 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Revisiting the Robustness of the Minimum Error Entropy Criterion: A Transfer Learning Case Study
Jul 25, 2023
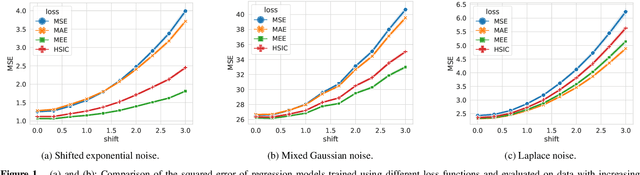
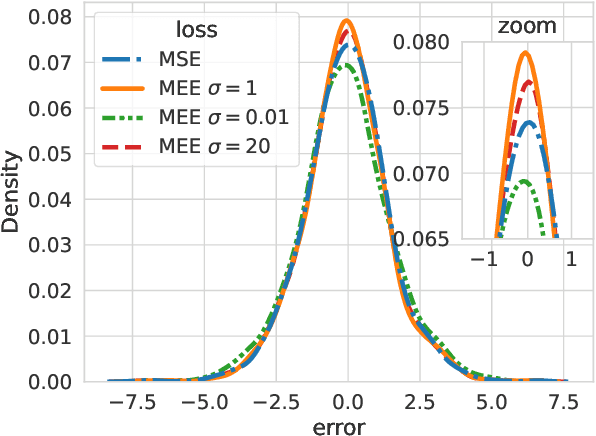

Coping with distributional shifts is an important part of transfer learning methods in order to perform well in real-life tasks. However, most of the existing approaches in this area either focus on an ideal scenario in which the data does not contain noises or employ a complicated training paradigm or model design to deal with distributional shifts. In this paper, we revisit the robustness of the minimum error entropy (MEE) criterion, a widely used objective in statistical signal processing to deal with non-Gaussian noises, and investigate its feasibility and usefulness in real-life transfer learning regression tasks, where distributional shifts are common. Specifically, we put forward a new theoretical result showing the robustness of MEE against covariate shift. We also show that by simply replacing the mean squared error (MSE) loss with the MEE on basic transfer learning algorithms such as fine-tuning and linear probing, we can achieve competitive performance with respect to state-of-the-art transfer learning algorithms. We justify our arguments on both synthetic data and 5 real-world time-series data.
An Empirical Study on Fairness Improvement with Multiple Protected Attributes
Jul 25, 2023
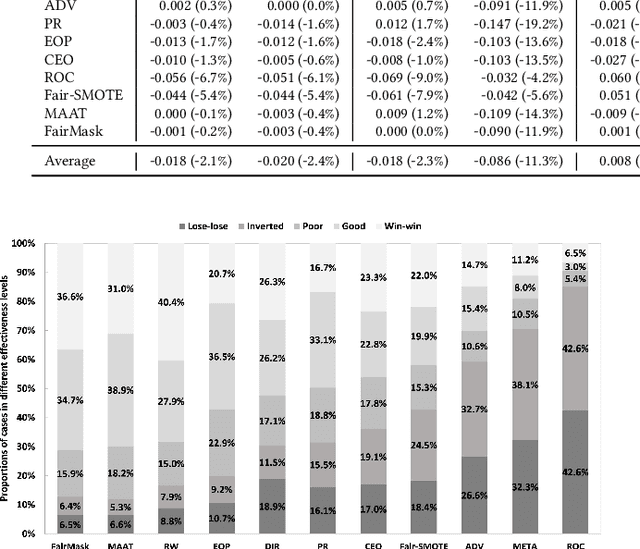

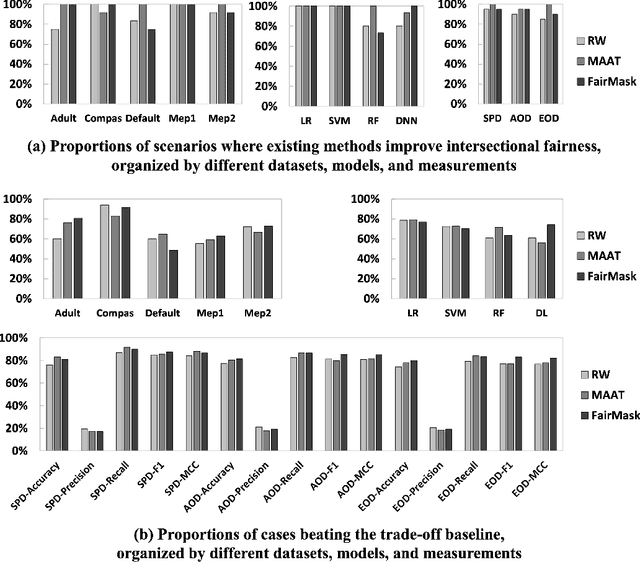
Existing research mostly improves the fairness of Machine Learning (ML) software regarding a single protected attribute at a time, but this is unrealistic given that many users have multiple protected attributes. This paper conducts an extensive study of fairness improvement regarding multiple protected attributes, covering 11 state-of-the-art fairness improvement methods. We analyze the effectiveness of these methods with different datasets, metrics, and ML models when considering multiple protected attributes. The results reveal that improving fairness for a single protected attribute can largely decrease fairness regarding unconsidered protected attributes. This decrease is observed in up to 88.3% of scenarios (57.5% on average). More surprisingly, we find little difference in accuracy loss when considering single and multiple protected attributes, indicating that accuracy can be maintained in the multiple-attribute paradigm. However, the effect on precision and recall when handling multiple protected attributes is about 5 times and 8 times that of a single attribute. This has important implications for future fairness research: reporting only accuracy as the ML performance metric, which is currently common in the literature, is inadequate.
Risk-Averse Trajectory Optimization via Sample Average Approximation
Jul 06, 2023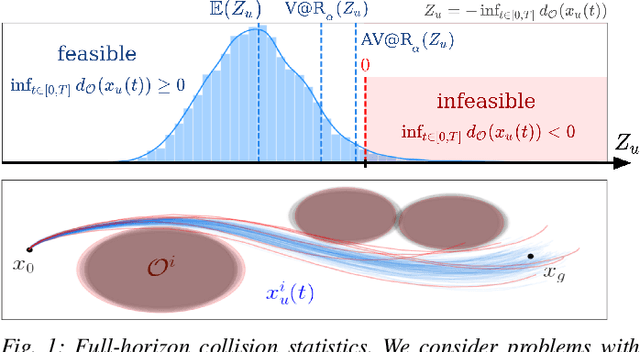
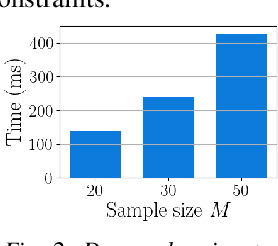
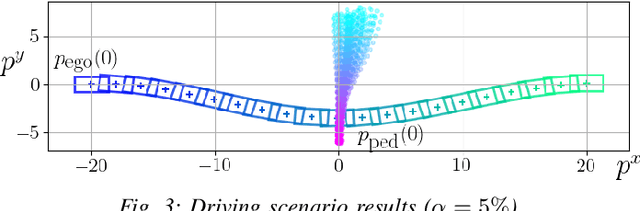
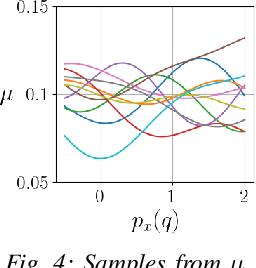
Trajectory optimization under uncertainty underpins a wide range of applications in robotics. However, existing methods are limited in terms of reasoning about sources of epistemic and aleatoric uncertainty, space and time correlations, nonlinear dynamics, and non-convex constraints. In this work, we first introduce a continuous-time planning formulation with an average-value-at-risk constraint over the entire planning horizon. Then, we propose a sample-based approximation that unlocks an efficient, general-purpose, and time-consistent algorithm for risk-averse trajectory optimization. We prove that the method is asymptotically optimal and derive finite-sample error bounds. Simulations demonstrate the high speed and reliability of the approach on problems with stochasticity in nonlinear dynamics, obstacle fields, interactions, and terrain parameters.
Waypoint-Based Imitation Learning for Robotic Manipulation
Jul 26, 2023While imitation learning methods have seen a resurgent interest for robotic manipulation, the well-known problem of compounding errors continues to afflict behavioral cloning (BC). Waypoints can help address this problem by reducing the horizon of the learning problem for BC, and thus, the errors compounded over time. However, waypoint labeling is underspecified, and requires additional human supervision. Can we generate waypoints automatically without any additional human supervision? Our key insight is that if a trajectory segment can be approximated by linear motion, the endpoints can be used as waypoints. We propose Automatic Waypoint Extraction (AWE) for imitation learning, a preprocessing module to decompose a demonstration into a minimal set of waypoints which when interpolated linearly can approximate the trajectory up to a specified error threshold. AWE can be combined with any BC algorithm, and we find that AWE can increase the success rate of state-of-the-art algorithms by up to 25% in simulation and by 4-28% on real-world bimanual manipulation tasks, reducing the decision making horizon by up to a factor of 10. Videos and code are available at https://lucys0.github.io/awe/
Tracking Anything in High Quality
Jul 26, 2023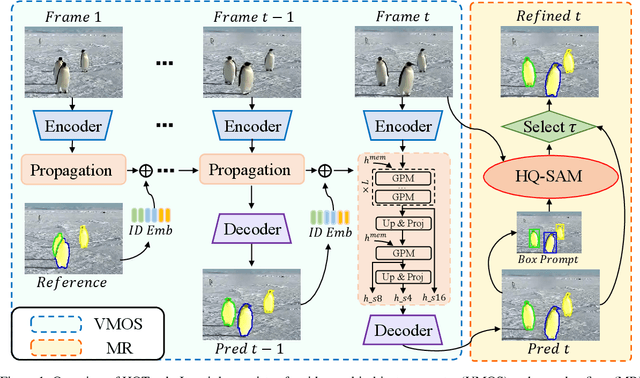
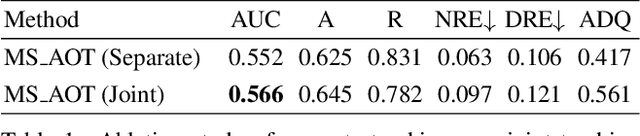
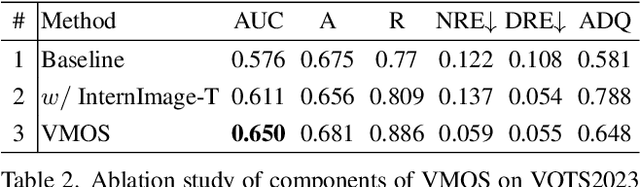

Visual object tracking is a fundamental video task in computer vision. Recently, the notably increasing power of perception algorithms allows the unification of single/multiobject and box/mask-based tracking. Among them, the Segment Anything Model (SAM) attracts much attention. In this report, we propose HQTrack, a framework for High Quality Tracking anything in videos. HQTrack mainly consists of a video multi-object segmenter (VMOS) and a mask refiner (MR). Given the object to be tracked in the initial frame of a video, VMOS propagates the object masks to the current frame. The mask results at this stage are not accurate enough since VMOS is trained on several closeset video object segmentation (VOS) datasets, which has limited ability to generalize to complex and corner scenes. To further improve the quality of tracking masks, a pretrained MR model is employed to refine the tracking results. As a compelling testament to the effectiveness of our paradigm, without employing any tricks such as test-time data augmentations and model ensemble, HQTrack ranks the 2nd place in the Visual Object Tracking and Segmentation (VOTS2023) challenge. Code and models are available at https://github.com/jiawen-zhu/HQTrack.
Single Channel Speech Enhancement Using U-Net Spiking Neural Networks
Jul 26, 2023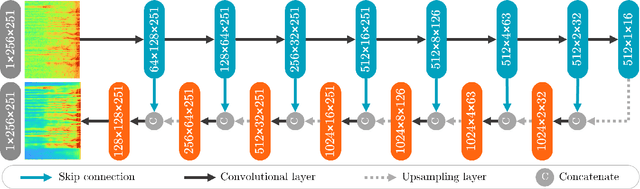
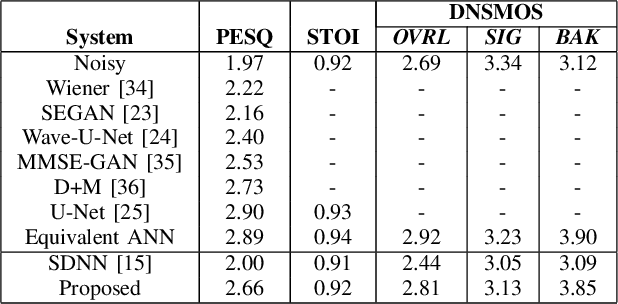
Speech enhancement (SE) is crucial for reliable communication devices or robust speech recognition systems. Although conventional artificial neural networks (ANN) have demonstrated remarkable performance in SE, they require significant computational power, along with high energy costs. In this paper, we propose a novel approach to SE using a spiking neural network (SNN) based on a U-Net architecture. SNNs are suitable for processing data with a temporal dimension, such as speech, and are known for their energy-efficient implementation on neuromorphic hardware. As such, SNNs are thus interesting candidates for real-time applications on devices with limited resources. The primary objective of the current work is to develop an SNN-based model with comparable performance to a state-of-the-art ANN model for SE. We train a deep SNN using surrogate-gradient-based optimization and evaluate its performance using perceptual objective tests under different signal-to-noise ratios and real-world noise conditions. Our results demonstrate that the proposed energy-efficient SNN model outperforms the Intel Neuromorphic Deep Noise Suppression Challenge (Intel N-DNS Challenge) baseline solution and achieves acceptable performance compared to an equivalent ANN model.
Learning Snippet-to-Motion Progression for Skeleton-based Human Motion Prediction
Jul 26, 2023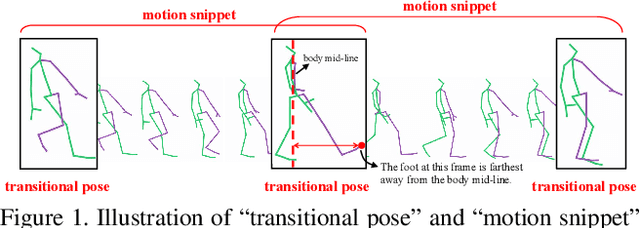
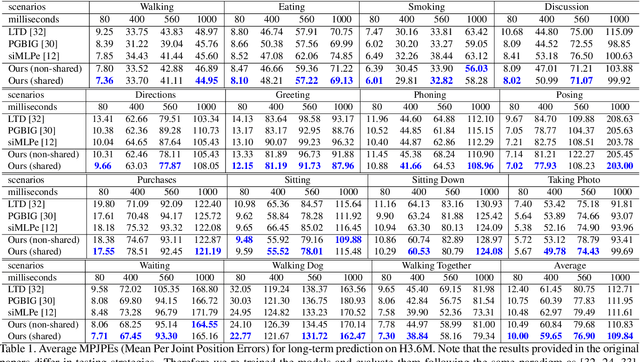
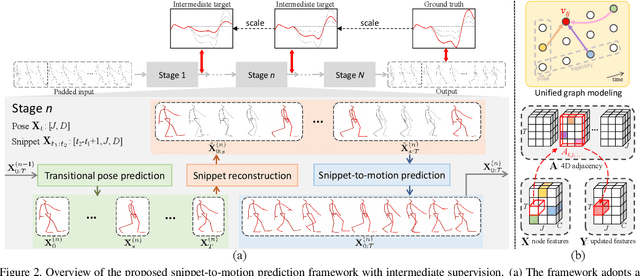
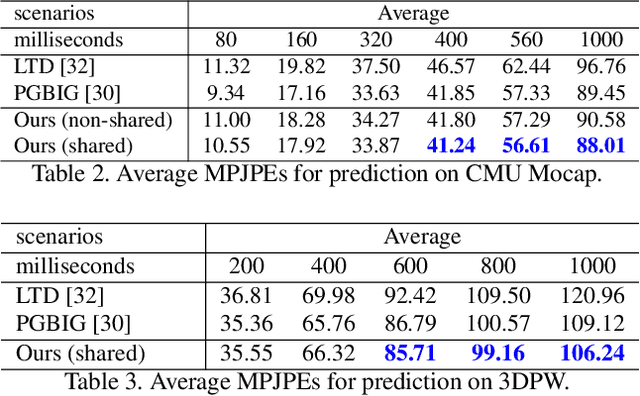
Existing Graph Convolutional Networks to achieve human motion prediction largely adopt a one-step scheme, which output the prediction straight from history input, failing to exploit human motion patterns. We observe that human motions have transitional patterns and can be split into snippets representative of each transition. Each snippet can be reconstructed from its starting and ending poses referred to as the transitional poses. We propose a snippet-to-motion multi-stage framework that breaks motion prediction into sub-tasks easier to accomplish. Each sub-task integrates three modules: transitional pose prediction, snippet reconstruction, and snippet-to-motion prediction. Specifically, we propose to first predict only the transitional poses. Then we use them to reconstruct the corresponding snippets, obtaining a close approximation to the true motion sequence. Finally we refine them to produce the final prediction output. To implement the network, we propose a novel unified graph modeling, which allows for direct and effective feature propagation compared to existing approaches which rely on separate space-time modeling. Extensive experiments on Human 3.6M, CMU Mocap and 3DPW datasets verify the effectiveness of our method which achieves state-of-the-art performance.
Artifact Restoration in Histology Images with Diffusion Probabilistic Models
Jul 26, 2023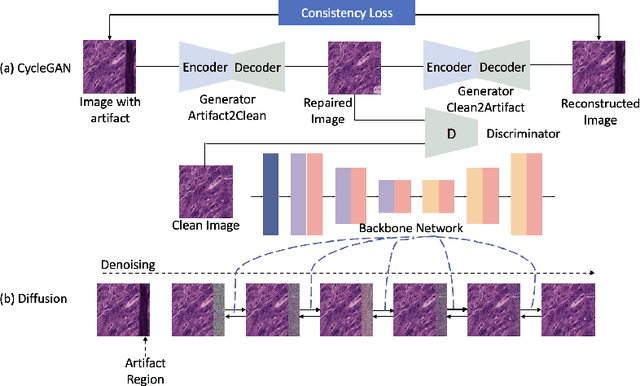
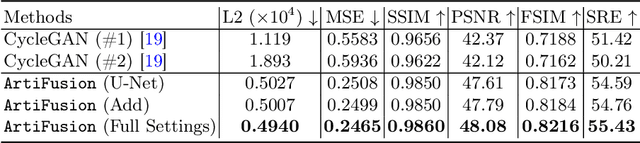
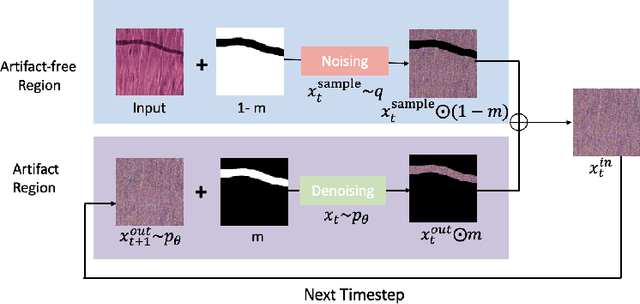
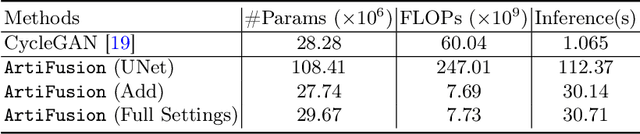
Histological whole slide images (WSIs) can be usually compromised by artifacts, such as tissue folding and bubbles, which will increase the examination difficulty for both pathologists and Computer-Aided Diagnosis (CAD) systems. Existing approaches to restoring artifact images are confined to Generative Adversarial Networks (GANs), where the restoration process is formulated as an image-to-image transfer. Those methods are prone to suffer from mode collapse and unexpected mistransfer in the stain style, leading to unsatisfied and unrealistic restored images. Innovatively, we make the first attempt at a denoising diffusion probabilistic model for histological artifact restoration, namely ArtiFusion.Specifically, ArtiFusion formulates the artifact region restoration as a gradual denoising process, and its training relies solely on artifact-free images to simplify the training complexity.Furthermore, to capture local-global correlations in the regional artifact restoration, a novel Swin-Transformer denoising architecture is designed, along with a time token scheme. Our extensive evaluations demonstrate the effectiveness of ArtiFusion as a pre-processing method for histology analysis, which can successfully preserve the tissue structures and stain style in artifact-free regions during the restoration. Code is available at https://github.com/zhenqi-he/ArtiFusion.
Uncertainty Guided Adaptive Warping for Robust and Efficient Stereo Matching
Jul 26, 2023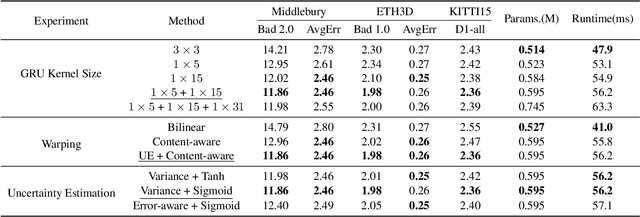
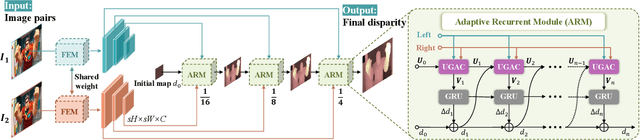
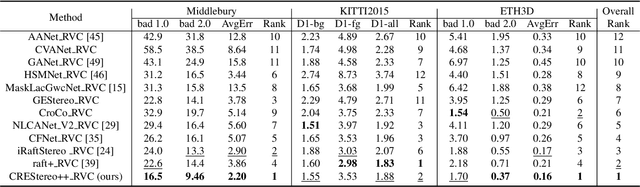
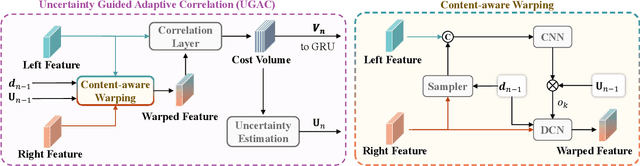
Correlation based stereo matching has achieved outstanding performance, which pursues cost volume between two feature maps. Unfortunately, current methods with a fixed model do not work uniformly well across various datasets, greatly limiting their real-world applicability. To tackle this issue, this paper proposes a new perspective to dynamically calculate correlation for robust stereo matching. A novel Uncertainty Guided Adaptive Correlation (UGAC) module is introduced to robustly adapt the same model for different scenarios. Specifically, a variance-based uncertainty estimation is employed to adaptively adjust the sampling area during warping operation. Additionally, we improve the traditional non-parametric warping with learnable parameters, such that the position-specific weights can be learned. We show that by empowering the recurrent network with the UGAC module, stereo matching can be exploited more robustly and effectively. Extensive experiments demonstrate that our method achieves state-of-the-art performance over the ETH3D, KITTI, and Middlebury datasets when employing the same fixed model over these datasets without any retraining procedure. To target real-time applications, we further design a lightweight model based on UGAC, which also outperforms other methods over KITTI benchmarks with only 0.6 M parameters.
A Vision for Cleaner Rivers: Harnessing Snapshot Hyperspectral Imaging to Detect Macro-Plastic Litter
Jul 22, 2023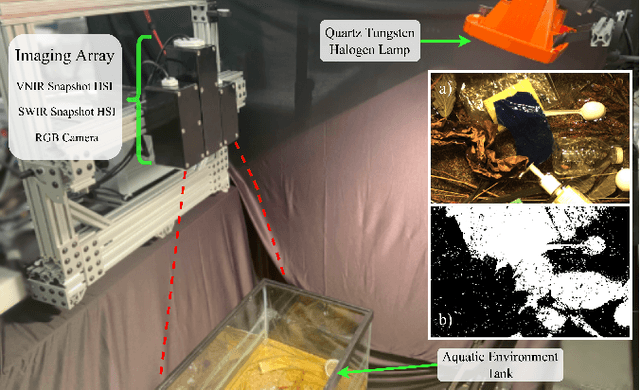

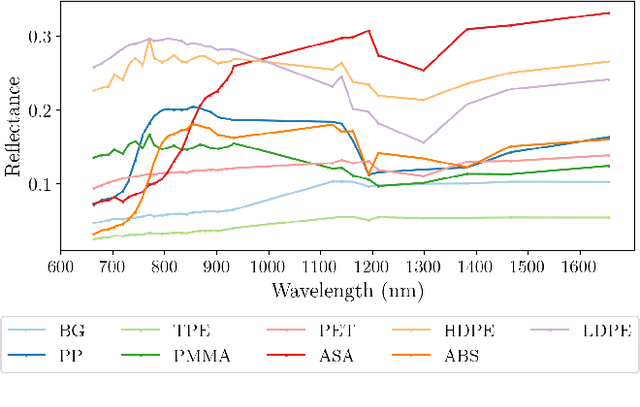
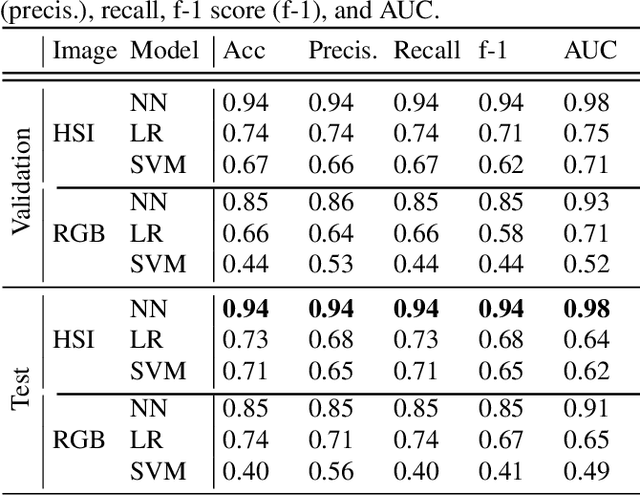
Plastic waste entering the riverine harms local ecosystems leading to negative ecological and economic impacts. Large parcels of plastic waste are transported from inland to oceans leading to a global scale problem of floating debris fields. In this context, efficient and automatized monitoring of mismanaged plastic waste is paramount. To address this problem, we analyze the feasibility of macro-plastic litter detection using computational imaging approaches in river-like scenarios. We enable near-real-time tracking of partially submerged plastics by using snapshot Visible-Shortwave Infrared hyperspectral imaging. Our experiments indicate that imaging strategies associated with machine learning classification approaches can lead to high detection accuracy even in challenging scenarios, especially when leveraging hyperspectral data and nonlinear classifiers. All code, data, and models are available online: https://github.com/RIVeR-Lab/hyperspectral_macro_plastic_detection.