification. However, further studies may extend to the synthesis of batik patterns. Generative Adversarial Networks (GANs) have been an important deep learning model for generating synthetic data, but often face challenges in the stability and consistency of results. This research focuses on the use of StyleGAN2-Ada and Diffusion techniques to produce realistic and high-quality synthetic batik patterns. StyleGAN2-Ada is a variation of the GAN model that separates the style and content aspects in an image, whereas diffusion techniques introduce random noise into the data. In the context of batik, StyleGAN2-Ada and Diffusion are used to produce realistic synthetic batik patterns. This study also made adjustments to the model architecture and used a well-curated batik dataset. The main goal is to assist batik designers or craftsmen in producing unique and quality batik motifs with efficient production time and costs. Based on qualitative and quantitative evaluations, the results show that the model tested is capable of producing authentic and quality batik patterns, with finer details and rich artistic variations. The dataset and code can be accessed here:https://github.com/octadion/diffusion-stylegan2-ada-pytorch
Discovering Spatio-Temporal Rationales for Video Question Answering
Jul 22, 2023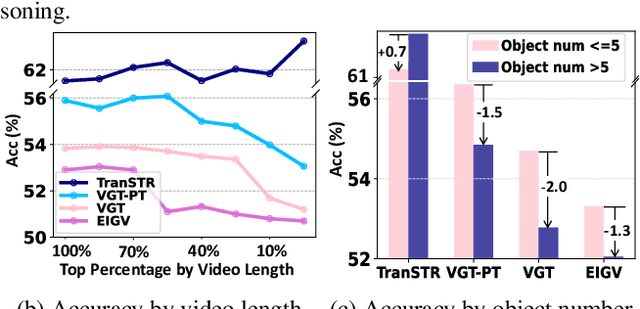
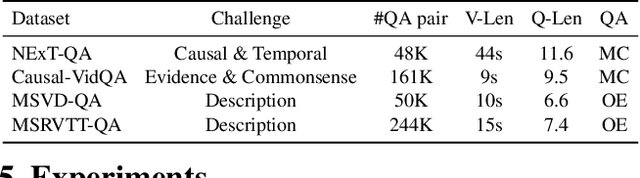
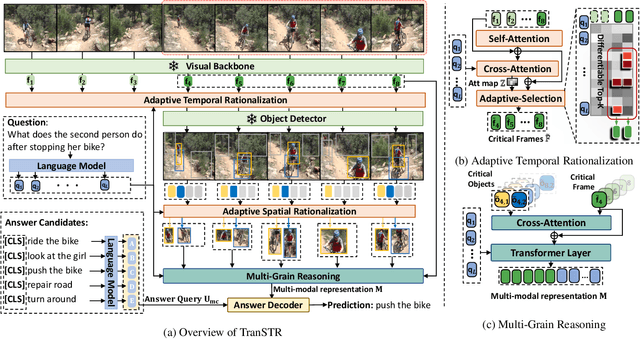
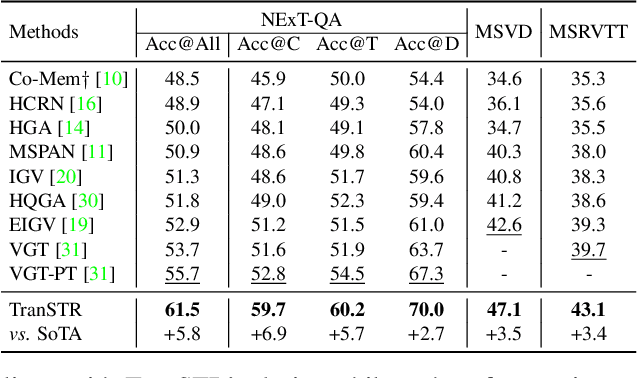
This paper strives to solve complex video question answering (VideoQA) which features long video containing multiple objects and events at different time. To tackle the challenge, we highlight the importance of identifying question-critical temporal moments and spatial objects from the vast amount of video content. Towards this, we propose a Spatio-Temporal Rationalization (STR), a differentiable selection module that adaptively collects question-critical moments and objects using cross-modal interaction. The discovered video moments and objects are then served as grounded rationales to support answer reasoning. Based on STR, we further propose TranSTR, a Transformer-style neural network architecture that takes STR as the core and additionally underscores a novel answer interaction mechanism to coordinate STR for answer decoding. Experiments on four datasets show that TranSTR achieves new state-of-the-art (SoTA). Especially, on NExT-QA and Causal-VidQA which feature complex VideoQA, it significantly surpasses the previous SoTA by 5.8\% and 6.8\%, respectively. We then conduct extensive studies to verify the importance of STR as well as the proposed answer interaction mechanism. With the success of TranSTR and our comprehensive analysis, we hope this work can spark more future efforts in complex VideoQA. Code will be released at https://github.com/yl3800/TranSTR.
Applications of Machine Learning to Modelling and Analysing Dynamical Systems
Jul 22, 2023We explore the use of Physics Informed Neural Networks to analyse nonlinear Hamiltonian Dynamical Systems with a first integral of motion. In this work, we propose an architecture which combines existing Hamiltonian Neural Network structures into Adaptable Symplectic Recurrent Neural Networks which preserve Hamilton's equations as well as the symplectic structure of phase space while predicting dynamics for the entire parameter space. This architecture is found to significantly outperform previously proposed neural networks when predicting Hamiltonian dynamics especially in potentials which contain multiple parameters. We demonstrate its robustness using the nonlinear Henon-Heiles potential under chaotic, quasiperiodic and periodic conditions. The second problem we tackle is whether we can use the high dimensional nonlinear capabilities of neural networks to predict the dynamics of a Hamiltonian system given only partial information of the same. Hence we attempt to take advantage of Long Short Term Memory networks to implement Takens' embedding theorem and construct a delay embedding of the system followed by mapping the topologically invariant attractor to the true form. This architecture is then layered with Adaptable Symplectic nets to allow for predictions which preserve the structure of Hamilton's equations. We show that this method works efficiently for single parameter potentials and provides accurate predictions even over long periods of time.