 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
CVPR MultiEarth 2023 Deforestation Estimation Challenge:SpaceVision4Amazon
Jul 10, 2023



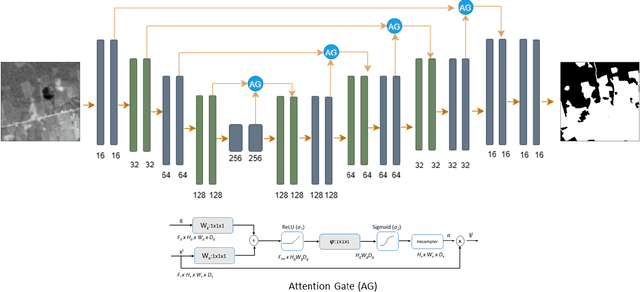
In this paper, we present a deforestation estimation method based on attention guided UNet architecture using Electro-Optical (EO) and Synthetic Aperture Radar (SAR) satellite imagery. For optical images, Landsat-8 and for SAR imagery, Sentinel-1 data have been used to train and validate the proposed model. Due to the unavailability of temporally and spatially collocated data, individual model has been trained for each sensor. During training time Landsat-8 model achieved training and validation pixel accuracy of 93.45% and Sentinel-2 model achieved 83.87% pixel accuracy. During the test set evaluation, the model achieved pixel accuracy of 84.70% with F1-Score of 0.79 and IoU of 0.69.
A Semi-Automated Solution Approach Selection Tool for Any Use Case via Scopus and OpenAI: a Case Study for AI/ML in Oncology
Jul 10, 2023In today's vast literature landscape, a manual review is very time-consuming. To address this challenge, this paper proposes a semi-automated tool for solution method review and selection. It caters to researchers, practitioners, and decision-makers while serving as a benchmark for future work. The tool comprises three modules: (1) paper selection and scoring, using a keyword selection scheme to query Scopus API and compute relevancy; (2) solution method extraction in papers utilizing OpenAI API; (3) sensitivity analysis and post-analyzes. It reveals trends, relevant papers, and methods. AI in the oncology case study and several use cases are presented with promising results, comparing the tool to manual ground truth.
GRAINS: Proximity Sensing of Objects in Granular Materials
Jul 18, 2023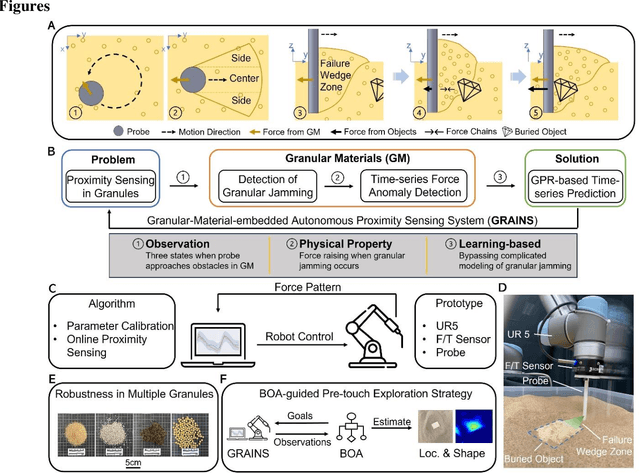
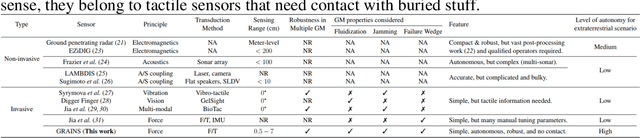
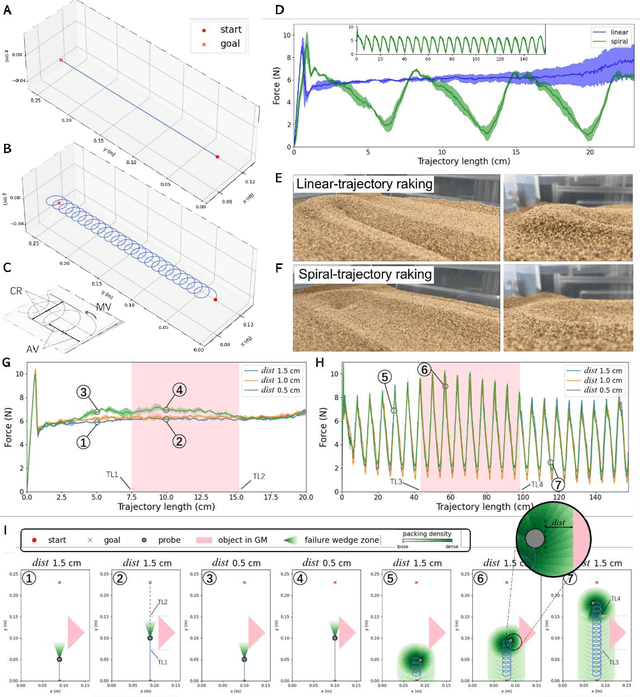
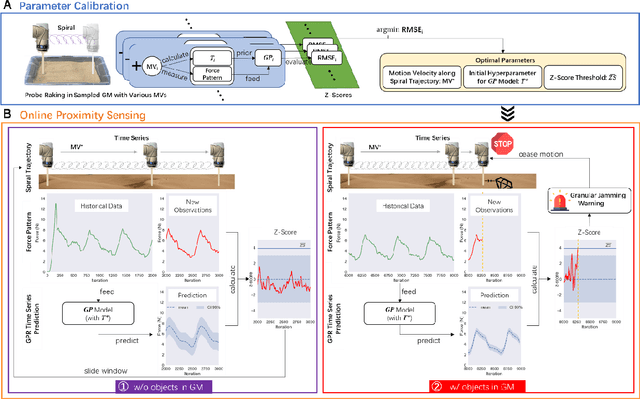
Proximity sensing detects an object's presence without contact. However, research has rarely explored proximity sensing in granular materials (GM) due to GM's lack of visual and complex properties. In this paper, we propose a granular-material-embedded autonomous proximity sensing system (GRAINS) based on three granular phenomena (fluidization, jamming, and failure wedge zone). GRAINS can automatically sense buried objects beneath GM in real-time manner (at least ~20 hertz) and perceive them 0.5 ~ 7 centimeters ahead in different granules without the use of vision or touch. We introduce a new spiral trajectory for the probe raking in GM, combining linear and circular motions, inspired by a common granular fluidization technique. Based on the observation of force-raising when granular jamming occurs in the failure wedge zone in front of the probe during its raking, we employ Gaussian process regression to constantly learn and predict the force patterns and detect the force anomaly resulting from granular jamming to identify the proximity sensing of buried objects. Finally, we apply GRAINS to a Bayesian-optimization-algorithm-guided exploration strategy to successfully localize underground objects and outline their distribution using proximity sensing without contact or digging. This work offers a simple yet reliable method with potential for safe operation in building habitation infrastructure on an alien planet without human intervention.
TableGPT: Towards Unifying Tables, Nature Language and Commands into One GPT
Jul 18, 2023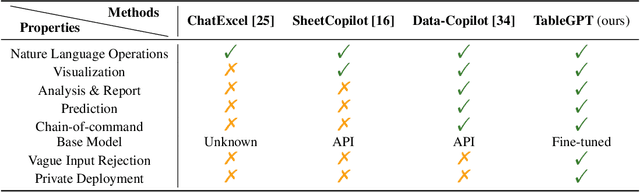
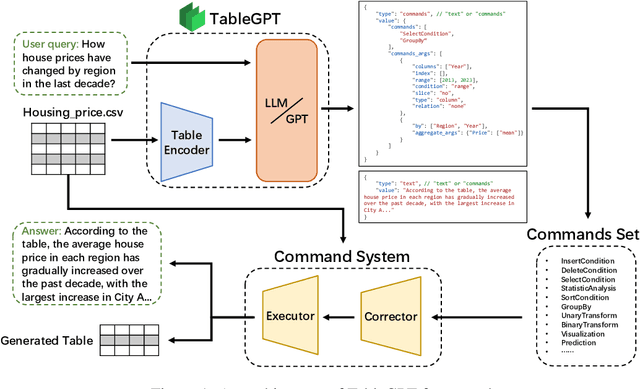
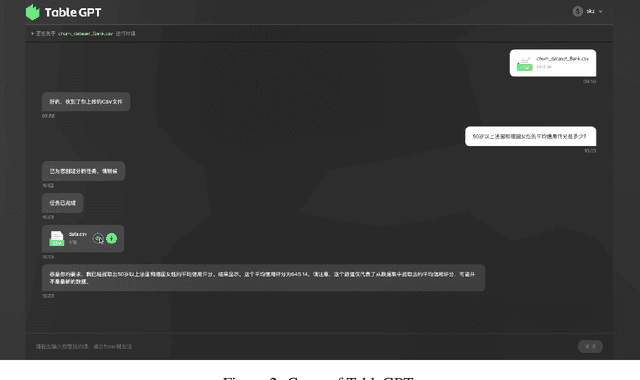
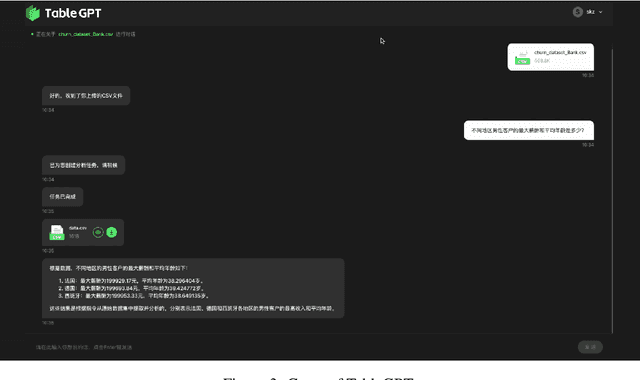
Tables are prevalent in real-world databases, requiring significant time and effort for humans to analyze and manipulate. The advancements in large language models (LLMs) have made it possible to interact with tables using natural language input, bringing this capability closer to reality. In this paper, we present TableGPT, a unified fine-tuned framework that enables LLMs to understand and operate on tables using external functional commands. It introduces the capability to seamlessly interact with tables, enabling a wide range of functionalities such as question answering, data manipulation (e.g., insert, delete, query, and modify operations), data visualization, analysis report generation, and automated prediction. TableGPT aims to provide convenience and accessibility to users by empowering them to effortlessly leverage tabular data. At the core of TableGPT lies the novel concept of global tabular representations, which empowers LLMs to gain a comprehensive understanding of the entire table beyond meta-information. By jointly training LLMs on both table and text modalities, TableGPT achieves a deep understanding of tabular data and the ability to perform complex operations on tables through chain-of-command instructions. Importantly, TableGPT offers the advantage of being a self-contained system rather than relying on external API interfaces. Moreover, it supports efficient data process flow, query rejection (when appropriate) and private deployment, enabling faster domain data fine-tuning and ensuring data privacy, which enhances the framework's adaptability to specific use cases.
Multimodal LLMs for health grounded in individual-specific data
Jul 18, 2023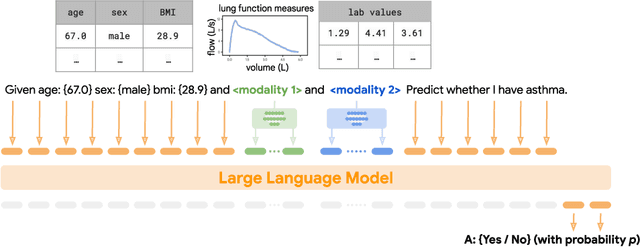
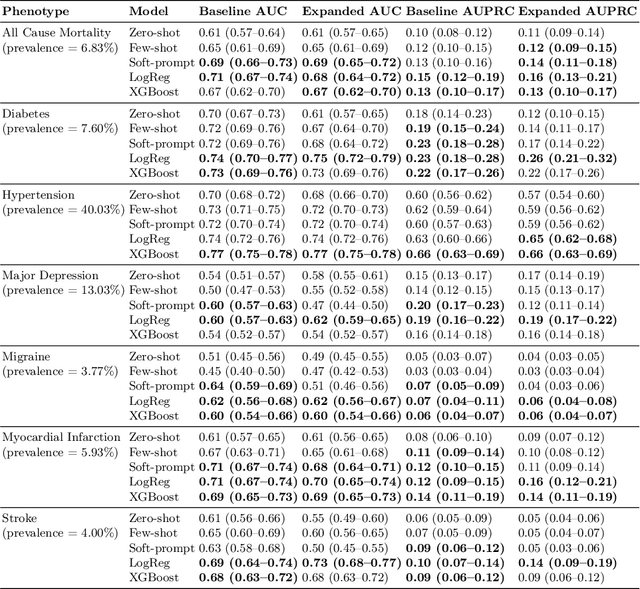
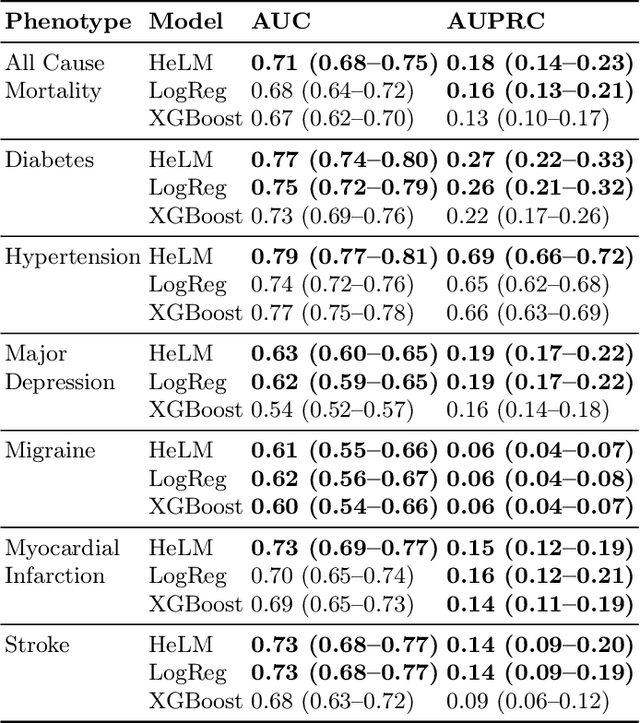
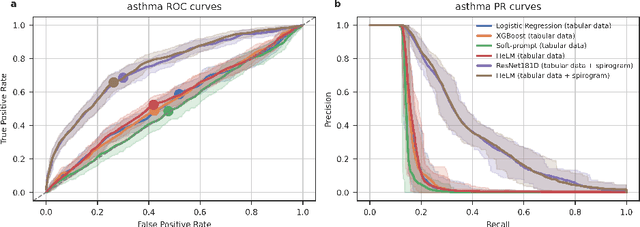
Foundation large language models (LLMs) have shown an impressive ability to solve tasks across a wide range of fields including health. To effectively solve personalized health tasks, LLMs need the ability to ingest a diversity of data modalities that are relevant to an individual's health status. In this paper, we take a step towards creating multimodal LLMs for health that are grounded in individual-specific data by developing a framework (HeLM: Health Large Language Model for Multimodal Understanding) that enables LLMs to use high-dimensional clinical modalities to estimate underlying disease risk. HeLM encodes complex data modalities by learning an encoder that maps them into the LLM's token embedding space and for simple modalities like tabular data by serializing the data into text. Using data from the UK Biobank, we show that HeLM can effectively use demographic and clinical features in addition to high-dimensional time-series data to estimate disease risk. For example, HeLM achieves an AUROC of 0.75 for asthma prediction when combining tabular and spirogram data modalities compared with 0.49 when only using tabular data. Overall, we find that HeLM outperforms or performs at parity with classical machine learning approaches across a selection of eight binary traits. Furthermore, we investigate the downstream uses of this model such as its generalizability to out-of-distribution traits and its ability to power conversations around individual health and wellness.
Multi-Stage Cable Routing through Hierarchical Imitation Learning
Jul 18, 2023
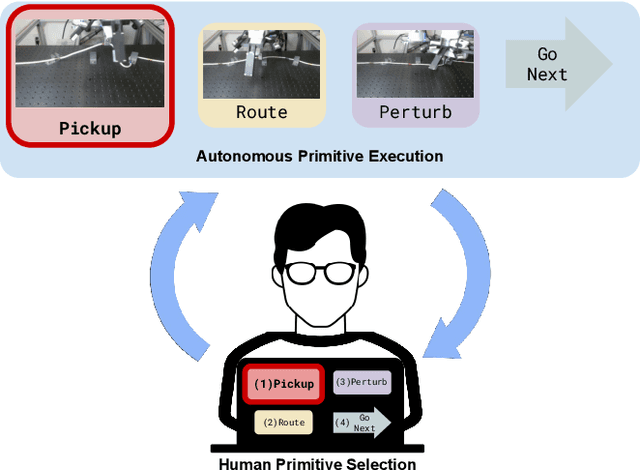

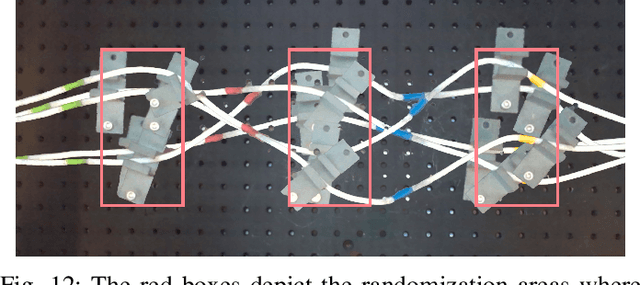
We study the problem of learning to perform multi-stage robotic manipulation tasks, with applications to cable routing, where the robot must route a cable through a series of clips. This setting presents challenges representative of complex multi-stage robotic manipulation scenarios: handling deformable objects, closing the loop on visual perception, and handling extended behaviors consisting of multiple steps that must be executed successfully to complete the entire task. In such settings, learning individual primitives for each stage that succeed with a high enough rate to perform a complete temporally extended task is impractical: if each stage must be completed successfully and has a non-negligible probability of failure, the likelihood of successful completion of the entire task becomes negligible. Therefore, successful controllers for such multi-stage tasks must be able to recover from failure and compensate for imperfections in low-level controllers by smartly choosing which controllers to trigger at any given time, retrying, or taking corrective action as needed. To this end, we describe an imitation learning system that uses vision-based policies trained from demonstrations at both the lower (motor control) and the upper (sequencing) level, present a system for instantiating this method to learn the cable routing task, and perform evaluations showing great performance in generalizing to very challenging clip placement variations. Supplementary videos, datasets, and code can be found at https://sites.google.com/view/cablerouting.
CertPri: Certifiable Prioritization for Deep Neural Networks via Movement Cost in Feature Space
Jul 18, 2023
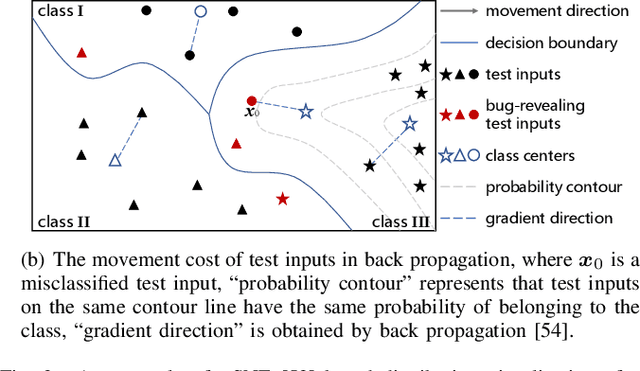
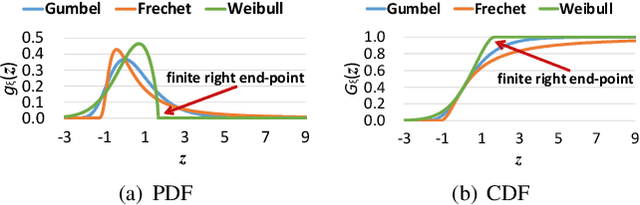
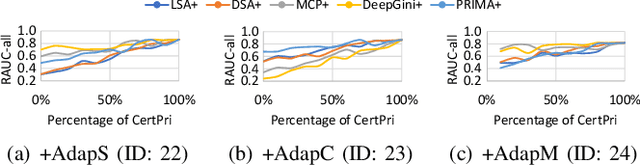
Deep neural networks (DNNs) have demonstrated their outperformance in various software systems, but also exhibit misbehavior and even result in irreversible disasters. Therefore, it is crucial to identify the misbehavior of DNN-based software and improve DNNs' quality. Test input prioritization is one of the most appealing ways to guarantee DNNs' quality, which prioritizes test inputs so that more bug-revealing inputs can be identified earlier with limited time and manual labeling efforts. However, the existing prioritization methods are still limited from three aspects: certifiability, effectiveness, and generalizability. To overcome the challenges, we propose CertPri, a test input prioritization technique designed based on a movement cost perspective of test inputs in DNNs' feature space. CertPri differs from previous works in three key aspects: (1) certifiable: it provides a formal robustness guarantee for the movement cost; (2) effective: it leverages formally guaranteed movement costs to identify malicious bug-revealing inputs; and (3) generic: it can be applied to various tasks, data, models, and scenarios. Extensive evaluations across 2 tasks (i.e., classification and regression), 6 data forms, 4 model structures, and 2 scenarios (i.e., white-box and black-box) demonstrate CertPri's superior performance. For instance, it significantly improves 53.97% prioritization effectiveness on average compared with baselines. Its robustness and generalizability are 1.41~2.00 times and 1.33~3.39 times that of baselines on average, respectively.
Distilling Coarse-to-Fine Semantic Matching Knowledge for Weakly Supervised 3D Visual Grounding
Jul 18, 2023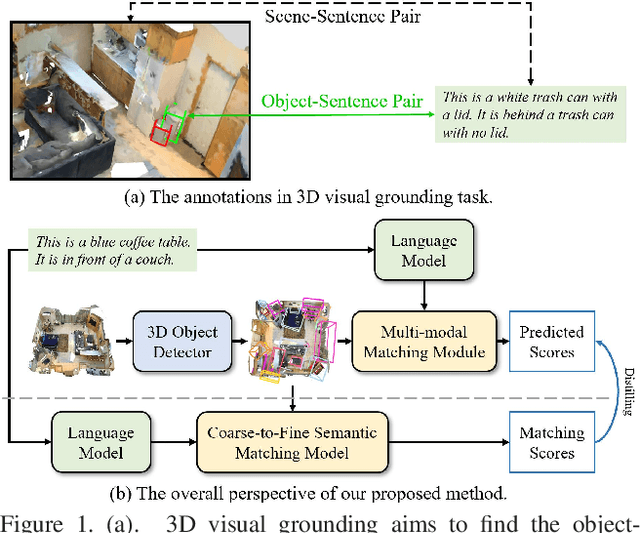
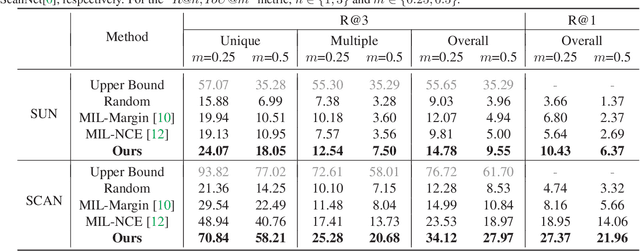
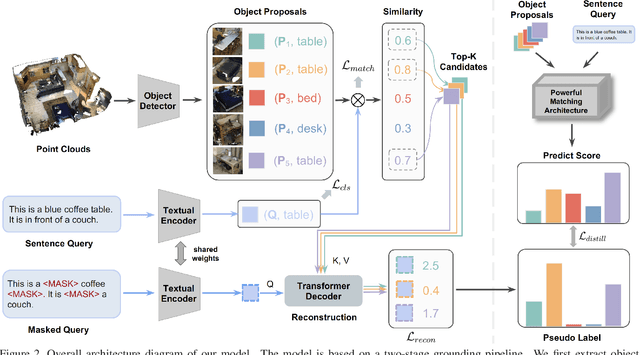

3D visual grounding involves finding a target object in a 3D scene that corresponds to a given sentence query. Although many approaches have been proposed and achieved impressive performance, they all require dense object-sentence pair annotations in 3D point clouds, which are both time-consuming and expensive. To address the problem that fine-grained annotated data is difficult to obtain, we propose to leverage weakly supervised annotations to learn the 3D visual grounding model, i.e., only coarse scene-sentence correspondences are used to learn object-sentence links. To accomplish this, we design a novel semantic matching model that analyzes the semantic similarity between object proposals and sentences in a coarse-to-fine manner. Specifically, we first extract object proposals and coarsely select the top-K candidates based on feature and class similarity matrices. Next, we reconstruct the masked keywords of the sentence using each candidate one by one, and the reconstructed accuracy finely reflects the semantic similarity of each candidate to the query. Additionally, we distill the coarse-to-fine semantic matching knowledge into a typical two-stage 3D visual grounding model, which reduces inference costs and improves performance by taking full advantage of the well-studied structure of the existing architectures. We conduct extensive experiments on ScanRefer, Nr3D, and Sr3D, which demonstrate the effectiveness of our proposed method.
Hybrid moderation in the newsroom: Recommending featured posts to content moderators
Jul 14, 2023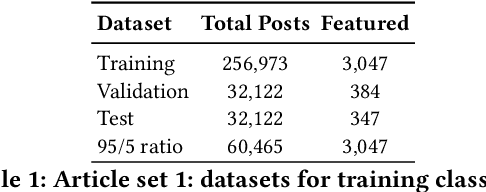
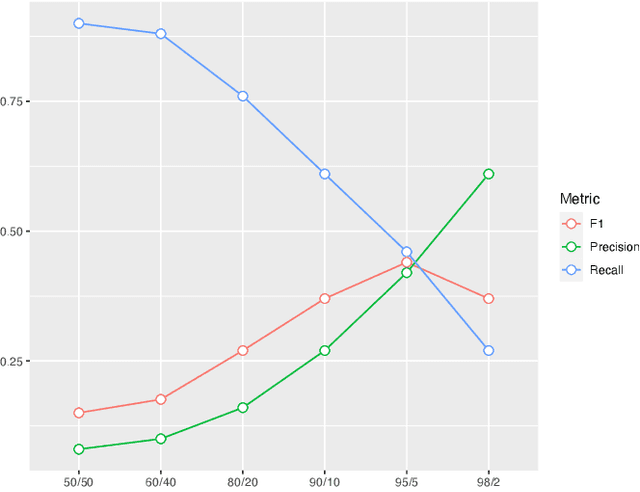
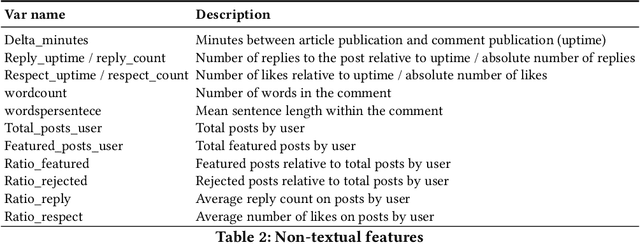
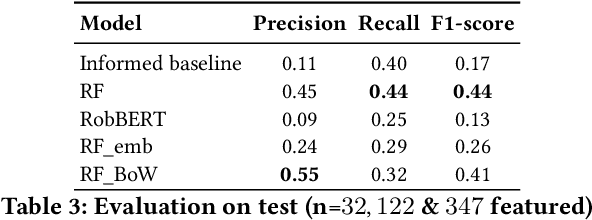
Online news outlets are grappling with the moderation of user-generated content within their comment section. We present a recommender system based on ranking class probabilities to support and empower the moderator in choosing featured posts, a time-consuming task. By combining user and textual content features we obtain an optimal classification F1-score of 0.44 on the test set. Furthermore, we observe an optimum mean NDCG@5 of 0.87 on a large set of validation articles. As an expert evaluation, content moderators assessed the output of a random selection of articles by choosing comments to feature based on the recommendations, which resulted in a NDCG score of 0.83. We conclude that first, adding text features yields the best score and second, while choosing featured content remains somewhat subjective, content moderators found suitable comments in all but one evaluated recommendations. We end the paper by analyzing our best-performing model, a step towards transparency and explainability in hybrid content moderation.
A Hybrid Genetic Algorithm for the min-max Multiple Traveling Salesman Problem
Jul 14, 2023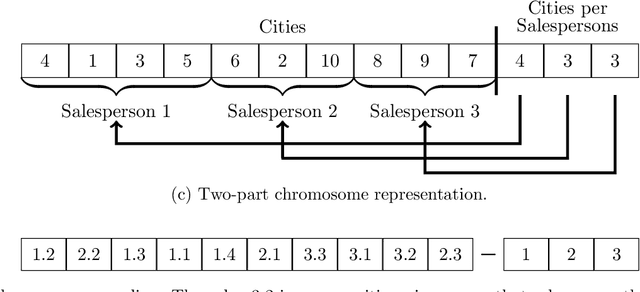
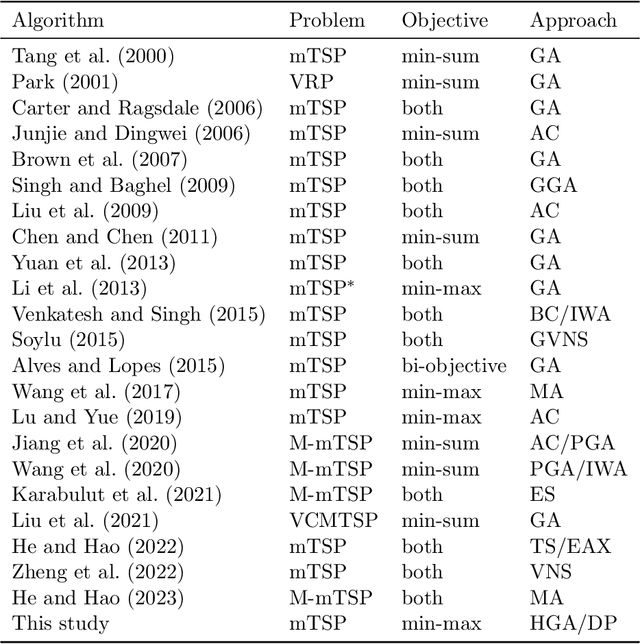
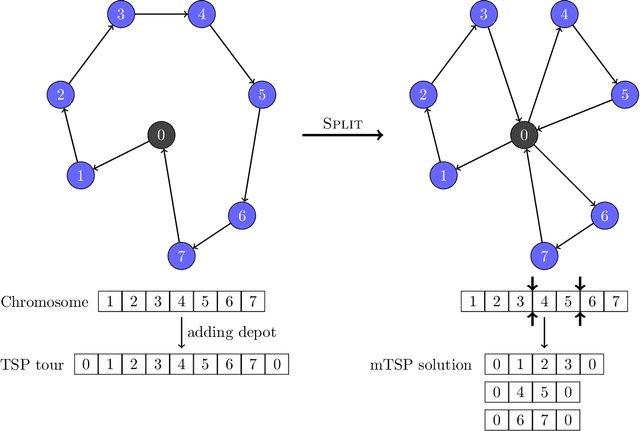
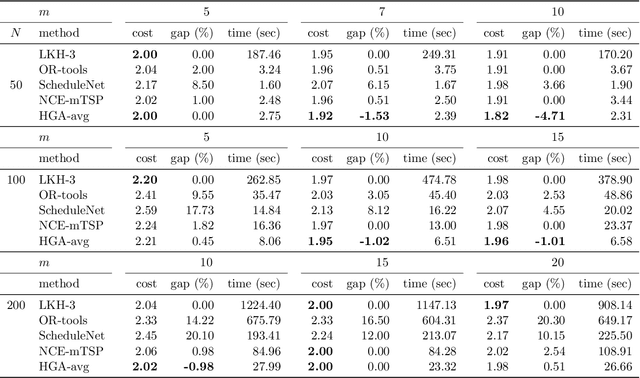
This paper proposes a hybrid genetic algorithm for solving the Multiple Traveling Salesman Problem (mTSP) to minimize the length of the longest tour. The genetic algorithm utilizes a TSP sequence as the representation of each individual, and a dynamic programming algorithm is employed to evaluate the individual and find the optimal mTSP solution for the given sequence of cities. A novel crossover operator is designed to combine similar tours from two parents and offers great diversity for the population. For some of the generated offspring, we detect and remove intersections between tours to obtain a solution with no intersections. This is particularly useful for the min-max mTSP. The generated offspring are also improved by a self-adaptive random local search and a thorough neighborhood search. Our algorithm outperforms all existing algorithms on average, with similar cutoff time thresholds, when tested against multiple benchmark sets found in the literature. Additionally, we improve the best-known solutions for 21 out of 89 instances on four benchmark sets.