 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Semantics from Space: Satellite-Guided Thermal Semantic Segmentation Annotation for Aerial Field Robots
Mar 21, 2024
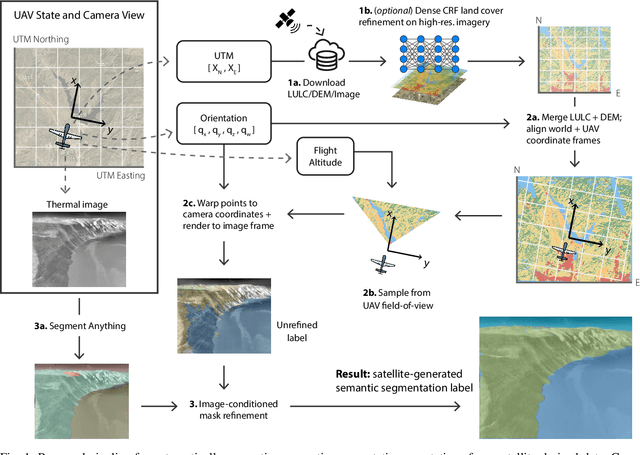
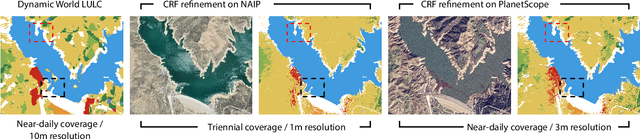
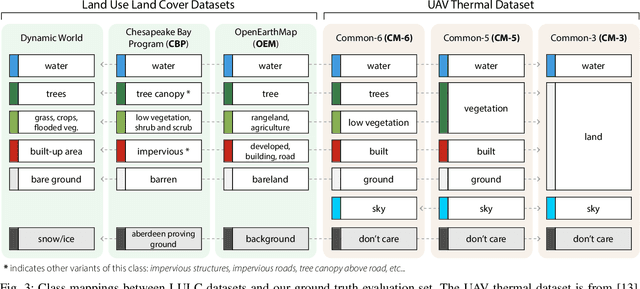

We present a new method to automatically generate semantic segmentation annotations for thermal imagery captured from an aerial vehicle by utilizing satellite-derived data products alongside onboard global positioning and attitude estimates. This new capability overcomes the challenge of developing thermal semantic perception algorithms for field robots due to the lack of annotated thermal field datasets and the time and costs of manual annotation, enabling precise and rapid annotation of thermal data from field collection efforts at a massively-parallelizable scale. By incorporating a thermal-conditioned refinement step with visual foundation models, our approach can produce highly-precise semantic segmentation labels using low-resolution satellite land cover data for little-to-no cost. It achieves 98.5% of the performance from using costly high-resolution options and demonstrates between 70-160% improvement over popular zero-shot semantic segmentation methods based on large vision-language models currently used for generating annotations for RGB imagery. Code will be available at: https://github.com/connorlee77/aerial-auto-segment.
IDAdapter: Learning Mixed Features for Tuning-Free Personalization of Text-to-Image Models
Mar 21, 2024
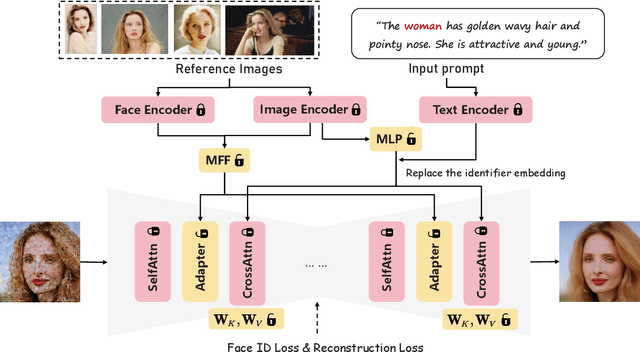
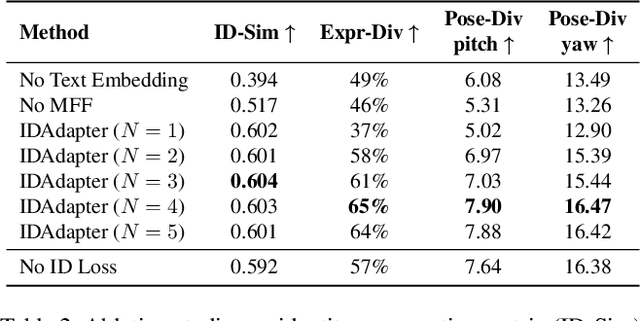

Leveraging Stable Diffusion for the generation of personalized portraits has emerged as a powerful and noteworthy tool, enabling users to create high-fidelity, custom character avatars based on their specific prompts. However, existing personalization methods face challenges, including test-time fine-tuning, the requirement of multiple input images, low preservation of identity, and limited diversity in generated outcomes. To overcome these challenges, we introduce IDAdapter, a tuning-free approach that enhances the diversity and identity preservation in personalized image generation from a single face image. IDAdapter integrates a personalized concept into the generation process through a combination of textual and visual injections and a face identity loss. During the training phase, we incorporate mixed features from multiple reference images of a specific identity to enrich identity-related content details, guiding the model to generate images with more diverse styles, expressions, and angles compared to previous works. Extensive evaluations demonstrate the effectiveness of our method, achieving both diversity and identity fidelity in generated images.
An Efficient Rate Splitting Precoding Approach in Multi-User MISO FDD Systems
Mar 21, 2024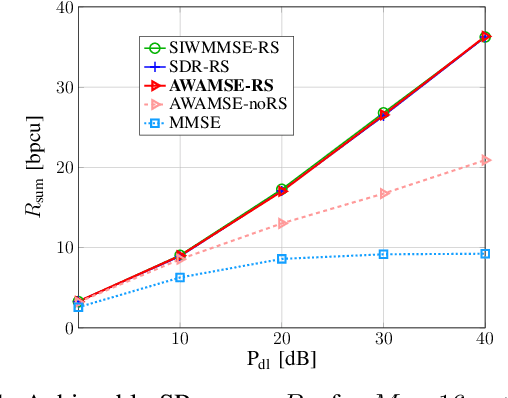
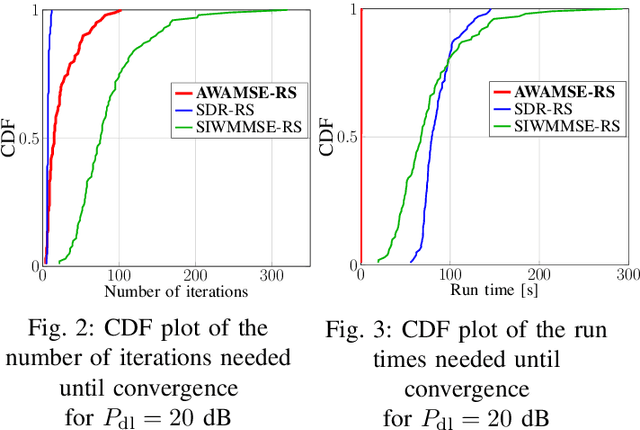
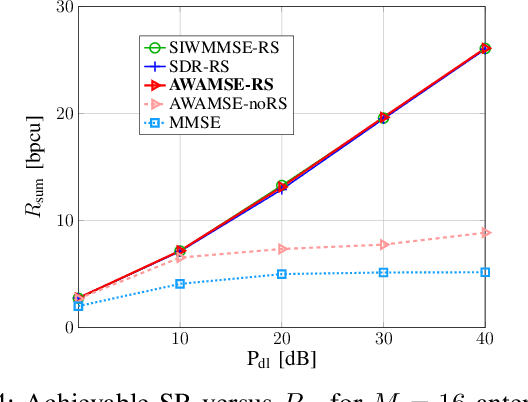
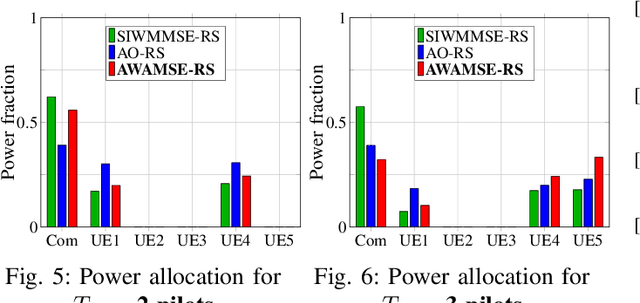
In this work, we develop an efficient precoding strategy for a multi-user multiple-input-single output (MU MISO) system operating in frequency-division-duplex (FDD) mode, where rate splitting multiple access (RSMA) is implemented. To this end, we consider one-layer RS and show its significant impact on the system performance, specifically in the case where the channel state information (CSI) is incomplete at the transmitter. Based on a lower bound on the achievable rate that takes into account the CSI errors, we establish an augmented weighted average mean squared error (AWAMSE) algorithm for the RS setup denoted by AWAMSE-RS, where even the updates for the common and the private precoders are computed via analytical expressions, hence circumventing the need for interior-point methods. Simulation results validate the efficiency of our approach in terms of computational time and its competitiveness in terms of the achievable system throughput compared to state-of-the-art methods and non-RS setups.
A Physics-embedded Deep Learning Framework for Cloth Simulation
Mar 19, 2024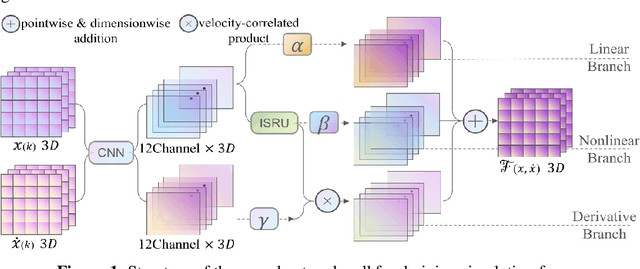

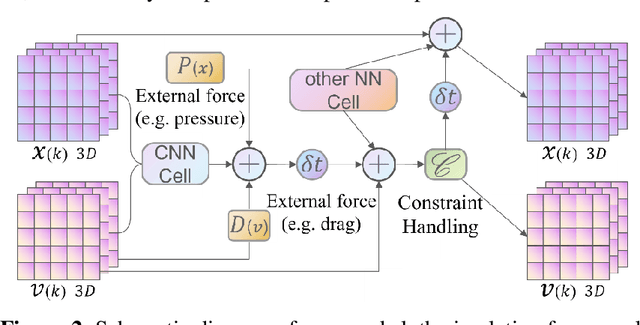

Delicate cloth simulations have long been desired in computer graphics. Various methods were proposed to improve engaged force interactions, collision handling, and numerical integrations. Deep learning has the potential to achieve fast and real-time simulation, but common neural network structures often demand many parameters to capture cloth dynamics. This paper proposes a physics-embedded learning framework that directly encodes physical features of cloth simulation. The convolutional neural network is used to represent spatial correlations of the mass-spring system, after which three branches are designed to learn linear, nonlinear, and time derivate features of cloth physics. The framework can also integrate with other external forces and collision handling through either traditional simulators or sub neural networks. The model is tested across different cloth animation cases, without training with new data. Agreement with baselines and predictive realism successfully validate its generalization ability. Inference efficiency of the proposed model also defeats traditional physics simulation. This framework is also designed to easily integrate with other visual refinement techniques like wrinkle carving, which leaves significant chances to incorporate prevailing macing learning techniques in 3D cloth amination.
IFSENet : Harnessing Sparse Iterations for Interactive Few-shot Segmentation Excellence
Mar 22, 2024Training a computer vision system to segment a novel class typically requires collecting and painstakingly annotating lots of images with objects from that class. Few-shot segmentation techniques reduce the required number of images to learn to segment a new class, but careful annotations of object boundaries are still required. On the other hand, interactive segmentation techniques only focus on incrementally improving the segmentation of one object at a time (typically, using clicks given by an expert) in a class-agnostic manner. We combine the two concepts to drastically reduce the effort required to train segmentation models for novel classes. Instead of trivially feeding interactive segmentation masks as ground truth to a few-shot segmentation model, we propose IFSENet, which can accept sparse supervision on a single or few support images in the form of clicks to generate masks on support (training, at least clicked upon once) as well as query (test, never clicked upon) images. To trade-off effort for accuracy flexibly, the number of images and clicks can be incrementally added to the support set to further improve the segmentation of support as well as query images. The proposed model approaches the accuracy of previous state-of-the-art few-shot segmentation models with considerably lower annotation effort (clicks instead of maps), when tested on Pascal and SBD datasets on query images. It also works well as an interactive segmentation method on support images.
SFOD: Spiking Fusion Object Detector
Mar 22, 2024Event cameras, characterized by high temporal resolution, high dynamic range, low power consumption, and high pixel bandwidth, offer unique capabilities for object detection in specialized contexts. Despite these advantages, the inherent sparsity and asynchrony of event data pose challenges to existing object detection algorithms. Spiking Neural Networks (SNNs), inspired by the way the human brain codes and processes information, offer a potential solution to these difficulties. However, their performance in object detection using event cameras is limited in current implementations. In this paper, we propose the Spiking Fusion Object Detector (SFOD), a simple and efficient approach to SNN-based object detection. Specifically, we design a Spiking Fusion Module, achieving the first-time fusion of feature maps from different scales in SNNs applied to event cameras. Additionally, through integrating our analysis and experiments conducted during the pretraining of the backbone network on the NCAR dataset, we delve deeply into the impact of spiking decoding strategies and loss functions on model performance. Thereby, we establish state-of-the-art classification results based on SNNs, achieving 93.7\% accuracy on the NCAR dataset. Experimental results on the GEN1 detection dataset demonstrate that the SFOD achieves a state-of-the-art mAP of 32.1\%, outperforming existing SNN-based approaches. Our research not only underscores the potential of SNNs in object detection with event cameras but also propels the advancement of SNNs. Code is available at https://github.com/yimeng-fan/SFOD.
Enhanced Detection of Transdermal Alcohol Levels Using Hyperdimensional Computing on Embedded Devices
Mar 18, 2024
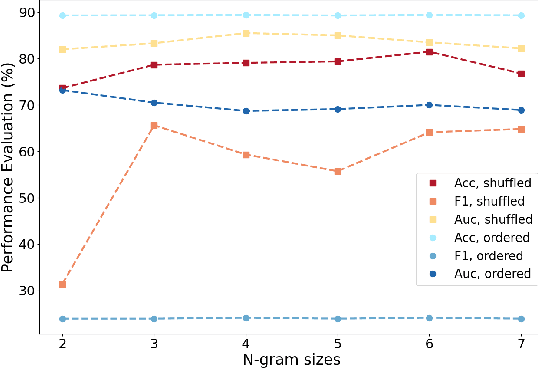
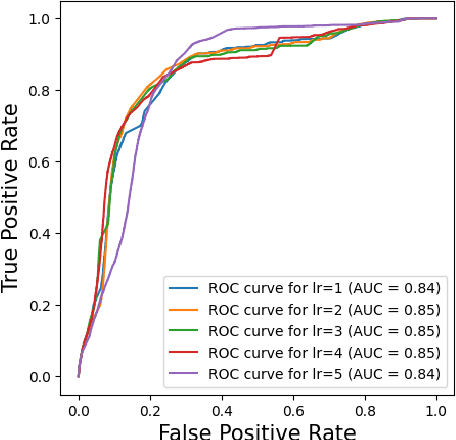
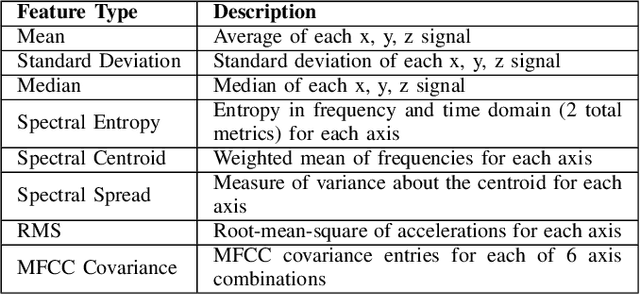
Alcohol consumption has a significant impact on individuals' health, with even more pronounced consequences when consumption becomes excessive. One approach to promoting healthier drinking habits is implementing just-in-time interventions, where timely notifications indicating intoxication are sent during heavy drinking episodes. However, the complexity or invasiveness of an intervention mechanism may deter an individual from using them in practice. Previous research tackled this challenge using collected motion data and conventional Machine Learning (ML) algorithms to classify heavy drinking episodes, but with impractical accuracy and computational efficiency for mobile devices. Consequently, we have elected to use Hyperdimensional Computing (HDC) to design a just-in-time intervention approach that is practical for smartphones, smart wearables, and IoT deployment. HDC is a framework that has proven results in processing real-time sensor data efficiently. This approach offers several advantages, including low latency, minimal power consumption, and high parallelism. We explore various HDC encoding designs and combine them with various HDC learning models to create an optimal and feasible approach for mobile devices. Our findings indicate an accuracy rate of 89\%, which represents a substantial 12\% improvement over the current state-of-the-art.
Methods for Generating Drift in Text Streams
Mar 18, 2024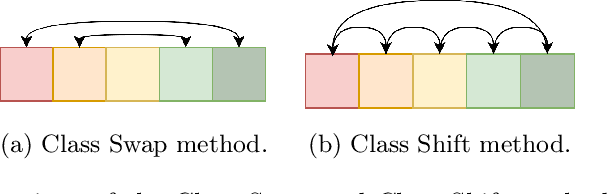
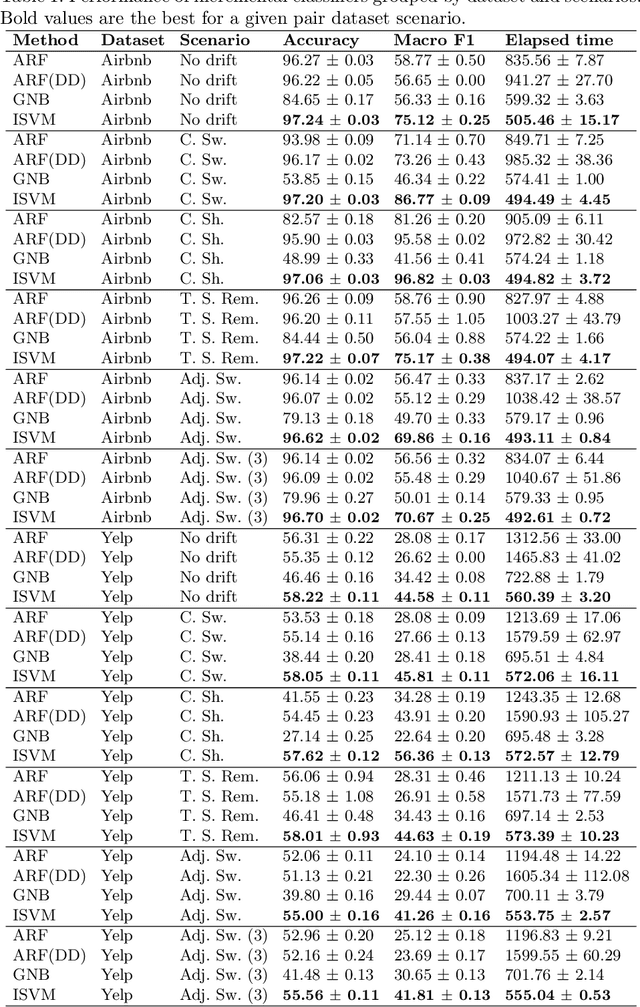

Systems and individuals produce data continuously. On the Internet, people share their knowledge, sentiments, and opinions, provide reviews about services and products, and so on. Automatically learning from these textual data can provide insights to organizations and institutions, thus preventing financial impacts, for example. To learn from textual data over time, the machine learning system must account for concept drift. Concept drift is a frequent phenomenon in real-world datasets and corresponds to changes in data distribution over time. For instance, a concept drift occurs when sentiments change or a word's meaning is adjusted over time. Although concept drift is frequent in real-world applications, benchmark datasets with labeled drifts are rare in the literature. To bridge this gap, this paper provides four textual drift generation methods to ease the production of datasets with labeled drifts. These methods were applied to Yelp and Airbnb datasets and tested using incremental classifiers respecting the stream mining paradigm to evaluate their ability to recover from the drifts. Results show that all methods have their performance degraded right after the drifts, and the incremental SVM is the fastest to run and recover the previous performance levels regarding accuracy and Macro F1-Score.
Exploring the Influence of Dimensionality Reduction on Anomaly Detection Performance in Multivariate Time Series
Mar 07, 2024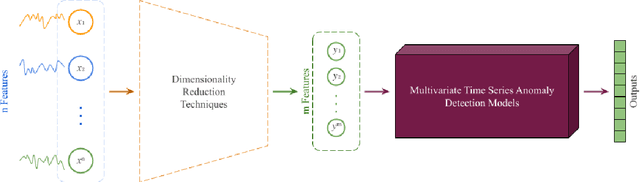

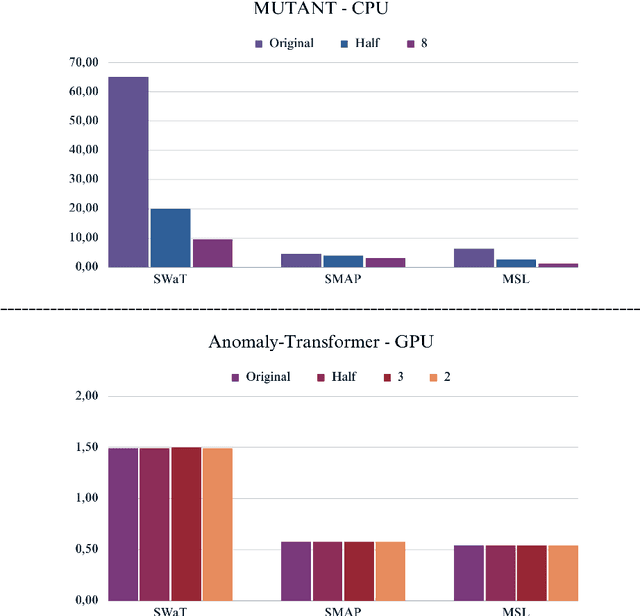
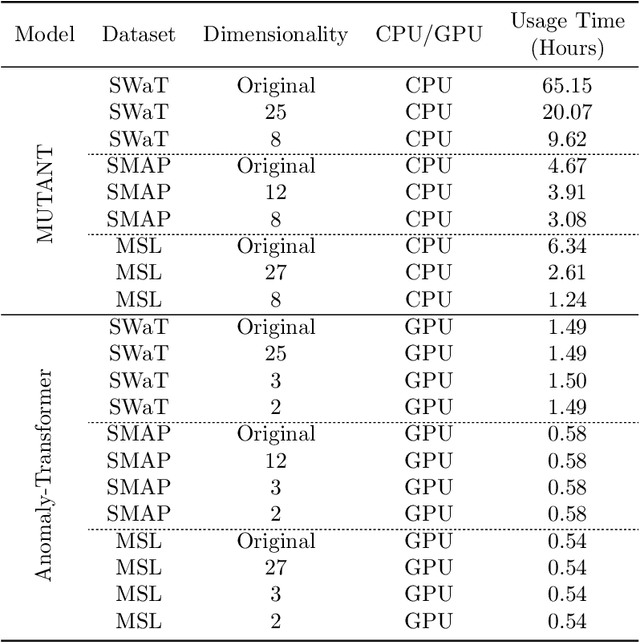
This paper presents an extensive empirical study on the integration of dimensionality reduction techniques with advanced unsupervised time series anomaly detection models, focusing on the MUTANT and Anomaly-Transformer models. The study involves a comprehensive evaluation across three different datasets: MSL, SMAP, and SWaT. Each dataset poses unique challenges, allowing for a robust assessment of the models' capabilities in varied contexts. The dimensionality reduction techniques examined include PCA, UMAP, Random Projection, and t-SNE, each offering distinct advantages in simplifying high-dimensional data. Our findings reveal that dimensionality reduction not only aids in reducing computational complexity but also significantly enhances anomaly detection performance in certain scenarios. Moreover, a remarkable reduction in training times was observed, with reductions by approximately 300\% and 650\% when dimensionality was halved and minimized to the lowest dimensions, respectively. This efficiency gain underscores the dual benefit of dimensionality reduction in both performance enhancement and operational efficiency. The MUTANT model exhibits notable adaptability, especially with UMAP reduction, while the Anomaly-Transformer demonstrates versatility across various reduction techniques. These insights provide a deeper understanding of the synergistic effects of dimensionality reduction and anomaly detection, contributing valuable perspectives to the field of time series analysis. The study underscores the importance of selecting appropriate dimensionality reduction strategies based on specific model requirements and dataset characteristics, paving the way for more efficient, accurate, and scalable solutions in anomaly detection.
Exploring 3D-aware Latent Spaces for Efficiently Learning Numerous Scenes
Mar 18, 2024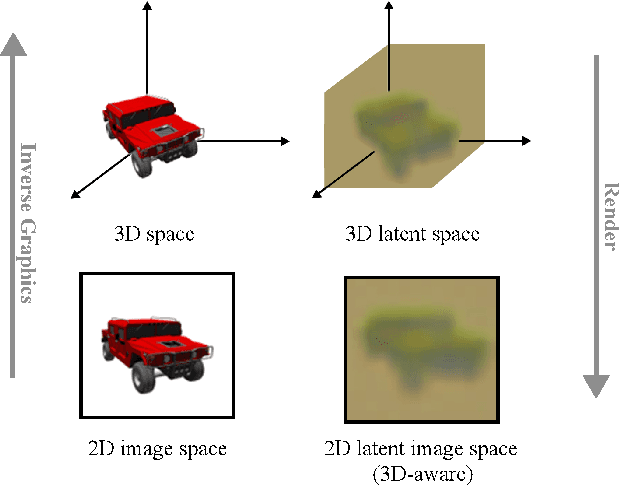
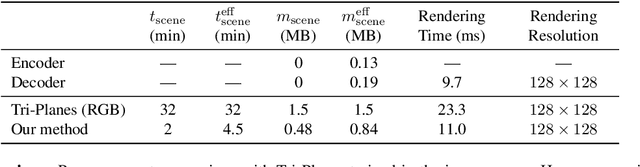
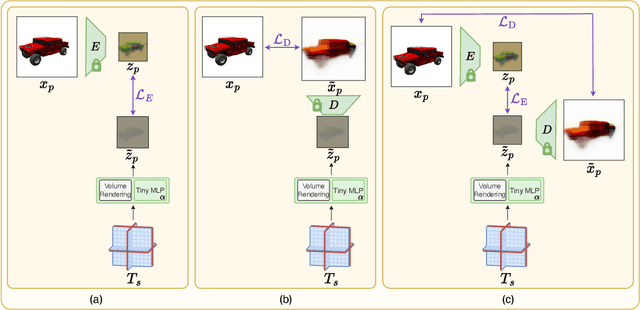

We present a method enabling the scaling of NeRFs to learn a large number of semantically-similar scenes. We combine two techniques to improve the required training time and memory cost per scene. First, we learn a 3D-aware latent space in which we train Tri-Plane scene representations, hence reducing the resolution at which scenes are learned. Moreover, we present a way to share common information across scenes, hence allowing for a reduction of model complexity to learn a particular scene. Our method reduces effective per-scene memory costs by 44% and per-scene time costs by 86% when training 1000 scenes. Our project page can be found at https://3da-ae.github.io .