 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural Machine Translation Data Generation and Augmentation using ChatGPT
Jul 11, 2023
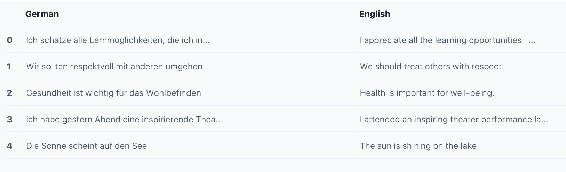
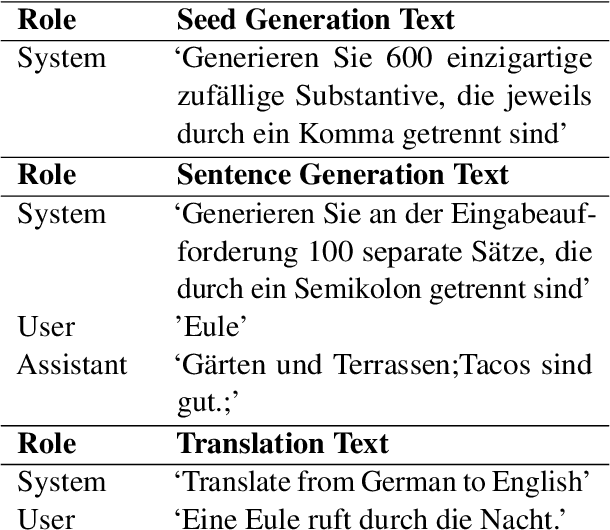
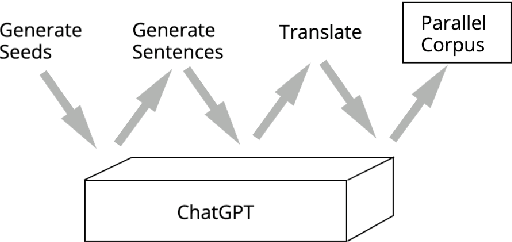
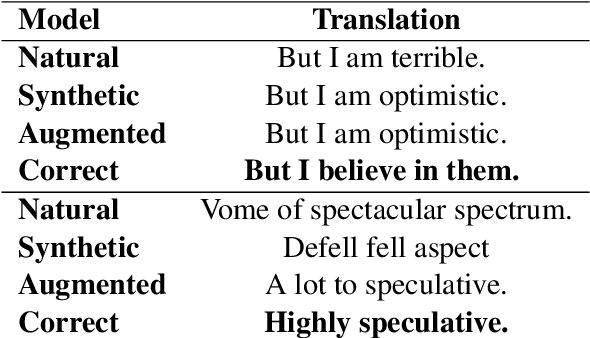
Neural models have revolutionized the field of machine translation, but creating parallel corpora is expensive and time-consuming. We investigate an alternative to manual parallel corpora - hallucinated parallel corpora created by generative language models. Although these models are themselves trained on parallel data, they can leverage a multilingual vector space to create data, and may be able to supplement small manually-procured corpora. Our experiments highlight two key findings - despite a lack of diversity in their output, the hallucinated data improves the translation signal, even when the domain clashes with the original dataset.
Count-Free Single-Photon 3D Imaging with Race Logic
Jul 10, 2023
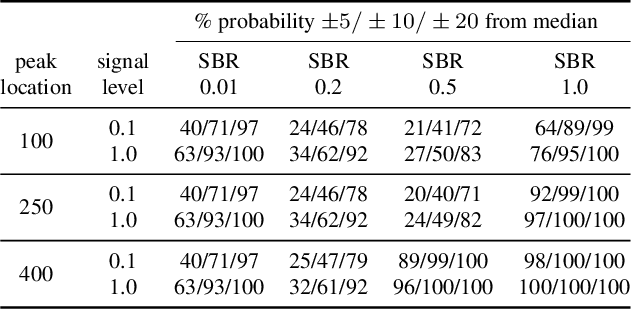
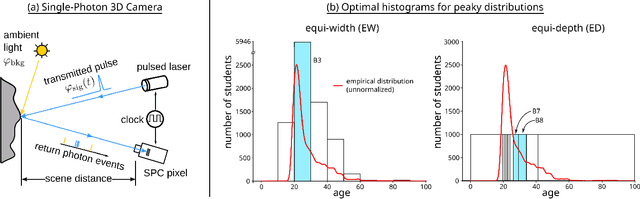
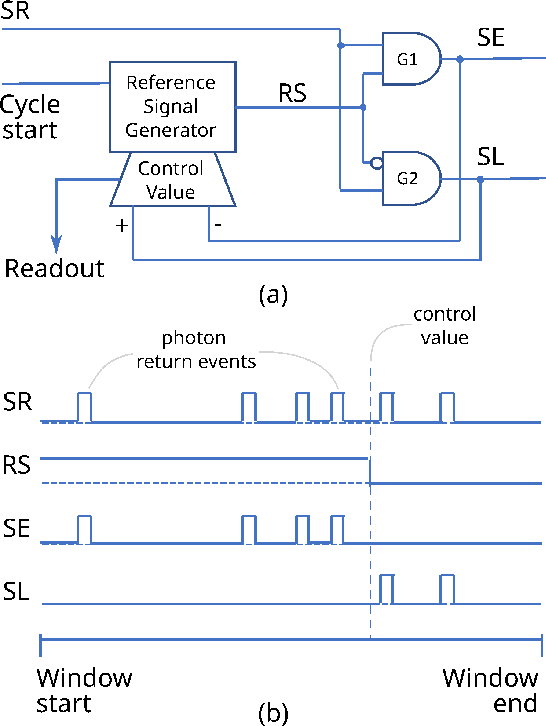
Single-photon cameras (SPCs) have emerged as a promising technology for high-resolution 3D imaging. A single-photon 3D camera determines the round-trip time of a laser pulse by capturing the arrival of individual photons at each camera pixel. Constructing photon-timestamp histograms is a fundamental operation for a single-photon 3D camera. However, in-pixel histogram processing is computationally expensive and requires large amount of memory per pixel. Digitizing and transferring photon timestamps to an off-sensor histogramming module is bandwidth and power hungry. Here we present an online approach for distance estimation without explicitly storing photon counts. The two key ingredients of our approach are (a) processing photon streams using race logic, which maintains photon data in the time-delay domain, and (b) constructing count-free equi-depth histograms. Equi-depth histograms are a succinct representation for ``peaky'' distributions, such as those obtained by an SPC pixel from a laser pulse reflected by a surface. Our approach uses a binner element that converges on the median (or, more generally, to another quantile) of a distribution. We cascade multiple binners to form an equi-depth histogrammer that produces multi-bin histograms. Our evaluation shows that this method can provide an order of magnitude reduction in bandwidth and power consumption while maintaining similar distance reconstruction accuracy as conventional processing methods.
Polarization-Based Security: Safeguarding Wireless Communications at the Physical Layer
Jul 14, 2023
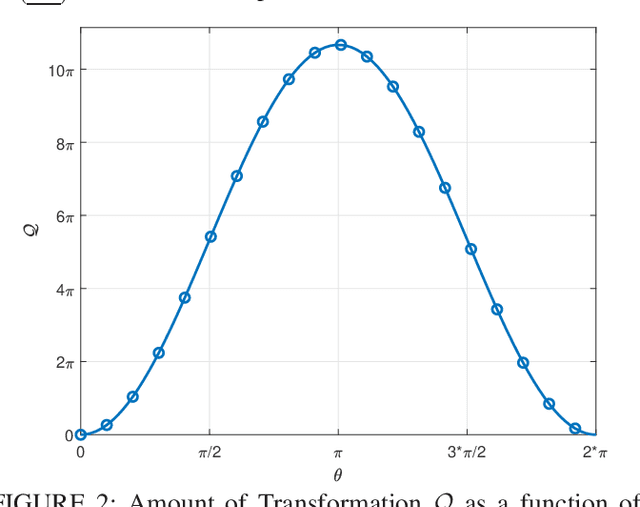
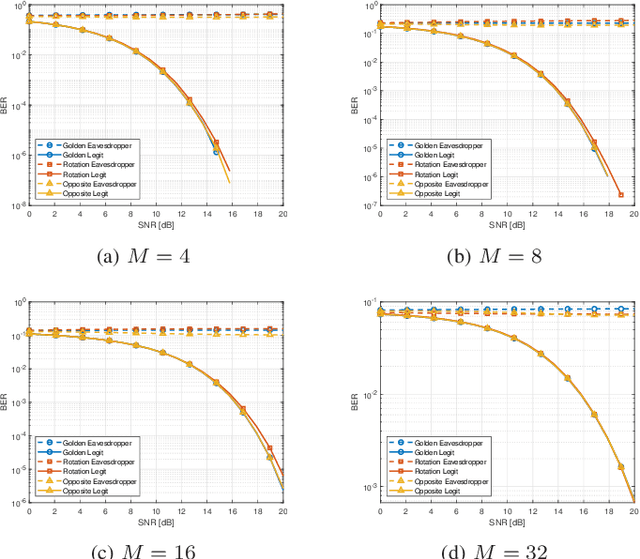
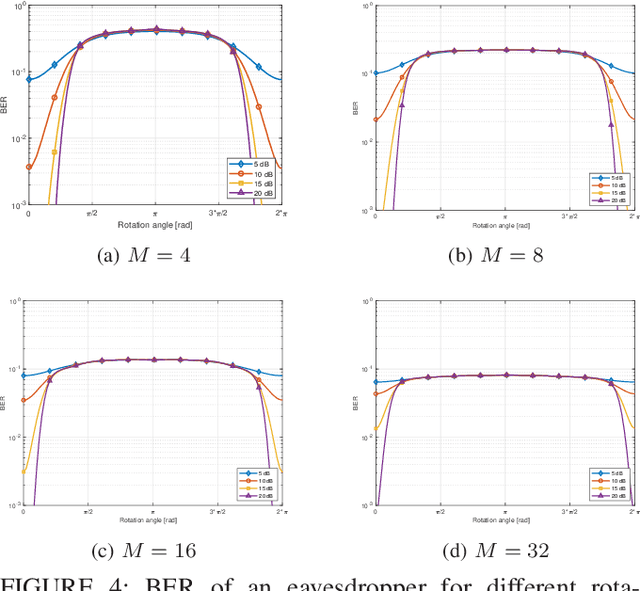
Physical layer security is a field of study that continues to gain importance over time. It encompasses a range of algorithms applicable to various aspects of communication systems. While research in the physical layer has predominantly focused on secrecy capacity, which involves logical and digital manipulations to achieve secure communication, there is limited exploration of directly manipulating electromagnetic fields to enhance security against eavesdroppers. In this paper, we propose a novel system that utilizes the Mueller calculation to establish a theoretical framework for manipulating electromagnetic fields in the context of physical layer security. We develop fundamental expressions and introduce new metrics to analyze the system's performance analytically. Additionally, we present three techniques that leverage polarization to enhance physical layer security.
Robust Test-Time Adaptation in Dynamic Scenarios
Mar 24, 2023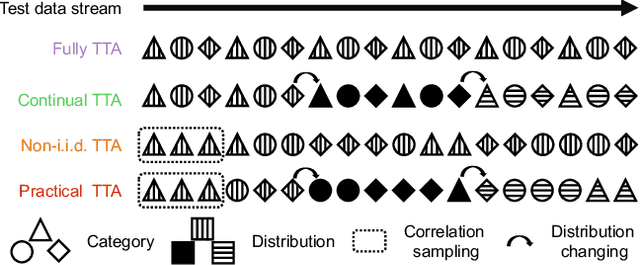

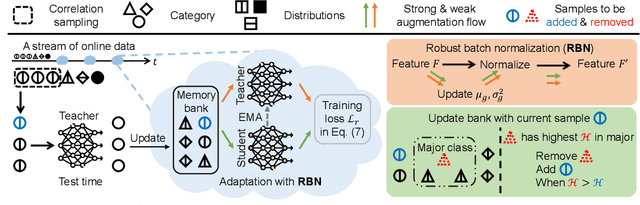
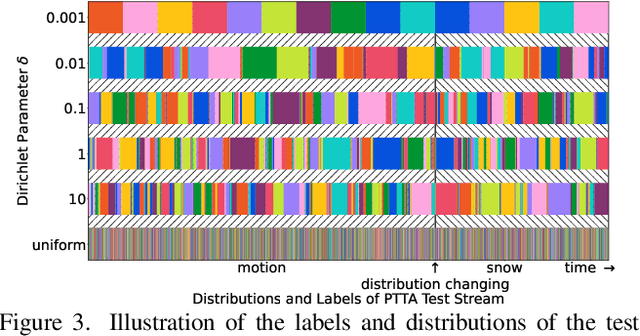
Test-time adaptation (TTA) intends to adapt the pretrained model to test distributions with only unlabeled test data streams. Most of the previous TTA methods have achieved great success on simple test data streams such as independently sampled data from single or multiple distributions. However, these attempts may fail in dynamic scenarios of real-world applications like autonomous driving, where the environments gradually change and the test data is sampled correlatively over time. In this work, we explore such practical test data streams to deploy the model on the fly, namely practical test-time adaptation (PTTA). To do so, we elaborate a Robust Test-Time Adaptation (RoTTA) method against the complex data stream in PTTA. More specifically, we present a robust batch normalization scheme to estimate the normalization statistics. Meanwhile, a memory bank is utilized to sample category-balanced data with consideration of timeliness and uncertainty. Further, to stabilize the training procedure, we develop a time-aware reweighting strategy with a teacher-student model. Extensive experiments prove that RoTTA enables continual testtime adaptation on the correlatively sampled data streams. Our method is easy to implement, making it a good choice for rapid deployment. The code is publicly available at https://github.com/BIT-DA/RoTTA
Accelerated Optimization Landscape of Linear-Quadratic Regulator
Jul 07, 2023Linear-quadratic regulator (LQR) is a landmark problem in the field of optimal control, which is the concern of this paper. Generally, LQR is classified into state-feedback LQR (SLQR) and output-feedback LQR (OLQR) based on whether the full state is obtained. It has been suggested in existing literature that both the SLQR and the OLQR could be viewed as \textit{constrained nonconvex matrix optimization} problems in which the only variable to be optimized is the feedback gain matrix. In this paper, we introduce a first-order accelerated optimization framework of handling the LQR problem, and give its convergence analysis for the cases of SLQR and OLQR, respectively. Specifically, a Lipschiz Hessian property of LQR performance criterion is presented, which turns out to be a crucial property for the application of modern optimization techniques. For the SLQR problem, a continuous-time hybrid dynamic system is introduced, whose solution trajectory is shown to converge exponentially to the optimal feedback gain with Nesterov-optimal order $1-\frac{1}{\sqrt{\kappa}}$ ($\kappa$ the condition number). Then, the symplectic Euler scheme is utilized to discretize the hybrid dynamic system, and a Nesterov-type method with a restarting rule is proposed that preserves the continuous-time convergence rate, i.e., the discretized algorithm admits the Nesterov-optimal convergence order. For the OLQR problem, a Hessian-free accelerated framework is proposed, which is a two-procedure method consisting of semiconvex function optimization and negative curvature exploitation. In a time $\mathcal{O}(\epsilon^{-7/4}\log(1/\epsilon))$, the method can find an $\epsilon$-stationary point of the performance criterion; this entails that the method improves upon the $\mathcal{O}(\epsilon^{-2})$ complexity of vanilla gradient descent. Moreover, our method provides the second-order guarantee of stationary point.
Self-Supervised and Semi-Supervised Polyp Segmentation using Synthetic Data
Jul 22, 2023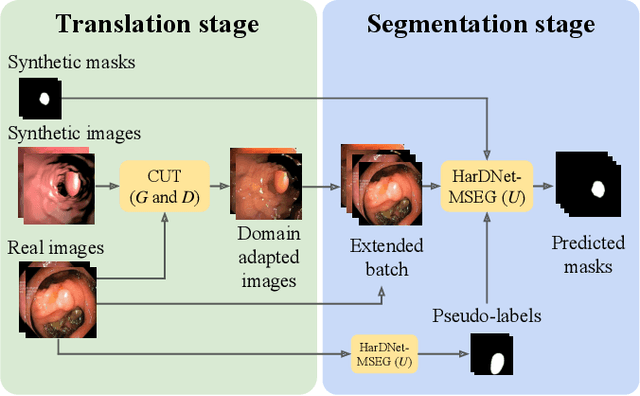
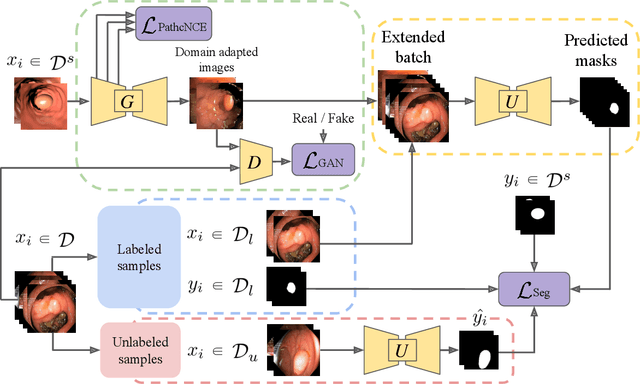
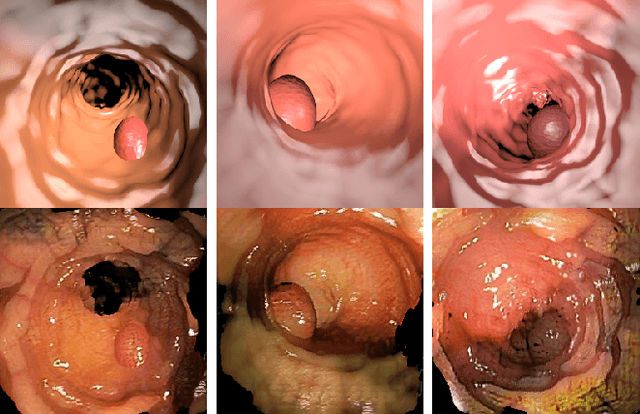
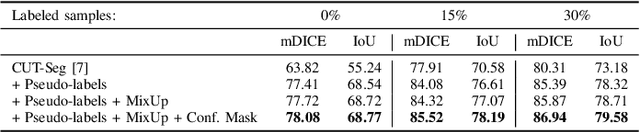
Early detection of colorectal polyps is of utmost importance for their treatment and for colorectal cancer prevention. Computer vision techniques have the potential to aid professionals in the diagnosis stage, where colonoscopies are manually carried out to examine the entirety of the patient's colon. The main challenge in medical imaging is the lack of data, and a further challenge specific to polyp segmentation approaches is the difficulty of manually labeling the available data: the annotation process for segmentation tasks is very time-consuming. While most recent approaches address the data availability challenge with sophisticated techniques to better exploit the available labeled data, few of them explore the self-supervised or semi-supervised paradigm, where the amount of labeling required is greatly reduced. To address both challenges, we leverage synthetic data and propose an end-to-end model for polyp segmentation that integrates real and synthetic data to artificially increase the size of the datasets and aid the training when unlabeled samples are available. Concretely, our model, Pl-CUT-Seg, transforms synthetic images with an image-to-image translation module and combines the resulting images with real images to train a segmentation model, where we use model predictions as pseudo-labels to better leverage unlabeled samples. Additionally, we propose PL-CUT-Seg+, an improved version of the model that incorporates targeted regularization to address the domain gap between real and synthetic images. The models are evaluated on standard benchmarks for polyp segmentation and reach state-of-the-art results in the self- and semi-supervised setups.
CAT-ViL: Co-Attention Gated Vision-Language Embedding for Visual Question Localized-Answering in Robotic Surgery
Jul 22, 2023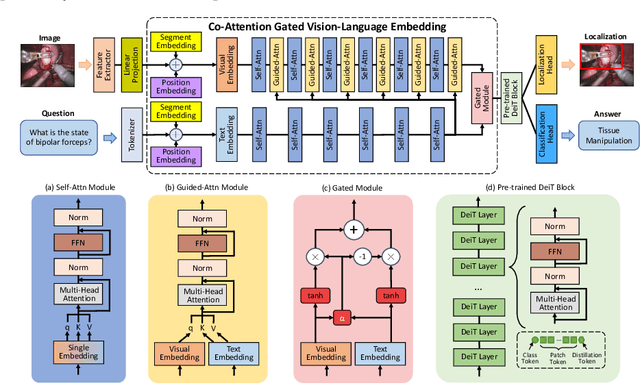
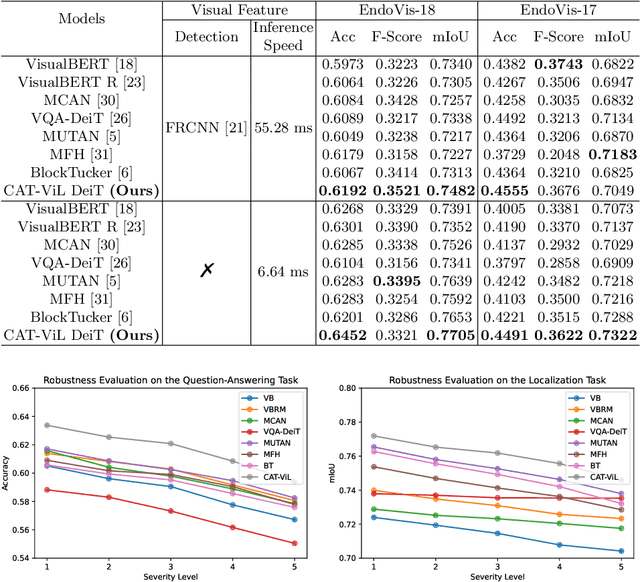
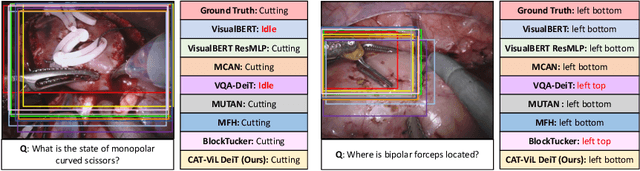
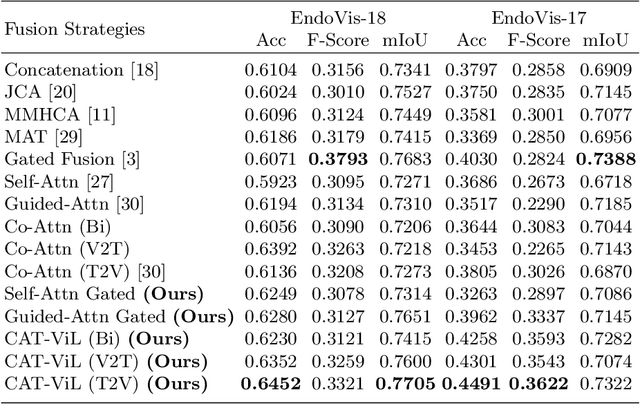
Medical students and junior surgeons often rely on senior surgeons and specialists to answer their questions when learning surgery. However, experts are often busy with clinical and academic work, and have little time to give guidance. Meanwhile, existing deep learning (DL)-based surgical Visual Question Answering (VQA) systems can only provide simple answers without the location of the answers. In addition, vision-language (ViL) embedding is still a less explored research in these kinds of tasks. Therefore, a surgical Visual Question Localized-Answering (VQLA) system would be helpful for medical students and junior surgeons to learn and understand from recorded surgical videos. We propose an end-to-end Transformer with the Co-Attention gaTed Vision-Language (CAT-ViL) embedding for VQLA in surgical scenarios, which does not require feature extraction through detection models. The CAT-ViL embedding module is designed to fuse multimodal features from visual and textual sources. The fused embedding will feed a standard Data-Efficient Image Transformer (DeiT) module, before the parallel classifier and detector for joint prediction. We conduct the experimental validation on public surgical videos from MICCAI EndoVis Challenge 2017 and 2018. The experimental results highlight the superior performance and robustness of our proposed model compared to the state-of-the-art approaches. Ablation studies further prove the outstanding performance of all the proposed components. The proposed method provides a promising solution for surgical scene understanding, and opens up a primary step in the Artificial Intelligence (AI)-based VQLA system for surgical training. Our code is publicly available.
Spatio-Temporal Avoidance of Predicted Occupancy in Human-Robot Collaboration
Jul 08, 2023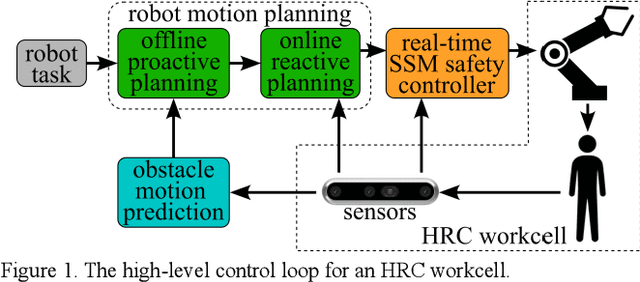
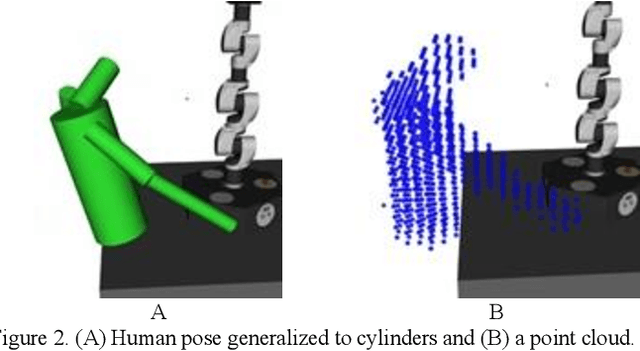

This paper addresses human-robot collaboration (HRC) challenges of integrating predictions of human activity to provide a proactive-n-reactive response capability for the robot. Prior works that consider current or predicted human poses as static obstacles are too nearsighted or too conservative in planning, potentially causing delayed robot paths. Alternatively, time-varying prediction of human poses would enable robot paths that avoid anticipated human poses, synchronized dynamically in time and space. Herein, a proactive path planning method, denoted STAP, is presented that uses spatiotemporal human occupancy maps to find robot trajectories that anticipate human movements, allowing robot passage without stopping. In addition, STAP anticipates delays from robot speed restrictions required by ISO/TS 15066 speed and separation monitoring (SSM). STAP also proposes a sampling-based planning algorithm based on RRT* to solve the spatio-temporal motion planning problem and find paths of minimum expected duration. Experimental results show STAP generates paths of shorter duration and greater average robot-human separation distance throughout tasks. Additionally, STAP more accurately estimates robot trajectory durations in HRC, which are useful in arriving at proactive-n-reactive robot sequencing.
* 7 pages, 7 figures. Accepted at IEEE ROMAN 2023
Estimation of symbol time offset using cyclic prefix in OFDM system
May 04, 2023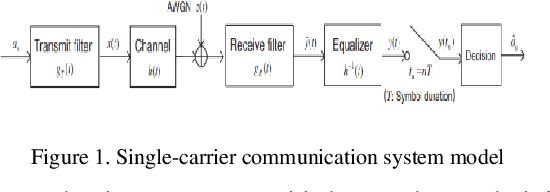
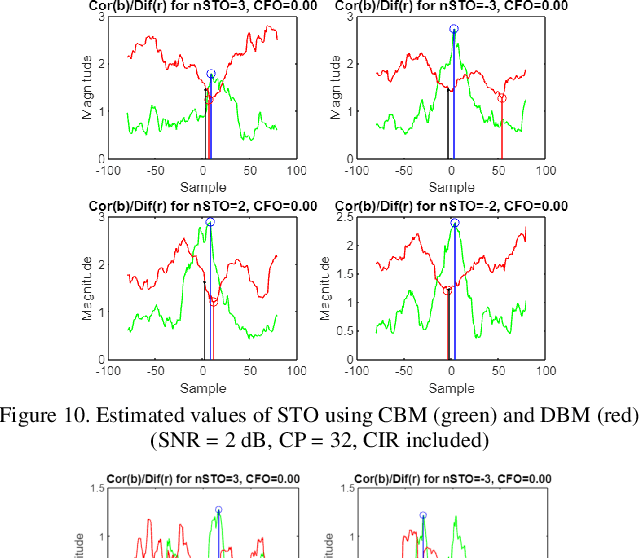
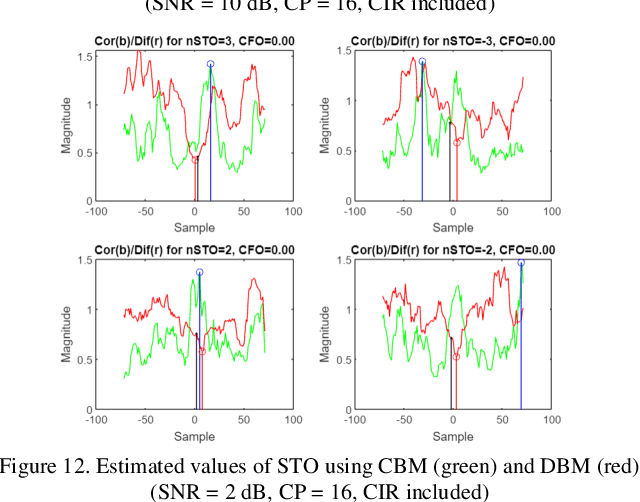
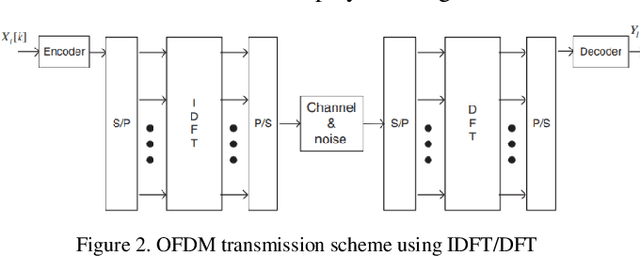
In this paper synchronization techniques using cyclic prefix (CP) are analyzed to remove the influence of symbol time offset (STO) for correct synchronization in Orthogonal Frequency Division Multiplex (OFDM) system. For correct detection of STO using CP two techniques are used. The first one is based on finding the maximum correlation between two blocks and the second one on finding the similarity between two blocks which is maximized when the difference between them is minimized. Two cases are observed. The first one uses only additive white Gaussian noise (AWGN), while the second also uses the channel impulse response (CIR) of Rayleigh channel. When channel effect is added both performances of estimation by correlation and difference deteriorate if sufficient level of signal to noise (SNR) and proper length of CP are not provided.
Rethinking the Encoding of Satellite Image Time Series
May 03, 2023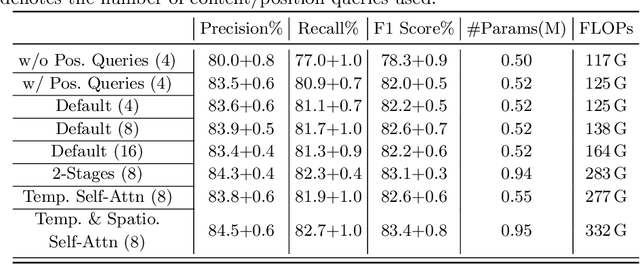
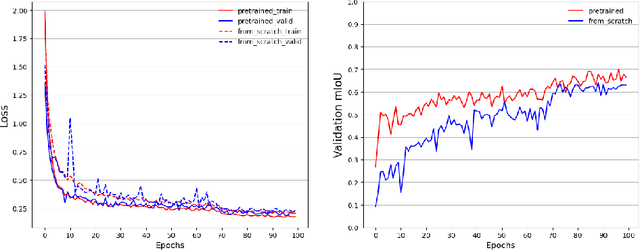
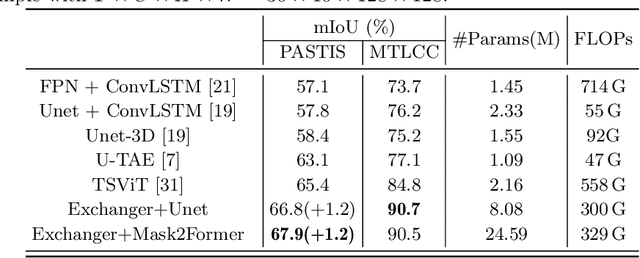
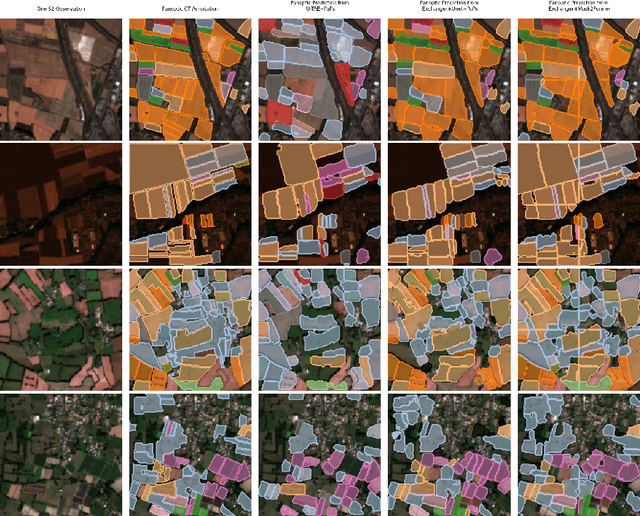
Representation learning of Satellite Image Time Series (SITS) presents its unique challenges, such as prohibitive computation burden caused by high spatiotemporal resolutions, irregular acquisition times, and complex spatiotemporal interactions, leading to highly-specialized neural network architectures for SITS analysis. Despite the promising results achieved by some pioneering work, we argue that satisfactory representation learning paradigms have not yet been established for SITS analysis, causing an isolated island where transferring successful paradigms or the latest advances from Computer Vision (CV) to SITS is arduous. In this paper, we develop a unique perspective of SITS processing as a direct set prediction problem, inspired by the recent trend in adopting query-based transformer decoders to streamline the object detection or image segmentation pipeline, and further propose to decompose the representation learning process of SITS into three explicit steps: collect--update--distribute, which is computationally efficient and suits for irregularly-sampled and asynchronous temporal observations. Facilitated by the unique reformulation and effective feature extraction framework proposed, our models pre-trained on pixel-set format input and then fine-tuned on downstream dense prediction tasks by simply appending a commonly-used segmentation network have attained new state-of-the-art (SoTA) results on PASTIS dataset compared to bespoke neural architectures such as U-TAE. Furthermore, the clear separation, conceptually and practically, between temporal and spatial components in the panoptic segmentation pipeline of SITS allows us to leverage the recent advances in CV, such as Mask2Former, a universal segmentation architecture, resulting in a noticeable 8.8 points increase in PQ compared to the best score reported so far.