 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Bridging the FL Performance-Explainability Trade-Off: A Trustworthy 6G RAN Slicing Use-Case
Jul 24, 2023
In the context of sixth-generation (6G) networks, where diverse network slices coexist, the adoption of AI-driven zero-touch management and orchestration (MANO) becomes crucial. However, ensuring the trustworthiness of AI black-boxes in real deployments is challenging. Explainable AI (XAI) tools can play a vital role in establishing transparency among the stakeholders in the slicing ecosystem. But there is a trade-off between AI performance and explainability, posing a dilemma for trustworthy 6G network slicing because the stakeholders require both highly performing AI models for efficient resource allocation and explainable decision-making to ensure fairness, accountability, and compliance. To balance this trade off and inspired by the closed loop automation and XAI methodologies, this paper presents a novel explanation-guided in-hoc federated learning (FL) approach where a constrained resource allocation model and an explainer exchange -- in a closed loop (CL) fashion -- soft attributions of the features as well as inference predictions to achieve a transparent 6G network slicing resource management in a RAN-Edge setup under non-independent identically distributed (non-IID) datasets. In particular, we quantitatively validate the faithfulness of the explanations via the so-called attribution-based confidence metric that is included as a constraint to guide the overall training process in the run-time FL optimization task. In this respect, Integrated-Gradient (IG) as well as Input $\times$ Gradient and SHAP are used to generate the attributions for our proposed in-hoc scheme, wherefore simulation results under different methods confirm its success in tackling the performance-explainability trade-off and its superiority over the unconstrained Integrated-Gradient post-hoc FL baseline.
Evaluating the reliability of automatically generated pedestrian and bicycle crash surrogates
Jul 24, 2023
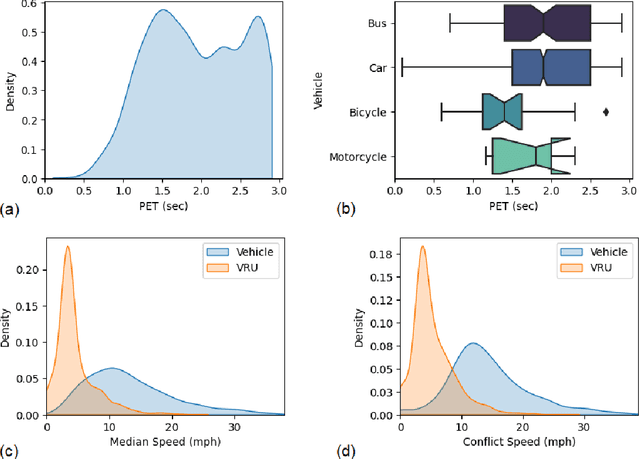
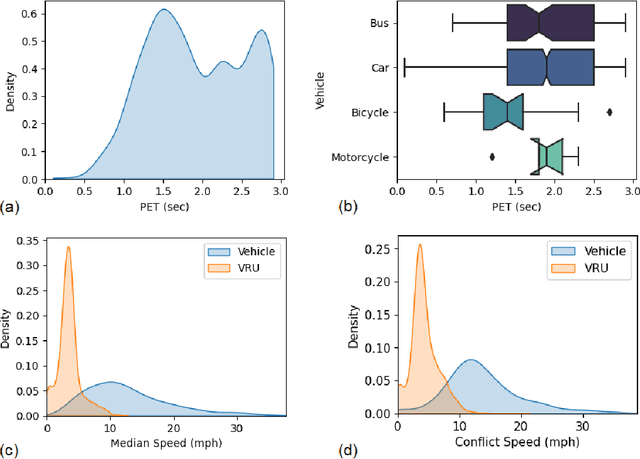
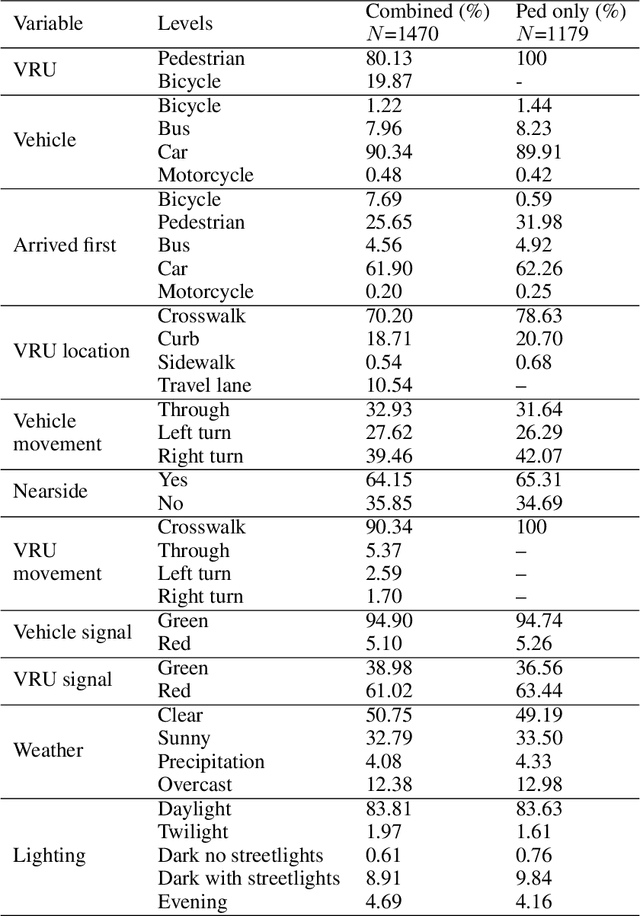
Vulnerable road users (VRUs), such as pedestrians and bicyclists, are at a higher risk of being involved in crashes with motor vehicles, and crashes involving VRUs also are more likely to result in severe injuries or fatalities. Signalized intersections are a major safety concern for VRUs due to their complex and dynamic nature, highlighting the need to understand how these road users interact with motor vehicles and deploy evidence-based countermeasures to improve safety performance. Crashes involving VRUs are relatively infrequent, making it difficult to understand the underlying contributing factors. An alternative is to identify and use conflicts between VRUs and motorized vehicles as a surrogate for safety performance. Automatically detecting these conflicts using a video-based systems is a crucial step in developing smart infrastructure to enhance VRU safety. The Pennsylvania Department of Transportation conducted a study using video-based event monitoring system to assess VRU and motor vehicle interactions at fifteen signalized intersections across Pennsylvania to improve VRU safety performance. This research builds on that study to assess the reliability of automatically generated surrogates in predicting confirmed conflicts using advanced data-driven models. The surrogate data used for analysis include automatically collectable variables such as vehicular and VRU speeds, movements, post-encroachment time, in addition to manually collected variables like signal states, lighting, and weather conditions. The findings highlight the varying importance of specific surrogates in predicting true conflicts, some being more informative than others. The findings can assist transportation agencies to collect the right types of data to help prioritize infrastructure investments, such as bike lanes and crosswalks, and evaluate their effectiveness.
Adaptive Graph Convolution Networks for Traffic Flow Forecasting
Jul 07, 2023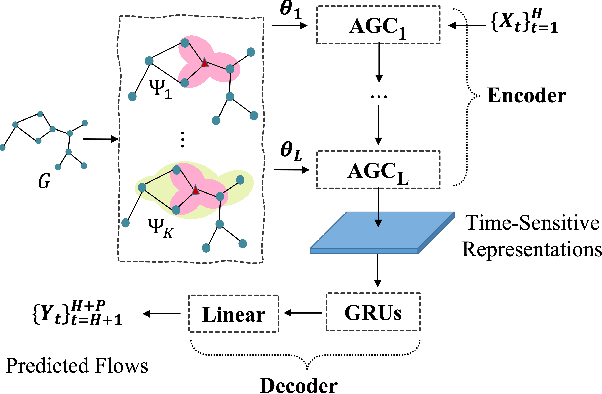
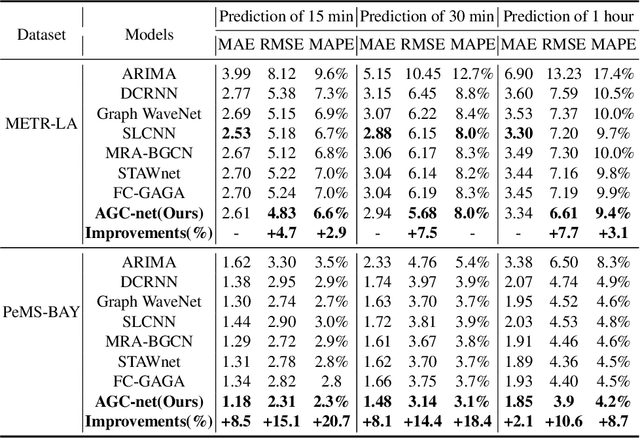
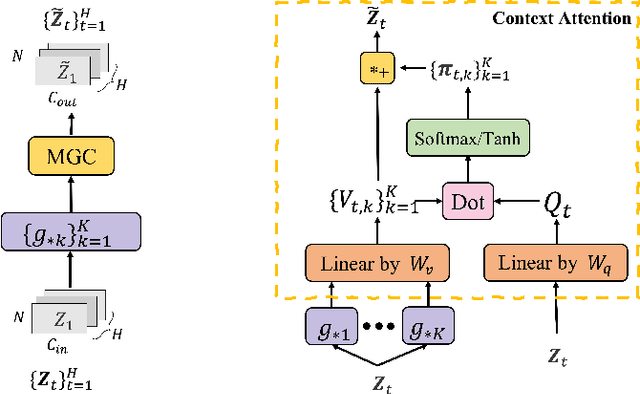
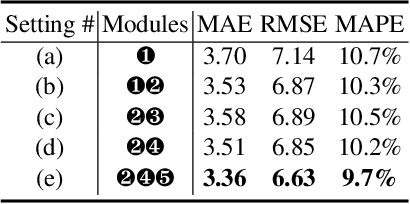
Traffic flow forecasting is a highly challenging task due to the dynamic spatial-temporal road conditions. Graph neural networks (GNN) has been widely applied in this task. However, most of these GNNs ignore the effects of time-varying road conditions due to the fixed range of the convolution receptive field. In this paper, we propose a novel Adaptive Graph Convolution Networks (AGC-net) to address this issue in GNN. The AGC-net is constructed by the Adaptive Graph Convolution (AGC) based on a novel context attention mechanism, which consists of a set of graph wavelets with various learnable scales. The AGC transforms the spatial graph representations into time-sensitive features considering the temporal context. Moreover, a shifted graph convolution kernel is designed to enhance the AGC, which attempts to correct the deviations caused by inaccurate topology. Experimental results on two public traffic datasets demonstrate the effectiveness of the AGC-net\footnote{Code is available at: https://github.com/zhengdaoli/AGC-net} which outperforms other baseline models significantly.
Neural Quantile Optimization for Edge-Cloud Computing
Jul 11, 2023
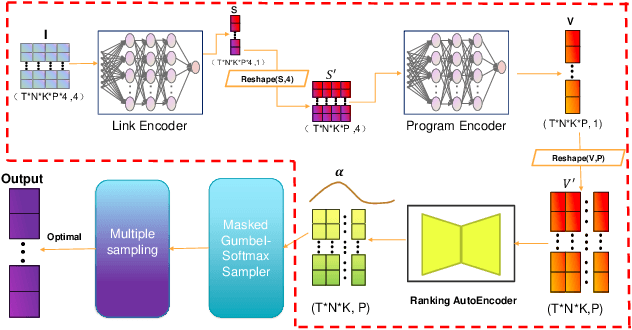
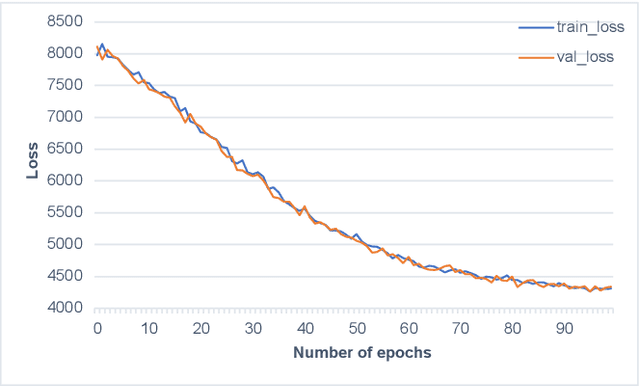
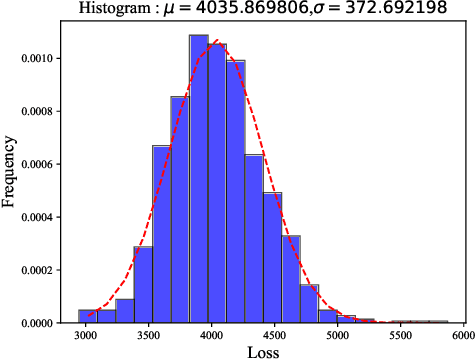
We seek the best traffic allocation scheme for the edge-cloud computing network that satisfies constraints and minimizes the cost based on burstable billing. First, for a fixed network topology, we formulate a family of integer programming problems with random parameters describing the various traffic demands. Then, to overcome the difficulty caused by the discrete feature of the problem, we generalize the Gumbel-softmax reparameterization method to induce an unconstrained continuous optimization problem as a regularized continuation of the discrete problem. Finally, we introduce the Gumbel-softmax sampling network to solve the optimization problems via unsupervised learning. The network structure reflects the edge-cloud computing topology and is trained to minimize the expectation of the cost function for unconstrained continuous optimization problems. The trained network works as an efficient traffic allocation scheme sampler, remarkably outperforming the random strategy in feasibility and cost function value. Besides testing the quality of the output allocation scheme, we examine the generalization property of the network by increasing the time steps and the number of users. We also feed the solution to existing integer optimization solvers as initial conditions and verify the warm-starts can accelerate the short-time iteration process. The framework is general with solid performance, and the decoupled feature of the random neural networks is adequate for practical implementations.
BASS: Block-wise Adaptation for Speech Summarization
Jul 17, 2023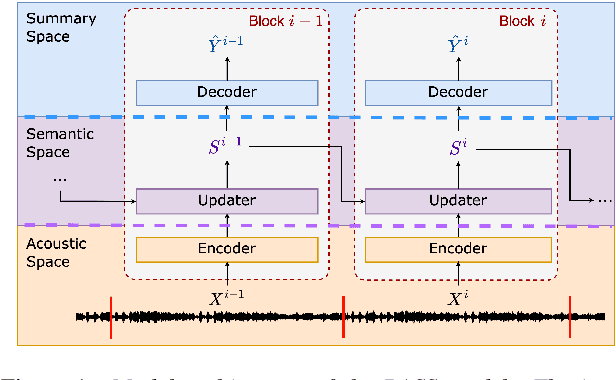
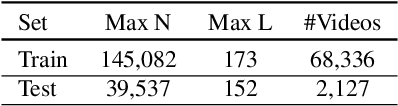
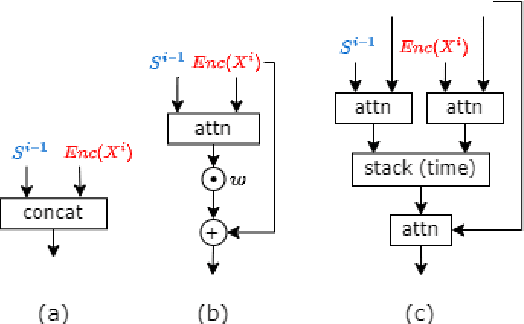

End-to-end speech summarization has been shown to improve performance over cascade baselines. However, such models are difficult to train on very large inputs (dozens of minutes or hours) owing to compute restrictions and are hence trained with truncated model inputs. Truncation leads to poorer models, and a solution to this problem rests in block-wise modeling, i.e., processing a portion of the input frames at a time. In this paper, we develop a method that allows one to train summarization models on very long sequences in an incremental manner. Speech summarization is realized as a streaming process, where hypothesis summaries are updated every block based on new acoustic information. We devise and test strategies to pass semantic context across the blocks. Experiments on the How2 dataset demonstrate that the proposed block-wise training method improves by 3 points absolute on ROUGE-L over a truncated input baseline.
Artificial Intelligence for the Electron Ion Collider (AI4EIC)
Jul 17, 2023

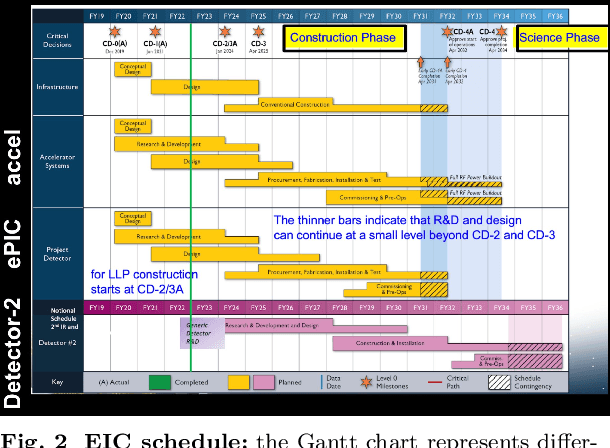
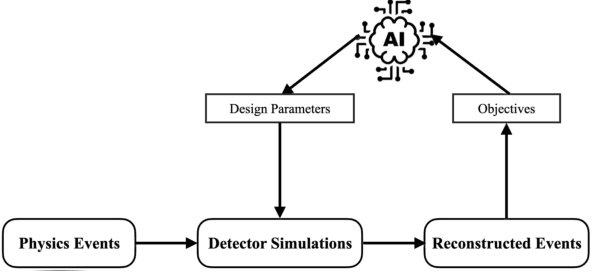
The Electron-Ion Collider (EIC), a state-of-the-art facility for studying the strong force, is expected to begin commissioning its first experiments in 2028. This is an opportune time for artificial intelligence (AI) to be included from the start at this facility and in all phases that lead up to the experiments. The second annual workshop organized by the AI4EIC working group, which recently took place, centered on exploring all current and prospective application areas of AI for the EIC. This workshop is not only beneficial for the EIC, but also provides valuable insights for the newly established ePIC collaboration at EIC. This paper summarizes the different activities and R&D projects covered across the sessions of the workshop and provides an overview of the goals, approaches and strategies regarding AI/ML in the EIC community, as well as cutting-edge techniques currently studied in other experiments.
Optimization-based Learning for Dynamic Load Planning in Trucking Service Networks
Jul 08, 2023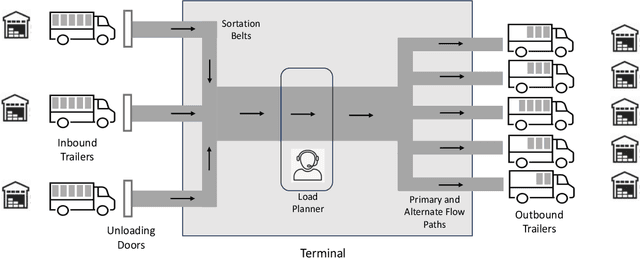
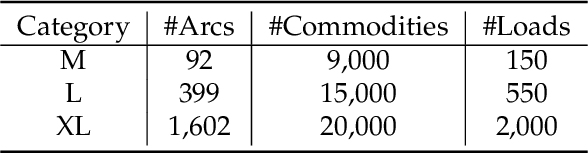
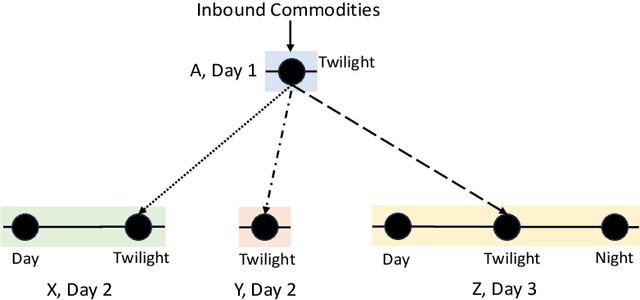

The load planning problem is a critical challenge in service network design for parcel carriers: it decides how many trailers (or loads) to assign for dispatch over time between pairs of terminals. Another key challenge is to determine a flow plan, which specifies how parcel volumes are assigned to planned loads. This paper considers the Dynamic Load Planning Problem (DLPP) that considers both flow and load planning challenges jointly to adjust loads and flows as the demand forecast changes over time before the day of operations. The paper aims at developing a decision-support tool to inform planners making these decisions at terminals across the network. The paper formulates the DLPP as a MIP and shows that it admits a large number of symmetries in a network where each commodity can be routed through primary and alternate paths. As a result, an optimization solver may return fundamentally different solutions to closely related problems, confusing planners and reducing trust in optimization. To remedy this limitation, the paper proposes a Goal-Directed Optimization that eliminates those symmetries by generating optimal solutions staying close to a reference plan. The paper also proposes an optimization proxy to address the computational challenges of the optimization models. The proxy combines a machine learning model and a feasibility restoration model and finds solutions that satisfy real-time constraints imposed by planners-in-the-loop. An extensive computational study on industrial instances shows that the optimization proxy is around 10 times faster than the commercial solver in obtaining the same quality solutions and orders of magnitude faster for generating solutions that are consistent with each other. The proposed approach also demonstrates the benefits of the DLPP for load consolidation, and the significant savings obtained from combining machine learning and optimization.
Sketch-A-Shape: Zero-Shot Sketch-to-3D Shape Generation
Jul 08, 2023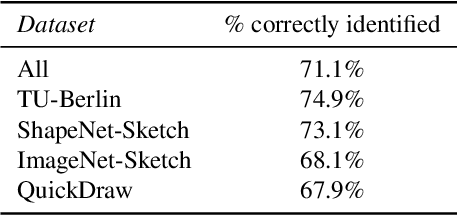
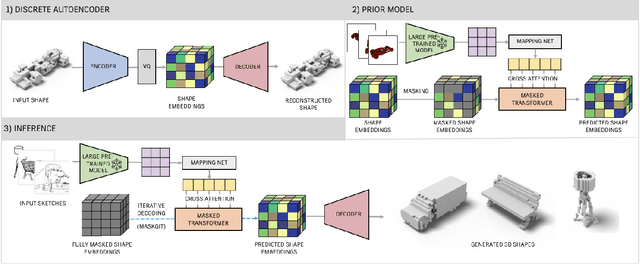


Significant progress has recently been made in creative applications of large pre-trained models for downstream tasks in 3D vision, such as text-to-shape generation. This motivates our investigation of how these pre-trained models can be used effectively to generate 3D shapes from sketches, which has largely remained an open challenge due to the limited sketch-shape paired datasets and the varying level of abstraction in the sketches. We discover that conditioning a 3D generative model on the features (obtained from a frozen large pre-trained vision model) of synthetic renderings during training enables us to effectively generate 3D shapes from sketches at inference time. This suggests that the large pre-trained vision model features carry semantic signals that are resilient to domain shifts, i.e., allowing us to use only RGB renderings, but generalizing to sketches at inference time. We conduct a comprehensive set of experiments investigating different design factors and demonstrate the effectiveness of our straightforward approach for generation of multiple 3D shapes per each input sketch regardless of their level of abstraction without requiring any paired datasets during training.
Reading Between the Lanes: Text VideoQA on the Road
Jul 08, 2023

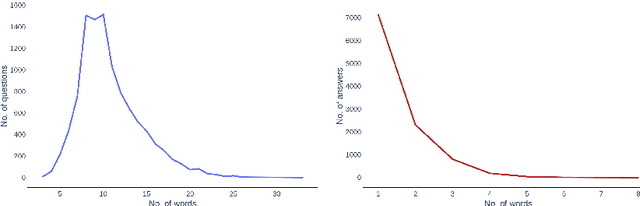
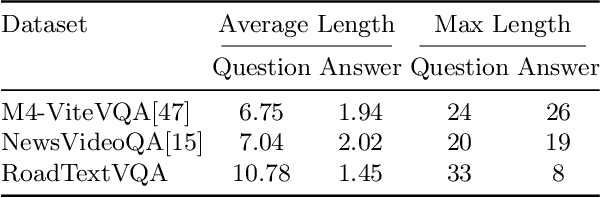
Text and signs around roads provide crucial information for drivers, vital for safe navigation and situational awareness. Scene text recognition in motion is a challenging problem, while textual cues typically appear for a short time span, and early detection at a distance is necessary. Systems that exploit such information to assist the driver should not only extract and incorporate visual and textual cues from the video stream but also reason over time. To address this issue, we introduce RoadTextVQA, a new dataset for the task of video question answering (VideoQA) in the context of driver assistance. RoadTextVQA consists of $3,222$ driving videos collected from multiple countries, annotated with $10,500$ questions, all based on text or road signs present in the driving videos. We assess the performance of state-of-the-art video question answering models on our RoadTextVQA dataset, highlighting the significant potential for improvement in this domain and the usefulness of the dataset in advancing research on in-vehicle support systems and text-aware multimodal question answering. The dataset is available at http://cvit.iiit.ac.in/research/projects/cvit-projects/roadtextvqa
Event Camera-based Visual Odometry for Dynamic Motion Tracking of a Legged Robot Using Adaptive Time Surface
May 15, 2023
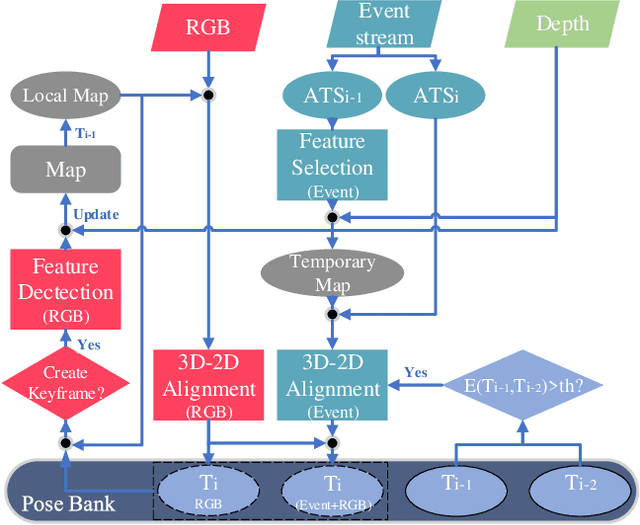
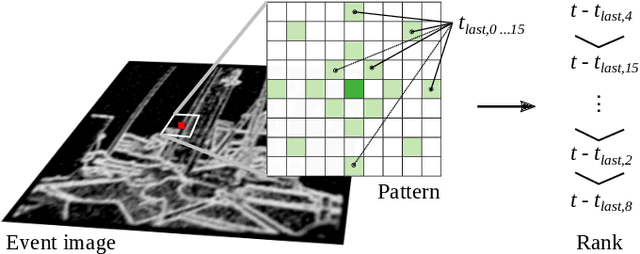

Our paper proposes a direct sparse visual odometry method that combines event and RGB-D data to estimate the pose of agile-legged robots during dynamic locomotion and acrobatic behaviors. Event cameras offer high temporal resolution and dynamic range, which can eliminate the issue of blurred RGB images during fast movements. This unique strength holds a potential for accurate pose estimation of agile-legged robots, which has been a challenging problem to tackle. Our framework leverages the benefits of both RGB-D and event cameras to achieve robust and accurate pose estimation, even during dynamic maneuvers such as jumping and landing a quadruped robot, the Mini-Cheetah. Our major contributions are threefold: Firstly, we introduce an adaptive time surface (ATS) method that addresses the whiteout and blackout issue in conventional time surfaces by formulating pixel-wise decay rates based on scene complexity and motion speed. Secondly, we develop an effective pixel selection method that directly samples from event data and applies sample filtering through ATS, enabling us to pick pixels on distinct features. Lastly, we propose a nonlinear pose optimization formula that simultaneously performs 3D-2D alignment on both RGB-based and event-based maps and images, allowing the algorithm to fully exploit the benefits of both data streams. We extensively evaluate the performance of our framework on both public datasets and our own quadruped robot dataset, demonstrating its effectiveness in accurately estimating the pose of agile robots during dynamic movements.