 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Nonautonomous Systems via Dynamic Mode Decomposition
Jun 27, 2023
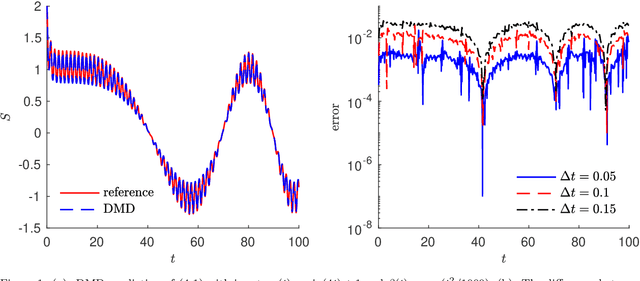
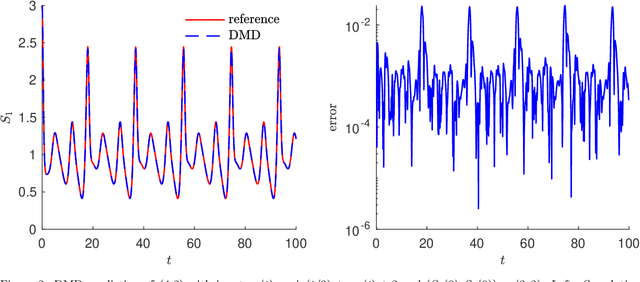
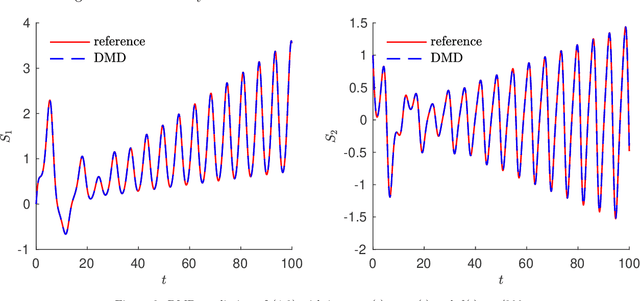
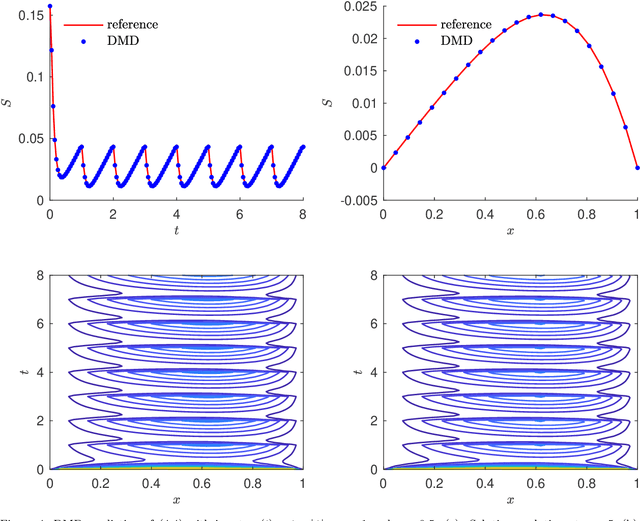
We present a data-driven learning approach for unknown nonautonomous dynamical systems with time-dependent inputs based on dynamic mode decomposition (DMD). To circumvent the difficulty of approximating the time-dependent Koopman operators for nonautonomous systems, a modified system derived from local parameterization of the external time-dependent inputs is employed as an approximation to the original nonautonomous system. The modified system comprises a sequence of local parametric systems, which can be well approximated by a parametric surrogate model using our previously proposed framework for dimension reduction and interpolation in parameter space (DRIPS). The offline step of DRIPS relies on DMD to build a linear surrogate model, endowed with reduced-order bases (ROBs), for the observables mapped from training data. Then the offline step constructs a sequence of iterative parametric surrogate models from interpolations on suitable manifolds, where the target/test parameter points are specified by the local parameterization of the test external time-dependent inputs. We present a number of numerical examples to demonstrate the robustness of our method and compare its performance with deep neural networks in the same settings.
Finite element inspired networks: Learning physically-plausible deformable object dynamics from partial observations
Jul 16, 2023The accurate simulation of deformable linear object (DLO) dynamics is challenging if the task at hand requires a human-interpretable and data-efficient model that also yields fast predictions. To arrive at such model, we draw inspiration from the rigid finite element method (R-FEM) and model a DLO as a serial chain of rigid bodies whose internal state is unrolled through time by a dynamics network. As this state is not observed directly, the dynamics network is trained jointly with a physics-informed encoder mapping observed motion variables to the body chain's state. To encourage that the state acquires a physically meaningful representation, we leverage the forward kinematics (FK) of the underlying R-FEM model as a decoder. We demonstrate in a robot experiment that this architecture - being termed "Finite element inspired network" - forms an easy to handle, yet capable DLO dynamics model yielding physically interpretable predictions from partial observations. The project code is available at: \url{https://tinyurl.com/fei-networks}
Reducing Onboard Processing Time for Path Planning in Dynamically Evolving Polygonal Maps
May 08, 2023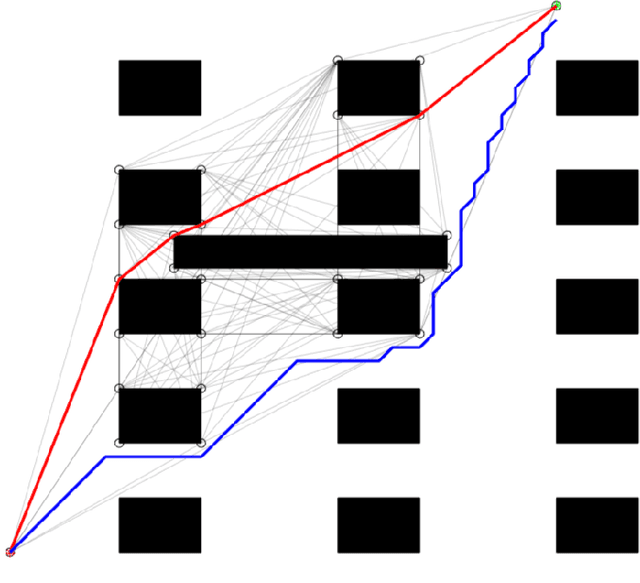
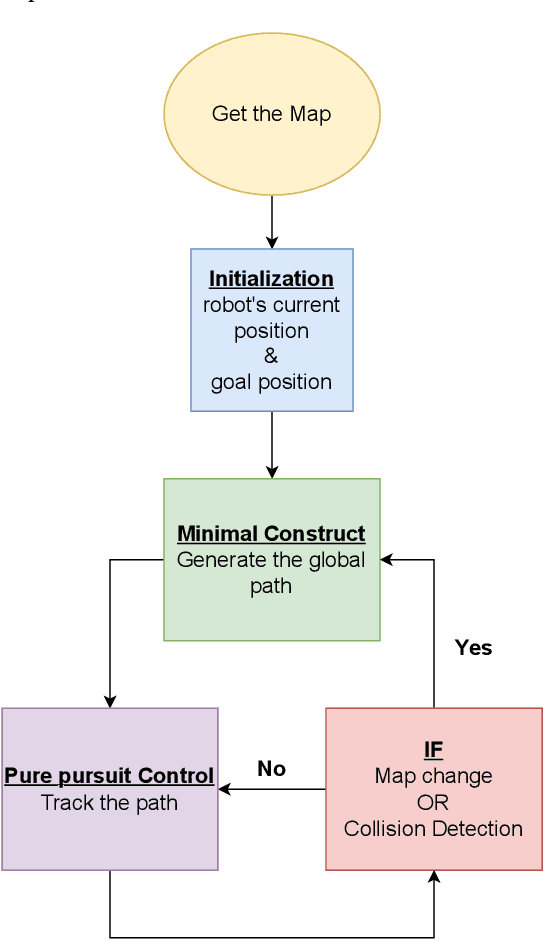
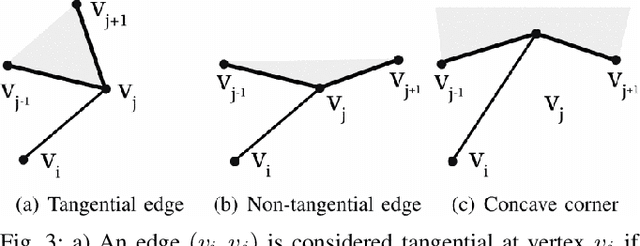
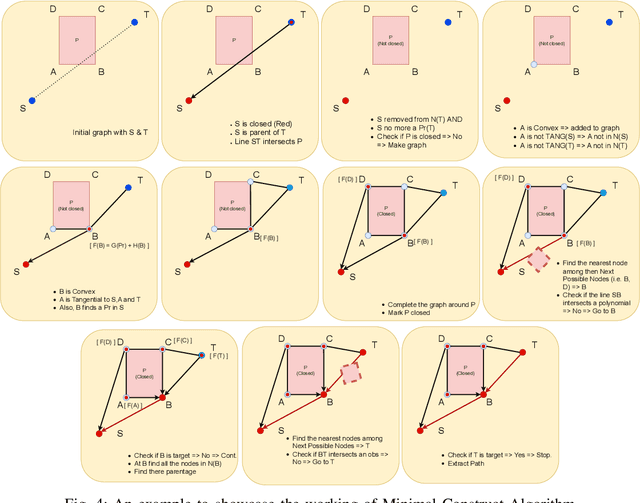
Autonomous agents face the challenge of coordinating multiple tasks (perception, motion planning, controller) which are computationally expensive on a single onboard computer. To utilize the onboard processing capacity optimally, it is imperative to arrive at computationally efficient algorithms for global path planning. In this work, it is attempted to reduce the processing time for global path planning in dynamically evolving polygonal maps. In dynamic environments, maps may not remain valid for long. Hence it is of utmost importance to obtain the shortest path quickly in an ever-changing environment. To address this, an existing rapid path-finding algorithm, the Minimal Construct was used. This algorithm discovers only a necessary portion of the Visibility Graph around obstacles and computes collision tests only for lines that seem heuristically promising. Simulations show that this algorithm finds shortest paths faster than traditional grid-based A* searches in most cases, resulting in smoother and shorter paths even in dynamic environments.
MaxMin-L2-SVC-NCH: A New Method to Train Support Vector Classifier with the Selection of Model's Parameters
Jul 14, 2023

The selection of model's parameters plays an important role in the application of support vector classification (SVC). The commonly used method of selecting model's parameters is the k-fold cross validation with grid search (CV). It is extremely time-consuming because it needs to train a large number of SVC models. In this paper, a new method is proposed to train SVC with the selection of model's parameters. Firstly, training SVC with the selection of model's parameters is modeled as a minimax optimization problem (MaxMin-L2-SVC-NCH), in which the minimization problem is an optimization problem of finding the closest points between two normal convex hulls (L2-SVC-NCH) while the maximization problem is an optimization problem of finding the optimal model's parameters. A lower time complexity can be expected in MaxMin-L2-SVC-NCH because CV is abandoned. A gradient-based algorithm is then proposed to solve MaxMin-L2-SVC-NCH, in which L2-SVC-NCH is solved by a projected gradient algorithm (PGA) while the maximization problem is solved by a gradient ascent algorithm with dynamic learning rate. To demonstrate the advantages of the PGA in solving L2-SVC-NCH, we carry out a comparison of the PGA and the famous sequential minimal optimization (SMO) algorithm after a SMO algorithm and some KKT conditions for L2-SVC-NCH are provided. It is revealed that the SMO algorithm is a special case of the PGA. Thus, the PGA can provide more flexibility. The comparative experiments between MaxMin-L2-SVC-NCH and the classical parameter selection models on public datasets show that MaxMin-L2-SVC-NCH greatly reduces the number of models to be trained and the test accuracy is not lost to the classical models. It indicates that MaxMin-L2-SVC-NCH performs better than the other models. We strongly recommend MaxMin-L2-SVC-NCH as a preferred model for SVC task.
EMQ: Evolving Training-free Proxies for Automated Mixed Precision Quantization
Jul 20, 2023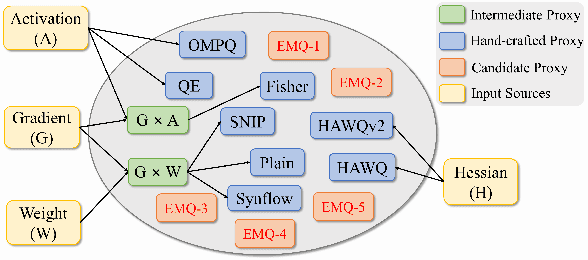
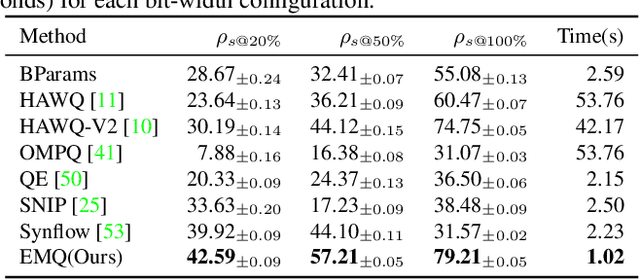
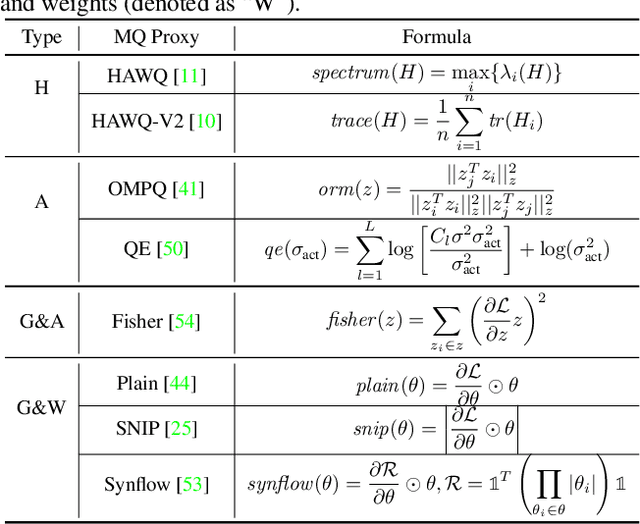
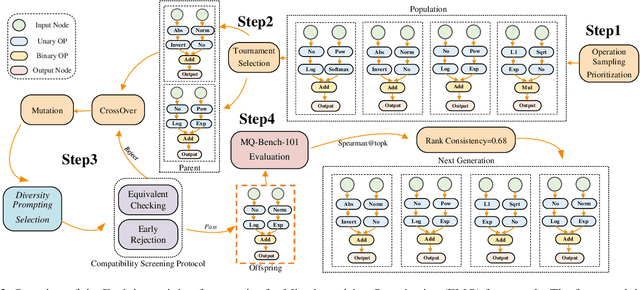
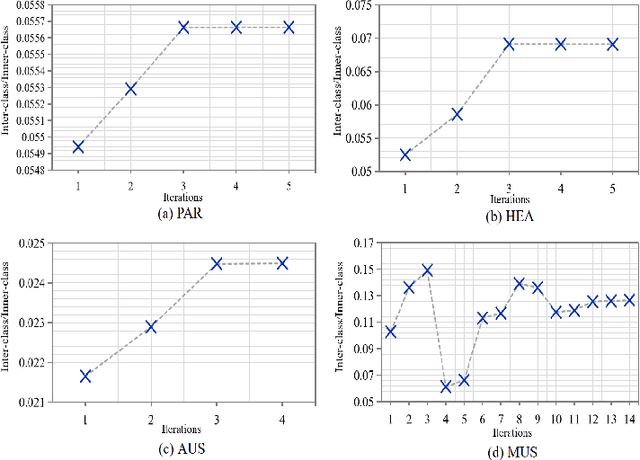
Mixed-Precision Quantization~(MQ) can achieve a competitive accuracy-complexity trade-off for models. Conventional training-based search methods require time-consuming candidate training to search optimized per-layer bit-width configurations in MQ. Recently, some training-free approaches have presented various MQ proxies and significantly improve search efficiency. However, the correlation between these proxies and quantization accuracy is poorly understood. To address the gap, we first build the MQ-Bench-101, which involves different bit configurations and quantization results. Then, we observe that the existing training-free proxies perform weak correlations on the MQ-Bench-101. To efficiently seek superior proxies, we develop an automatic search of proxies framework for MQ via evolving algorithms. In particular, we devise an elaborate search space involving the existing proxies and perform an evolution search to discover the best correlated MQ proxy. We proposed a diversity-prompting selection strategy and compatibility screening protocol to avoid premature convergence and improve search efficiency. In this way, our Evolving proxies for Mixed-precision Quantization~(EMQ) framework allows the auto-generation of proxies without heavy tuning and expert knowledge. Extensive experiments on ImageNet with various ResNet and MobileNet families demonstrate that our EMQ obtains superior performance than state-of-the-art mixed-precision methods at a significantly reduced cost. The code will be released.
Sensing User's Activity, Channel, and Location with Near-Field Extra-Large-Scale MIMO
Jul 20, 2023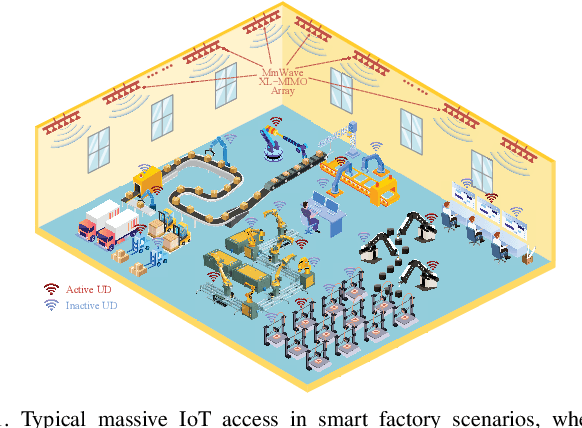
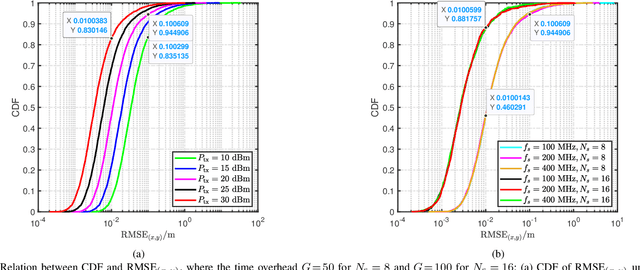
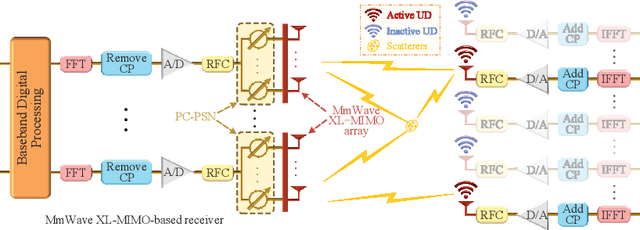
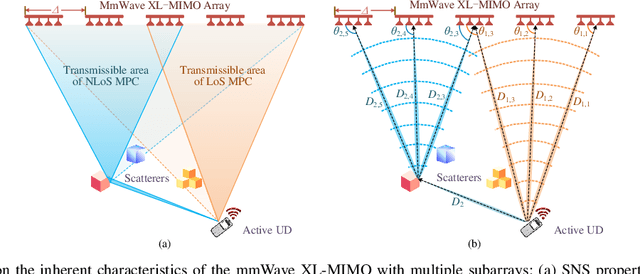
This paper proposes a grant-free massive access scheme based on the millimeter wave (mmWave) extra-large-scale multiple-input multiple-output (XL-MIMO) to support massive Internet-of-Things (IoT) devices with low latency, high data rate, and high localization accuracy in the upcoming sixth-generation (6G) networks. The XL-MIMO consists of multiple antenna subarrays that are widely spaced over the service area to ensure line-of-sight (LoS) transmissions. First, we establish the XL-MIMO-based massive access model considering the near-field spatial non-stationary (SNS) property. Then, by exploiting the block sparsity of subarrays and the SNS property, we propose a structured block orthogonal matching pursuit algorithm for efficient active user detection (AUD) and channel estimation (CE). Furthermore, different sensing matrices are applied in different pilot subcarriers for exploiting the diversity gains. Additionally, a multi-subarray collaborative localization algorithm is designed for localization. In particular, the angle of arrival (AoA) and time difference of arrival (TDoA) of the LoS links between active users and related subarrays are extracted from the estimated XL-MIMO channels, and then the coordinates of active users are acquired by jointly utilizing the AoAs and TDoAs. Simulation results show that the proposed algorithms outperform existing algorithms in terms of AUD and CE performance and can achieve centimeter-level localization accuracy.
Multimodal LLMs for health grounded in individual-specific data
Jul 20, 2023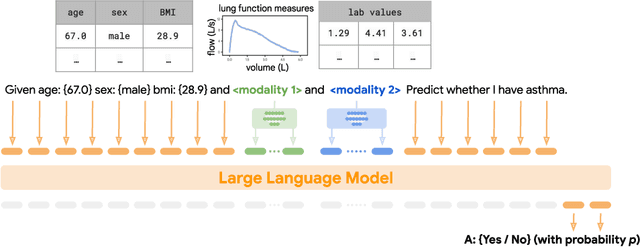
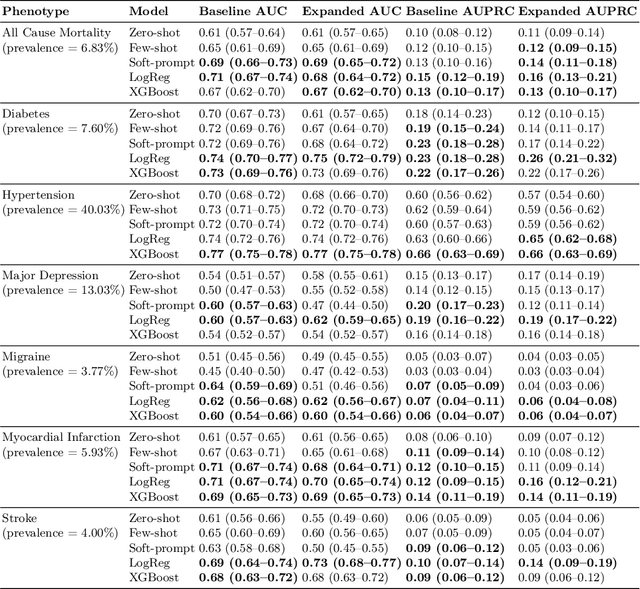
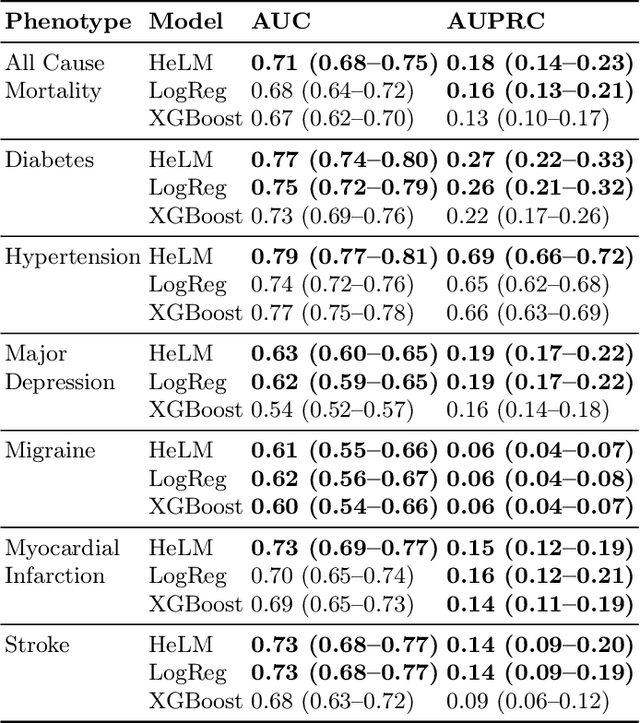
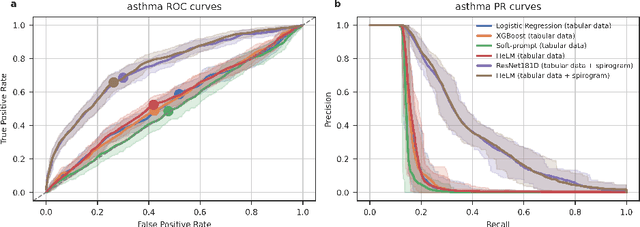
Foundation large language models (LLMs) have shown an impressive ability to solve tasks across a wide range of fields including health. To effectively solve personalized health tasks, LLMs need the ability to ingest a diversity of data modalities that are relevant to an individual's health status. In this paper, we take a step towards creating multimodal LLMs for health that are grounded in individual-specific data by developing a framework (HeLM: Health Large Language Model for Multimodal Understanding) that enables LLMs to use high-dimensional clinical modalities to estimate underlying disease risk. HeLM encodes complex data modalities by learning an encoder that maps them into the LLM's token embedding space and for simple modalities like tabular data by serializing the data into text. Using data from the UK Biobank, we show that HeLM can effectively use demographic and clinical features in addition to high-dimensional time-series data to estimate disease risk. For example, HeLM achieves an AUROC of 0.75 for asthma prediction when combining tabular and spirogram data modalities compared with 0.49 when only using tabular data. Overall, we find that HeLM outperforms or performs at parity with classical machine learning approaches across a selection of eight binary traits. Furthermore, we investigate the downstream uses of this model such as its generalizability to out-of-distribution traits and its ability to power conversations around individual health and wellness.
Learning Active Subspaces and Discovering Important Features with Gaussian Radial Basis Functions Neural Networks
Jul 11, 2023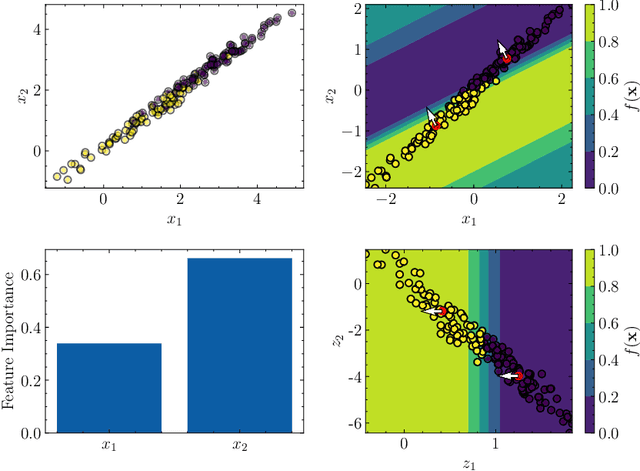
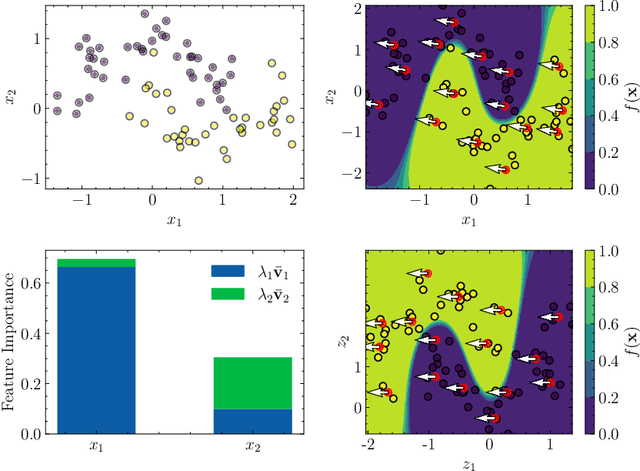
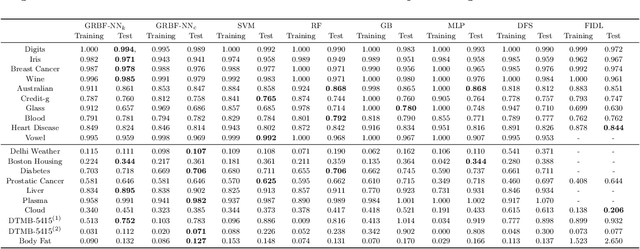
Providing a model that achieves a strong predictive performance and at the same time is interpretable by humans is one of the most difficult challenges in machine learning research due to the conflicting nature of these two objectives. To address this challenge, we propose a modification of the Radial Basis Function Neural Network model by equipping its Gaussian kernel with a learnable precision matrix. We show that precious information is contained in the spectrum of the precision matrix that can be extracted once the training of the model is completed. In particular, the eigenvectors explain the directions of maximum sensitivity of the model revealing the active subspace and suggesting potential applications for supervised dimensionality reduction. At the same time, the eigenvectors highlight the relationship in terms of absolute variation between the input and the latent variables, thereby allowing us to extract a ranking of the input variables based on their importance to the prediction task enhancing the model interpretability. We conducted numerical experiments for regression, classification, and feature selection tasks, comparing our model against popular machine learning models and the state-of-the-art deep learning-based embedding feature selection techniques. Our results demonstrate that the proposed model does not only yield an attractive prediction performance with respect to the competitors but also provides meaningful and interpretable results that potentially could assist the decision-making process in real-world applications. A PyTorch implementation of the model is available on GitHub at the following link. https://github.com/dannyzx/GRBF-NNs
Towards Anytime Optical Flow Estimation with Event Cameras
Jul 11, 2023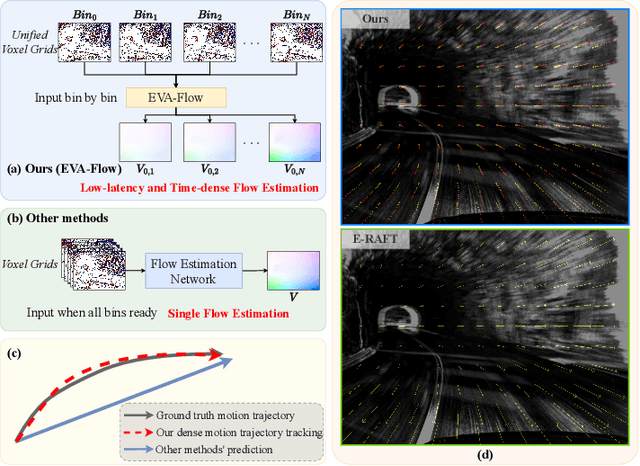
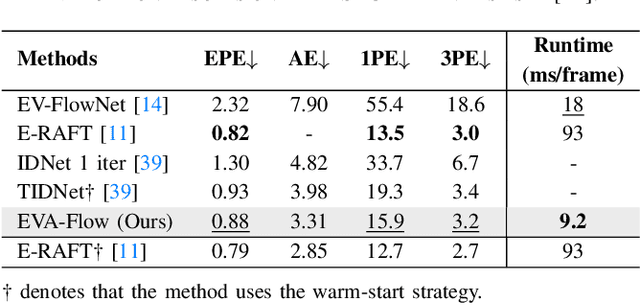
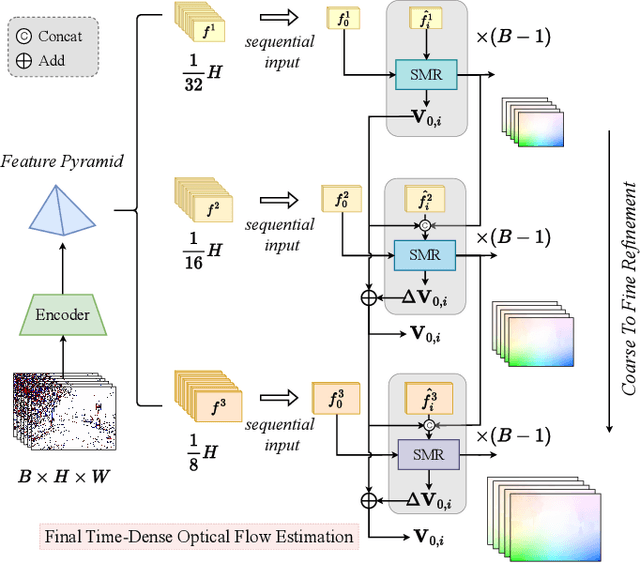
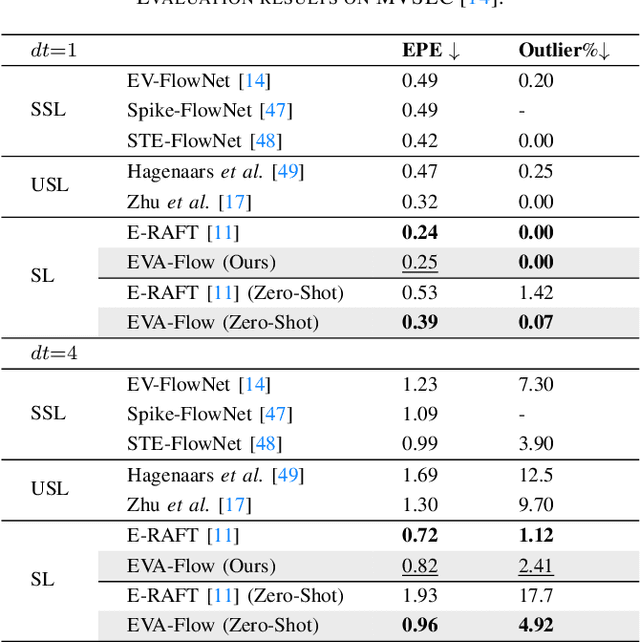
Event cameras are capable of responding to log-brightness changes in microseconds. Its characteristic of producing responses only to the changing region is particularly suitable for optical flow estimation. In contrast to the super low-latency response speed of event cameras, existing datasets collected via event cameras, however, only provide limited frame rate optical flow ground truth, (e.g., at 10Hz), greatly restricting the potential of event-driven optical flow. To address this challenge, we put forward a high-frame-rate, low-latency event representation Unified Voxel Grid, sequentially fed into the network bin by bin. We then propose EVA-Flow, an EVent-based Anytime Flow estimation network to produce high-frame-rate event optical flow with only low-frame-rate optical flow ground truth for supervision. The key component of our EVA-Flow is the stacked Spatiotemporal Motion Refinement (SMR) module, which predicts temporally-dense optical flow and enhances the accuracy via spatial-temporal motion refinement. The time-dense feature warping utilized in the SMR module provides implicit supervision for the intermediate optical flow. Additionally, we introduce the Rectified Flow Warp Loss (RFWL) for the unsupervised evaluation of intermediate optical flow in the absence of ground truth. This is, to the best of our knowledge, the first work focusing on anytime optical flow estimation via event cameras. A comprehensive variety of experiments on MVSEC, DESC, and our EVA-FlowSet demonstrates that EVA-Flow achieves competitive performance, super-low-latency (5ms), fastest inference (9.2ms), time-dense motion estimation (200Hz), and strong generalization. Our code will be available at https://github.com/Yaozhuwa/EVA-Flow.
Early Prediction of Alzheimers Disease Leveraging Symptom Occurrences from Longitudinal Electronic Health Records of US Military Veterans
Jul 23, 2023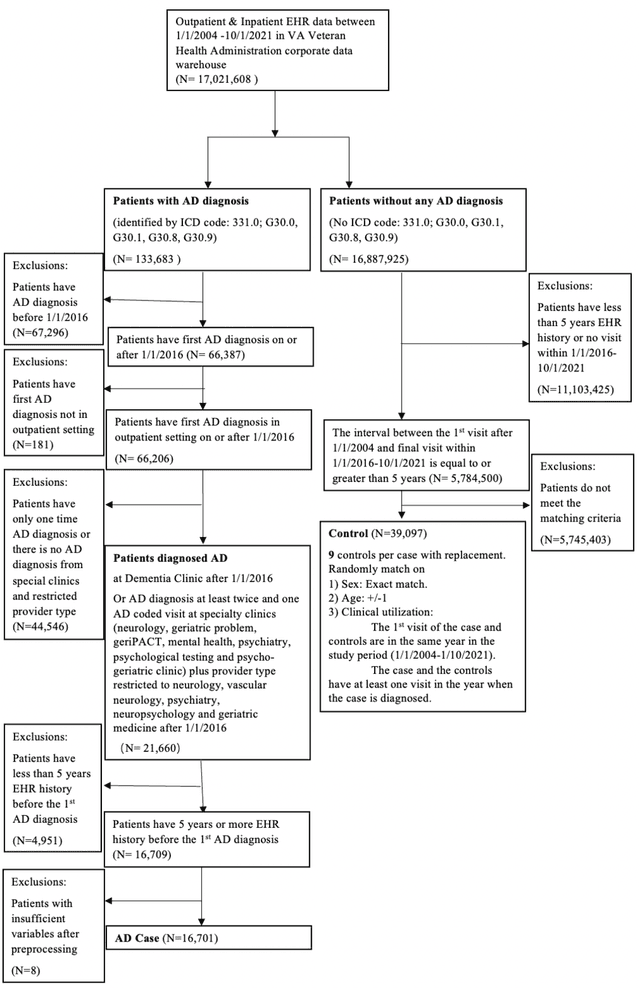
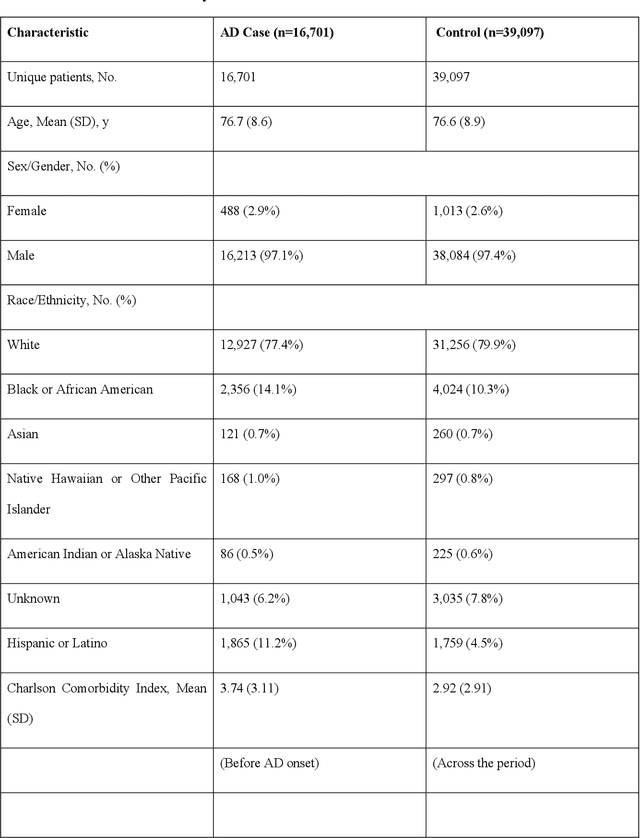
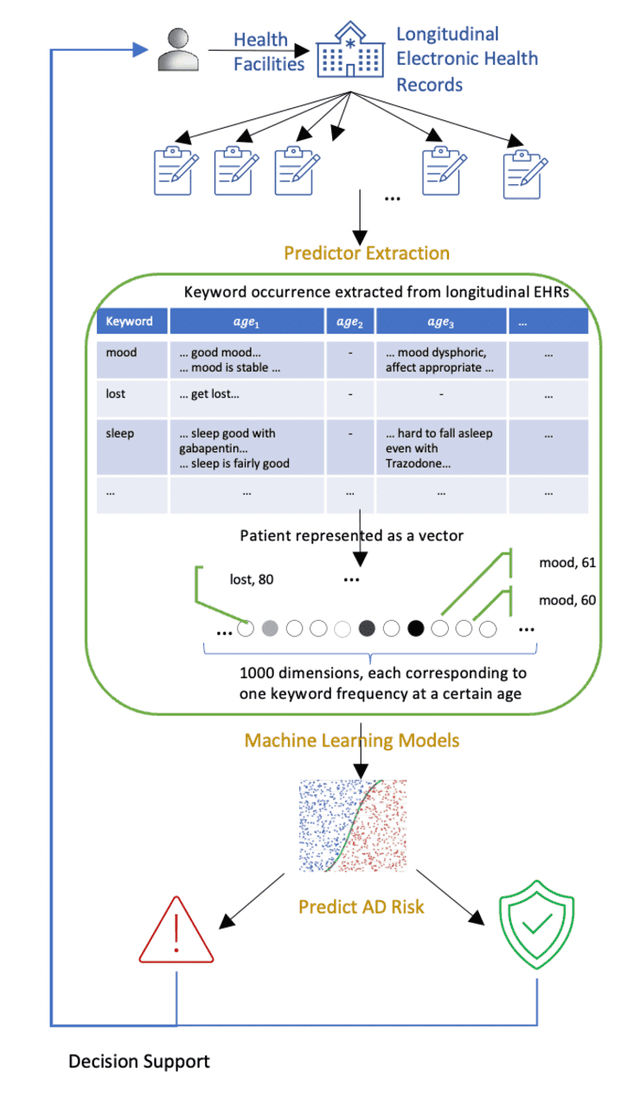
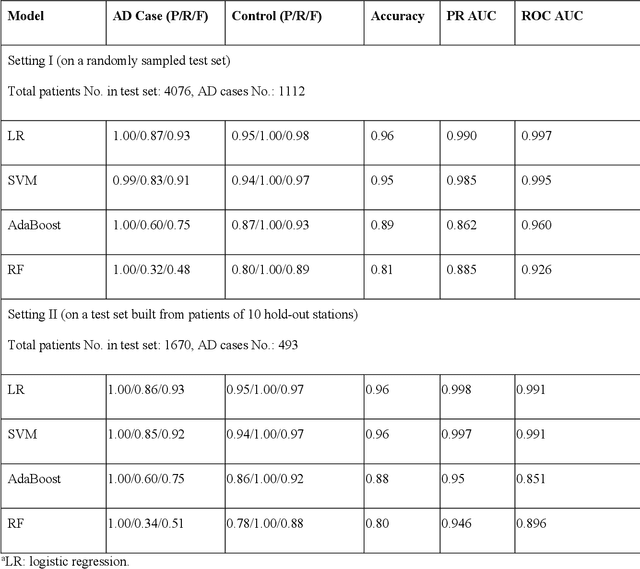
Early prediction of Alzheimer's disease (AD) is crucial for timely intervention and treatment. This study aims to use machine learning approaches to analyze longitudinal electronic health records (EHRs) of patients with AD and identify signs and symptoms that can predict AD onset earlier. We used a case-control design with longitudinal EHRs from the U.S. Department of Veterans Affairs Veterans Health Administration (VHA) from 2004 to 2021. Cases were VHA patients with AD diagnosed after 1/1/2016 based on ICD-10-CM codes, matched 1:9 with controls by age, sex and clinical utilization with replacement. We used a panel of AD-related keywords and their occurrences over time in a patient's longitudinal EHRs as predictors for AD prediction with four machine learning models. We performed subgroup analyses by age, sex, and race/ethnicity, and validated the model in a hold-out and "unseen" VHA stations group. Model discrimination, calibration, and other relevant metrics were reported for predictions up to ten years before ICD-based diagnosis. The study population included 16,701 cases and 39,097 matched controls. The average number of AD-related keywords (e.g., "concentration", "speaking") per year increased rapidly for cases as diagnosis approached, from around 10 to over 40, while remaining flat at 10 for controls. The best model achieved high discriminative accuracy (ROCAUC 0.997) for predictions using data from at least ten years before ICD-based diagnoses. The model was well-calibrated (Hosmer-Lemeshow goodness-of-fit p-value = 0.99) and consistent across subgroups of age, sex and race/ethnicity, except for patients younger than 65 (ROCAUC 0.746). Machine learning models using AD-related keywords identified from EHR notes can predict future AD diagnoses, suggesting its potential use for identifying AD risk using EHR notes, offering an affordable way for early screening on large population.