 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Deep learning for dynamic graphs: models and benchmarks
Jul 12, 2023
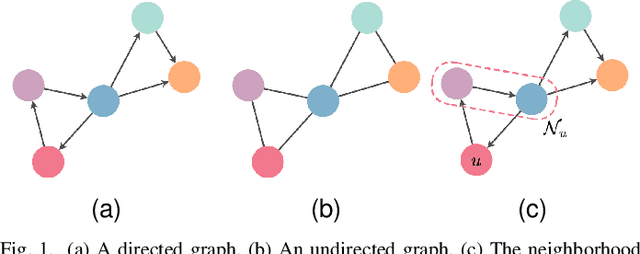
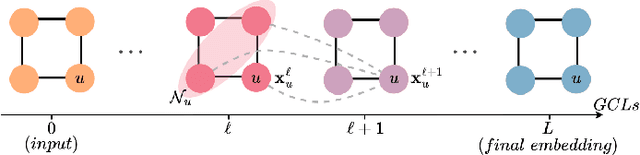
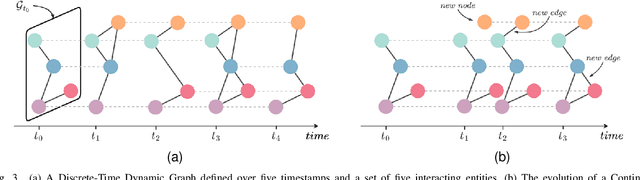
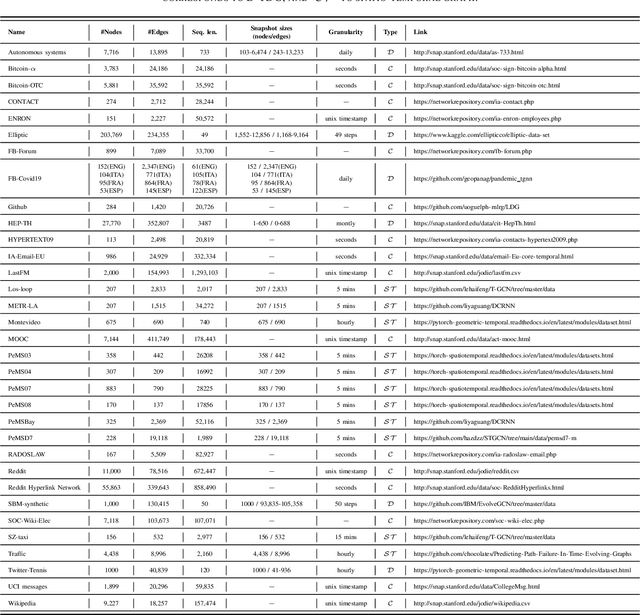
Recent progress in research on Deep Graph Networks (DGNs) has led to a maturation of the domain of learning on graphs. Despite the growth of this research field, there are still important challenges that are yet unsolved. Specifically, there is an urge of making DGNs suitable for predictive tasks on realworld systems of interconnected entities, which evolve over time. With the aim of fostering research in the domain of dynamic graphs, at first, we survey recent advantages in learning both temporal and spatial information, providing a comprehensive overview of the current state-of-the-art in the domain of representation learning for dynamic graphs. Secondly, we conduct a fair performance comparison among the most popular proposed approaches, leveraging rigorous model selection and assessment for all the methods, thus establishing a sound baseline for evaluating new architectures and approaches
Learning Stochastic Dynamical Systems as an Implicit Regularization with Graph Neural Networks
Jul 12, 2023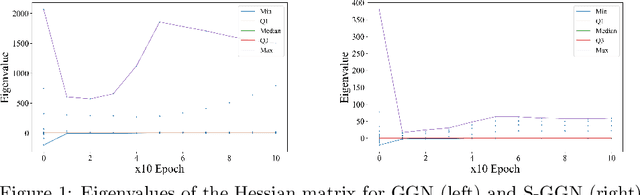
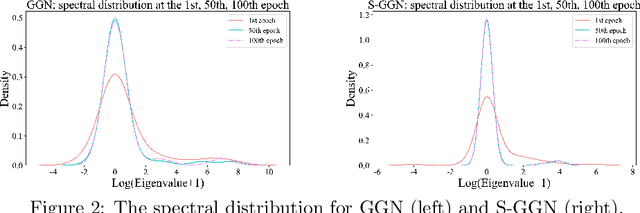
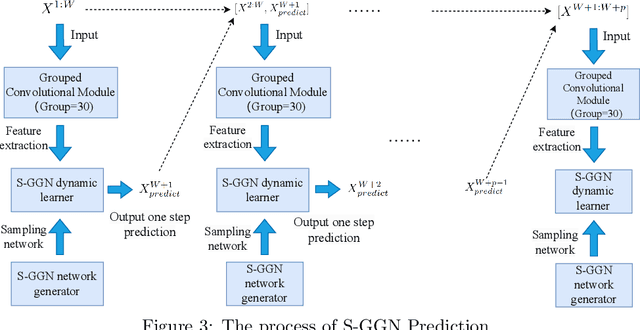
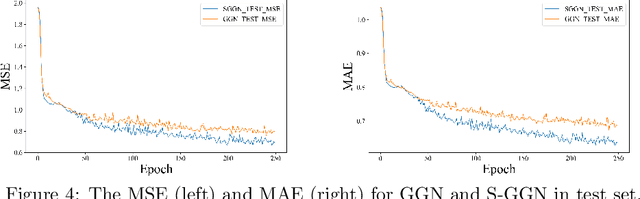
Stochastic Gumbel graph networks are proposed to learn high-dimensional time series, where the observed dimensions are often spatially correlated. To that end, the observed randomness and spatial-correlations are captured by learning the drift and diffusion terms of the stochastic differential equation with a Gumble matrix embedding, respectively. In particular, this novel framework enables us to investigate the implicit regularization effect of the noise terms in S-GGNs. We provide a theoretical guarantee for the proposed S-GGNs by deriving the difference between the two corresponding loss functions in a small neighborhood of weight. Then, we employ Kuramoto's model to generate data for comparing the spectral density from the Hessian Matrix of the two loss functions. Experimental results on real-world data, demonstrate that S-GGNs exhibit superior convergence, robustness, and generalization, compared with state-of-the-arts.
PDT: Pretrained Dual Transformers for Time-aware Bipartite Graphs
Jun 02, 2023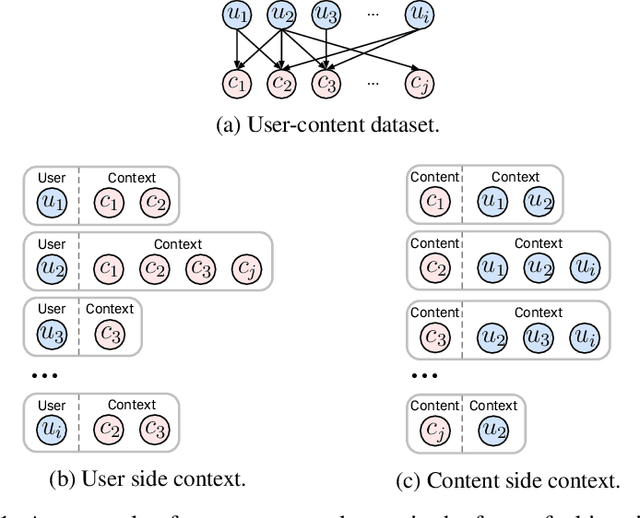
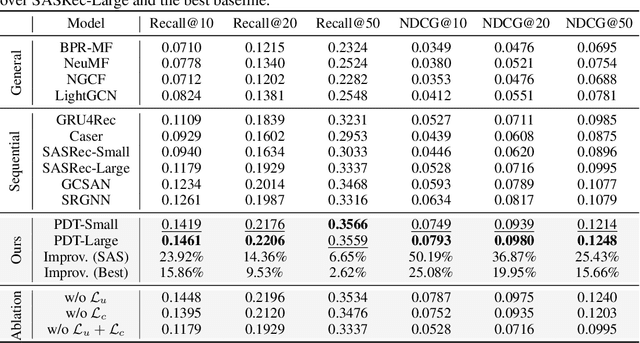
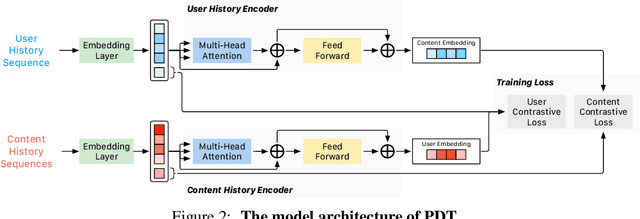
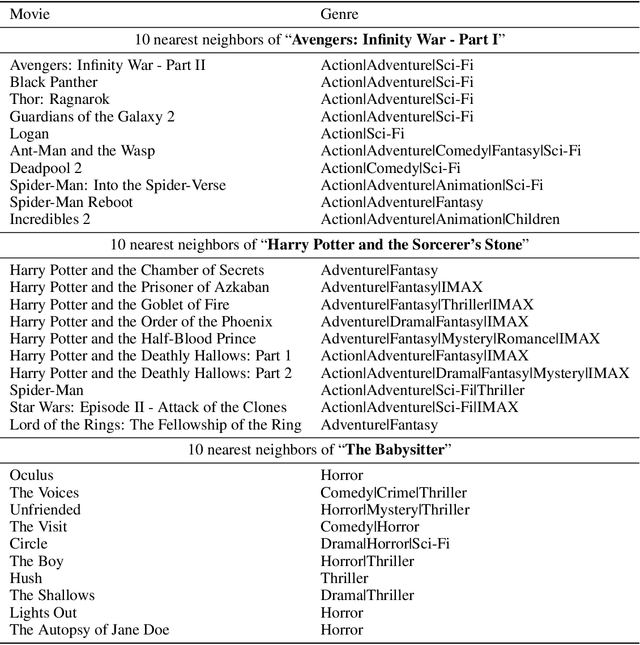
Pre-training on large models is prevalent and emerging with the ever-growing user-generated content in many machine learning application categories. It has been recognized that learning contextual knowledge from the datasets depicting user-content interaction plays a vital role in downstream tasks. Despite several studies attempting to learn contextual knowledge via pre-training methods, finding an optimal training objective and strategy for this type of task remains a challenging problem. In this work, we contend that there are two distinct aspects of contextual knowledge, namely the user-side and the content-side, for datasets where user-content interaction can be represented as a bipartite graph. To learn contextual knowledge, we propose a pre-training method that learns a bi-directional mapping between the spaces of the user-side and the content-side. We formulate the training goal as a contrastive learning task and propose a dual-Transformer architecture to encode the contextual knowledge. We evaluate the proposed method for the recommendation task. The empirical studies have demonstrated that the proposed method outperformed all the baselines with significant gains.
Occlusion-aware Risk Assessment and Driving Strategy for Autonomous Vehicles Using Simplified Reachability Quantification
Jul 02, 2023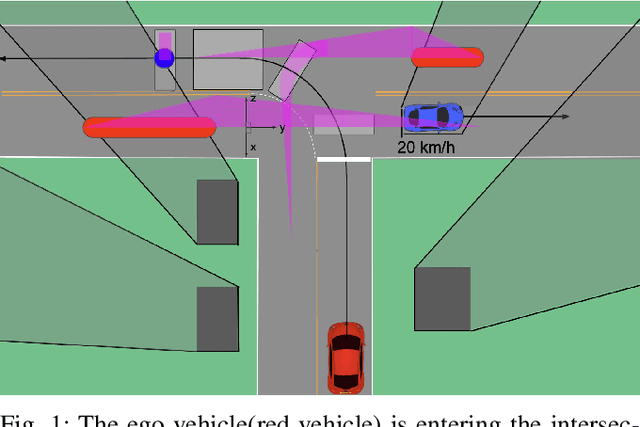
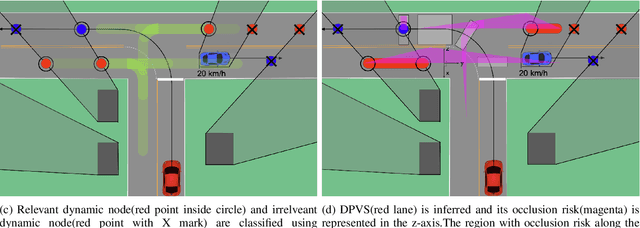
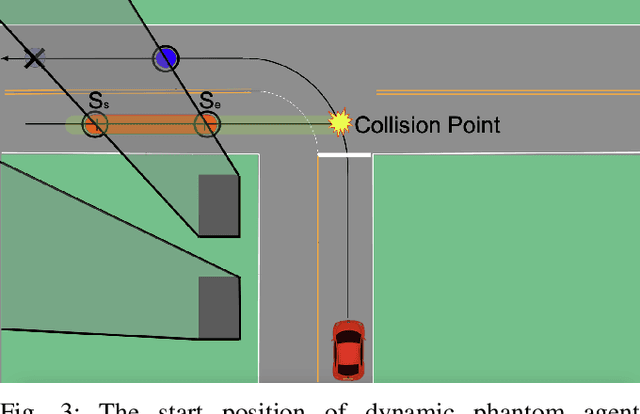
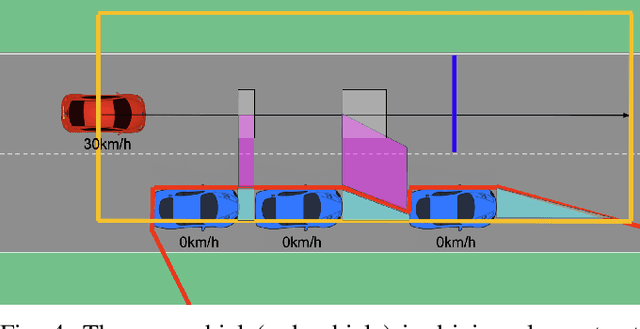
There are several unresolved challenges for autonomous vehicles. One of them is safely navigating among occluded pedestrians and vehicles. Much of the previous work tried to solve this problem by generating phantom cars and assessing their risk. In this paper, motivated by the previous works, we propose an algorithm that efficiently assesses risks of phantom pedestrians/vehicles using Simplified Reachability Quantification. We utilized this occlusion risk to set a speed limit at the risky position when planning the velocity profile of an autonomous vehicle. This allows an autonomous vehicle to safely and efficiently drive in occluded areas. The proposed algorithm was evaluated in various scenarios in the CARLA simulator and it reduced the average collision rate by 6.14X, the discomfort score by 5.03X, while traversal time was increased by 1.48X compared to baseline 1, and computation time was reduced by 20.15X compared to baseline 2.
Anticipating Technical Expertise and Capability Evolution in Research Communities using Dynamic Graph Transformers
Jul 18, 2023The ability to anticipate technical expertise and capability evolution trends globally is essential for national and global security, especially in safety-critical domains like nuclear nonproliferation (NN) and rapidly emerging fields like artificial intelligence (AI). In this work, we extend traditional statistical relational learning approaches (e.g., link prediction in collaboration networks) and formulate a problem of anticipating technical expertise and capability evolution using dynamic heterogeneous graph representations. We develop novel capabilities to forecast collaboration patterns, authorship behavior, and technical capability evolution at different granularities (e.g., scientist and institution levels) in two distinct research fields. We implement a dynamic graph transformer (DGT) neural architecture, which pushes the state-of-the-art graph neural network models by (a) forecasting heterogeneous (rather than homogeneous) nodes and edges, and (b) relying on both discrete -- and continuous -- time inputs. We demonstrate that our DGT models predict collaboration, partnership, and expertise patterns with 0.26, 0.73, and 0.53 mean reciprocal rank values for AI and 0.48, 0.93, and 0.22 for NN domains. DGT model performance exceeds the best-performing static graph baseline models by 30-80% across AI and NN domains. Our findings demonstrate that DGT models boost inductive task performance, when previously unseen nodes appear in the test data, for the domains with emerging collaboration patterns (e.g., AI). Specifically, models accurately predict which established scientists will collaborate with early career scientists and vice-versa in the AI domain.
GeneFace++: Generalized and Stable Real-Time Audio-Driven 3D Talking Face Generation
May 01, 2023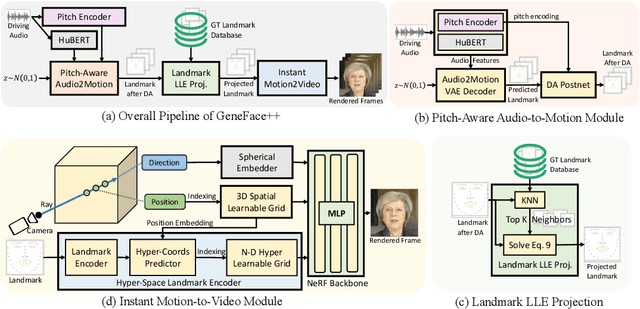
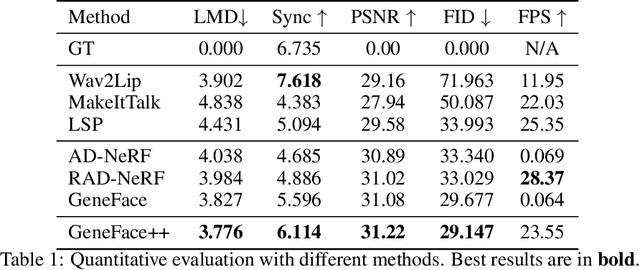
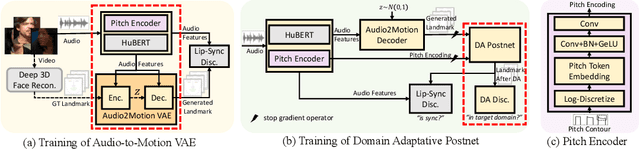

Generating talking person portraits with arbitrary speech audio is a crucial problem in the field of digital human and metaverse. A modern talking face generation method is expected to achieve the goals of generalized audio-lip synchronization, good video quality, and high system efficiency. Recently, neural radiance field (NeRF) has become a popular rendering technique in this field since it could achieve high-fidelity and 3D-consistent talking face generation with a few-minute-long training video. However, there still exist several challenges for NeRF-based methods: 1) as for the lip synchronization, it is hard to generate a long facial motion sequence of high temporal consistency and audio-lip accuracy; 2) as for the video quality, due to the limited data used to train the renderer, it is vulnerable to out-of-domain input condition and produce bad rendering results occasionally; 3) as for the system efficiency, the slow training and inference speed of the vanilla NeRF severely obstruct its usage in real-world applications. In this paper, we propose GeneFace++ to handle these challenges by 1) utilizing the pitch contour as an auxiliary feature and introducing a temporal loss in the facial motion prediction process; 2) proposing a landmark locally linear embedding method to regulate the outliers in the predicted motion sequence to avoid robustness issues; 3) designing a computationally efficient NeRF-based motion-to-video renderer to achieves fast training and real-time inference. With these settings, GeneFace++ becomes the first NeRF-based method that achieves stable and real-time talking face generation with generalized audio-lip synchronization. Extensive experiments show that our method outperforms state-of-the-art baselines in terms of subjective and objective evaluation. Video samples are available at https://genefaceplusplus.github.io .
Differentially Private Distributed Estimation and Learning
Jun 28, 2023We study distributed estimation and learning problems in a networked environment in which agents exchange information to estimate unknown statistical properties of random variables from their privately observed samples. By exchanging information about their private observations, the agents can collectively estimate the unknown quantities, but they also face privacy risks. The goal of our aggregation schemes is to combine the observed data efficiently over time and across the network, while accommodating the privacy needs of the agents and without any coordination beyond their local neighborhoods. Our algorithms enable the participating agents to estimate a complete sufficient statistic from private signals that are acquired offline or online over time, and to preserve the privacy of their signals and network neighborhoods. This is achieved through linear aggregation schemes with adjusted randomization schemes that add noise to the exchanged estimates subject to differential privacy (DP) constraints. In every case, we demonstrate the efficiency of our algorithms by proving convergence to the estimators of a hypothetical, omniscient observer that has central access to all of the signals. We also provide convergence rate analysis and finite-time performance guarantees and show that the noise that minimizes the convergence time to the best estimates is the Laplace noise, with parameters corresponding to each agent's sensitivity to their signal and network characteristics. Finally, to supplement and validate our theoretical results, we run experiments on real-world data from the US Power Grid Network and electric consumption data from German Households to estimate the average power consumption of power stations and households under all privacy regimes.
Time-dependent Iterative Imputation for Multivariate Longitudinal Clinical Data
Apr 16, 2023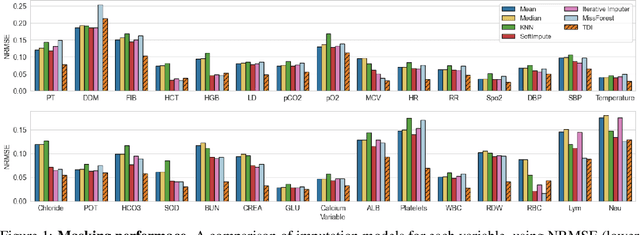

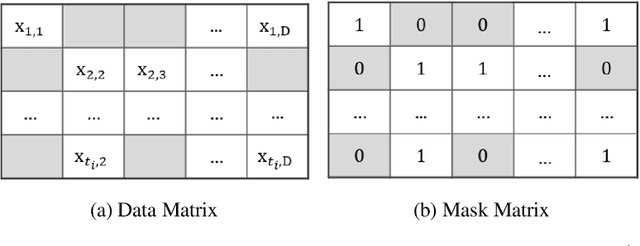
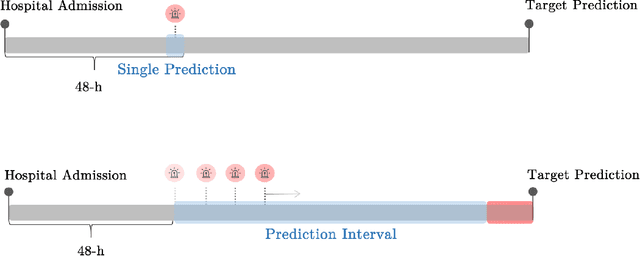
Missing data is a major challenge in clinical research. In electronic medical records, often a large fraction of the values in laboratory tests and vital signs are missing. The missingness can lead to biased estimates and limit our ability to draw conclusions from the data. Additionally, many machine learning algorithms can only be applied to complete datasets. A common solution is data imputation, the process of filling-in the missing values. However, some of the popular imputation approaches perform poorly on clinical data. We developed a simple new approach, Time-Dependent Iterative imputation (TDI), which offers a practical solution for imputing time-series data. It addresses both multivariate and longitudinal data, by integrating forward-filling and Iterative Imputer. The integration employs a patient, variable, and observation-specific dynamic weighting strategy, based on the clinical patterns of the data, including missing rates and measurement frequency. We tested TDI on randomly masked clinical datasets. When applied to a cohort consisting of more than 500,000 patient observations from MIMIC III, our approach outperformed state-of-the-art imputation methods for 25 out of 30 clinical variables, with an overall root-mean-squared-error of 0.63, compared to 0.85 for SoftImpute, the second best method. MIMIC III and COVID-19 inpatient datasets were used to perform prediction tasks. Importantly, these tests demonstrated that TDI imputation can lead to improved risk prediction.
Embodied Lifelong Learning for Task and Motion Planning
Jul 13, 2023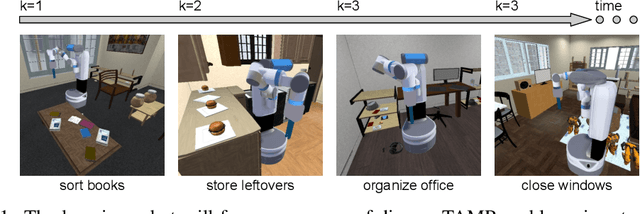
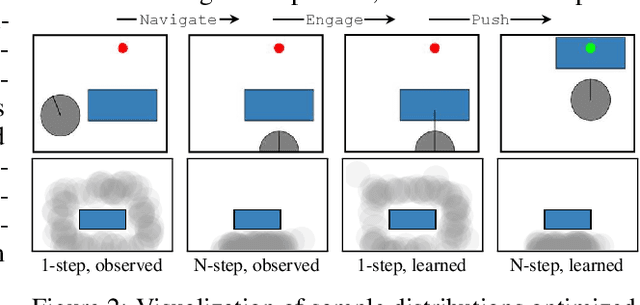
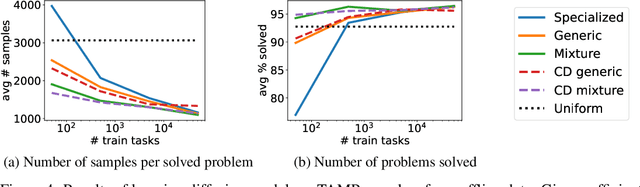
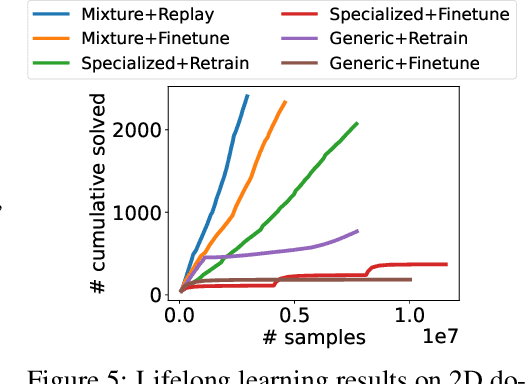
A robot deployed in a home over long stretches of time faces a true lifelong learning problem. As it seeks to provide assistance to its users, the robot should leverage any accumulated experience to improve its own knowledge to become a more proficient assistant. We formalize this setting with a novel lifelong learning problem formulation in the context of learning for task and motion planning (TAMP). Exploiting the modularity of TAMP systems, we develop a generative mixture model that produces candidate continuous parameters for a planner. Whereas most existing lifelong learning approaches determine a priori how data is shared across task models, our approach learns shared and non-shared models and determines which to use online during planning based on auxiliary tasks that serve as a proxy for each model's understanding of a state. Our method exhibits substantial improvements in planning success on simulated 2D domains and on several problems from the BEHAVIOR benchmark.
MaxCorrMGNN: A Multi-Graph Neural Network Framework for Generalized Multimodal Fusion of Medical Data for Outcome Prediction
Jul 13, 2023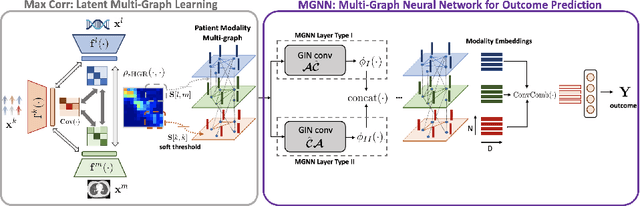
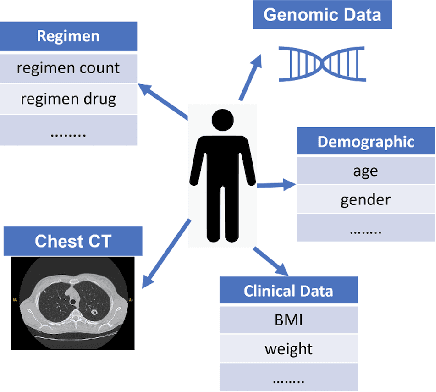
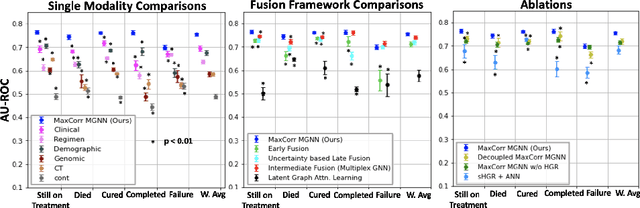
With the emergence of multimodal electronic health records, the evidence for an outcome may be captured across multiple modalities ranging from clinical to imaging and genomic data. Predicting outcomes effectively requires fusion frameworks capable of modeling fine-grained and multi-faceted complex interactions between modality features within and across patients. We develop an innovative fusion approach called MaxCorr MGNN that models non-linear modality correlations within and across patients through Hirschfeld-Gebelein-Renyi maximal correlation (MaxCorr) embeddings, resulting in a multi-layered graph that preserves the identities of the modalities and patients. We then design, for the first time, a generalized multi-layered graph neural network (MGNN) for task-informed reasoning in multi-layered graphs, that learns the parameters defining patient-modality graph connectivity and message passing in an end-to-end fashion. We evaluate our model an outcome prediction task on a Tuberculosis (TB) dataset consistently outperforming several state-of-the-art neural, graph-based and traditional fusion techniques.