 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A 137.5 TOPS/W SRAM Compute-in-Memory Macro with 9-b Memory Cell-Embedded ADCs and Signal Margin Enhancement Techniques for AI Edge Applications
Jul 19, 2023
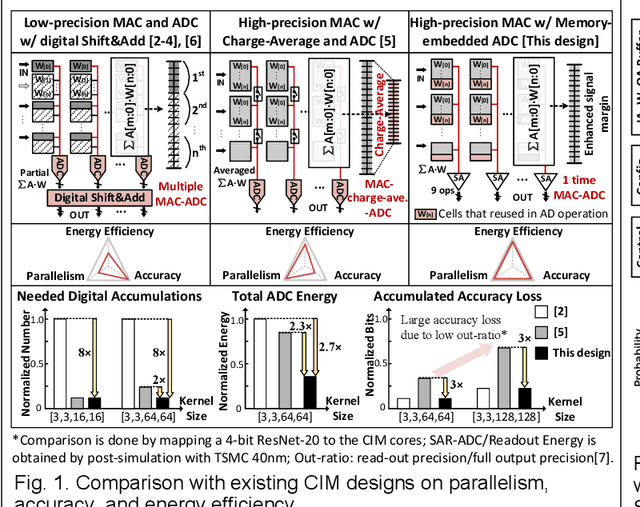
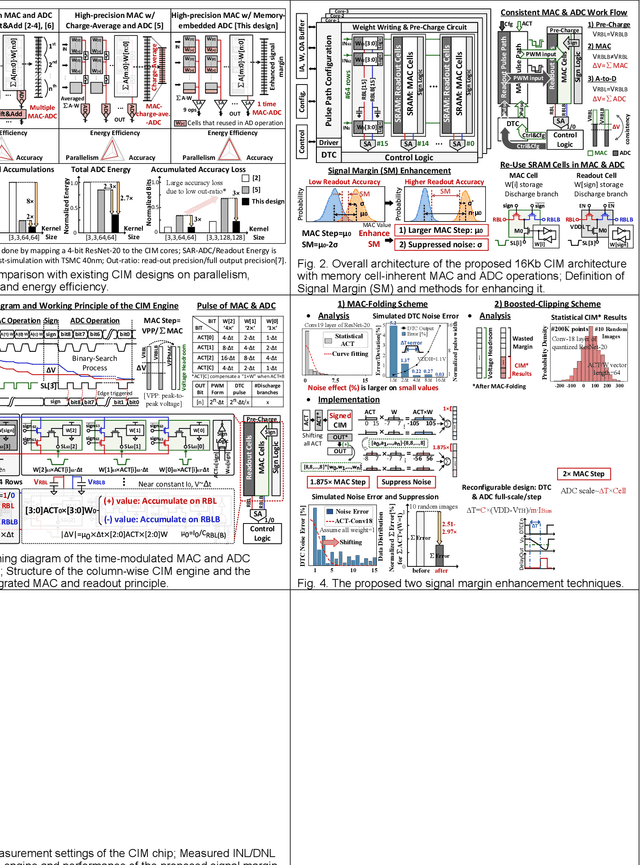
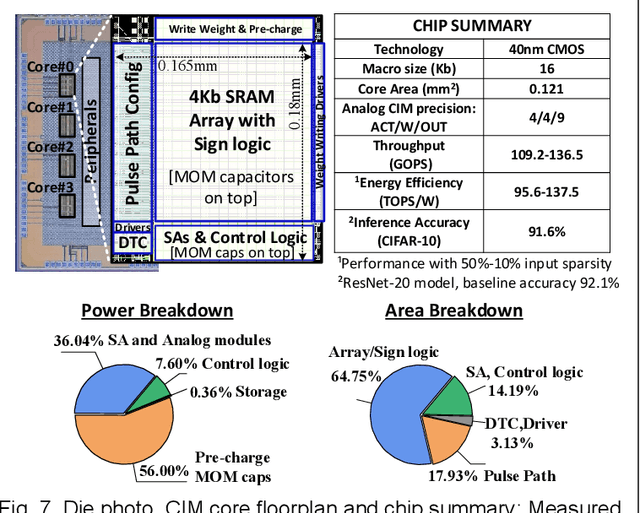
In this paper, we propose a high-precision SRAM-based CIM macro that can perform 4x4-bit MAC operations and yield 9-bit signed output. The inherent discharge branches of SRAM cells are utilized to apply time-modulated MAC and 9-bit ADC readout operations on two bit-line capacitors. The same principle is used for both MAC and A-to-D conversion ensuring high linearity and thus supporting large number of analog MAC accumulations. The memory cell-embedded ADC eliminates the use of separate ADCs and enhances energy and area efficiency. Additionally, two signal margin enhancement techniques, namely the MAC-folding and boosted-clipping schemes, are proposed to further improve the CIM computation accuracy.
One-shot Joint Extraction, Registration and Segmentation of Neuroimaging Data
Jul 27, 2023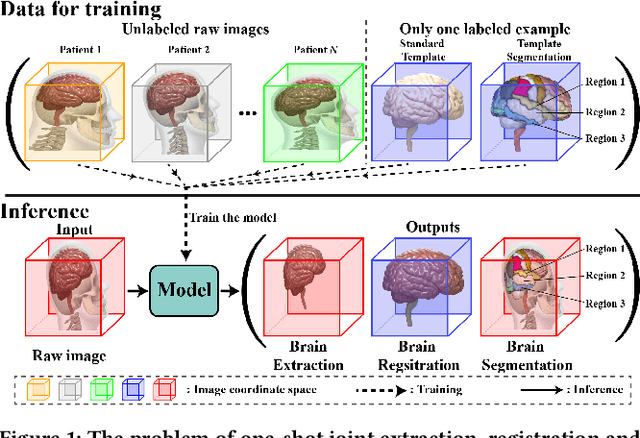
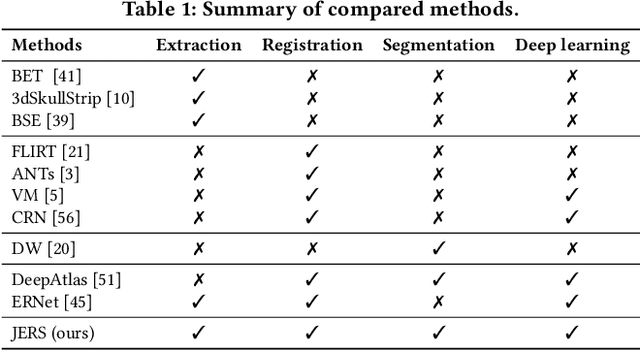
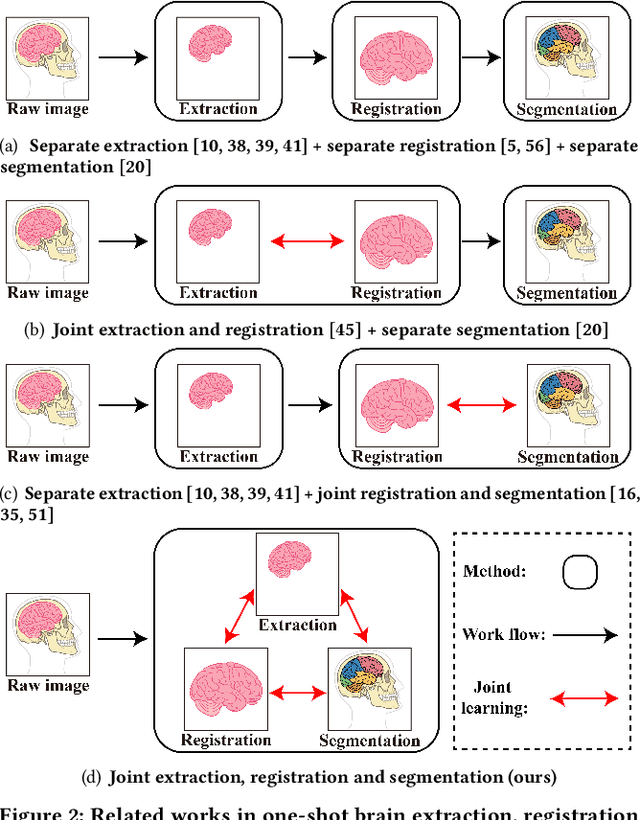

Brain extraction, registration and segmentation are indispensable preprocessing steps in neuroimaging studies. The aim is to extract the brain from raw imaging scans (i.e., extraction step), align it with a target brain image (i.e., registration step) and label the anatomical brain regions (i.e., segmentation step). Conventional studies typically focus on developing separate methods for the extraction, registration and segmentation tasks in a supervised setting. The performance of these methods is largely contingent on the quantity of training samples and the extent of visual inspections carried out by experts for error correction. Nevertheless, collecting voxel-level labels and performing manual quality control on high-dimensional neuroimages (e.g., 3D MRI) are expensive and time-consuming in many medical studies. In this paper, we study the problem of one-shot joint extraction, registration and segmentation in neuroimaging data, which exploits only one labeled template image (a.k.a. atlas) and a few unlabeled raw images for training. We propose a unified end-to-end framework, called JERS, to jointly optimize the extraction, registration and segmentation tasks, allowing feedback among them. Specifically, we use a group of extraction, registration and segmentation modules to learn the extraction mask, transformation and segmentation mask, where modules are interconnected and mutually reinforced by self-supervision. Empirical results on real-world datasets demonstrate that our proposed method performs exceptionally in the extraction, registration and segmentation tasks. Our code and data can be found at https://github.com/Anonymous4545/JERS
Scalable Real-Time Vehicle Deformation for Interactive Environments
Apr 11, 2023This paper proposes a real-time physically-based method for simulating vehicle deformation. Our system synthesizes vehicle deformation characteristics by considering a low-dimensional coupled vehicle body technique. We simulate the motion and crumbling behavior of vehicles smashing into rigid objects. We explain and demonstrate the combination of a reduced complexity non-linear finite element system that is scalable and computationally efficient. We use an explicit position-based integration scheme to improve simulation speeds, while remaining stable and preserving modeling accuracy. We show our approach using a variety of vehicle deformation test cases which were simulated in real-time.
Symbolic State Space Optimization for Long Horizon Mobile Manipulation Planning
Jul 21, 2023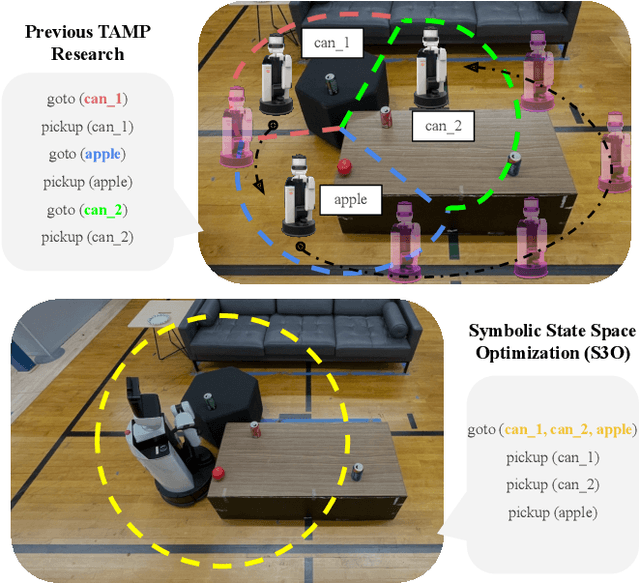
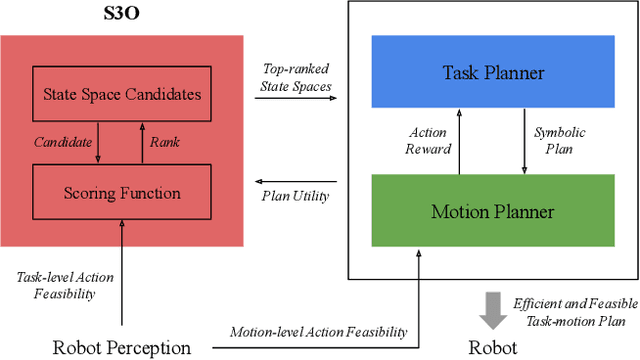
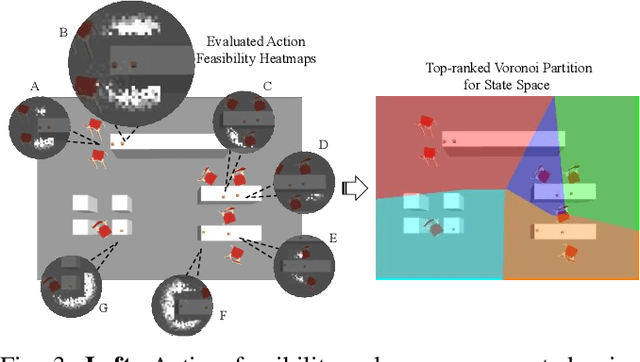
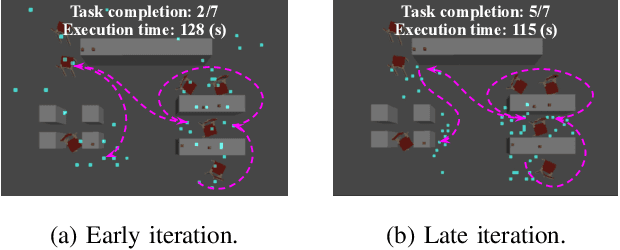
In existing task and motion planning (TAMP) research, it is a common assumption that experts manually specify the state space for task-level planning. A well-developed state space enables the desirable distribution of limited computational resources between task planning and motion planning. However, developing such task-level state spaces can be non-trivial in practice. In this paper, we consider a long horizon mobile manipulation domain including repeated navigation and manipulation. We propose Symbolic State Space Optimization (S3O) for computing a set of abstracted locations and their 2D geometric groundings for generating task-motion plans in such domains. Our approach has been extensively evaluated in simulation and demonstrated on a real mobile manipulator working on clearing up dining tables. Results show the superiority of the proposed method over TAMP baselines in task completion rate and execution time.
Identifying document similarity using a fast estimation of the Levenshtein Distance based on compression and signatures
Jul 21, 2023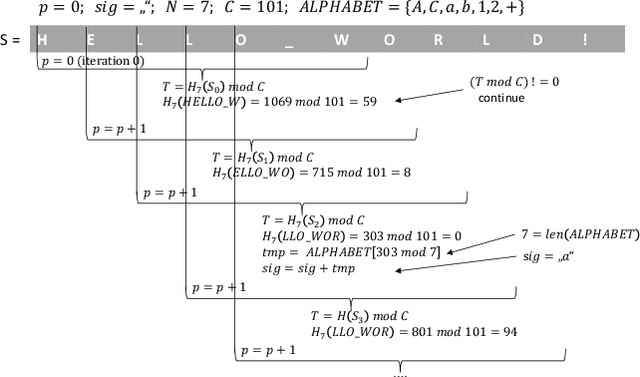
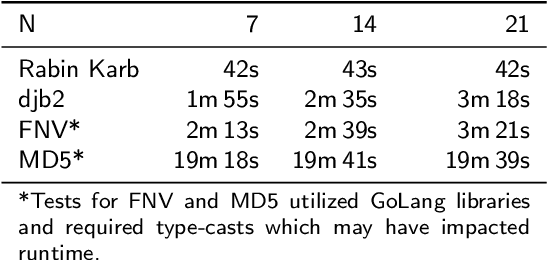
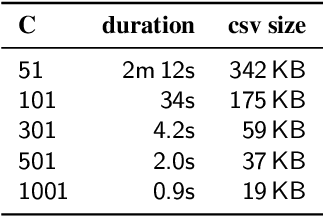
Identifying document similarity has many applications, e.g., source code analysis or plagiarism detection. However, identifying similarities is not trivial and can be time complex. For instance, the Levenshtein Distance is a common metric to define the similarity between two documents but has quadratic runtime which makes it impractical for large documents where large starts with a few hundred kilobytes. In this paper, we present a novel concept that allows estimating the Levenshtein Distance: the algorithm first compresses documents to signatures (similar to hash values) using a user-defined compression ratio. Signatures can then be compared against each other (some constrains apply) where the outcome is the estimated Levenshtein Distance. Our evaluation shows promising results in terms of runtime efficiency and accuracy. In addition, we introduce a significance score allowing examiners to set a threshold and identify related documents.
Impact of Deep Learning Libraries on Online Adaptive Lightweight Time Series Anomaly Detection
Apr 30, 2023
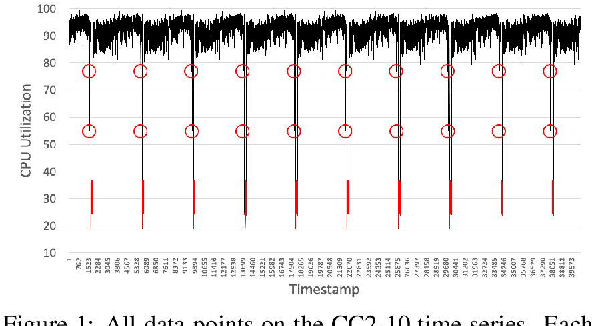
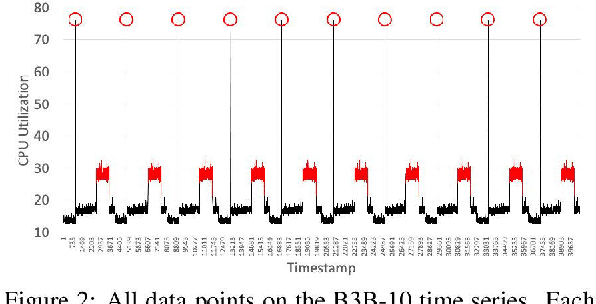
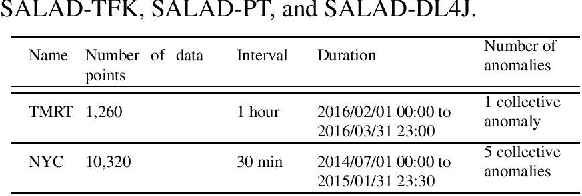
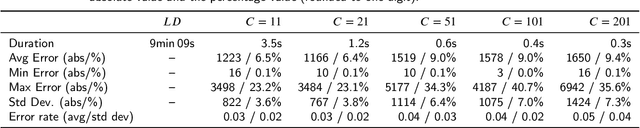
Providing online adaptive lightweight time series anomaly detection without human intervention and domain knowledge is highly valuable. Several such anomaly detection approaches have been introduced in the past years, but all of them were only implemented in one deep learning library. With the development of deep learning libraries, it is unclear how different deep learning libraries impact these anomaly detection approaches since there is no such evaluation available. Randomly choosing a deep learning library to implement an anomaly detection approach might not be able to show the true performance of the approach. It might also mislead users in believing one approach is better than another. Therefore, in this paper, we investigate the impact of deep learning libraries on online adaptive lightweight time series anomaly detection by implementing two state-of-the-art anomaly detection approaches in three well-known deep learning libraries and evaluating how these two approaches are individually affected by the three deep learning libraries. A series of experiments based on four real-world open-source time series datasets were conducted. The results provide a good reference to select an appropriate deep learning library for online adaptive lightweight anomaly detection.
A Cryogenic Memristive Neural Decoder for Fault-tolerant Quantum Error Correction
Jul 18, 2023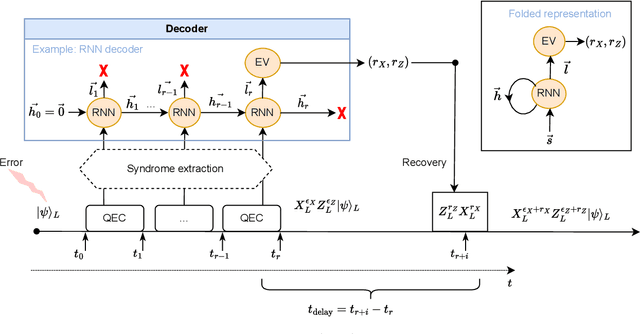
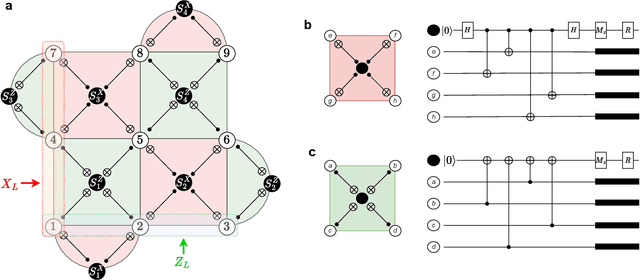
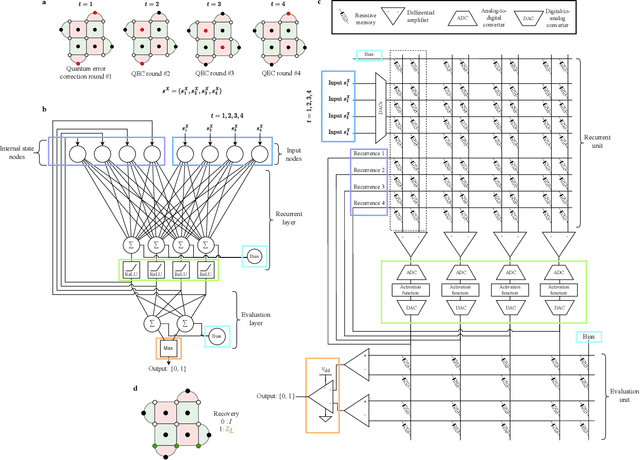
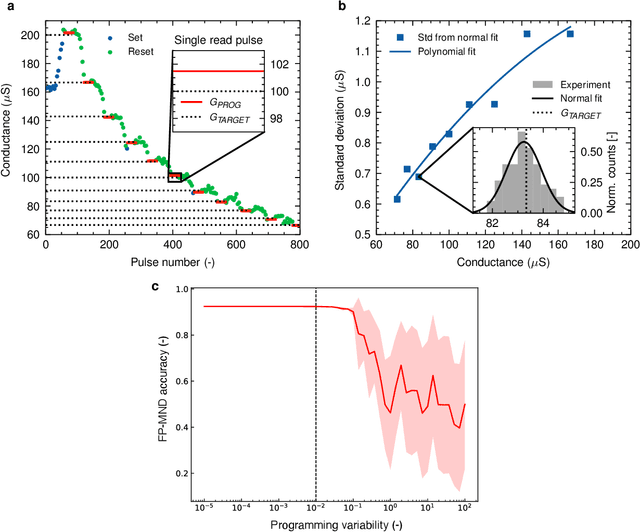
Neural decoders for quantum error correction (QEC) rely on neural networks to classify syndromes extracted from error correction codes and find appropriate recovery operators to protect logical information against errors. Despite the good performance of neural decoders, important practical requirements remain to be achieved, such as minimizing the decoding time to meet typical rates of syndrome generation in repeated error correction schemes, and ensuring the scalability of the decoding approach as the code distance increases. Designing a dedicated integrated circuit to perform the decoding task in co-integration with a quantum processor appears necessary to reach these decoding time and scalability requirements, as routing signals in and out of a cryogenic environment to be processed externally leads to unnecessary delays and an eventual wiring bottleneck. In this work, we report the design and performance analysis of a neural decoder inference accelerator based on an in-memory computing (IMC) architecture, where crossbar arrays of resistive memory devices are employed to both store the synaptic weights of the decoder neural network and perform analog matrix-vector multiplications during inference. In proof-of-concept numerical experiments supported by experimental measurements, we investigate the impact of TiO$_\textrm{x}$-based memristive devices' non-idealities on decoding accuracy. Hardware-aware training methods are developed to mitigate the loss in accuracy, allowing the memristive neural decoders to achieve a pseudo-threshold of $9.23\times 10^{-4}$ for the distance-three surface code, whereas the equivalent digital neural decoder achieves a pseudo-threshold of $1.01\times 10^{-3}$. This work provides a pathway to scalable, fast, and low-power cryogenic IMC hardware for integrated QEC.
Reinforced Disentanglement for Face Swapping without Skip Connection
Jul 26, 2023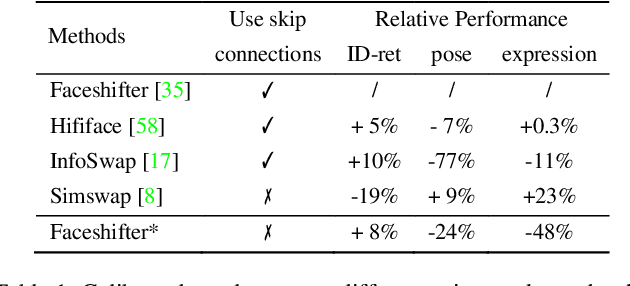
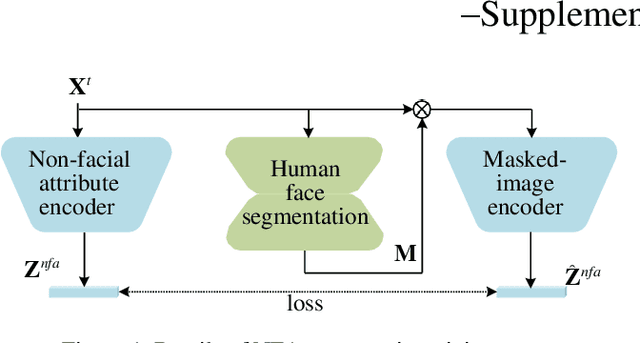
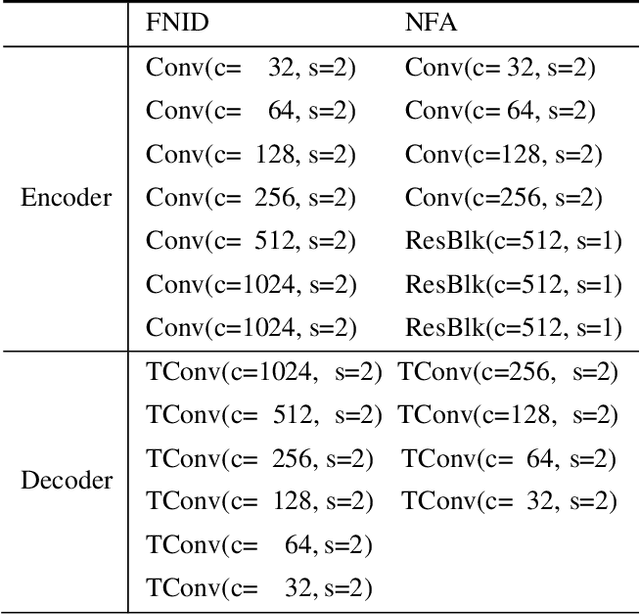

The SOTA face swap models still suffer the problem of either target identity (i.e., shape) being leaked or the target non-identity attributes (i.e., background, hair) failing to be fully preserved in the final results. We show that this insufficient disentanglement is caused by two flawed designs that were commonly adopted in prior models: (1) counting on only one compressed encoder to represent both the semantic-level non-identity facial attributes(i.e., pose) and the pixel-level non-facial region details, which is contradictory to satisfy at the same time; (2) highly relying on long skip-connections between the encoder and the final generator, leaking a certain amount of target face identity into the result. To fix them, we introduce a new face swap framework called 'WSC-swap' that gets rid of skip connections and uses two target encoders to respectively capture the pixel-level non-facial region attributes and the semantic non-identity attributes in the face region. To further reinforce the disentanglement learning for the target encoder, we employ both identity removal loss via adversarial training (i.e., GAN) and the non-identity preservation loss via prior 3DMM models like [11]. Extensive experiments on both FaceForensics++ and CelebA-HQ show that our results significantly outperform previous works on a rich set of metrics, including one novel metric for measuring identity consistency that was completely neglected before.
Unsupervised Deep Learning-based Pansharpening with Jointly-Enhanced Spectral and Spatial Fidelity
Jul 26, 2023

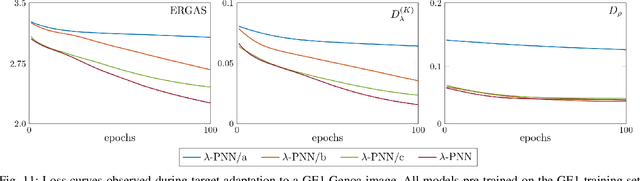

In latest years, deep learning has gained a leading role in the pansharpening of multiresolution images. Given the lack of ground truth data, most deep learning-based methods carry out supervised training in a reduced-resolution domain. However, models trained on downsized images tend to perform poorly on high-resolution target images. For this reason, several research groups are now turning to unsupervised training in the full-resolution domain, through the definition of appropriate loss functions and training paradigms. In this context, we have recently proposed a full-resolution training framework which can be applied to many existing architectures. Here, we propose a new deep learning-based pansharpening model that fully exploits the potential of this approach and provides cutting-edge performance. Besides architectural improvements with respect to previous work, such as the use of residual attention modules, the proposed model features a novel loss function that jointly promotes the spectral and spatial quality of the pansharpened data. In addition, thanks to a new fine-tuning strategy, it improves inference-time adaptation to target images. Experiments on a large variety of test images, performed in challenging scenarios, demonstrate that the proposed method compares favorably with the state of the art both in terms of numerical results and visual output. Code is available online at https://github.com/matciotola/Lambda-PNN.
Unite-Divide-Unite: Joint Boosting Trunk and Structure for High-accuracy Dichotomous Image Segmentation
Jul 26, 2023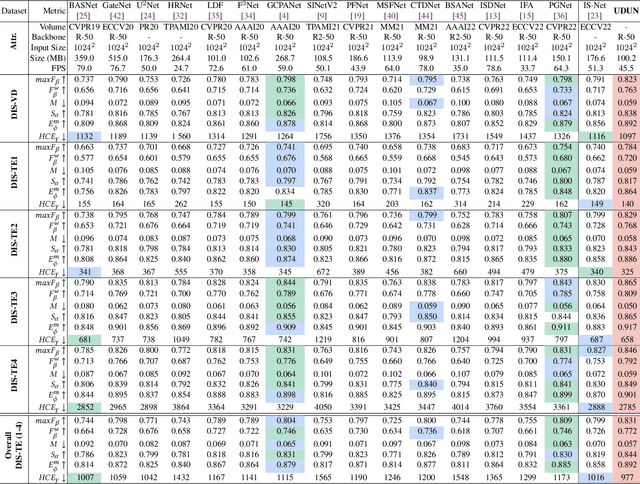
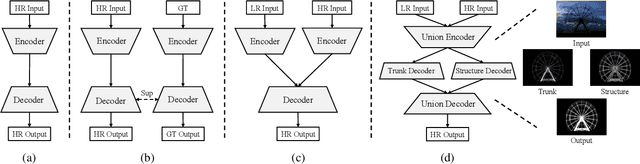

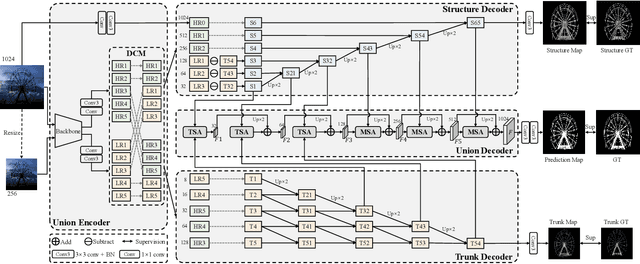
High-accuracy Dichotomous Image Segmentation (DIS) aims to pinpoint category-agnostic foreground objects from natural scenes. The main challenge for DIS involves identifying the highly accurate dominant area while rendering detailed object structure. However, directly using a general encoder-decoder architecture may result in an oversupply of high-level features and neglect the shallow spatial information necessary for partitioning meticulous structures. To fill this gap, we introduce a novel Unite-Divide-Unite Network (UDUN} that restructures and bipartitely arranges complementary features to simultaneously boost the effectiveness of trunk and structure identification. The proposed UDUN proceeds from several strengths. First, a dual-size input feeds into the shared backbone to produce more holistic and detailed features while keeping the model lightweight. Second, a simple Divide-and-Conquer Module (DCM) is proposed to decouple multiscale low- and high-level features into our structure decoder and trunk decoder to obtain structure and trunk information respectively. Moreover, we design a Trunk-Structure Aggregation module (TSA) in our union decoder that performs cascade integration for uniform high-accuracy segmentation. As a result, UDUN performs favorably against state-of-the-art competitors in all six evaluation metrics on overall DIS-TE, i.e., achieving 0.772 weighted F-measure and 977 HCE. Using 1024*1024 input, our model enables real-time inference at 65.3 fps with ResNet-18.