 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ReBotNet: Fast Real-time Video Enhancement
Mar 23, 2023
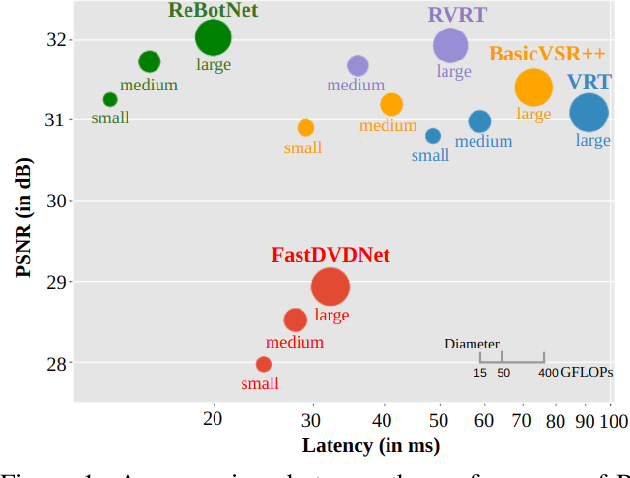
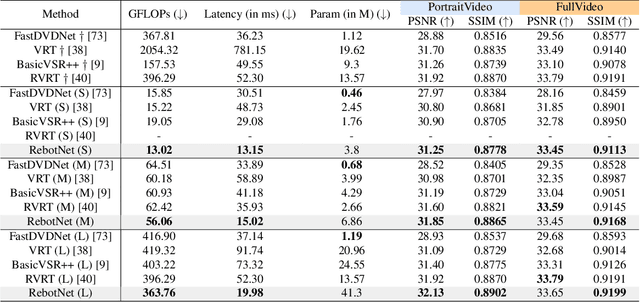
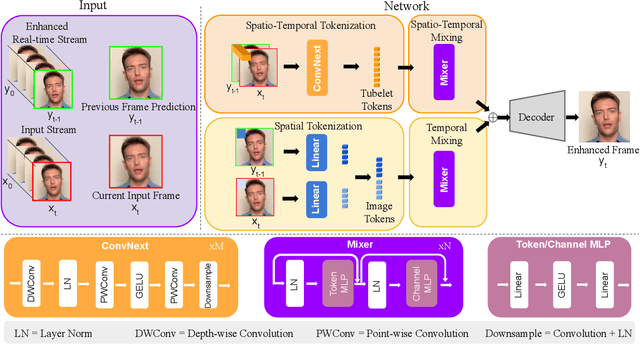
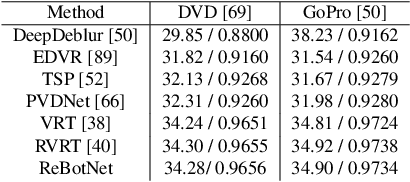
Most video restoration networks are slow, have high computational load, and can't be used for real-time video enhancement. In this work, we design an efficient and fast framework to perform real-time video enhancement for practical use-cases like live video calls and video streams. Our proposed method, called Recurrent Bottleneck Mixer Network (ReBotNet), employs a dual-branch framework. The first branch learns spatio-temporal features by tokenizing the input frames along the spatial and temporal dimensions using a ConvNext-based encoder and processing these abstract tokens using a bottleneck mixer. To further improve temporal consistency, the second branch employs a mixer directly on tokens extracted from individual frames. A common decoder then merges the features form the two branches to predict the enhanced frame. In addition, we propose a recurrent training approach where the last frame's prediction is leveraged to efficiently enhance the current frame while improving temporal consistency. To evaluate our method, we curate two new datasets that emulate real-world video call and streaming scenarios, and show extensive results on multiple datasets where ReBotNet outperforms existing approaches with lower computations, reduced memory requirements, and faster inference time.
Co-SLAM: Joint Coordinate and Sparse Parametric Encodings for Neural Real-Time SLAM
Apr 27, 2023We present Co-SLAM, a neural RGB-D SLAM system based on a hybrid representation, that performs robust camera tracking and high-fidelity surface reconstruction in real time. Co-SLAM represents the scene as a multi-resolution hash-grid to exploit its high convergence speed and ability to represent high-frequency local features. In addition, Co-SLAM incorporates one-blob encoding, to encourage surface coherence and completion in unobserved areas. This joint parametric-coordinate encoding enables real-time and robust performance by bringing the best of both worlds: fast convergence and surface hole filling. Moreover, our ray sampling strategy allows Co-SLAM to perform global bundle adjustment over all keyframes instead of requiring keyframe selection to maintain a small number of active keyframes as competing neural SLAM approaches do. Experimental results show that Co-SLAM runs at 10-17Hz and achieves state-of-the-art scene reconstruction results, and competitive tracking performance in various datasets and benchmarks (ScanNet, TUM, Replica, Synthetic RGBD). Project page: https://hengyiwang.github.io/projects/CoSLAM
Distributed Decisions on Optimal Load Balancing in Loss Networks
Jul 17, 2023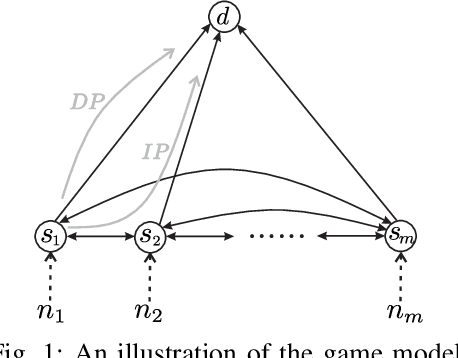
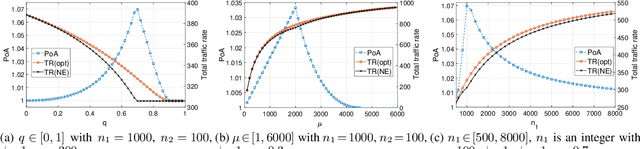
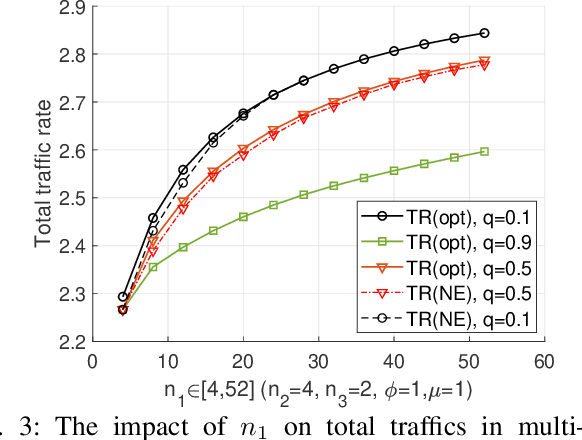
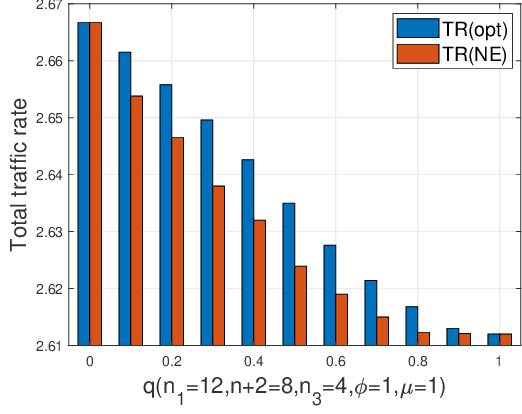
When multiple users share a common link in direct transmission, packet loss and network collision may occur due to the simultaneous arrival of traffics at the source node. To tackle this problem, users may resort to an indirect path: the packet flows are first relayed through a sidelink to another source node, then transmitted to the destination. This behavior brings the problems of packet routing or load balancing: (1) how to maximize the total traffic in a collaborative way; (2) how self-interested users choose routing strategies to minimize their individual packet loss independently. In this work, we propose a generalized mathematical framework to tackle the packet and load balancing issue in loss networks. In centralized scenarios with a planner, we provide a polynomial-time algorithm to compute the system optimum point where the total traffic rate is maximized. Conversely, in decentralized settings with autonomous users making distributed decisions, the system converges to an equilibrium where no user can reduce their loss probability through unilateral deviation. We thereby provide a full characterization of Nash equilibrium and examine the efficiency loss stemming from selfish behaviors, both theoretically and empirically. In general, the performance degradation caused by selfish behaviors is not catastrophic; however, this gap is not monotonic and can have extreme values in certain specific scenarios.
Autoregressive Diffusion Model for Graph Generation
Jul 17, 2023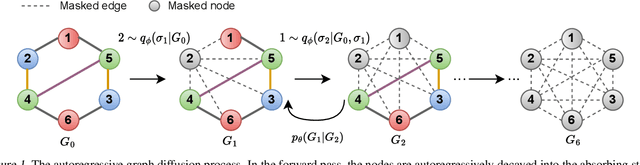
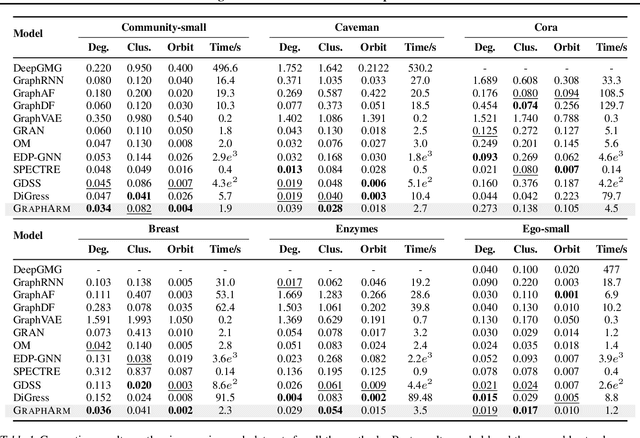
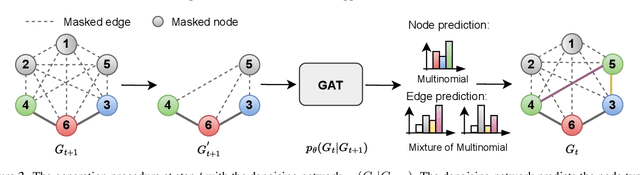
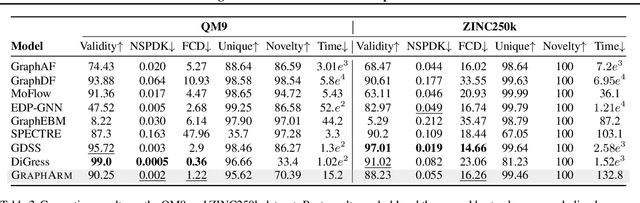
Diffusion-based graph generative models have recently obtained promising results for graph generation. However, existing diffusion-based graph generative models are mostly one-shot generative models that apply Gaussian diffusion in the dequantized adjacency matrix space. Such a strategy can suffer from difficulty in model training, slow sampling speed, and incapability of incorporating constraints. We propose an \emph{autoregressive diffusion} model for graph generation. Unlike existing methods, we define a node-absorbing diffusion process that operates directly in the discrete graph space. For forward diffusion, we design a \emph{diffusion ordering network}, which learns a data-dependent node absorbing ordering from graph topology. For reverse generation, we design a \emph{denoising network} that uses the reverse node ordering to efficiently reconstruct the graph by predicting the node type of the new node and its edges with previously denoised nodes at a time. Based on the permutation invariance of graph, we show that the two networks can be jointly trained by optimizing a simple lower bound of data likelihood. Our experiments on six diverse generic graph datasets and two molecule datasets show that our model achieves better or comparable generation performance with previous state-of-the-art, and meanwhile enjoys fast generation speed.
A Lightweight Framework for High-Quality Code Generation
Jul 17, 2023In recent years, the use of automated source code generation utilizing transformer-based generative models has expanded, and these models can generate functional code according to the requirements of the developers. However, recent research revealed that these automatically generated source codes can contain vulnerabilities and other quality issues. Despite researchers' and practitioners' attempts to enhance code generation models, retraining and fine-tuning large language models is time-consuming and resource-intensive. Thus, we describe FRANC, a lightweight framework for recommending more secure and high-quality source code derived from transformer-based code generation models. FRANC includes a static filter to make the generated code compilable with heuristics and a quality-aware ranker to sort the code snippets based on a quality score. Moreover, the framework uses prompt engineering to fix persistent quality issues. We evaluated the framework with five Python and Java code generation models and six prompt datasets, including a newly created one in this work (SOEval). The static filter improves 9% to 46% Java suggestions and 10% to 43% Python suggestions regarding compilability. The average improvement over the NDCG@10 score for the ranking system is 0.0763, and the repairing techniques repair the highest 80% of prompts. FRANC takes, on average, 1.98 seconds for Java; for Python, it takes 0.08 seconds.
SkeletonMAE: Graph-based Masked Autoencoder for Skeleton Sequence Pre-training
Jul 17, 2023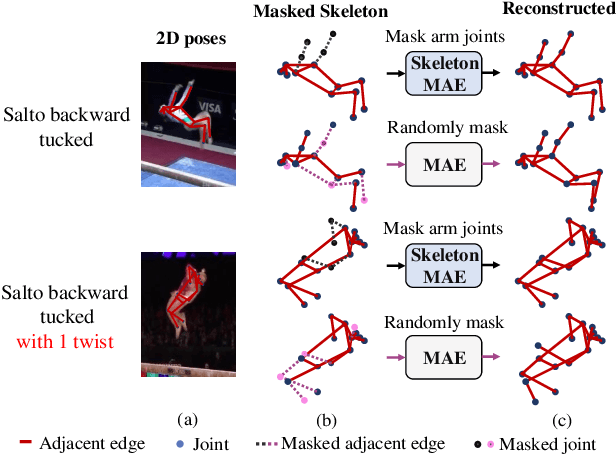
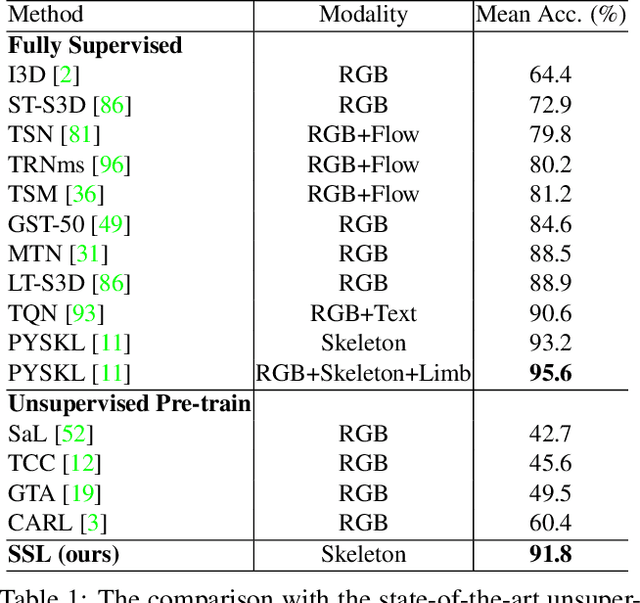
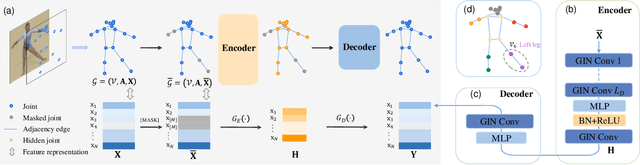
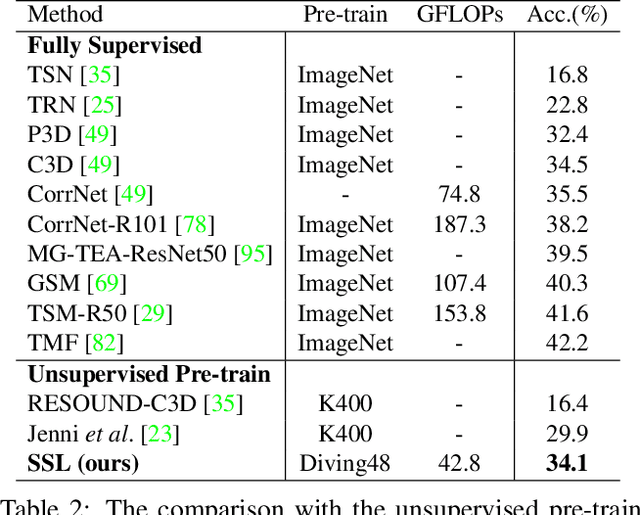
Skeleton sequence representation learning has shown great advantages for action recognition due to its promising ability to model human joints and topology. However, the current methods usually require sufficient labeled data for training computationally expensive models, which is labor-intensive and time-consuming. Moreover, these methods ignore how to utilize the fine-grained dependencies among different skeleton joints to pre-train an efficient skeleton sequence learning model that can generalize well across different datasets. In this paper, we propose an efficient skeleton sequence learning framework, named Skeleton Sequence Learning (SSL). To comprehensively capture the human pose and obtain discriminative skeleton sequence representation, we build an asymmetric graph-based encoder-decoder pre-training architecture named SkeletonMAE, which embeds skeleton joint sequence into Graph Convolutional Network (GCN) and reconstructs the masked skeleton joints and edges based on the prior human topology knowledge. Then, the pre-trained SkeletonMAE encoder is integrated with the Spatial-Temporal Representation Learning (STRL) module to build the SSL framework. Extensive experimental results show that our SSL generalizes well across different datasets and outperforms the state-of-the-art self-supervised skeleton-based action recognition methods on FineGym, Diving48, NTU 60 and NTU 120 datasets. Additionally, we obtain comparable performance to some fully supervised methods. The code is avaliable at https://github.com/HongYan1123/SkeletonMAE.
Image-based Regularization for Action Smoothness in Autonomous Miniature Racing Car with Deep Reinforcement Learning
Jul 17, 2023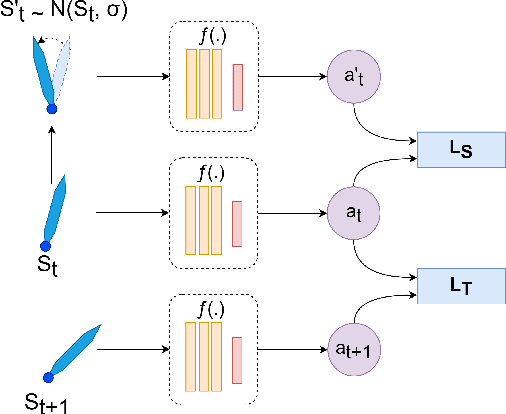
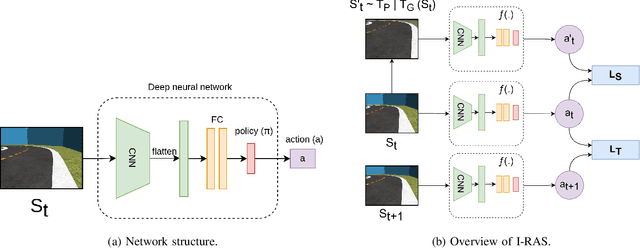

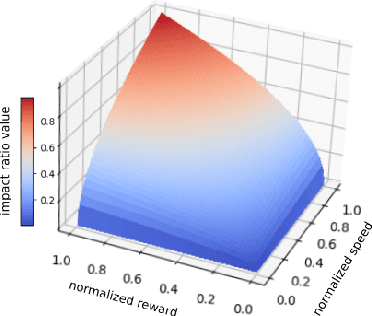
Deep reinforcement learning has achieved significant results in low-level controlling tasks. However, for some applications like autonomous driving and drone flying, it is difficult to control behavior stably since the agent may suddenly change its actions which often lowers the controlling system's efficiency, induces excessive mechanical wear, and causes uncontrollable, dangerous behavior to the vehicle. Recently, a method called conditioning for action policy smoothness (CAPS) was proposed to solve the problem of jerkiness in low-dimensional features for applications such as quadrotor drones. To cope with high-dimensional features, this paper proposes image-based regularization for action smoothness (I-RAS) for solving jerky control in autonomous miniature car racing. We also introduce a control based on impact ratio, an adaptive regularization weight to control the smoothness constraint, called IR control. In the experiment, an agent with I-RAS and IR control significantly improves the success rate from 59% to 95%. In the real-world-track experiment, the agent also outperforms other methods, namely reducing the average finish lap time, while also improving the completion rate even without real world training. This is also justified by an agent based on I-RAS winning the 2022 AWS DeepRacer Final Championship Cup.
Universal Online Learning with Gradual Variations: A Multi-layer Online Ensemble Approach
Jul 17, 2023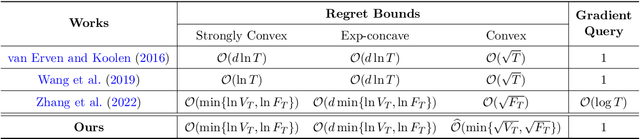

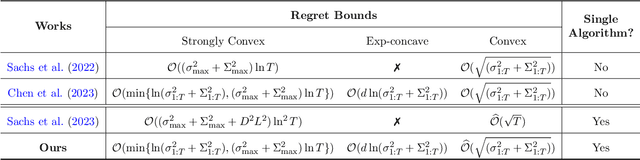
In this paper, we propose an online convex optimization method with two different levels of adaptivity. On a higher level, our method is agnostic to the specific type and curvature of the loss functions, while at a lower level, it can exploit the niceness of the environments and attain problem-dependent guarantees. To be specific, we obtain $\mathcal{O}(\ln V_T)$, $\mathcal{O}(d \ln V_T)$ and $\hat{\mathcal{O}}(\sqrt{V_T})$ regret bounds for strongly convex, exp-concave and convex loss functions, respectively, where $d$ is the dimension, $V_T$ denotes problem-dependent gradient variations and $\hat{\mathcal{O}}(\cdot)$-notation omits logarithmic factors on $V_T$. Our result finds broad implications and applications. It not only safeguards the worst-case guarantees, but also implies the small-loss bounds in analysis directly. Besides, it draws deep connections with adversarial/stochastic convex optimization and game theory, further validating its practical potential. Our method is based on a multi-layer online ensemble incorporating novel ingredients, including carefully-designed optimism for unifying diverse function types and cascaded corrections for algorithmic stability. Remarkably, despite its multi-layer structure, our algorithm necessitates only one gradient query per round, making it favorable when the gradient evaluation is time-consuming. This is facilitated by a novel regret decomposition equipped with customized surrogate losses.
Rhythm Modeling for Voice Conversion
Jul 12, 2023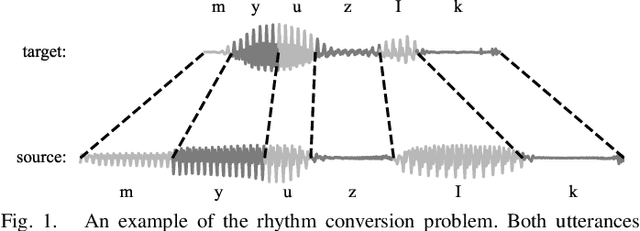

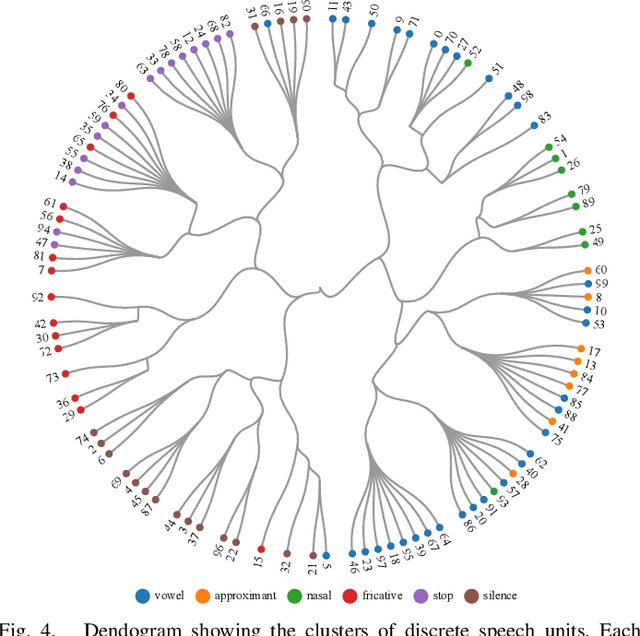
Voice conversion aims to transform source speech into a different target voice. However, typical voice conversion systems do not account for rhythm, which is an important factor in the perception of speaker identity. To bridge this gap, we introduce Urhythmic-an unsupervised method for rhythm conversion that does not require parallel data or text transcriptions. Using self-supervised representations, we first divide source audio into segments approximating sonorants, obstruents, and silences. Then we model rhythm by estimating speaking rate or the duration distribution of each segment type. Finally, we match the target speaking rate or rhythm by time-stretching the speech segments. Experiments show that Urhythmic outperforms existing unsupervised methods in terms of quality and prosody. Code and checkpoints: https://github.com/bshall/urhythmic. Audio demo page: https://ubisoft-laforge.github.io/speech/urhythmic.
GastroVision: A Multi-class Endoscopy Image Dataset for Computer Aided Gastrointestinal Disease Detection
Jul 16, 2023
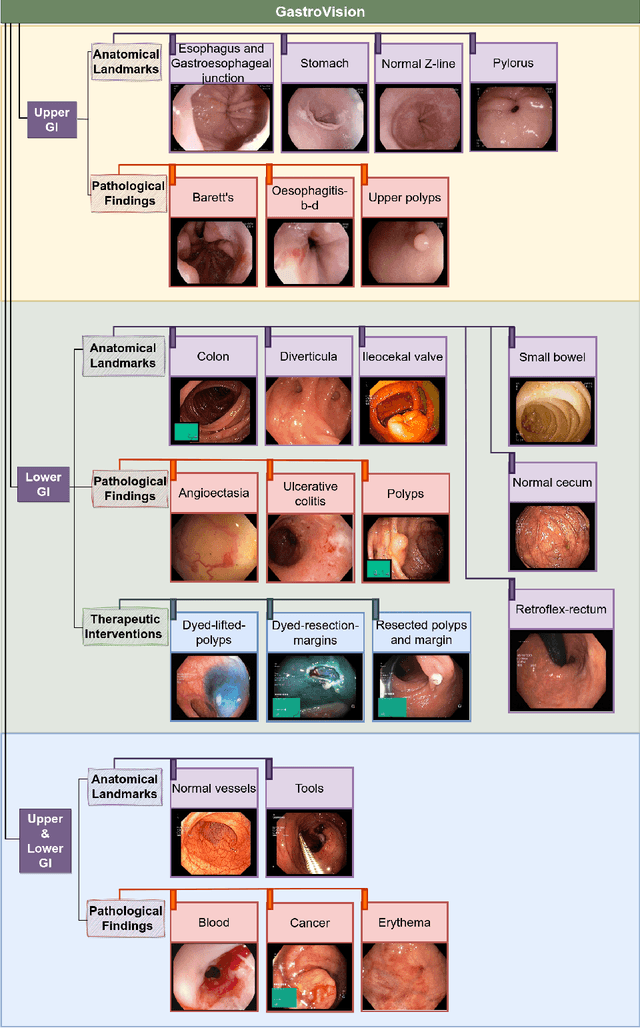
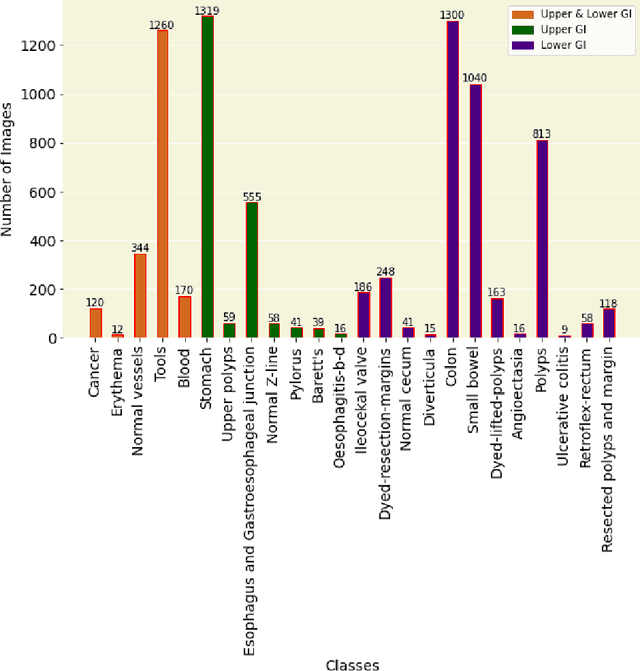
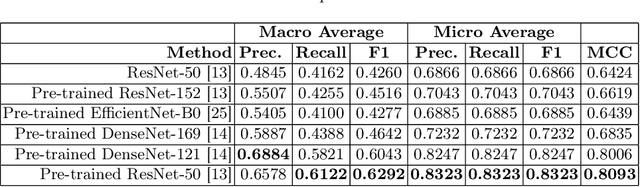
Integrating real-time artificial intelligence (AI) systems in clinical practices faces challenges such as scalability and acceptance. These challenges include data availability, biased outcomes, data quality, lack of transparency, and underperformance on unseen datasets from different distributions. The scarcity of large-scale, precisely labeled, and diverse datasets are the major challenge for clinical integration. This scarcity is also due to the legal restrictions and extensive manual efforts required for accurate annotations from clinicians. To address these challenges, we present GastroVision, a multi-center open-access gastrointestinal (GI) endoscopy dataset that includes different anatomical landmarks, pathological abnormalities, polyp removal cases and normal findings (a total of 24 classes) from the GI tract. The dataset comprises 8,000 images acquired from B{\ae}rum Hospital in Norway and Karolinska University in Sweden and was annotated and verified by experienced GI endoscopists. Furthermore, we validate the significance of our dataset with extensive benchmarking based on the popular deep learning based baseline models. We believe our dataset can facilitate the development of AI-based algorithms for GI disease detection and classification. Our dataset is available at https://osf.io/84e7f/.