 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Graph-Level Embedding for Time-Evolving Graphs
Jun 01, 2023

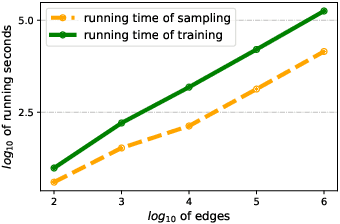
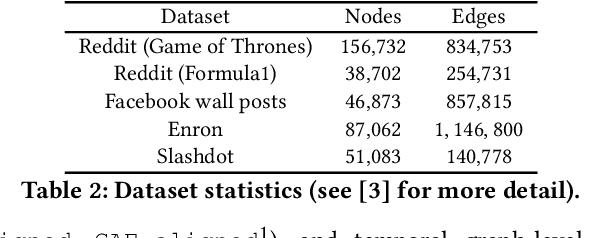
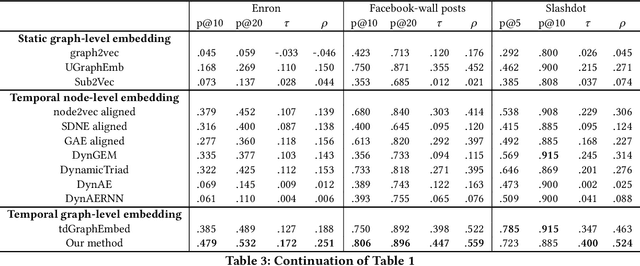
Graph representation learning (also known as network embedding) has been extensively researched with varying levels of granularity, ranging from nodes to graphs. While most prior work in this area focuses on node-level representation, limited research has been conducted on graph-level embedding, particularly for dynamic or temporal networks. However, learning low-dimensional graph-level representations for dynamic networks is critical for various downstream graph retrieval tasks such as temporal graph similarity ranking, temporal graph isomorphism, and anomaly detection. In this paper, we present a novel method for temporal graph-level embedding that addresses this gap. Our approach involves constructing a multilayer graph and using a modified random walk with temporal backtracking to generate temporal contexts for the graph's nodes. We then train a "document-level" language model on these contexts to generate graph-level embeddings. We evaluate our proposed model on five publicly available datasets for the task of temporal graph similarity ranking, and our model outperforms baseline methods. Our experimental results demonstrate the effectiveness of our method in generating graph-level embeddings for dynamic networks.
RePAD2: Real-Time, Lightweight, and Adaptive Anomaly Detection for Open-Ended Time Series
Mar 02, 2023
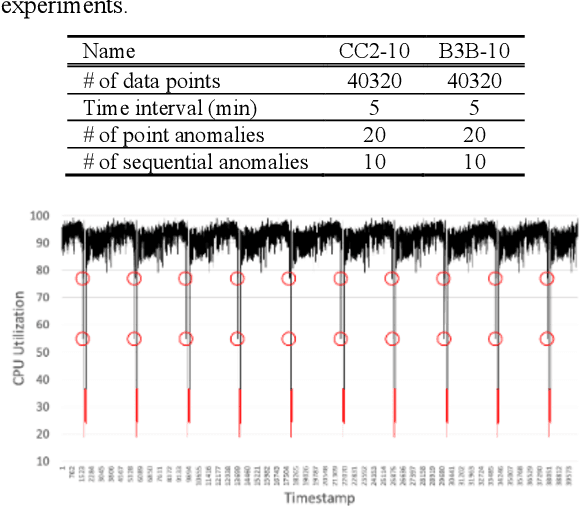


An open-ended time series refers to a series of data points indexed in time order without an end. Such a time series can be found everywhere due to the prevalence of Internet of Things. Providing lightweight and real-time anomaly detection for open-ended time series is highly desirable to industry and organizations since it allows immediate response and avoids potential financial loss. In the last few years, several real-time time series anomaly detection approaches have been introduced. However, they might exhaust system resources when they are applied to open-ended time series for a long time. To address this issue, in this paper we propose RePAD2, a lightweight real-time anomaly detection approach for open-ended time series by improving its predecessor RePAD, which is one of the state-of-the-art anomaly detection approaches. We conducted a series of experiments to compare RePAD2 with RePAD and another similar detection approach based on real-world time series datasets, and demonstrated that RePAD2 can address the mentioned resource exhaustion issue while offering comparable detection accuracy and slightly less time consumption.
A User Study on Explainable Online Reinforcement Learning for Adaptive Systems
Jul 09, 2023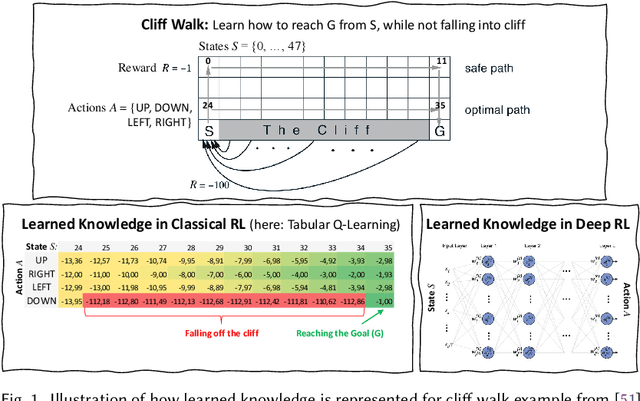

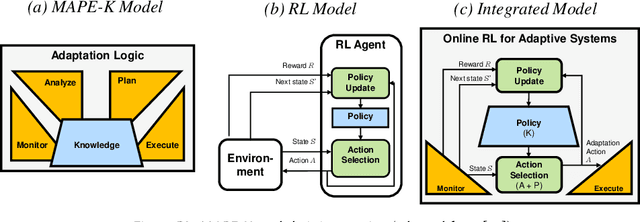

Online reinforcement learning (RL) is increasingly used for realizing adaptive systems in the presence of design time uncertainty. Online RL facilitates learning from actual operational data and thereby leverages feedback only available at runtime. However, Online RL requires the definition of an effective and correct reward function, which quantifies the feedback to the RL algorithm and thereby guides learning. With Deep RL gaining interest, the learned knowledge is no longer explicitly represented, but is represented as a neural network. For a human, it becomes practically impossible to relate the parametrization of the neural network to concrete RL decisions. Deep RL thus essentially appears as a black box, which severely limits the debugging of adaptive systems. We previously introduced the explainable RL technique XRL-DINE, which provides visual insights into why certain decisions were made at important time points. Here, we introduce an empirical user study involving 54 software engineers from academia and industry to assess (1) the performance of software engineers when performing different tasks using XRL-DINE and (2) the perceived usefulness and ease of use of XRL-DINE.
Fairness Scheduling in User-Centric Cell-Free Massive MIMO Wireless Networks
Jul 03, 2023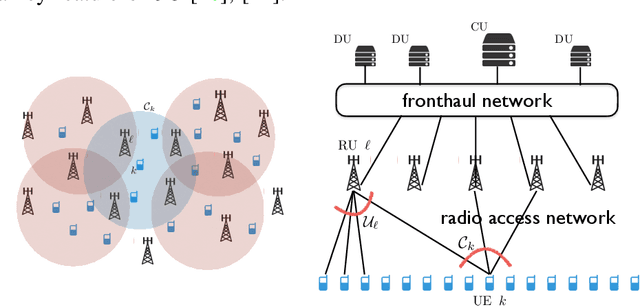
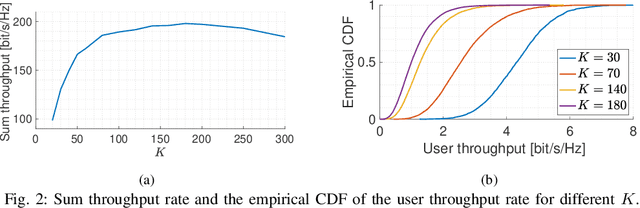
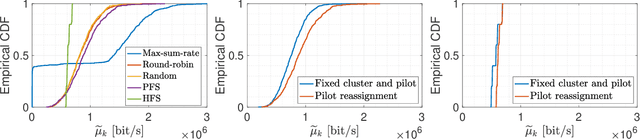
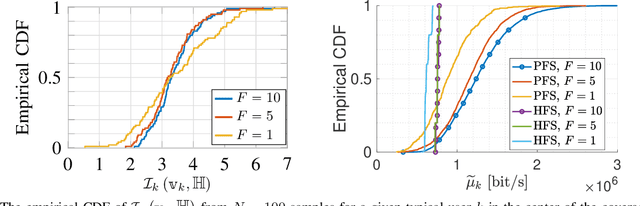
We consider a user-centric cell-free massive MIMO wireless network with $L$ remote radio units, each with $M$ antennas, serving $K_{\rm tot}$ user equipments (UEs). Most of the literature considers the regime $LM \gg K_{\rm tot}$, where the $K$ UEs are active on each time-frequency slot, and evaluates the system performance in terms of ergodic rates. In this paper, we take a quite different viewpoint. We observe that the regime of $LM \gg K_{\rm tot}$ corresponds to a lightly loaded system with low sum spectral efficiency (SE). In contrast, in most relevant scenarios, the number of UEs is much larger than the total number of antennas, but users are not all active at the same time. To achieve high sum SE and handle $K_{\rm tot} \gg ML$, users must be scheduled over the time-frequency resource. The number of active users $K_{\rm act} \leq K_{\rm tot}$ must be chosen such that: 1) the network operates close to its maximum SE; 2) the active user set must be chosen dynamically over time in order to enforce fairness in terms of per-user time-averaged throughput rates. The fairness scheduling problem is formulated as the maximization of a concave componentwise non-decreasing network utility function of the per-user rates. Intermittent user activity imposes slot-by-slot coding/decoding which prevents the achievability of ergodic rates. Hence, we model the per-slot service rates using information outage probability. To obtain a tractable problem, we make a decoupling assumption on the CDF of the instantaneous mutual information seen at each UE $k$ receiver. We approximately enforce this condition with a conflict graph that prevents the simultaneous scheduling of users with large pilot contamination and propose an adaptive scheme for instantaneous service rate scheduling. Overall, the proposed dynamic scheduling is robust to system model uncertainties and can be easily implemented in practice.
LTE SFBC MIMO Transmitter Modelling and Performance Evaluation
Jul 25, 2023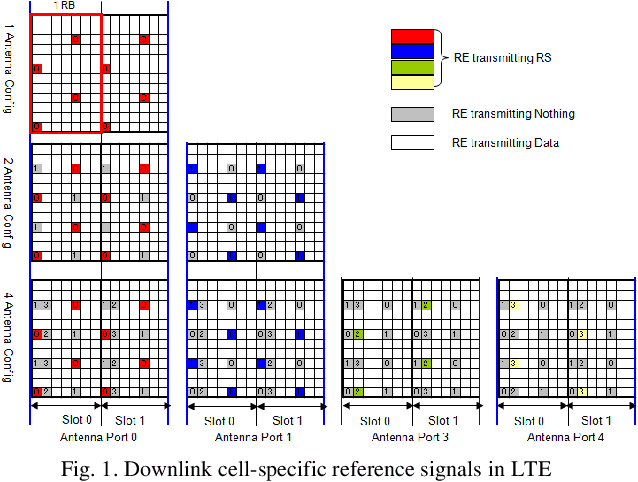
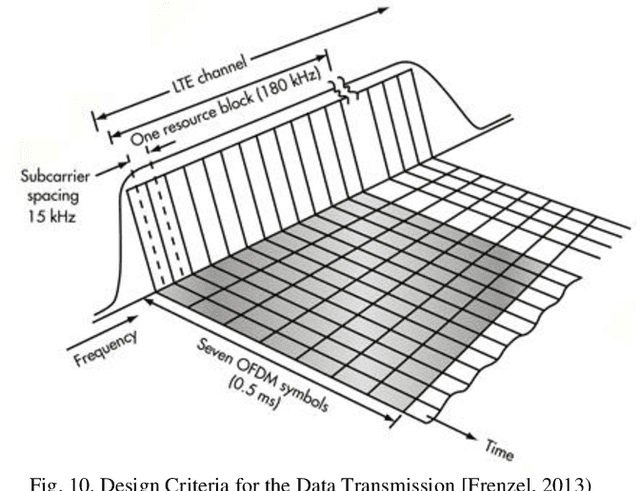
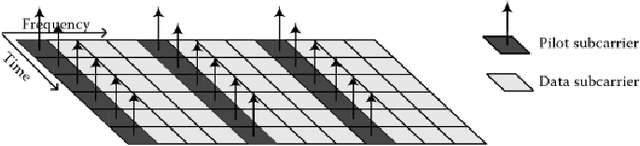
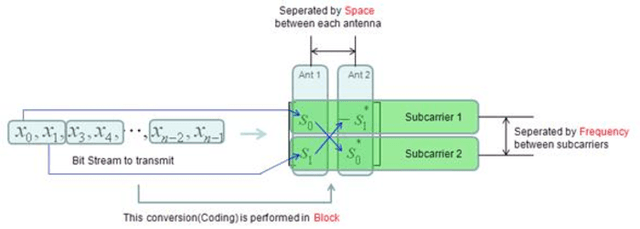
High data rates are one of the most prevalent requirements in current mobile communications. To cover this and other high standards regarding performance, increasing coverage, capacity, and reliability, numerous works have proposed the development of systems employing the combination of several techniques such as Multiple Input Multiple Output (MIMO) wireless technologies with Orthogonal Frequency Division Multiplexing (OFDM) in the evolving 4G wireless communications. Our proposed system is based on the 2x2 MIMO antenna technique, which is defined to enhance the performance of radio communication systems in terms of capacity and spectral efficiency, and the OFDM technique, which can be implemented using two types of sub-carrier mapping modes: Space-Time Block Coding and Space Frequency Block Code. SFBC has been considered in our developed model. The main advantage of SFBC over STBC is that SFBC encodes two modulated symbols over two subcarriers of the same OFDM symbol, whereas STBC encodes two modulated symbols over two subcarriers of the same OFDM symbol; thus, the coding is performed in the frequency domain. Our solution aims to demonstrate the performance analysis of the Space Frequency Block Codes scheme, increasing the Signal Noise Ratio (SNR) at the receiver and decreasing the Bit Error Rate (BER) through the use of 4 QAM, 16 QAM and 64QAM modulation over a 2x2 MIMO channel for an LTE downlink transmission, in different channel radio environments. In this work, an analytical tool to evaluate the performance of SFBC - Orthogonal Frequency Division Multiplexing, using two transmit antennas and two receive antennas has been implemented, and the analysis using the average SNR has been considered as a sufficient statistic to describe the performance of SFBC in the 3GPP Long Term Evolution system over Multiple Input Multiple Output channels.
Mitigating Memory Wall Effects in CNN Engines with On-the-Fly Weights Generation
Jul 25, 2023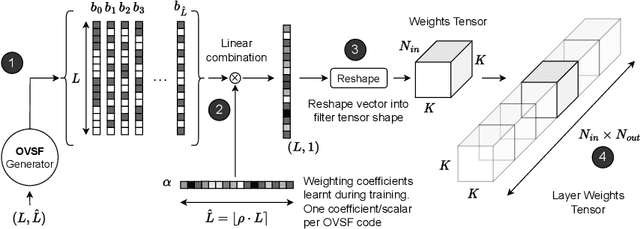
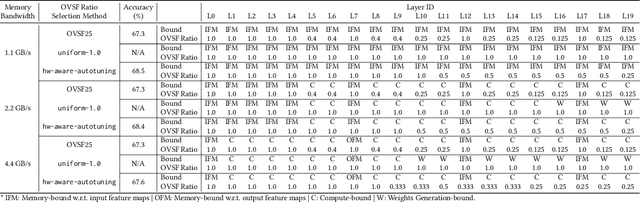


The unprecedented accuracy of convolutional neural networks (CNNs) across a broad range of AI tasks has led to their widespread deployment in mobile and embedded settings. In a pursuit for high-performance and energy-efficient inference, significant research effort has been invested in the design of FPGA-based CNN accelerators. In this context, single computation engines constitute a popular approach to support diverse CNN modes without the overhead of fabric reconfiguration. Nevertheless, this flexibility often comes with significantly degraded performance on memory-bound layers and resource underutilisation due to the suboptimal mapping of certain layers on the engine's fixed configuration. In this work, we investigate the implications in terms of CNN engine design for a class of models that introduce a pre-convolution stage to decompress the weights at run time. We refer to these approaches as on-the-fly. This paper presents unzipFPGA, a novel CNN inference system that counteracts the limitations of existing CNN engines. The proposed framework comprises a novel CNN hardware architecture that introduces a weights generator module that enables the on-chip on-the-fly generation of weights, alleviating the negative impact of limited bandwidth on memory-bound layers. We further enhance unzipFPGA with an automated hardware-aware methodology that tailors the weights generation mechanism to the target CNN-device pair, leading to an improved accuracy-performance balance. Finally, we introduce an input selective processing element (PE) design that balances the load between PEs in suboptimally mapped layers. The proposed framework yields hardware designs that achieve an average of 2.57x performance efficiency gain over highly optimised GPU designs for the same power constraints and up to 3.94x higher performance density over a diverse range of state-of-the-art FPGA-based CNN accelerators.
Continuous-Time Range-Only Pose Estimation
Apr 18, 2023
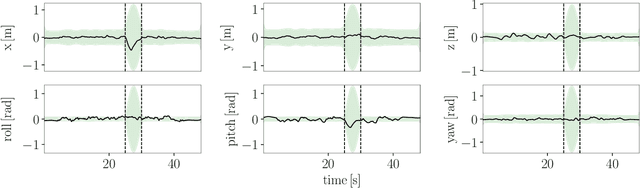
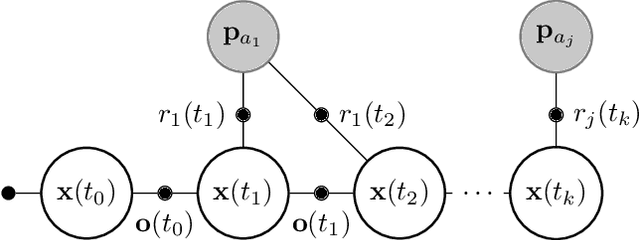
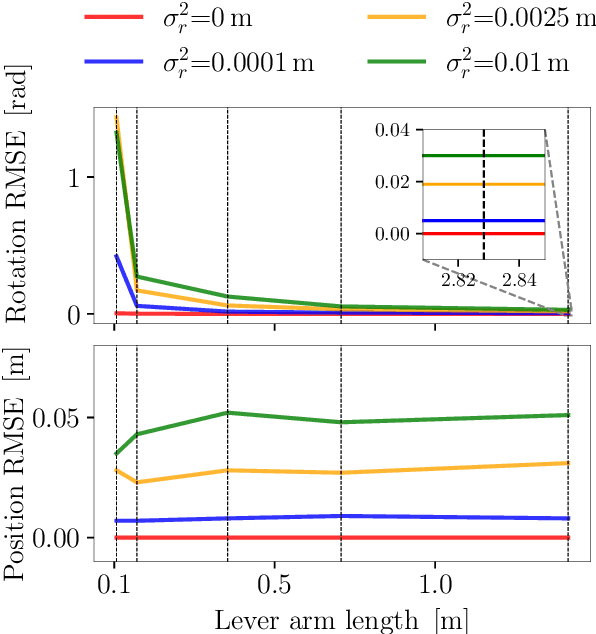
Range-only (RO) localization involves determining the position of a mobile robot by measuring the distance to specific anchors. RO localization is challenging since the measurements are low-dimensional and a single range sensor does not have enough information to estimate the full pose of the robot. As such, range sensors are typically coupled with other sensing modalities such as wheel encoders or inertial measurement units (IMUs) to estimate the full pose. In this work, we propose a continuous-time Gaussian process (GP)- based trajectory estimation method to estimate the full pose of a robot using only range measurements from multiple range sensors. Results from simulation and real experiments show that our proposed method, using off-the-shelf range sensors, is able to achieve comparable performance and in some cases outperform alternative state-of-the-art sensor-fusion methods that use additional sensing modalities.
Zero-DeepSub: Zero-Shot Deep Subspace Reconstruction for Rapid Multiparametric Quantitative MRI Using 3D-QALAS
Jul 04, 2023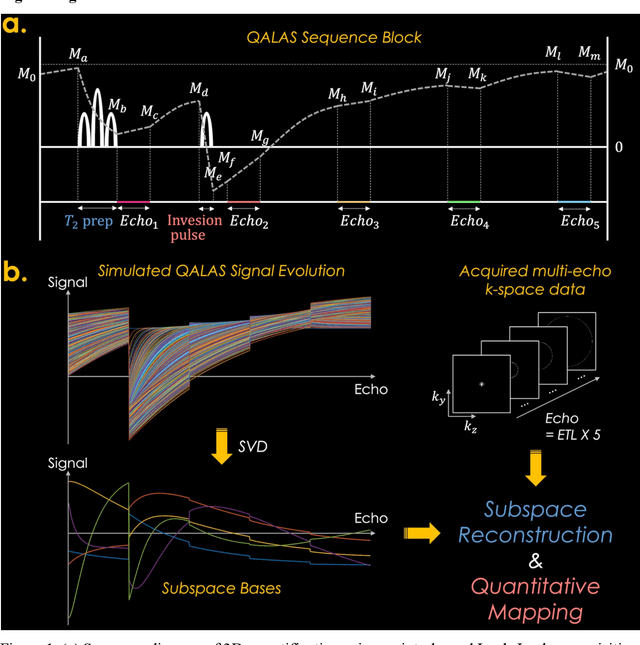
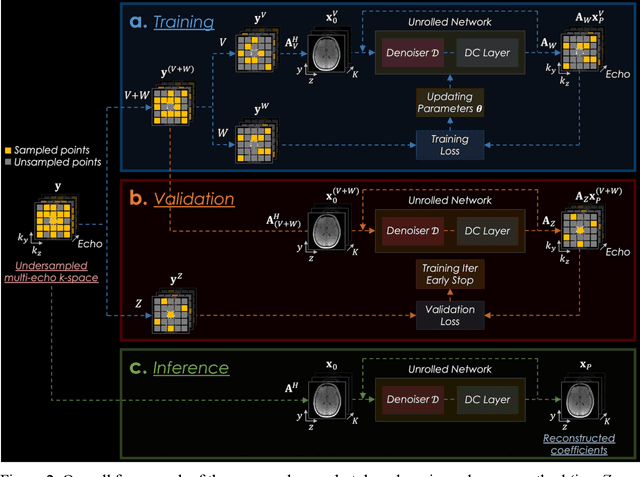
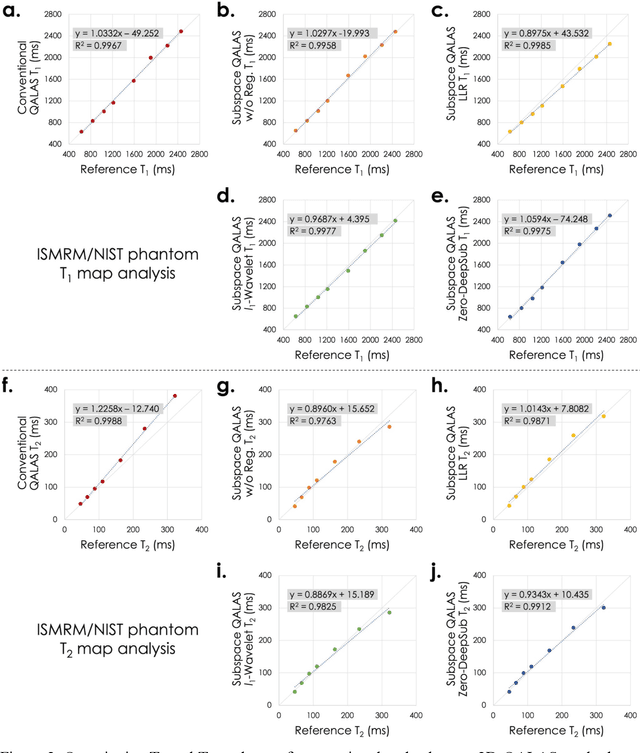
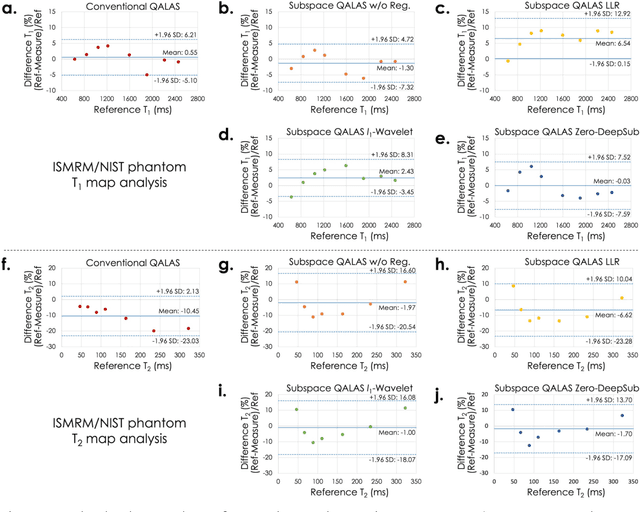
Purpose: To develop and evaluate methods for 1) reconstructing 3D-quantification using an interleaved Look-Locker acquisition sequence with T2 preparation pulse (3D-QALAS) time-series images using a low-rank subspace method, which enables accurate and rapid T1 and T2 mapping, and 2) improving the fidelity of subspace QALAS by combining scan-specific deep-learning-based reconstruction and subspace modeling. Methods: A low-rank subspace method for 3D-QALAS (i.e., subspace QALAS) and zero-shot deep-learning subspace method (i.e., Zero-DeepSub) were proposed for rapid and high fidelity T1 and T2 mapping and time-resolved imaging using 3D-QALAS. Using an ISMRM/NIST system phantom, the accuracy of the T1 and T2 maps estimated using the proposed methods was evaluated by comparing them with reference techniques. The reconstruction performance of the proposed subspace QALAS using Zero-DeepSub was evaluated in vivo and compared with conventional QALAS at high reduction factors of up to 9-fold. Results: Phantom experiments showed that subspace QALAS had good linearity with respect to the reference methods while reducing biases compared to conventional QALAS, especially for T2 maps. Moreover, in vivo results demonstrated that subspace QALAS had better g-factor maps and could reduce voxel blurring, noise, and artifacts compared to conventional QALAS and showed robust performance at up to 9-fold acceleration with Zero-DeepSub, which enabled whole-brain T1, T2, and PD mapping at 1 mm isotropic resolution within 2 min of scan time. Conclusion: The proposed subspace QALAS along with Zero-DeepSub enabled high fidelity and rapid whole-brain multiparametric quantification and time-resolved imaging.
Two-stream Multi-level Dynamic Point Transformer for Two-person Interaction Recognition
Jul 22, 2023
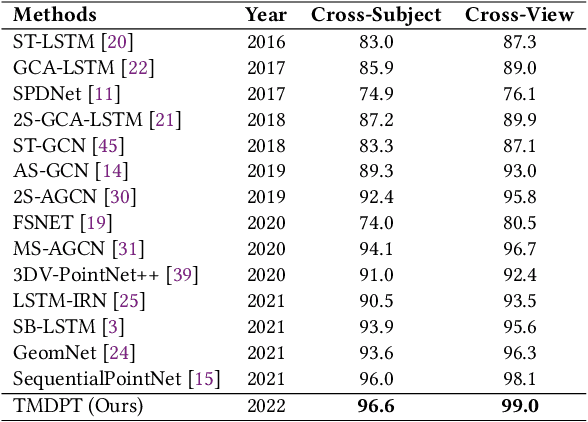
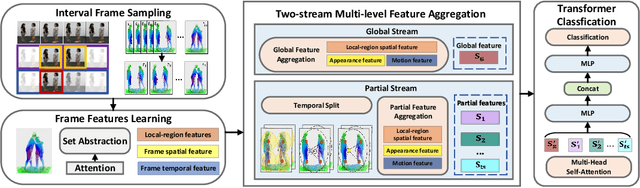
As a fundamental aspect of human life, two-person interactions contain meaningful information about people's activities, relationships, and social settings. Human action recognition serves as the foundation for many smart applications, with a strong focus on personal privacy. However, recognizing two-person interactions poses more challenges due to increased body occlusion and overlap compared to single-person actions. In this paper, we propose a point cloud-based network named Two-stream Multi-level Dynamic Point Transformer for two-person interaction recognition. Our model addresses the challenge of recognizing two-person interactions by incorporating local-region spatial information, appearance information, and motion information. To achieve this, we introduce a designed frame selection method named Interval Frame Sampling (IFS), which efficiently samples frames from videos, capturing more discriminative information in a relatively short processing time. Subsequently, a frame features learning module and a two-stream multi-level feature aggregation module extract global and partial features from the sampled frames, effectively representing the local-region spatial information, appearance information, and motion information related to the interactions. Finally, we apply a transformer to perform self-attention on the learned features for the final classification. Extensive experiments are conducted on two large-scale datasets, the interaction subsets of NTU RGB+D 60 and NTU RGB+D 120. The results show that our network outperforms state-of-the-art approaches across all standard evaluation settings.
Racial Bias Trends in the Text of US Legal Opinions
Jul 04, 2023Although there is widespread recognition of racial bias in US law, it is unclear how such bias appears in the language of law, namely judicial opinions, and whether it varies across time period or region. Building upon approaches for measuring implicit racial bias in large-scale corpora, we approximate GloVe word embeddings for over 6 million US federal and state court cases from 1860 to 2009. We find strong evidence of racial bias across nearly all regions and time periods, as traditionally Black names are more closely associated with pre-classified "unpleasant" terms whereas traditionally White names are more closely associated with pre-classified "pleasant" terms. We also test whether legal opinions before 1950 exhibit more implicit racial bias than those after 1950, as well as whether opinions from Southern states exhibit less change in racial bias than those from Northeastern states. We do not find evidence of elevated bias in legal opinions before 1950, or evidence that legal opinions from Northeastern states show greater change in racial bias over time compared to Southern states. These results motivate further research into institutionalized racial bias.