 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Fuzzy clustering of ordinal time series based on two novel distances with economic applications
Apr 24, 2023

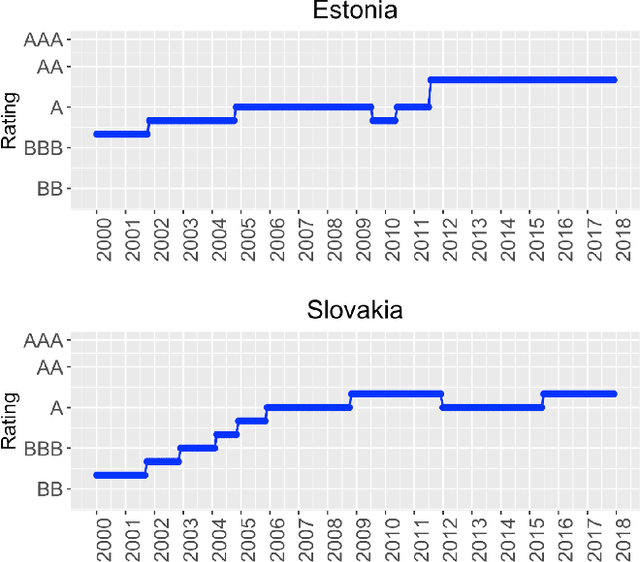
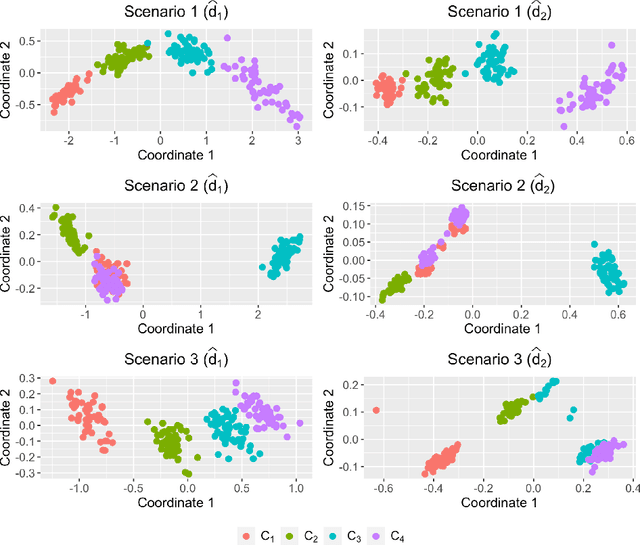
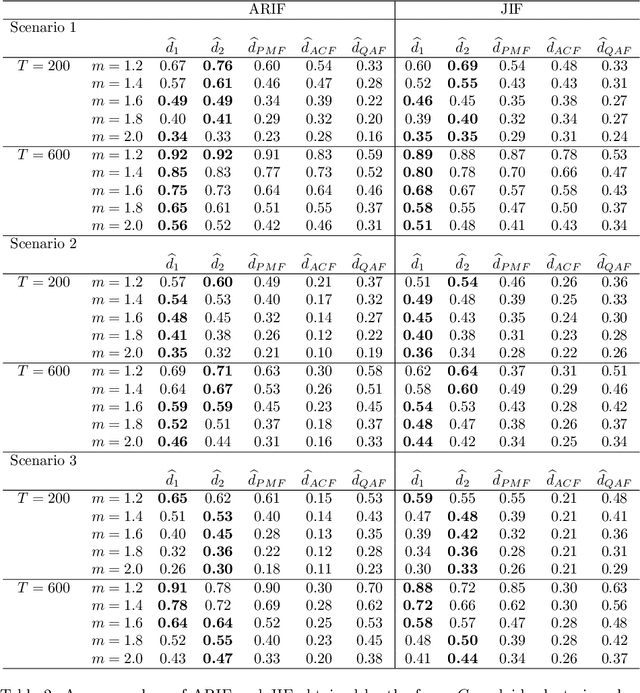
Time series clustering is a central machine learning task with applications in many fields. While the majority of the methods focus on real-valued time series, very few works consider series with discrete response. In this paper, the problem of clustering ordinal time series is addressed. To this aim, two novel distances between ordinal time series are introduced and used to construct fuzzy clustering procedures. Both metrics are functions of the estimated cumulative probabilities, thus automatically taking advantage of the ordering inherent to the series' range. The resulting clustering algorithms are computationally efficient and able to group series generated from similar stochastic processes, reaching accurate results even though the series come from a wide variety of models. Since the dynamic of the series may vary over the time, we adopt a fuzzy approach, thus enabling the procedures to locate each series into several clusters with different membership degrees. An extensive simulation study shows that the proposed methods outperform several alternative procedures. Weighted versions of the clustering algorithms are also presented and their advantages with respect to the original methods are discussed. Two specific applications involving economic time series illustrate the usefulness of the proposed approaches.
Assessing the Impact of Context Inference Error and Partial Observability on RL Methods for Just-In-Time Adaptive Interventions
May 17, 2023
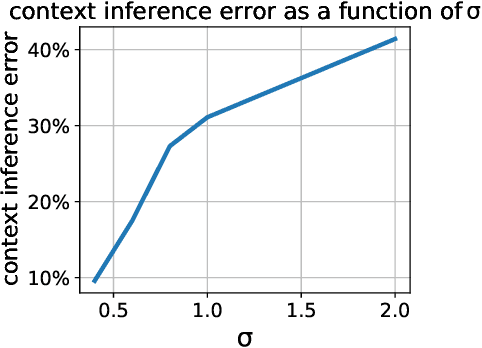

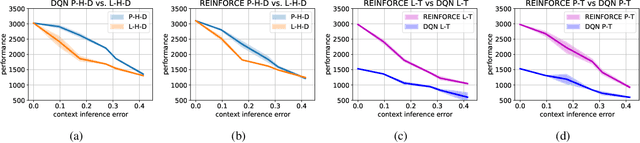
Just-in-Time Adaptive Interventions (JITAIs) are a class of personalized health interventions developed within the behavioral science community. JITAIs aim to provide the right type and amount of support by iteratively selecting a sequence of intervention options from a pre-defined set of components in response to each individual's time varying state. In this work, we explore the application of reinforcement learning methods to the problem of learning intervention option selection policies. We study the effect of context inference error and partial observability on the ability to learn effective policies. Our results show that the propagation of uncertainty from context inferences is critical to improving intervention efficacy as context uncertainty increases, while policy gradient algorithms can provide remarkable robustness to partially observed behavioral state information.
Digital Health Discussion Through Articles Published Until the Year 2021: A Digital Topic Modeling Approach
Jul 14, 2023


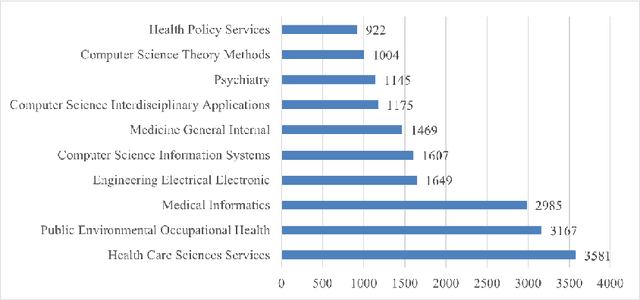
The digital health industry has grown in popularity since the 2010s, but there has been limited analysis of the topics discussed in the field across academic disciplines. This study aims to analyze the research trends of digital health-related articles published on the Web of Science until 2021, in order to understand the concentration, scope, and characteristics of the research. 15,950 digital health-related papers from the top 10 academic fields were analyzed using the Web of Science. The papers were grouped into three domains: public health, medicine, and electrical engineering and computer science (EECS). Two time periods (2012-2016 and 2017-2021) were compared using Latent Dirichlet Allocation (LDA) for topic modeling. The number of topics was determined based on coherence score, and topic compositions were compared using a homogeneity test. The number of optimal topics varied across domains and time periods. For public health, the first and second halves had 13 and 19 topics, respectively. Medicine had 14 and 25 topics, and EECS had 7 and 21 topics. Text analysis revealed shared topics among the domains, but with variations in composition. The homogeneity test confirmed significant differences between the groups (p<2.2e-16). Six dominant themes emerged, including journal article methodology, information technology, medical issues, population demographics, social phenomena, and healthcare. Digital health research is expanding and evolving, particularly in relation to Covid-19, where topics such as depression and mental disorders, education, and physical activity have gained prominence. There was no bias in topic composition among the three domains, but other fields like kinesiology or psychology could contribute to future digital health research. Exploring expanded topics that reflect people's needs for digital health over time will be crucial.
Value-based Fast and Slow AI Nudging
Jul 14, 2023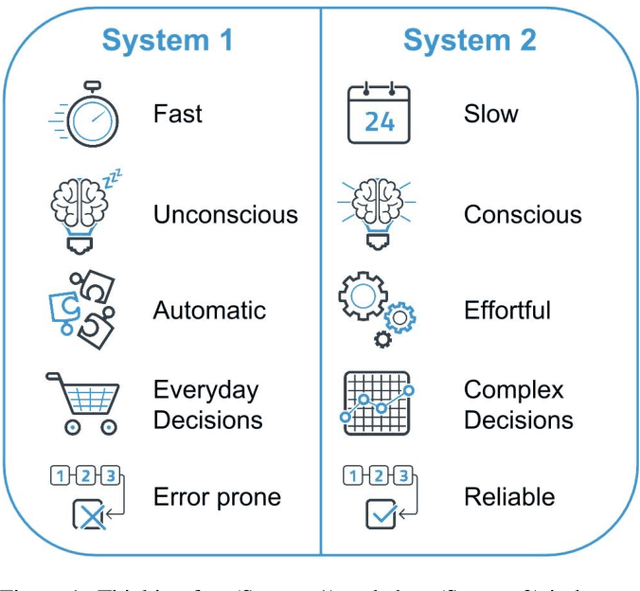
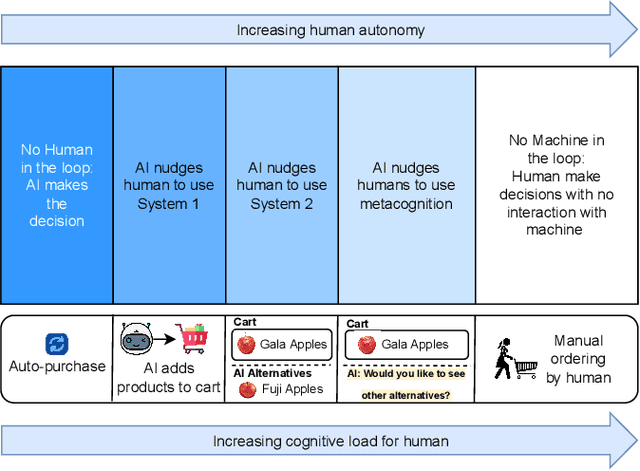
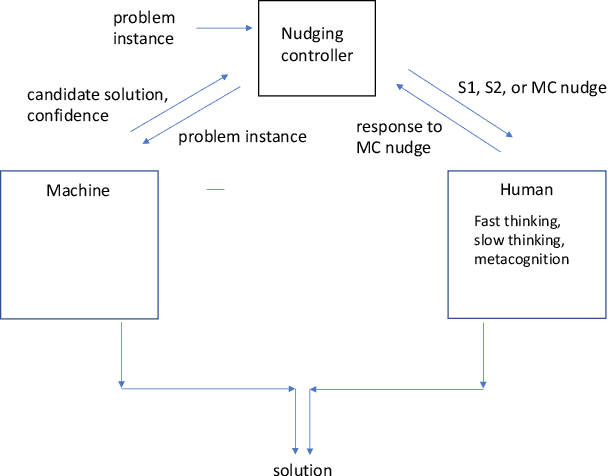
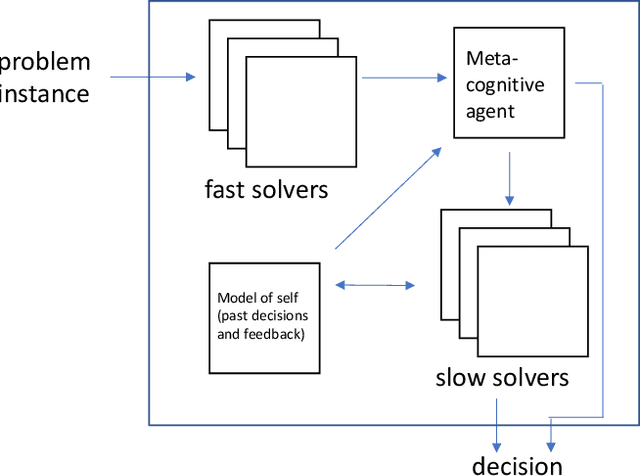
Nudging is a behavioral strategy aimed at influencing people's thoughts and actions. Nudging techniques can be found in many situations in our daily lives, and these nudging techniques can targeted at human fast and unconscious thinking, e.g., by using images to generate fear or the more careful and effortful slow thinking, e.g., by releasing information that makes us reflect on our choices. In this paper, we propose and discuss a value-based AI-human collaborative framework where AI systems nudge humans by proposing decision recommendations. Three different nudging modalities, based on when recommendations are presented to the human, are intended to stimulate human fast thinking, slow thinking, or meta-cognition. Values that are relevant to a specific decision scenario are used to decide when and how to use each of these nudging modalities. Examples of values are decision quality, speed, human upskilling and learning, human agency, and privacy. Several values can be present at the same time, and their priorities can vary over time. The framework treats values as parameters to be instantiated in a specific decision environment.
INVE: Interactive Neural Video Editing
Jul 15, 2023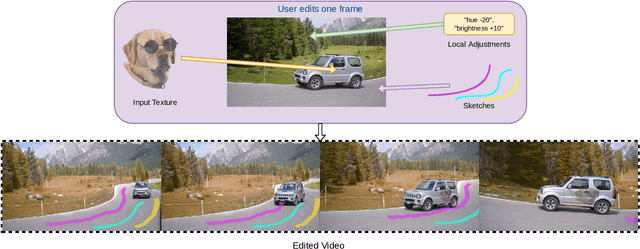
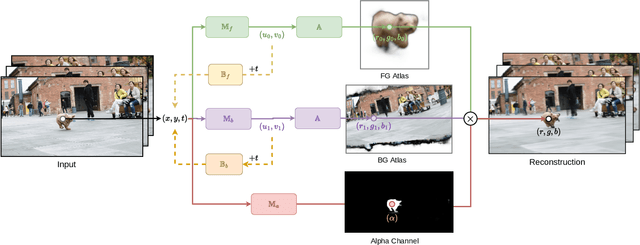
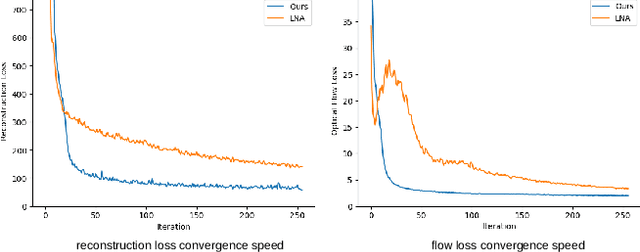
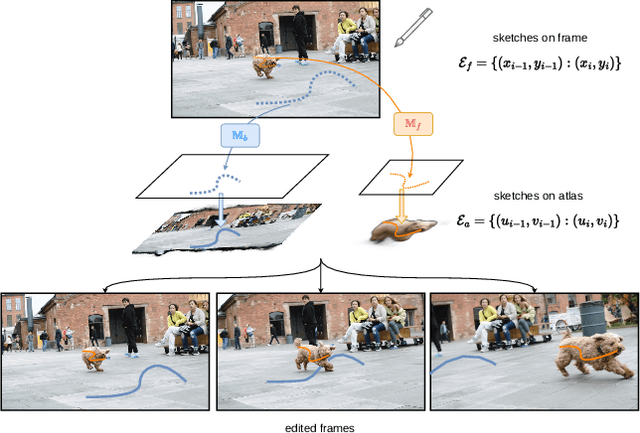
We present Interactive Neural Video Editing (INVE), a real-time video editing solution, which can assist the video editing process by consistently propagating sparse frame edits to the entire video clip. Our method is inspired by the recent work on Layered Neural Atlas (LNA). LNA, however, suffers from two major drawbacks: (1) the method is too slow for interactive editing, and (2) it offers insufficient support for some editing use cases, including direct frame editing and rigid texture tracking. To address these challenges we leverage and adopt highly efficient network architectures, powered by hash-grids encoding, to substantially improve processing speed. In addition, we learn bi-directional functions between image-atlas and introduce vectorized editing, which collectively enables a much greater variety of edits in both the atlas and the frames directly. Compared to LNA, our INVE reduces the learning and inference time by a factor of 5, and supports various video editing operations that LNA cannot. We showcase the superiority of INVE over LNA in interactive video editing through a comprehensive quantitative and qualitative analysis, highlighting its numerous advantages and improved performance. For video results, please see https://gabriel-huang.github.io/inve/
Comparison between transformers and convolutional models for fine-grained classification of insects
Jul 20, 2023
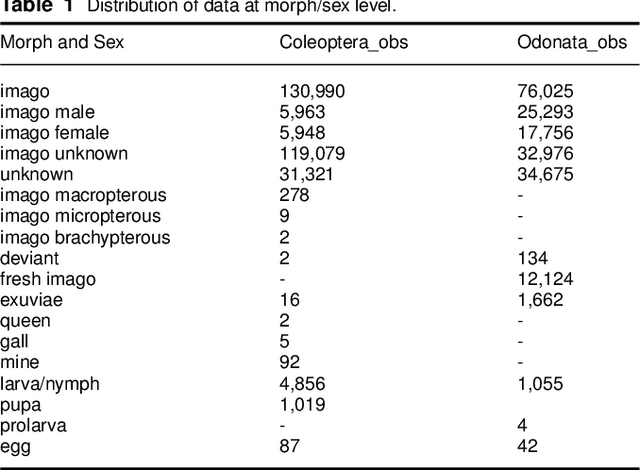

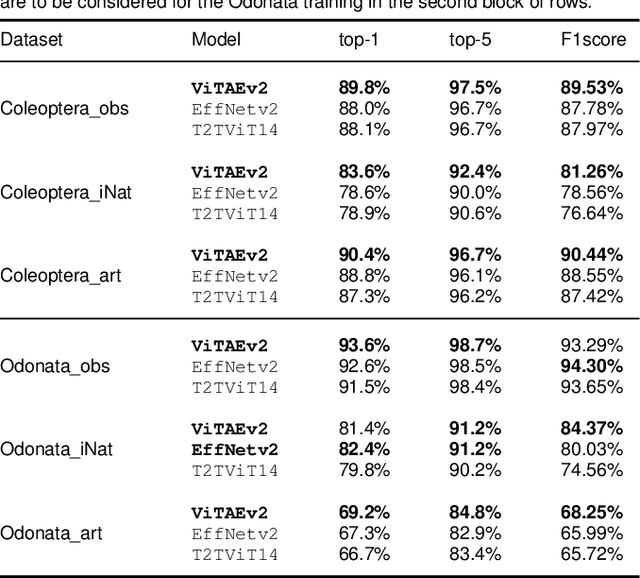
Fine-grained classification is challenging due to the difficulty of finding discriminatory features. This problem is exacerbated when applied to identifying species within the same taxonomical class. This is because species are often sharing morphological characteristics that make them difficult to differentiate. We consider the taxonomical class of Insecta. The identification of insects is essential in biodiversity monitoring as they are one of the inhabitants at the base of many ecosystems. Citizen science is doing brilliant work of collecting images of insects in the wild giving the possibility to experts to create improved distribution maps in all countries. We have billions of images that need to be automatically classified and deep neural network algorithms are one of the main techniques explored for fine-grained tasks. At the SOTA, the field of deep learning algorithms is extremely fruitful, so how to identify the algorithm to use? We focus on Odonata and Coleoptera orders, and we propose an initial comparative study to analyse the two best-known layer structures for computer vision: transformer and convolutional layers. We compare the performance of T2TViT, a fully transformer-base, EfficientNet, a fully convolutional-base, and ViTAE, a hybrid. We analyse the performance of the three models in identical conditions evaluating the performance per species, per morph together with sex, the inference time, and the overall performance with unbalanced datasets of images from smartphones. Although we observe high performances with all three families of models, our analysis shows that the hybrid model outperforms the fully convolutional-base and fully transformer-base models on accuracy performance and the fully transformer-base model outperforms the others on inference speed and, these prove the transformer to be robust to the shortage of samples and to be faster at inference time.
Multiscale Representation for Real-Time Anti-Aliasing Neural Rendering
Apr 20, 2023
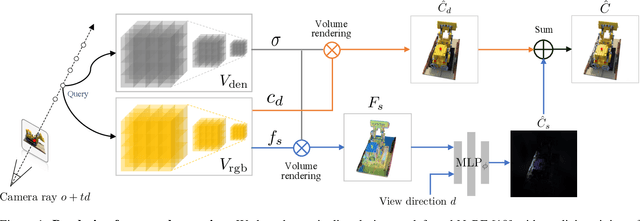
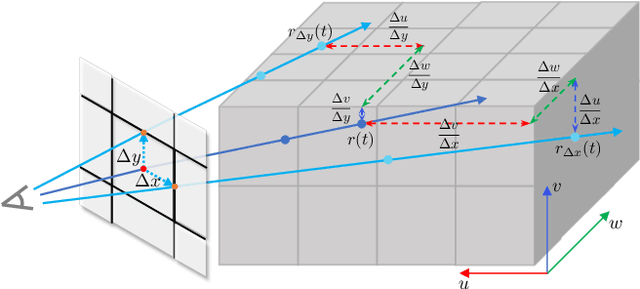

The rendering scheme in neural radiance field (NeRF) is effective in rendering a pixel by casting a ray into the scene. However, NeRF yields blurred rendering results when the training images are captured at non-uniform scales, and produces aliasing artifacts if the test images are taken in distant views. To address this issue, Mip-NeRF proposes a multiscale representation as a conical frustum to encode scale information. Nevertheless, this approach is only suitable for offline rendering since it relies on integrated positional encoding (IPE) to query a multilayer perceptron (MLP). To overcome this limitation, we propose mip voxel grids (Mip-VoG), an explicit multiscale representation with a deferred architecture for real-time anti-aliasing rendering. Our approach includes a density Mip-VoG for scene geometry and a feature Mip-VoG with a small MLP for view-dependent color. Mip-VoG encodes scene scale using the level of detail (LOD) derived from ray differentials and uses quadrilinear interpolation to map a queried 3D location to its features and density from two neighboring downsampled voxel grids. To our knowledge, our approach is the first to offer multiscale training and real-time anti-aliasing rendering simultaneously. We conducted experiments on multiscale datasets, and the results show that our approach outperforms state-of-the-art real-time rendering baselines.
Quasi Real-Time Autonomous Satellite Detection and Orbit Estimation
Apr 13, 2023
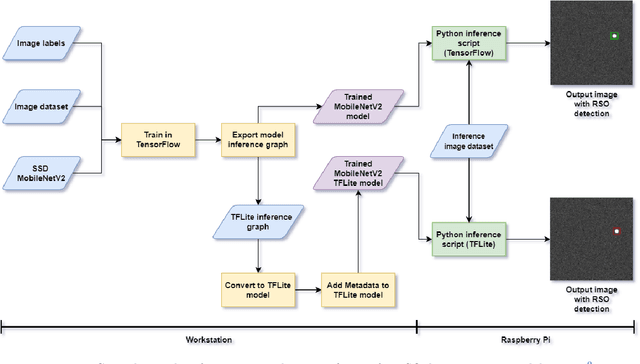
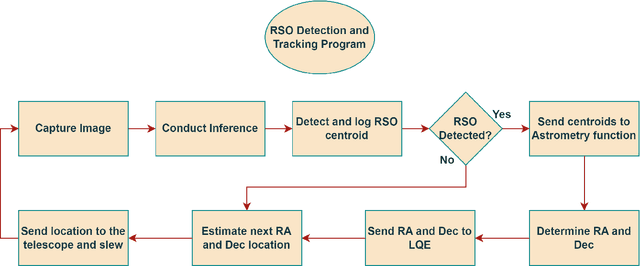
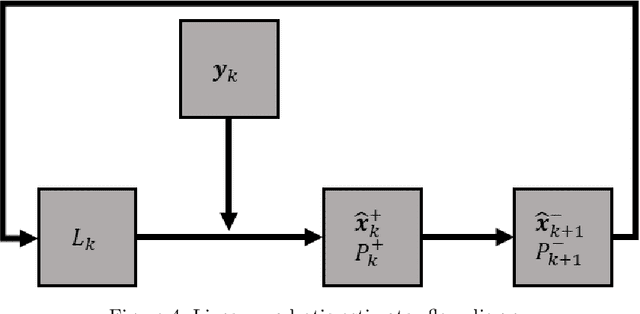
A method of near real-time detection and tracking of resident space objects (RSOs) using a convolutional neural network (CNN) and linear quadratic estimator (LQE) is proposed. Advances in machine learning architecture allow the use of low-power/cost embedded devices to perform complex classification tasks. In order to reduce the costs of tracking systems, a low-cost embedded device will be used to run a CNN detection model for RSOs in unresolved images captured by a gray-scale camera and small telescope. Detection results computed in near real-time are then passed to an LQE to compute tracking updates for the telescope mount, resulting in a fully autonomous method of optical RSO detection and tracking. Keywords: Space Domain Awareness, Neural Networks, Real-Time, Object Detection, Embedded Systems.
Learning Nonlinear Projections for Reduced-Order Modeling of Dynamical Systems using Constrained Autoencoders
Jul 28, 2023Recently developed reduced-order modeling techniques aim to approximate nonlinear dynamical systems on low-dimensional manifolds learned from data. This is an effective approach for modeling dynamics in a post-transient regime where the effects of initial conditions and other disturbances have decayed. However, modeling transient dynamics near an underlying manifold, as needed for real-time control and forecasting applications, is complicated by the effects of fast dynamics and nonnormal sensitivity mechanisms. To begin to address these issues, we introduce a parametric class of nonlinear projections described by constrained autoencoder neural networks in which both the manifold and the projection fibers are learned from data. Our architecture uses invertible activation functions and biorthogonal weight matrices to ensure that the encoder is a left inverse of the decoder. We also introduce new dynamics-aware cost functions that promote learning of oblique projection fibers that account for fast dynamics and nonnormality. To demonstrate these methods and the specific challenges they address, we provide a detailed case study of a three-state model of vortex shedding in the wake of a bluff body immersed in a fluid, which has a two-dimensional slow manifold that can be computed analytically. In anticipation of future applications to high-dimensional systems, we also propose several techniques for constructing computationally efficient reduced-order models using our proposed nonlinear projection framework. This includes a novel sparsity-promoting penalty for the encoder that avoids detrimental weight matrix shrinkage via computation on the Grassmann manifold.
D2S: Representing local descriptors and global scene coordinates for camera relocalization
Jul 28, 2023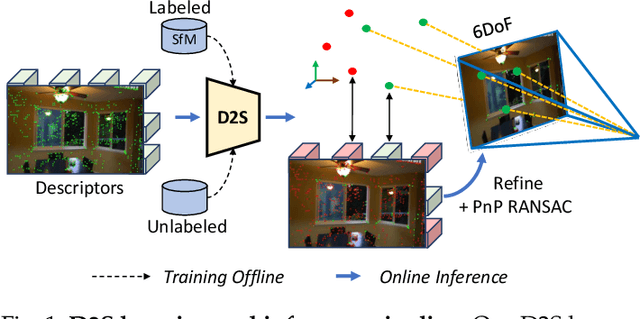
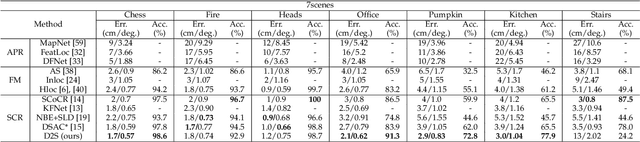
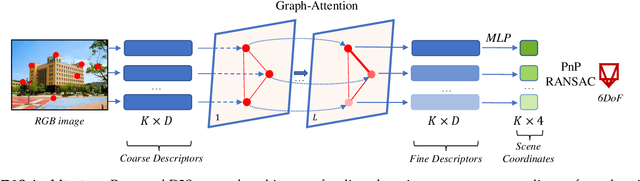

State-of-the-art visual localization methods mostly rely on complex procedures to match local descriptors and 3D point clouds. However, these procedures can incur significant cost in terms of inference, storage, and updates over time. In this study, we propose a direct learning-based approach that utilizes a simple network named D2S to represent local descriptors and their scene coordinates. Our method is characterized by its simplicity and cost-effectiveness. It solely leverages a single RGB image for localization during the testing phase and only requires a lightweight model to encode a complex sparse scene. The proposed D2S employs a combination of a simple loss function and graph attention to selectively focus on robust descriptors while disregarding areas such as clouds, trees, and several dynamic objects. This selective attention enables D2S to effectively perform a binary-semantic classification for sparse descriptors. Additionally, we propose a new outdoor dataset to evaluate the capabilities of visual localization methods in terms of scene generalization and self-updating from unlabeled observations. Our approach outperforms the state-of-the-art CNN-based methods in scene coordinate regression in indoor and outdoor environments. It demonstrates the ability to generalize beyond training data, including scenarios involving transitions from day to night and adapting to domain shifts, even in the absence of the labeled data sources. The source code, trained models, dataset, and demo videos are available at the following link: https://thpjp.github.io/d2s