 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
EsaNet: Environment Semantics Enabled Physical Layer Authentication
Jul 18, 2023
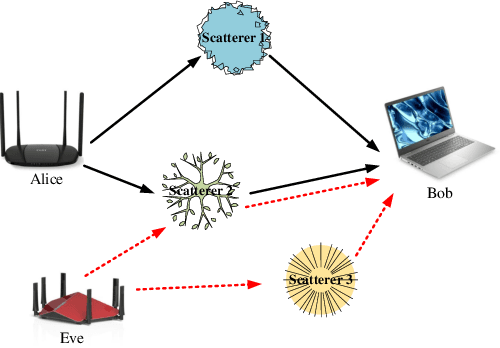
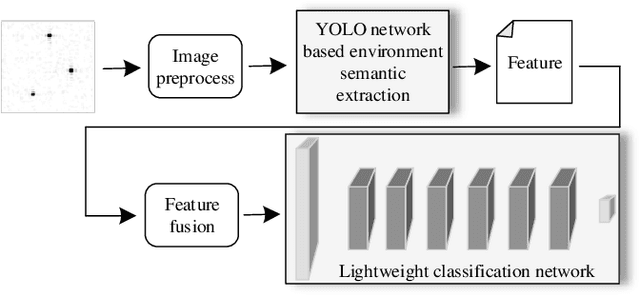
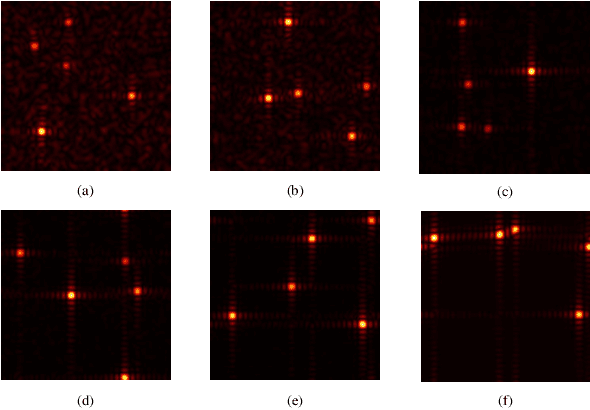
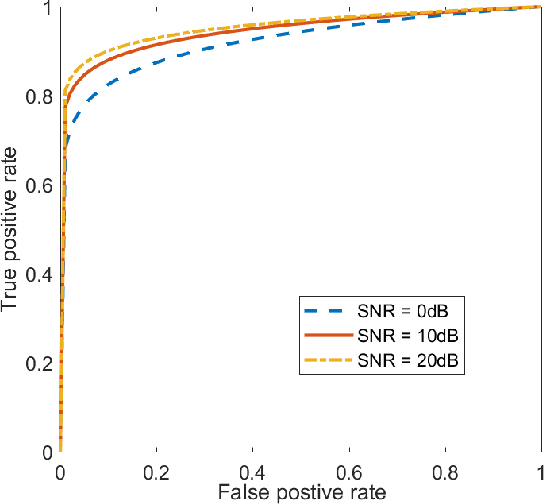
Wireless networks are vulnerable to physical layer spoofing attacks due to the wireless broadcast nature, thus, integrating communications and security (ICAS) is urgently needed for 6G endogenous security. In this letter, we propose an environment semantics enabled physical layer authentication network based on deep learning, namely EsaNet, to authenticate the spoofing from the underlying wireless protocol. Specifically, the frequency independent wireless channel fingerprint (FiFP) is extracted from the channel state information (CSI) of a massive multi-input multi-output (MIMO) system based on environment semantics knowledge. Then, we transform the received signal into a two-dimensional red green blue (RGB) image and apply the you only look once (YOLO), a single-stage object detection network, to quickly capture the FiFP. Next, a lightweight classification network is designed to distinguish the legitimate from the illegitimate users. Finally, the experimental results show that the proposed EsaNet can effectively detect physical layer spoofing attacks and is robust in time-varying wireless environments.
Deep Neural Aggregation for Recommending Items to Group of Users
Jul 18, 2023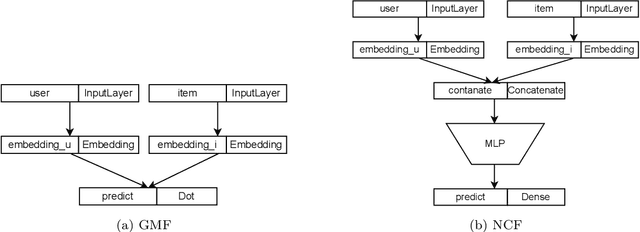

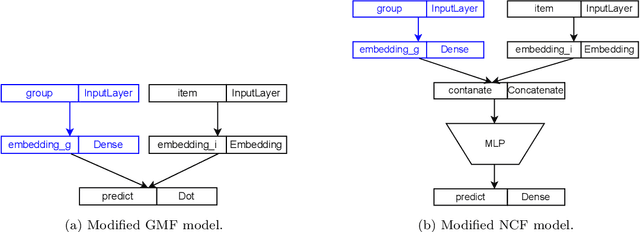
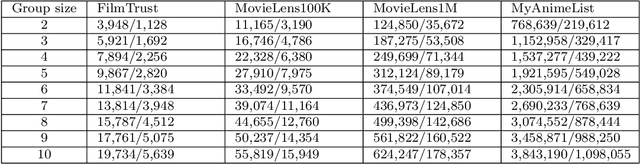
Modern society devotes a significant amount of time to digital interaction. Many of our daily actions are carried out through digital means. This has led to the emergence of numerous Artificial Intelligence tools that assist us in various aspects of our lives. One key tool for the digital society is Recommender Systems, intelligent systems that learn from our past actions to propose new ones that align with our interests. Some of these systems have specialized in learning from the behavior of user groups to make recommendations to a group of individuals who want to perform a joint task. In this article, we analyze the current state of Group Recommender Systems and propose two new models that use emerging Deep Learning architectures. Experimental results demonstrate the improvement achieved by employing the proposed models compared to the state-of-the-art models using four different datasets. The source code of the models, as well as that of all the experiments conducted, is available in a public repository.
CG-fusion CAM: Online segmentation of laser-induced damage on large-aperture optics
Jul 18, 2023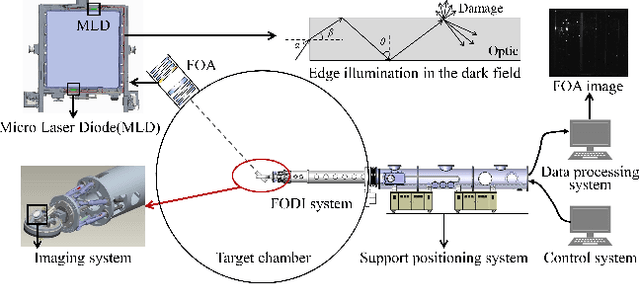

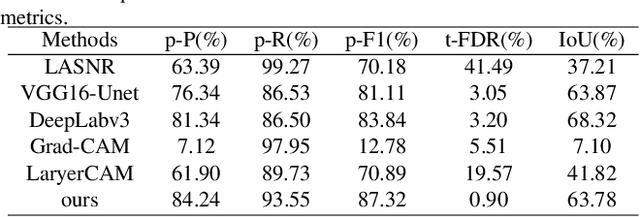
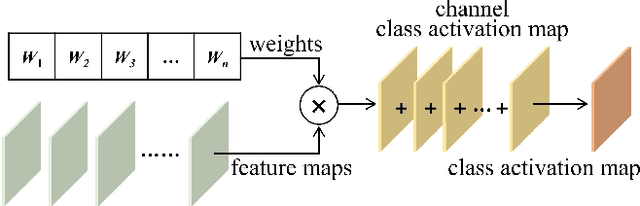
Online segmentation of laser-induced damage on large-aperture optics in high-power laser facilities is challenged by complicated damage morphology, uneven illumination and stray light interference. Fully supervised semantic segmentation algorithms have achieved state-of-the-art performance, but rely on plenty of pixel-level labels, which are time-consuming and labor-consuming to produce. LayerCAM, an advanced weakly supervised semantic segmentation algorithm, can generate pixel-accurate results using only image-level labels, but its scattered and partially under-activated class activation regions degrade segmentation performance. In this paper, we propose a weakly supervised semantic segmentation method with Continuous Gradient CAM and its nonlinear multi-scale fusion (CG-fusion CAM). The method redesigns the way of back-propagating gradients and non-linearly activates the multi-scale fused heatmaps to generate more fine-grained class activation maps with appropriate activation degree for different sizes of damage sites. Experiments on our dataset show that the proposed method can achieve segmentation performance comparable to that of fully supervised algorithms.
Generalizable Classification of UHF Partial Discharge Signals in Gas-Insulated HVDC Systems Using Neural Networks
Jul 18, 2023Undetected partial discharges (PDs) are a safety critical issue in high voltage (HV) gas insulated systems (GIS). While the diagnosis of PDs under AC voltage is well-established, the analysis of PDs under DC voltage remains an active research field. A key focus of these investigations is the classification of different PD sources to enable subsequent sophisticated analysis. In this paper, we propose and analyze a neural network-based approach for classifying PD signals caused by metallic protrusions and conductive particles on the insulator of HVDC GIS, without relying on pulse sequence analysis features. In contrast to previous approaches, our proposed model can discriminate the studied PD signals obtained at negative and positive potentials, while also generalizing to unseen operating voltage multiples. Additionally, we compare the performance of time- and frequency-domain input signals and explore the impact of different normalization schemes to mitigate the influence of free-space path loss between the sensor and defect location.
PixelHuman: Animatable Neural Radiance Fields from Few Images
Jul 18, 2023
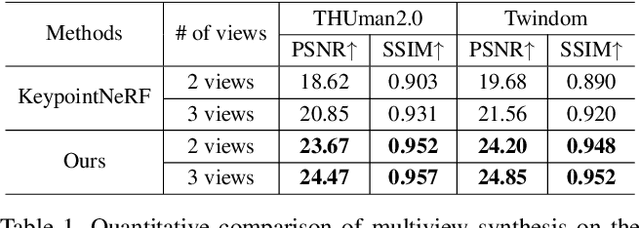
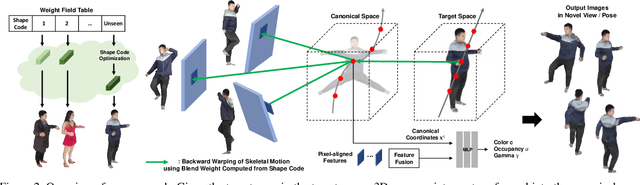
In this paper, we propose PixelHuman, a novel human rendering model that generates animatable human scenes from a few images of a person with unseen identity, views, and poses. Previous work have demonstrated reasonable performance in novel view and pose synthesis, but they rely on a large number of images to train and are trained per scene from videos, which requires significant amount of time to produce animatable scenes from unseen human images. Our method differs from existing methods in that it can generalize to any input image for animatable human synthesis. Given a random pose sequence, our method synthesizes each target scene using a neural radiance field that is conditioned on a canonical representation and pose-aware pixel-aligned features, both of which can be obtained through deformation fields learned in a data-driven manner. Our experiments show that our method achieves state-of-the-art performance in multiview and novel pose synthesis from few-shot images.
Machine Learning for SAT: Restricted Heuristics and New Graph Representations
Jul 18, 2023Boolean satisfiability (SAT) is a fundamental NP-complete problem with many applications, including automated planning and scheduling. To solve large instances, SAT solvers have to rely on heuristics, e.g., choosing a branching variable in DPLL and CDCL solvers. Such heuristics can be improved with machine learning (ML) models; they can reduce the number of steps but usually hinder the running time because useful models are relatively large and slow. We suggest the strategy of making a few initial steps with a trained ML model and then releasing control to classical heuristics; this simplifies cold start for SAT solving and can decrease both the number of steps and overall runtime, but requires a separate decision of when to release control to the solver. Moreover, we introduce a modification of Graph-Q-SAT tailored to SAT problems converted from other domains, e.g., open shop scheduling problems. We validate the feasibility of our approach with random and industrial SAT problems.
ECSIC: Epipolar Cross Attention for Stereo Image Compression
Jul 18, 2023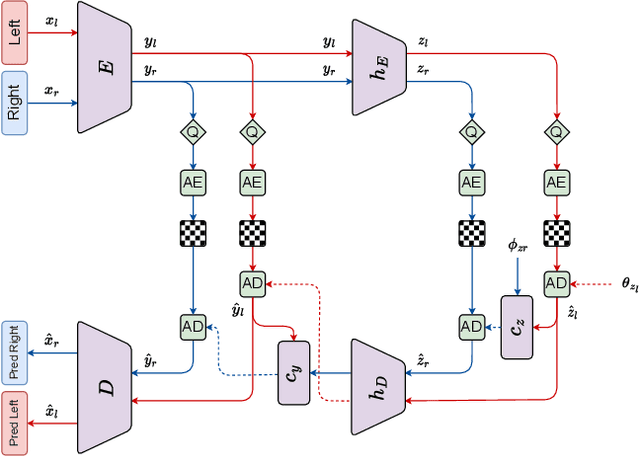
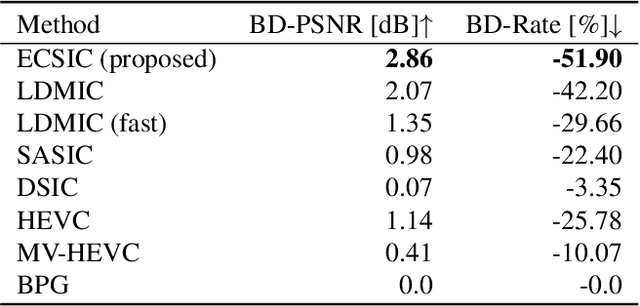
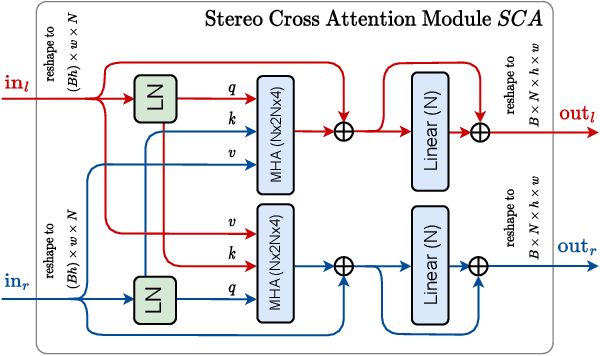
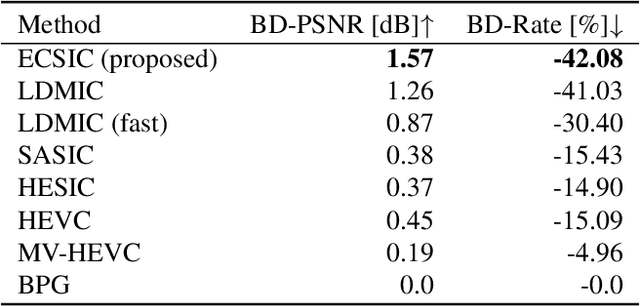
In this paper, we present ECSIC, a novel learned method for stereo image compression. Our proposed method compresses the left and right images in a joint manner by exploiting the mutual information between the images of the stereo image pair using a novel stereo cross attention (SCA) module and two stereo context modules. The SCA module performs cross-attention restricted to the corresponding epipolar lines of the two images and processes them in parallel. The stereo context modules improve the entropy estimation of the second encoded image by using the first image as a context. We conduct an extensive ablation study demonstrating the effectiveness of the proposed modules and a comprehensive quantitative and qualitative comparison with existing methods. ECSIC achieves state-of-the-art performance among stereo image compression models on the two popular stereo image datasets Cityscapes and InStereo2k while allowing for fast encoding and decoding, making it highly practical for real-time applications.
LTE SFBC MIMO Transmitter Modelling and Performance Evaluation
Jul 25, 2023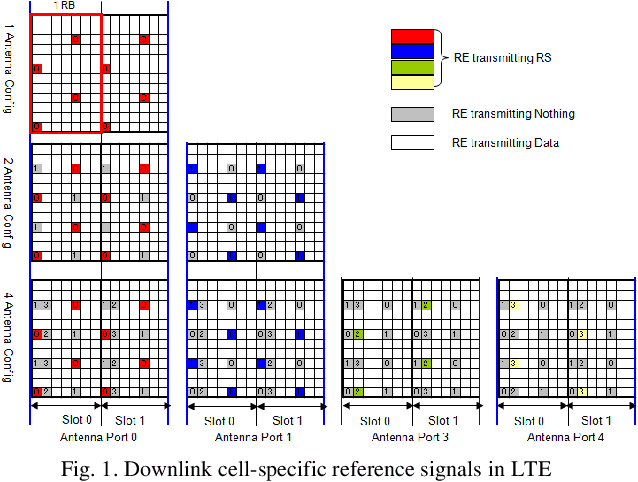
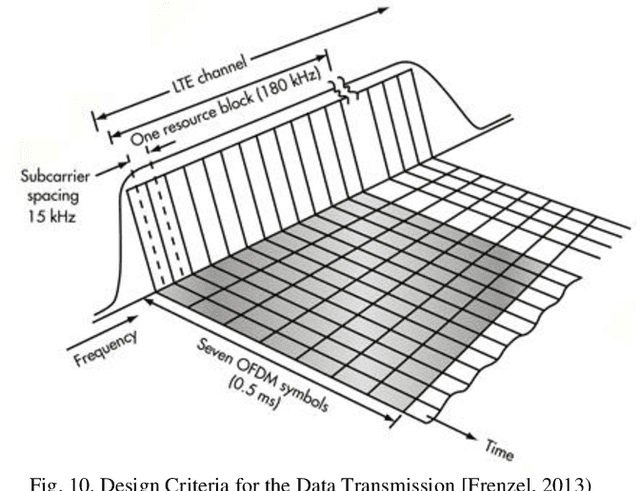
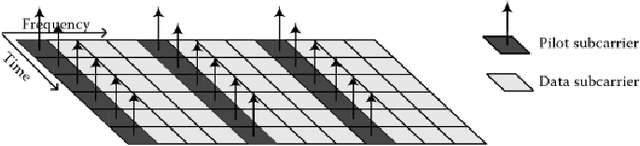
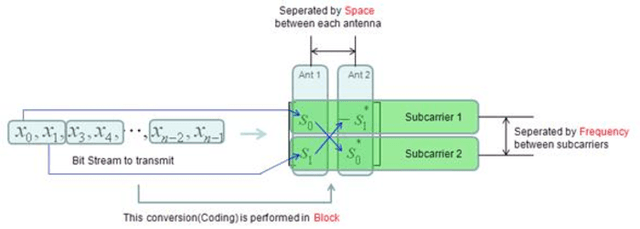
High data rates are one of the most prevalent requirements in current mobile communications. To cover this and other high standards regarding performance, increasing coverage, capacity, and reliability, numerous works have proposed the development of systems employing the combination of several techniques such as Multiple Input Multiple Output (MIMO) wireless technologies with Orthogonal Frequency Division Multiplexing (OFDM) in the evolving 4G wireless communications. Our proposed system is based on the 2x2 MIMO antenna technique, which is defined to enhance the performance of radio communication systems in terms of capacity and spectral efficiency, and the OFDM technique, which can be implemented using two types of sub-carrier mapping modes: Space-Time Block Coding and Space Frequency Block Code. SFBC has been considered in our developed model. The main advantage of SFBC over STBC is that SFBC encodes two modulated symbols over two subcarriers of the same OFDM symbol, whereas STBC encodes two modulated symbols over two subcarriers of the same OFDM symbol; thus, the coding is performed in the frequency domain. Our solution aims to demonstrate the performance analysis of the Space Frequency Block Codes scheme, increasing the Signal Noise Ratio (SNR) at the receiver and decreasing the Bit Error Rate (BER) through the use of 4 QAM, 16 QAM and 64QAM modulation over a 2x2 MIMO channel for an LTE downlink transmission, in different channel radio environments. In this work, an analytical tool to evaluate the performance of SFBC - Orthogonal Frequency Division Multiplexing, using two transmit antennas and two receive antennas has been implemented, and the analysis using the average SNR has been considered as a sufficient statistic to describe the performance of SFBC in the 3GPP Long Term Evolution system over Multiple Input Multiple Output channels.
Mitigating Memory Wall Effects in CNN Engines with On-the-Fly Weights Generation
Jul 25, 2023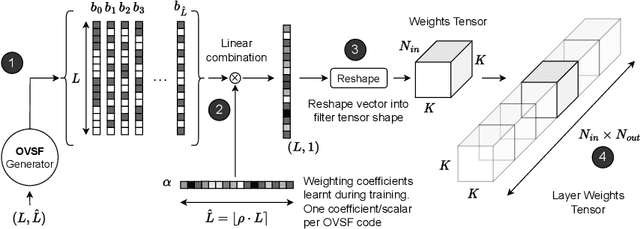
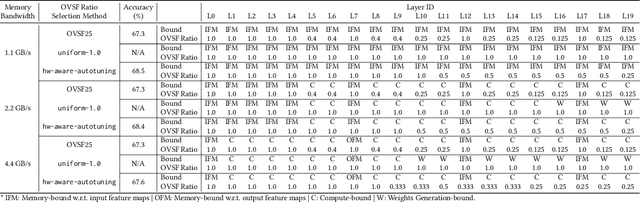


The unprecedented accuracy of convolutional neural networks (CNNs) across a broad range of AI tasks has led to their widespread deployment in mobile and embedded settings. In a pursuit for high-performance and energy-efficient inference, significant research effort has been invested in the design of FPGA-based CNN accelerators. In this context, single computation engines constitute a popular approach to support diverse CNN modes without the overhead of fabric reconfiguration. Nevertheless, this flexibility often comes with significantly degraded performance on memory-bound layers and resource underutilisation due to the suboptimal mapping of certain layers on the engine's fixed configuration. In this work, we investigate the implications in terms of CNN engine design for a class of models that introduce a pre-convolution stage to decompress the weights at run time. We refer to these approaches as on-the-fly. This paper presents unzipFPGA, a novel CNN inference system that counteracts the limitations of existing CNN engines. The proposed framework comprises a novel CNN hardware architecture that introduces a weights generator module that enables the on-chip on-the-fly generation of weights, alleviating the negative impact of limited bandwidth on memory-bound layers. We further enhance unzipFPGA with an automated hardware-aware methodology that tailors the weights generation mechanism to the target CNN-device pair, leading to an improved accuracy-performance balance. Finally, we introduce an input selective processing element (PE) design that balances the load between PEs in suboptimally mapped layers. The proposed framework yields hardware designs that achieve an average of 2.57x performance efficiency gain over highly optimised GPU designs for the same power constraints and up to 3.94x higher performance density over a diverse range of state-of-the-art FPGA-based CNN accelerators.
Two-stream Multi-level Dynamic Point Transformer for Two-person Interaction Recognition
Jul 22, 2023
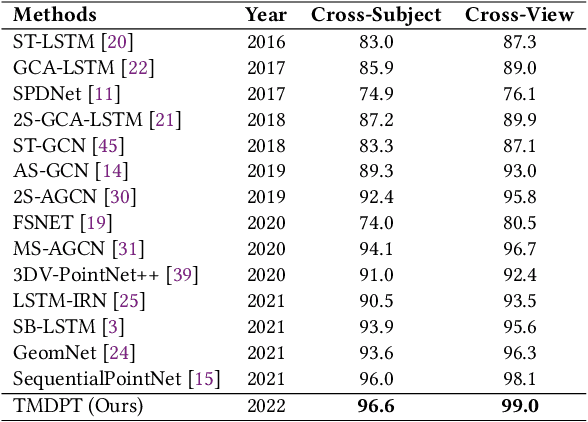
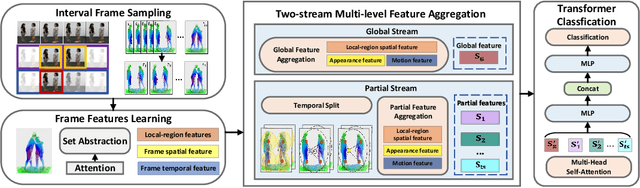
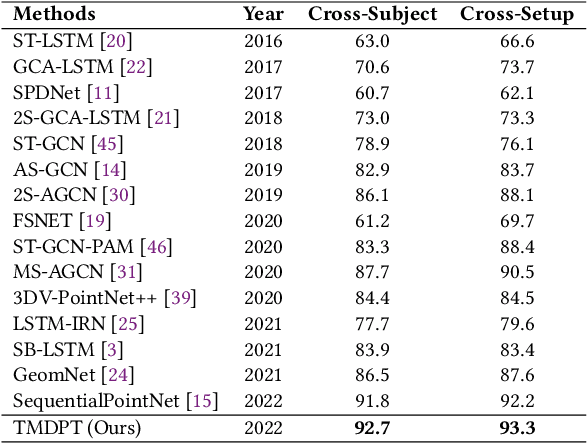
As a fundamental aspect of human life, two-person interactions contain meaningful information about people's activities, relationships, and social settings. Human action recognition serves as the foundation for many smart applications, with a strong focus on personal privacy. However, recognizing two-person interactions poses more challenges due to increased body occlusion and overlap compared to single-person actions. In this paper, we propose a point cloud-based network named Two-stream Multi-level Dynamic Point Transformer for two-person interaction recognition. Our model addresses the challenge of recognizing two-person interactions by incorporating local-region spatial information, appearance information, and motion information. To achieve this, we introduce a designed frame selection method named Interval Frame Sampling (IFS), which efficiently samples frames from videos, capturing more discriminative information in a relatively short processing time. Subsequently, a frame features learning module and a two-stream multi-level feature aggregation module extract global and partial features from the sampled frames, effectively representing the local-region spatial information, appearance information, and motion information related to the interactions. Finally, we apply a transformer to perform self-attention on the learned features for the final classification. Extensive experiments are conducted on two large-scale datasets, the interaction subsets of NTU RGB+D 60 and NTU RGB+D 120. The results show that our network outperforms state-of-the-art approaches across all standard evaluation settings.