 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Real-time and Robust Feature Detection of Continuous Marker Pattern for Dense 3-D Deformation Measurement
May 22, 2023

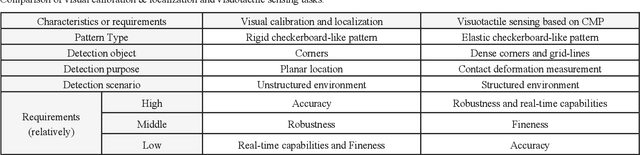
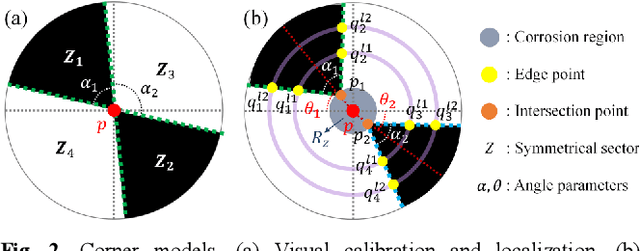
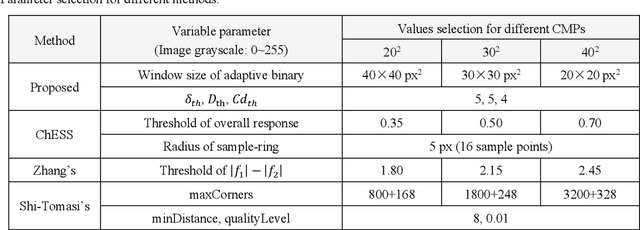
Visuotactile sensing technology has received much attention in recent years. This article proposes a feature detection method applicable to visuotactile sensors based on continuous marker patterns (CMP) to measure 3-d deformation. First, we construct the feature model of checkerboard-like corners under contact deformation, and design a novel double-layer circular sampler. Then, we propose the judging criteria and response function of corner features by analyzing sampling signals' amplitude-frequency characteristics and circular cross-correlation behavior. The proposed feature detection algorithm fully considers the boundary characteristics retained by the corners with geometric distortion, thus enabling reliable detection at a low calculation cost. The experimental results show that the proposed method has significant advantages in terms of real-time and robustness. Finally, we have achieved the high-density 3-d contact deformation visualization based on this detection method. This technique is able to clearly record the process of contact deformation, thus enabling inverse sensing of dynamic contact processes.
Auto-CARD: Efficient and Robust Codec Avatar Driving for Real-time Mobile Telepresence
Apr 24, 2023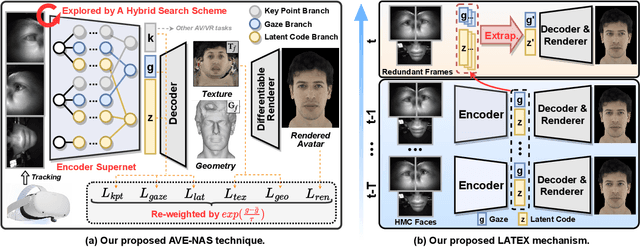
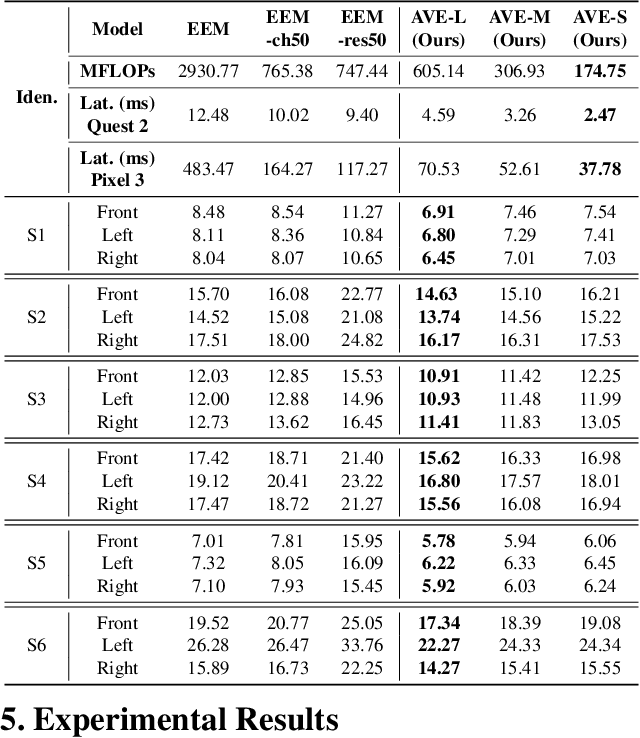

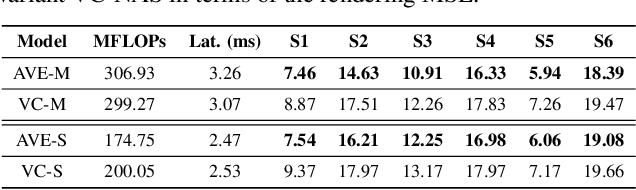
Real-time and robust photorealistic avatars for telepresence in AR/VR have been highly desired for enabling immersive photorealistic telepresence. However, there still exists one key bottleneck: the considerable computational expense needed to accurately infer facial expressions captured from headset-mounted cameras with a quality level that can match the realism of the avatar's human appearance. To this end, we propose a framework called Auto-CARD, which for the first time enables real-time and robust driving of Codec Avatars when exclusively using merely on-device computing resources. This is achieved by minimizing two sources of redundancy. First, we develop a dedicated neural architecture search technique called AVE-NAS for avatar encoding in AR/VR, which explicitly boosts both the searched architectures' robustness in the presence of extreme facial expressions and hardware friendliness on fast evolving AR/VR headsets. Second, we leverage the temporal redundancy in consecutively captured images during continuous rendering and develop a mechanism dubbed LATEX to skip the computation of redundant frames. Specifically, we first identify an opportunity from the linearity of the latent space derived by the avatar decoder and then propose to perform adaptive latent extrapolation for redundant frames. For evaluation, we demonstrate the efficacy of our Auto-CARD framework in real-time Codec Avatar driving settings, where we achieve a 5.05x speed-up on Meta Quest 2 while maintaining a comparable or even better animation quality than state-of-the-art avatar encoder designs.
Geometric Ultrasound Localization Microscopy
Jul 18, 2023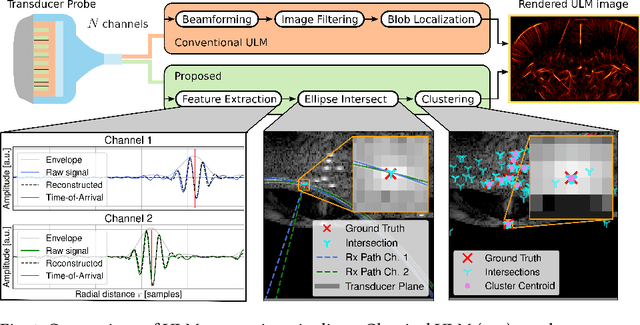
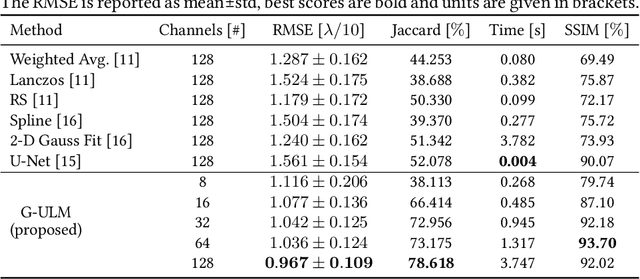
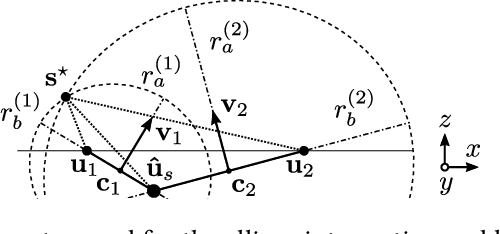
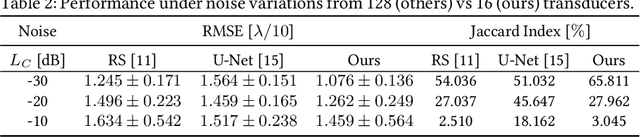
Contrast-Enhanced Ultra-Sound (CEUS) has become a viable method for non-invasive, dynamic visualization in medical diagnostics, yet Ultrasound Localization Microscopy (ULM) has enabled a revolutionary breakthrough by offering ten times higher resolution. To date, Delay-And-Sum (DAS) beamformers are used to render ULM frames, ultimately determining the image resolution capability. To take full advantage of ULM, this study questions whether beamforming is the most effective processing step for ULM, suggesting an alternative approach that relies solely on Time-Difference-of-Arrival (TDoA) information. To this end, a novel geometric framework for micro bubble localization via ellipse intersections is proposed to overcome existing beamforming limitations. We present a benchmark comparison based on a public dataset for which our geometric ULM outperforms existing baseline methods in terms of accuracy and robustness while only utilizing a portion of the available transducer data.
Sharpness-Aware Graph Collaborative Filtering
Jul 18, 2023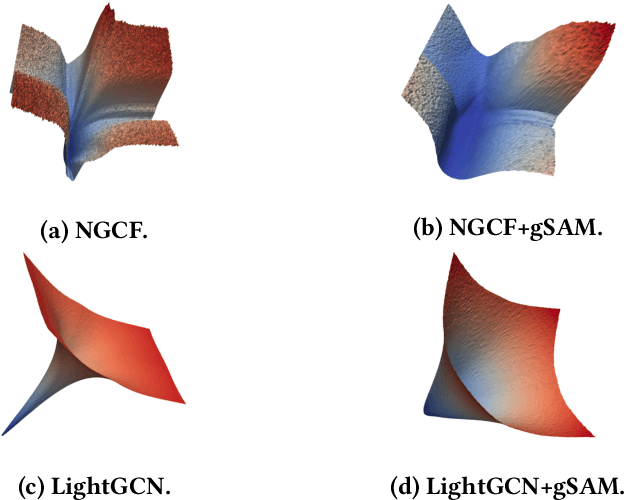
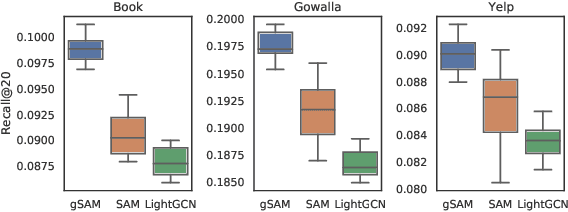
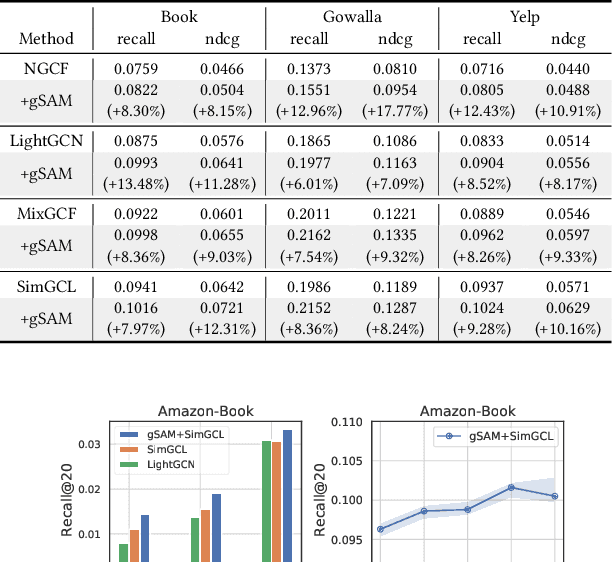
Graph Neural Networks (GNNs) have achieved impressive performance in collaborative filtering. However, GNNs tend to yield inferior performance when the distributions of training and test data are not aligned well. Also, training GNNs requires optimizing non-convex neural networks with an abundance of local and global minima, which may differ widely in their performance at test time. Thus, it is essential to choose the minima carefully. Here we propose an effective training schema, called {gSAM}, under the principle that the \textit{flatter} minima has a better generalization ability than the \textit{sharper} ones. To achieve this goal, gSAM regularizes the flatness of the weight loss landscape by forming a bi-level optimization: the outer problem conducts the standard model training while the inner problem helps the model jump out of the sharp minima. Experimental results show the superiority of our gSAM.
Online Self-Supervised Thermal Water Segmentation for Aerial Vehicles
Jul 18, 2023We present a new method to adapt an RGB-trained water segmentation network to target-domain aerial thermal imagery using online self-supervision by leveraging texture and motion cues as supervisory signals. This new thermal capability enables current autonomous aerial robots operating in near-shore environments to perform tasks such as visual navigation, bathymetry, and flow tracking at night. Our method overcomes the problem of scarce and difficult-to-obtain near-shore thermal data that prevents the application of conventional supervised and unsupervised methods. In this work, we curate the first aerial thermal near-shore dataset, show that our approach outperforms fully-supervised segmentation models trained on limited target-domain thermal data, and demonstrate real-time capabilities onboard an Nvidia Jetson embedded computing platform. Code and datasets used in this work will be available at: https://github.com/connorlee77/uav-thermal-water-segmentation.
PLiNIO: A User-Friendly Library of Gradient-based Methods for Complexity-aware DNN Optimization
Jul 18, 2023
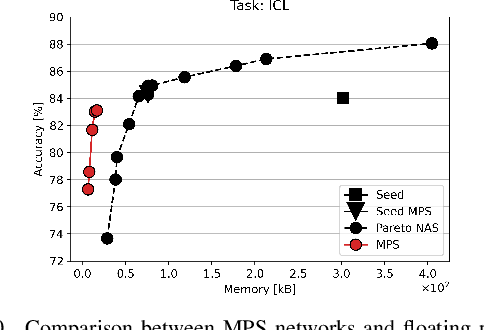
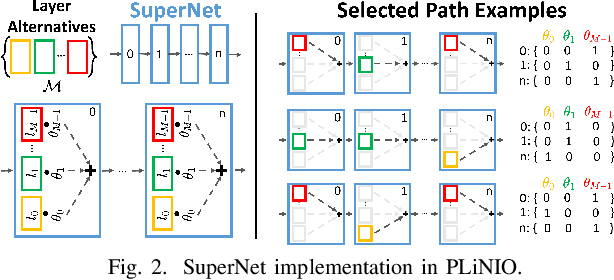
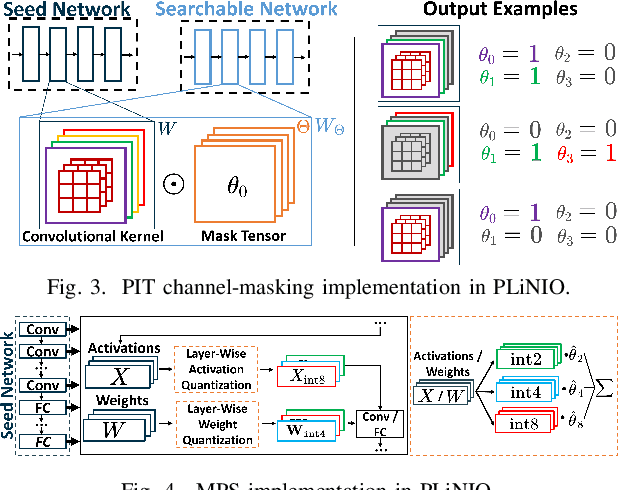
Accurate yet efficient Deep Neural Networks (DNNs) are in high demand, especially for applications that require their execution on constrained edge devices. Finding such DNNs in a reasonable time for new applications requires automated optimization pipelines since the huge space of hyper-parameter combinations is impossible to explore extensively by hand. In this work, we propose PLiNIO, an open-source library implementing a comprehensive set of state-of-the-art DNN design automation techniques, all based on lightweight gradient-based optimization, under a unified and user-friendly interface. With experiments on several edge-relevant tasks, we show that combining the various optimizations available in PLiNIO leads to rich sets of solutions that Pareto-dominate the considered baselines in terms of accuracy vs model size. Noteworthy, PLiNIO achieves up to 94.34% memory reduction for a <1% accuracy drop compared to a baseline architecture.
Prawn Morphometrics and Weight Estimation from Images using Deep Learning for Landmark Localization
Jul 15, 2023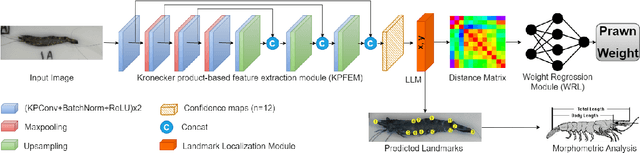


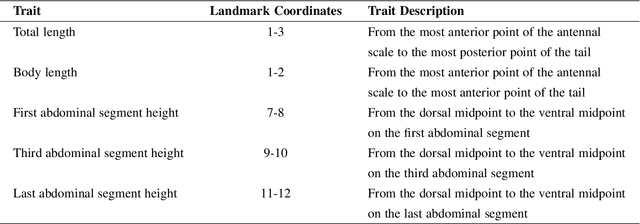
Accurate weight estimation and morphometric analyses are useful in aquaculture for optimizing feeding, predicting harvest yields, identifying desirable traits for selective breeding, grading processes, and monitoring the health status of production animals. However, the collection of phenotypic data through traditional manual approaches at industrial scales and in real-time is time-consuming, labour-intensive, and prone to errors. Digital imaging of individuals and subsequent training of prediction models using Deep Learning (DL) has the potential to rapidly and accurately acquire phenotypic data from aquaculture species. In this study, we applied a novel DL approach to automate weight estimation and morphometric analysis using the black tiger prawn (Penaeus monodon) as a model crustacean. The DL approach comprises two main components: a feature extraction module that efficiently combines low-level and high-level features using the Kronecker product operation; followed by a landmark localization module that then uses these features to predict the coordinates of key morphological points (landmarks) on the prawn body. Once these landmarks were extracted, weight was estimated using a weight regression module based on the extracted landmarks using a fully connected network. For morphometric analyses, we utilized the detected landmarks to derive five important prawn traits. Principal Component Analysis (PCA) was also used to identify landmark-derived distances, which were found to be highly correlated with shape features such as body length, and width. We evaluated our approach on a large dataset of 8164 images of the Black tiger prawn (Penaeus monodon) collected from Australian farms. Our experimental results demonstrate that the novel DL approach outperforms existing DL methods in terms of accuracy, robustness, and efficiency.
A Synthetic Electrocardiogram (ECG) Image Generation Toolbox to Facilitate Deep Learning-Based Scanned ECG Digitization
Jul 04, 2023

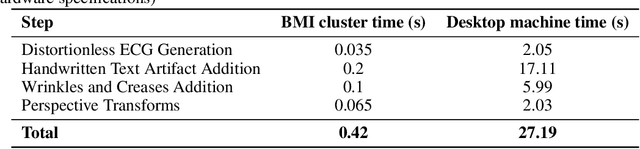
Access to medical data is often limited as it contains protected health information (PHI). There are privacy concerns regarding using records containing personally identifiable information. Recent advancements have been made in applying deep learning-based algorithms for clinical diagnosis and decision-making. However, deep learning models are data-greedy, whereas the availability of medical datasets for training and evaluating these models is relatively limited. Data augmentation with so-called \textit{digital twins} is an emerging technique to address this need. This paper presents a novel approach for generating synthetic electrocardiogram (ECG) images with realistic artifacts from time-series data for use in developing algorithms for digitization of ECG images. Synthetic data is generated in a privacy-preserving manner by generating distortionless ECG images on standard ECG paper background. Next, various distortions, including handwritten text artifacts, wrinkles, creases, and perspective transforms are applied to the ECG images. The artifacts are generated synthetically, without personally identifiable information. As a use case, we generated a large ECG image dataset of 21,801 records from the PhysioNet PTB-XL dataset, with 12 lead ECG time-series data from 18,869 patients. A deep ECG image digitization model was developed and trained on the synthetic dataset, and was employed to convert the synthetic images to time-series data for evaluation. The signal-to-noise ratio (SNR) was calculated to assess the image digitization quality vs the ground truth ECG time-series. The results show an average signal recovery SNR of 27$\pm$2.8\,dB, demonstrating the significance of the proposed synthetic ECG image dataset for training deep learning models.
From $O(\sqrt{n})$ to $O(\log(n))$ in Quadratic Programming
Jul 19, 2023
A "dark cloud" hangs over numerical optimization theory for decades, namely, whether an optimization algorithm $O(\log(n))$ iteration complexity exists. "Yes", this paper answers, with a new optimization algorithm and strict theory proof. It starts with box-constrained quadratic programming (Box-QP), and many practical optimization problems fall into Box-QP. General smooth quadratic programming (QP), nonsmooth Lasso, and support vector machine (or regression) can be reformulated as Box-QP via duality theory. It is the first time to present an $O(\log(n))$ iteration complexity QP algorithm, in particular, which behaves like a "direct" method: the required number of iterations is deterministic with exact value $\left\lceil\log\left(\frac{3.125n}{\epsilon}\right)/\log(1.5625)\right\rceil$. This significant breakthrough enables us to transition from the $O(\sqrt{n})$ to the $O(\log(n))$ optimization algorithm, whose amazing scalability is particularly relevant in today's era of big data and artificial intelligence.
A Low-Complexity Beamforming Design for Beyond-Diagonal RIS aided Multi-User Networks
Jul 19, 2023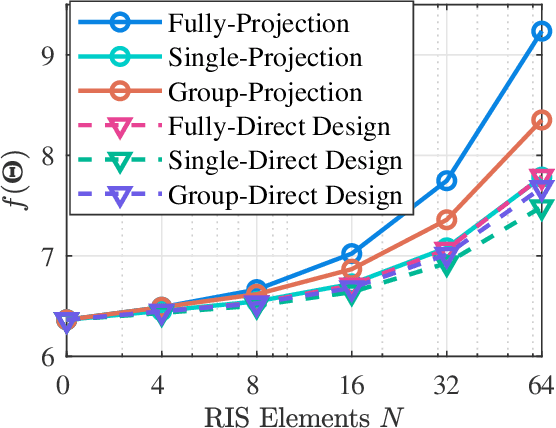
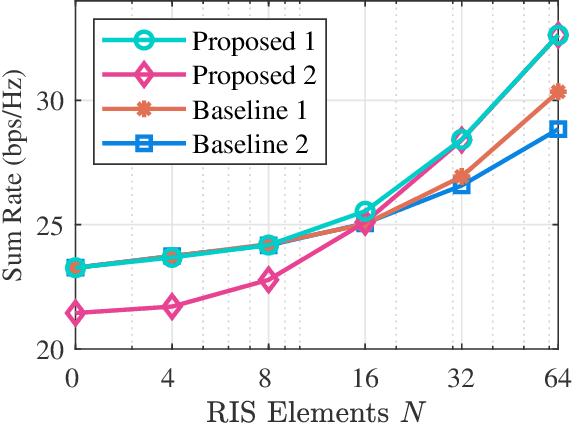
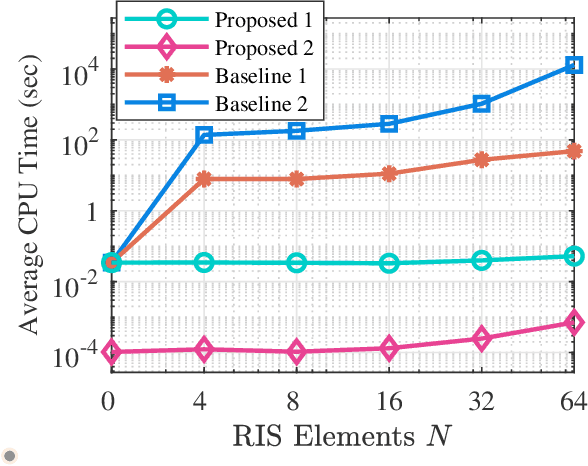
Beyond-diagonal reconfigurable intelligent surface (BD-RIS) has been proposed recently as a novel and generalized RIS architecture that offers enhanced wave manipulation flexibility and large coverage expansion. However, the beyond-diagonal mathematical model in BD-RIS inevitably introduces additional optimization challenges in beamforming design. In this letter, we derive a closed-form solution for the BD-RIS passive beamforming matrix that maximizes the sum of the effective channel gains among users. We further propose a computationally efficient two-stage beamforming framework to jointly design the active beamforming at the base station and passive beamforming at the BD-RIS to enhance the sum-rate for a BD-RIS aided multi-user multi-antenna network.Numerical results show that our proposed algorithm achieves a higher sum-rate while requiring less computation time compared to state-of-the-art algorithms. The proposed algorithm paves the way for practical beamforming design in BD-RIS aided wireless networks.