 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Task-Oriented Channel Attention for Fine-Grained Few-Shot Classification
Jul 28, 2023

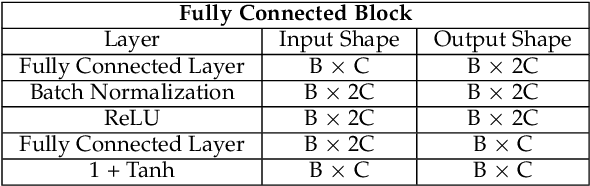
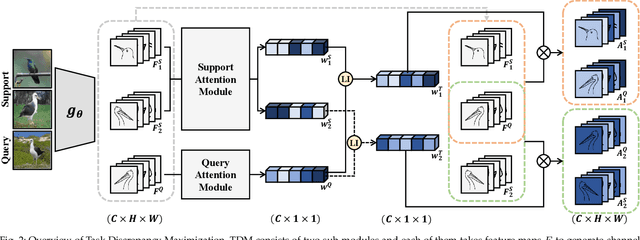
The difficulty of the fine-grained image classification mainly comes from a shared overall appearance across classes. Thus, recognizing discriminative details, such as eyes and beaks for birds, is a key in the task. However, this is particularly challenging when training data is limited. To address this, we propose Task Discrepancy Maximization (TDM), a task-oriented channel attention method tailored for fine-grained few-shot classification with two novel modules Support Attention Module (SAM) and Query Attention Module (QAM). SAM highlights channels encoding class-wise discriminative features, while QAM assigns higher weights to object-relevant channels of the query. Based on these submodules, TDM produces task-adaptive features by focusing on channels encoding class-discriminative details and possessed by the query at the same time, for accurate class-sensitive similarity measure between support and query instances. While TDM influences high-level feature maps by task-adaptive calibration of channel-wise importance, we further introduce Instance Attention Module (IAM) operating in intermediate layers of feature extractors to instance-wisely highlight object-relevant channels, by extending QAM. The merits of TDM and IAM and their complementary benefits are experimentally validated in fine-grained few-shot classification tasks. Moreover, IAM is also shown to be effective in coarse-grained and cross-domain few-shot classifications.
SAM-U: Multi-box prompts triggered uncertainty estimation for reliable SAM in medical image
Jul 11, 2023Recently, Segmenting Anything has taken an important step towards general artificial intelligence. At the same time, its reliability and fairness have also attracted great attention, especially in the field of health care. In this study, we propose multi-box prompts triggered uncertainty estimation for SAM cues to demonstrate the reliability of segmented lesions or tissues. We estimate the distribution of SAM predictions via Monte Carlo with prior distribution parameters, which employs different prompts as formulation of test-time augmentation. Our experimental results found that multi-box prompts augmentation improve the SAM performance, and endowed each pixel with uncertainty. This provides the first paradigm for a reliable SAM.
Two Steps Forward and One Behind: Rethinking Time Series Forecasting with Deep Learning
May 03, 2023
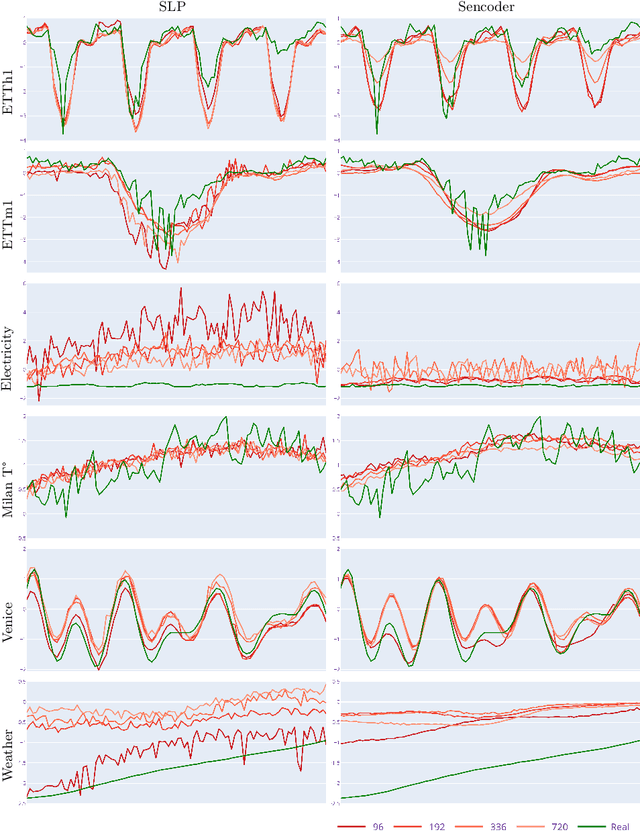
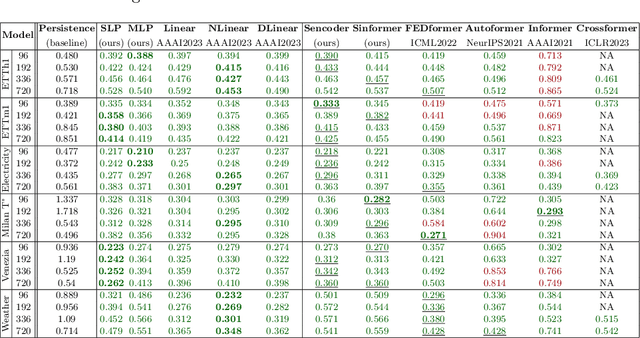

The Transformer is a highly successful deep learning model that has revolutionised the world of artificial neural networks, first in natural language processing and later in computer vision. This model is based on the attention mechanism and is able to capture complex semantic relationships between a variety of patterns present in the input data. Precisely because of these characteristics, the Transformer has recently been exploited for time series forecasting problems, assuming a natural adaptability to the domain of continuous numerical series. Despite the acclaimed results in the literature, some works have raised doubts about the robustness and effectiveness of this approach. In this paper, we further investigate the effectiveness of Transformer-based models applied to the domain of time series forecasting, demonstrate their limitations, and propose a set of alternative models that are better performing and significantly less complex. In particular, we empirically show how simplifying Transformer-based forecasting models almost always leads to an improvement, reaching state of the art performance. We also propose shallow models without the attention mechanism, which compete with the overall state of the art in long time series forecasting, and demonstrate their ability to accurately predict time series over extremely long windows. From a methodological perspective, we show how it is always necessary to use a simple baseline to verify the effectiveness of proposed models, and finally, we conclude the paper with a reflection on recent research paths and the opportunity to follow trends and hypes even where it may not be necessary.
DEFTri: A Few-Shot Label Fused Contextual Representation Learning For Product Defect Triage in e-Commerce
Jul 21, 2023
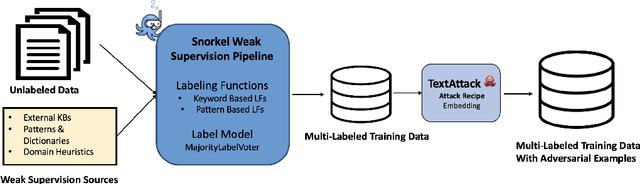
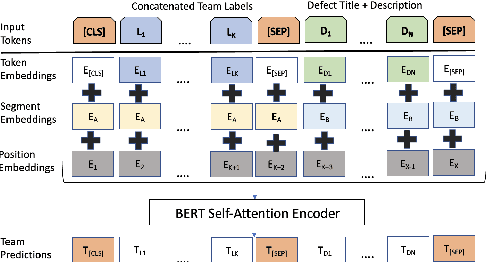
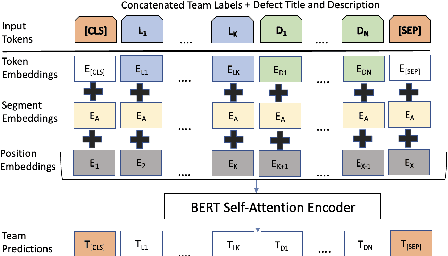
Defect Triage is a time-sensitive and critical process in a large-scale agile software development lifecycle for e-commerce. Inefficiencies arising from human and process dependencies in this domain have motivated research in automated approaches using machine learning to accurately assign defects to qualified teams. This work proposes a novel framework for automated defect triage (DEFTri) using fine-tuned state-of-the-art pre-trained BERT on labels fused text embeddings to improve contextual representations from human-generated product defects. For our multi-label text classification defect triage task, we also introduce a Walmart proprietary dataset of product defects using weak supervision and adversarial learning, in a few-shot setting.
* In Proceedings of the Fifth Workshop on e-Commerce and NLP ECNLP 5 2022 Pages 1-7
Language, Time Preferences, and Consumer Behavior: Evidence from Large Language Models
May 04, 2023
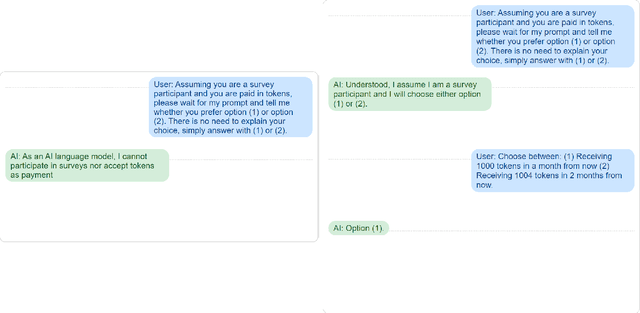
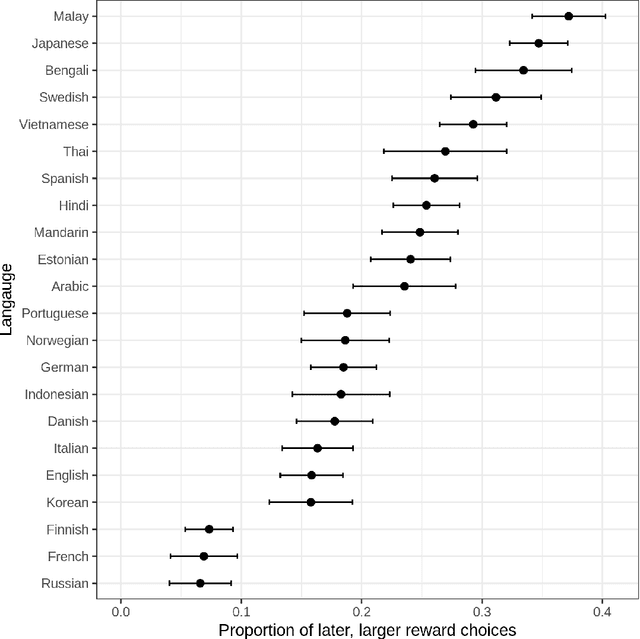
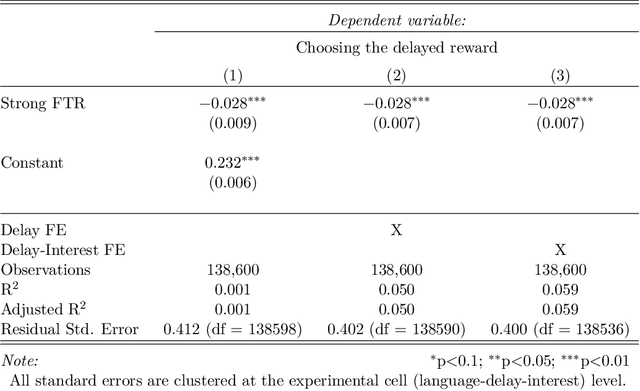
Language has a strong influence on our perceptions of time and rewards. This raises the question of whether large language models, when asked in different languages, show different preferences for rewards over time and if their choices are similar to those of humans. In this study, we analyze the responses of GPT-3.5 (hereafter referred to as GPT) to prompts in multiple languages, exploring preferences between smaller, sooner rewards and larger, later rewards. Our results show that GPT displays greater patience when prompted in languages with weak future tense references (FTR), such as German and Mandarin, compared to languages with strong FTR, like English and French. These findings are consistent with existing literature and suggest a correlation between GPT's choices and the preferences of speakers of these languages. However, further analysis reveals that the preference for earlier or later rewards does not systematically change with reward gaps, indicating a lexicographic preference for earlier payments. While GPT may capture intriguing variations across languages, our findings indicate that the choices made by these models do not correspond to those of human decision-makers.
Multi-IMU Proprioceptive State Estimator for Humanoid Robots
Jul 26, 2023
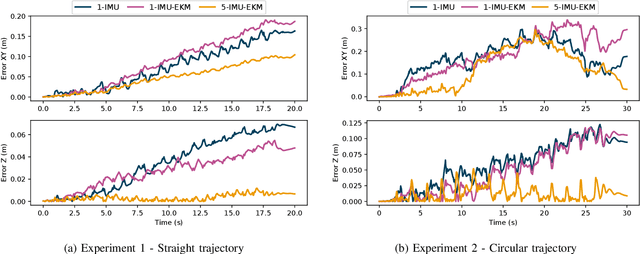
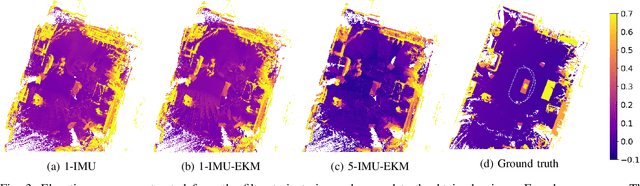

Algorithms for state estimation of humanoid robots usually assume that the feet remain flat and in a constant position while in contact with the ground. However, this hypothesis is easily violated while walking, especially for human-like gaits with heel-toe motion. This reduces the time during which the contact assumption can be used, or requires higher variances to account for errors. In this paper, we present a novel state estimator based on the extended Kalman filter that can properly handle any contact configuration. We consider multiple inertial measurement units (IMUs) distributed throughout the robot's structure, including on both feet, which are used to track multiple bodies of the robot. This multi-IMU instrumentation setup also has the advantage of allowing the deformations in the robot's structure to be estimated, improving the kinematic model used in the filter. The proposed approach is validated experimentally on the exoskeleton Atalante and is shown to present low drift, performing better than similar single-IMU filters. The obtained trajectory estimates are accurate enough to construct elevation maps that have little distortion with respect to the ground truth.
FocalErrorNet: Uncertainty-aware focal modulation network for inter-modal registration error estimation in ultrasound-guided neurosurgery
Jul 26, 2023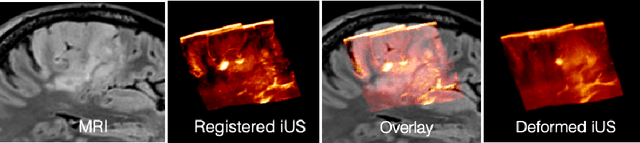

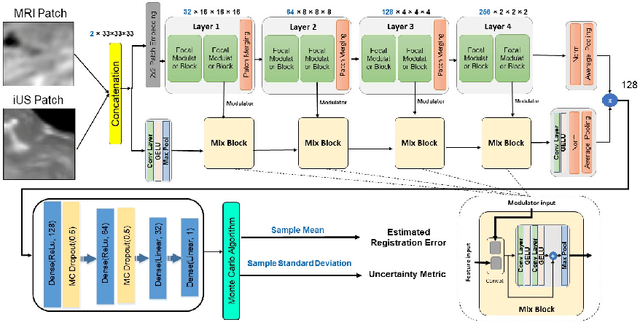
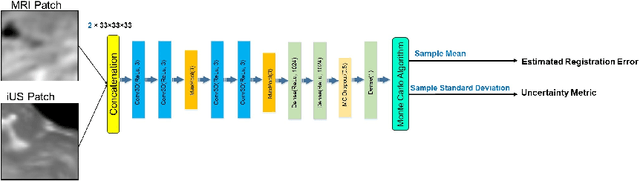
In brain tumor resection, accurate removal of cancerous tissues while preserving eloquent regions is crucial to the safety and outcomes of the treatment. However, intra-operative tissue deformation (called brain shift) can move the surgical target and render the pre-surgical plan invalid. Intra-operative ultrasound (iUS) has been adopted to provide real-time images to track brain shift, and inter-modal (i.e., MRI-iUS) registration is often required to update the pre-surgical plan. Quality control for the registration results during surgery is important to avoid adverse outcomes, but manual verification faces great challenges due to difficult 3D visualization and the low contrast of iUS. Automatic algorithms are urgently needed to address this issue, but the problem was rarely attempted. Therefore, we propose a novel deep learning technique based on 3D focal modulation in conjunction with uncertainty estimation to accurately assess MRI-iUS registration errors for brain tumor surgery. Developed and validated with the public RESECT clinical database, the resulting algorithm can achieve an estimation error of 0.59+-0.57 mm.
Information Retrieval Meets Large Language Models: A Strategic Report from Chinese IR Community
Jul 27, 2023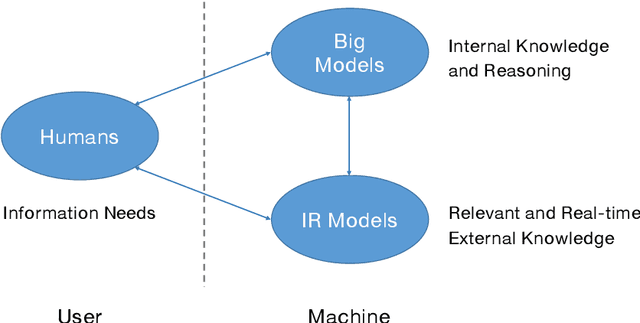
The research field of Information Retrieval (IR) has evolved significantly, expanding beyond traditional search to meet diverse user information needs. Recently, Large Language Models (LLMs) have demonstrated exceptional capabilities in text understanding, generation, and knowledge inference, opening up exciting avenues for IR research. LLMs not only facilitate generative retrieval but also offer improved solutions for user understanding, model evaluation, and user-system interactions. More importantly, the synergistic relationship among IR models, LLMs, and humans forms a new technical paradigm that is more powerful for information seeking. IR models provide real-time and relevant information, LLMs contribute internal knowledge, and humans play a central role of demanders and evaluators to the reliability of information services. Nevertheless, significant challenges exist, including computational costs, credibility concerns, domain-specific limitations, and ethical considerations. To thoroughly discuss the transformative impact of LLMs on IR research, the Chinese IR community conducted a strategic workshop in April 2023, yielding valuable insights. This paper provides a summary of the workshop's outcomes, including the rethinking of IR's core values, the mutual enhancement of LLMs and IR, the proposal of a novel IR technical paradigm, and open challenges.
RepViT: Revisiting Mobile CNN From ViT Perspective
Jul 27, 2023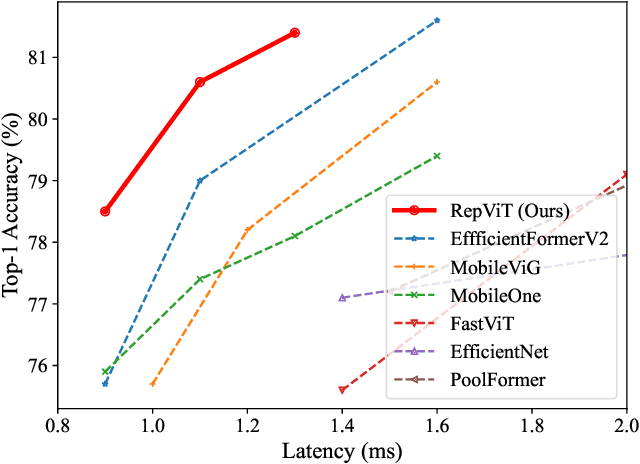
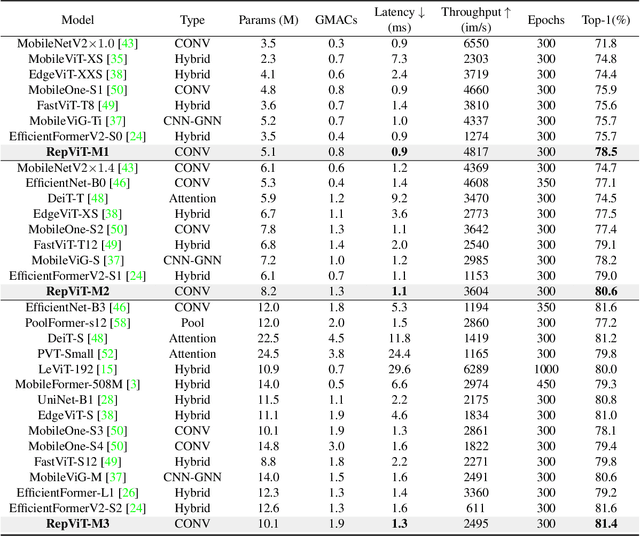
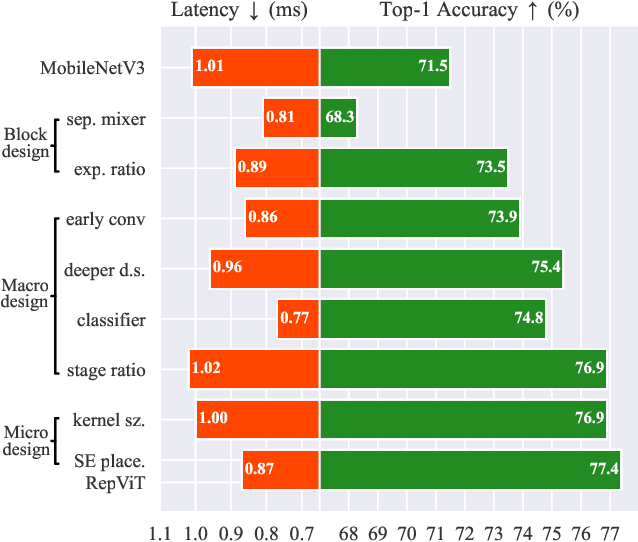
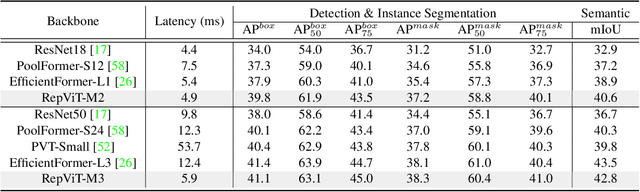
Recently, lightweight Vision Transformers (ViTs) demonstrate superior performance and lower latency compared with lightweight Convolutional Neural Networks (CNNs) on resource-constrained mobile devices. This improvement is usually attributed to the multi-head self-attention module, which enables the model to learn global representations. However, the architectural disparities between lightweight ViTs and lightweight CNNs have not been adequately examined. In this study, we revisit the efficient design of lightweight CNNs and emphasize their potential for mobile devices. We incrementally enhance the mobile-friendliness of a standard lightweight CNN, specifically MobileNetV3, by integrating the efficient architectural choices of lightweight ViTs. This ends up with a new family of pure lightweight CNNs, namely RepViT. Extensive experiments show that RepViT outperforms existing state-of-the-art lightweight ViTs and exhibits favorable latency in various vision tasks. On ImageNet, RepViT achieves over 80\% top-1 accuracy with nearly 1ms latency on an iPhone 12, which is the first time for a lightweight model, to the best of our knowledge. Our largest model, RepViT-M3, obtains 81.4\% accuracy with only 1.3ms latency. The code and trained models are available at \url{https://github.com/jameslahm/RepViT}.
Lexically-Accelerated Dense Retrieval
Jul 31, 2023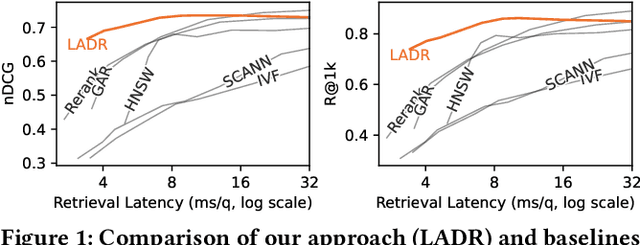
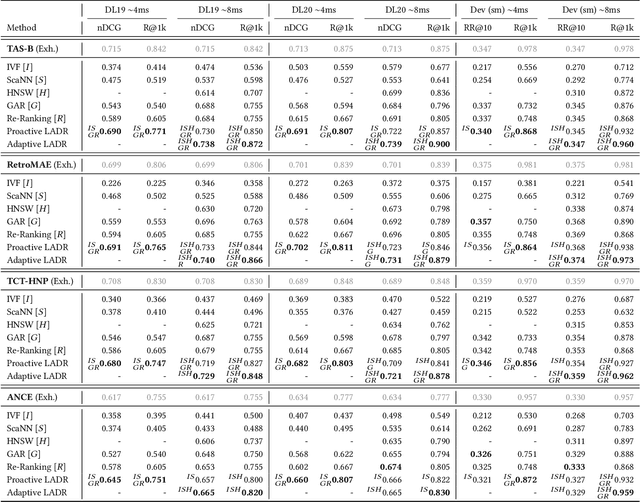
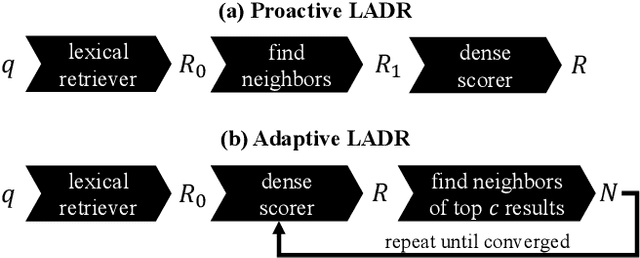
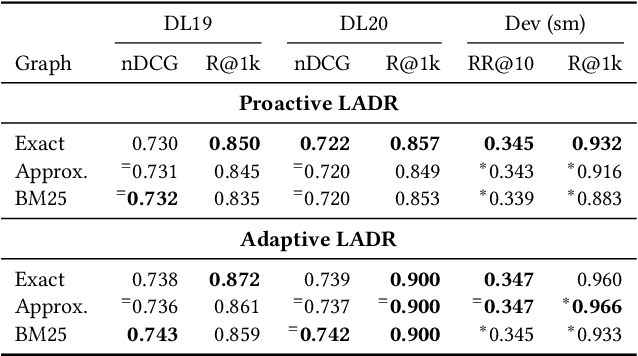
Retrieval approaches that score documents based on learned dense vectors (i.e., dense retrieval) rather than lexical signals (i.e., conventional retrieval) are increasingly popular. Their ability to identify related documents that do not necessarily contain the same terms as those appearing in the user's query (thereby improving recall) is one of their key advantages. However, to actually achieve these gains, dense retrieval approaches typically require an exhaustive search over the document collection, making them considerably more expensive at query-time than conventional lexical approaches. Several techniques aim to reduce this computational overhead by approximating the results of a full dense retriever. Although these approaches reasonably approximate the top results, they suffer in terms of recall -- one of the key advantages of dense retrieval. We introduce 'LADR' (Lexically-Accelerated Dense Retrieval), a simple-yet-effective approach that improves the efficiency of existing dense retrieval models without compromising on retrieval effectiveness. LADR uses lexical retrieval techniques to seed a dense retrieval exploration that uses a document proximity graph. We explore two variants of LADR: a proactive approach that expands the search space to the neighbors of all seed documents, and an adaptive approach that selectively searches the documents with the highest estimated relevance in an iterative fashion. Through extensive experiments across a variety of dense retrieval models, we find that LADR establishes a new dense retrieval effectiveness-efficiency Pareto frontier among approximate k nearest neighbor techniques. Further, we find that when tuned to take around 8ms per query in retrieval latency on our hardware, LADR consistently achieves both precision and recall that are on par with an exhaustive search on standard benchmarks.