 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Tachikuma: Understading Complex Interactions with Multi-Character and Novel Objects by Large Language Models
Jul 24, 2023

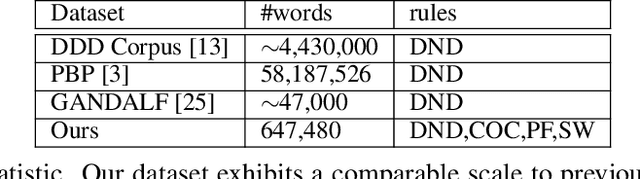

Recent advancements in natural language and Large Language Models (LLMs) have enabled AI agents to simulate human-like interactions within virtual worlds. However, these interactions still face limitations in complexity and flexibility, particularly in scenarios involving multiple characters and novel objects. Pre-defining all interactable objects in the agent's world model presents challenges, and conveying implicit intentions to multiple characters through complex interactions remains difficult. To address these issues, we propose integrating virtual Game Masters (GMs) into the agent's world model, drawing inspiration from Tabletop Role-Playing Games (TRPGs). GMs play a crucial role in overseeing information, estimating players' intentions, providing environment descriptions, and offering feedback, compensating for current world model deficiencies. To facilitate future explorations for complex interactions, we introduce a benchmark named Tachikuma, comprising a Multiple character and novel Object based interaction Estimation (MOE) task and a supporting dataset. MOE challenges models to understand characters' intentions and accurately determine their actions within intricate contexts involving multi-character and novel object interactions. Besides, the dataset captures log data from real-time communications during gameplay, providing diverse, grounded, and complex interactions for further explorations. Finally, we present a simple prompting baseline and evaluate its performance, demonstrating its effectiveness in enhancing interaction understanding. We hope that our dataset and task will inspire further research in complex interactions with natural language, fostering the development of more advanced AI agents.
Optimized data collection and analysis process for studying solar-thermal desalination by machine learning
Jul 24, 2023
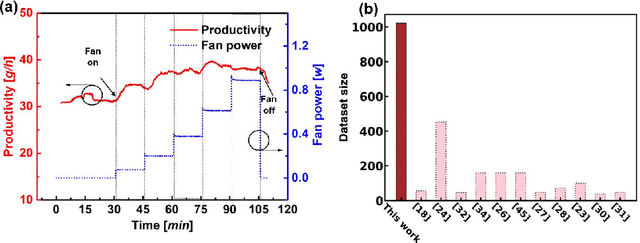

An effective interdisciplinary study between machine learning and solar-thermal desalination requires a sufficiently large and well-analyzed experimental datasets. This study develops a modified dataset collection and analysis process for studying solar-thermal desalination by machine learning. Based on the optimized water condensation and collection process, the proposed experimental method collects over one thousand datasets, which is ten times more than the average number of datasets in previous works, by accelerating data collection and reducing the time by 83.3%. On the other hand, the effects of dataset features are investigated by using three different algorithms, including artificial neural networks, multiple linear regressions, and random forests. The investigation focuses on the effects of dataset size and range on prediction accuracy, factor importance ranking, and the model's generalization ability. The results demonstrate that a larger dataset can significantly improve prediction accuracy when using artificial neural networks and random forests. Additionally, the study highlights the significant impact of dataset size and range on ranking the importance of influence factors. Furthermore, the study reveals that the extrapolation data range significantly affects the extrapolation accuracy of artificial neural networks. Based on the results, massive dataset collection and analysis of dataset feature effects are important steps in an effective and consistent machine learning process flow for solar-thermal desalination, which can promote machine learning as a more general tool in the field of solar-thermal desalination.
Introducing CALMED: Multimodal Annotated Dataset for Emotion Detection in Children with Autism
Jul 24, 2023Automatic Emotion Detection (ED) aims to build systems to identify users' emotions automatically. This field has the potential to enhance HCI, creating an individualised experience for the user. However, ED systems tend to perform poorly on people with Autism Spectrum Disorder (ASD). Hence, the need to create ED systems tailored to how people with autism express emotions. Previous works have created ED systems tailored for children with ASD but did not share the resulting dataset. Sharing annotated datasets is essential to enable the development of more advanced computer models for ED within the research community. In this paper, we describe our experience establishing a process to create a multimodal annotated dataset featuring children with a level 1 diagnosis of autism. In addition, we introduce CALMED (Children, Autism, Multimodal, Emotion, Detection), the resulting multimodal emotion detection dataset featuring children with autism aged 8-12. CALMED includes audio and video features extracted from recording files of study sessions with participants, together with annotations provided by their parents into four target classes. The generated dataset includes a total of 57,012 examples, with each example representing a time window of 200ms (0.2s). Our experience and methods described here, together with the dataset shared, aim to contribute to future research applications of affective computing in ASD, which has the potential to create systems to improve the lives of people with ASD.
Personalized Category Frequency prediction for Buy It Again recommendations
Jul 24, 2023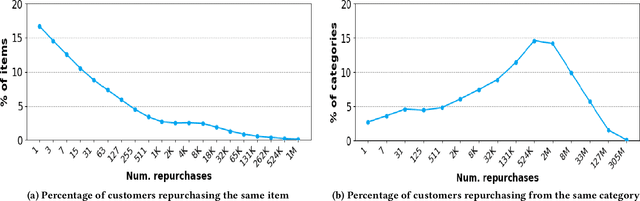
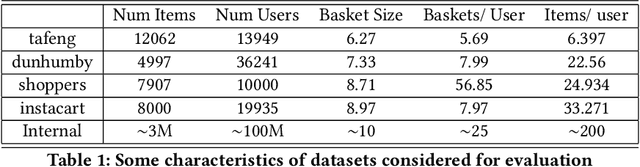
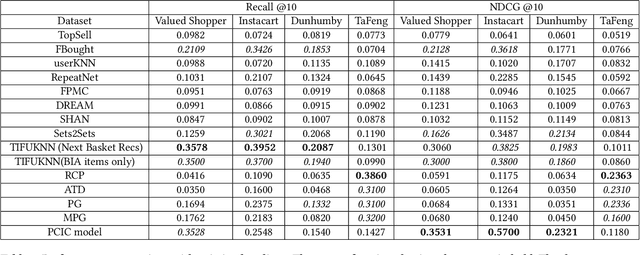
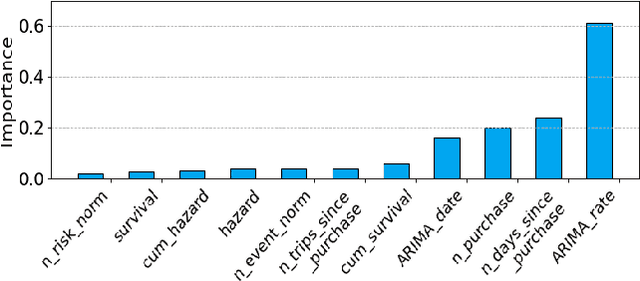
Buy It Again (BIA) recommendations are crucial to retailers to help improve user experience and site engagement by suggesting items that customers are likely to buy again based on their own repeat purchasing patterns. Most existing BIA studies analyze guests personalized behavior at item granularity. A category-based model may be more appropriate in such scenarios. We propose a recommendation system called a hierarchical PCIC model that consists of a personalized category model (PC model) and a personalized item model within categories (IC model). PC model generates a personalized list of categories that customers are likely to purchase again. IC model ranks items within categories that guests are likely to consume within a category. The hierarchical PCIC model captures the general consumption rate of products using survival models. Trends in consumption are captured using time series models. Features derived from these models are used in training a category-grained neural network. We compare PCIC to twelve existing baselines on four standard open datasets. PCIC improves NDCG up to 16 percent while improving recall by around 2 percent. We were able to scale and train (over 8 hours) PCIC on a large dataset of 100M guests and 3M items where repeat categories of a guest out number repeat items. PCIC was deployed and AB tested on the site of a major retailer, leading to significant gains in guest engagement.
FANET Experiment: Real-Time Surveillance Applications Connected to Image Processing System
Jun 15, 2023

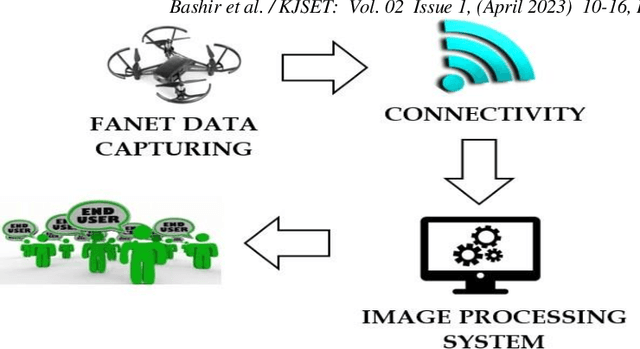
The major goal of this paper is to use image enhancement techniques for enhancing and extracting data in FANET applications to improve the efficiency of surveillance. The proposed conceptual system design can improve the likelihood of FANET operations in oil pipeline surveillance, and sports and media coverage with the ultimate goal of providing efficient services to those who are interested. The system architecture model is based on current scientific principles and developing technologies. A FANET, which is capable of gathering image data from video-enabled drones, and an image processing system that permits data collection and analysis are the two primary components of the system. Based on the image processing technique, a proof of concept for efficient data extraction and enhancement in FANET situations and possible services is illustrated.
Conformal Prediction Regions for Time Series using Linear Complementarity Programming
Apr 07, 2023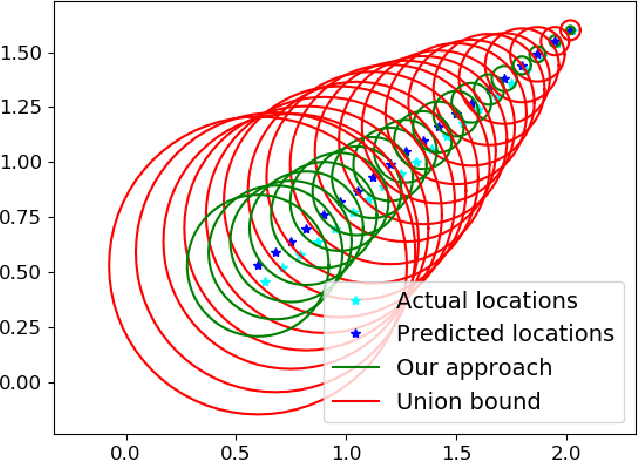
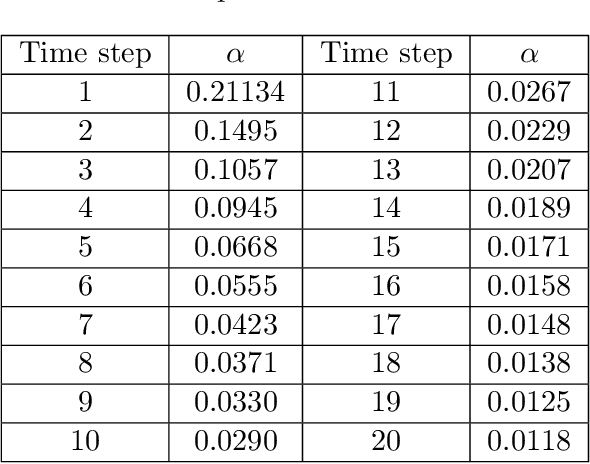
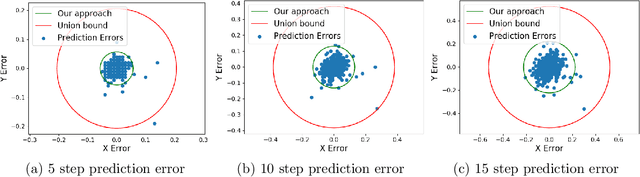
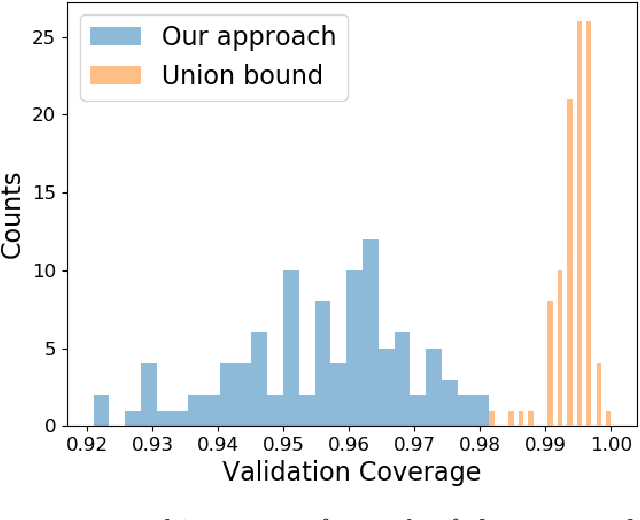
Conformal prediction is a statistical tool for producing prediction regions of machine learning models that are valid with high probability. However, applying conformal prediction to time series data leads to conservative prediction regions. In fact, to obtain prediction regions over $T$ time steps with confidence $1-\delta$, {previous works require that each individual prediction region is valid} with confidence $1-\delta/T$. We propose an optimization-based method for reducing this conservatism to enable long horizon planning and verification when using learning-enabled time series predictors. Instead of considering prediction errors individually at each time step, we consider a parameterized prediction error over multiple time steps. By optimizing the parameters over an additional dataset, we find prediction regions that are not conservative. We show that this problem can be cast as a mixed integer linear complementarity program (MILCP), which we then relax into a linear complementarity program (LCP). Additionally, we prove that the relaxed LP has the same optimal cost as the original MILCP. Finally, we demonstrate the efficacy of our method on a case study using pedestrian trajectory predictors.
WEPRO: Weight Prediction for Efficient Optimization of Hybrid Quantum-Classical Algorithms
Jul 23, 2023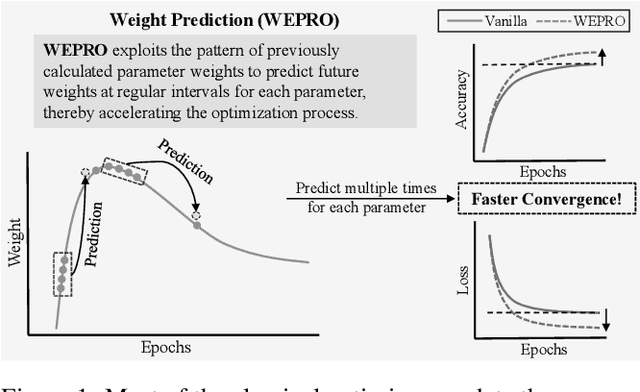
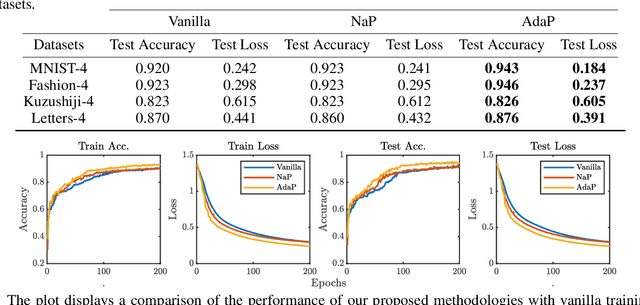
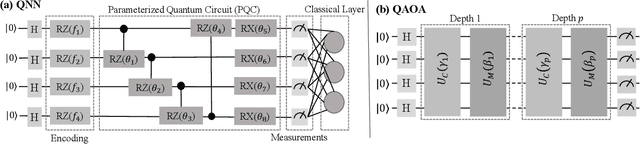
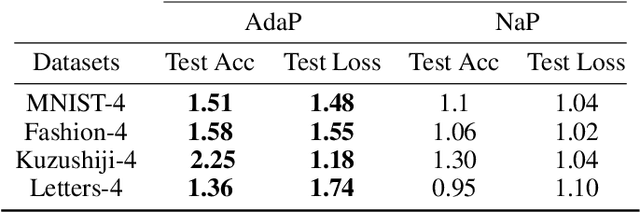
The exponential run time of quantum simulators on classical machines and long queue depths and high costs of real quantum devices present significant challenges in the effective training of Variational Quantum Algorithms (VQAs) like Quantum Neural Networks (QNNs), Variational Quantum Eigensolver (VQE) and Quantum Approximate Optimization Algorithm (QAOA). To address these limitations, we propose a new approach, WEPRO (Weight Prediction), which accelerates the convergence of VQAs by exploiting regular trends in the parameter weights. We introduce two techniques for optimal prediction performance namely, Naive Prediction (NaP) and Adaptive Prediction (AdaP). Through extensive experimentation and training of multiple QNN models on various datasets, we demonstrate that WEPRO offers a speedup of approximately $2.25\times$ compared to standard training methods, while also providing improved accuracy (up to $2.3\%$ higher) and loss (up to $6.1\%$ lower) with low storage and computational overheads. We also evaluate WEPRO's effectiveness in VQE for molecular ground-state energy estimation and in QAOA for graph MaxCut. Our results show that WEPRO leads to speed improvements of up to $3.1\times$ for VQE and $2.91\times$ for QAOA, compared to traditional optimization techniques, while using up to $3.3\times$ less number of shots (i.e., repeated circuit executions) per training iteration.
Integration of Domain Expert-Centric Ontology Design into the CRISP-DM for Cyber-Physical Production Systems
Jul 21, 2023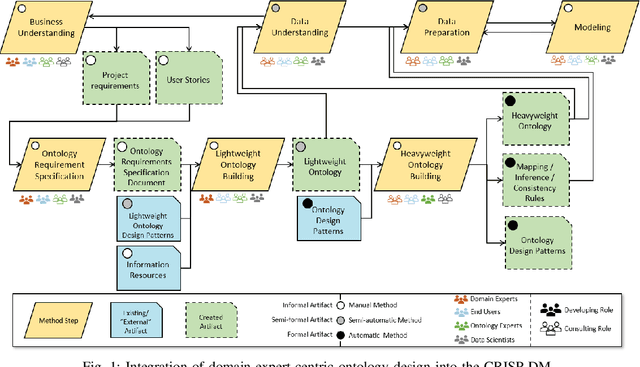
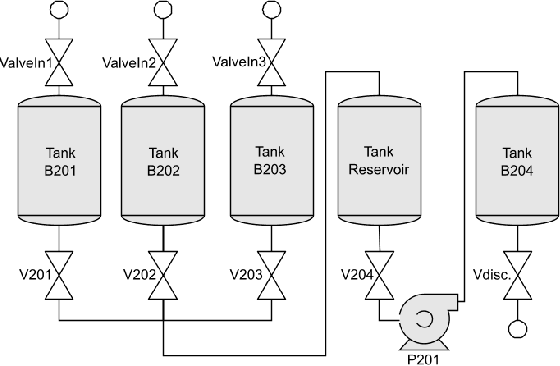
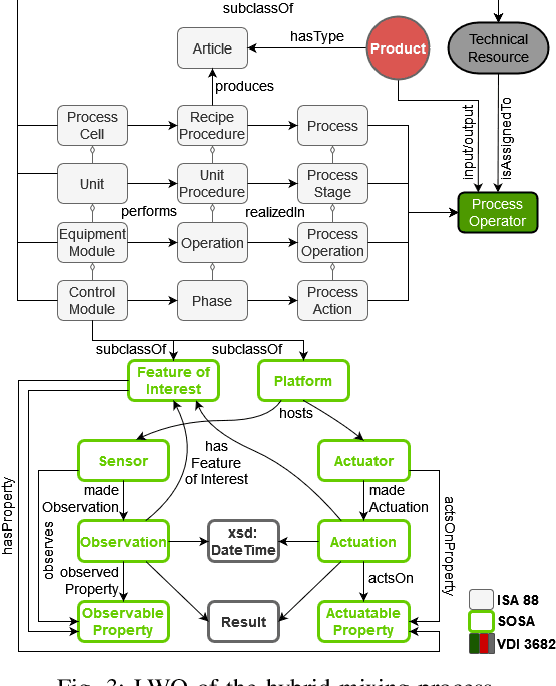
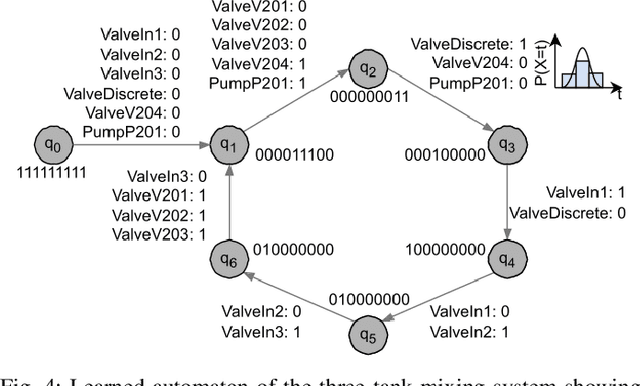
In the age of Industry 4.0 and Cyber-Physical Production Systems (CPPSs) vast amounts of potentially valuable data are being generated. Methods from Machine Learning (ML) and Data Mining (DM) have proven to be promising in extracting complex and hidden patterns from the data collected. The knowledge obtained can in turn be used to improve tasks like diagnostics or maintenance planning. However, such data-driven projects, usually performed with the Cross-Industry Standard Process for Data Mining (CRISP-DM), often fail due to the disproportionate amount of time needed for understanding and preparing the data. The application of domain-specific ontologies has demonstrated its advantageousness in a wide variety of Industry 4.0 application scenarios regarding the aforementioned challenges. However, workflows and artifacts from ontology design for CPPSs have not yet been systematically integrated into the CRISP-DM. Accordingly, this contribution intends to present an integrated approach so that data scientists are able to more quickly and reliably gain insights into the CPPS. The result is exemplarily applied to an anomaly detection use case.
Adaptive ResNet Architecture for Distributed Inference in Resource-Constrained IoT Systems
Jul 21, 2023As deep neural networks continue to expand and become more complex, most edge devices are unable to handle their extensive processing requirements. Therefore, the concept of distributed inference is essential to distribute the neural network among a cluster of nodes. However, distribution may lead to additional energy consumption and dependency among devices that suffer from unstable transmission rates. Unstable transmission rates harm real-time performance of IoT devices causing low latency, high energy usage, and potential failures. Hence, for dynamic systems, it is necessary to have a resilient DNN with an adaptive architecture that can downsize as per the available resources. This paper presents an empirical study that identifies the connections in ResNet that can be dropped without significantly impacting the model's performance to enable distribution in case of resource shortage. Based on the results, a multi-objective optimization problem is formulated to minimize latency and maximize accuracy as per available resources. Our experiments demonstrate that an adaptive ResNet architecture can reduce shared data, energy consumption, and latency throughout the distribution while maintaining high accuracy.
Transferability of Convolutional Neural Networks in Stationary Learning Tasks
Jul 21, 2023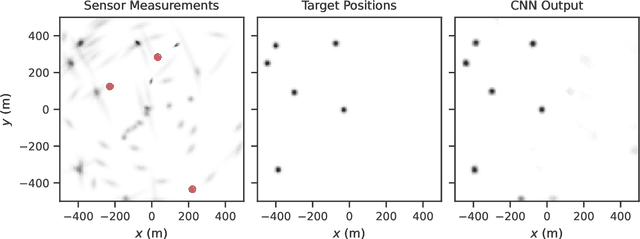
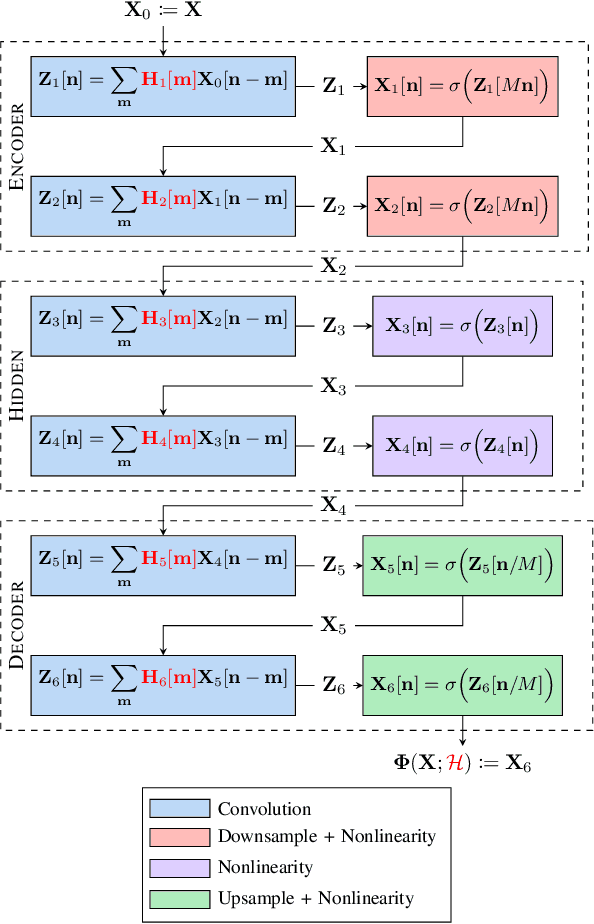

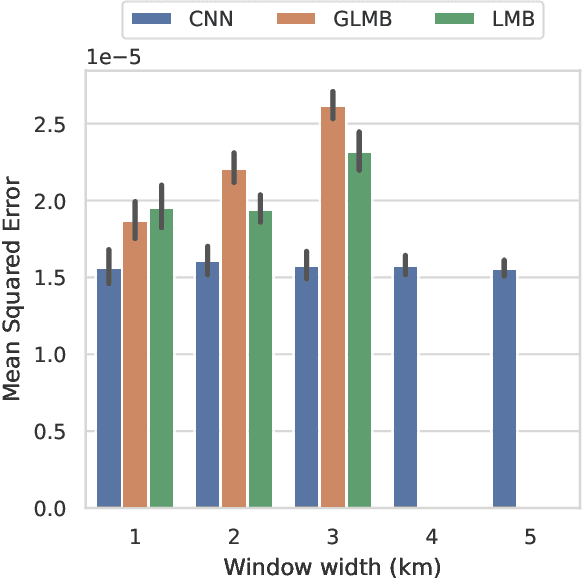
Recent advances in hardware and big data acquisition have accelerated the development of deep learning techniques. For an extended period of time, increasing the model complexity has led to performance improvements for various tasks. However, this trend is becoming unsustainable and there is a need for alternative, computationally lighter methods. In this paper, we introduce a novel framework for efficient training of convolutional neural networks (CNNs) for large-scale spatial problems. To accomplish this we investigate the properties of CNNs for tasks where the underlying signals are stationary. We show that a CNN trained on small windows of such signals achieves a nearly performance on much larger windows without retraining. This claim is supported by our theoretical analysis, which provides a bound on the performance degradation. Additionally, we conduct thorough experimental analysis on two tasks: multi-target tracking and mobile infrastructure on demand. Our results show that the CNN is able to tackle problems with many hundreds of agents after being trained with fewer than ten. Thus, CNN architectures provide solutions to these problems at previously computationally intractable scales.