 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
WSCLoc: Weakly-Supervised Sparse-View Camera Relocalization
Mar 22, 2024
Despite the advancements in deep learning for camera relocalization tasks, obtaining ground truth pose labels required for the training process remains a costly endeavor. While current weakly supervised methods excel in lightweight label generation, their performance notably declines in scenarios with sparse views. In response to this challenge, we introduce WSCLoc, a system capable of being customized to various deep learning-based relocalization models to enhance their performance under weakly-supervised and sparse view conditions. This is realized with two stages. In the initial stage, WSCLoc employs a multilayer perceptron-based structure called WFT-NeRF to co-optimize image reconstruction quality and initial pose information. To ensure a stable learning process, we incorporate temporal information as input. Furthermore, instead of optimizing SE(3), we opt for $\mathfrak{sim}(3)$ optimization to explicitly enforce a scale constraint. In the second stage, we co-optimize the pre-trained WFT-NeRF and WFT-Pose. This optimization is enhanced by Time-Encoding based Random View Synthesis and supervised by inter-frame geometric constraints that consider pose, depth, and RGB information. We validate our approaches on two publicly available datasets, one outdoor and one indoor. Our experimental results demonstrate that our weakly-supervised relocalization solutions achieve superior pose estimation accuracy in sparse-view scenarios, comparable to state-of-the-art camera relocalization methods. We will make our code publicly available.
Coexisting Passive RIS and Active Relay Assisted NOMA Systems
Mar 22, 2024A novel coexisting passive reconfigurable intelligent surface (RIS) and active decode-and-forward (DF) relay assisted non-orthogonal multiple access (NOMA) transmission framework is proposed. In particular, two communication protocols are conceived, namely Hybrid NOMA (H-NOMA) and Full NOMA (F-NOMA). Based on the proposed two protocols, both the sum rate maximization and max-min rate fairness problems are formulated for jointly optimizing the power allocation at the access point and relay as well as the passive beamforming design at the RIS. To tackle the non-convex problems, an alternating optimization (AO) based algorithm is first developed, where the transmit power and the RIS phase-shift are alternatingly optimized by leveraging the two-dimensional search and rank-relaxed difference-of-convex (DC) programming, respectively. Then, a two-layer penalty based joint optimization (JO) algorithm is developed to jointly optimize the resource allocation coefficients within each iteration. Finally, numerical results demonstrate that: i) the proposed coexisting RIS and relay assisted transmission framework is capable of achieving a significant user performance improvement than conventional schemes without RIS or relay; ii) compared with the AO algorithm, the JO algorithm requires less execution time at the cost of a slight performance loss; and iii) the H-NOMA and F-NOMA protocols are generally preferable for ensuring user rate fairness and enhancing user sum rate, respectively.
HySim: An Efficient Hybrid Similarity Measure for Patch Matching in Image Inpainting
Mar 21, 2024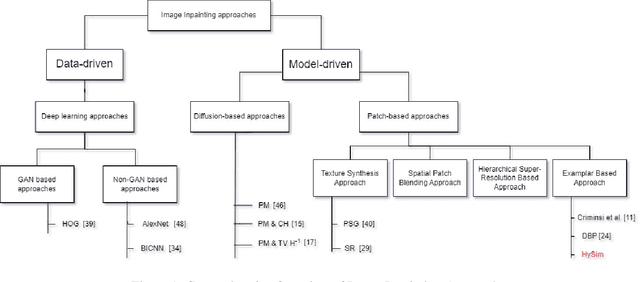
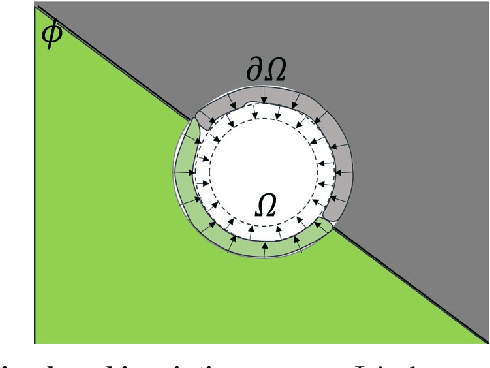
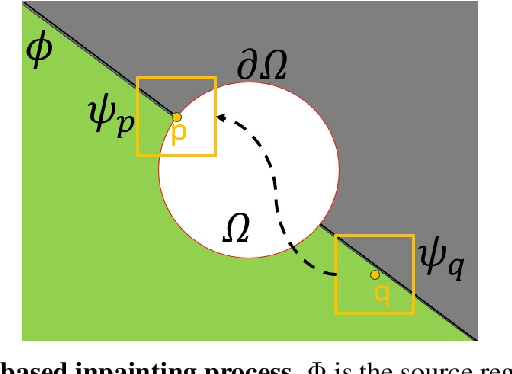
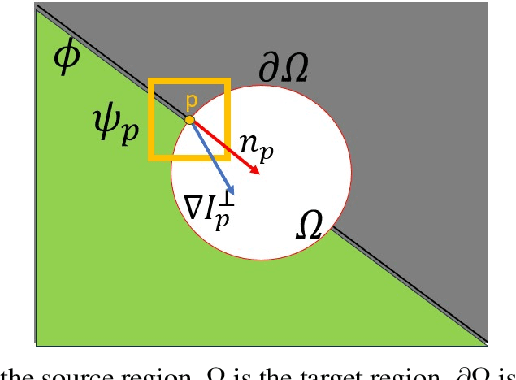
Inpainting, for filling missing image regions, is a crucial task in various applications, such as medical imaging and remote sensing. Trending data-driven approaches efficiency, for image inpainting, often requires extensive data preprocessing. In this sense, there is still a need for model-driven approaches in case of application constrained with data availability and quality, especially for those related for time series forecasting using image inpainting techniques. This paper proposes an improved modeldriven approach relying on patch-based techniques. Our approach deviates from the standard Sum of Squared Differences (SSD) similarity measure by introducing a Hybrid Similarity (HySim), which combines both strengths of Chebychev and Minkowski distances. This hybridization enhances patch selection, leading to high-quality inpainting results with reduced mismatch errors. Experimental results proved the effectiveness of our approach against other model-driven techniques, such as diffusion or patch-based approaches, showcasing its effectiveness in achieving visually pleasing restorations.
Generalizing deep learning models for medical image classification
Mar 21, 2024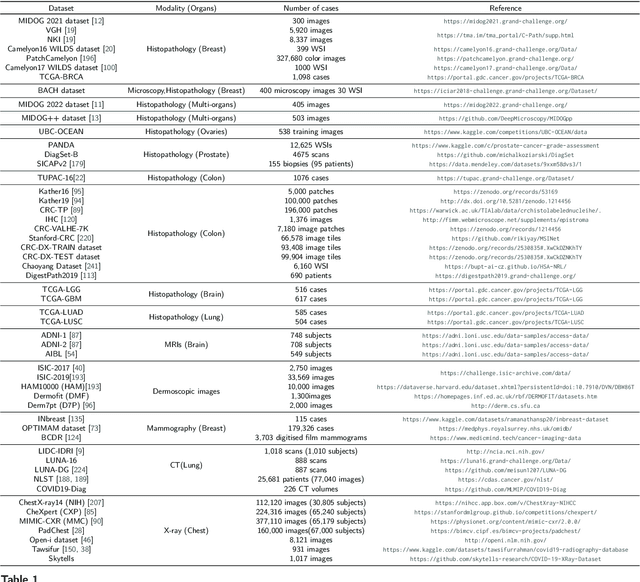
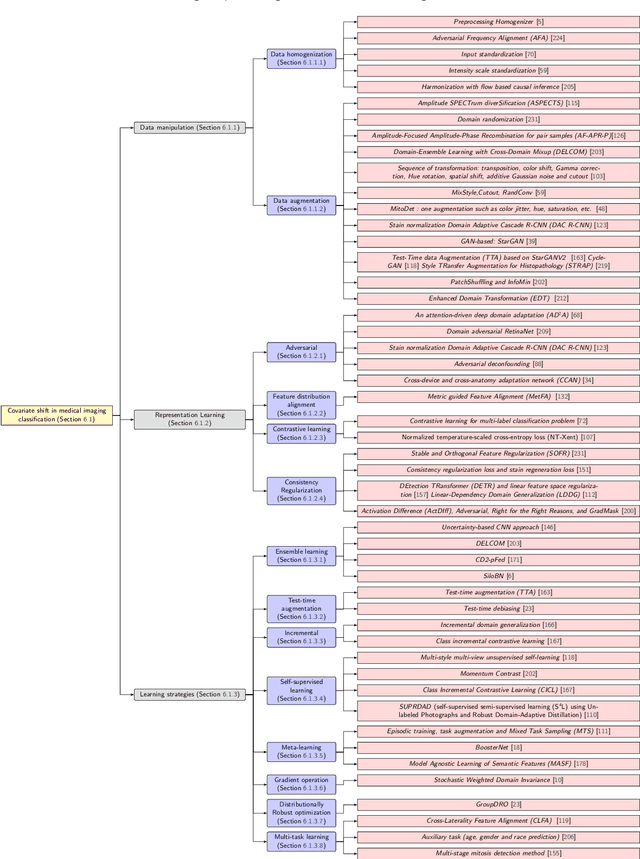
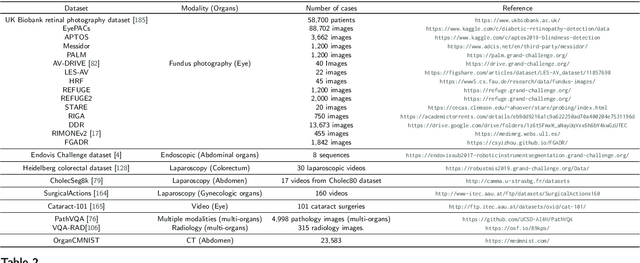
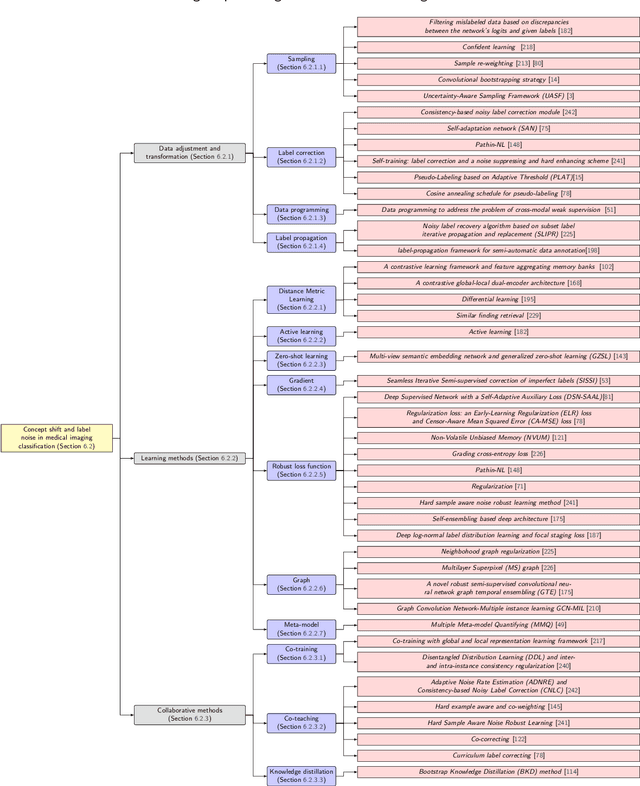
Numerous Deep Learning (DL) models have been developed for a large spectrum of medical image analysis applications, which promises to reshape various facets of medical practice. Despite early advances in DL model validation and implementation, which encourage healthcare institutions to adopt them, some fundamental questions remain: are the DL models capable of generalizing? What causes a drop in DL model performances? How to overcome the DL model performance drop? Medical data are dynamic and prone to domain shift, due to multiple factors such as updates to medical equipment, new imaging workflow, and shifts in patient demographics or populations can induce this drift over time. In this paper, we review recent developments in generalization methods for DL-based classification models. We also discuss future challenges, including the need for improved evaluation protocols and benchmarks, and envisioned future developments to achieve robust, generalized models for medical image classification.
STG-Mamba: Spatial-Temporal Graph Learning via Selective State Space Model
Mar 19, 2024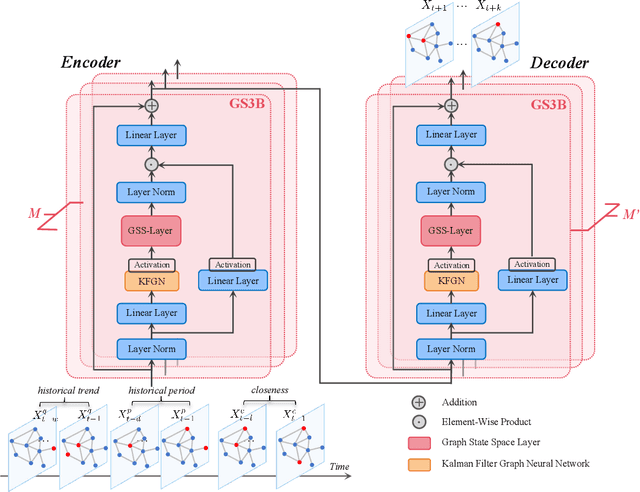
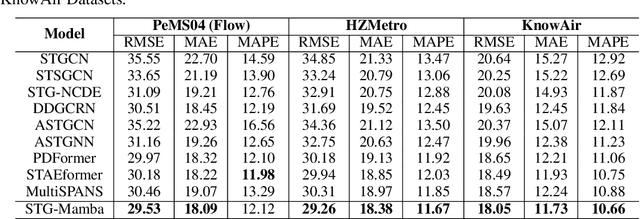
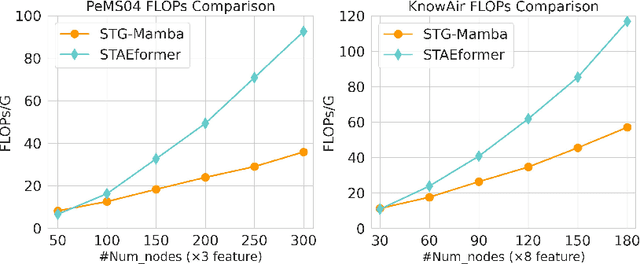
Spatial-Temporal Graph (STG) data is characterized as dynamic, heterogenous, and non-stationary, leading to the continuous challenge of spatial-temporal graph learning. In the past few years, various GNN-based methods have been proposed to solely focus on mimicking the relationships among node individuals of the STG network, ignoring the significance of modeling the intrinsic features that exist in STG system over time. In contrast, modern Selective State Space Models (SSSMs) present a new approach which treat STG Network as a system, and meticulously explore the STG system's dynamic state evolution across temporal dimension. In this work, we introduce Spatial-Temporal Graph Mamba (STG-Mamba) as the first exploration of leveraging the powerful selective state space models for STG learning by treating STG Network as a system, and employing the Graph Selective State Space Block (GS3B) to precisely characterize the dynamic evolution of STG networks. STG-Mamba is formulated as an Encoder-Decoder architecture, which takes GS3B as the basic module, for efficient sequential data modeling. Furthermore, to strengthen GNN's ability of modeling STG data under the setting of SSSMs, we propose Kalman Filtering Graph Neural Networks (KFGN) for adaptive graph structure upgrading. KFGN smoothly fits in the context of selective state space evolution, and at the same time keeps linear complexity. Extensive empirical studies are conducted on three benchmark STG forecasting datasets, demonstrating the performance superiority and computational efficiency of STG-Mamba. It not only surpasses existing state-of-the-art methods in terms of STG forecasting performance, but also effectively alleviate the computational bottleneck of large-scale graph networks in reducing the computational cost of FLOPs and test inference time.
ConvTimeNet: A Deep Hierarchical Fully Convolutional Model for Multivariate Time Series Analysis
Mar 03, 2024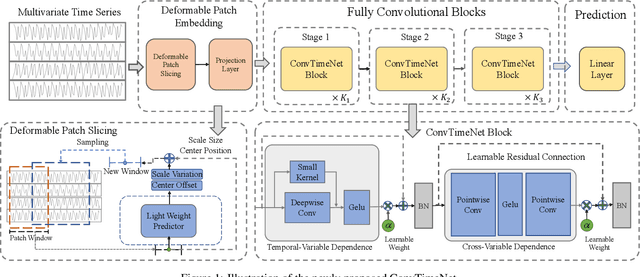

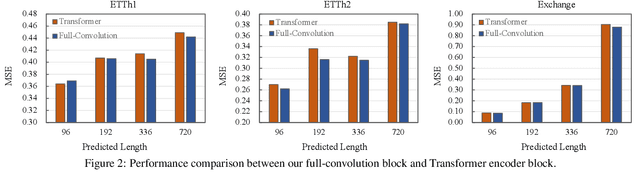
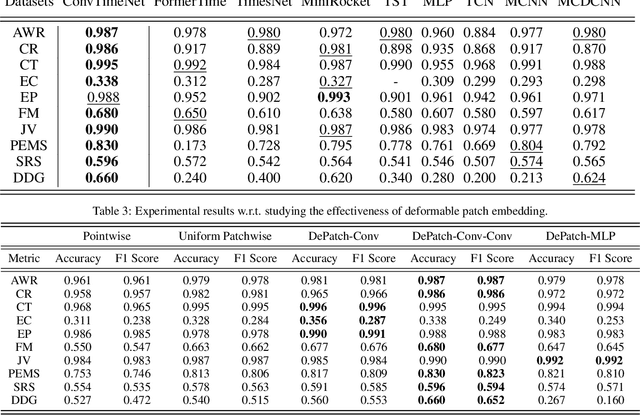
This paper introduces ConvTimeNet, a novel deep hierarchical fully convolutional network designed to serve as a general-purpose model for time series analysis. The key design of this network is twofold, designed to overcome the limitations of traditional convolutional networks. Firstly, we propose an adaptive segmentation of time series into sub-series level patches, treating these as fundamental modeling units. This setting avoids the sparsity semantics associated with raw point-level time steps. Secondly, we design a fully convolutional block by skillfully integrating deepwise and pointwise convolution operations, following the advanced building block style employed in Transformer encoders. This backbone network allows for the effective capture of both global sequence and cross-variable dependence, as it not only incorporates the advancements of Transformer architecture but also inherits the inherent properties of convolution. Furthermore, multi-scale representations of given time series instances can be learned by controlling the kernel size flexibly. Extensive experiments are conducted on both time series forecasting and classification tasks. The results consistently outperformed strong baselines in most situations in terms of effectiveness.The code is publicly available.
Scene-Graph ViT: End-to-End Open-Vocabulary Visual Relationship Detection
Mar 21, 2024
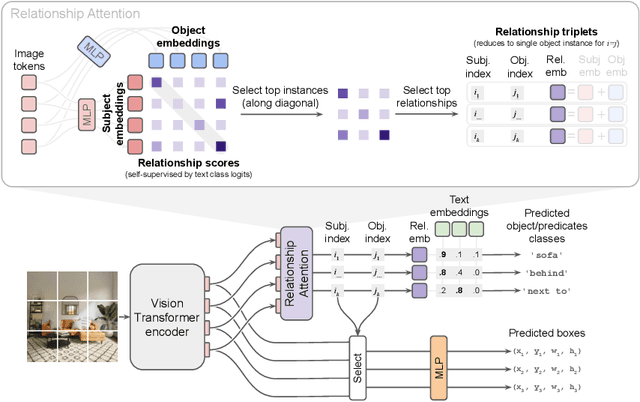

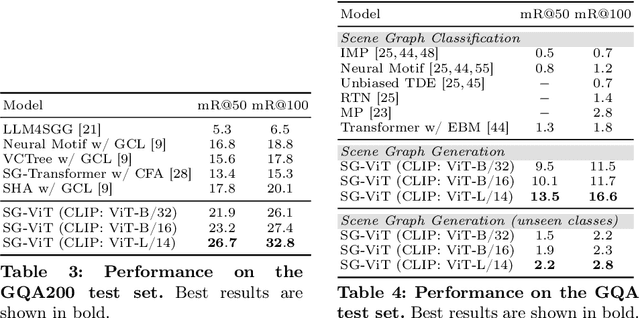
Visual relationship detection aims to identify objects and their relationships in images. Prior methods approach this task by adding separate relationship modules or decoders to existing object detection architectures. This separation increases complexity and hinders end-to-end training, which limits performance. We propose a simple and highly efficient decoder-free architecture for open-vocabulary visual relationship detection. Our model consists of a Transformer-based image encoder that represents objects as tokens and models their relationships implicitly. To extract relationship information, we introduce an attention mechanism that selects object pairs likely to form a relationship. We provide a single-stage recipe to train this model on a mixture of object and relationship detection data. Our approach achieves state-of-the-art relationship detection performance on Visual Genome and on the large-vocabulary GQA benchmark at real-time inference speeds. We provide analyses of zero-shot performance, ablations, and real-world qualitative examples.
DouRN: Improving DouZero by Residual Neural Networks
Mar 21, 2024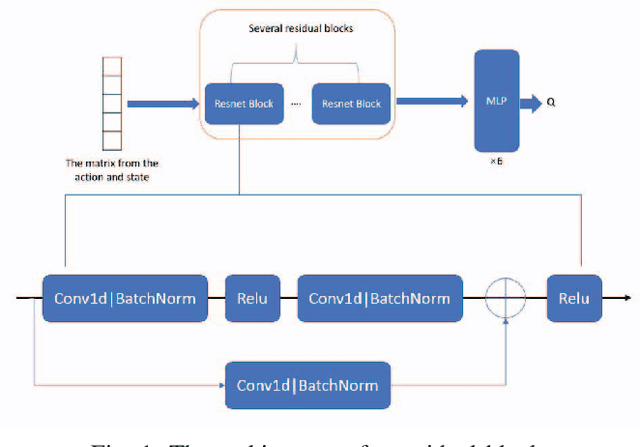
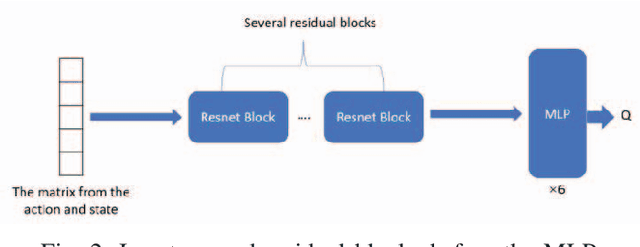
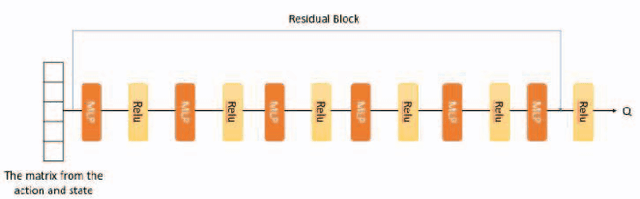
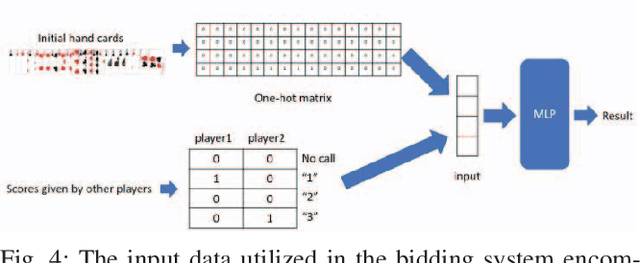
Deep reinforcement learning has made significant progress in games with imperfect information, but its performance in the card game Doudizhu (Chinese Poker/Fight the Landlord) remains unsatisfactory. Doudizhu is different from conventional games as it involves three players and combines elements of cooperation and confrontation, resulting in a large state and action space. In 2021, a Doudizhu program called DouZero\cite{zha2021douzero} surpassed previous models without prior knowledge by utilizing traditional Monte Carlo methods and multilayer perceptrons. Building on this work, our study incorporates residual networks into the model, explores different architectural designs, and conducts multi-role testing. Our findings demonstrate that this model significantly improves the winning rate within the same training time. Additionally, we introduce a call scoring system to assist the agent in deciding whether to become a landlord. With these enhancements, our model consistently outperforms the existing version of DouZero and even experienced human players. \footnote{The source code is available at \url{https://github.com/Yingchaol/Douzero_Resnet.git.}
Semantics from Space: Satellite-Guided Thermal Semantic Segmentation Annotation for Aerial Field Robots
Mar 21, 2024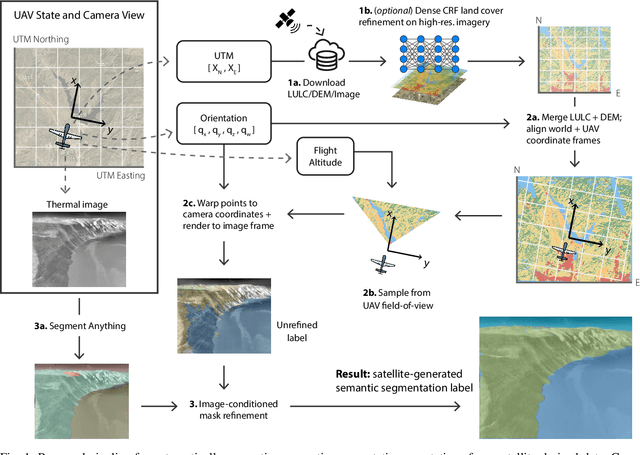
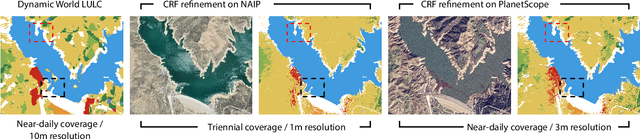
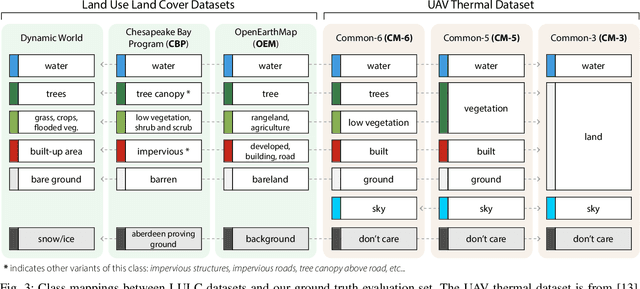

We present a new method to automatically generate semantic segmentation annotations for thermal imagery captured from an aerial vehicle by utilizing satellite-derived data products alongside onboard global positioning and attitude estimates. This new capability overcomes the challenge of developing thermal semantic perception algorithms for field robots due to the lack of annotated thermal field datasets and the time and costs of manual annotation, enabling precise and rapid annotation of thermal data from field collection efforts at a massively-parallelizable scale. By incorporating a thermal-conditioned refinement step with visual foundation models, our approach can produce highly-precise semantic segmentation labels using low-resolution satellite land cover data for little-to-no cost. It achieves 98.5% of the performance from using costly high-resolution options and demonstrates between 70-160% improvement over popular zero-shot semantic segmentation methods based on large vision-language models currently used for generating annotations for RGB imagery. Code will be available at: https://github.com/connorlee77/aerial-auto-segment.
IDAdapter: Learning Mixed Features for Tuning-Free Personalization of Text-to-Image Models
Mar 21, 2024
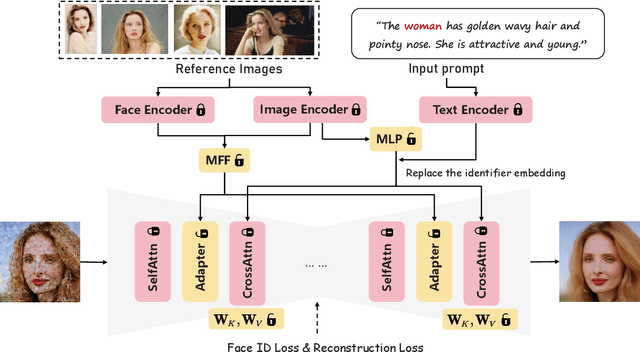
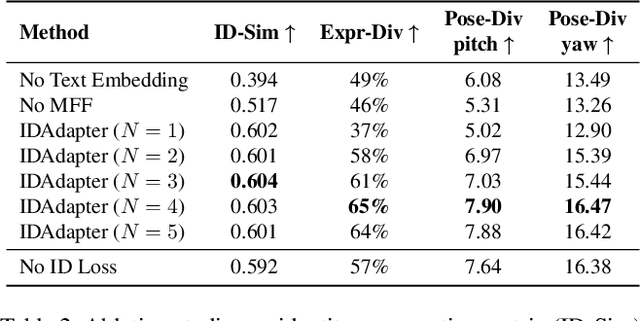

Leveraging Stable Diffusion for the generation of personalized portraits has emerged as a powerful and noteworthy tool, enabling users to create high-fidelity, custom character avatars based on their specific prompts. However, existing personalization methods face challenges, including test-time fine-tuning, the requirement of multiple input images, low preservation of identity, and limited diversity in generated outcomes. To overcome these challenges, we introduce IDAdapter, a tuning-free approach that enhances the diversity and identity preservation in personalized image generation from a single face image. IDAdapter integrates a personalized concept into the generation process through a combination of textual and visual injections and a face identity loss. During the training phase, we incorporate mixed features from multiple reference images of a specific identity to enrich identity-related content details, guiding the model to generate images with more diverse styles, expressions, and angles compared to previous works. Extensive evaluations demonstrate the effectiveness of our method, achieving both diversity and identity fidelity in generated images.